
数仓血缘应用(一):表血缘热度
文章目录
前言
在数据仓库的建设过程中,伴随着时间的迁移或多或少会遇到一些问题:
1、模型越来越多,表也越来越多,运维压力愈来愈大,当一大波问题来临时,感觉每张表都需要保障,但对优先保障哪些表没有数据支撑
2、业务口径的变化导致需要对下游数据链路进行改造,但数据链路较多,优先保障哪些链路、那些表没有数据支撑
3、数仓应用层报表在业务侧实际的使用情况如何?哪些模型可以下线?(减少人力成本与资源消耗成本)
面对这些问题我们怎么应用数据去提供更好的支持?
一、价值衡量指标——应用层
数据仓库的价值在于提供数据整合和一致性、支持决策制定、提供业务洞察力、提升工作效率和改善风险管理能力。它为企业提供了一个强大的数据分析和管理平台,帮助企业更好地理解和运营其业务。
数仓的价值在于为企业、为相关业务提供强大的数据分析能力。而如何衡量数仓哪些模型更重要——无外乎业务应用的更加频繁。呢么通过BI的pv、uv数据我们就可以获取到数仓应用层报表的重要程度。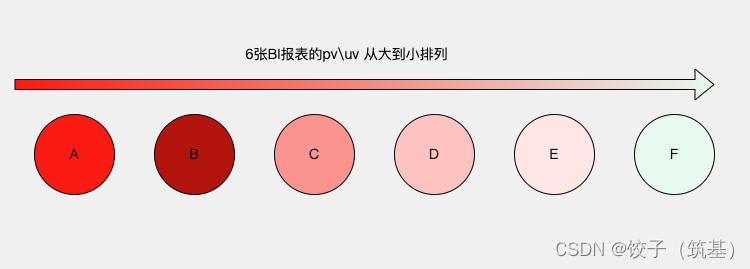
结论:从上图来看,应用层的报表从左到右访问量逐级递减。我们很清晰的可以知道表A对业务的帮助是最大的。
二、血缘节点应用——热度
1、指标透传(应用层——>数仓)
业务需要分析的数据一般在数仓中加工完成后通过ads层出库至应用层数据库并通过BI工具配置成相关报表呈现给业务进行分析,也就是上图我们展示的表A~F。
这里我们仅做一个简单的模型模型分析(忽略配置BI工具时的多表关联等情况),可以近似的认为应用层BI报表与数仓ads层表存在一一映射的关系。这样我们就可以将应用层的价值指标pv、uv透传至数仓表,为每一个数仓表打上热度标签。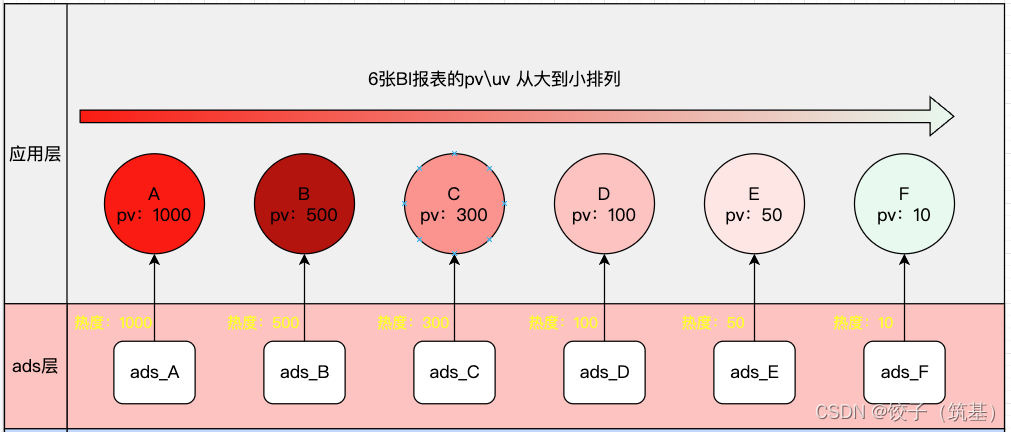
2、指标应用(热度)
2.1、数仓血缘节点关系
数据血缘也称为数据血统或谱系,是来描述数据的来源和派生关系。说白了就是这个数据是怎么来的,从那个表来到那个表去。即下图所示的表节点间关系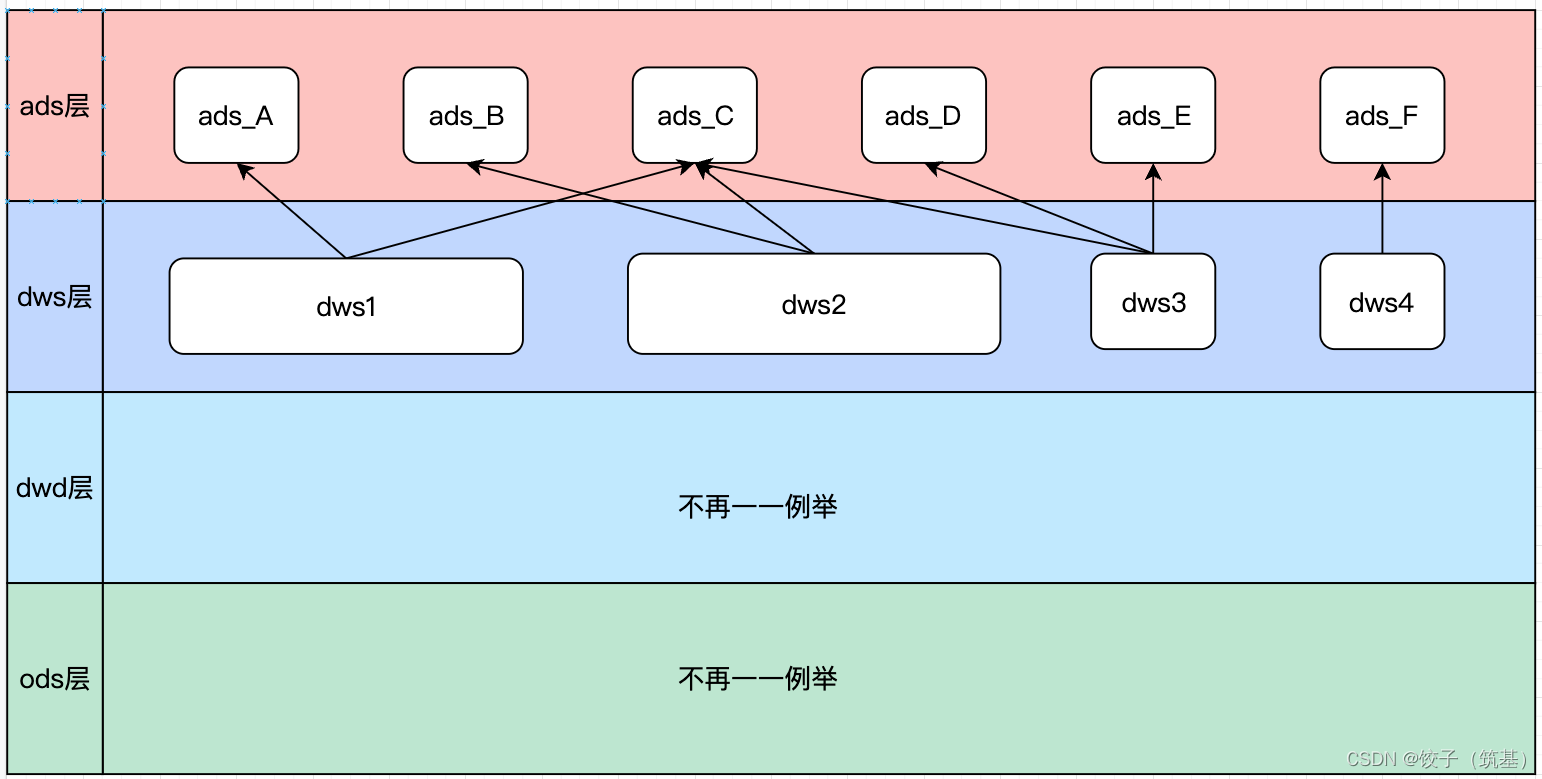
2.2、热度
通过结合数仓血缘节点关系与应用层指标,我们可以获取数仓各层级表的应用热度,为我们的运维工作提供相应的数据支持。
注:这里热度仅通过简单的加法运算处理。实际应用中在数仓不同的层级间还需计算相关的层级系数,保障热度数据更有效。
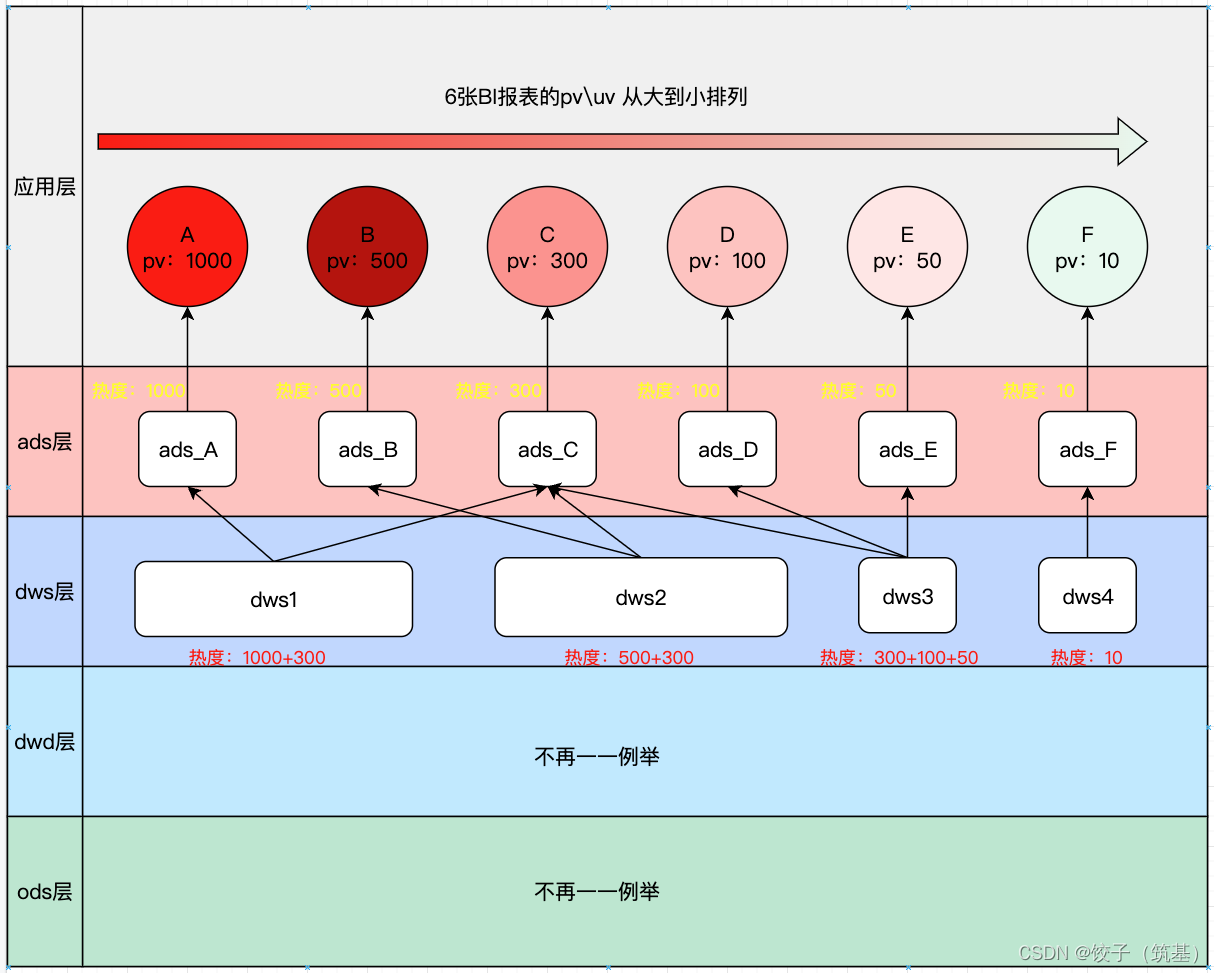
2.3、热度应用
表名热度topdws113001ads_A10002dws28003ads_B5004dws34505ads_C3006ads_D1007ads_E508dws4109ads_F1010
结论:根据数据热度我们可以得出表dws1时在当前模型中的影响较大,保障优先级最高!
总结
本文仅仅简单介绍了数据血缘在数仓中的一种应用场景。而血缘的价值远非如此。期待和大家一起交流学习。
版权归原作者 饺子(筑基) 所有, 如有侵权,请联系我们删除。