
Selenium(Web端自动测试)
Selenium是一个用于Web应用程序测试的工具:中文是
硒
- 开源
- 跨平台:linux、windows、mac
- 核心:可以在多个浏览器上进行自动化测试
- 多语言
Selenium WebDriver控制原理
- Selenium Client Library:通过他们提供的库来编写脚本,可以使用Java、Python等进行编写脚本
- JSON Wire Protocol是在HTTP服务器之间传输信息的REST风格的API。
- Browser Drivers:浏览器驱动,不同浏览器会有一个单独的浏览器驱动程序
- Browsers:Selenium 支持的浏览器,Firefox、Chrome、IE、Safar等
安装环境
- Python 3.5以上
- 安装PyCharm
- 安装selenium包(在pycharm或者cmd中)
# 安装pip install selenium# 卸载pip uninstall selenium# 查看pip show selenium - WebDriver安装谷歌Driver国内镜像:http://npm.taobao.org/mirrors/chromedriver/```注意要去下载和自己电脑谷歌浏览器相匹配的版本```全局:下载解压缩后,可以将webdriver的路径配置到环境变量中,方便使用局部:下载解压缩后,将可执行文件放入到本地项目目录中
入门案例
import time
from selenium.webdriver.chrome.service import Service
from selenium import webdriver
# 定义chrome驱动去地址
path = Service('chromedriver.exe')# webdriver 获取浏览器对象
driver = webdriver.Chrome(service = path)# 准备一个网址
url ="https://www.baidu.com/"
driver.get(url)# 模拟时间
time.sleep(5)# 回收资源
driver.quit()
元素定位
普通定位
如百度的输入框,输入文字后+点击查询
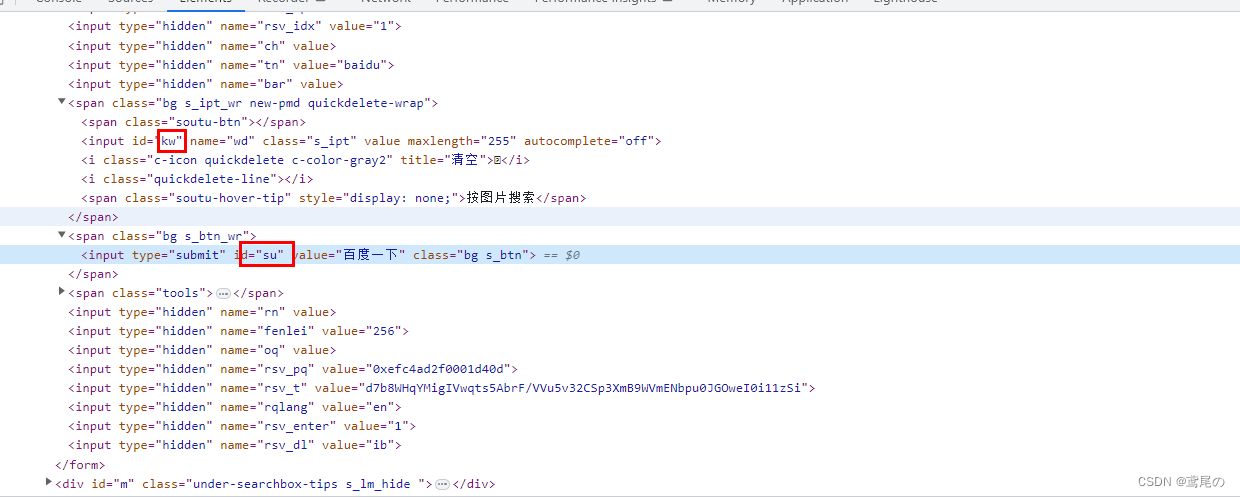
通过ID定位
那么可以在代码中进行定位
from selenium.webdriver.chrome.service import Service
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
# 定义chrome驱动去地址
path = Service('chromedriver.exe')# webdriver 获取浏览器对象
driver = webdriver.Chrome(service=path)# 准备一个网址
url ="https://www.baidu.com/"
driver.get(url)# 根据id查询到元素,发送关键词
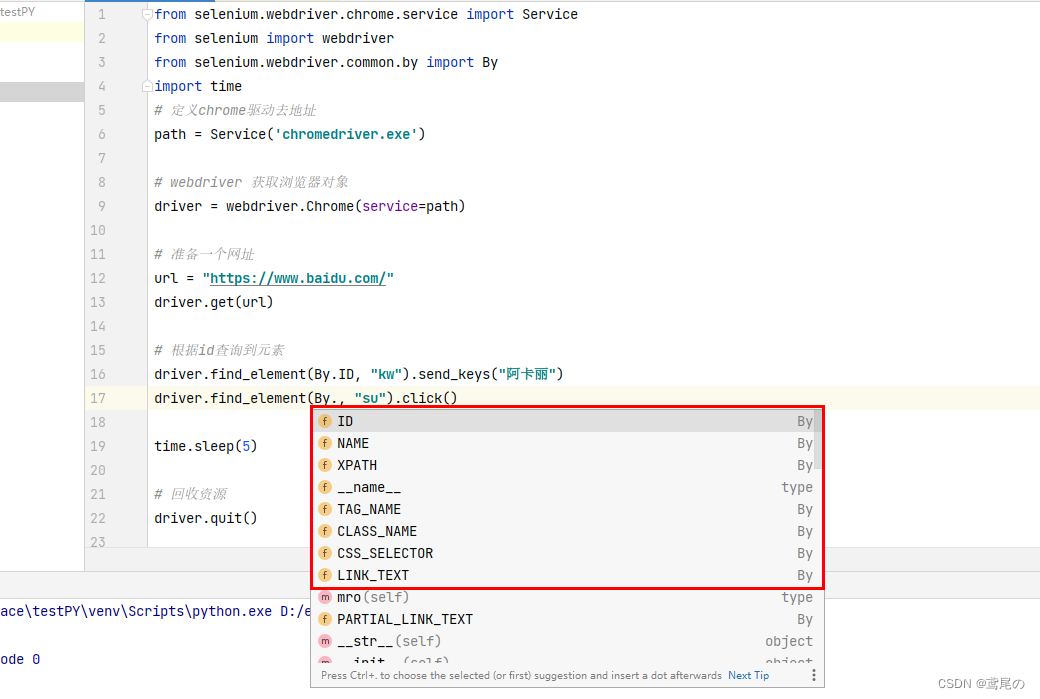
driver.find_element(By.ID,"kw").send_keys("阿卡丽")# 同理找到查询按钮的id,执行click事件
driver.find_element(By.ID,"su").click()
time.sleep(5)# 回收资源
driver.quit()
其他定位:name,tag_name,class_name等
a标签定位
# 定位a标签, link_text | partial_link_text# 方式一(完整)
driver.find_element(By.LINK_TEXT,"hao123").click()# 方式二(模糊)
driver.find_element(By.PARTIAL_LINK_TEXT,"hao1").click()
需要注意的是:如果相同的规则会对应多个标签,那么这些方法只会返回第一个标签,除非使用的是find_elements()方法
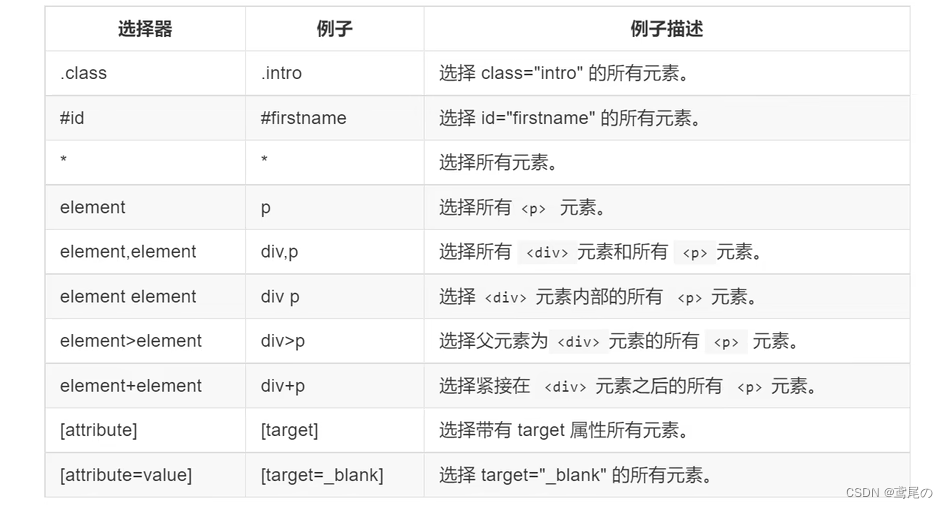
CSS选择器定位
了解下CSS选择器基本知识
# 通过CSS选择器# id
driver.find_element(By.CSS_SELECTOR,"#kw").send_keys("阿卡丽")# 属性选择器
driver.find_element(By.CSS_SELECTOR,"[name=wd]").send_keys("阿卡丽")
xpath获取元素
xpath=xml path
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gSvzKOqF-1677652557333)(imgs3/4.png)]](https://img-blog.csdnimg.cn/577237f9e633468caea824d251d78658.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hVasXHVs-1677652557333)(imgs3/5.png)]](https://img-blog.csdnimg.cn/670ce6fc9b73404290b0190f98471b88.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ETC0VGRr-1677652557334)(imgs3/6.png)]](https://img-blog.csdnimg.cn/f30e586bbc4649aba3294306151dc845.png)
# 通过XPAth定位
driver.find_element(By.XPATH,"//*[@id='kw']").send_keys("阿卡丽")
driver.find_element(By.XPATH,"//*[@id='su']").click()
driver.find_element(By.XPATH,"//*[text()='hao123']").click()
浏览器其他操作
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-382JrOLL-1677652557334)(imgs3/7.png)]](https://img-blog.csdnimg.cn/11a0a84def3e4e94871216cefae6aef2.png)
# 设置最大化
driver.maximize_window()# 设置浏览器 宽高像素
driver.set_window_size(1920,1080)# 设置窗口位置
driver.set_window_position(200,200)# 刷新
driver.refresh()# 前进
driver.forward()# 后退
driver.back()# 关闭 当前页面
driver.close()# 关闭浏览器
driver.quit()# 获取浏览器属性print(driver.title)print(driver.current_url)
页面等待
某些html元素可能加载稍微慢些,那么我们的测试脚本就需要进行页面等待完毕后,再执行测试过程。
等待方式:
- 强制等待(不推荐)
time.sleep(1) - 显示等待(导包太多,麻烦)
from selenium.webdriver.support.wait import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECWebDriverWait(driver,5).until(EC.presence_of_element_located((By.XPATH,"//*[@id='1']/div/div[1]/div/div[2]/a[2]/img")))driver.find_element(By.XPATH,"//*[@id='1']/div/div[1]/div/div[2]/a[2]/img").click() - 隐式等待
# 隐式等待(等所有的元素)driver.implicitly_wait(5)
元素操作
操作
- clear() 清除文本
- send_keys() 模拟输入
- click() 单击元素
元素属性获取
- size : 返回元素大小
- text :获取元素文本
- get_attribute() 获取某个属性值
- is_display() :元素是否可见
- is_enabled() :元素是否可用
# 清除文本
driver.find_element(By.ID,"kw").clear()print(driver.find_element(By.ID,"kw").size)# 获取大小print(driver.find_element(By.ID,"kw").text)# 获取文本print(driver.find_element(By.ID,"kw").is_enabled())# 是否可用print(driver.find_element(By.ID,"kw").is_displayed())# 是否显示print(driver.find_element(By.XPATH,"//*[text()='新闻']").get_attribute("href"))# 获取属性##########{'height':43,'width':549}TrueTrue
http://news.baidu.com/
模拟鼠标操作
selenium模拟鼠标操作:
- 创建ActionChains对象,使用ActionChains对象的方法进行操作 - context_click() : 鼠标右击- double_click() : 鼠标双击- drag_and_drop():拖动- move_to_element() : 悬停
- 通过perform()执行以上的鼠标操作方法
import time
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
url ="https://www.baidu.com/"
driver.get(url)
action = ActionChains(driver)
action.context_click(driver.find_element(By.ID,"su"))# 右键
action.move_to_element(driver.find_element(By.CLASS_NAME,"soutu-btn"))# 悬停
action.drag_and_drop(driver.find_element(By.ID,"div1"), driver.find_element(By.ID,"div2"))# 拖拽,把一个元素拖拽到另一个元素中# 执行
action.perform()
time.sleep(5)
driver.quit()
键盘操作
- send_keys()
在
Keys类
中封装了所有的键盘操作
实例
import time
from selenium import webdriver
from selenium.webdriver import Keys
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
url ="https://www.baidu.com/"
driver.get(url)
el = driver.find_element(By.ID,"kw")# 输入Python
el.send_keys("Python")
time.sleep(2)# ctrl+a 全选
el.send_keys(Keys.CONTROL,"a")# 退格
el.send_keys(Keys.BACKSPACE)# 输入其他
el.send_keys("阿卡丽")
time.sleep(2)
el.send_keys(Keys.CONTROL,"a")
time.sleep(2)# 复制
el.send_keys(Keys.CONTROL,"c")
el.send_keys(Keys.CONTROL,"a")
time.sleep(2)# 粘贴
el.send_keys(Keys.CONTROL,"v")
time.sleep(5)
driver.quit()
下拉框
通过Select对象来处理,记得导
Select
包
driver = webdriver.Chrome()
url ="https://manager.hezhuyun.net/"
driver.get(url)# 获取页面 下拉框并且转换为 Select对象
select = Select(driver.find_element(By.ID,"selectA"))# 根据索引选择
select.select_by_index(2)# 根据value 值选择
select.select_by_value("bj")# 根据 option 文本选择
select.select_by_visible_text("广州")
页面滚动
有些页面数据过多,采用懒加载模式,那么我们要选取一些懒加载元素,就必须触发页面滚动,让元素加载出来。
我们需要使用驱动来执行js的浏览器页面滚动代码来实现。
# 触发调动js代码 x轴不滚动, y轴向下滚动(当y轴滚动超过屏幕时将自动到最底部)
js_tr ='window.scrollTo(0,10000)'# 触发调动js代码
driver.execute_script(js_tr)
警告框
<button id="alertAAA" onclick="alert('我是警告框')">我是警告框</button>
driver = webdriver.Chrome()
url ="file:///D:/environment/python-workspace/testPY/index.html"
driver.get(url)# 模拟一个弹框出现,点击 alterAAA后出现了一个警告框
driver.find_element(By.ID,"alertAAA").click()# 获取警告框对象
alert = driver.switch_to.alert
print(alert.text)
time.sleep(2)# 确定
alert.accept()# 取消# alert.dismiss()
time.sleep(5)
driver.quit()
Frame切换
需要注意:在一个网页中如果使用了iframe标签嵌套网页,那么对于驱动来讲,只能获取到当前的网页,嵌套的内部网页一般无法去获取里面的元素。
那么就需要用到了Frame切换
切换Frame后如果需要外部网页的元素,那么还要再切换回去。
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
url ="https://mail.qq.com"
driver.get(url)
driver.implicitly_wait(2)# 原始页面的元素print(driver.find_element(By.CLASS_NAME,"login_pictures_title").text)# 切换至内部frame
driver.switch_to.frame("login_frame")
driver.find_element(By.ID,"u").send_keys("100001")# 切换回原始页面里
driver.switch_to.default_content()# 原始页面的元素print(driver.find_element(By.CLASS_NAME,"login_pictures_title").text)
time.sleep(5)
driver.quit()
当然还有 switch_to.parent_frame()方法可回到父级的frame中。
页面窗口切换
浏览器中的多标签页的切换。handle意为控制者,在selenium中,通过一个随机生成的UUID来标识某个窗口。
需要先获取到标签页的句柄 handle
# 获取所有
driver.window_handles
# 获取当前的 handle
driver.current_window_handle
# 切换
driver.switch_to.window(handleName)########################################实例###########################################import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
url ="https://www.baidu.com"
driver.get(url)
driver.maximize_window()
time.sleep(2)print(driver.window_handles)
driver.find_element(By.ID,"kw").send_keys("阿卡丽")
driver.find_element(By.ID,"su").click()
driver.implicitly_wait(2)
driver.find_element(By.XPATH,"//*[@id='1']/div[1]/div[1]/div/div[1]/a[1]/img").click()# 关闭上一个
driver.close()# 由于现在只剩一个了,直接选择第一个handle即可
driver.switch_to.window(driver.window_handles[0])
driver.find_element(By.XPATH,"//*[@id='srcPic']/img").click()
time.sleep(5)
driver.quit()
截图
# 获取文件截图
driver.get_screenshot_as_file("imgs.png")# 获取截图二进制数据流 bytes#driver.get_screenshot_as_png()
Cookie处理
添加Cookie,需要涉及到登录或其他业务必须添加时
driver.add_cookie({"name":"DBUSS","value":"通过Chrome浏览器工具查看"})
本文转载自: https://blog.csdn.net/weixin_45248492/article/details/129281030
版权归原作者 鸢尾の 所有, 如有侵权,请联系我们删除。
版权归原作者 鸢尾の 所有, 如有侵权,请联系我们删除。