
适合新手入门玩一下目标的检测和分割,大概了解yolov5算法的一些基本操作。
**1.1 **课题背景
目标检测的目的是判断在单张图片或者连续图片(视频)中,感兴趣的单个或者 多个物体是否存在,如果存在,需要将感兴趣的单个或者多个物体的位置和大小确 定。通常情况下我们使用一个矩形框来表示一个物体的位置和大小,矩形框的位置信息使用其左上角点和右下角点的坐标,共四个数字表示展示(也可以使用中心点坐 标,长和宽表示)。如图中包含多个目标,如人,自行车,道路,草 地,天空,当我们感兴趣的目标为人和自行车时,目标检测的任务就是将这些目标识 别出来,确定其类别,并使用矩形框标注其位置和大小
目标分割在计算机视觉领域由于具体需求的不同,研究人员通常将其分为两项任务:语义分割和实例分割。
语义分割的目的是判断在单张或者连续的图片(视频)中,某种类别的感兴趣的 物体是否存在,如果存在,需要将这一种类别感兴趣物体的具体像素位置在图片中标 注出来。通常情况下我们使用一个同原图片长宽相同的单通道二值矩阵对一种类型的 感兴趣物体的语义分割结果进行标注,未出现感兴趣物体的像素使用 0 表示,出现感 兴趣物体的像素用 1 表示。若有若干个种类的感兴趣物体,则需要若干个单通道二值 矩阵表示语义分割结果。如中包含多种感兴趣物体,如人,自行车, 道路,草地,天等,当我们感兴趣的目标为人和自行车时,语义分割的任务就是将 人,马,汽车所在的像素点位置识别出来,并使用单通道二值矩阵表示其位置。
实例分割的目的是判断在单张图片或者连续图片(视频)中,感兴趣的单个或者 多个物体是否存在,如果存在,需要将感兴趣的单个或者多个物体的具体像素位置在 图片中标注出来。通常情况下我们使用一个同原图像长宽相同的单通道二值矩阵对一个感兴趣物体的实例分割结果进行标注,未出现感兴趣物体的像素使用 0 表示,出现 感兴趣物体的像素用 1 表示。若有若干个感兴趣物体,则需要若干个单通道二值矩阵 表示实例分割的结果。
目标检测和实例分割这两项任务所需要识别的对象都是单独的个体,需要算法不 仅要识别出来感兴趣的物体是什么类别,而且要把相同类别的不同个体分隔开来。语 义分割和实例分割这两项任务对于被识别的对象来说,对于位置的识别比检测中用矩 形框表示的“大概的位置”更加严格,需要得到被识别对象的确切边缘信息。可以说 实例分割是目标检测和语义分割这两项任务综合起来得
目标检测的目的是判断在单张图片或者连续图片(视频)中,感兴趣的单个或者 多个物体是否存在,如果存在,需要将感兴趣的单个或者多个物体的位置和大小确 定。通常情况下我们使用一个矩形框来表示一个物体的位置和大小,矩形框的位置信息使用其左上角点和右下角点的坐标,共四个数字表示展示(也可以使用中心点坐 标,长和宽表示)。如图中包含多个目标,如人,自行车,道路,草 地,天空,当我们感兴趣的目标为人和自行车时,目标检测的任务就是将这些目标识 别出来,确定其类别,并使用矩形框标注其位置和大小
目标分割在计算机视觉领域由于具体需求的不同,研究人员通常将其分为两项任务:语义分割和实例分割。
语义分割的目的是判断在单张或者连续的图片(视频)中,某种类别的感兴趣的 物体是否存在,如果存在,需要将这一种类别感兴趣物体的具体像素位置在图片中标 注出来。通常情况下我们使用一个同原图片长宽相同的单通道二值矩阵对一种类型的 感兴趣物体的语义分割结果进行标注,未出现感兴趣物体的像素使用 0 表示,出现感 兴趣物体的像素用 1 表示。若有若干个种类的感兴趣物体,则需要若干个单通道二值 矩阵表示语义分割结果。如中包含多种感兴趣物体,如人,自行车, 道路,草地,天等,当我们感兴趣的目标为人和自行车时,语义分割的任务就是将 人,马,汽车所在的像素点位置识别出来,并使用单通道二值矩阵表示其位置。
实例分割的目的是判断在单张图片或者连续图片(视频)中,感兴趣的单个或者 多个物体是否存在,如果存在,需要将感兴趣的单个或者多个物体的具体像素位置在 图片中标注出来。通常情况下我们使用一个同原图像长宽相同的单通道二值矩阵对一个感兴趣物体的实例分割结果进行标注,未出现感兴趣物体的像素使用 0 表示,出现 感兴趣物体的像素用 1 表示。若有若干个感兴趣物体,则需要若干个单通道二值矩阵 表示实例分割的结果。
目标检测和实例分割这两项任务所需要识别的对象都是单独的个体,需要算法不 仅要识别出来感兴趣的物体是什么类别,而且要把相同类别的不同个体分隔开来。语 义分割和实例分割这两项任务对于被识别的对象来说,对于位置的识别比检测中用矩 形框表示的“大概的位置”更加严格,需要得到被识别对象的确切边缘信息。可以说 实例分割是目标检测和语义分割这两项任务综合起来得到的一个任务,事实上,深度学习中语义分割算法也是由目标检测算法和语义分割算法发展而来。
1.2基于深度学习的目标检测
传统目标检测方法的缺点,一是候选区框区域的选择计算量大,冗余窗口的产生无法避免,物体的语义特征不参与此过程,最终导致得到的候选框数量庞大,不能有效定位感兴趣物体。二是手工特征生成器的设计难度高,效果差,想要设计出优秀的,符合 任务的手工特征需要对任务知识和图像处理都有很深的了解,即使这样也难以设计出鲁棒性优秀的特征生成算法。这两个问题在基于深度学习的目标检测算法上都有比较 不错的解决方案。在基于深度学习的目标检测领域,通常使用卷积神经网络搭建机器 学习模型,由大量的带标签数据进行驱动。候选框由基于锚点框的算法生成,特征的生成不再需要手工设计特征生成算法,而是通过神经网络进行学习。基于深度学习的 目标检测算法在计算机视觉领域通常有两大类方法,一是“两步(two-stage)”法,以 R-CNN算法为主,在 Faster R-CNN 算法中将候选框区域的特征通过 ROIpooling 的方式输入卷积神经网络分类器进行分类,二是“一步(one-stage)”法,以 SSD,YOLO算法为主,不需要显式得将候选框区域拿出来,而是直接在结 果中同时得到所有检测结果。
本次目标检测实验采用yolov5算法。
**1.3 **基于深度学习的目标分割算法
基于深度学习的目标分割算法相比于传统的方法可以适用于更加复杂的任务场景。 在语义分割任务中又存在两种比较常见的任务分类。 一是需要像素级别的边缘分割的任务,如医疗图像处理中的血管分割,肿瘤分割,大气信息处理中的云层分割,这种类型的任务通常对实时性要求不高,对于目标的语义信息提取能力要求不高,但是对于目标边缘的准确率要求较高,通常采用以 U-Net网络为主的方法。二是需要任务目标的语义信息较为丰富,识别的目标往往就是 RGB摄像头所采集到的常见生活场景,常用的数据集有COCO ,ADE20K ,Cityscapes,这种任务的网络需要一定的实时性,对于边缘的要求不高,一般在一个较小的特征图上进行预测常见的算法有FCN,PSP,Deeplab系列。实例分割任务可以理解为在目标检测的结果上,对矩形框内的感兴趣目标进行语义分割。最常用的算法是基于“二步”法 Faster R-CNN 算法的改进算法 Mask R-CNN 算法,使用 ROI Align 代替 Faster R-CNN 中的 ROI Pooling,并引入了语义分割 分支。
2 准备训练模型数据
** 我这是直接用的GitHub大佬的程序,先下载GitHub大佬改过的yolov5:**GitHub - TomMao23/multiyolov5: joint detection and semantic segmentation, based on ultralytics/yolov5,
以下所有步骤直接在原程序上改就行
- 检测数据按照yolov5组织格式,如customdata的detdata文件夹下images和labels两个文件夹分别放图像和yolo格式标签,两个文件夹下各有train和val两个子文件夹用于存放训练和验证数据、标签。
- 分割图像、标签放在segimages和seglabels两个文件夹。这两个文件夹下各有trian,val两个子文件夹,子文件夹里面放图像(jpg、png)或标签(必须png,像素值就是类别,忽略类值为255,参考bdd100k的格式)。
- 仿照(复制修改)data/cityscapes_det.yaml的配置数据,train和val写图片数据的train和val文件夹的路径(yolo自己会对应找labels),nc为检测类别数,segtrain和segval写分割数据segimages和seglabels父文件夹的路径,names为各检测类别名字。
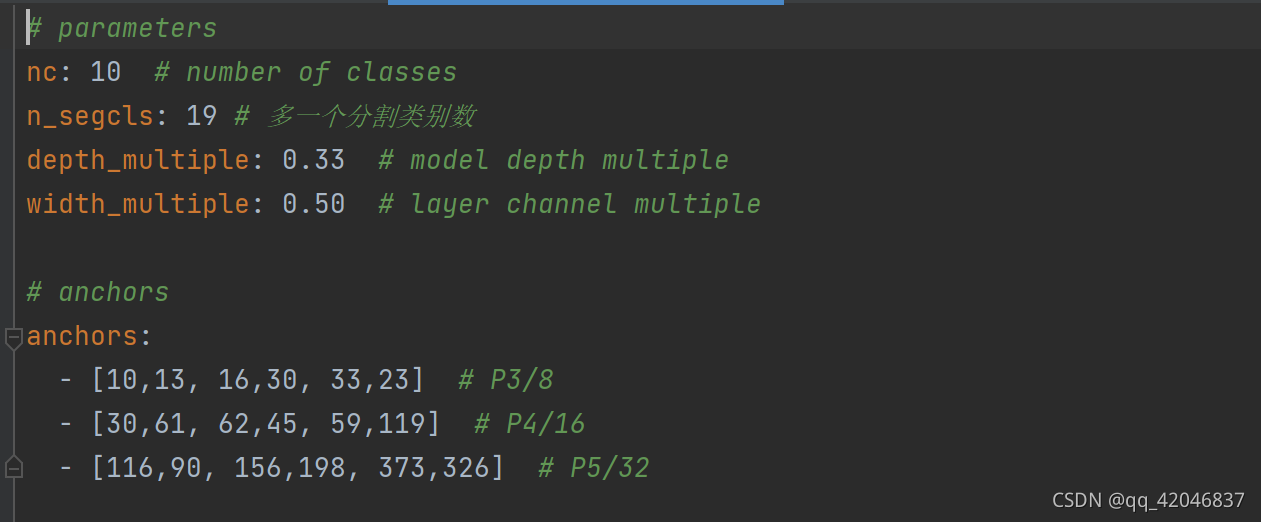
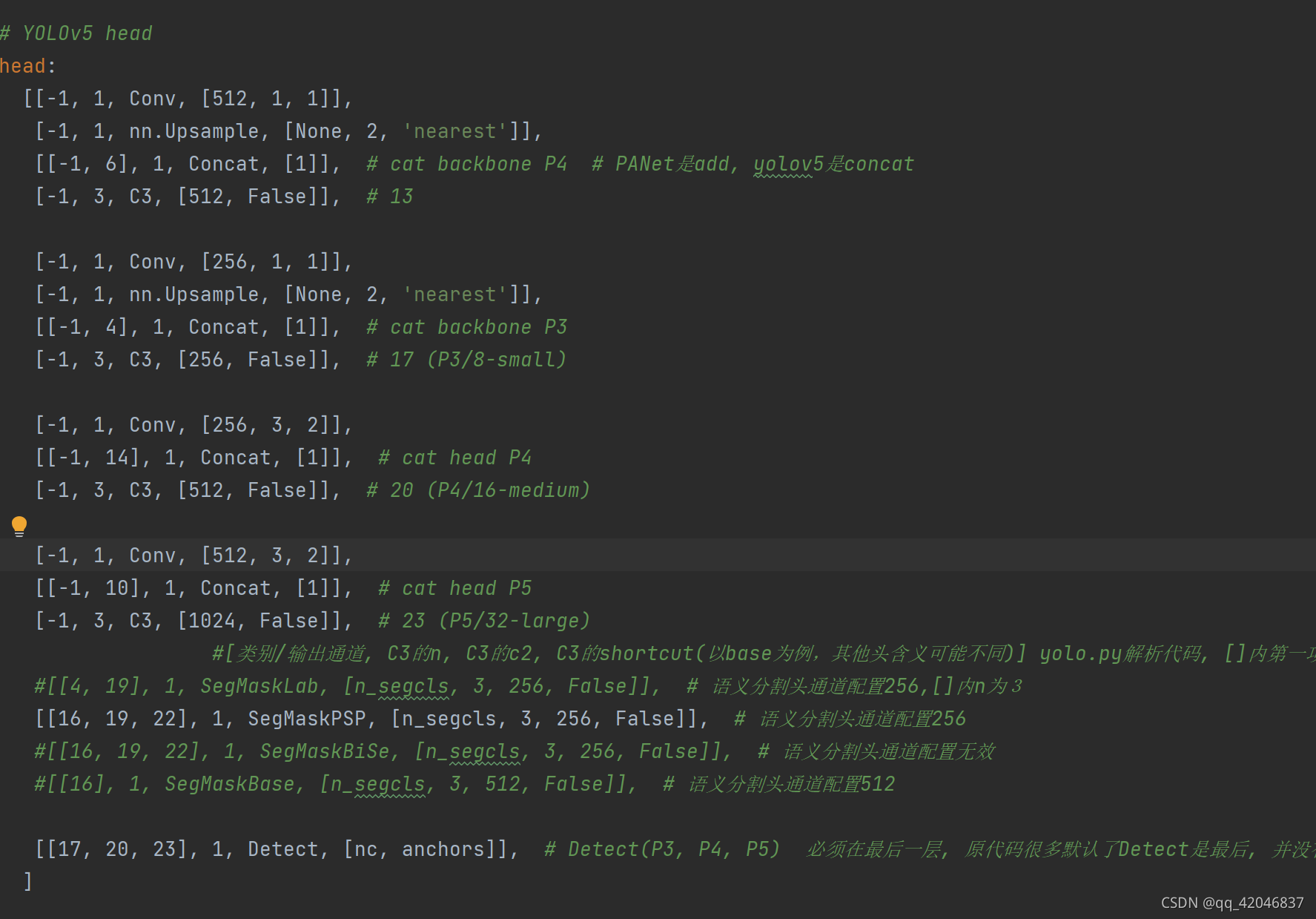
- 仿照(复制修改)models/yolov5s_city_seg.yaml的配置模型,nc为检测类别数,n_segcls为分割类别数。depth_multiple,width_multiple控制深度和宽度,是yolov5s,m,l,x唯一的区别。
- 对应主文件夹下README的训练和测试部分命令,修改为你的数据集、数据集配置文件、模型配置文件路径即可训练你的数据
**2.1 **目标检测数据集制作的几种方法(这步可以先不看,后面做不过再回来看这一步)
1 已有数据集——标注
2 自己获得数据集(手动)——人工标注
3 自己获得数据集——半人工标注,利用已经训练好的网络进行简单的标注,然后再人工微调
4 仿真数据集(GAN,数字图像处理的方式)
本次目标检测实验采用自己获得数据集,先收集70张汽车行驶过程中的图片,然后人工标注。标注工具为yolov5官方推荐的在线标注工具makesense.ai。
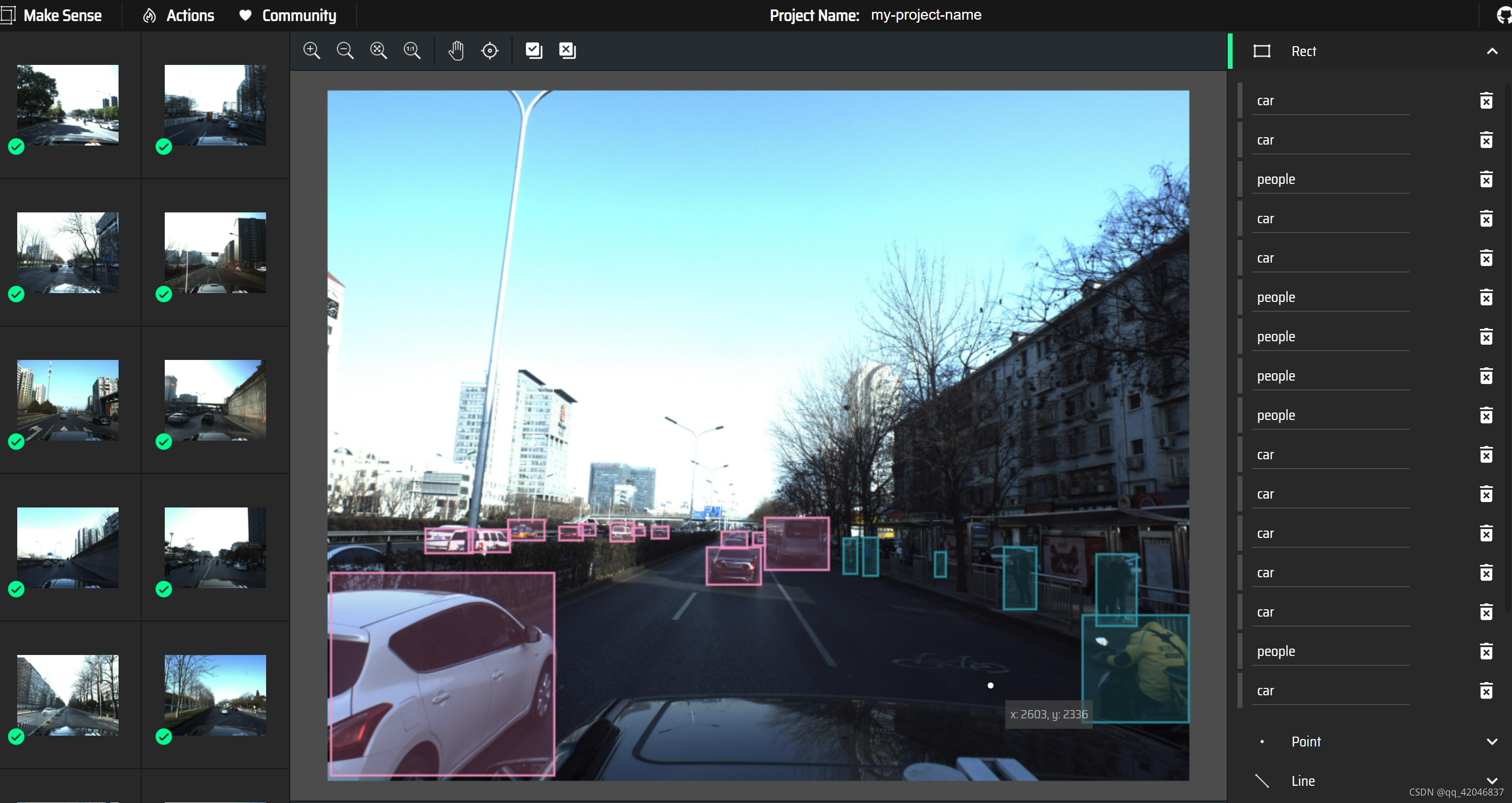
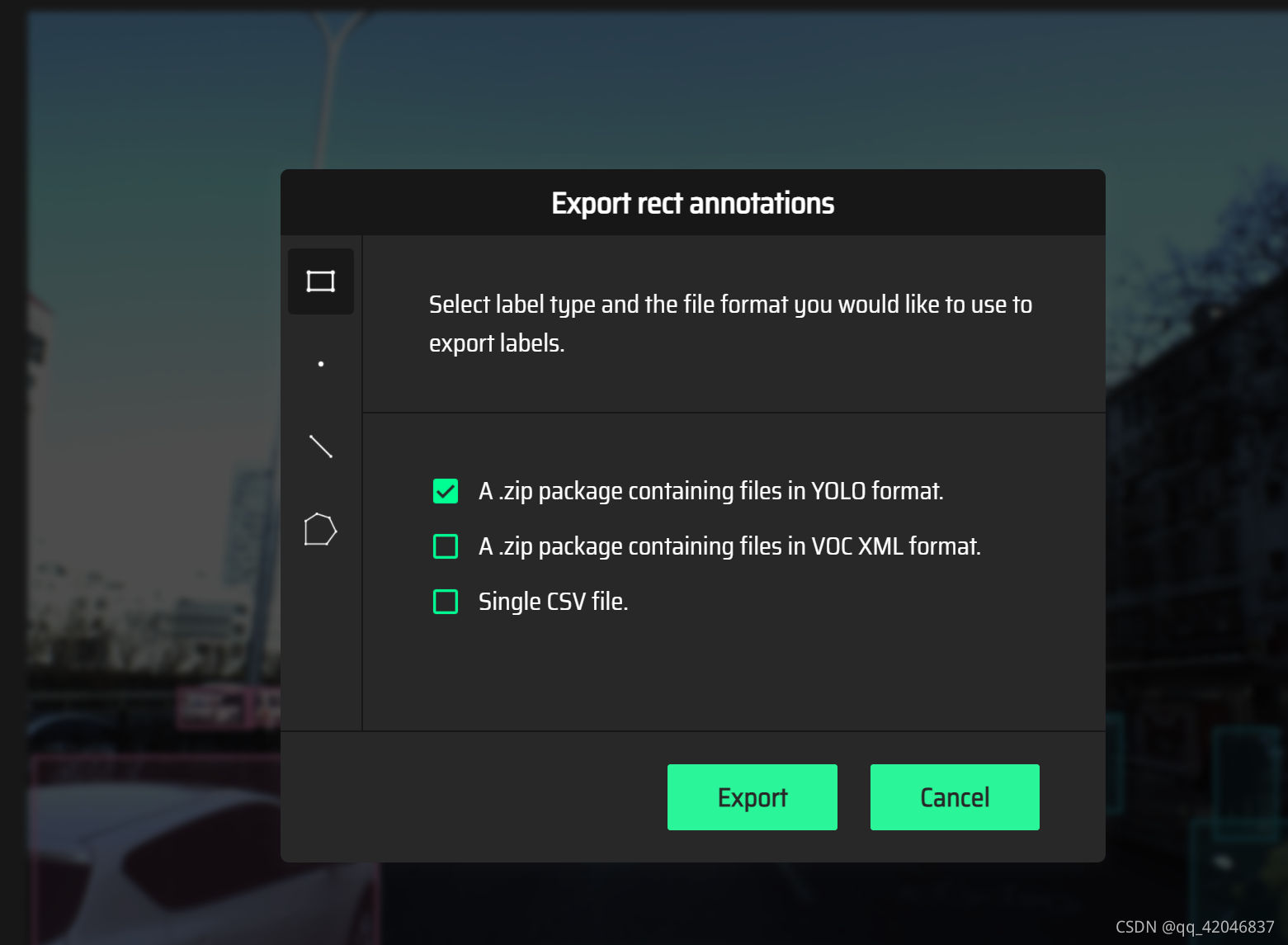
标注完后可以直接生成 yolo格式,将原图放入train文件夹中,生成的txt格式的标签放入label文件夹中
如下图片:第一张为images,第二张为labels。


**2.2 **目标分割数据集制作
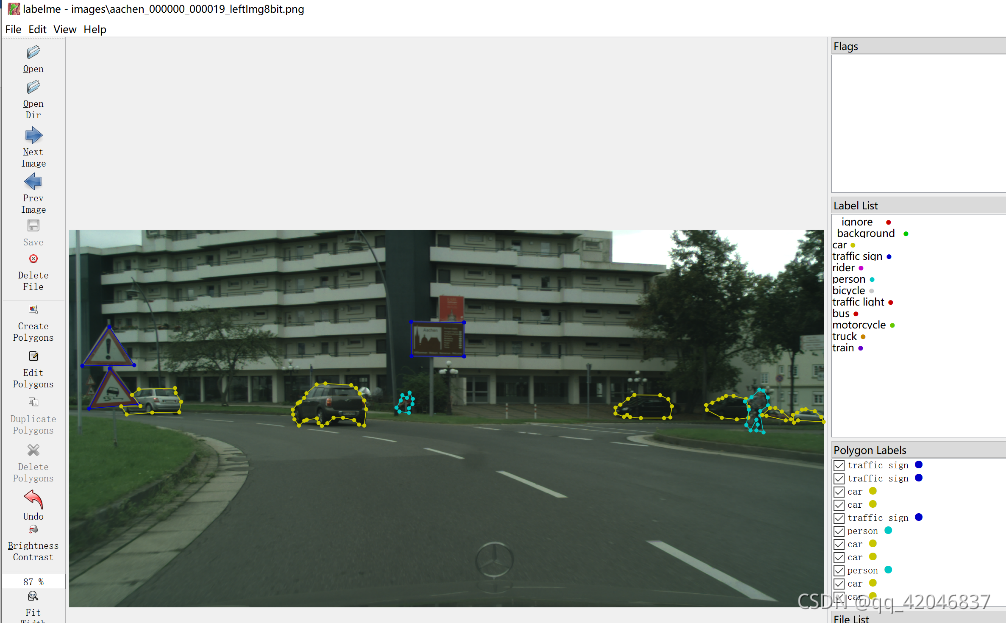
** 1. labelme标注分割数据**
1标注后把图片和同名json文件放在一个文件夹中,如example的det和seg
2 先使用两个labelme脚本(来自labelme自己的检测、分割example,因同名重命名过)转换为voc格式。仿照example定义好自己的detlabels.txt和seglabels.txt类别
终端运行:
$ cd convert_tools
$ python labelme2detvoc.py example/det example/detvoc --labels example/detlabels.txt
$ python labelme2segvoc.py example/seg example/segvoc --labels example/seglabels.txt
即可在example中看到detvoc和segvoc这两个voc格式的检测和分割数据
tips:若转换失败要删除输出文件夹重新运行脚本
生成detvoc和segvoc文件夹,如下图:
2 使用convert2Yolo工具把检测转为yolo格式
$ python convert2Yolo/example.py --datasets VOC --img_path ./example/detvoc/JPEGImages --label ./example/detvoc/Annotations --convert_output_path ./example/yolodetlabels --img_type ".jpg" --manifest_path ./example --cls_list_file ./example/names.txt
即可在./example/yolodetlabels找到转换完成的yolo标签,这些就是要放入detdata的labels/train或val内的检测标签,把对应的图像也放在detdata的images/train或val里。根据以上和主目录的REAME说明修改训练和测试部分命令,修改为你的数据集(customdata/detdata)、数据集配置文件、模型配置文件路径即完成了检测部分的数据准备。
这一步我没做出来,程序运行的时候有问题,还没有找到原因。这步报错可以返回去看前面的制作目标检测标签,用前面方法制作的标签替代这一步,采用上述人工在线标注的数据。
使用generate_mask.py把voc格式的分割npy文件转为png格式的mask
3 使用generate_mask.py把voc格式的分割npy文件转为png格式的mask
$ python generate_mask.py --input-dir ./example/segvoc/SegmentationClass --output-dir ./example/masklabels
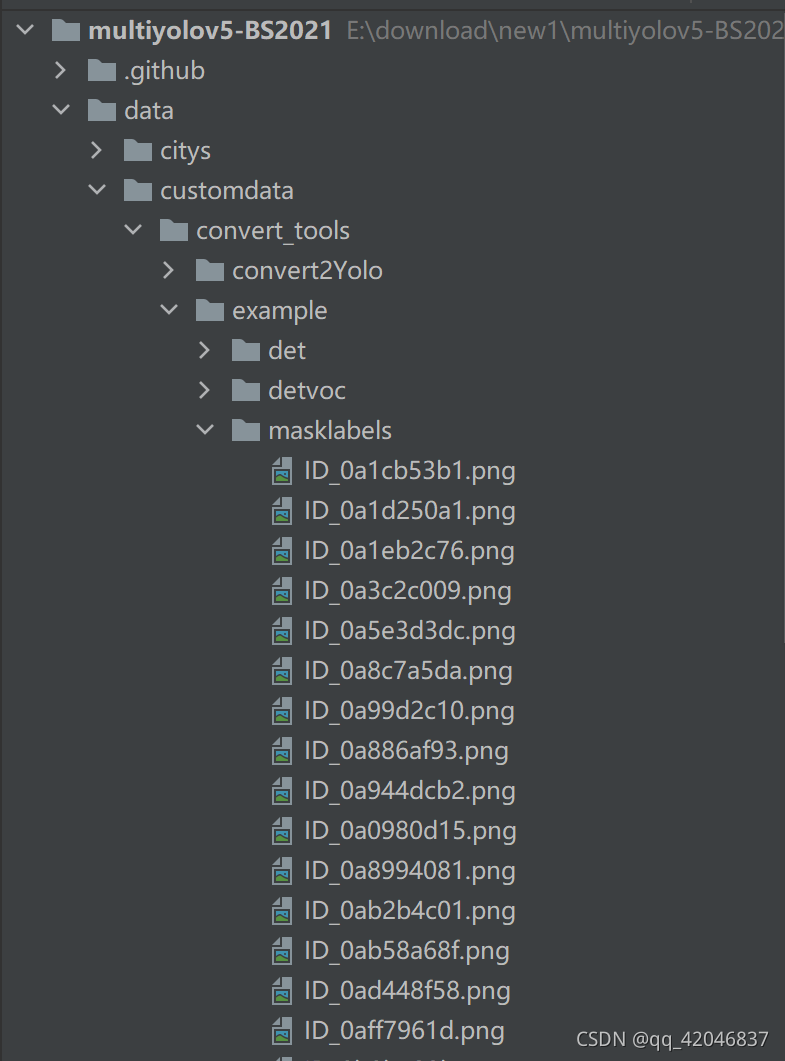
即可在./example/masklabels找到图片同名的.png标签(如example中1为crack,0为background,数值很小所以看起来几乎是黑的)把这些mask标签放在seglabels/train或val中,对应图像文件放在segimages/train或val中。根据以上和主目录的REAME说明修改训练和测试部分命令,修改为你的数据集(customdata)、数据集配置文件、模型配置文件路径即完成了分割部分的数据准备
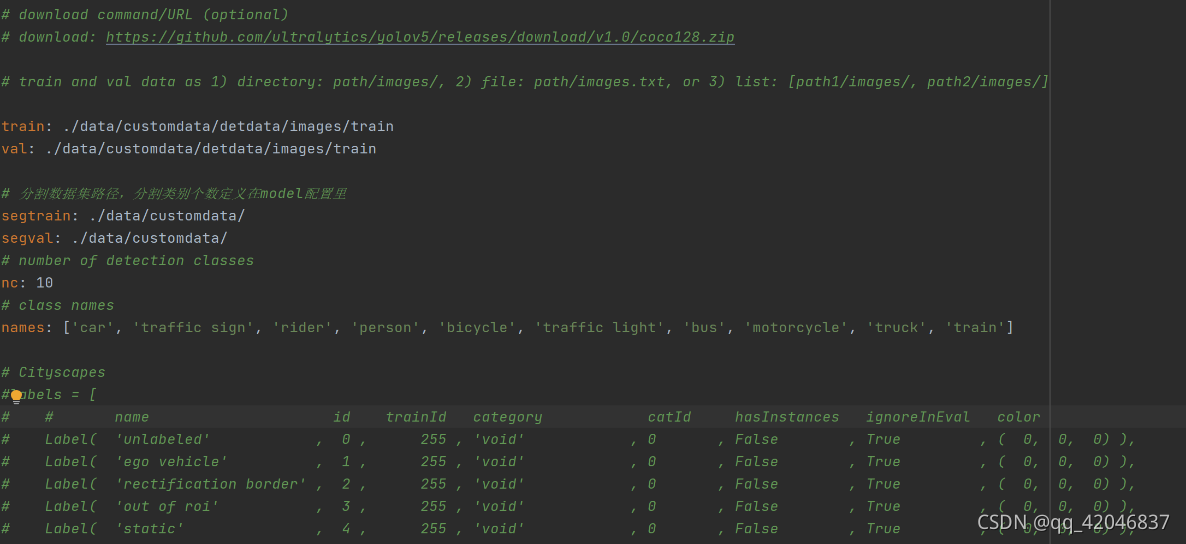
2.4配置数据data/custom.yaml
直接修改coco128.yaml
- 配置模型 yolov5s_custom_seg.yaml
直接修改 yolov5s.yaml
准备好这几个文件,就可以直接跑代码,进行训练了
$ python train_custom.py --data custom.yaml --cfg yolov5s_custom_seg.yaml --weights ./yolov5s.pt --workers 4 --label-smoothing 0.1 --img-size 832 --batch-size 4 --epochs 1000 --rect
可能报错:
** 代码在下面网址,直接下载就行,基本不用改动直接就能跑。没有成功转为yolo格式标签的可以试试我上面那种方法。转成功的直接跟着原作者的代码跑就行。这种不是正经方法,训练出来的误差很大,只能用于练手**
** 在训练的时候可能会报多进程错误,我这里的原因是笔记本性能的问题,修改了workers和batch 的数值就可以了。**
** 还可能报读取yaml文件错误,可以打断点看一下,这是由于yaml文件可能不是utf8格式,需要自己转换一下,这个就根据报错指示,找到打开yaml文件的函数open(),直接添加encoding=utf8。**
参考:GitHub - TomMao23/multiyolov5: joint detection and semantic segmentation, based on ultralytics/yolov5,
版权归原作者 无损检测小白白 所有, 如有侵权,请联系我们删除。