
1、Filebeat概述
Filebeat用于日志采集,将采集的日志做简单处理(多行合并)发送至Kafka、Logstash、Elasticsearch等。
2、快速开始
先以最简模型快速开始再讲原理及细节。
2.1、下载、安装、配置、启动:
1、下载
curl -L-O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.3.2-linux-x86_64.tar.gz
2、解压
tar xzvf filebeat-8.3.2-linux-x86_64.tar.gz
3、配置
进入filebeat解压目录,编辑filebean.yml
#输入配置
filebeat.inputs:
#输入类型
- type: log
#开启输入
enabled:true
#日志文件路径
paths:-/usr/share/filebeat/log/test.log
#输出到控制台
output.console:
pretty:true
enable:true
4、启动:
./filebeat -e -c filebeat.yml
5、成功示例
启动成功后向配置中的日志文件(/usr/share/filebeat/log/test.log)写入信息,控制台将打印采集到的日志,如下图1-1所示: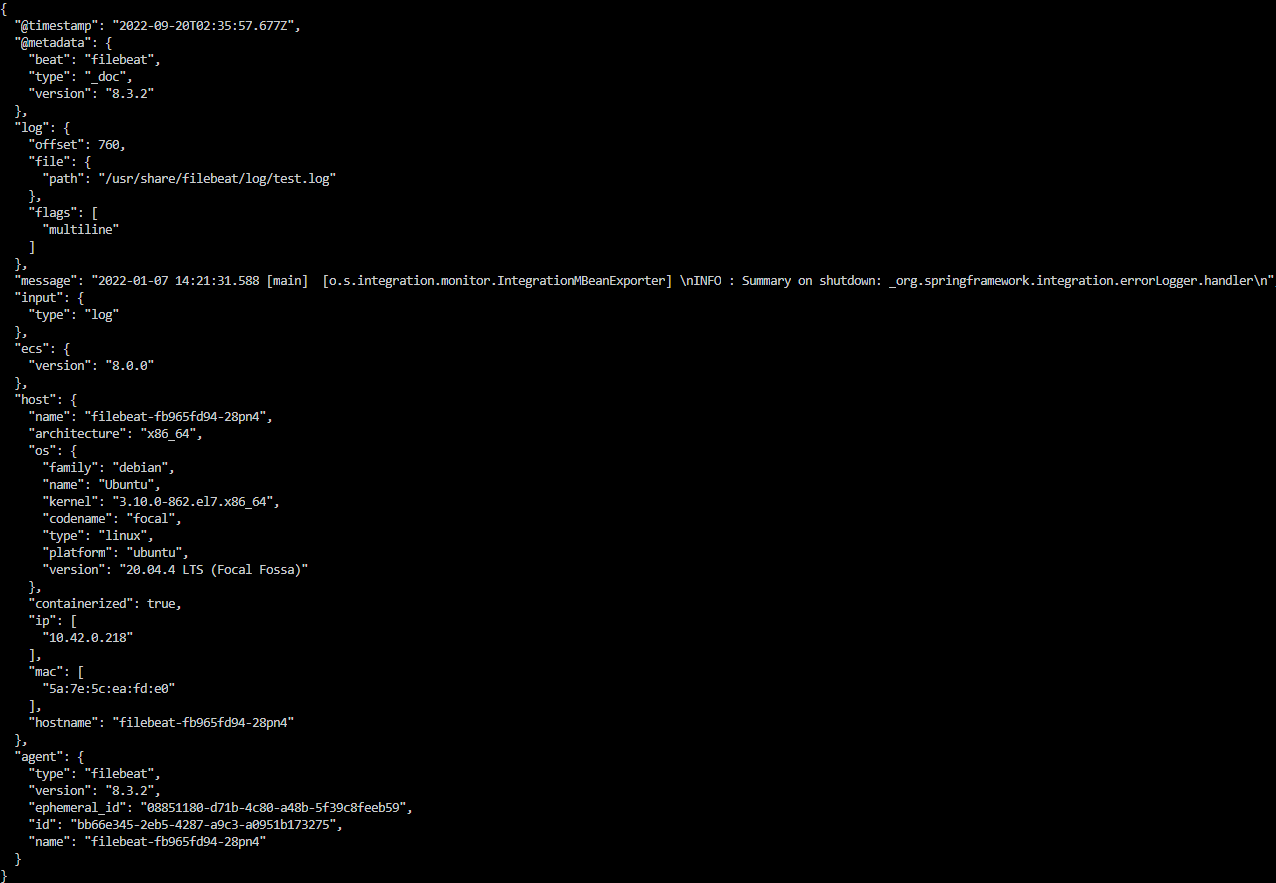
如上图所示,最简单的Filebeat日志采集已搭建成功(指定文件路径,直接输出到控制台)。message字段就是日志文件中的日志信息,其他数据都是Filebeat附带的信息,包括采集时间@TimeStamp、日志文件路径path等。
6、实际工作开发
Filebeat工作原理、采集数据发送至Kafka/Logstash/Elasticsearch、日志格式及字段处理等详细配置见下文。
3、Filebeat是什么
3.1、Filebeat和Beats的关系
首先filebeat是Beats中的一员。
Beats在是一个轻量级日志采集器,其实Beats家族有6个成员,早期的ELK架构中使用Logstash收集、解析日志,但是Logstash对内存、cpu、io等资源消耗比较高。相比Logstash,Beats所占系统的CPU和内存几乎可以忽略不计。
目前Beats包含六种工具:
- Packetbeat:网络数据(收集网络流量数据)
- Metricbeat:指标(收集系统、进程和文件系统级别的CPU和内存使用情况等数据)
- Filebeat:日志文件(收集文件数据)
- Winlogbeat:windows事件日志(收集Windows事件日志数据)
- Auditbeat:审计数据(收集审计日志)
- Heartbeat:运行时间监控(收集系统运行时的数据)
3.2、filebeat是什么
Filebeat是用于转发和集中日志数据的轻量级传送工具。Filebeat监视您指定的日志文件或位置,收集日志事件,并将它们转发到Elasticsearch或 Logstash进行索引。
Filebeat的工作方式如下:启动Filebeat时,它将启动一个或多个输入,这些输入将在为日志数据指定的位置中查找。对于Filebeat所找到的每个日志,Filebeat都会启动收集器。每个收集器都读取单个日志以获取新内容,并将新日志数据发送到libbeat,libbeat将聚集事件,并将聚集的数据发送到为Filebeat配置的输出。
工作的流程图3-1如下:
4、filebeat原理是什么
4.1、filebeat的构成
filebeat结构:由两个组件构成,分别是inputs(输入)和harvesters(收集器),这些组件一起工作来跟踪文件并将事件数据发送到您指定的输出,harvester负责读取单个文件的内容。harvester逐行读取每个文件,并将内容发送到输出。为每个文件启动一个harvester。harvester负责打开和关闭文件,这意味着文件描述符在harvester运行时保持打开状态。如果在收集文件时删除或重命名文件,Filebeat将继续读取该文件。这样做的副作用是,磁盘上的空间一直保留到harvester关闭。默认情况下,Filebeat保持文件打开,直到达到close_inactive。
关闭harvester可以会产生的结果:
文件处理程序关闭,如果harvester仍在读取文件时被删除,则释放底层资源。
只有在scan_frequency结束之后,才会再次启动文件的收集。
如果该文件在harvester关闭时被移动或删除,该文件的收集将不会继续。
一个input负责管理harvesters和寻找所有来源读取。如果input类型是log,则input将查找驱动器上与定义的路径匹配的所有文件,并为每个文件启动一个harvester。每个input在它自己的Go进程中运行,Filebeat当前支持多种输入类型。每个输入类型可以定义多次。日志输入检查每个文件,以查看是否需要启动harvester、是否已经在运行harvester或是否可以忽略该文件
4.2、filebeat如何保存文件的状态
Filebeat保留每个文件的状态,并经常将状态刷新到磁盘中的注册表文件中。该状态用于记住harvester读取的最后一个偏移量,并确保发送所有日志行。如果无法访问输出(如Elasticsearch或Logstash),Filebeat将跟踪最后发送的行,并在输出再次可用时继续读取文件。当Filebeat运行时,每个输入的状态信息也保存在内存中。当Filebeat重新启动时,来自注册表文件的数据用于重建状态,Filebeat在最后一个已知位置继续每个harvester。对于每个输入,Filebeat都会保留它找到的每个文件的状态。由于文件可以重命名或移动,文件名和路径不足以标识文件。对于每个文件,Filebeat存储唯一的标识符,以检测文件是否以前被捕获。
4.3、filebeat何如保证至少一次数据消费
Filebeat保证事件将至少传递到配置的输出一次,并且不会丢失数据。是因为它将每个事件的传递状态存储在注册表文件中。在已定义的输出被阻止且未确认所有事件的情况下,Filebeat将继续尝试发送事件,直到输出确认已接收到事件为止。如果Filebeat在发送事件的过程中关闭,它不会等待输出确认所有事件后再关闭。当Filebeat重新启动时,将再次将Filebeat关闭前未确认的所有事件发送到输出。这样可以确保每个事件至少发送一次,但最终可能会有重复的事件发送到输出。通过设置shutdown_timeout选项,可以将Filebeat配置为在关机前等待特定时间。
5、Filebeat详细使用说明
本部分将介绍Filebeat采集多数据源(多个输入)、原始日志处理、字段过滤筛选、搭配输出至Kafka/Logstash/Elasticsearch等功能。
完整配置如下,后续根据该完整配置分段分析输入、输出、过滤筛选等功能
# ====================== Inputs =====================#日志采集类型及路径(可配置多个)
filebeat.inputs:
-type: log
enabled: true
#每次采集缓冲大小,默认16k(16384),可手动调大,提供吞吐量#harvester_buffer_size: 1638400#每条日志最大字节数,默认10M,超过该设置将丢弃剩余信息。# max_bytes: 10485760#日志文件路径
paths:
#采集该具体日志文件-/var/log/test.log
#添加新字段可发送至不同topic
fields:
kafka_topic: firstTopic
#第二个采集配置-type: log
enabled: true
paths:
#采集该目录下所有.log文件-/var/log/*.log
#添加新字段可发送至不同topic
fields:
kafka_topic: secondTopic
#多行合并规则,以时间开头的为一条完整日志,否则合并到上一行(java、python日志都以日期开头)
multiline.type: pattern
#中括号日期开头:[2015-08-24 11:49:14,389]#multiline.pattern: '^\[[0-9]{4}-[0-9]{2}-[0-9]{2}'#日期开头:2015-08-24 11:49:14,389
multiline.pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2}'
multiline.negate: true
multiline.match: after
#合并最大条数,默认500
mutiline.max_lines: 1000
# 这个文件记录日志读取的位置,如果容器重启,可以从记录的位置开始取日志# registry_file: /usr/soft/filebeat/data/registry# ============= Filebeat modules ====================
filebeat.config.modules:
# Glob pattern for configuration loading
path: ${path.config}/modules.d/*.yml
# Set to true to enable config reloading
reload.enabled: false
# ==================== Outputs =========================#kafka地址,可配置多个用逗号隔开
output.kafka:
enabled: true
hosts: ["192.168.154.128:9092","192.168.154.129:9092"]#根据上面添加字段发送不同topic
topic: '%{[fields.kafka_topic]}'#控制台输出#output.console:# pretty: true# enable: true# ===================== Processors ===========================
processors:
- add_host_metadata:
when.not.contains.tags: forwarded
- add_cloud_metadata: ~
- add_docker_metadata: ~
- add_kubernetes_metadata: ~
#设置忽略字段,以下字段不显示在日志中- drop_fields:
fields: ["host","input","agent","ecs","log","@version","flags"]
ignore_missing: false
#提取日志内容中的时间,并添加到msg_time自动中- script:
lang: javascript
tag: my_filter
source: >
functionprocess(event){var msg = event.Get("message");var time = msg.split(" ").slice(0,2).join(" ");
event.Put("msg_time",time);}#使用日志中的时间替换filebeat采集时间,即上面提取的msg_time字段值替换@Timestamp字段值- timestamp:
field: msg_time
timezone: Asia/Shanghai
layouts:
-'2006-01-02 15:04:05'-'2006-01-02 15:04:05.999'-'2006-01-02 15:04:05.999-07:00'- drop_fields:
fields: [msg_time]
5.1、输入配置
Filebeat输入类型包括多种如:log/filestream(日志文件)、Kafka、Redis、UDP、TCP、HTTP等20余种输入类型,详细信息请参考官方文档:输入配置。
本文以多个log输入方式讲解,如下配置所示,采集两个不同文件地址的日志信息。
# ====================== Inputs =====================#日志采集类型及路径(可配置多个)
filebeat.inputs:
-type: log
enabled: true
#日志文件路径
paths:
#采集该具体日志文件-/var/log/test.log
#添加新字段可发送至不同topic
fields:
kafka_topic: firstTopic
#第二个采集配置-type: log
enabled: true
paths:
#采集该目录下所有.log文件-/var/log/*.log
#添加新字段可发送至不同topic
fields:
kafka_topic: secondTopic
如上代码所示,第一个采集源采集一个具体的文件/var/log/test.log;
第二个采集源采集/var/log/目录下的所有.log文件。
在每个采集源上添加fields.kafka_topic字段,后续可根据该字段动态发送至不同的Topic。
5.2、多行日志合并
实际项目中一条完整日志可能包含多行信息,如下面一条Java错误日志。
2022-01-0714:21:31.616[main][org.springframework.boot.SpringApplication]ERROR:Application run failed
org.springframework.beans.factory.BeanCreationException:Error creating bean withname 'scopedTarget.Config':Injection of autowired dependencies failed;
Caused by:java.lang.IllegalArgumentException:Could not resolve placeholder at org.springframework.util.PropertyPlaceholderHelper.parseStringValue(PropertyPlaceholderHelper.java:178)
因为Filebeat每次采集以行为单位,默认认为每一行为一条消息,所以需要将多行日志合并成一条完整日志。
如上所示java日志都是以2022-01-07 14:21:31.616这样的日期开始,所以合并规则为:不是以日期开始的视为上一条日志的一部分。规则代码如下:
#多行合并规则,以时间开头的为一条完整日志,否则合并到上一行(java、python日志都以日期开头)
multiline.type: pattern
#中括号日期开头:[2015-08-24 11:49:14,389]#multiline.pattern: '^\[[0-9]{4}-[0-9]{2}-[0-9]{2}'#日期开头:2015-08-24 11:49:14,389。日期判断正则表达式
multiline.pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2}'
multiline.negate: true
multiline.match: after
Filebeat提供几种常见日志格式的正则表达式,详情见官方文档:多行消息。
如需合并特殊格式的多行日志,需要自行编写正则表达式结合合并规则实现。
5.3、输出配置
Filebeat支持将采集到的数据发送至不同平台,如Elasticsearch、Kafka、logstash、Redis、控制台、文件。随让支持发送至不同平台,但一个配置中只能配置一种输出。
各种输出的详细配置见官方文档:输出配置。
各种输出比较类似也比较简单,以发送到Kafka为例,在filebeat.yml中添加配置,配置如下:
# =============== Outputs ====================#kafka地址,可配置多个用逗号隔开
output.kafka:
enabled: true
hosts: ["192.168.154.127:9092","192.168.154.128:9092","192.168.154.129:9092"]#根据上面添加字段发送不同topic
topic: '%{[fields.kafka_topic]}'
其中topic使用
'%{[字段名称]}'
,可根据上面添加的字段,动态发送至不同的topic;如上面配置了两个采集源,每一个采集源设置了不同的kafka_topic值,所以将发送至kafka中的两个topic。当然也可以写死固定如:topic: ‘topicName’。
5.4、字段增删
1、添加字段
fields:
name: test
kafka-topic: topic1
如上所示增加两个字段:fields.name和fields.kafka-topic并设置值,在采集到到的结果信息中就可以显示。也可以使用’%{[字段名]}'获取,动态发送至不同kafka的topic就是这样使用的。
2、添加标签
tags: ["my-service","hardware","test"]
给采集到的数据添加标签,方便后续对数据进行分类筛选等操作。如在Logstash中之筛选tags = "test"的数据。
3、删除字段
如上图1-1采集的日志信息,实际日志信息只有message字段,其他字段都是Filebeat添加的,大部分字段可能并用不上,且导致传输数据比较大,因此可以删除部分字段只留下自己想要的。配置如下:
#设置忽略字段,以下字段不显示在日志中# ===================== Processors ===========================
processors:
- drop_fields:
fields: ["host","input","agent","ecs","log","@version","flags"]
ignore_missing: false
上述配置为删除host,input,agent等字段,**
注意@TimeStamp字段无法删除
**,即使配置了也无法删除。
5.5、采集时间@TimeStamp替换为日志产生时间
需求说明: 对接部分项目时,需求方只需要filebeat对日志进行采集,不需要logstash对其解析,但日志产生和采集有时延而导致这两个时间不一致,而又不使用logstash对其解析替换,所以只能在filebeat中处理替换。具体流程如下:
1、 解析日志时间
根据具体的日志格式,编写js代码解析出日志中的时间
2、替换采集时间
将上面解析的日志产生时间,替换@TimeStamp的值
以Java日志为例:
日志格式:2023-02-0100:00:00.049ERROR20632---[nio-8989-exec-4]o.a.c.c.C.[.[.[.[dispatcherServlet]
具体配置如下:
processors:
#提取日志内容中的时间,并添加到msg_time自动中- script:
lang: javascript
tag: my_filter
source: >
functionprocess(event){var msg = event.Get("message");var time = msg.split(" ").slice(0,2).join(" ");
event.Put("msg_time",time);}#使用日志中的时间替换filebeat采集时间,即上面提取的msg_time字段值替换@Timestamp字段值- timestamp:
field: msg_time
timezone: Asia/Shanghai
layouts:
-'2006-01-02 15:04:05'-'2006-01-02 15:04:05.999'-'2006-01-02 15:04:05.999-07:00'- drop_fields:
fields: [msg_time]
输出结果: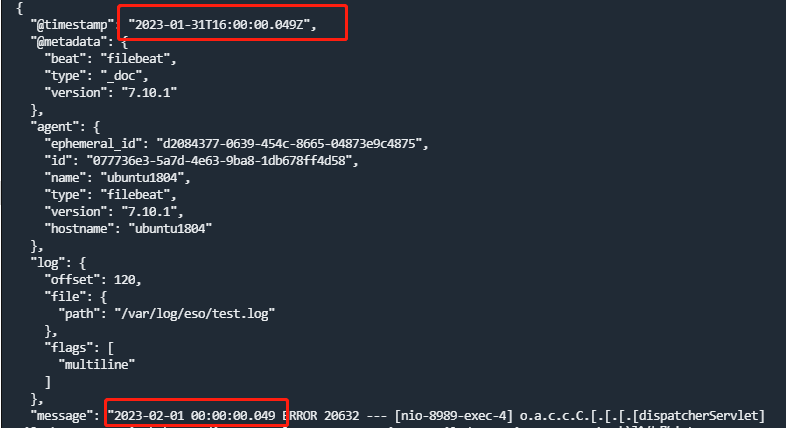
注意: @TimeStamp默认为标准时区UTC,在后续kibana中展示时可能会增加8个小时,这里将时区设置为东八区
timezone: Asia/Shanghai
后续便展示便正常了。
6、K8S容器方式部署
以采集nginx日志为例,采集流程图如下: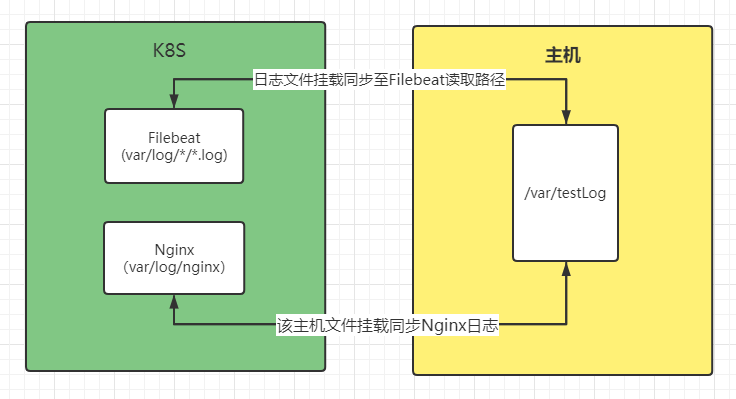
如上图所示,将主机/var/testLog文件分别挂载至Nginx日志文件下和Filebeat采集目录下。
部署Filebeat时设置为deamonset模式,每新增节点时都将部署filebeat。
Filebeat挂载代码:
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
k8s.kuboard.cn/displayName: filebeat-log-collection
labels:
k8s.kuboard.cn/name: filebeat
name: filebeat
namespace: log-collect-test
resourceVersion: '28750821'
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
k8s.kuboard.cn/name: filebeat
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
annotations:
kubectl.kubernetes.io/restartedAt: '2022-09-02T15:48:19+08:00'
creationTimestamp: null
labels:
k8s.kuboard.cn/name: filebeat
spec:
containers:
- image: 'docker.elastic.co/beats/filebeat:8.3.2'
imagePullPolicy: IfNotPresent
name: filebeat
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /usr/share/filebeat/filebeat.yml
name: volume-config
readOnly: true
subPath: filebeat.yml
- mountPath: /var/log
name: volume-log
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
volumes:
- configMap:
defaultMode: 420
name: filebeat-config
name: volume-config
- hostPath:
path: /var/testLog
type: DirectoryOrCreate
name: volume-log
status:
availableReplicas: 1
conditions:
- lastTransitionTime: '2022-08-25T09:14:16Z'
lastUpdateTime: '2022-09-02T07:48:21Z'
message: ReplicaSet "filebeat-fb965fd94" has successfully progressed.
reason: NewReplicaSetAvailable
status: 'True'type: Progressing
- lastTransitionTime: '2022-09-20T02:35:52Z'
lastUpdateTime: '2022-09-20T02:35:52Z'
message: Deployment has minimum availability.
reason: MinimumReplicasAvailable
status: 'True'type: Available
observedGeneration: 45
readyReplicas: 1
replicas: 1
updatedReplicas: 1
Nginx挂载代码:
volumeMounts:
- mountPath: /var/nginx/log
name: varlog
readOnly: true
volumes:
- hostPath:
path: /var/testLog
type: DirectoryOrCreate
name: varlog
7、启动方式
./filebeat -e -c filebeat.yml
启动 , ctrl + c退出,关闭终端连接filebeat也将退出。此方式只适合调试时使用。
7.1、后台启动
nohup ./filebeat -e -c filebeat.yml > ./filebeat.log 2>&1 &
后台启动,相关日志保存在当前目录filebeat.log中。
问题: 若是远程连接终端,关闭终端连接后filebeat还是退出了!
解决方案:
启动filebeat后需手动执行exit 命令退出终端连接。原因大概是直接关闭终端连接,将杀死相关进程;而使用exit命令退出终端不杀进程。
7.2、服务方式启动
后台启动方式虽然可以一直在后台运行,当主机或虚机出现意外重启,此时filebeat还是挂掉了。因此以服务的方式filebeat
启动,并设置为开机启动。
制作服务:
进入/usr/lib/systemd/system目录建立文件filebeat.service,文件内容如下:
[Unit]
Description=filebeat service...
Wants=network-online.target
After=network-online.target
[Service]
User=root
ExecStart=/usr/local/filebeat -e -c /usr/local/filebeat.yml
Restart=always
[Install]
WantedBy=multi-user.target
更新service配置:
sudo systemctl daemon-reload
设置开机启动
systemctl enable service_name
以后便可以使用
systemctl start/stop/restart filebeat
来启动/停止filebeat了。
参考文章:
Filebeat官方文档:Filebeat官方文档。
k8s-EFK (filebeat)日志收集:https://blog.csdn.net/qq_36961626/article/details/126438828
filebeat介绍:https://blog.csdn.net/hwjcmozw/article/details/109473925
版权归原作者 shallwe小威 所有, 如有侵权,请联系我们删除。