
Julia的入门非常简单,尤其是当您熟悉Python时。在本篇文章中,我们将使用约翰霍普金斯大学系统科学与工程中心在其GitHub存储库中提供的Covid-19数据(https://github.com/CSSEGISandData/)。
入门
对于我们的数据分析,我们将会使用一些软件包来简化操作:CSV,DataFrame,日期和可视化。只需输入软件包名称,即可开始使用。
using CSV
using DataFrames
using Dates
using Plots
如果包还没有添加到您的项目环境中,您可以轻松地添加它们。
using Pkg
Pkg.add("CSV")
Pkg.add("DataFrames")
Pkg.add("Dates")
Pkg.add("Plots")
读取数据
读取数据只需几个简单的步骤。首先,我们指定CSV文件的URL。其次,我们指定文件在本地机器上的路径。我们将加入目前的工作目录和文件名“confirmed.csv”路径。然后将文件从URL下载到指定的路径。第四个也是最后一个步骤是将CSV文件读入一个名为“df”的DataFrame中。
# Step 1: Specify the file location
URL = "https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_confirmed_global.csv"
# Step 2: Specify the path
path = joinpath(pwd(), "confirmed.csv")
# Step 3: Download the file
download(URL, path)
# Step 4: Reading the CSV file into a DataFrame
df = CSV.File(path) |> DataFrame
让我们看看数据的前10行。
first(df, 10)
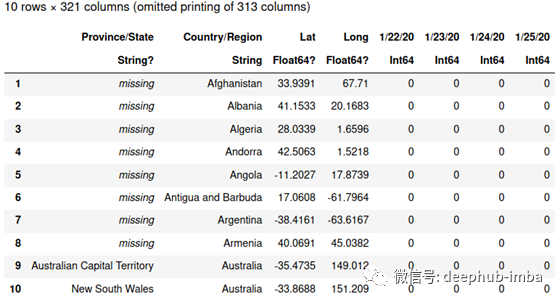
整理数据
在本例中,我们不需要省份/州、Lat和Long列。所以我们先把它们放下。通过在select语句后加上感叹号,df会被修改。
select!(df, Not(["Province/State", "Lat", "Long"]))
澳大利亚和其他一些国家有多个行。当我们想要绘制每个国家的数据时,我们必须聚合数据。我们将通过执行split — apply — combine来做到这一点。首先,我们使用groupby函数按国家分割数据。然后我们对每组(即每个国家)的所有日期列应用一个求和函数,因此我们需要排除第一列“国家/地区”。最后,我们将结果合并到一个df中。
grp = groupby(df, "Country/Region")
column_names = names(grp)
date_columns = column_names[2:end] # select all columns except the first column "Country/Region"
df = combine(gdf, date_columns .=> sum .=> date_columns)
让我们看看到目前为止我们有什么。
first(df, 10)
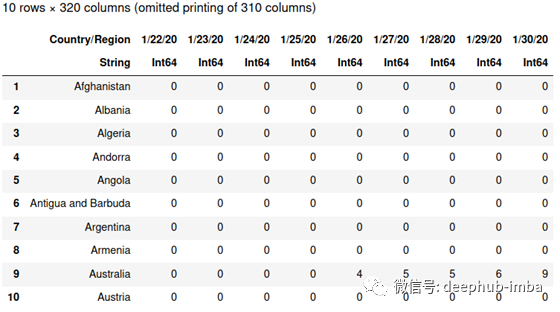
我们的df现在(在写入时)有320列。但是,我们希望一列显示日期,另一列显示我们称之为“case”的值。换句话说,我们要把数据帧从宽格式转换成长格式,这里就需要使用堆栈函数。
df = DataFrames.stack(
df,
Not("Country/Region"),
"Country/Region",
variable_name="Date",
value_name="Cases",
)
下面是我们格式化完成的数据,显示最后10行。
last(df, 10)
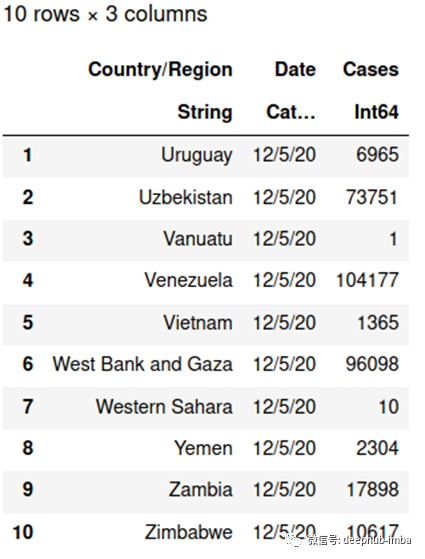
还有一件事要做。我们需要将de列“Date”从分类字符串格式转换为绘制时间序列的日期格式。
df.Date = Dates.Date.(df.Date |> Array, Dates.DateFormat("m/d/Y")) .+ Dates.Year(2000)
这是对最终整理后数据的描述如下。
describe(df)

在可视化数据之前,让我们先将整理后的数据写入磁盘。
CSV.write(joinpath(pwd(), "confirmed_tidy.csv"), df)
可视化数据
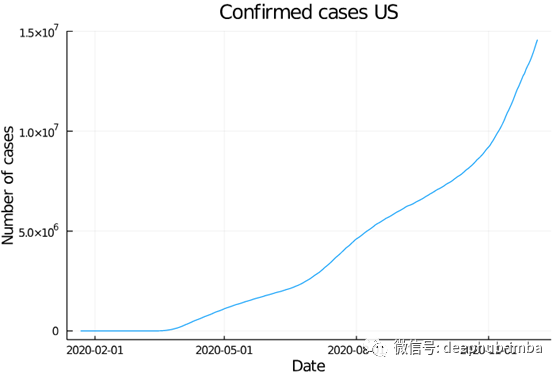
在我们的第一张图中,我们将可视化美国Covid-19累计确诊病例。
plot(
df[df["Country/Region"] .== "US", :Date],
df[df["Country/Region"] .== "US", :Cases],
title = "Confirmed cases US",
xlabel = "Date",
ylabel = "Number of cases",
legend = false,
)
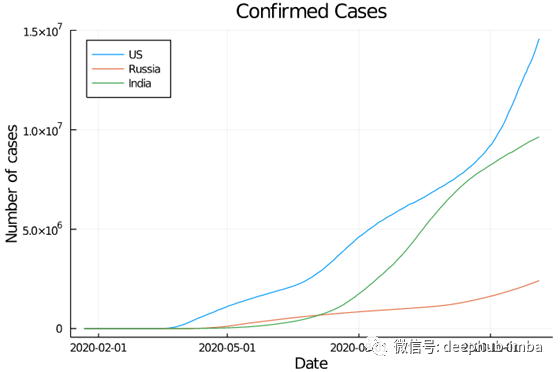
在一个图中绘制多个国家的时间序列非常简单。首先创建基本块,并为每个国家添加一层。
p = plot(
title = "Confirmed Cases",
xlabel = "Date",
ylabel = "Number of cases",
legend = :topleft,
)
for country = ["US", "Russia", "India"]
plot!(
df[df["Country/Region"] .== country, :Date],
df[df["Country/Region"] .== country, :Cases],
label = country,
)
end
p
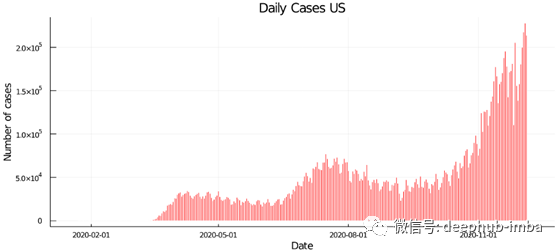
在我们的最后一个图中,我们将绘制美国每天的新病例。要做到这一点,我们必须计算连续天数之间的差值。因此,对于时间序列的第一天,这个值将不可用。
bar(
df[df["Country/Region"] .== "US", :Date][2:end],
diff(df[df["Country/Region"] .== "US", :Cases]),
title = "Daily Cases US",
xlabel = "Date",
ylabel = "Number of cases",
color = "red",
linecolor = "white",
legend = false,
size = (900, 400),
)
最后,我们将把图保存到磁盘上。
savefig(joinpath(pwd(), "daily_cases_US.svg"))
总结
在本文中,我们介绍了使用Julia进行数据分析的基础知识。根据我的经验,Julia很像python。这两种语言都易于编写和学习。两者都是开源的。我喜欢Julia的原因是它的高性能以及它与其他编程语言(如Python)的互操作性。我喜欢Python的地方在于它庞大的包集合和庞大的在线社区。
作者:R e n é
deephub翻译组
原文地址:https://towardsdatascience.com/getting-started-with-data-analysis-in-julia-421ce0032916