
文章目录
HDFS Java API操作
Hadoop是使用Java语言编写的,因此使用Java API操作Hadoop文件系统,HDFS Shell本质上就是对Java API的应用,通过编程的形式,操作HDFS,其核心是使用HDFS提供的Java API构造一个访问客户端对象,然后通过客户端对象对HDFS上的文件进行操作(增,删,改,查)
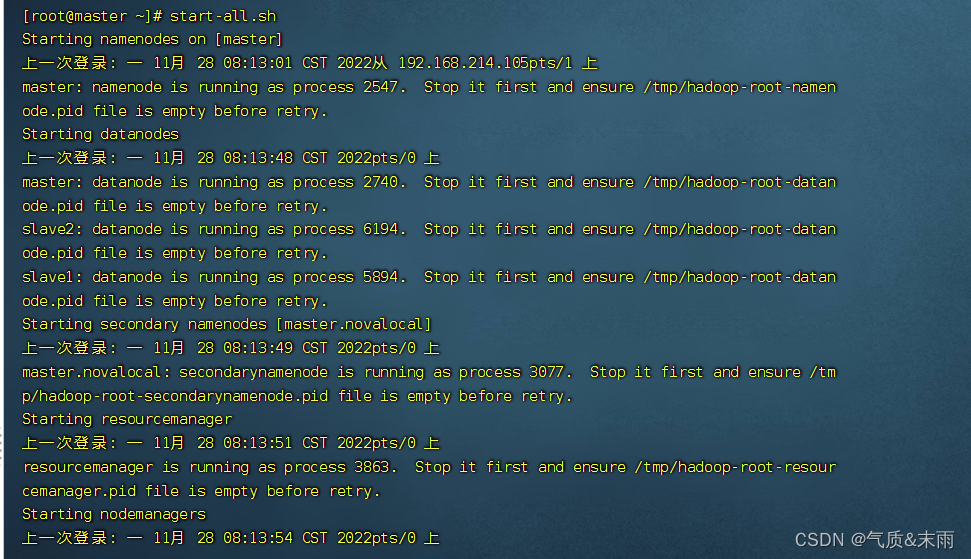
零、启动hadoop
一、HDFS常见类接口与方法
1、hdfs 常见类与接口
Hadoop
整合了众多文件系统,
HDFS
只是这个文件系统的一个实例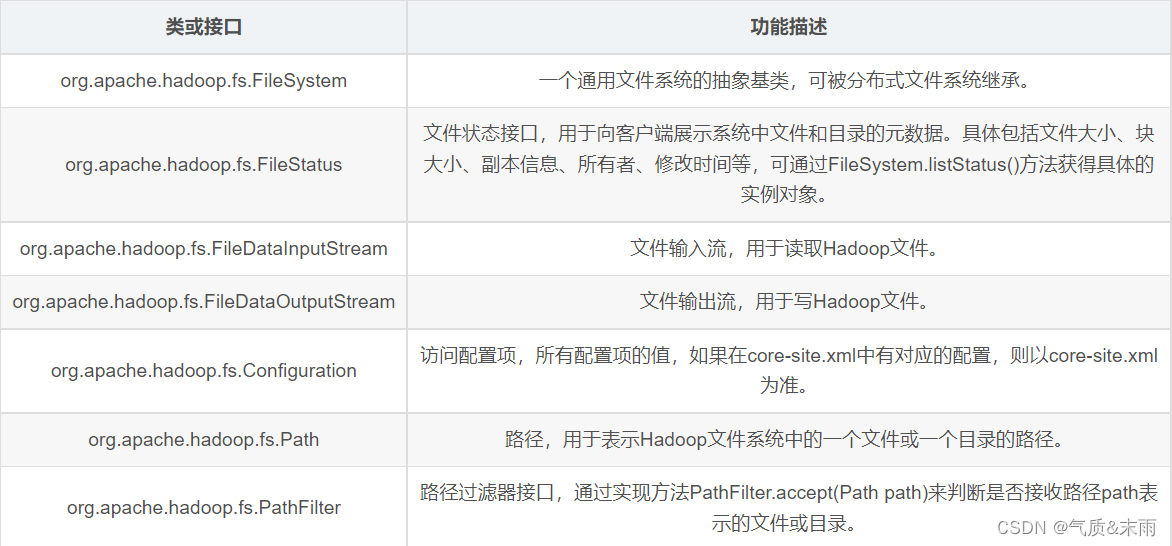
2、FileSystem 的常用方法
FileSystem
对象的一些方法可以对文件进行操作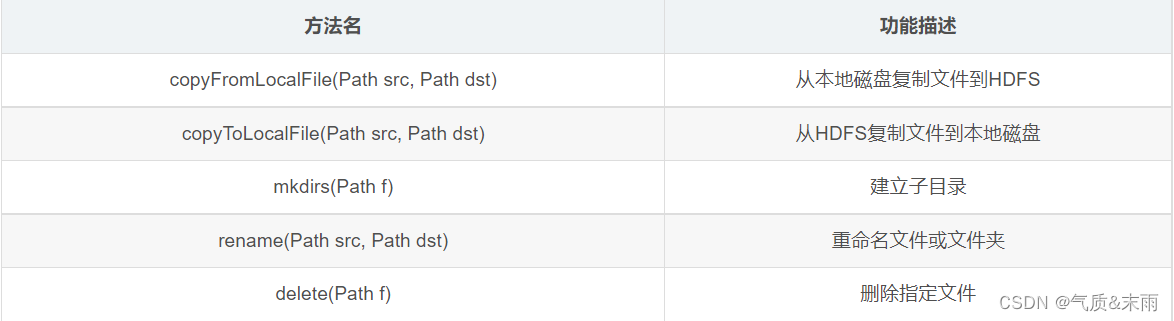
二、Java 创建Hadoop项目
1、创建文件夹
现在D盘创建一个空的文件夹,
HDFS02
用来存放hadoop项目
2、打开Java IDEA
1) 新建项目
点击左上角,新建项目
2) 选择Maven
选择Maven包管理,记住一定是
jdk1.8
版本的,然后那个从
archetype
不要选择
然后点击下一步,位置选择刚刚D盘创建的那个
HDFS02
文件夹,然后点击完成
三、配置环境
1、添加相关依赖
创建完成之后,进来是一个
pom.xml
文件
添加以下的相关的
hadoop
和
junit
依赖配置,其中大部分都是有的,主要是
<dependencise></dependencise>
这个部分
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>HDFS02</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>18</maven.compiler.source><maven.compiler.target>18</maven.compiler.target></properties><dependencies><dependency><!--hadoop客户端--><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.3.4</version></dependency><!--单元调试框架--><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.13.2</version></dependency></dependencies></project>
然后右上角有一个m的图标,点击一下,加载配置文件,导入包,这个很关键,不然那些包都用不起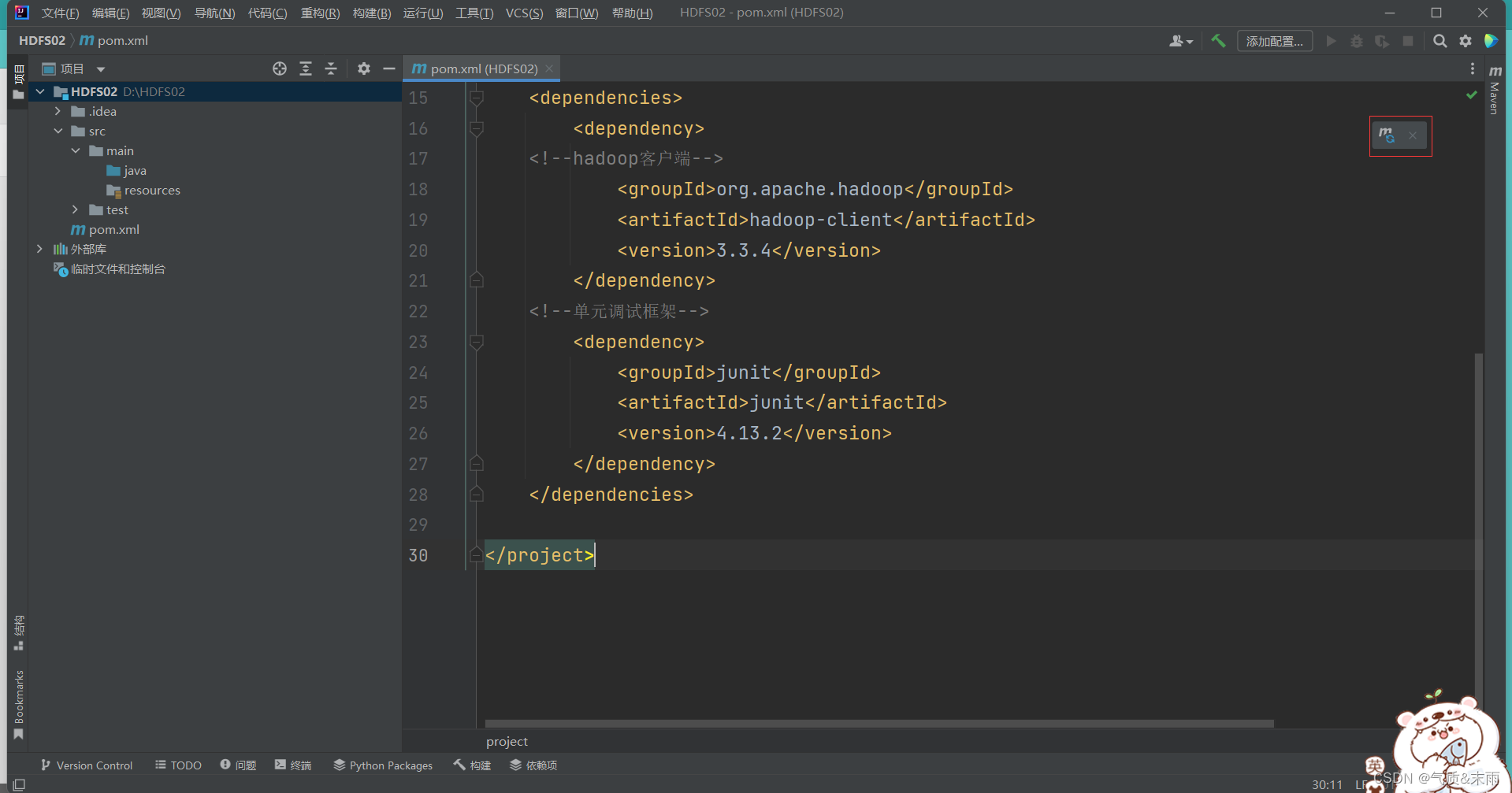
Manen Repository (Maven仓库) http://mvnrepository.com/
搜索
hadoop
点击
hadoop-client
超链接,然后点击下面的3.3.4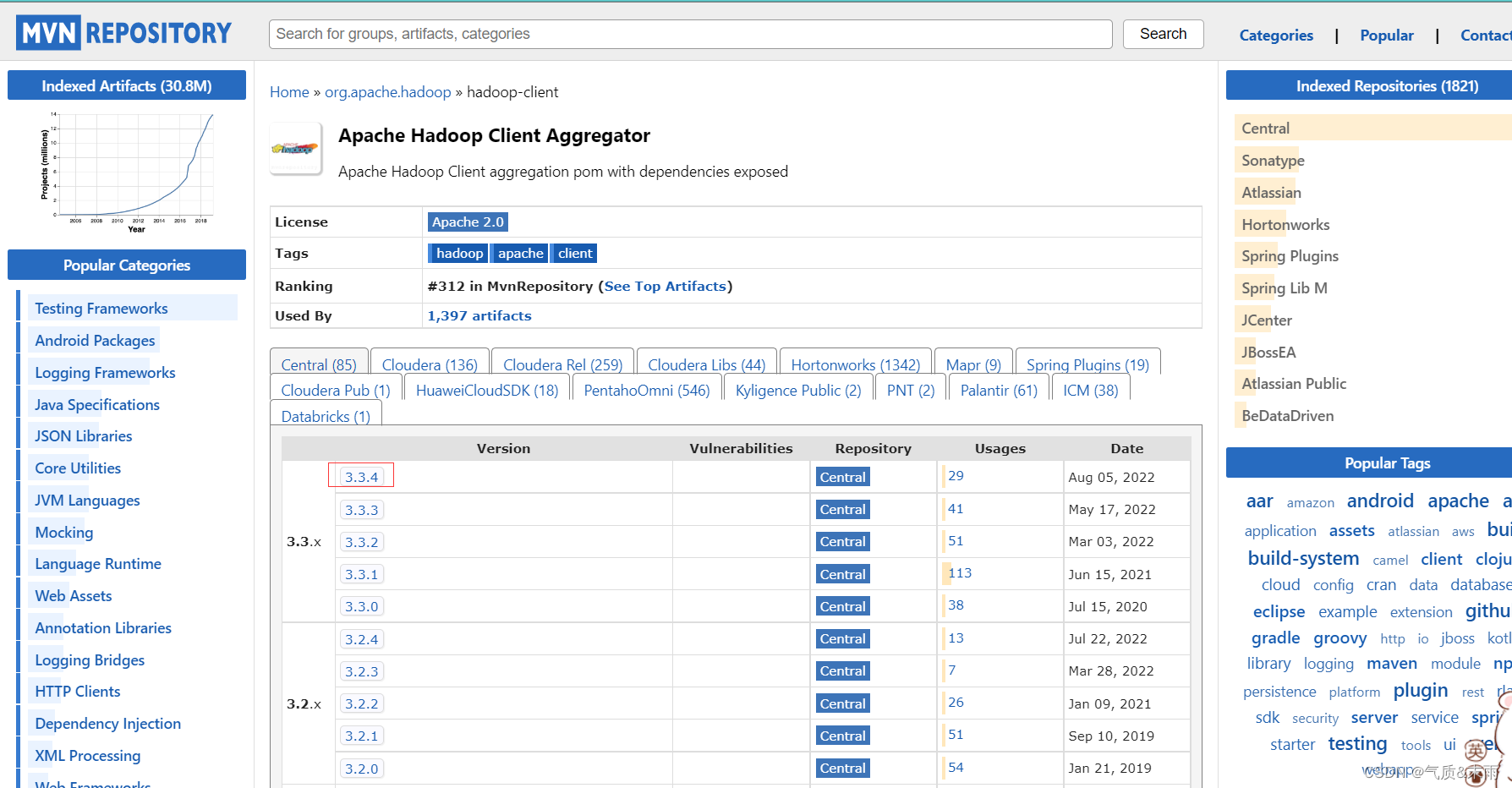
就可以看到上面在Java里面配置的hadoop的依赖就是这个地方的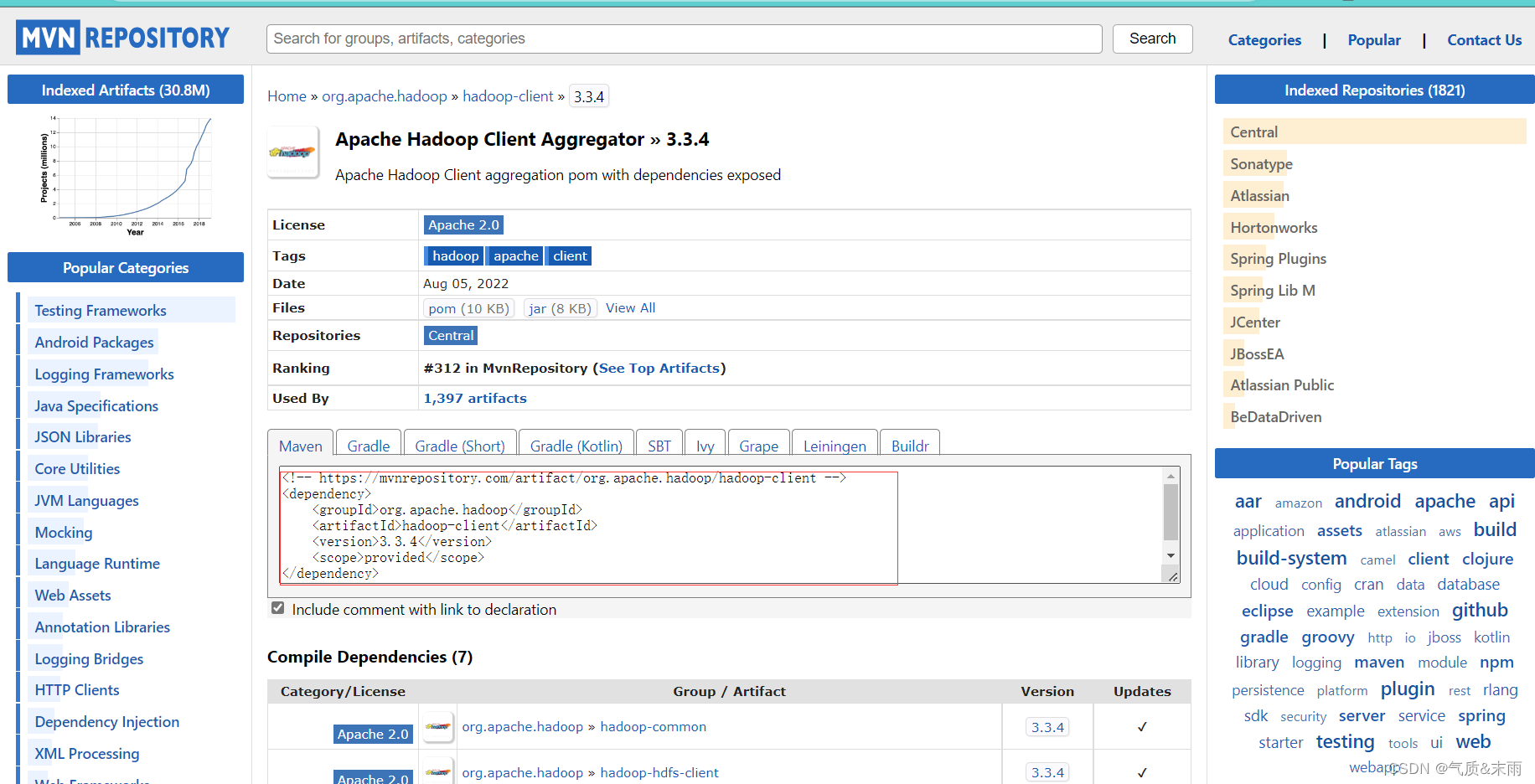
2、创建日志属性文件
在
resources
目录里创建
log4j.properties
文件
把下面的配置添加进去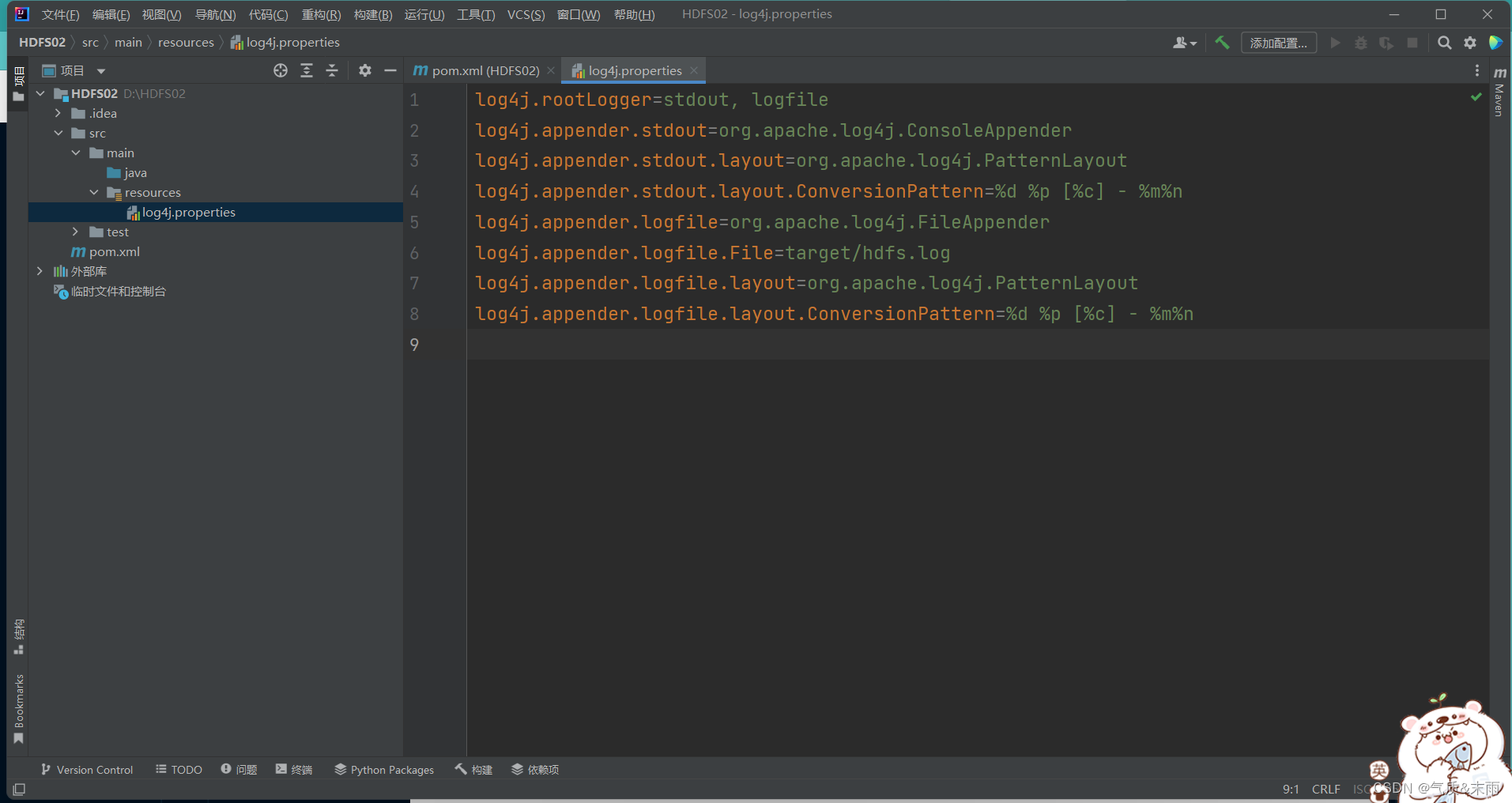
log4j.rootLogger=stdout, logfile
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayoutlog4j.appender.stdout.layout.ConversionPattern=%d %p [%c]-%m%n
log4j.appender.logfile=org.apache.log4j.FileAppenderlog4j.appender.logfile.File=target/hdfs.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayoutlog4j.appender.logfile.layout.ConversionPattern=%d %p [%c]-%m%n
四、Java API操作
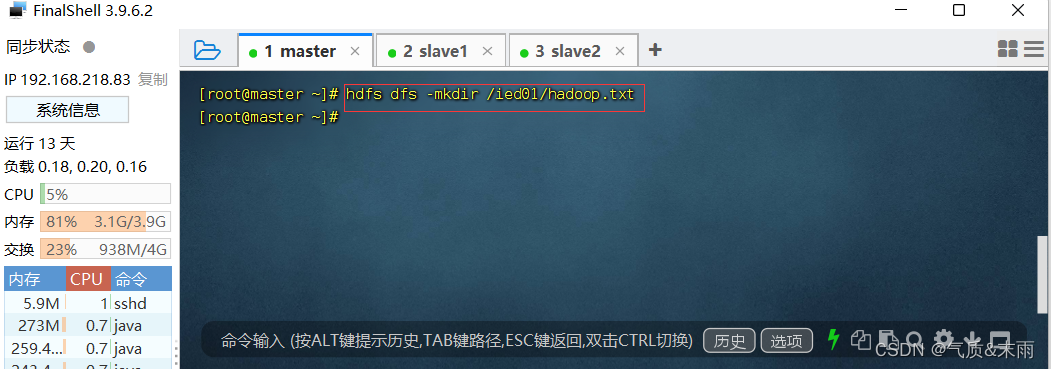
1、在HDFS上创建文件
在 /ied01 目录里创建hadoop.txt 文件
输入命令:
hdfs dfs -mkdir /ied01/hadoop.txt
在webUI界面进行查看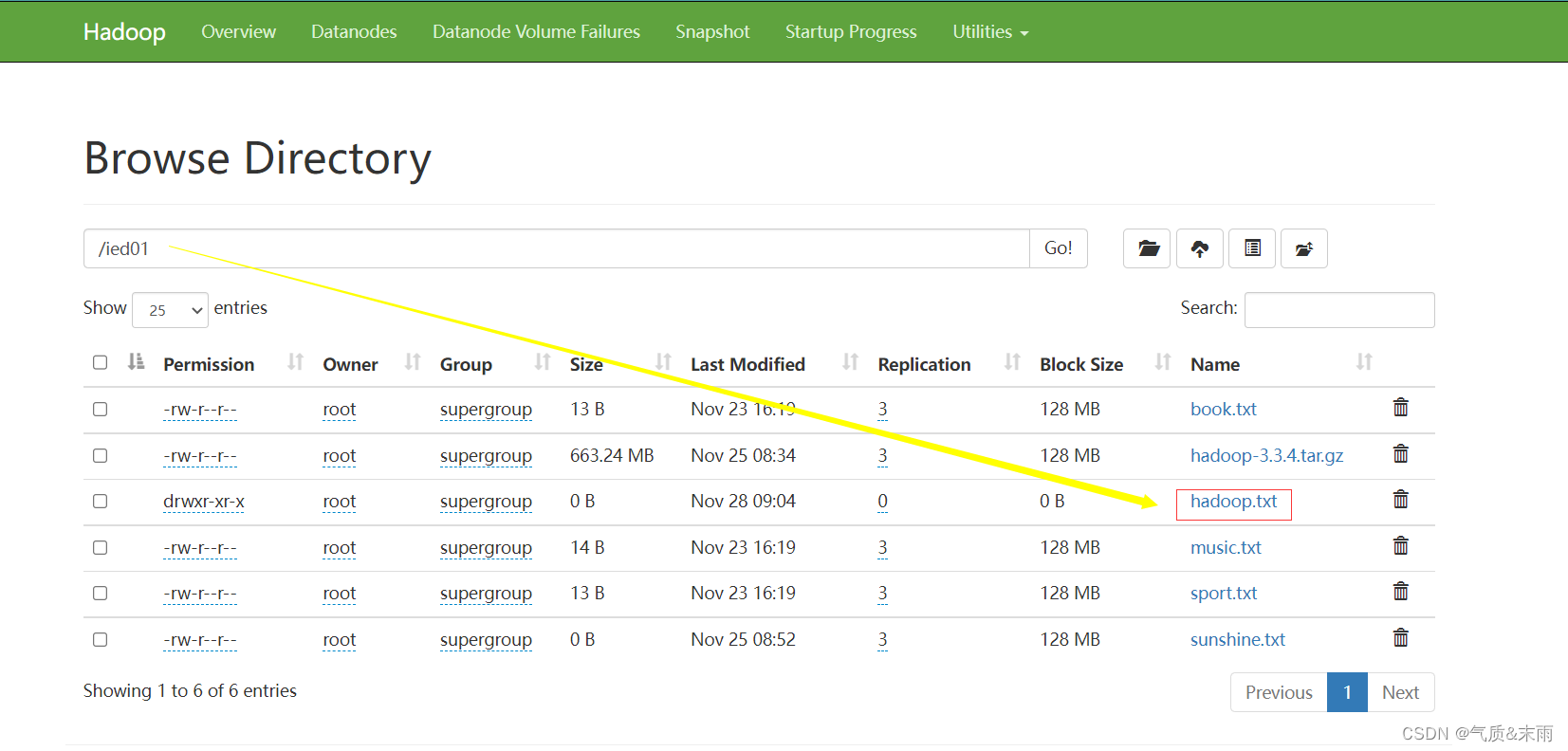
2、在Java 上创建包
创建
net.aex.hdfs
包,在包里创建
CreateFileOnHDFS
类
1) 编写
create1()
方法
注意导入包的时候一定不要导错了,有些很相似
packagenet.aex.hdfs;importorg.apache.hadoop.conf.Configuration;importjava.net.URI;importorg.apache.hadoop.fs.FileSystem;importorg.apache.hadoop.fs.Path;//下面这两个是错的//import java.nio.file.FileSystem;//import java.nio.file.Path;publicclassCreateFileOnHDFS{publicstaticvoidcreate1()throwsException{//创建配置对象Configuration conf =newConfiguration();//定义统一资源标识符 (uri: uniform resource identifer)String uri ="hdfs://master:9000";//创建文件系统对象(基于HDFS的文件系统)FileSystem fs =FileSystem.get(newURI(uri),conf);//创建路径对象Path path =newPath(uri +"/ied01/hadoop.txt");//基于路径对象创建文件boolean result = fs.createNewFile(path);//根据返回值判断文件是否创建成功if(result){System.out.println("文件["+ path +"创建成功]");}else{System.out.println("文件["+ path +"创建失败]");}}publicstaticvoidmain(String[] args)throwsException{create1();}}
下面使用
main
方法 对CreateFileOnHDFS 函数方法进行调用
运行程序查看结果,创建失败,因为我们之前已经在linux本地 hdfs上创建了这个文件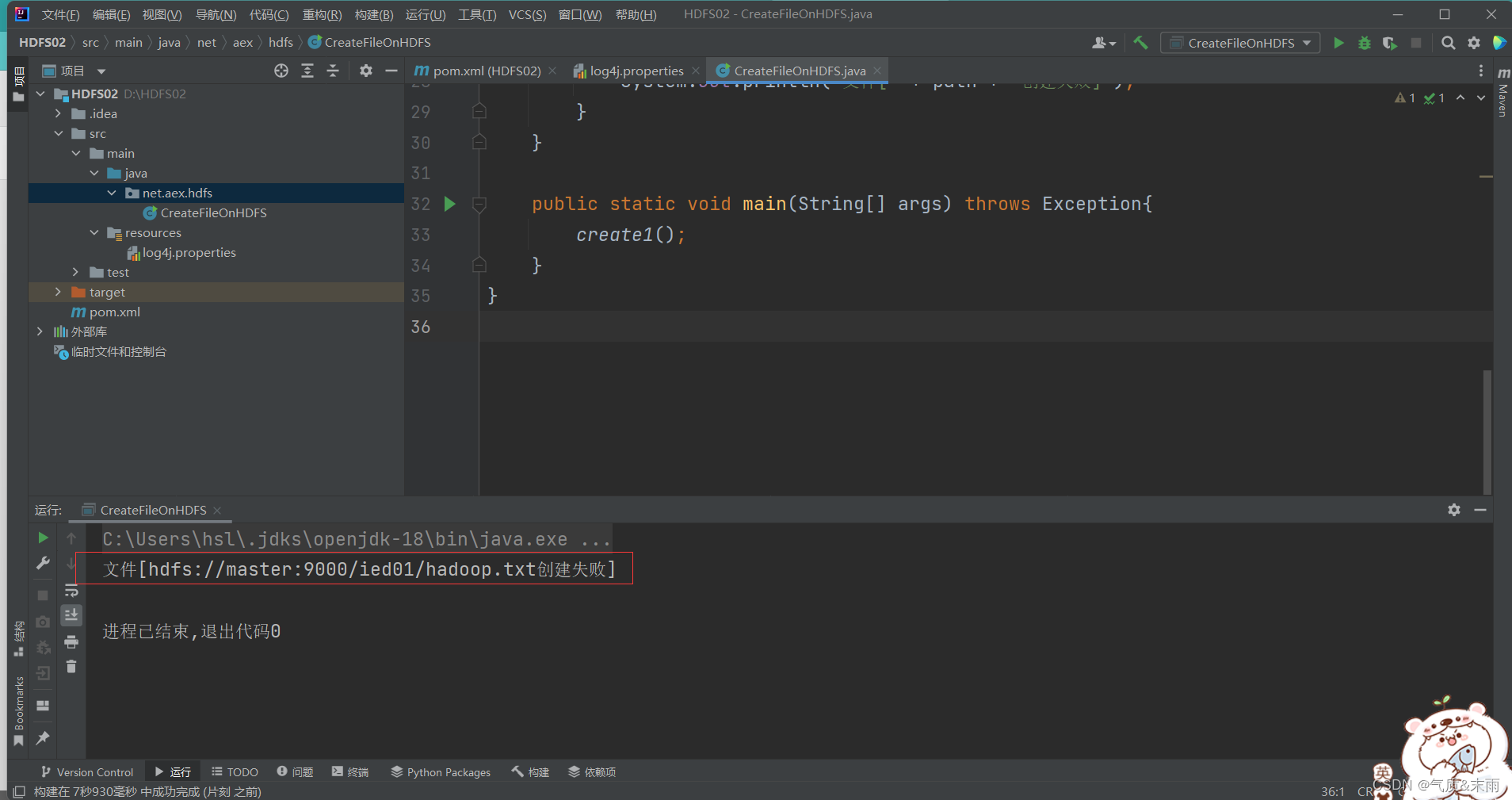
此时将这个创建的文件路径改为
/ied02/hadoop02.txt
就成功了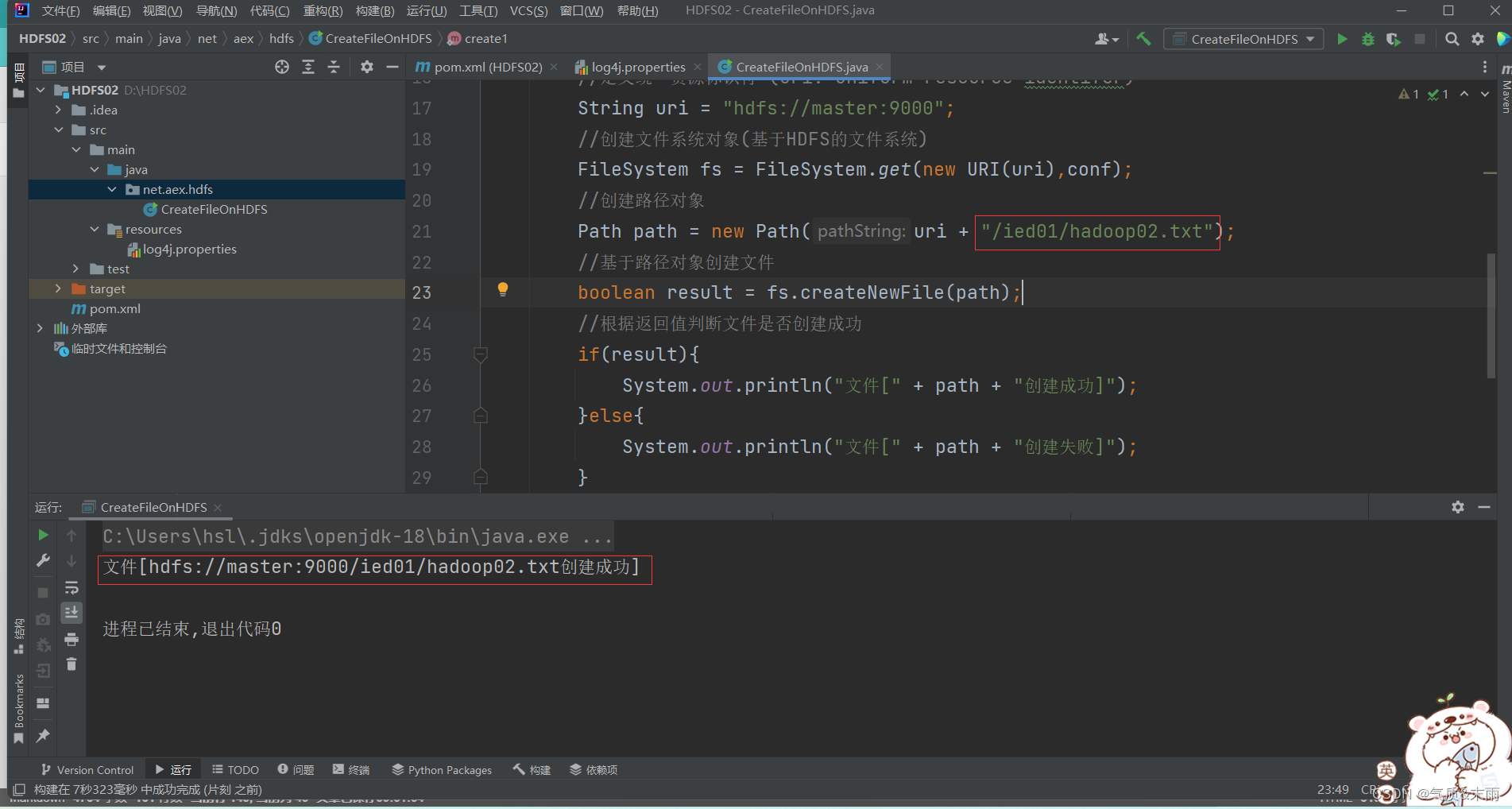
在webUI界面上进行查看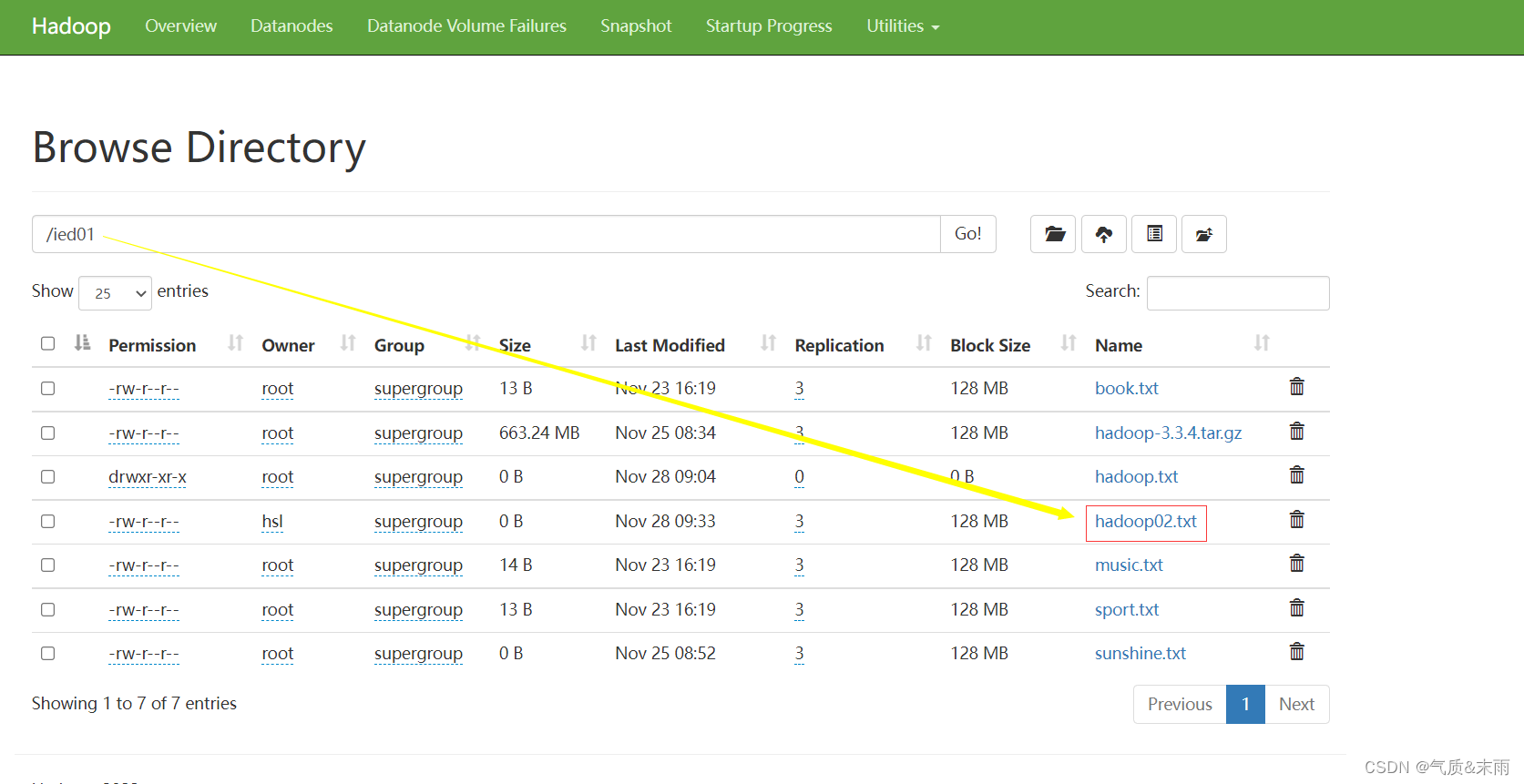
注意:在
/ied01
目录里确实创建了一个
0字节
的
hadoop02.txt
文件,有点类似于Hadoop shell 里执行
hdfs dfs -touchz /ied01/hadoop02.txt
但是在linux上面重复执行不会失败,只是会不断改变这个文件的时间戳,但是在Java API里面操作,如果重复执行就会失败
2) 编写create2() 方法
编写create2() 方法,事先判断文件是否已经存在
//create2publicstaticvoidcreate2()throwsException{//创建配置对象Configuration conf =newConfiguration();//定义统一资源标识符 (uri: uniform resource identifer)String uri ="hdfs://master:9000";//创建文件系统对象(基于HDFS的文件系统)FileSystem fs =FileSystem.get(newURI(uri),conf);//创建路径对象Path path =newPath(uri +"/ied01/hadoop.txt");//判断路径对象指定的文件是否已经存在if(fs.exists(path)){//提示用户文件已经存在System.out.println("文件["+path+"]已经存在!");}else{//基于路径对象创建文件boolean result = fs.createNewFile(path);//根据返回值判断文件是否已经创建成功if(result){System.out.println("文件["+ path +"创建成功!");}else{System.out.println("文件["+ path +"创建失败!");}}}
使用
main
方法调用
create2()
函数方法,查看程序运行结果,提示文件已经存在
此时我们怎么才能出现文件创建失败的情况呢,我们故意让HDFS进入安全模式(只能读,不能写)
在
linux
上删除已经创建的
/ied01/hadoop02.txt
文件
输入命令:
hdfs dfs -rm /ied01/hadoop02.txt

输入命令:
hdfs dfsadmin safemode enter
进入安全模式
此时,再运行程序,抛出SafeModelException 异常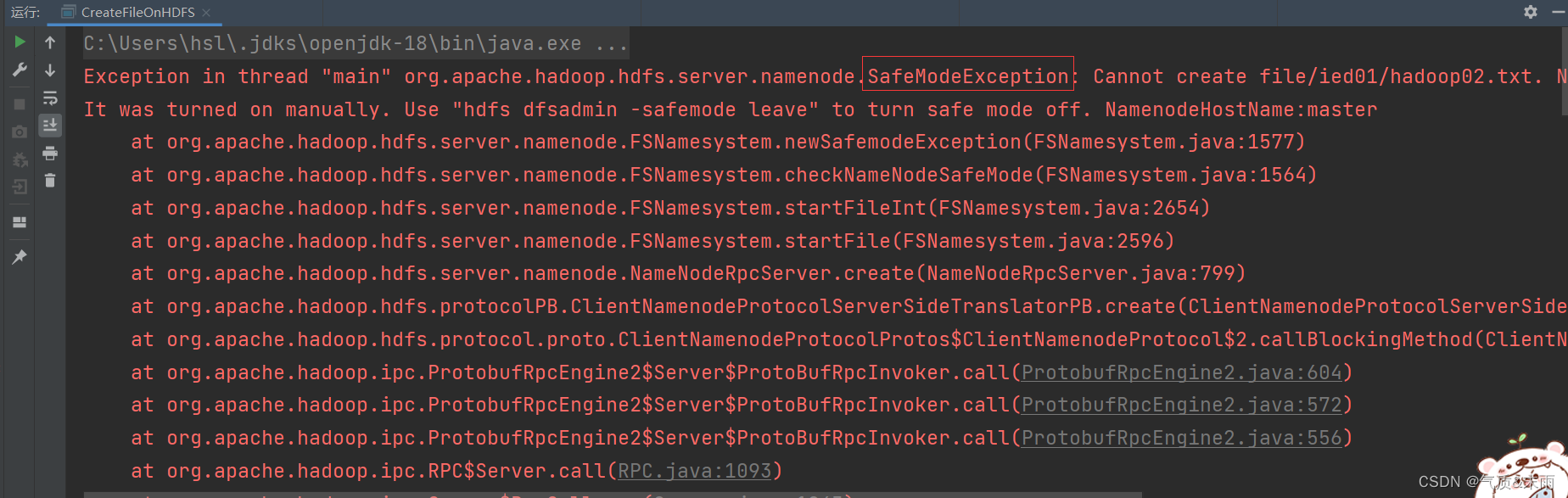
修改程序,来处理这个可能会抛出的安全模式异常
使用try catch 来抛出捕获异常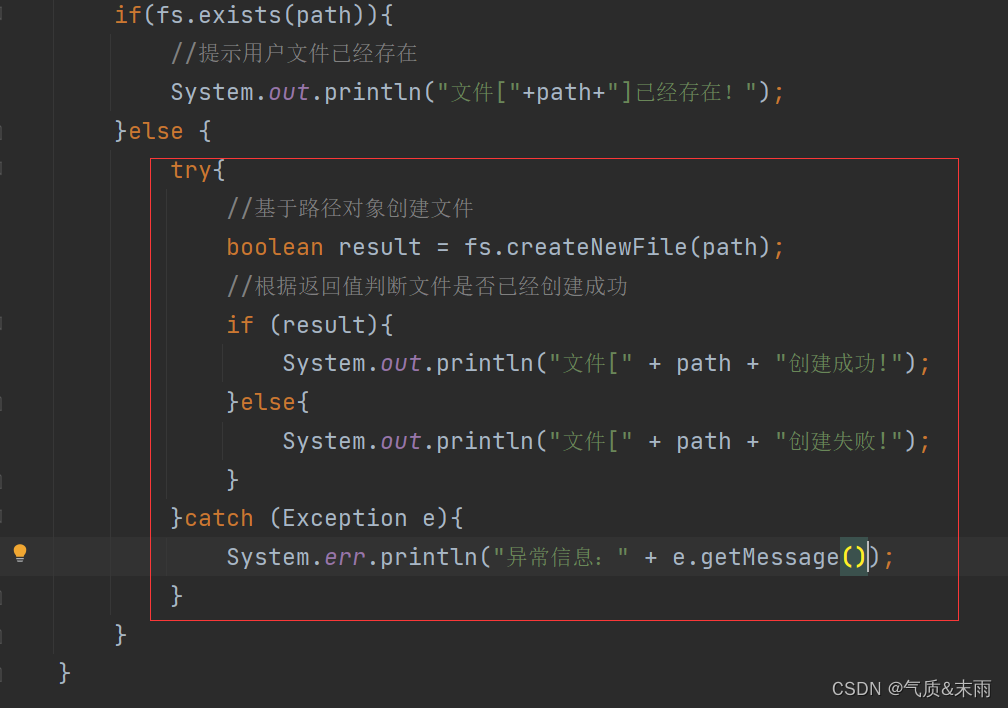
运行程序,查看结果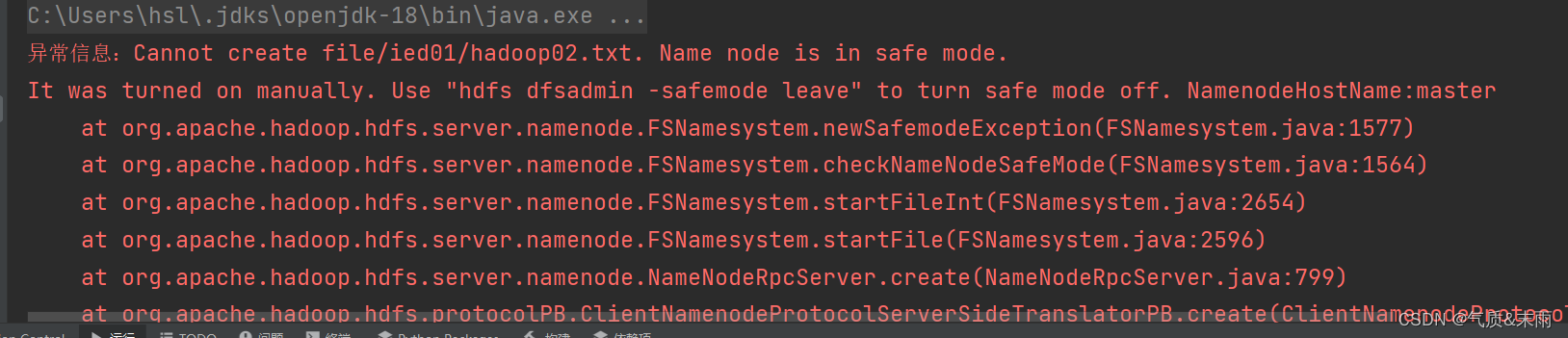
linux 输入命令:
hdfs dfsadmin -safemode leave
关闭安全模式
再运行程序,查看结果 创建成功
3、在HDFS上写入文件
在
net.aex.hdfs
包里创建
WriteFileOnHDFS
类
1) 将数据直接写入HDFS文件
在linux本地 hdfs
/ied01
目录创建
hello.txt
文件
(1)编写write1() 方法
在Java 里创建 write1() 函数方法
packagenet.aex.hdfs;importorg.apache.hadoop.conf.Configuration;importorg.apache.hadoop.fs.FSDataOutputStream;importorg.apache.hadoop.fs.FileSystem;importorg.apache.hadoop.fs.Path;importjava.net.URI;importjava.nio.charset.StandardCharsets;publicclassWriteFileOnHDFS{publicstaticvoidwrite1()throwsException{//创建配置对象Configuration conf =newConfiguration();//定义统一资源标识符 (uri: uniform resource identifer)String uri ="hdfs://master:9000";//创建文件系统对象(基于HDFS的文件系统)FileSystem fs =FileSystem.get(newURI(uri),conf);//创建路径对象Path path =newPath(uri +"/ied01/hello.txt");//创建文件系统数据字节输出流FSDataOutputStream out = fs.create(path);//通过字节输出流向文件写入数据
out.write("Hello hadoop world".getBytes());//关闭输出流
out.close();//关闭文件系统对象
fs.close();}publicstaticvoidmain(String[] args)throwsException{write1();}}
运行程序,查看结果,报错,没有数据节点可以写入数据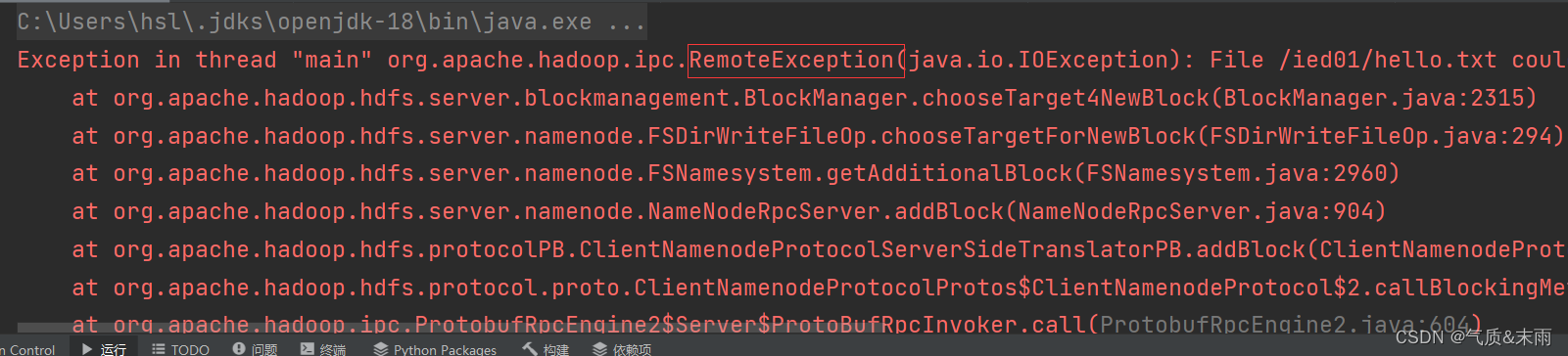
修改代码,添加一个 设置数据节点主机名属性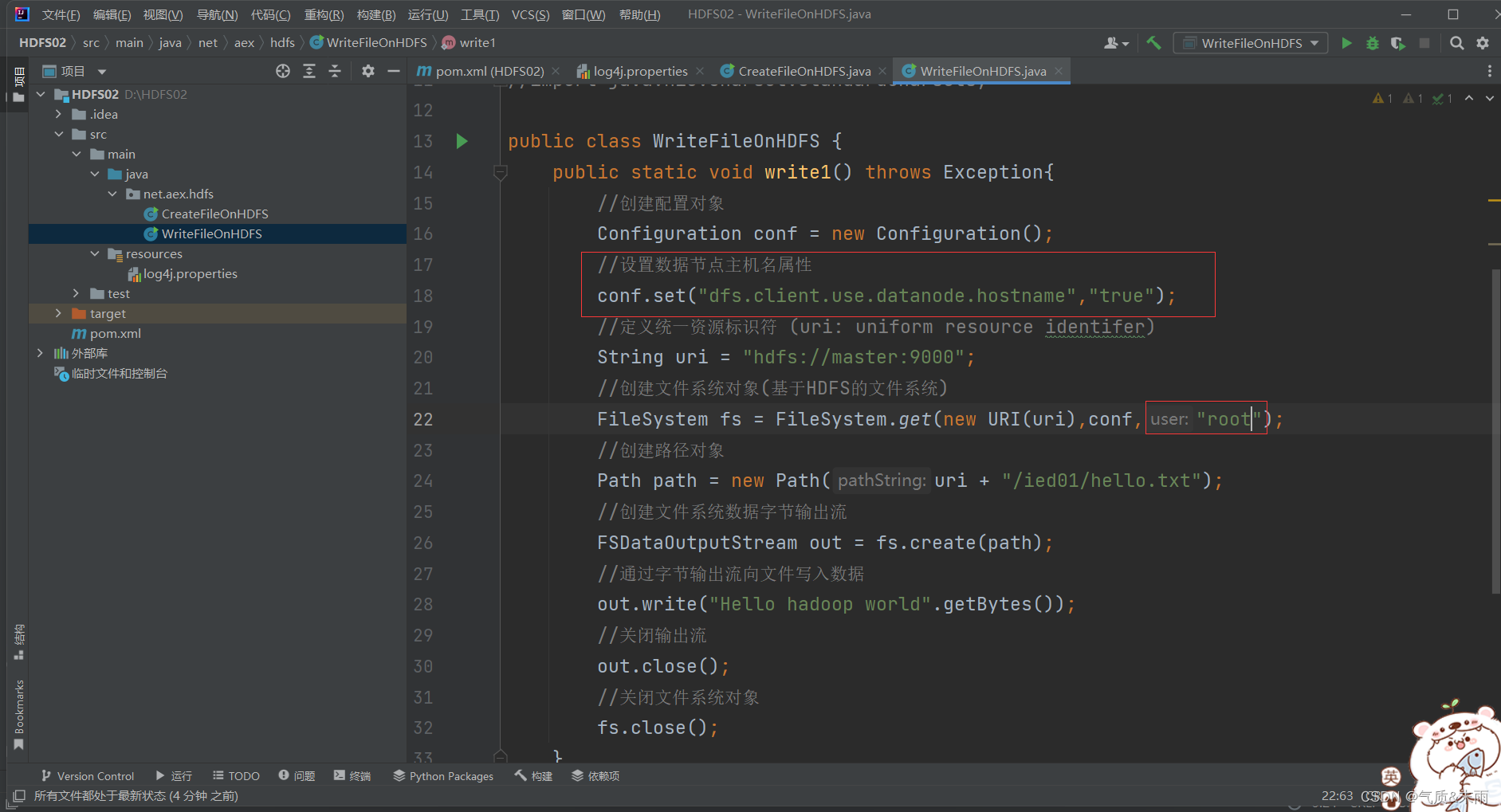
运行1程序,查看结果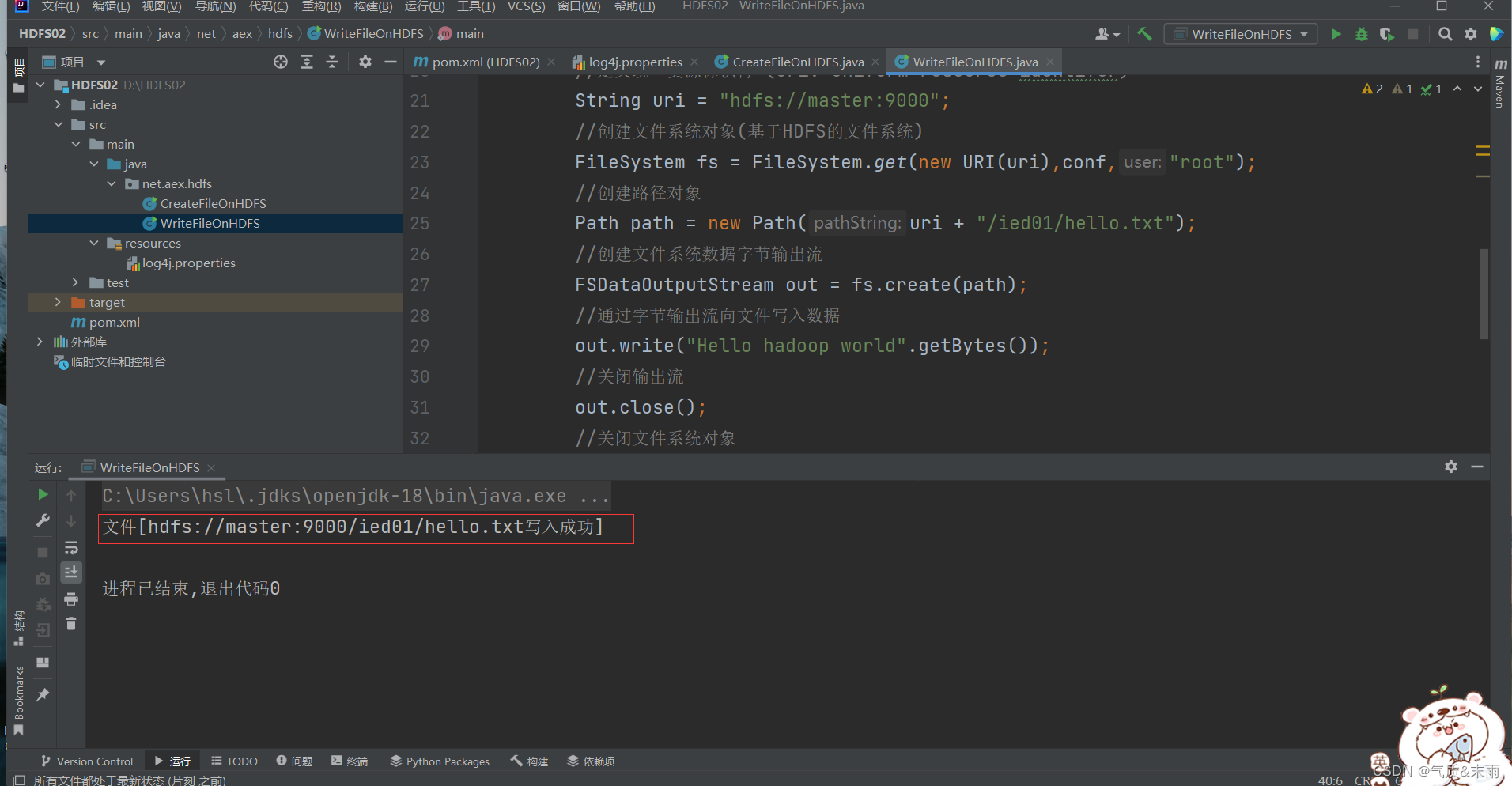
在webUI界面上查看
hello.txt
文件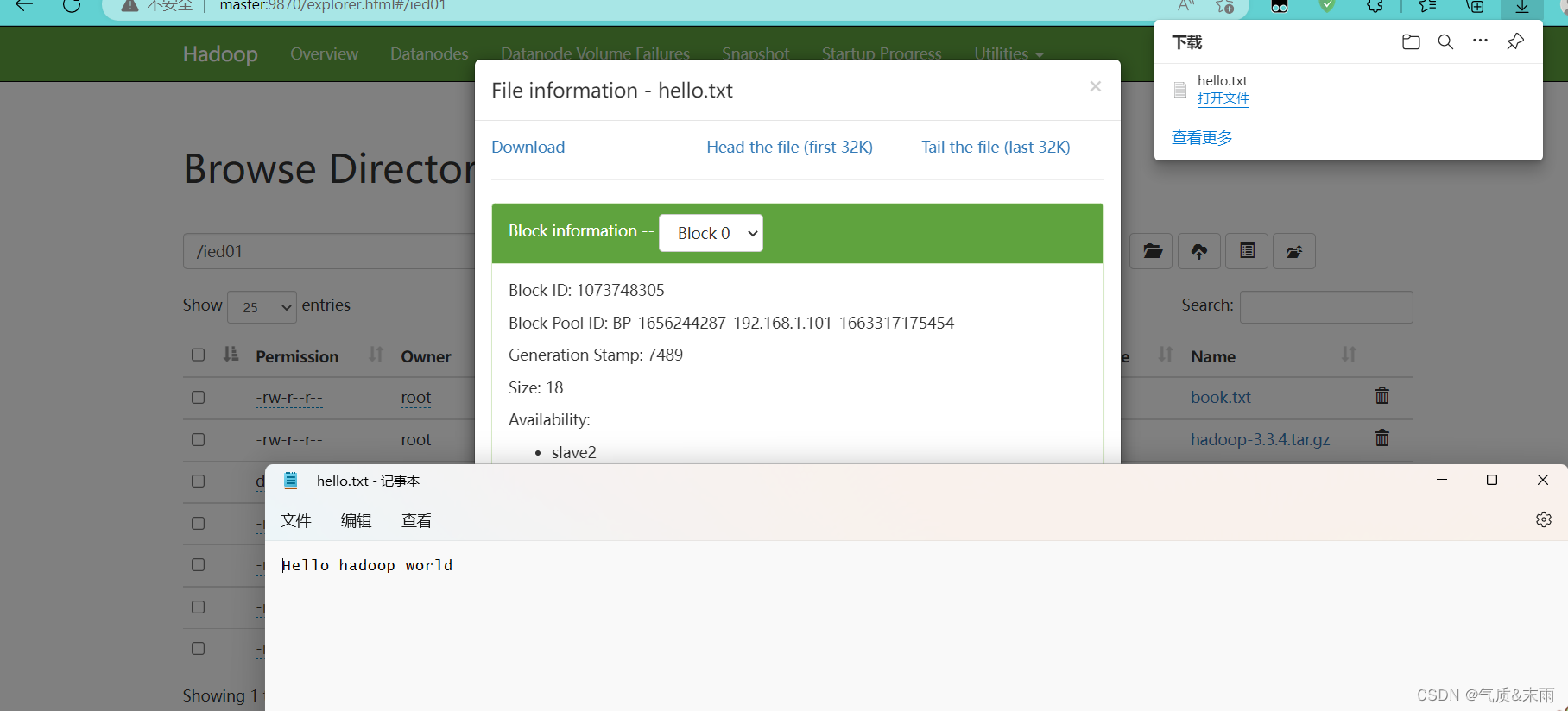
2) 将本地文件写入HDFS文件
在Java项目根目录创建一个文本文件test.txt
(1)、编写witer2() 方法
在Java WriteFileOnHDFS类里面创建 write2函数方法
//write2publicstaticvoidwrite2()throwsException{//创建配置对象Configuration conf =newConfiguration();//设置数据节点主机名属性
conf.set("dfs.client.use.datanode.hostname","true");//定义统一资源标识符 (uri: uniform resource identifer)String uri ="hdfs://master:9000";//创建文件系统对象(基于HDFS的文件系统)FileSystem fs =FileSystem.get(newURI(uri),conf,"root");//创建路径对象Path path =newPath(uri +"/ied01/exam.txt");//创建文件系统数据字节输出流对象FSDataOutputStream out = fs.create(path);//创建文字字符输入流对象FileReader fr =newFileReader("test.txt");//创建缓冲字符输入流对象BufferedReader br =newBufferedReader(fr);//定义行字符串String nextLine ="";//通过循环读取缓冲字符输入流while((nextLine=br.readLine())!=null){//在控制台输出读取的行System.out.println(nextLine);//通过文件系统数据字节输出流对象写入指定文件
out.write(nextLine.getBytes());}//关闭文件系统字节输出流
out.close();//关闭缓冲字符输入流
br.close();//关闭文件字符输入流
fr.close();//提示用户写入文件成功System.out.println("本地文件[test.txt]成功写入["+ path +"]!");}
main函数调用write2() 方法,查看结果 写入成功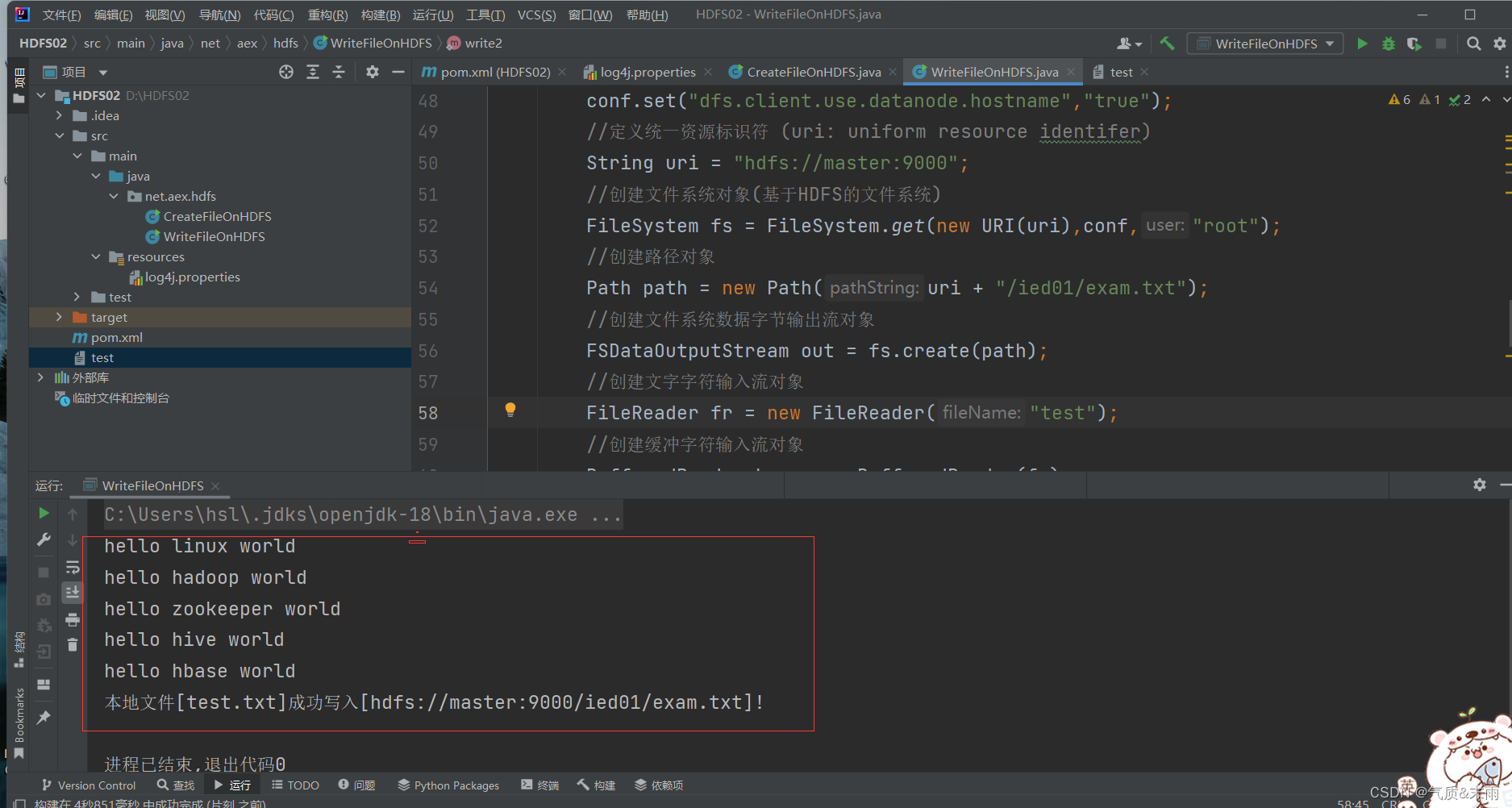
其实这个方法的功能就是将本地文件复制(上传)到
HDFS
,有更简单的处理方法,通过使用一个工具类
IOUtils
来完成文件的相关操作
(2)、编写write2_2() 方法
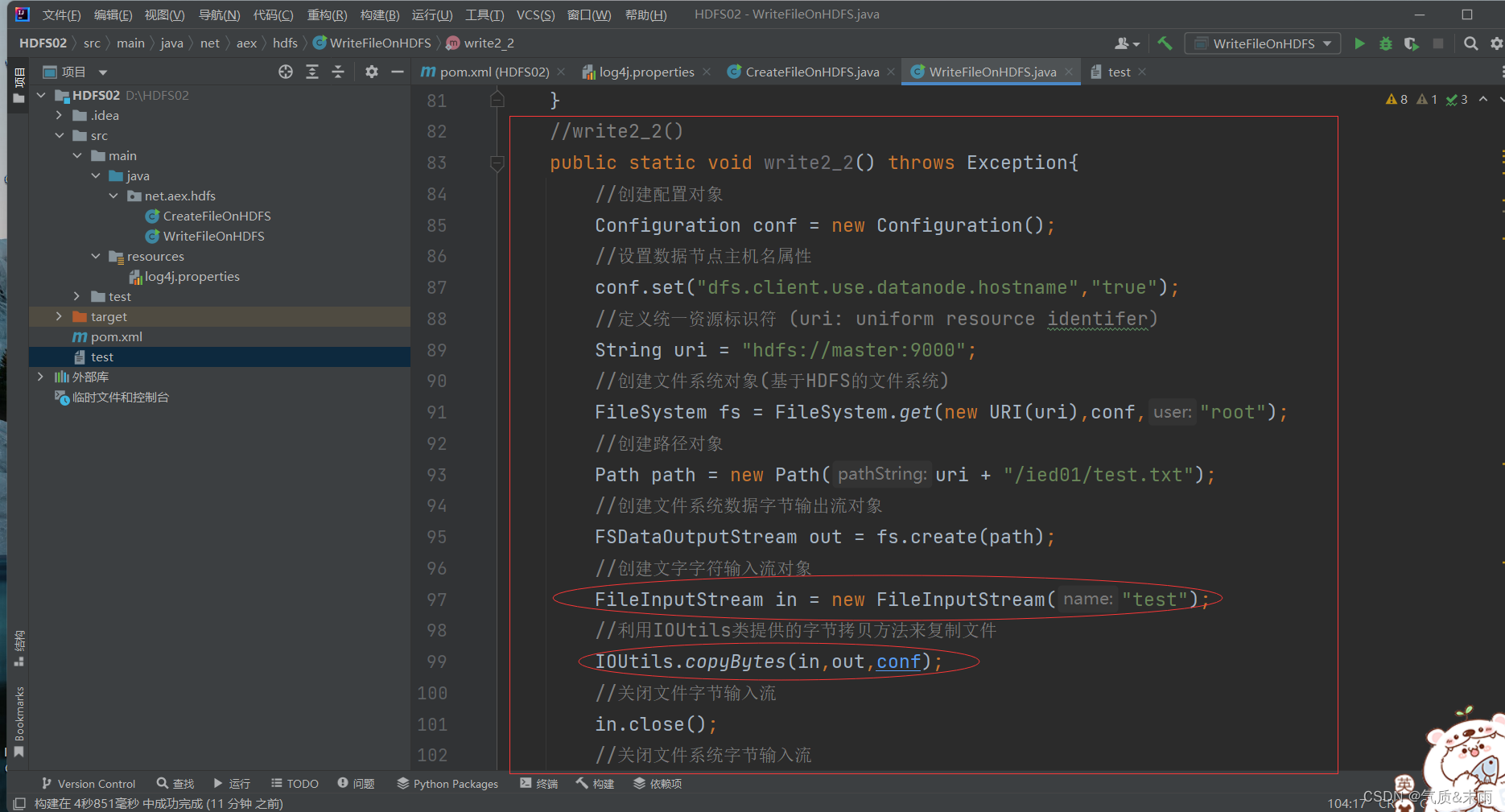
//write2_2()publicstaticvoidwrite2_2()throwsException{//创建配置对象Configuration conf =newConfiguration();//设置数据节点主机名属性
conf.set("dfs.client.use.datanode.hostname","true");//定义统一资源标识符 (uri: uniform resource identifer)String uri ="hdfs://master:9000";//创建文件系统对象(基于HDFS的文件系统)FileSystem fs =FileSystem.get(newURI(uri),conf,"root");//创建路径对象Path path =newPath(uri +"/ied01/test.txt");//创建文件系统数据字节输出流对象FSDataOutputStream out = fs.create(path);//创建文字字符输入流对象FileInputStream in =newFileInputStream("test");//利用IOUtils类提供的字节拷贝方法来复制文件IOUtils.copyBytes(in,out,conf);//关闭文件字节输入流
in.close();//关闭文件系统字节输入流
out.close();//关闭文件系统
fs.close();//提示用户写入文件成功System.out.println("本地文件[test.txt]成功写入["+ path +"]!");}
使用main方法,运行write2_2() 函数方法 查看结果 写入成功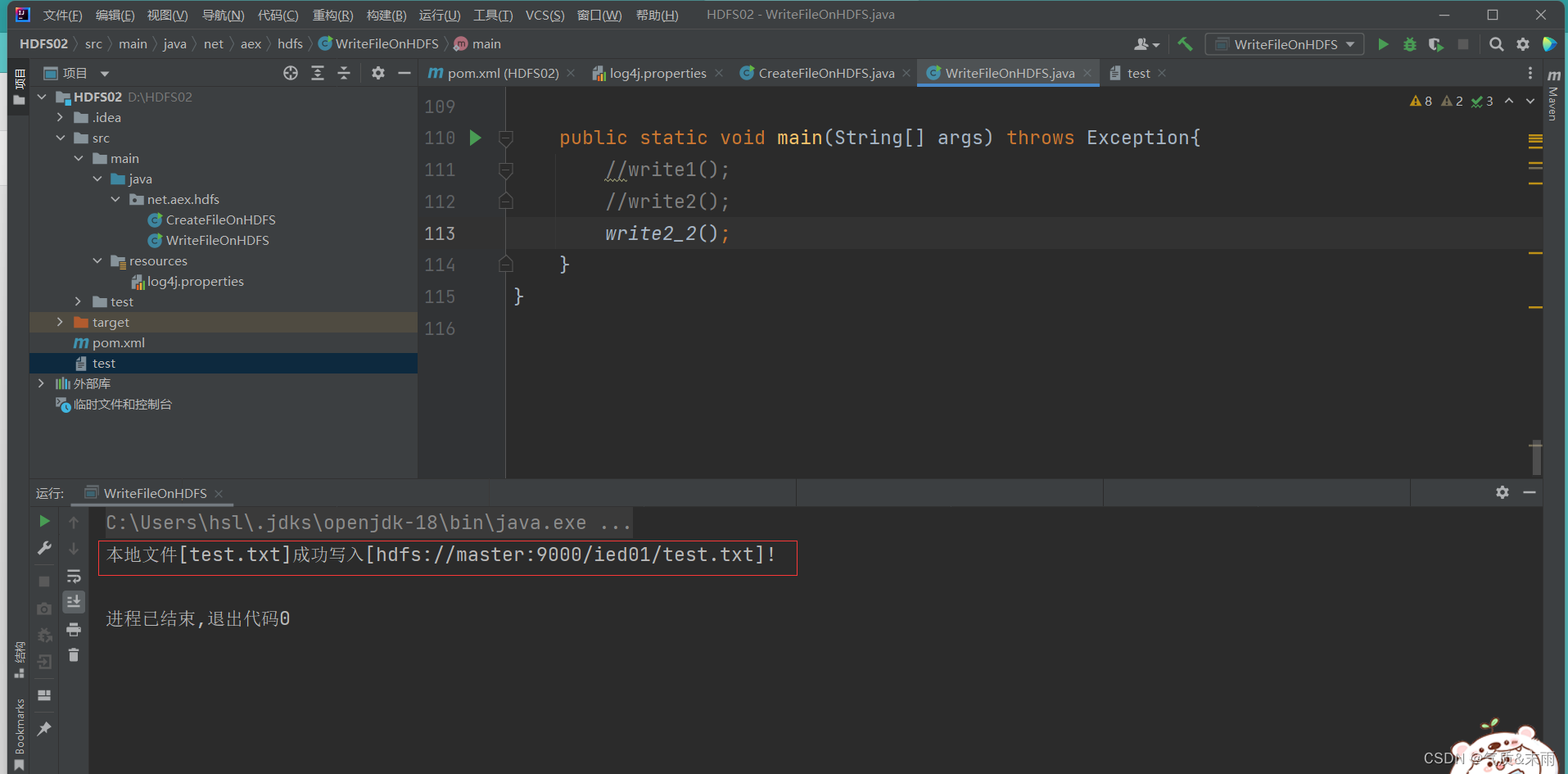
在linux查看
hdfs
目录
/ied01/test.txt
内容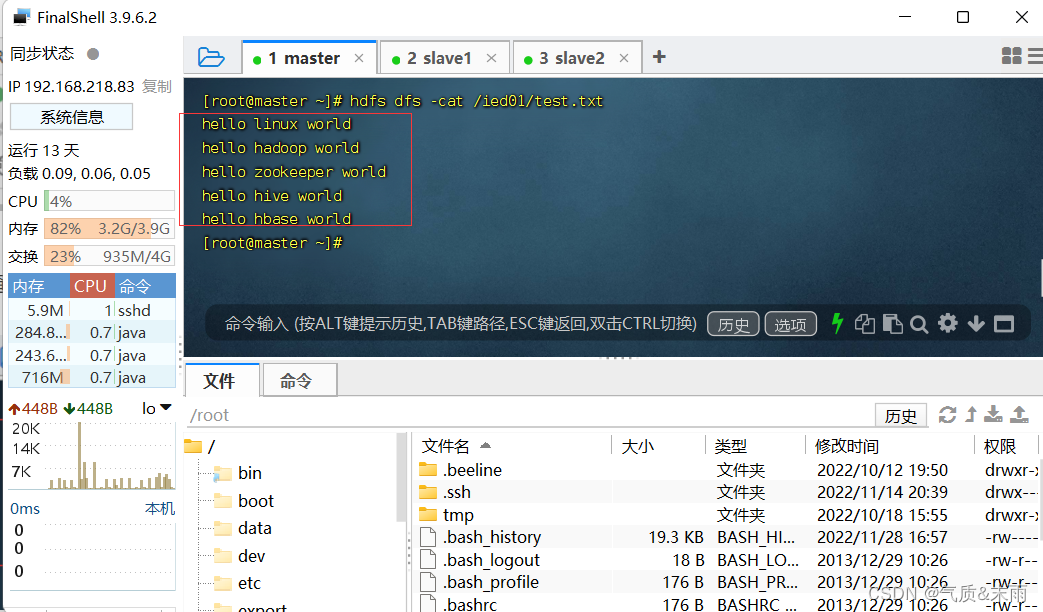
4、读取HDFS文件
相当于Shell里的两个命令:
hdfs dfs -cat
和
hdfs dfs -get
在
net.aex.hdfs
包里创建
ReadFileOnHDFS
类
1) 读取HDFS文件直接在控制台显示
准备读取
/ied01/test.txt
文件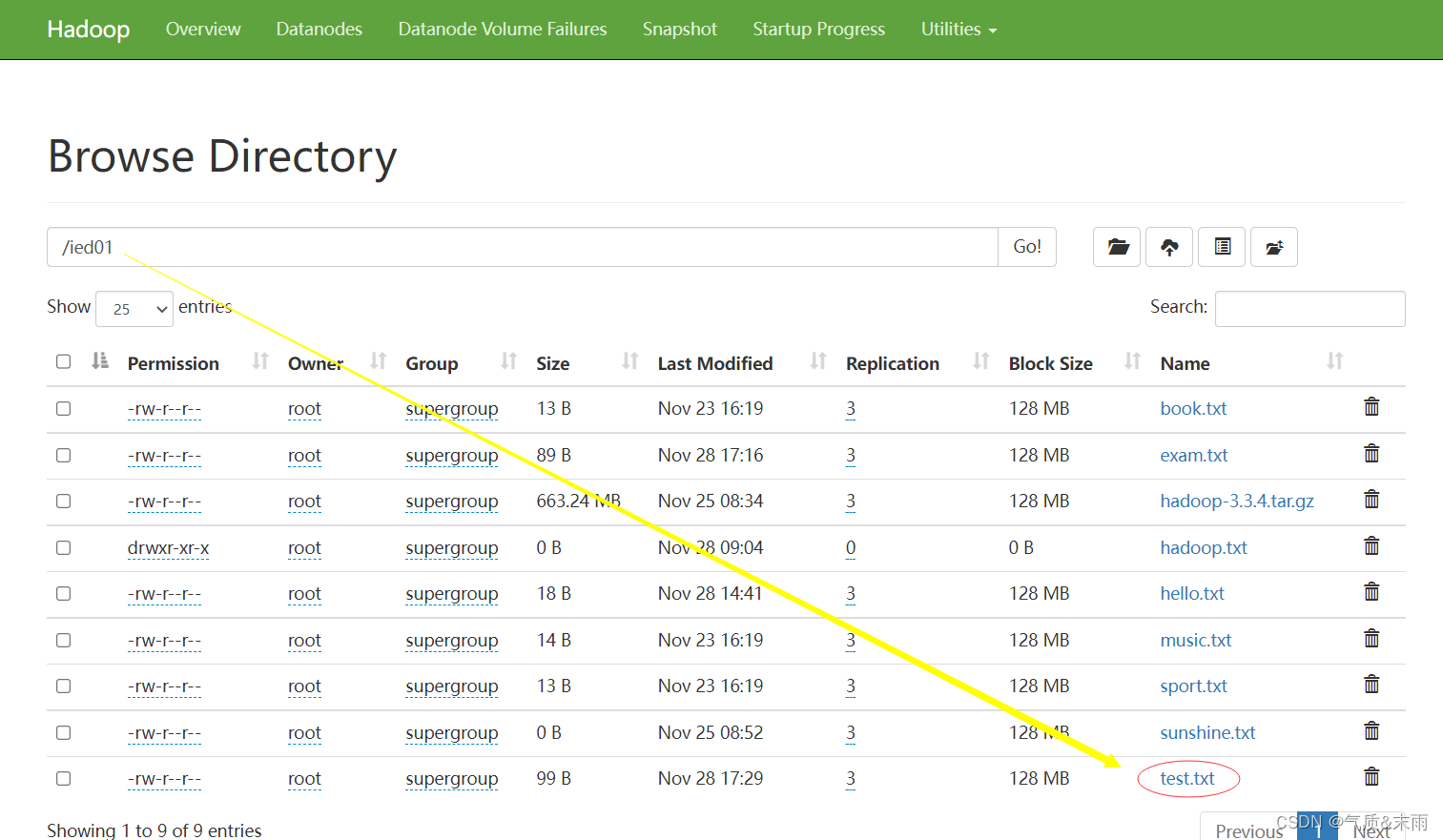
(1) 编写read1() 方法
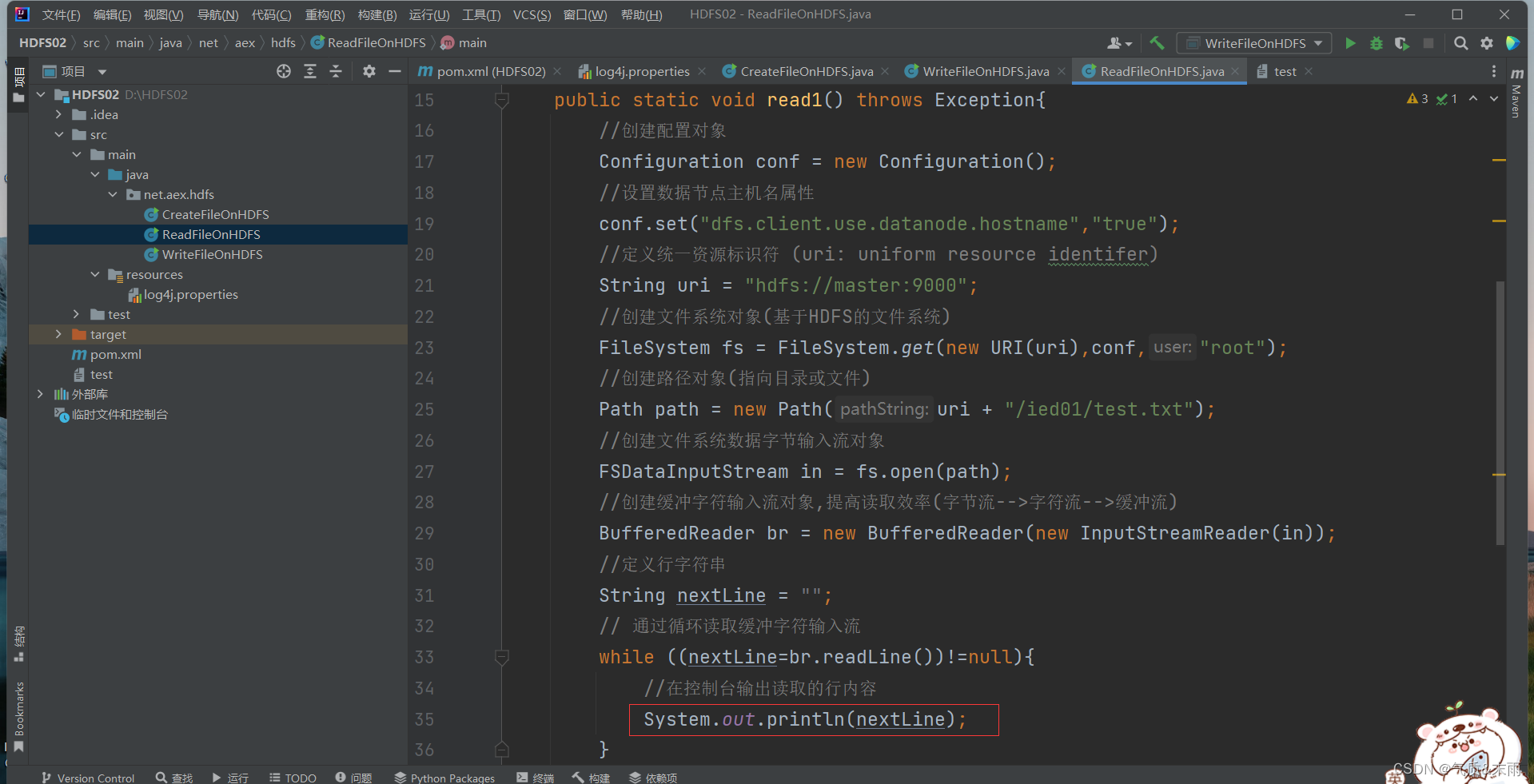
packagenet.aex.hdfs;importorg.apache.hadoop.conf.Configuration;importorg.apache.hadoop.fs.FSDataInputStream;importorg.apache.hadoop.fs.FSDataOutputStream;importorg.apache.hadoop.fs.FileSystem;importorg.apache.hadoop.fs.Path;importjava.io.BufferedReader;importjava.io.FileReader;importjava.io.InputStreamReader;importjava.net.URI;publicclassReadFileOnHDFS{publicstaticvoidread1()throwsException{//创建配置对象Configuration conf =newConfiguration();//设置数据节点主机名属性
conf.set("dfs.client.use.datanode.hostname","true");//定义统一资源标识符 (uri: uniform resource identifer)String uri ="hdfs://master:9000";//创建文件系统对象(基于HDFS的文件系统)FileSystem fs =FileSystem.get(newURI(uri),conf,"root");//创建路径对象(指向目录或文件)Path path =newPath(uri +"/ied01/test.txt");//创建文件系统数据字节输入流对象FSDataInputStream in = fs.open(path);//创建缓冲字符输入流对象,提高读取效率(字节流-->字符流-->缓冲流)BufferedReader br =newBufferedReader(newInputStreamReader(in));//定义行字符串String nextLine ="";// 通过循环读取缓冲字符输入流while((nextLine=br.readLine())!=null){//在控制台输出读取的行内容System.out.println(nextLine);}//关闭缓冲字符输入流
br.close();//关闭文件系统数据字节输入流
in.close();//关闭文件系统
fs.close();}publicstaticvoidmain(String[] args)throwsException{read1();}}
使用main方法调用 read1() 函数方法 查看结果 将
/ied01/test.txt
里的文件读取出来了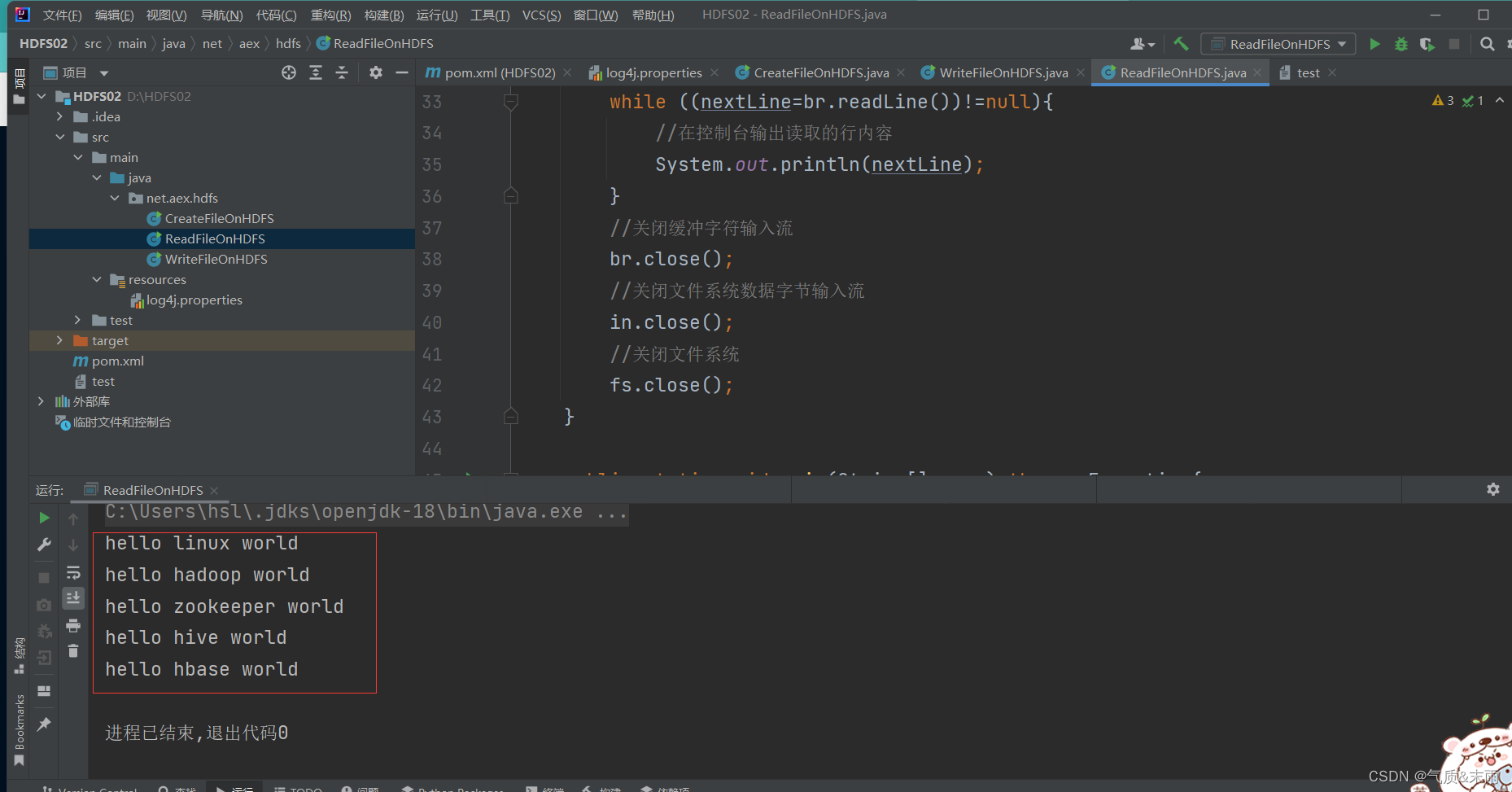
其实我们可以使用IOUtils类来简化代码,创建read_()函数方法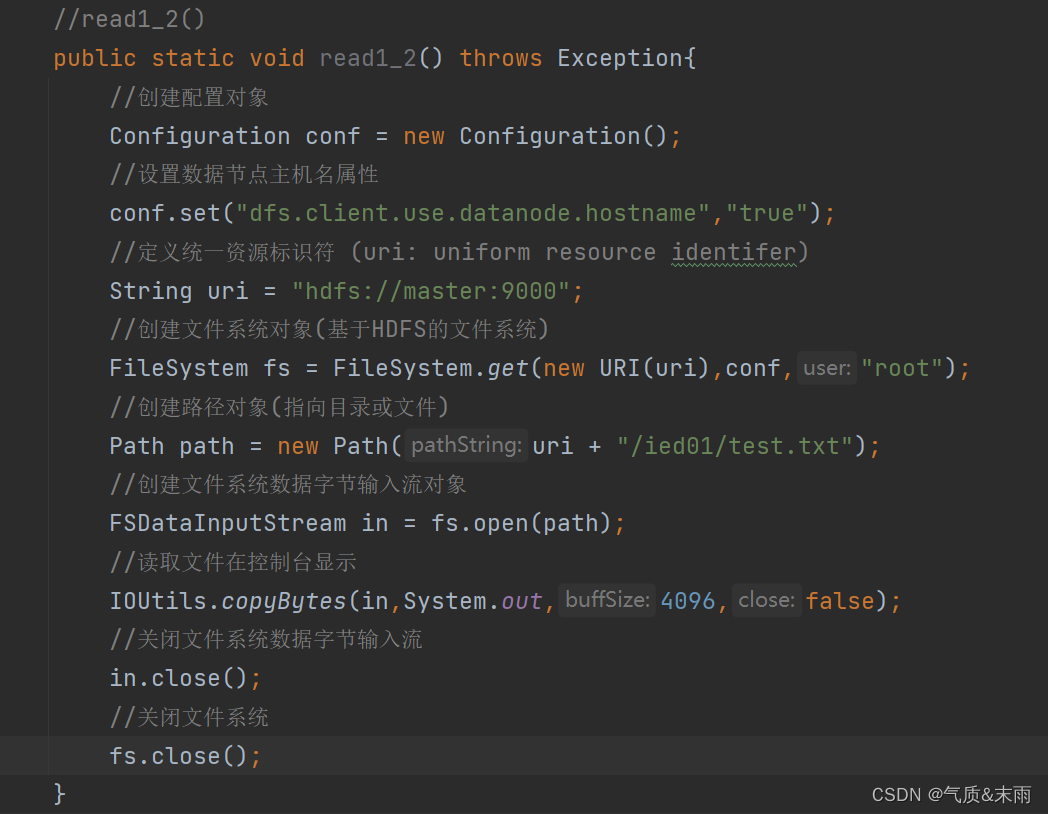
//read1_2()publicstaticvoidread1_2()throwsException{//创建配置对象Configuration conf =newConfiguration();//设置数据节点主机名属性
conf.set("dfs.client.use.datanode.hostname","true");//定义统一资源标识符 (uri: uniform resource identifer)String uri ="hdfs://master:9000";//创建文件系统对象(基于HDFS的文件系统)FileSystem fs =FileSystem.get(newURI(uri),conf,"root");//创建路径对象(指向目录或文件)Path path =newPath(uri +"/ied01/test.txt");//创建文件系统数据字节输入流对象FSDataInputStream in = fs.open(path);//读取文件在控制台显示IOUtils.copyBytes(in,System.out,4096,false);//关闭文件系统数据字节输入流
in.close();//关闭文件系统
fs.close();}
使用main方法,调用read1_2() 函数方法 查看结果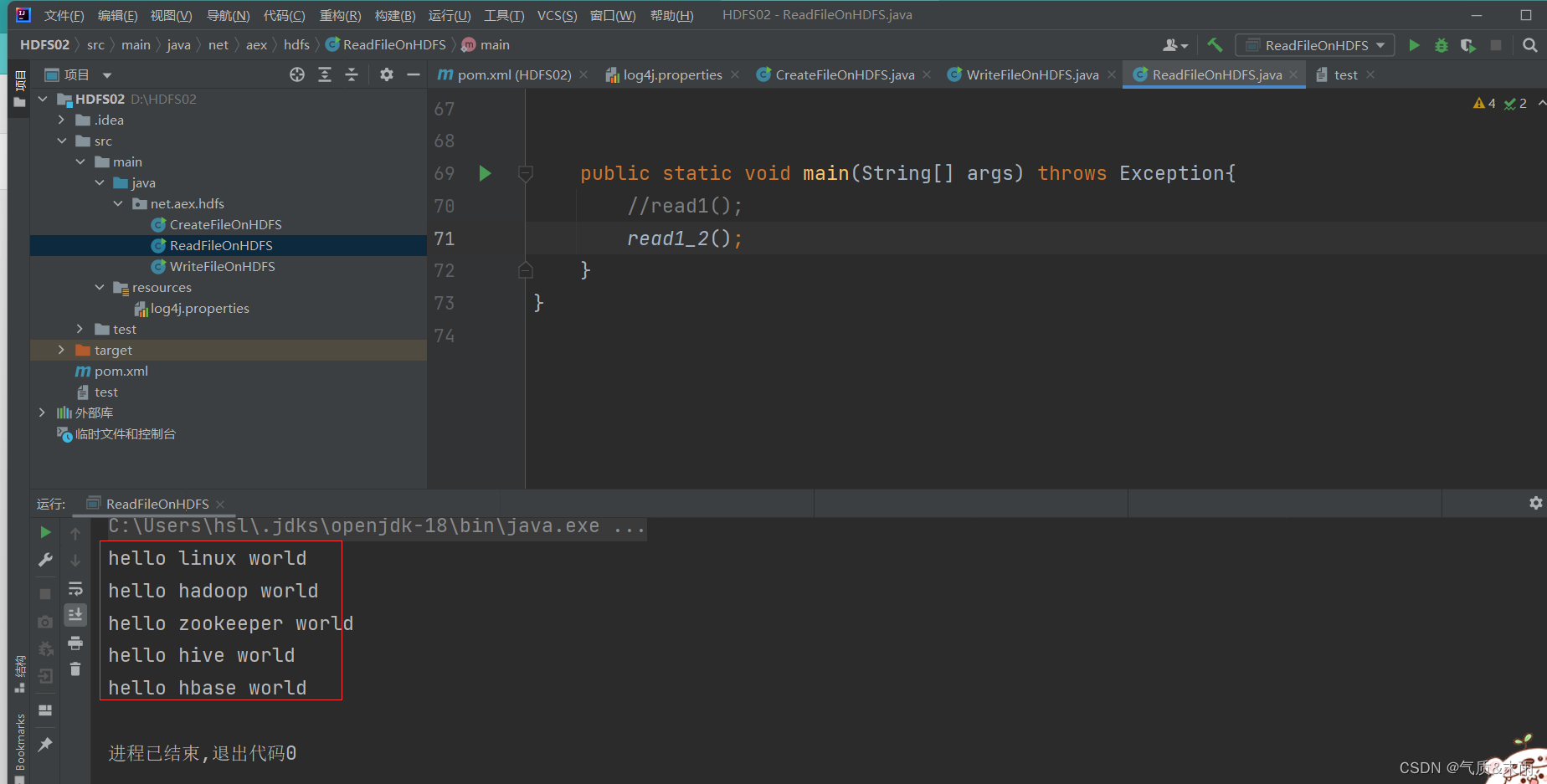
2) 读取HDFS文件,保存为本地文件
任务:将/ied01/test.txt 下载到项目下download目录里
(1) 创建
read2()
方法
//read2()publicstaticvoidread2()throwsException{//创建配置对象Configuration conf =newConfiguration();//设置数据节点主机名属性
conf.set("dfs.client.use.datanode.hostname","true");//定义统一资源标识符 (uri: uniform resource identifer)String uri ="hdfs://master:9000";//创建文件系统对象(基于HDFS的文件系统)FileSystem fs =FileSystem.get(newURI(uri),conf,"root");//创建路径对象(指向目录或文件)Path path =newPath(uri +"/ied01/test.txt");//创建文件系统数据字节输入流对象FSDataInputStream in = fs.open(path);//创建文件字节输出流FileOutputStream out =newFileOutputStream("D:\\HDFS02\\.idea\\download\\exam.txt");//读取HDFS文件(靠输入流),写入本地文件(靠输出流)IOUtils.copyBytes(in,out,conf);//关闭文件系统数据字节输入流
in.close();//关闭文件字节输出流
in.close();//关闭文件系统
fs.close();//提示用户文件下载成功System.out.println("文件["+path+"]下载到本地文件[download/exam.txt]!");}
使用main方法,调用read2()函数,查看结果 exam.txt 文件已经下载到本地的download目录下了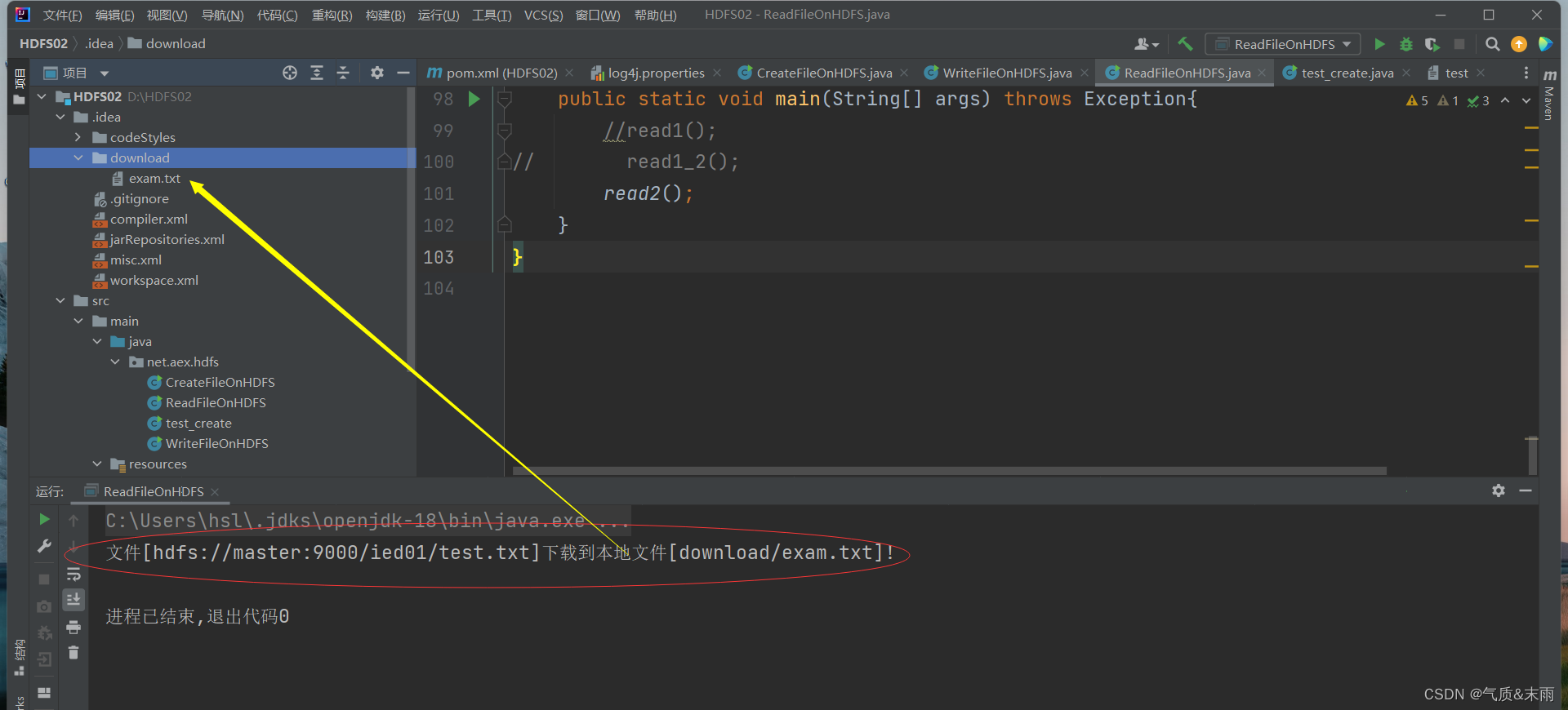
5、重命名目录或文件
1) 重命名目录
任务:将/ied01 目录更名为 /lzy01
(1) 编写
renameDir()
方法
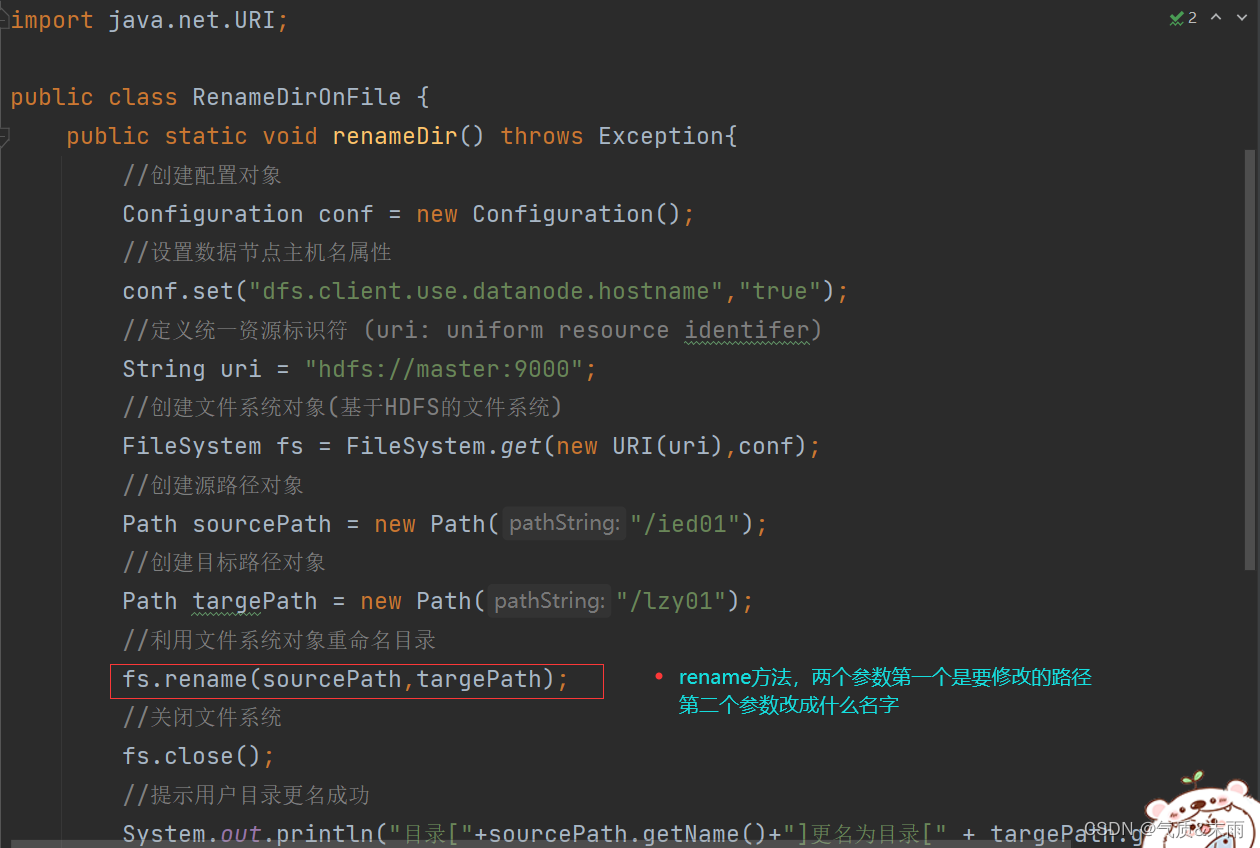
packagenet.aex.hdfs;importorg.apache.hadoop.conf.Configuration;importorg.apache.hadoop.fs.FileSystem;importorg.apache.hadoop.fs.Path;importjava.net.URI;publicclassRenameDirOnFile{publicstaticvoidrenameDir()throwsException{//创建配置对象Configuration conf =newConfiguration();//设置数据节点主机名属性
conf.set("dfs.client.use.datanode.hostname","true");//定义统一资源标识符 (uri: uniform resource identifer)String uri ="hdfs://master:9000";//创建文件系统对象(基于HDFS的文件系统)FileSystem fs =FileSystem.get(newURI(uri),conf);//创建源路径对象Path sourcePath =newPath("/ied01");//创建目标路径对象Path targePath =newPath("/lzy01");//利用文件系统对象重命名目录
fs.rename(sourcePath,targePath);//关闭文件系统
fs.close();//提示用户目录更名成功System.out.println("目录["+sourcePath.getName()+"]更名为目录["+ targePath.getName()+"]!");}publicstaticvoidmain(String[] args)throwsException{renameDir();}}
使用main方法调用renameDir()函数,查看结果 成功从/ied01 改为 lzy01
在webUI界面进行查看
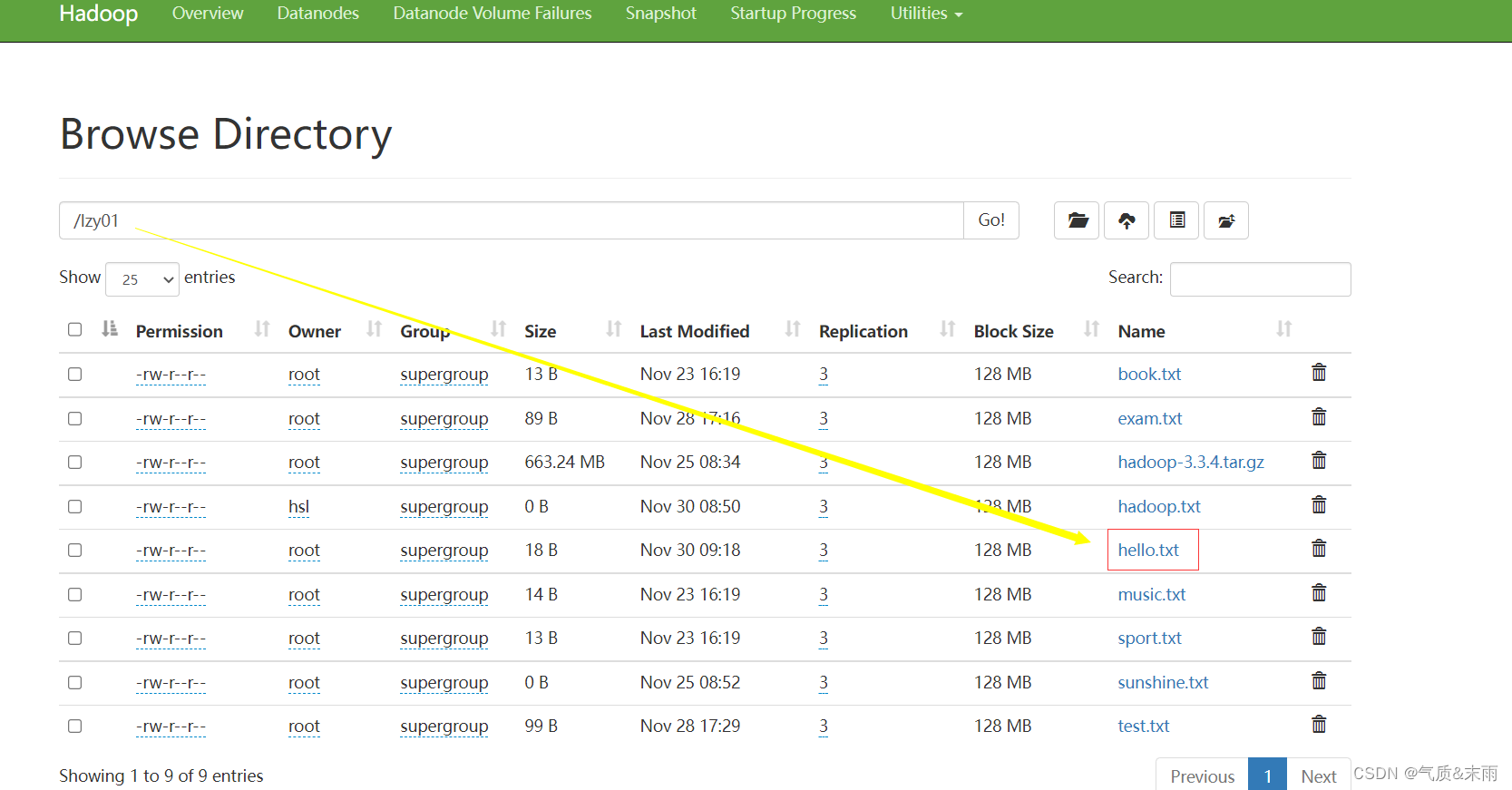
2) 重命名文件
任务:将
/lzy01
目录下的
hello.txt
重名为
hi.txt
(1)编写renameFile() 方法
主要需要两个对象的路径然后通过文件系统.rename()方法,把两个文件路径放进去进行更改
publicstaticvoidrenameFile()throwsException{//创建配置对象Configuration conf =newConfiguration();//定义统一资源标识符 (uri: uniform resource identifer)String uri ="hdfs://master:9000";//创建文件系统对象(基于HDFS的文件系统)FileSystem fs =FileSystem.get(newURI(uri),conf);//创建源路径对象Path sourcePath =newPath("/lzy01/hello.txt");//目标对象//创建目标路径对象(指向文件)Path targePath =newPath("/lzy01/hi.txt");//利用文件系统重命名文件
fs.rename(sourcePath,targePath);//关闭文件系统
fs.close();//提示用户更更名成功System.out.println("文件["+ sourcePath.getName()+"]更名文件["+ targePath.getName()+"]!");}
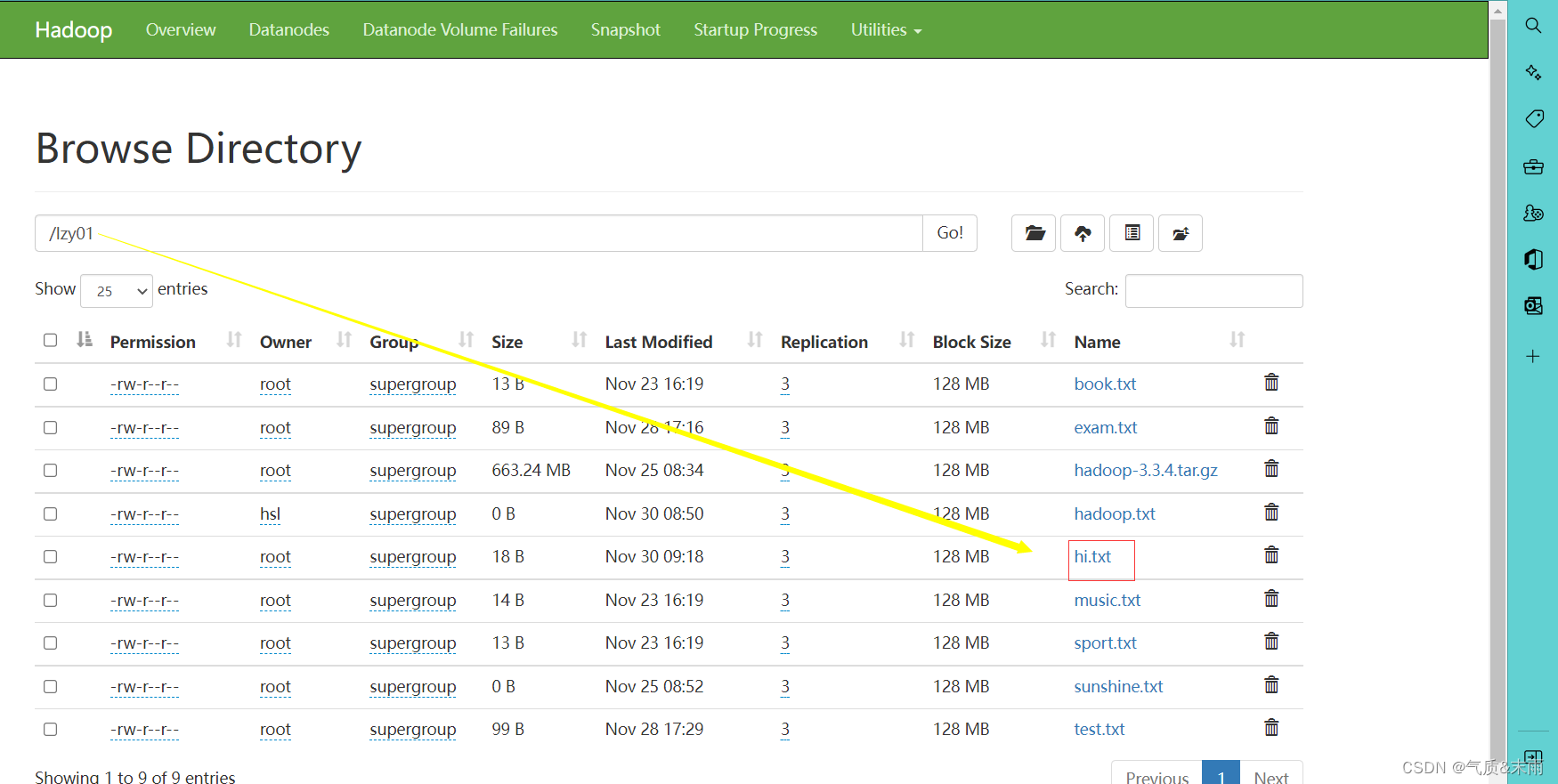
使用main方法调用
renameFile()方法
,查看结果 更名成功
6、显示文件列表
在
net.aex.hdfs
包里创建
ListHDFSFiles
类
1) 显示指定目录下文件全部信息
任务:显示
/lzy01
目录下的文件列表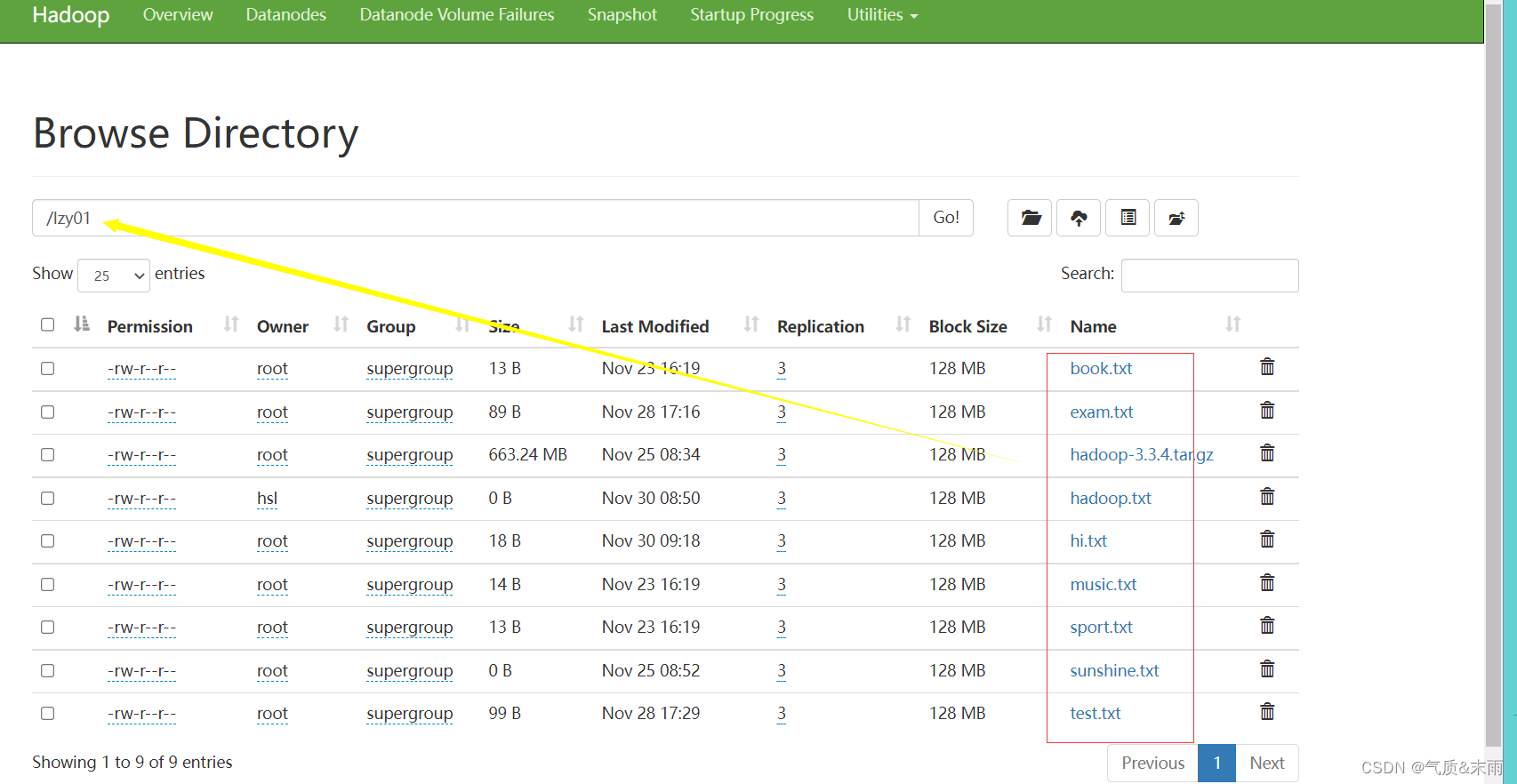
(1)、编写list1() 方法
packagenet.aex.hdfs;importjdk.jshell.execution.LoaderDelegate;importorg.apache.hadoop.conf.Configuration;importorg.apache.hadoop.fs.FileSystem;importorg.apache.hadoop.fs.LocatedFileStatus;importorg.apache.hadoop.fs.Path;importorg.apache.hadoop.fs.RemoteIterator;importjava.net.URI;publicclassListHDFSFile{publicstaticvoidlist1()throwsException{//设置配置对象Configuration conf =newConfiguration();//设置数据节点主机名属性
conf.set("dfs.client.use.datanode.hostname","true");//定义统一资源标识符 (uri: uniform resource identifer)String uri ="hdfs://master:9000";//创建文件系统对象(基于HDFS的文件系统)FileSystem fs =FileSystem.get(newURI(uri),conf,"root");//创建远程迭代器对象,泛型是位置文件状态类(相当于`hdfs dfs -ls -R /lzy01`)RemoteIterator<LocatedFileStatus> ri = fs.listFiles(newPath("/lzy01"),true);//遍历远程迭代器while(ri.hasNext()){System.out.println(ri.next());}}publicstaticvoidmain(String[] args)throwsException{list1();}}
使用main 方法,调用list1() 方法 查看结果 这些hdfs /lzy01 目录下的文件都读取出来了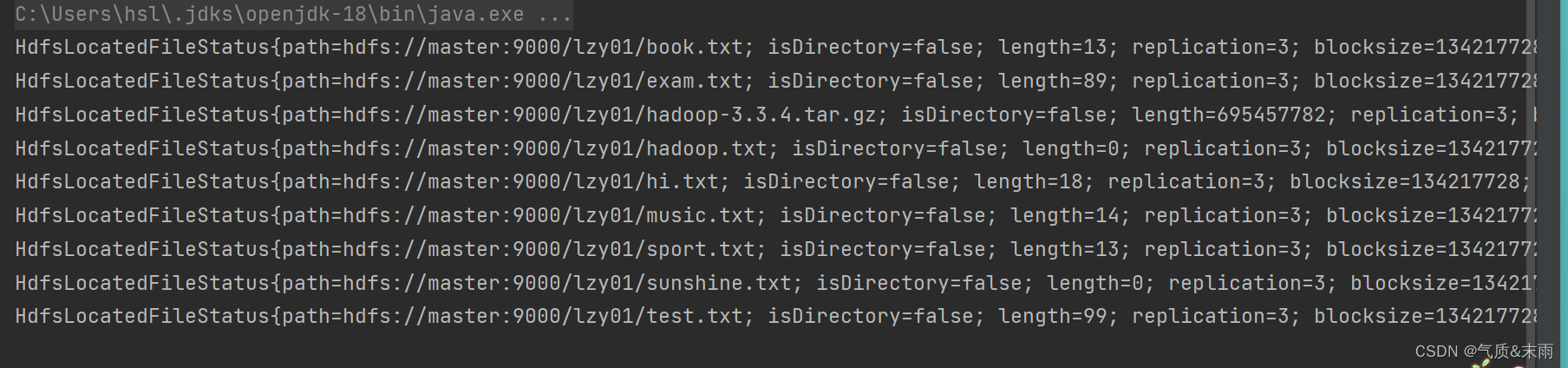 上述文件状态对象封装的有关信息,可以通过相应的方法来获取,比如getPath() 方法就可以获取路径信息,getLen()方法就可以获取文件长度信息
上述文件状态对象封装的有关信息,可以通过相应的方法来获取,比如getPath() 方法就可以获取路径信息,getLen()方法就可以获取文件长度信息
2) 显示指定目录下文件路径和长度信息
(1) 编写list2() 方法
//list2()publicstaticvoidlist2()throwsException{//创建配置对象Configuration conf =newConfiguration();//设置数据节点主机名属性
conf.set("dfs.client.use.datanode.hosename","true");//定义uri字符串String uri ="hdfs://master:9000";//创建文件系统对象FileSystem fs =FileSystem.get(newURI(uri),conf,"root");//创建远程迭代器对象,泛型是位置文件状态类(相当于`hdfs dfs -ls -R /lzy01`)RemoteIterator<LocatedFileStatus> ri = fs.listFiles(newPath("/lzy01"),true);//遍历远程迭代器while(ri.hasNext()){LocatedFileStatus lfs = ri.next();System.out.println(lfs.getPath()+""+ lfs.getLen()+"字节");}}
使用main方法调用list2() 方法,查看结果 /lzy01目录下的文件的字节都显示出来了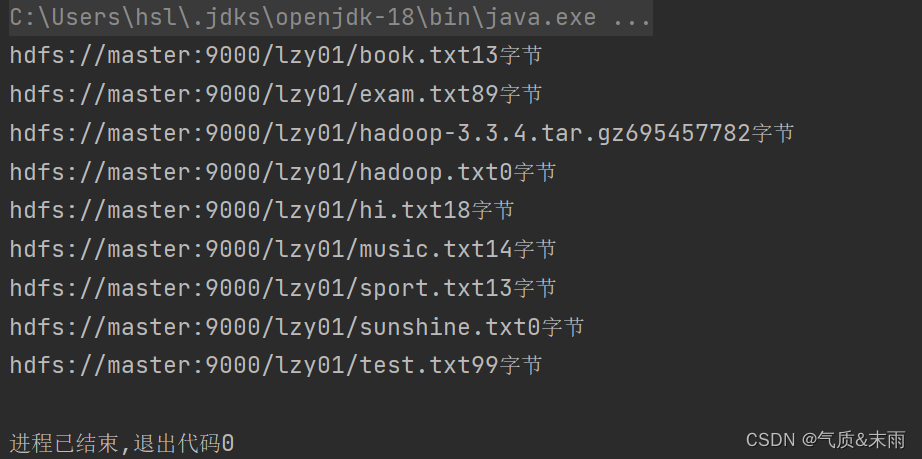
7、获取文件块信息
任务:获取
/lzy01/hadoop-3.3.4.tar.gz
文件块信息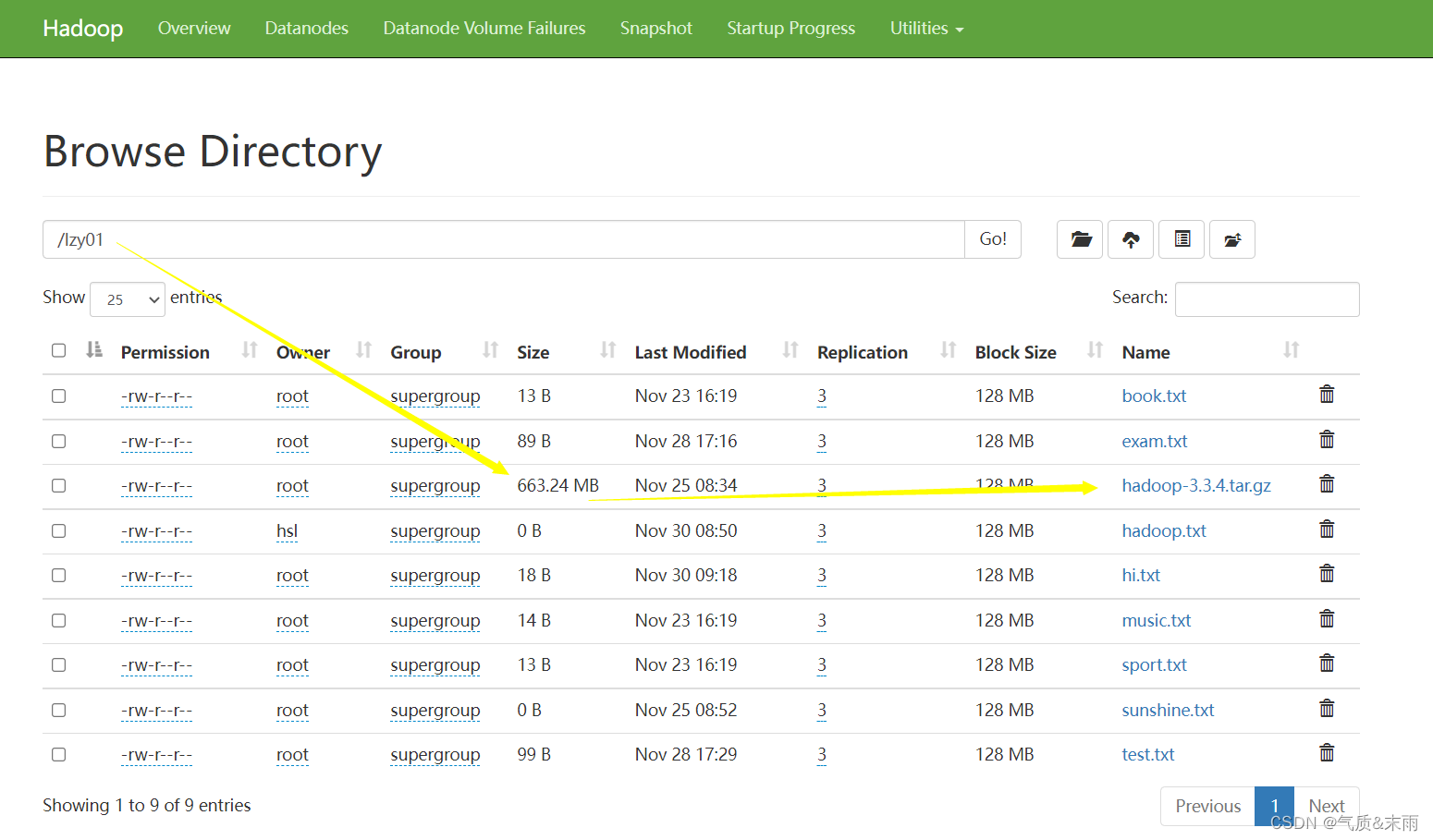
hadoop压缩包会分割成6个文件块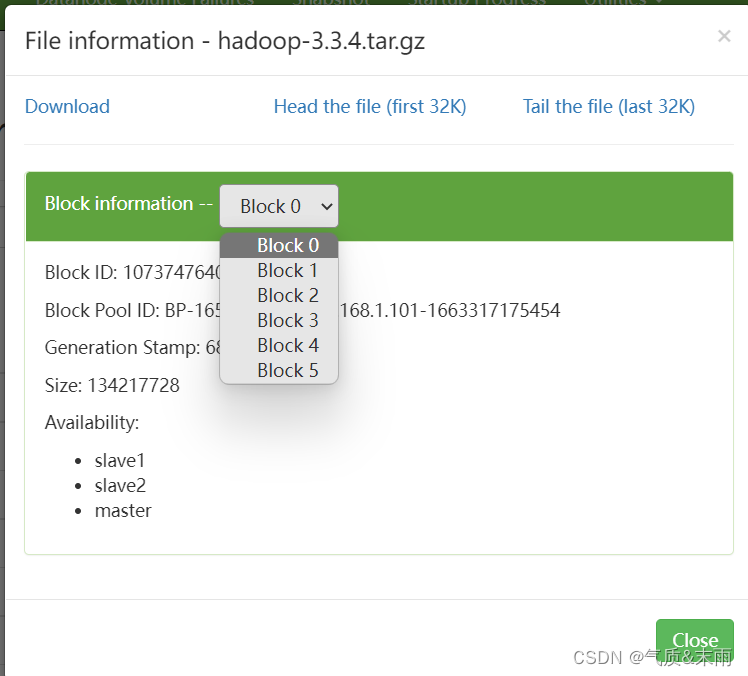
在
net.aex.hdfs
包里创建
GetBlockLocations
类
版权归原作者 气质&末雨 所有, 如有侵权,请联系我们删除。