
第一章 ES简介
第1节 ES介绍
1
2
3
4
1、Elasticsearch是一个基于Lucene的搜索服务器
2、提供了一个分布式的全文搜索引擎,基于restful web接口
3、Elasticsearch是用Java语言开发的,基于Apache协议的开源项目,是目前最受欢迎的企业搜索引擎
4、Elasticsearch广泛运用于云计算中,能够达到实时搜索,具有稳定,可靠,快速的特点
第2节 ES版本
- 版本历史
1``````ES : 1.x ---> 2.x ---> 5.x ---> 6.x --->7.x(目前) - 版本选择
1``````在版本选择一般选择5.x版本以上,我们本课程的学习使用6.x版本,低版本会随着官网的不断推动,在未来可能就不维护了,所以在选择的时候要尽量选择目前来说一个长期的稳定版本
第二章 安装(v6.3.2)
第1节 window下单点安装ES
- 下载地址
123456``````官网地址:https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.3.1.zip华为镜像站:https://mirrors.huaweicloud.com/elasticsearch/6.3.2/elasticsearch-6.3.2.zip - 安装步骤
123``````1、将下载的安装包解压到指定目录下(不能有中文)2、找到目录下的bin目录(比如: D:\soft\elasticsearch-6.3.2\bin)3、bin目录下有一个[elasticsearch.bat]脚本命令,直接鼠标双击即可,启动ES服务 - 访问
12345678910111213141516171819``````ES服务的默认端口号为 9200,在浏览器访问 http://localhost:9200/ 浏览器就会输出下面信息,安装成功{ "name" : "G7lh1eQ", "cluster_name" : "elasticsearch", "cluster_uuid" : "4T38-ecWQ5O8OpIM3RibAw", "version" : { "number" : "6.3.2", "build_flavor" : "default", "build_type" : "zip", "build_hash" : "053779d", "build_date" : "2018-07-20T05:20:23.451332Z", "build_snapshot" : false, "lucene_version" : "7.3.1", "minimum_wire_compatibility_version" : "5.6.0", "minimum_index_compatibility_version" : "5.0.0" }, "tagline" : "You Know, for Search"}
第2节 window下安装Head插件
2.1 Head插件介绍
1
是一款能连接ES,并提供对ES进行操作的可视化界面
2.2 Head插件下载地址
1
https://github.com/mobz/elasticsearch-head/archive/master.zip
2.3 安装步骤
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
1. 电脑首先要安装node.js,因为安装Head插件需要使用npm命令
注意: 由于npm命令使用的是国外的镜像库,所以可能会很慢或者发生失败的情况,可以有两种方式解决
方式一: 切换镜像地址
-- 查看当前npm的镜像地址: npm config get registry
-- 默认地址为: https://registry.npmjs.org/
-- 将默认镜像地址设置成淘宝的地址: npm config set registry https://registry.npm.taobao.org
方式二: 使用cnpm
-- 下载cnpm并且同时设置镜像源命令 npm install cnpm -g --registry=https://registry.npm.taobao.org
-- 使用cnpm -v查看
-- 以后使用cnpm 命令安装依赖
2. nodejs安装好之后,那么开始解压head插件压缩包
3. 切换到解压文件目录下 D:\soft\elasticsearch-head-master,我的解压到了d盘soft目录下
4. 使用cmd命令行工具切换到解压目录下,执行命令 npm install 安装
5. 安装完成之后启动head插件 npm run start 这时候就会在在计算机9100端口号上启动服务
6. 在浏览器访问,在浏览器中输入 http://localhost:9100/ 访问
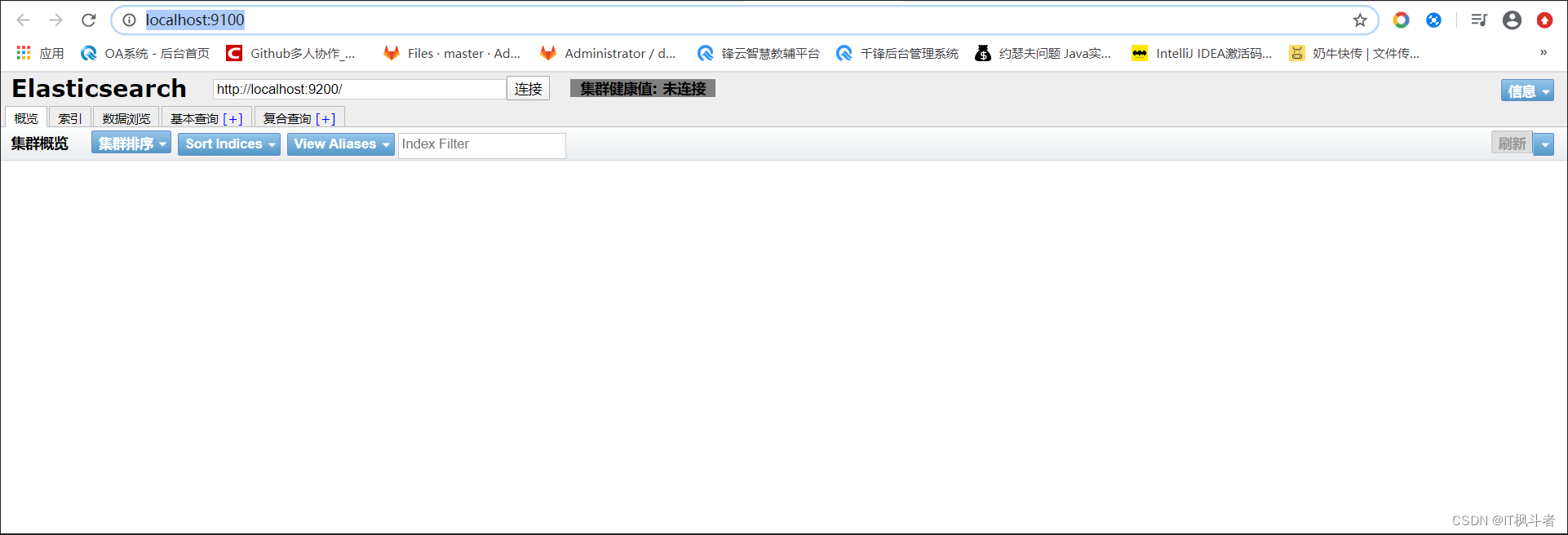
2.4 Head插件和ES关联配置
1
因为两个服务之间可能ip地址和端口号不同造成跨域的问题,所以需要配置可以跨域
- 修改ES的配置文件
12345678``````1、因为ES和Head插件之间是两个不同的服务,所以需要进行配置 - 1.1 修改ES的配置,找到我们的ES配置文件 elasticsearch-6.3.2\config\elasticsearch.yml - 1.2 在文件的最后一行设置一个可以进行跨域访问的属性 http: cors: enabled: true allow-origin: "*" - 1.3 重启ES服务,重启Head服务
第3节 window ES 集群安装
3.1 集群配置步骤
1
2
3
4
1. 创建一个elasticsearch-cluster文件夹
2. 解压我们的elasticsearch-6.3.2.zip压缩包到elasticsearch-cluster目录下
3. 分别命名为 elasticsearch-node01,elasticsearch-node02,elasticsearch-node03
4. 修改配置文件
3.2 配置文件编写
- elasticsearch-node01节点配置文件
1234567891011121314151617``````# 集群名称,保证唯一cluster.name: elasticsearch# 节点名称,每个节点不能相同node.name: node-01# 本机的ip地址network.host: 127.0.0.1# 服务端口号,在同一机器下端口号不能相同http.port: 9200# 集群间通信端口号,在同一机器下端口号不能相同transport.tcp.port: 9300# 设置集群自动发现机器ip集合discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"]# 跨域调用http: cors: enabled: true allow-origin: "*" - elasticsearch-node02节点配置文件
1234567891011121314151617``````# 集群名称,保证唯一cluster.name: elasticsearch# 节点名称,每个节点不能相同node.name: node-02# 本机的ip地址network.host: 127.0.0.1# 服务端口号,在同一机器下端口号不能相同http.port: 9201# 集群间通信端口号,在同一机器下端口号不能相同transport.tcp.port: 9301# 设置集群自动发现机器ip集合discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"]# 跨域调用http: cors: enabled: true allow-origin: "*" - elasticsearch-node03节点配置文件
1234567891011121314151617``````# 集群名称,保证唯一cluster.name: elasticsearch# 节点名称,每个节点不能相同node.name: node-03# 本机的ip地址network.host: 127.0.0.1# 服务端口号,在同一机器下端口号不能相同http.port: 9202# 集群间通信端口号,在同一机器下端口号不能相同transport.tcp.port: 9302# 设置集群自动发现机器ip集合discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"]# 跨域调用http: cors: enabled: true allow-origin: "*"``````123456``````重启各个节点注意: 如果在重启各个节点时出现点击启动脚本闪退的问题,可能造成的原因是配置文件需要使用UTF-8编码的格式编写解决方式,使用notepad++修改当前配置文件的编码格式为utf-8重启Head服务
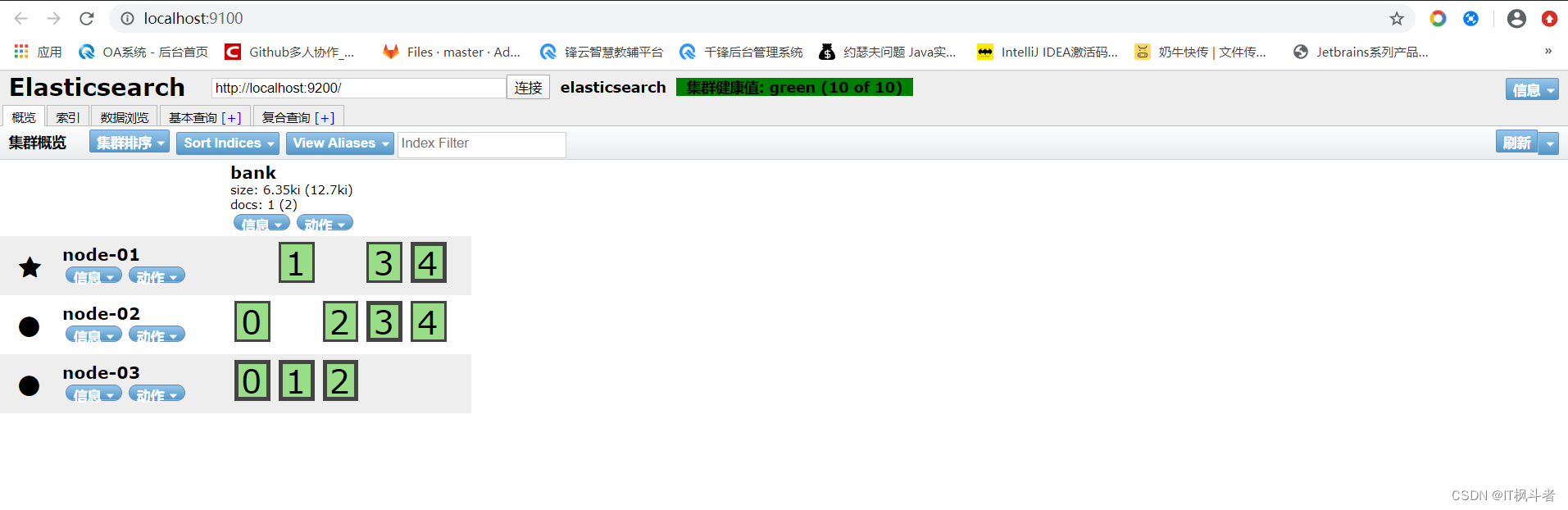
1
2
1. 图中黑色的粗框代表这分片
2. 细的黑框代表着副本
第三章 基础概念
第1节 索引
1
含有相同属性的文档集合,相当于我们MYSQL数据库中的数据库(DATABASE)
第2节 类型
1
索引可以定义一个或多个类型(ES6中已经逐步弃用,在更高的7版本中已经删除),文档必须属于一个类型,相当于我们MYSQL中的一个表(TABLE)
第3节 文档
1
文档是可以被索引的基本数据单位,相当于MYSQL数据库表中的一行记录
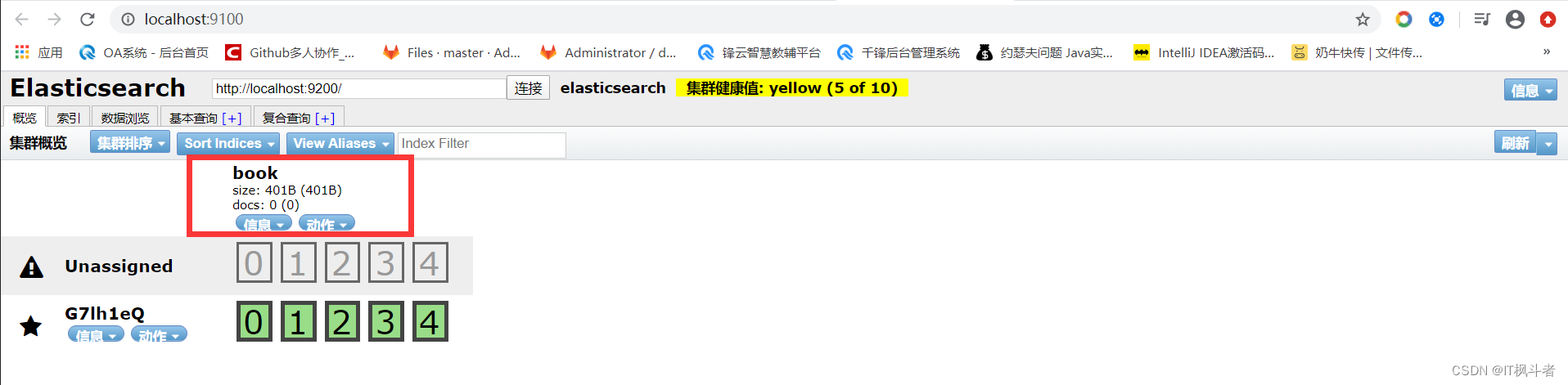
第4节 分片/副本(备份)
- 分片(shard)
12345``````1. 每个索引有一个或多个分片2. 索引的数据被分配到各个分片上,相当于一桶水使用多个杯子去装,分片有助于横向扩展3. 如果将大量的数据保存到一个分片里面,那么分片越来越大数据越来越多,查找性能越来越差4. 默认情况下一个索引创建5个分片5. 分片会默认的分配到es集群的各个节点上,集群自动完成 - 副本(replica)
123``````1. 副本,可以理解为分片的备份2. 主分片和副本(备分片)不会出现在同一个节点上(防止单点故障)默认情况下一个索引创建5个分片一个备份(5个主分片+5个副本分片=10个分片)3. 如果只有一个es节点,那么replica就无法分配(因为主/副不能同在一个节点上),此时cluster status会变成Yellow
第四章 基本用法
第1节 ES 的 RESTFul API
- API的基本格式
1``````http://<ip>:<port>/<索引>/<类型>/<文档id> - 常用的HTTP动作
1``````GET/POST/PUT/DELETE
第2节 创建索引
2.1 使用Head插件创建索引
- 创建索引的步骤
12345``````1. 登陆Head页面2. 找到索引标签3. 新建索引4. 添加索引名称(英文,全部都是小写字母,不能用下划线开头)5. 索引创建成功之后回到概览页面就会在上面发现我们新建的索引 - Head页面展示
2.2 结构化索引/非结构化索引
- 结构化和非结构化介绍
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
进入我们的Head界面,进入概览,点击索引名称下面的信息,点击索引信息,查看数据里面有一个mappings属性,内容为空,说明我们此索引为非结构化索引
{
"state": "open",
"settings": {
"index": {
"creation_date": "1597547149325",
"number_of_shards": "5",
"number_of_replicas": "1",
"uuid": "UvYCPtp0TZeCiPexCT517g",
"version": {
"created": "6030299"
},
"provided_name": "book"
}
},
"mappings": {},
"aliases": [],
"primary_terms": {
"0": 1,
"1": 1,
"2": 1,
"3": 1,
"4": 1
},
"in_sync_allocations": {
"0": [
"BHBNGrGCSiOl-wuKptvGtQ"
],
"1": [
"yMyL9GsMR9SziVr9OK_Uxw"
],
"2": [
"b8EGEtGlTySAqvlKPtW_EA"
],
"3": [
"0azU6MwTSCqMdzVXyuPVrw"
],
"4": [
"DY2oxeUuSNaxva5dgKTSAg"
]
}
}
- 结构化和非结构化转化
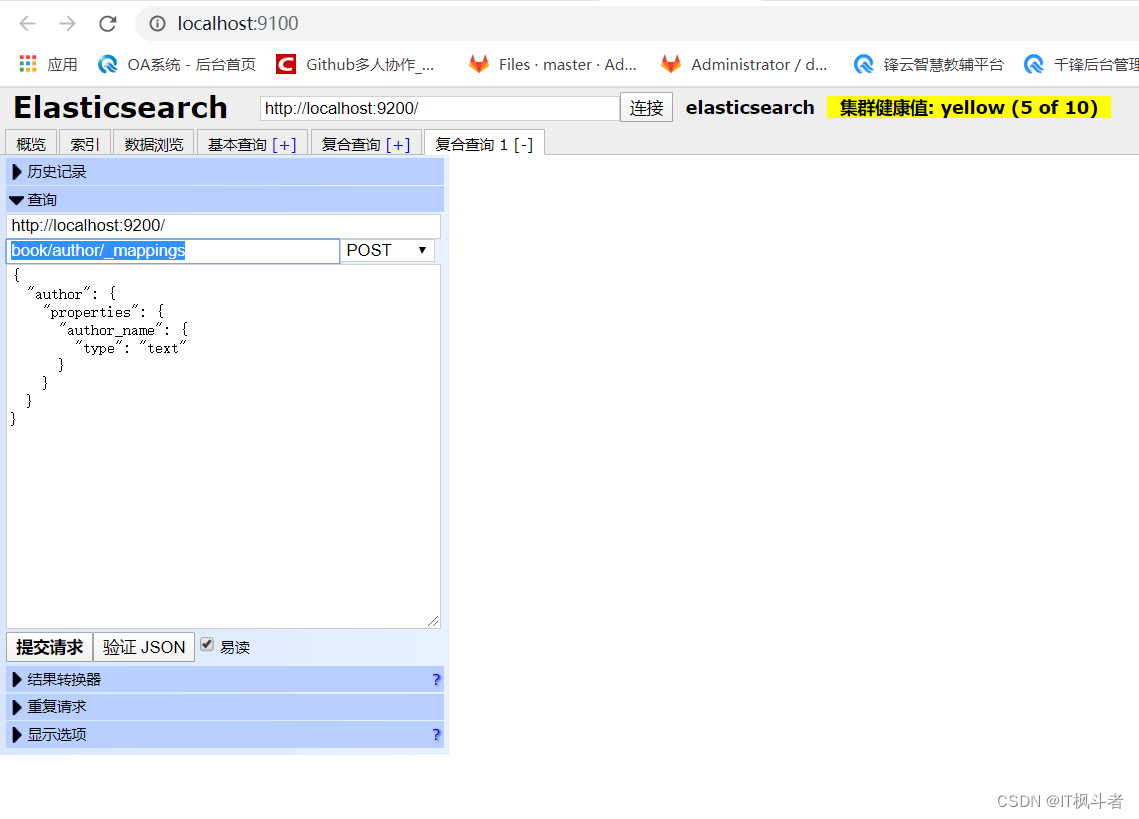
12``````1、在当前的head页面中点击【复合查询】2、调用ES的API构建一个请求url``````1``````我这里给book索引添加一个author类型,使用_mappings关键字(ES给索引、类型、文档等起名字时不能以下划线开头,因为ES中很多关键字都是以下划线开头的)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
3、给上面的非结构化索引添加一些结构化的数据,让他变成结构化索引
点击易读,点击验证json,防止自己写的json数据有问题,点击提交请求
properties: 关键字,设置属性
type: 关键字,设置属性类型
{
"author": {
"properties": {
"author_name": {
"type": "text"
}
}
}
}
4、添加成功标志
{
"acknowledged": true
}
5、在进入概览点击索引信息查看数据(mappings中就有了机构化数据)
{
"state": "open",
"settings": {
"index": {
"creation_date": "1597547149325",
"number_of_shards": "5",
"number_of_replicas": "1",
"uuid": "UvYCPtp0TZeCiPexCT517g",
"version": {
"created": "6030299"
},
"provided_name": "book"
}
},
"mappings": {
"author": {
"properties": {
"author_name": {
"type": "text"
}
}
}
},
"aliases": [],
"primary_terms": {
"0": 1,
"1": 1,
"2": 1,
"3": 1,
"4": 1
},
"in_sync_allocations": {
"0": [
"BHBNGrGCSiOl-wuKptvGtQ"
],
"1": [
"yMyL9GsMR9SziVr9OK_Uxw"
],
"2": [
"b8EGEtGlTySAqvlKPtW_EA"
],
"3": [
"0azU6MwTSCqMdzVXyuPVrw"
],
"4": [
"DY2oxeUuSNaxva5dgKTSAg"
]
}
}
2.3 使用postman创建索引
1
Head在进行结构化数据创建的时候,验证json数据格式比较麻烦,我们可以使用postman进行结构化数据创建
- 使用postman创建索引

- postman创建索引的请求数据
1234567891011121314151617181920212223242526272829303132``````{ "settings":{ "number_of_shards":5, "number_of_replicas":1 }, "mappings":{ "man":{ "properties":{ "name":{ "type":"text" }, "country":{ "type":"keyword" }, "age":{ "type":"integer" }, "date":{ "type":"date", "format":"yyyy-MM-dd HH:mm:ss || yyyy-MM-dd || epoch_millis" } } } }}-----------------------------参数变量的简单介绍----------------------------------settings : 设置当前索引的基本信息mappings : 结构化索引配置format : 时间格式epoch_millis : 时间戳(毫秒数) - head页面查看创建结果
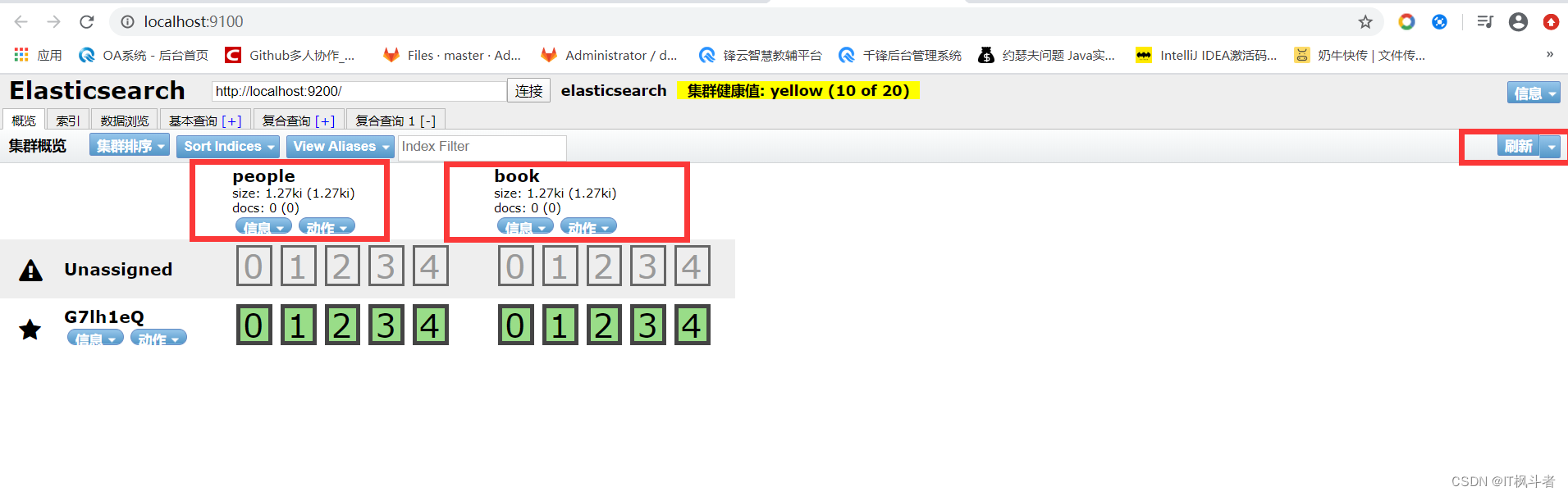
第3节 数据插入(postman)
3.1 指定id插入
- 请求地址
1``````http://localhost:9200/people/man/1 - 请求图例
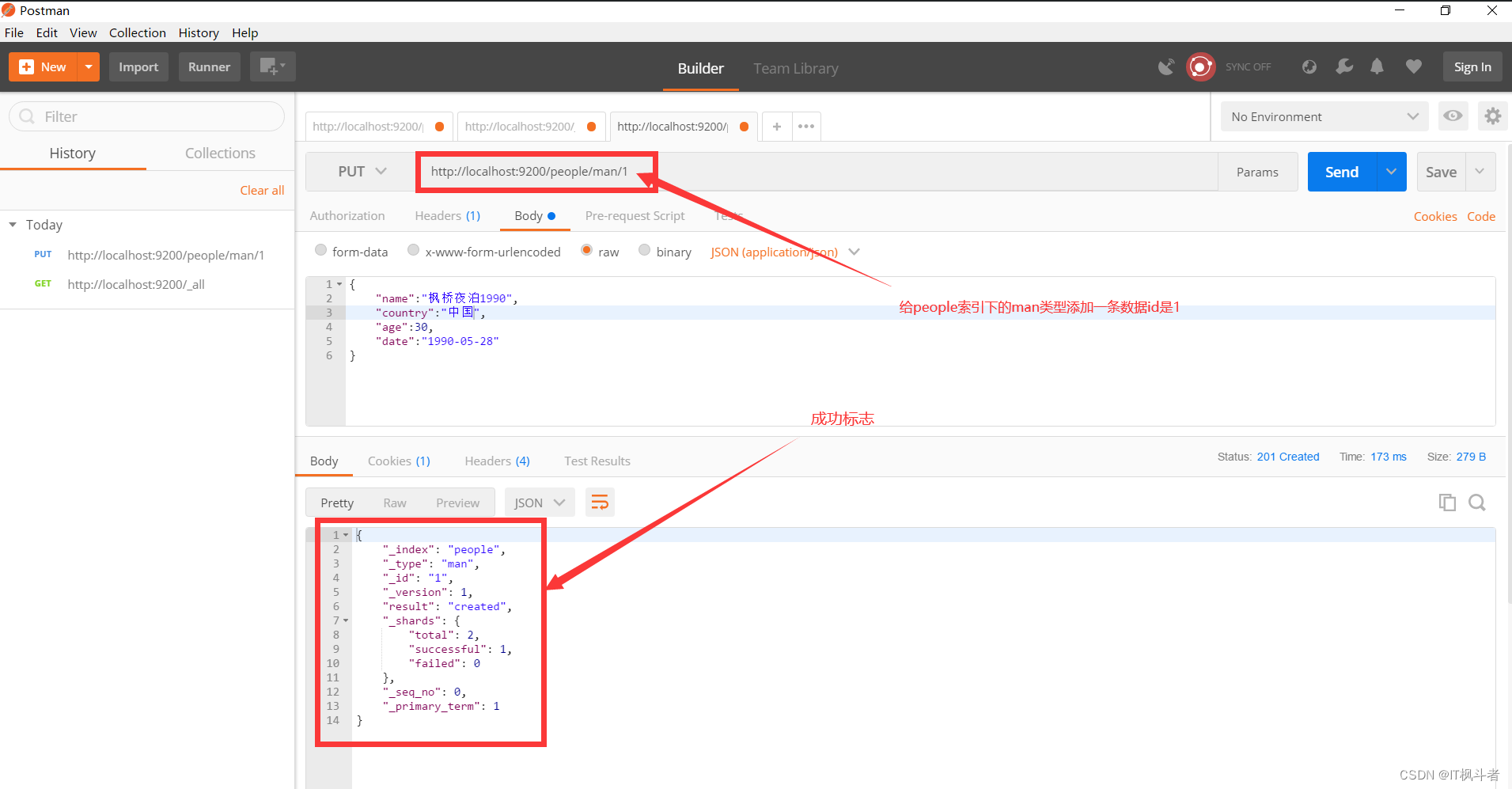
- 添加数据
123456``````{ "name":"1990", "country":"中国", "age":30, "date":"1990-05-28"} - 返回结果数据
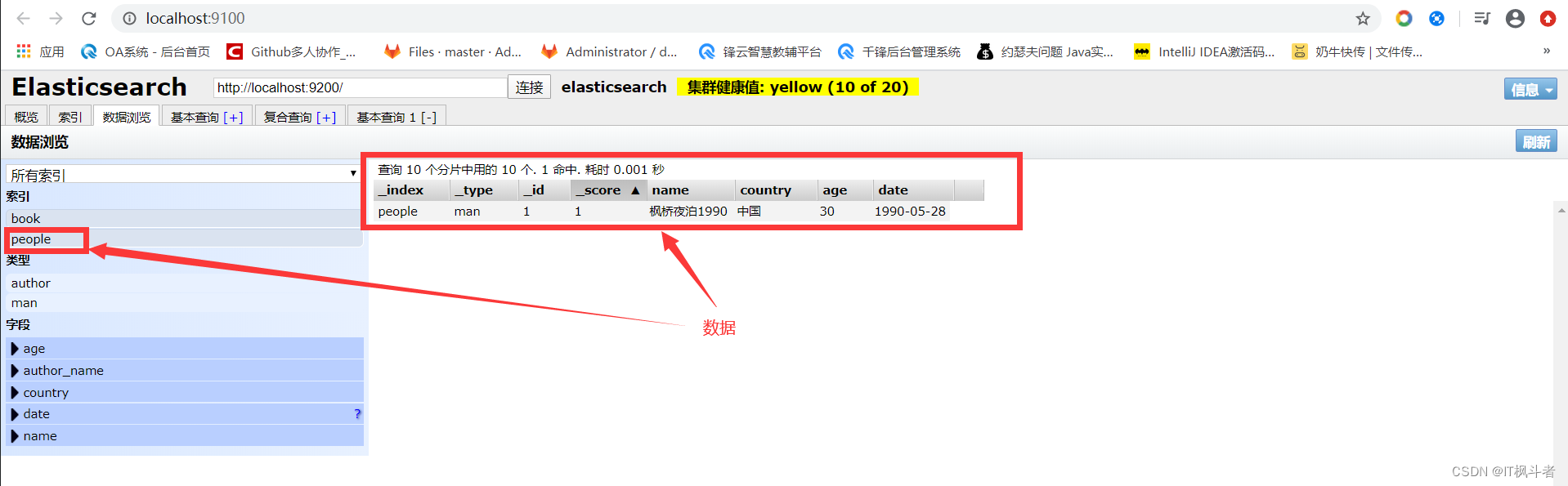
1234567891011121314``````{ "_index": "people", "_type": "man", "_id": "1", "_version": 1, "result": "created", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "_seq_no": 0, "_primary_term": 1} - head查看

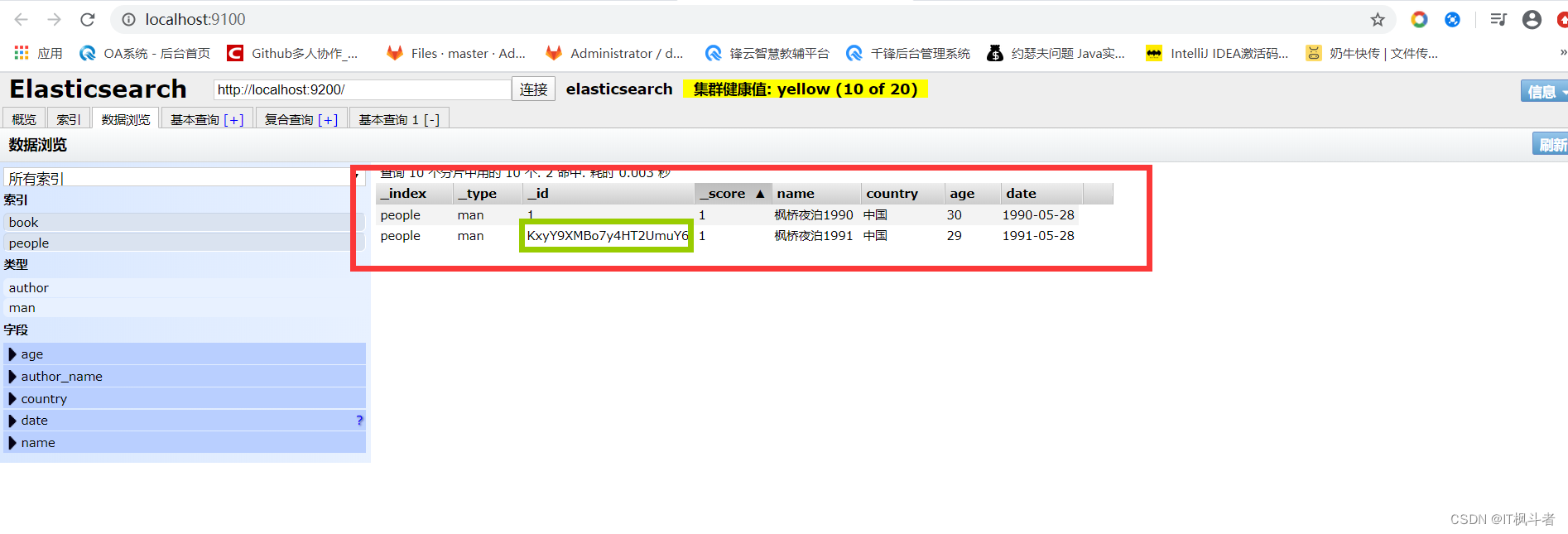
3.2 自动生成id插入
- 请求地址
1``````http://localhost:9200/people/man/ - 请求图例
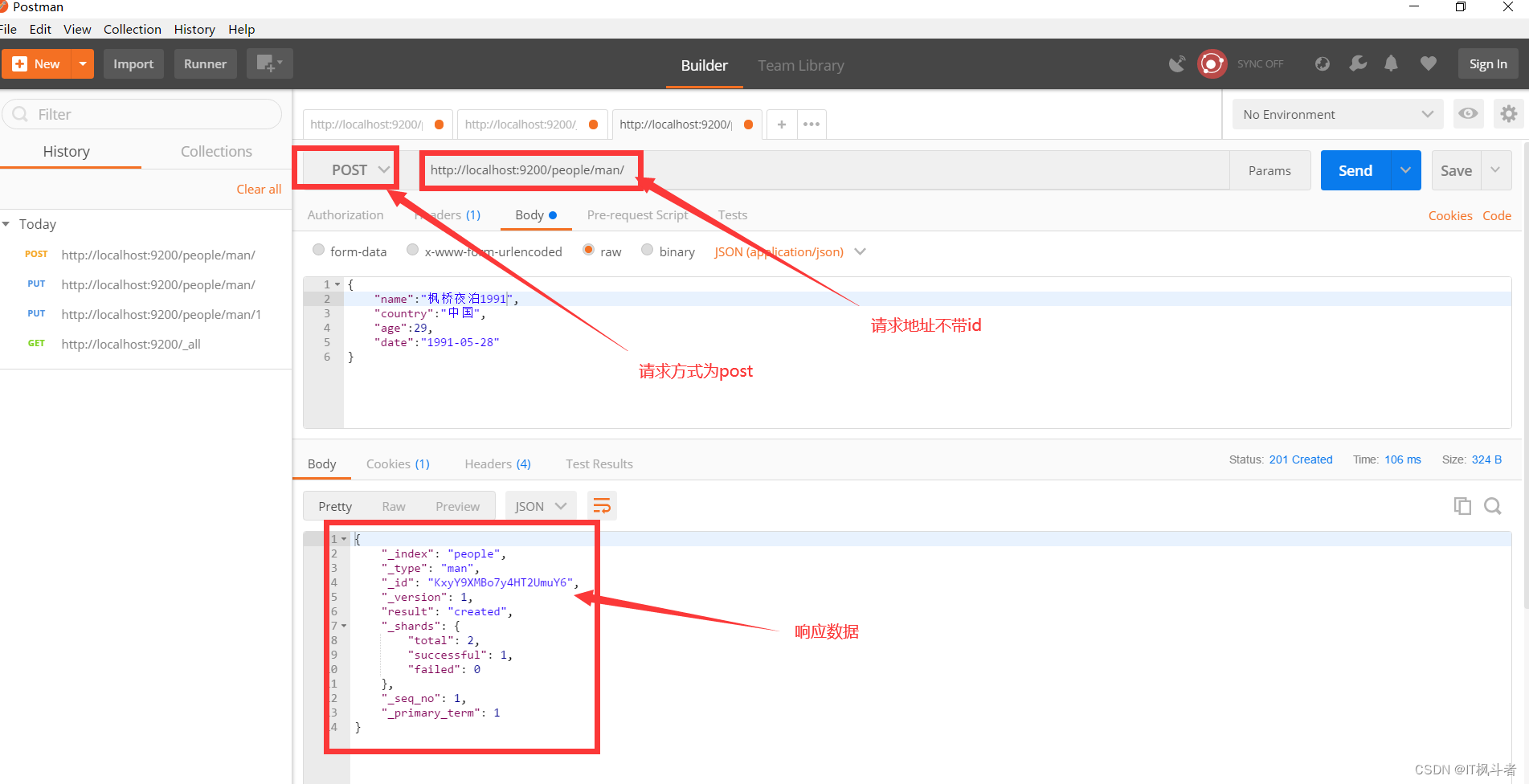
- head查看
第4节 数据修改(postman)
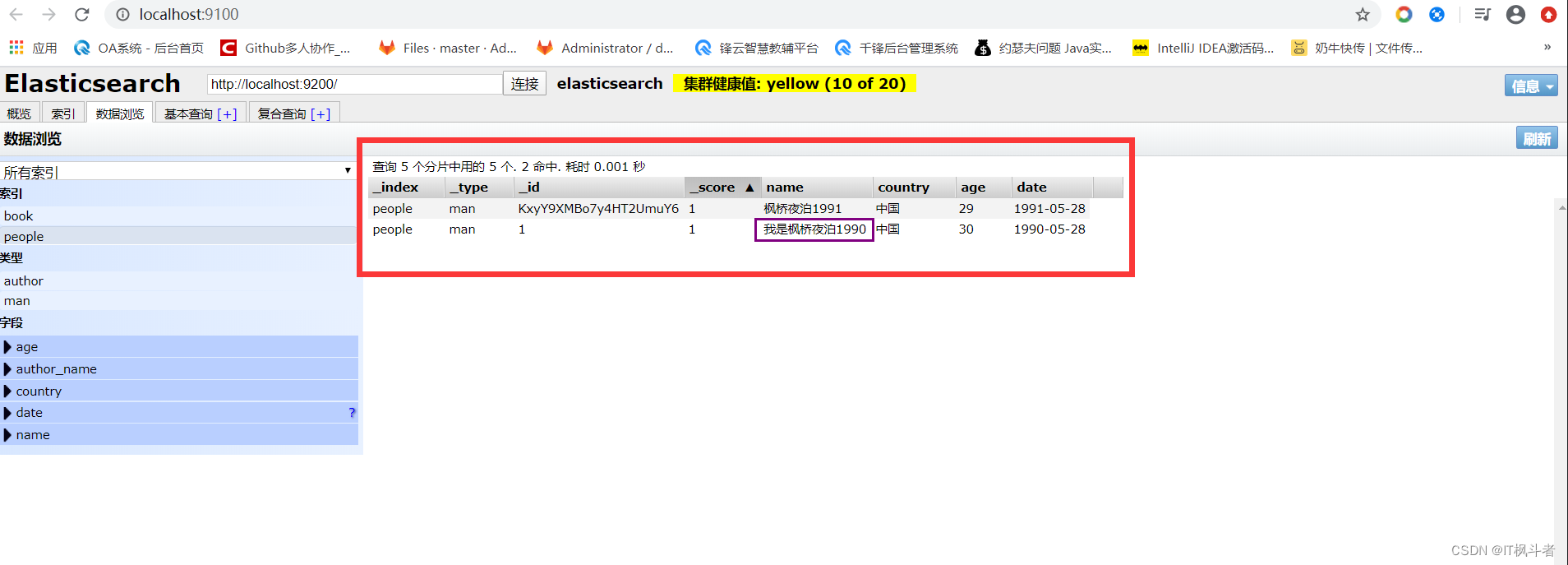
4.1 直接修改文档
- 请求地址
1``````http://localhost:9200/people/man/1/_update - 请求参数
12345``````{ "doc":{ "name":"1990" }} - 请求图例

- 响应数据
1234567891011121314``````{ "_index": "people", "_type": "man", "_id": "1", "_version": 2, "result": "updated", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "_seq_no": 2, "_primary_term": 1} - head查看
4.2 使用脚本修改文档(了解)
4.2.1 Painless简介
1
2
1. Painless 是默认情况下 Elasticsearch 中提供的一种简单,安全的脚本语言
2. 它专门设计用于 Elasticsearch,可以安全地使用内联和存储的脚本,默认情况下启用
4.2.2 Painless使用
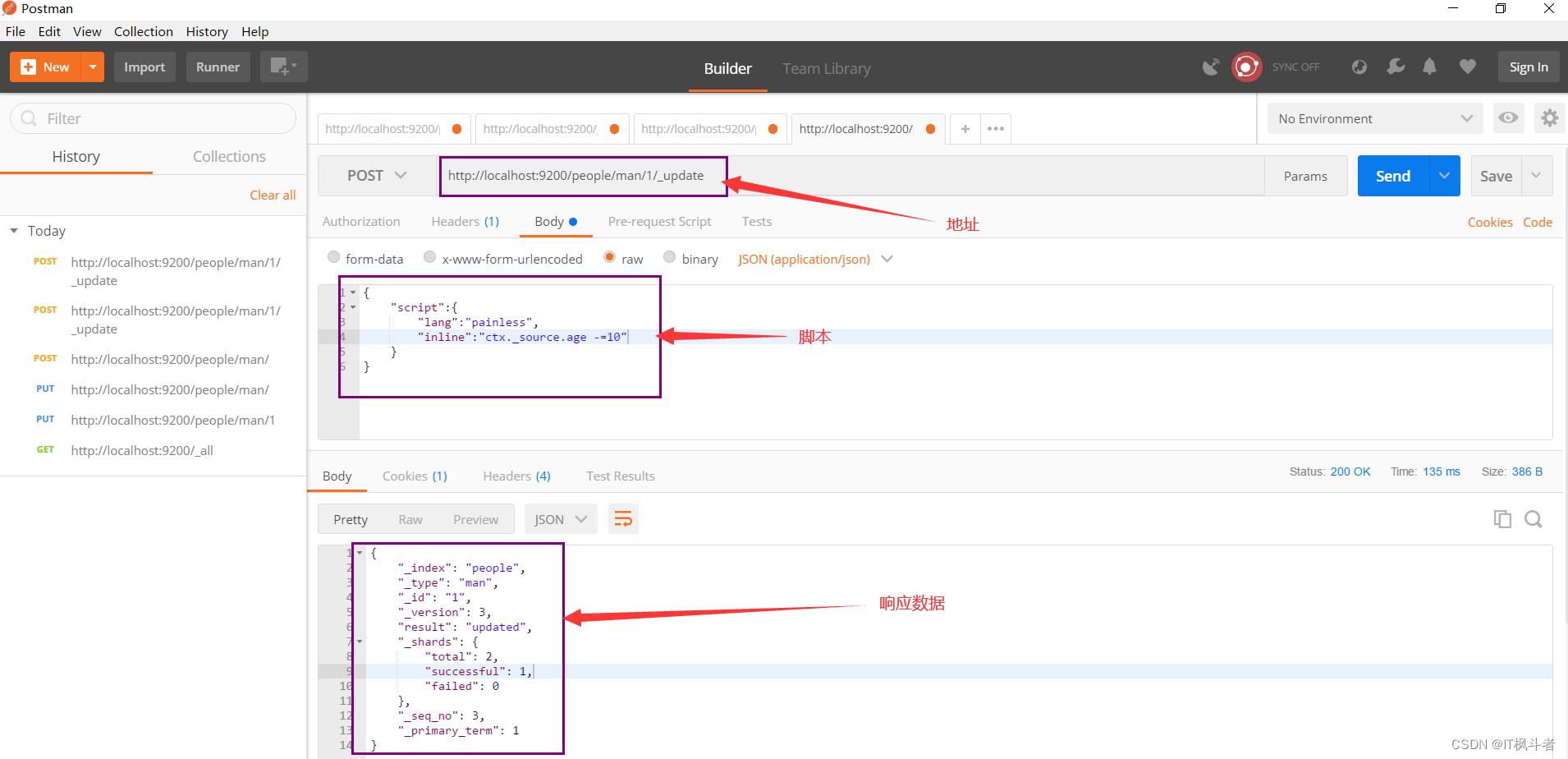
- 请求地址
1``````http://localhost:9200/people/man/1/_update - 请求参数
1234567891011121314151617181920``````方式一:{ "script":{ "lang":"painless", "inline":"ctx._source.age -=10" }}方式二:{ "script":{ "lang":"painless", "inline":"ctx._source.age = params.age", "params":{ "age":21 } }} - 请求图例
第5节 数据删除(postman)
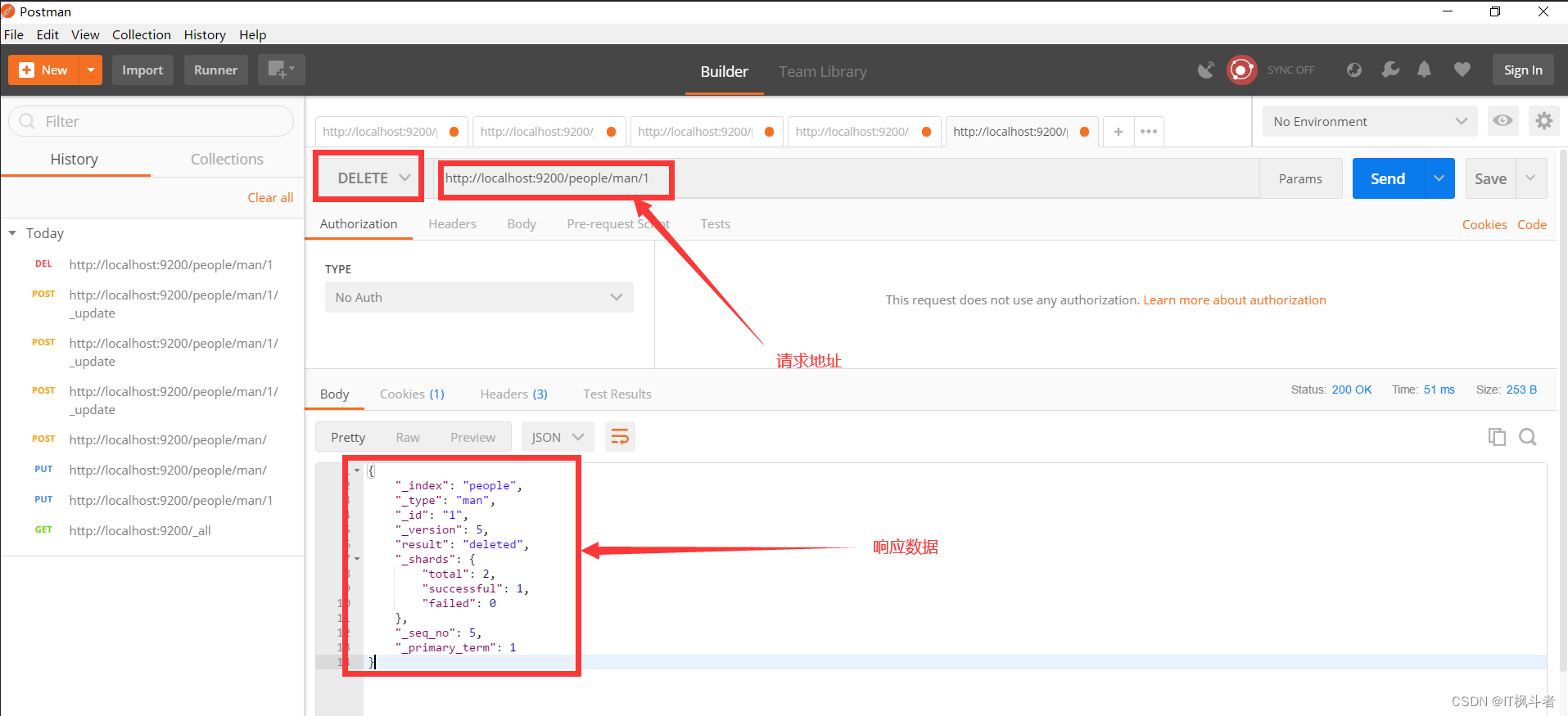
5.1 删除文档(postman)
- 请求地址
1``````http://localhost:9200/people/man/1 - 请求图例
5.2 删除索引(postman)
- 请求地址
1``````http://localhost:9200/people - 请求图例
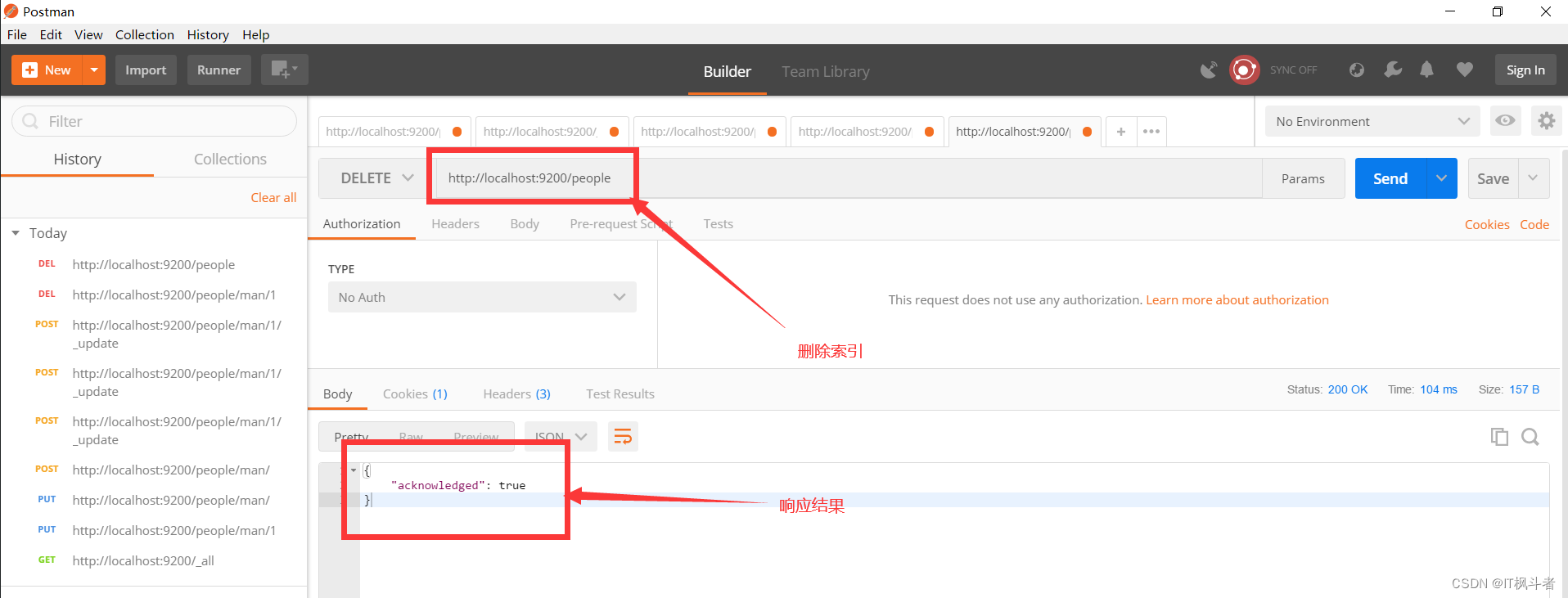
5.3 使用head删除索引
- 图例演示

第五章 高级查询(Kibana)
第1节 Kibana安装
1.1 Kibana简介
1
Kibana是一个针对Elasticsearch的开源分析及可视化平台,用来搜索、查看交互存储在Elasticsearch索引中的数据.使用Kibana,可以通过各种图表进行高级数据分析及展示
1.2 Kibana下载
- 官网地址
1``````https://www.elastic.co/cn/kibana - 华为云地址
1``````https://mirrors.huaweicloud.com/kibana/6.3.2/kibana-6.3.2-windows-x86_64.zip
1.3 Kibana安装
1
2
3
4
1、将下载的kibana-6.3.2-windows-x86_64.zip压缩包解压到指定文件夹下
2、在bin目录下D:\soft\kibana-6.3.2-windows-x86_64\bin找到kibana.bat
3、双击运行即可
4、浏览器访问 http://localhost:5601/进入 Dev Tools选项
第2节 Kibana使用
2.1 基本操作
2.1.1 查看集群健康状态
1
GET /_cat/health?v
2.1.2 查看节点状态
1
GET /_cat/nodes?v
2.1.3 查看索引信息
1
GET /_cat/indices?v
2.1.4 创建索引
1
2
3
4
5
6
7
8
1. 命令 PUT /book
2. 返回结果
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "book"
}
2.1.5 删除索引
1
2
3
4
5
1. 命令 DELETE /book
2. 返回结果
{
"acknowledged": true
}
2.1.6 向文档中添加数据
1
2
3
4
5
PUT /book/doc/1
{
"name":"李雷",
"age":18
}
2.1.7 查看文档类型
1
2
3
4
5
6
7
GET /book/doc/_mapping
GET: 请求方式
book: 索引(相当于MYSQL数据库的库名)
doc : 类型(相当于数据库的表名)
_mapping: ES的关键字查询文档类型
2.1.8 查看索引中的文档(根据ID查询)
1
GET /book/doc/1
2.1.9 更新索引中的文档
1
2
3
4
5
6
7
8
9
10
11
12
POST /book/doc/1/_update
{
"doc":{
"name":"韩梅梅"
}
}
POST : 请求方式
book : 索引名称
doc : 类型
1 : 文档id
_update: 关键字,用于更新
2.1.10 删除索引中的文档
1
DELETE /book/doc/2
2.1.11 对索引中的文档进行批量操作
1
2
3
4
5
6
7
POST /book/doc/_bulk
{"index":{"_id":"3"}}
{"name": "John Doe" }
{"index":{"_id":"4"}}
{"name": "Jane Doe" }
_bulk: 批量操作
2.2 高级查询
2.2.1 数据导入
- 数据地址
1``````https://github.com/macrozheng/mall-learning/blob/master/document/json/accounts.json - 导入命令(批量)
12``````POST /bank/account/_bulk//这里放上面的数据地址中的数据
2.2.2 高级查询
2.2.2.1 简单搜索
- 搜索全部(match_all)
1234``````GET /bank/_search{ "query": { "match_all": {} }} - 分页搜索(from表示偏移量,从0开始,size表示每页显示的数量)
123456``````GET /bank/_search{ "query": { "match_all": {} }, "from": 0, "size": 10} - 搜索排序(sort)
1234567``````GET /bank/_search{ "query": { "match_all": {} }, "sort": { "balance": { "order": "desc" } }}使用sort关键字 以balance字段排序,设置order属性的值为desc倒叙输出 - 搜索并返回指定字段内容(_source)
1234567``````GET /bank/_search{ "query": { "match_all": {} }, "_source": ["account_number", "balance"]}_source: 将要查询出来的属性设置到_source数组中
2.2.2.2 条件搜索(match)
- 搜索出account_number为20的文档
12345678``````GET /bank/_search{ "query": { "match": { "account_number": 20 } }} - 搜索address字段中包含mill的文档
123456789101112``````GET /bank/_search{ "query": { "match": { "address": "mill" } }, "_source": [ "address", "account_number" ]}> 注意: 对于数值类型match操作使用的是精确匹配,对于文本类型使用的是模糊匹配
2.2.2.3 短语匹配搜索(match_phrase)
- 搜索address字段中同时包含mill和lane的
12345678``````GET /bank/_search{ "query": { "match_phrase": { "address": "mill lane" } }}
2.2.2.4 组合搜索(bool)
- 同时满足(must)
- 搜索address字段中同时包含mill和lane的文档
1234567891011``````GET /bank/_search{ "query": { "bool": { "must": [ { "match": { "address": "mill" } }, { "match": { "address": "lane" } } ] } }}
- 搜索address字段中同时包含mill和lane的文档
- 满足其中任意一个(should)
- 搜索address字段中包含mill或者lane的文档
1234567891011``````GET /bank/_search{ "query": { "bool": { "should": [ { "match": { "address": "mill" } }, { "match": { "address": "lane" } } ] } }}
- 搜索address字段中包含mill或者lane的文档
- 同时不满足(must_not)
- 搜索address字段中不包含mill且不包含lane的文档
1234567891011``````GET /bank/_search{ "query": { "bool": { "must_not": [ { "match": { "address": "mill" } }, { "match": { "address": "lane" } } ] } }}
- 搜索address字段中不包含mill且不包含lane的文档
- 满足其中一部分,并且不包含另一部分(组合must和must_not)
- 搜索age字段等于40且state字段不包含ID的文档
12345678910111213``````GET /bank/_search{ "query": { "bool": { "must": [ { "match": { "age": "40" } } ], "must_not": [ { "match": { "state": "ID" } } ] } }}
- 搜索age字段等于40且state字段不包含ID的文档
2.2.2.5 过滤搜索(filter)
- 过滤出balance字段在20000~30000的文档
12345678910111213141516``````GET /bank/_search{ "query": { "bool": { "must": { "match_all": {} }, "filter": { "range": { "balance": { "gte": 20000, "lte": 30000 } } } } }}
2.2.2.6 搜索聚合(aggs)
- 对state字段进行聚合,统计出相同state的文档数量
12345678910111213141516``````GET /bank/_search{ "aggs":{ "group_by_state":{ "terms":{ "field":"state.keyword" } } }}aggs: 分组聚合关键字group_by_state: 聚合条件名字,自定义terms : 关键字,查询某个字段里含有多个关键词的文档keyword: state是一个关键字类型 - 对balance取平均值
1234567891011``````GET /bank/_search{ "size": 0, "aggs":{ "avg_balance":{ "avg":{ "field": "balance" } } }} - 对state字段进行聚合,统计出相同state的文档数量和balance平均值
12345678910111213141516``````GET /bank/_search{ "size": 0, "aggs":{ "group_by_state":{ "terms":{ "field":"state.keyword" } }, "avg_balance":{ "avg":{ "field": "balance" } } }}
具体ES的聚合函数请参考官方文档这里不再讲解
第六章 ES和SpringBoot整合(Spring-data版本使用)
第1节 分词器介绍
1.1 分词器的作用
1
将原始内容进行拆分,将一段话拆分成单词或者一个一个的字,或者语义单元
1.2 常见分词器
- standars
1``````ES默认分词器,将词汇单元转成小写,取出一些停用词和标点符号,支持中文,将中文拆分成单个的字 - IK分词器
1``````一个可以很好的支持中文,并且可以自定义的开源分词器
第2节 standars分词器演示(kibana工具)
2.1 演示英文
- 命令
12345``````POST _analyze{ "analyzer": "standard", "text":"Hello Java"} - 结果
1234567891011121314151617181920``````将Hello Java分成了两个词分别是hello和java,首字母都变成了小写{ "tokens": [ { "token": "hello", "start_offset": 0, "end_offset": 5, "type": "<ALPHANUM>", "position": 0 }, { "token": "java", "start_offset": 6, "end_offset": 10, "type": "<ALPHANUM>", "position": 1 } ]}2.2 演示中文 - 命令
12345``````POST _analyze{ "analyzer": "standard", "text":"我是中国人"} - 结果
123456789101112131415161718192021222324252627282930313233343536373839``````{ "tokens": [ { "token": "我", "start_offset": 0, "end_offset": 1, "type": "<IDEOGRAPHIC>", "position": 0 }, { "token": "是", "start_offset": 1, "end_offset": 2, "type": "<IDEOGRAPHIC>", "position": 1 }, { "token": "中", "start_offset": 2, "end_offset": 3, "type": "<IDEOGRAPHIC>", "position": 2 }, { "token": "国", "start_offset": 3, "end_offset": 4, "type": "<IDEOGRAPHIC>", "position": 3 }, { "token": "人", "start_offset": 4, "end_offset": 5, "type": "<IDEOGRAPHIC>", "position": 4 } ]}
第3节 ik分词器安装和使用
1
medcl/elasticsearch-analysis-ik分词器是当前对中文支持最好的分词器
- IK分词器地址
123``````https://github.com/medcl/elasticsearch-analysis-ik/archive/v6.3.2.zip下载的分词器一定要和当前安装的ES版本相同 - 安装步骤
123``````1. 将下载的分词器压缩包复制到我们的es的安装目录D:\soft\elasticsearch-6.3.2\plugins插件目录下3. 将elasticsearch-analysis-ik解压4. 重启ES服务
第4节 ik分词器演示(kibana工具)
- 命令
12345678910111213``````POST _analyze{ "analyzer": "ik_smart", "text":"我是中国人"}-----------------POST _analyze{ "analyzer": "ik_max_word", "text":"我是中国人"} - 返回效果
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768697071``````ik_smart分词器效果{ "tokens": [ { "token": "我", "start_offset": 0, "end_offset": 1, "type": "CN_CHAR", "position": 0 }, { "token": "是", "start_offset": 1, "end_offset": 2, "type": "CN_CHAR", "position": 1 }, { "token": "中国人", "start_offset": 2, "end_offset": 5, "type": "CN_WORD", "position": 2 } ]}---------------------ik_max_word分词器效果{ "tokens": [ { "token": "我", "start_offset": 0, "end_offset": 1, "type": "CN_CHAR", "position": 0 }, { "token": "是", "start_offset": 1, "end_offset": 2, "type": "CN_CHAR", "position": 1 }, { "token": "中国人", "start_offset": 2, "end_offset": 5, "type": "CN_WORD", "position": 2 }, { "token": "中国", "start_offset": 2, "end_offset": 4, "type": "CN_WORD", "position": 3 }, { "token": "国人", "start_offset": 3, "end_offset": 5, "type": "CN_WORD", "position": 4 } ]}
第5节 ES和SpringBoot整合
5.1 创建SpringBoot项目
1
2
3
4
5
6
7
添加依赖,依赖在springboot-data中
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>

5.2 配置
1
2
3
4
5
# 设置ES的节点地址
# spring.data.elasticsearch.cluster-nodes=127.0.0.1:9300,127.0.0.1:9301,127.0.0.1:9302
spring.data.elasticsearch.cluster-nodes=127.0.0.1:9300
# es集群名称
spring.data.elasticsearch.cluster-name=elasticsearch
5.3 常见的操作
5.3.1 映射ES文档的实体类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
/**
* Document: 设置文档
* indexName:设置索引
* type: 设置类型
* shards: 设置分片
* replicas: 设置副本
*/
@Document(indexName = "bank",type = "account",shards = 5,replicas = 1)
public class EsAccount {
@Id
private Long id;
@Field(type = FieldType.Long)
private Long account_number;
@Field(type = FieldType.Text) //是有IK分词器(一定要安装IK分词器)
private String firstname;
@Field(type = FieldType.Text)
private String address;
@Field(type = FieldType.Text)
private String gender;
@Field(type = FieldType.Text)
private String city;
@Field(type = FieldType.Long)
private Long balance;
@Field(type = FieldType.Text)
private String lastname;
@Field(type = FieldType.Text)
private String employer;
@Field(type = FieldType.Text)
private String state;
@Field(type = FieldType.Long)
private Long age;
@Field(type = FieldType.Text)
private String email;
}
5.3.2 操作ES的接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
public interface EsAccountRepository extends ElasticsearchRepository<EsAccount,Long> {
/**
* 根据名称查询
* 方法名字不能随便乱起
*/
List<EsAccount> findByLastname(String lastname);
/**
* 根据地址查询
* 方法名字不能随便乱起
*/
List<EsAccount> findByAddress(String address);
/**
* 根据名称删除
* 方法名字不能随便乱起
*/
void deleteByFirstname(String firstname);
/**
* 根据地址查询,并且分页
* 方法名字不能随便乱起
*/
Page<EsAccount> findByAddress(String address, Pageable pageable);
}
5.3.3 单元测试操作
- 常见操作
1456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126127128129130131132133134135136137138139140141142143144145146147148149150151152153154155156157158159160161162163164165166167168169170171172173174175176177178179180181182183184185186187188189190191192193194195196197198199200201202203204205206207208209210211212213214215216217218219220221222223224225226227228229230231232233234235236237``````public class EsAccountRepositoryTest extends SpringbootEs01ApplicationTests { @Autowired private EsAccountRepository esAccountRepository; /** * 测试findAll */ @Test public void findAll1(){ Iterable<EsAccount> esAccounts = esAccountRepository.findAll(); //esAccounts.forEach(System.out::println); //esAccounts.forEach((x)->{System.out.println(x);}); Iterator<EsAccount> iterator = esAccounts.iterator(); while (iterator.hasNext()){ System.out.println(iterator.next()); } } /** * 测试添加一条数据 * 更新数据,更新和添加主要判断是否有id */ @Test public void saveAccount(){ EsAccount account = new EsAccount(); account.setAccount_number(4570L); account.setAddress("北京"); account.setAge(18L); account.setBalance(1000000L); account.setCity("中国"); account.setEmail("[email protected]"); account.setEmployer("李雷"); account.setFirstname("李"); account.setGender("男"); account.setId(4570L); account.setLastname("李雷"); account.setState("NL"); esAccountRepository.save(account); } /** * 根据ID查询account */ @Test public void findAccountById(){ Optional<EsAccount> esAccount = esAccountRepository.findById(4570L); System.out.println(esAccount.get()); } /** * 根据ID删除 */ @Test public void deleteAccount(){ esAccountRepository.deleteById(4570L); } /** * 更新 */ @Test public void updateAccount(){ Optional<EsAccount> esAccount = esAccountRepository.findById(456L); EsAccount account = esAccount.get(); account.setLastname("李雷super"); esAccountRepository.save(account); } /** * 根据Lastname查询(模糊查询) */ @Test public void findByLastname(){ List<EsAccount> accountList = esAccountRepository.findByLastname("李雷"); System.out.println(accountList); } /** * 根据地址查询(模糊查询) */ @Test public void findByAddress(){ List<EsAccount> accounts = esAccountRepository.findByAddress("京"); System.out.println(accounts); } /** * 分页查询 */ @Test public void findPage(){ Pageable p = PageRequest.of(0, 5); Page<EsAccount> accounts = esAccountRepository.findAll(p); for (EsAccount account : accounts) { System.out.println(account); } } /** * 排序分页查询 */ @Test public void findPageMult(){ Sort sort = Sort.by(Sort.Direction.DESC, "account_number"); Pageable p = PageRequest.of(0, 5, sort); Page<EsAccount> accounts = esAccountRepository.findByAddress("Place", p); for (EsAccount account : accounts) { System.out.println(account); } } /** * 复杂查询,采用search方法 * 构建条件查询 使用match语法 * 过滤查询 */ @Test public void testMatch01(){ //单个条件 // QueryBuilder query = QueryBuilders.matchQuery("account_number", 20); //多个条件 NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder(); NativeSearchQueryBuilder queryBuilder = builder .withQuery(QueryBuilders.matchQuery("account_number", 20)) .withQuery(QueryBuilders.matchQuery("firstname","Elinor")); NativeSearchQuery build = queryBuilder.build(); Iterable<EsAccount> accounts = esAccountRepository.search(build); for (EsAccount account : accounts) { System.out.println(account); } } /** * 复杂查询,采用search方法 * 构建条件查询 使用match语法 * 短语匹配搜索 */ @Test public void testMatchPhrase(){ NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder(); NativeSearchQueryBuilder queryBuilder = builder.withQuery(QueryBuilders.matchPhraseQuery("address", "mill lane")); NativeSearchQuery searchQuery = queryBuilder.build(); Page<EsAccount> accountPage = esAccountRepository.search(searchQuery); //accountPage.forEach(System.out::println); //accountPage.forEach((x)->{System.out.println(x);}); //获取迭代器 Iterator<EsAccount> iterator = accountPage.iterator(); while(iterator.hasNext()){ System.out.println(iterator.next()); } } /** * 组合搜索(bool) * 同时满足(must) */ @Test public void testMust(){ NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder(); builder.withQuery(QueryBuilders.boolQuery().must(QueryBuilders.matchQuery("address","mill")).must(QueryBuilders.matchQuery("address","lane"))); NativeSearchQuery query = builder.build(); Page<EsAccount> accounts = esAccountRepository.search(query); for (EsAccount account : accounts) { System.out.println(account); } } /** * 满足其中任意一个(should) */ @Test public void testShould(){ NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder(); builder.withQuery(QueryBuilders.boolQuery().should(QueryBuilders.matchQuery("address","lane")).should(QueryBuilders.matchQuery("address","mill"))); NativeSearchQuery searchQuery = builder.build(); Page<EsAccount> accounts = esAccountRepository.search(searchQuery); for (EsAccount account : accounts) { System.out.println(account); } } /** * 同时不满足 must_not */ @Test public void testMustNot(){ NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder(); builder.withQuery(QueryBuilders.boolQuery().mustNot(QueryBuilders.matchQuery("address","mill")).mustNot(QueryBuilders.matchQuery("address","lane"))); NativeSearchQuery query = builder.build(); Page<EsAccount> search = esAccountRepository.search(query); for (EsAccount esAccount : search) { System.out.println(esAccount); } } /** * 满足其中一部分,并且不包含另一部分(组合must和must_not) */ @Test public void testMustAndNotMust(){ NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder(); builder.withQuery(QueryBuilders.boolQuery().mustNot(QueryBuilders.matchQuery("state","ID")).must(QueryBuilders.matchQuery("age","40"))); NativeSearchQuery query = builder.build(); Page<EsAccount> accounts = esAccountRepository.search(query); for (EsAccount account : accounts) { System.out.println(account); } } /** * 过滤搜索 filter * 过滤出balance字段在20000~30000的文档 */ @Test public void testFilter(){ NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder(); builder.withFilter(QueryBuilders.boolQuery().filter(QueryBuilders.rangeQuery("balance").gte(20000).lte(30000))); NativeSearchQuery query = builder.build(); Page<EsAccount> accounts = esAccountRepository.search(query); for (EsAccount account : accounts) { System.out.println(account); } }} - 分组聚合
123456789``````Elasticsearch有一个功能叫做聚合(aggregations),它允许你在数据上生成复杂的分析统计。它很像SQL中的 GROUP BY 但是功能更强大.Elasticsearch的聚合中声明了两个概念如下: -- Buckets(桶):满足某个条件的文档集合。 -- Metrics(指标):为某个桶中的文档计算得到的统计信息我们可以把类似于数据库中的COUNT(*) 看成一个指标将 GROUP BY 看成一个桶``````123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990``````@Autowiredprivate ElasticsearchTemplate elasticsearchTemplate;/** * 分组聚合 ElasticsearchTemplate * 单个分组聚合 * 对state字段进行聚合,统计出相同state的文档数量 */@Testpublic void group01(){ NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder(); //统计state字段相同数据出现的次数 TermsAggregationBuilder field = AggregationBuilders.terms("group_by_state").field("state.keyword"); //查询全部 builder.withQuery(QueryBuilders.matchAllQuery()); //添加聚合条件 builder.addAggregation(field); //构建 NativeSearchQuery query = builder.build(); //查询,采用ElasticsearchTemplate Aggregations aggregations = elasticsearchTemplate.query(query, new ResultsExtractor<Aggregations>() { @Override public Aggregations extract(SearchResponse response) { return response.getAggregations(); } }); //转换成map集合 Map<String, Aggregation> aggregationMap = aggregations.asMap(); //获取响应的聚合子类group_by_state StringTerms groupByState = (StringTerms) aggregationMap.get("group_by_state"); //获取所有的桶 List<StringTerms.Bucket> buckets = groupByState.getBuckets(); Iterator<StringTerms.Bucket> iterator = buckets.iterator(); while (iterator.hasNext()){ StringTerms.Bucket bucket = iterator.next(); System.out.println(bucket.getKeyAsString()); System.out.println(bucket.getDocCount()); }}/** * 分组聚合 ElasticsearchTemplate * 多个分组聚合 * 统计出相同state的文档数量,再统计出balance的平均值 */@Testpublic void group02(){ NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder(); //统计state字段相同数据出现的次数 TermsAggregationBuilder field = AggregationBuilders.terms("group_by_state").field("state.keyword"); //统计出balance的平均值 AvgAggregationBuilder field2 = AggregationBuilders.avg("avg_balance").field("balance"); //查询全部 builder.withQuery(QueryBuilders.matchAllQuery()); //添加聚合条件 builder.addAggregation(field); builder.addAggregation(field2); //构建 NativeSearchQuery query = builder.build(); //查询,采用ElasticsearchTemplate Aggregations aggregations = elasticsearchTemplate.query(query, new ResultsExtractor<Aggregations>() { @Override public Aggregations extract(SearchResponse response) { return response.getAggregations(); } }); //转换成map集合 Map<String, Aggregation> aggregationMap = aggregations.asMap(); //获取响应的聚合子类group_by_state StringTerms groupByState = (StringTerms) aggregationMap.get("group_by_state"); //获取响应的聚合子类avg_balance InternalAvg avgBalance = (InternalAvg) aggregationMap.get("avg_balance"); //获取所有的桶 List<StringTerms.Bucket> buckets = groupByState.getBuckets(); Iterator<StringTerms.Bucket> iterator = buckets.iterator(); while (iterator.hasNext()){ StringTerms.Bucket bucket = iterator.next(); System.out.println(bucket.getKeyAsString()); System.out.println(bucket.getDocCount()); } //获取指标 double value = avgBalance.getValue(); System.out.println("==="+value);}
第七章 ES和MYSQL数据同步
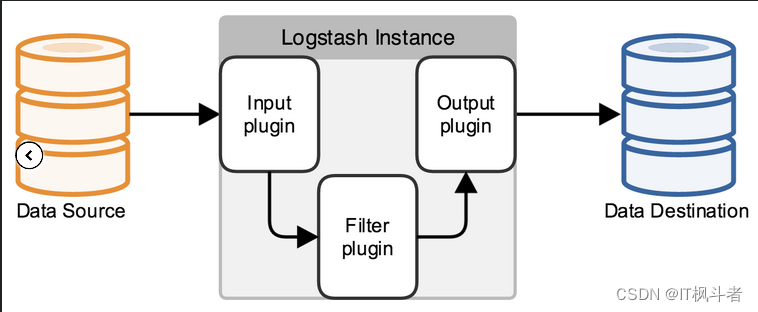
第1节 logstash简介
Logstash是一款开源的数据收集引擎,具备实时管道处理能力。简单来说,logstash作为数据源与数据存储分析工具之间的桥梁,结合ElasticSearch以及Kibana,能够极大方便数据的处理与分析。通过200多个插件,logstash可以接受几乎各种各样的数据。包括日志、网络请求、关系型数据库、传感器或物联网等等
第2节 logstash下载(6.3.2)
- 官网地址
1``````https://www.elastic.co/cn/downloads/logstash - 华为镜像站
1``````https://mirrors.huaweicloud.com/logstash/
第3节 logstash配置(简单配置-单表/多表)
1
2
3
4
logstash工作时,主要设置3个部分的工作属性。
input:设置数据来源
filter:可以对数据进行一定的加工处理过滤,但是不建议做复杂的处理逻辑。这个步骤不是必须的
output:设置输出目标
- 安装/配置步骤(使用单个表生成索引)
123``````1. 将下载的logstash-6.3.2.zip文件解压到指定位置2. 创建一个配置文件名字自定义,我命名为 mysql.conf,将自定义配置文件放到指定位置(我放到了D:\soft\logstash-6.3.2\config文件夹下)3. 在mysql.conf中添加配置信息``````12345678910111213141516171819202122232425262728293031323334``````input{ jdbc{ # 数据库驱动地址 jdbc_driver_library => "D:\\soft\\logstash-6.3.2\\lib\\mysql-connector-java-5.1.47.jar" # 数据库驱动类名 jdbc_driver_class => "com.mysql.jdbc.Driver" # 数据库连接地址 jdbc_connection_string => "jdbc:mysql://127.0.0.1:3306/gn_oa" # 数据库用户名 jdbc_user => "root" # 数据库密码 jdbc_password => "root" # 定时任务 schedule => "* * * * *" # 生成索引的数据来源 statement => "SELECT * FROM department" }}output{ elasticsearch{ # 集群地址 hosts => ["127.0.0.1:9200","127.0.0.1:9201","127.0.0.1:9202"] # 索引名称 index => "department" # 生成根据dept_id,生成ES的 _id document_id => "%{dept_id}" # 类型 document_type => "dept_doc" }}4. 启动logstash服务,使用我们自定义的配置启动 -- 使用cmd命令行定位到当前logstash目录的bin目录下使用命令为: logstash -f ../config/mysql.conf 启动服务 5. 等待索引创建完成(这种方式为全量方式) - 安装/配置步骤(使用多张表生成索引)
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768697071``````input{ # 第1张表 jdbc{ # 设置当前jdbc的type type => "department" # 数据库驱动地址 jdbc_driver_library => "D:\\soft\\logstash-6.3.2\\lib\\mysql-connector-java-5.1.47.jar" # 数据库驱动类名 jdbc_driver_class => "com.mysql.jdbc.Driver" # 数据库连接地址 jdbc_connection_string => "jdbc:mysql://127.0.0.1:3306/gn_oa" # 数据库用户名 jdbc_user => "root" # 数据库密码 jdbc_password => "root" # 定时任务 schedule => "* * * * *" # 生成索引的数据来源 statement => "SELECT * FROM department" } # 第2张表 jdbc{ # 设置当前jdbc的type type => "student" # 数据库驱动地址 jdbc_driver_library => "D:\\soft\\logstash-6.3.2\\lib\\mysql-connector-java-5.1.47.jar" # 数据库驱动类名 jdbc_driver_class => "com.mysql.jdbc.Driver" # 数据库连接地址 jdbc_connection_string => "jdbc:mysql://127.0.0.1:3306/gn_oa" # 数据库用户名 jdbc_user => "root" # 数据库密码 jdbc_password => "root" # 定时任务 schedule => "* * * * *" # 生成索引的数据来源 statement => "SELECT * FROM student" }}output{ # 根据jdbc中的type值指定输入的jdbc对应的输出为哪一个elasticsearch if[type]=="department"{ elasticsearch{ # 集群地址 hosts => ["127.0.0.1:9200","127.0.0.1:9201","127.0.0.1:9202"] # 索引名称 index => "department" # 生成根据dept_id,生成ES的 _id document_id => "%{dept_id}" # 类型 document_type => "dept_doc" } } if[type]=="student"{ elasticsearch{ # 集群地址 hosts => ["127.0.0.1:9200","127.0.0.1:9201","127.0.0.1:9202"] # 索引名称 index => "student" # 生成根据student_id,生成ES的 _id document_id => "%{student_id}" # 类型 document_type => "student_doc" } }}
第4节 logstash配置(其他配置)
- 官网配置地址
1``````https://www.elastic.co/guide/en/logstash/6.3/plugins-inputs-jdbc.html
4.1 使用时间字段进行追踪(一般使用更新时间字段)
1
在阿里巴巴嵩山版手册中强调,任何数据库表都必须有创建时间和更新时间字段,都是datetime类型,也就是保存时间为年月日时分秒
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
input{
# 第1张表
jdbc{
# 设置当前jdbc的type
type => "department"
# 数据库驱动地址
jdbc_driver_library => "D:\\soft\\logstash-6.3.2\\lib\\mysql-connector-java-5.1.47.jar"
# 数据库驱动类名
jdbc_driver_class => "com.mysql.jdbc.Driver"
# 数据库连接地址
jdbc_connection_string => "jdbc:mysql://127.0.0.1:3306/gn_oa"
# 数据库用户名
jdbc_user => "root"
# 数据库密码
jdbc_password => "root"
# 定时任务,一分钟同步一次
schedule => "* * * * *"
# 如果sql语句使用sql_last_value属性要设置use_column_value为true,并且指定tracking_column属性,指定哪一列
use_column_value => true
# 指定sql_last_value参数使用哪一列
tracking_column => "create_time"
# 设置tracking_column属性名保存的状态
last_run_metadata_path => "D:\\soft\\logstash-6.3.2\\a\\a.txt"
# 是否保留前一次的运行状态,如果不保留下次重启服务器所以会被重新创建
clean_run => false
# 设置时间戳
tracking_column_type => "timestamp"
# 生成索引的数据来源
statement => "SELECT * FROM department WHERE create_time > :sql_last_value AND create_time < now() ORDER BY create_time desc"
}
# 第2张表
jdbc{
# 设置当前jdbc的type
type => "student"
# 数据库驱动地址
jdbc_driver_library => "D:\\soft\\logstash-6.3.2\\lib\\mysql-connector-java-5.1.47.jar"
# 数据库驱动类名
jdbc_driver_class => "com.mysql.jdbc.Driver"
# 数据库连接地址
jdbc_connection_string => "jdbc:mysql://127.0.0.1:3306/gn_oa"
# 数据库用户名
jdbc_user => "root"
# 数据库密码
jdbc_password => "root"
# 定时任务,一分钟同步一次
schedule => "* * * * *"
# 如果sql语句使用sql_last_value属性要设置use_column_value为true
use_column_value => true
# 指定sql_last_value参数使用哪一列
tracking_column => "create_time"
# 设置tracking_column属性名保存的状态
last_run_metadata_path => "D:\\soft\\logstash-6.3.2\\b\\b.txt"
# 是否保留前一次的运行状态,如果不保留下次重启服务器所以会被重新创建
clean_run => false
# 设置时间戳
tracking_column_type => "timestamp"
# 生成索引的数据来源
statement => "SELECT * FROM student WHERE create_time > :sql_last_value AND create_time < now() ORDER BY create_time desc"
}
}
output{
# 根据jdbc中的type值指定输入的jdbc对应的输出为哪一个elasticsearch
if[type]=="department"{
elasticsearch{
# 集群地址
hosts => ["127.0.0.1:9200","127.0.0.1:9201","127.0.0.1:9202"]
# 索引名称
index => "department"
# 生成根据dept_id,生成ES的 _id
document_id => "%{dept_id}"
# 类型
document_type => "dept_doc"
}
}
if[type]=="student"{
elasticsearch{
# 集群地址
hosts => ["127.0.0.1:9200","127.0.0.1:9201","127.0.0.1:9202"]
# 索引名称
index => "student"
# 生成根据student_id,生成ES的 _id
document_id => "%{student_id}"
# 类型
document_type => "student_doc"
}
}
}
4.2 使用其他字段进行追踪(设置使用主键进行追踪)
1
在修改其他字段进行追踪时,一定不要忘记修改tracking_column_type类型,详情修改请参官网
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
input{
# 第1张表
jdbc{
# 设置当前jdbc的type
type => "department"
# 数据库驱动地址
jdbc_driver_library => "D:\\soft\\logstash-6.3.2\\lib\\mysql-connector-java-5.1.47.jar"
# 数据库驱动类名
jdbc_driver_class => "com.mysql.jdbc.Driver"
# 数据库连接地址
jdbc_connection_string => "jdbc:mysql://127.0.0.1:3306/gn_oa"
# 数据库用户名
jdbc_user => "root"
# 数据库密码
jdbc_password => "root"
# 定时任务,一分钟同步一次
schedule => "* * * * *"
# 如果sql语句使用sql_last_value属性要设置use_column_value为true,并且指定tracking_column属性,指定哪一列
use_column_value => true
# 指定sql_last_value参数使用哪一列
tracking_column => "dept_id"
# 设置tracking_column属性名保存的状态
last_run_metadata_path => "D:\\soft\\logstash-6.3.2\\a\\a.txt"
# 是否保留前一次的运行状态,如果不保留下次重启服务器所以会被重新创建
clean_run => false
# 设置列的类型
tracking_column_type => "numeric"
# 生成索引的数据来源
statement => "SELECT * FROM department WHERE dept_id > :sql_last_value"
}
# 第2张表
jdbc{
# 设置当前jdbc的type
type => "student"
# 数据库驱动地址
jdbc_driver_library => "D:\\soft\\logstash-6.3.2\\lib\\mysql-connector-java-5.1.47.jar"
# 数据库驱动类名
jdbc_driver_class => "com.mysql.jdbc.Driver"
# 数据库连接地址
jdbc_connection_string => "jdbc:mysql://127.0.0.1:3306/gn_oa"
# 数据库用户名
jdbc_user => "root"
# 数据库密码
jdbc_password => "root"
# 定时任务,一分钟同步一次
schedule => "* * * * *"
# 如果sql语句使用sql_last_value属性要设置use_column_value为true
use_column_value => true
# 指定sql_last_value参数使用哪一列
tracking_column => "student_id"
# 设置tracking_column属性名保存的状态
last_run_metadata_path => "D:\\soft\\logstash-6.3.2\\b\\b.txt"
# 是否保留前一次的运行状态,如果不保留下次重启服务器所以会被重新创建
clean_run => false
# 设置列的类型
tracking_column_type => "numeric"
# 生成索引的数据来源
statement => "SELECT * FROM student WHERE student_id > :sql_last_value"
}
}
output{
# 根据jdbc中的type值指定输入的jdbc对应的输出为哪一个elasticsearch
if[type]=="department"{
elasticsearch{
# 集群地址
hosts => ["127.0.0.1:9200","127.0.0.1:9201","127.0.0.1:9202"]
# 索引名称
index => "department"
# 生成根据dept_id,生成ES的 _id
document_id => "%{dept_id}"
# 类型
document_type => "dept_doc"
}
}
if[type]=="student"{
elasticsearch{
# 集群地址
hosts => ["127.0.0.1:9200","127.0.0.1:9201","127.0.0.1:9202"]
# 索引名称
index => "student"
# 生成根据student_id,生成ES的 _id
document_id => "%{student_id}"
# 类型
document_type => "student_doc"
}
}
}
注意: 日常bug记录与采坑指南,如果出现下面的BUG并且在进行配置查找的时候,无论怎么校验都不能从自己的配置中找到错误,但是服务器还启动不起来,那么可以尝试在错误信息中查找关键信息,经过反复校验,如果设置了last_run_metadata_path服务器可以正常启动,如果配置中少了last_run_metadata_path 属性服务器启动失败,就会报如下错误,并且在下面的错误中,有相关信息,我的报错信息如下,关键信息last_run_metadata_path=>"C:\Users\lenovo/.logstash_jdbc_last_run",说明在上次发生错的时候logstash对我上次的错误信息进行的保存,造成服务器每次启动读取错误信息,造成的服务器启动失败,去指定位置删除即可.
1
2
3
[2020-08-20T02:27:40,897][ERROR][logstash.pipeline ] Error registering plugin {:pipeline_id=>"main", :plugin=>"<LogStash::Inputs::Jdbc jdbc_driver_library=>\"D:\\\\\\\\soft\\\\\\\\logstash-6.3.2\\\\\\\\lib\\\\\\\\mysql-connector-java-5.1.47.jar\", jdbc_driver_class=>\"com.mysql.jdbc.Driver\", jdbc_connection_string=>\"jdbc:mysql://127.0.0.1:3306/gn_oa\", jdbc_user=>\"root\", jdbc_password=><password>, schedule=>\"* * * * *\", statement=>\"SELECT * FROM department\", id=>\"02efb29127a061192768f52b1a09e6638672c521b53edda48b19f6b9880e90d6\", enable_metric=>true, codec=><LogStash::Codecs::Plain id=>\"plain_e50f7aa8-3c57-4f33-9000-86265d442ec7\", enable_metric=>true, charset=>\"UTF-8\">, jdbc_paging_enabled=>false, jdbc_page_size=>100000, jdbc_validate_connection=>false, jdbc_validation_timeout=>3600, jdbc_pool_timeout=>5, sql_log_level=>\"info\", connection_retry_attempts=>1, connection_retry_attempts_wait_time=>0.5, last_run_metadata_path=>\"C:\\\\Users\\\\lenovo/.logstash_jdbc_last_run\", use_column_value=>false, tracking_column_type=>\"numeric\", clean_run=>false, record_last_run=>true, lowercase_column_names=>true>", :error=>"can't dup Fixnum", :thread=>"#<Thread:0x703b95e6 run>"}
[2020-08-20T02:27:41,426][ERROR][logstash.pipeline ] Pipeline aborted due to error {:pipeline_id=>"main", :exception=>#<TypeError: can't dup Fixnum>, :backtrace=>["org/jruby/RubyKernel.java:1882:in `dup'", "uri:classloader:/META-INF/jruby.home/lib/ruby/stdlib/date/format.rb:838:in `_parse'", "uri:classloader:/META-INF/jruby.home/lib/ruby/stdlib/date.rb:1830:in `parse'", "D:/soft/logstash-6.3.2/vendor/bundle/jruby/2.3.0/gems/logstash-input-jdbc-4.3.9/lib/logstash/plugin_mixins/value_tracking.rb:87:in `set_value'", "D:/soft/logstash-6.3.2/vendor/bundle/jruby/2.3.0/gems/logstash-input-jdbc-4.3.9/lib/logstash/plugin_mixins/value_tracking.rb:36:in `initialize'", "D:/soft/logstash-6.3.2/vendor/bundle/jruby/2.3.0/gems/logstash-input-jdbc-4.3.9/lib/logstash/plugin_mixins/value_tracking.rb:29:in `build_last_value_tracker'", "D:/soft/logstash-6.3.2/vendor/bundle/jruby/2.3.0/gems/logstash-input-jdbc-4.3.9/lib/logstash/inputs/jdbc.rb:216:in `register'", "D:/soft/logstash-6.3.2/logstash-core/lib/logstash/pipeline.rb:340:in `register_plugin'", "D:/soft/logstash-6.3.2/logstash-core/lib/logstash/pipeline.rb:351:in `block in register_plugins'", "org/jruby/RubyArray.java:1734:in `each'", "D:/soft/logstash-6.3.2/logstash-core/lib/logstash/pipeline.rb:351:in `register_plugins'", "D:/soft/logstash-6.3.2/logstash-core/lib/logstash/pipeline.rb:498:in `start_inputs'", "D:/soft/logstash-6.3.2/logstash-core/lib/logstash/pipeline.rb:392:in `start_workers'", "D:/soft/logstash-6.3.2/logstash-core/lib/logstash/pipeline.rb:288:in `run'", "D:/soft/logstash-6.3.2/logstash-core/lib/logstash/pipeline.rb:248:in `block in start'"], :thread=>"#<Thread:0x703b95e6 run>"}
[2020-08-20T02:27:41,467][ERROR][logstash.agent ] Failed to execute action {:id=>:main, :action_type=>LogStash::ConvergeResult::FailedAction, :message=>"Could not execute action: PipelineAction::Create<main>,
版权归原作者 IT枫斗者 所有, 如有侵权,请联系我们删除。