
一、 Apache Hive概述
**1. 目的:**了解什么是分布式SQL计算;了解什么是Apache Hive
- 使用Hive处理数据的好处
- 操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)
- 底层执行MapReduce,可以完成分布式海量数据的SQL处理
- 什么是分布式SQL计算?
以分布式的形式,执行SQL语句,进行数据统计分析。
- Apache Hive是做什么的?
很简单,是一款分布式SQL计算的工具,将SQL语句翻译成MapReduce程序,从而提供用户分布式SQL计算的能力。
- 传统MapReduce开发:写MR代码 -> 得到结果
- 使用Hive开发:写SQL -> 得到结果
- 底层都是MR在运行,但是使用层面更加简单了。
2. 模拟实现Hive功能
基于MapReduce构建分布式SQL执行引擎,主要需要有哪些功能组件?
- 元数据管理
- SQL解析器
3. Hive基础架构

4. Hive部署
4.1 在VMware虛拟机集群中,完成Hive的安装部署
Hive是单机工具,只需要部署在一台服务器即可。Hive虽然是单机的,但是它可以提交分布式运行的MapReduce程序运行。
第四章-04-[实操]Hive在VMware虚拟机中部署_哔哩哔哩_bilibili
步骤1: 安装MySQL数据库(部署MySQL数据库,并配置root账户密码)
步骤2: 配置Hadoop(下载Hive上传并解压和设置软链)
步骤3: 下载解压Hive
步骤4: 提供MySQL Driver包(下载MySQL驱动jar包放入Hive的lib目录)
步骤5: 配置Hive(修改配置文件 (hive-env.sh和hive-site.xm)
步骤6: 初始化元数据库(启动hive的metastore服务:前台/后台启动)
步骤7: 启动Hive(使用Hadoop用户)(bin/hive)
4.2 在阿里云中创建RDS作为Hive的元数据存储数据库,并完成Hive的安装部署
第四章-05-[可选]在阿里云上部署Hive_哔哩哔哩_bilibili
- 云平台上均有提供RDS服务(Relational Database service,关系型数据库服务),即云上的数据库。
- 借助云平合我们无需手动搭建MySQL服务,只需要简单的购买RDS即可(需付费)
4.3 在Ucloud云中创建UDB作为Hive的元数据存储数据库,并完成Hive的安装部署
第四章-06-[可选]在UCloud云上部署Hive.mp4_哔哩哔哩_bilibili
5. Hive初体验
目标:体验在Hive中使用SQL来处理数据

- Hive客户端
6.1 HiveServer2 & Beeline
目标:理解HiveServer2的作用;掌握使用Beeline客户端连接Hiveserver2操作Hive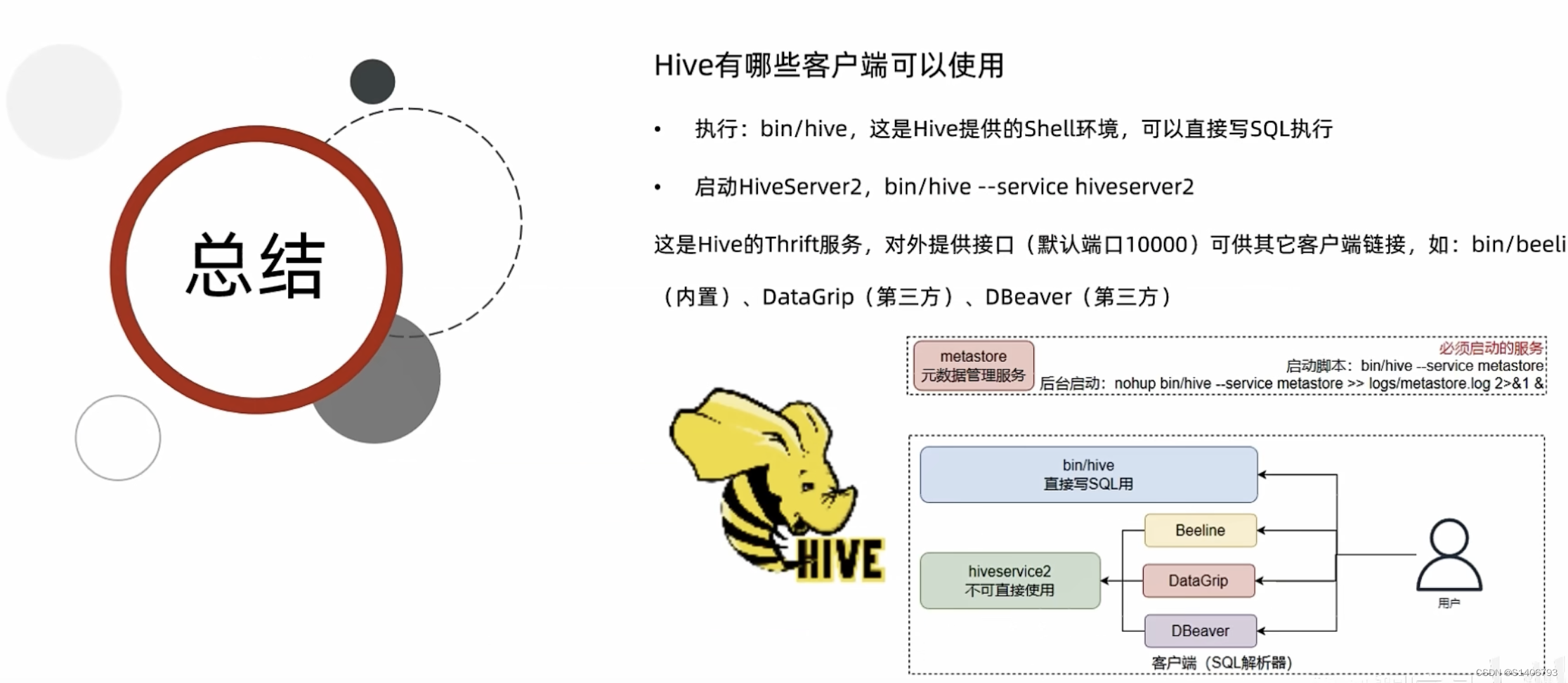
6.2 DataGrip & DBeaver
目标:掌握使用DataGrip链接Hive使用;掌握使用DBeaver链接Hive使用
第四章-09-[实操]DataGrip&DBeaver连接HiveServer2使用_哔哩哔哩_bilibili
版权归原作者 S1406793 所有, 如有侵权,请联系我们删除。