
一、collect_set() /collect_list()介绍
collect_set()函数与collect_list()函数属于高级聚合函数(行转列),将分组中的某列转换成一个数组返回,常与concat_ws()函数连用实现字段拼接效果。
- collect_list:收集并形成list集合,结果不去重
- collect_set:收集并形成set集合,结果去重
二、collect_set() /collect_list()有序性
0 问题描述
有一张用户关注表table20,需求:根据用户user_id分组,按照粉丝关注的时间升序排序,输出粉丝id数组和粉丝关注的时间数组,并保障两个数组的数据能一一对应。
1 数据准备
create table if not exists table20 (
user_id int comment '用户id',
follow_user_id int comment '粉丝id',
update_time string comment '粉丝关注的时间'
) comment '用户关注表';
insert overwrite table table20 values
(1, 101,'2021-09-30 10:12:00'),
(1, 103,'2021-10-01 11:00:00'),
(1, 104,'2021-11-02 10:00:00'),
(1, 103,'2021-11-28 10:22:00'),
(2, 104,'2021-11-02 10:11:00'),
(2, 100,'2021-11-03 10:21:00'),
(1, 99,'2021-11-23 12:28:00');
2 数据分析
方式一: row_number() over(partition by .. order by..) as rn 排序,然后再使用collect_list()/collect_set()进行聚合.
select
user_id,
concat_ws('|', collect_list(cast(follow_user_id as string))) as fui,
concat_ws('|', collect_list(update_time)) as ut
from (select
user_id,
follow_user_id,
update_time,
row_number() over (partition by user_id order by update_time) rn
from table20) tmp1
group by user_id;

发现问题:ut数组内的时间并没有按照升序排序输出。
原因分析:
- HiveSQL执行时,底层转换成MR任务执行,当同时开启多个mapper任务时,mapper1可能处理的user_id是 1,update_time排名为1,2,3的数据,mapper2可能处理的user_id是1,update_time排名为4,5的数据。
- collect_list()的底层是arrayList 来实现的,当put到arrayList集合时,无法知道是哪个mapper先计算完,所以可能会出现ArrayList集合中的数据顺序与原来数据插入的顺序不对齐的情况。因此:row_number() over(partition by .. order by ..) 与collect_list一起使用的时候,只能是实现局部有序(单个mapper的数据有序),不能实现全局有序。
解决方案:
方案一:使用distribute by + order by
select
user_id,
concat_ws('|', collect_list(cast(follow_user_id as string))) as fui_list,
concat_ws('|', collect_list(update_time)) as ut_list
from (select
user_id,
follow_user_id,
update_time,
row_number() over (partition by user_id order by update_time ) as rn
from (
select
user_id,
follow_user_id,
update_time
from table20
distribute by user_id sort by update_time
) tmp1) tmp2
group by user_id
order by user_id;


** 上述代码用到的函数:**
(1)concat_ws:带分隔符的字符串连接
语法: concat_ws(string SEP, string A, string B…)
select concat_ws('-','abc','def') // abc-def
(2)collect_list:收集并形成list集合,结果不去重
语法:select id, collect_list(likes) from student group by id;
(2)collect_set:收集并形成set集合,结果去重
语法:select id, collect_set(likes) from student group by id;
方案二:****sort_array(只支持升序)
select
user_id,
concat_ws(',', collect_list(cast(follow_user_id as string))) as fui,
concat_ws(',', sort_array(collect_list
(concat_ws('|', lpad(cast(rn as string), 2, '0'), update_time)))) as middle,
regexp_replace(concat_ws(',', sort_array(collect_list
(concat_ws('|', lpad(cast(rn as string), 2, '0'), update_time)))), '\\d+\\|', '') as ut
from (select
user_id,
follow_user_id,
update_time,
rn
from (
select
user_id,
follow_user_id,
update_time,
row_number() over (partition by user_id order by update_time ) as rn
from table20
) tmp1
order by rn) tmp2
group by user_id
order by user_id
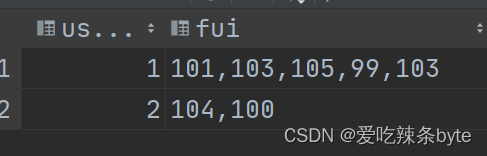
middle字段值的结果:

ut字段值的结果:

select regexp_replace('04|','\\d+\\|','*') --> *
正则表达式:\\d+代表所有数字字符
上述代码用到的函数:
(一)lpad / rpad:左/右补足函数
语法:lpad(string str, int len,string pad) / rpad(string str, int len, string pad)
参数说明:
第一个参数:要补齐的字符串
第二个参数:补齐之后字符串的总位数
第三个参数:从左边/右边填充的字符, lpad代表从左边填充;rpad代表从右边填充
举例:
select lpad('abc',5,'fg') --> fgabc
select rpad('abc',7,'df') --> abcdfdf
因为sort_array 是按照顺序对字符进行排序(例如11会排在2前面),所以可以使用函数lpad补位(将原来的1,2,3,4 转换成 01,02,03,04),然后再正常排序
(二)regexp_replace : 字符串替换
语法:regexp_replace(string initial_string, string pattern, string replacement)
参数说明:
initial_string为要替换的字符串,
pattern为匹配字符串的正则表达式,
replacement为要替换为的字符串。
简述: regexp_replace (StrA,StrB,StrC) 函数:将字符串A中的符合java正则表达式B的部分替换成C
(三)sort_array : 数组排序函数
语法:sort_array(array, [asc|desc]) : 按照指定的排序规则对数组进行排序,并返回一个排好序的新数组
参数说明:
第一个参数:array为需要排序的数组,
第二个参数:asc为可选参数,如果设置为true则按升序排序;desc为可选参数,如果设置为true,则按降序排序。如果既不设置asc也不设置desc,则按升序排序
举例:
select sort_array(array(2, 5, 3, 1)) as sorted_array; ---> [1,2,3,5]
select sort_array(array(2, 5, 3, 1), true, true) as sorted_array; ---> [5,3,2,1]
3 小结
本文转载自: https://blog.csdn.net/SHWAITME/article/details/136011647
版权归原作者 爱吃辣条byte 所有, 如有侵权,请联系我们删除。
版权归原作者 爱吃辣条byte 所有, 如有侵权,请联系我们删除。