
前言👀~
上一章我们介绍了CRUD的一些基础操作,关于如何在表里进行增加记录、查询记录、修改记录以及删除记录的一些基础操作,今天我们学习CRUD(增删改查)进阶操作
如果各位对文章的内容感兴趣的话,请点点小赞,关注一手不迷路,如果内容有什么问题的话,欢迎各位评论纠正 🤞🤞🤞
个人主页:N_0050-CSDN博客
相关专栏:java SE_N_0050的博客-CSDN博客 java数据结构_N_0050的博客-CSDN博客

数据库约束
含义:数据库,自动的对数据的合法性进行 校验检查 的一系列机制,目的就是为了保证数据
库中能够 避免 被插入/修改 一些非法的数据

not null
这一列不能填null值(相当于必填项),并且插入和修改都会被限制
create table 表名(列名 类型 not null,列名 类型....);
创建

插入
当我们进行插入发现会报错,因为我们设置了id这一列不能为空

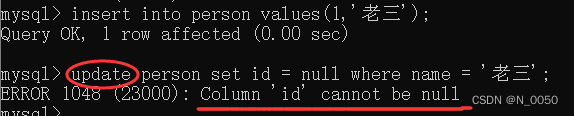
修改
当我们进行修改的时候也会报错,也是因为我们设置了id这一列不能为空
unique
相当于填写的值不能重复,并且插入和修改都会被限制,且会让后续的 插入和修改数据 的时候,都会先触发一次 查询 的操作(通过这个查询,来确定当前这个记录是否已经存在)
create table 表名(列名 类型 unique,列名 类型...);
创建

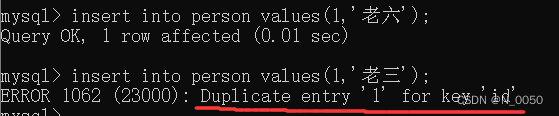
插入
我们先插入一条数据,然后再插入一条数据但是id跟上一次插入的id一样,发现报错了,结合上面说的后续的插入和修改数据的时候,都会先触发一次 查询的操作,通过这个查询,来确定当前这****个记录是否已经存在
default
没有给列赋值时,就按默认值进行插入
create table 表名(列名 类型 default '你想默认值显示什么就填什么' ,列名 类型...);
一般没赋值的话,默认都是null
创建

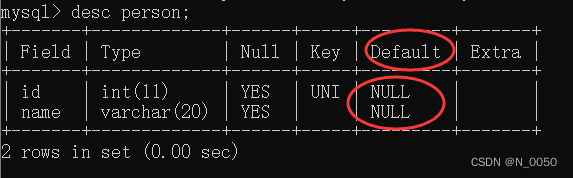
查看表结构
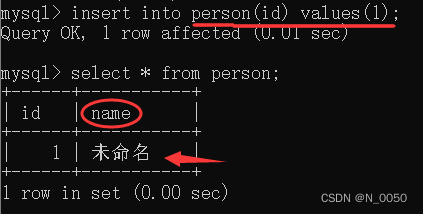
查看表结构的时候,我们会发现name这列default默认值是未命名
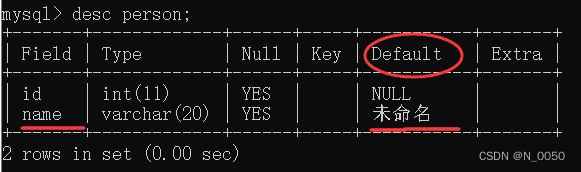
查询
当我们只对id列插入数据,去查询发现我们的name这列这行的默认值是我们刚才设置的
primary key(主键,最重要的约束)
确保列有唯一标识,例如我们的身份证,在填写的时候不能为空且不能重复,**相当于是 not null ****和 **unique 的结合
create table 表名(列名 类型 primary key,列名 类型);
创建

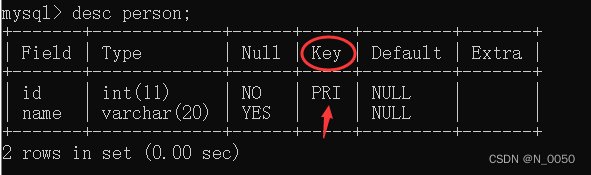
查看表结构
插入
我们先插入一条数据,第二次插入同样的id会报错,原因是id设置为主键了,值不能重复

如何保证主键唯一呢?
mysql提供了一种“自增主键”这样的机制
create table 表名(列名 类型 primary key auto_increment,列名 类型);
创建

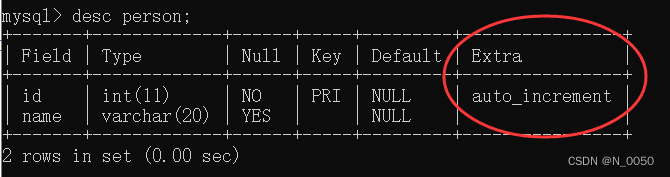
查看表结构
插入
我们在插入数据的时候id列设为空,查询的时候会发现它会进行自增
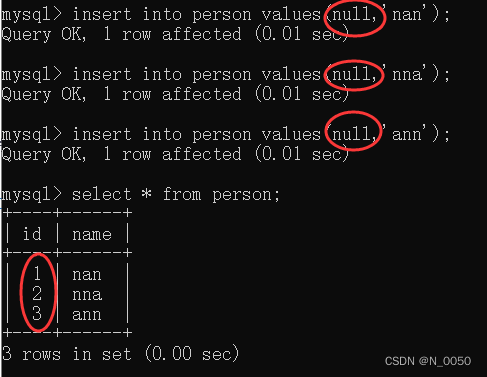
插入的时候从 刚才的最大值 开始,继续往后分配的
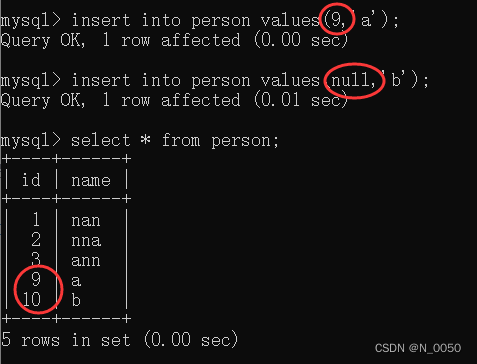
补充:
这里的id的自动分配,有一定的局限性,如果是单个mysql服务器,没什么问题
如果是一个分布式系统,有多个mysql服务器构成的集群,这个时候依靠 自增主键 就不行了
分布式系统:面临的数据量大(大数据),客户端的请求量(高并发)比较大,一台
服务器搞不定就需要多台机器(分布式)
注意:
一张表里只能有 一个primary key(主键)
虽然只能有一个 主键,但是主键不一定只是一个列,也可以用多个列共同构造一个主键(联合主键)
主键经常会使用 int / bigint
对于带有主键的表来说,每次 插入和修改数据,也会涉及到先触发查询的操作
mysql会把带有 unique 和 primary key 的列自动生成 索引(后续会讲到),从而加快查询速度
foreign key(外键)
保证一个表中的数据匹配另一个表中的值的参照完整性
一个表可以有多个外键,但是只能有一个主键!!!
create table 表名(列名 类型 ,foreign key 列名,列名 类型...,references 另一张表名(列名));
没有设置外键的演示
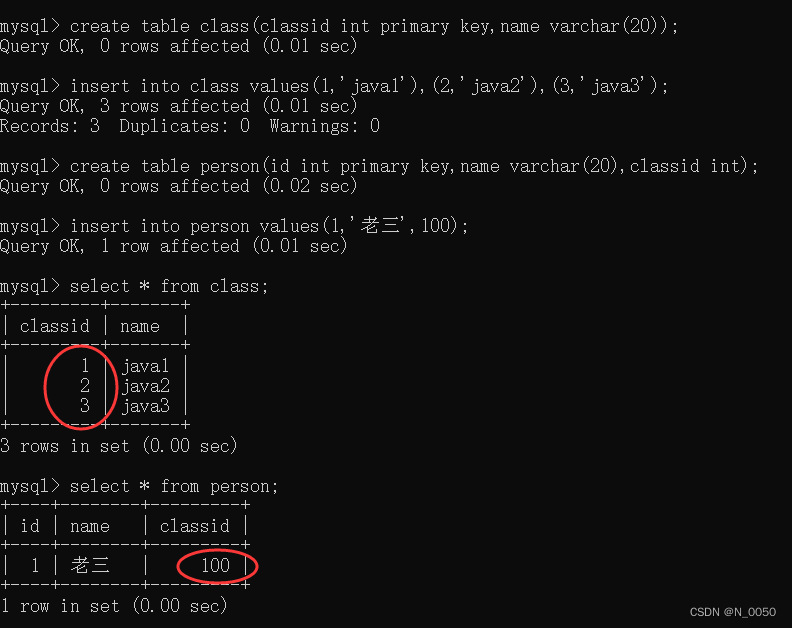
我们会发现没有设置外键的话,我们在person表里可以插入这条数据,即使在class表里没有存在classid为100的数据
接下来是设置外键的演示
references 此处表示了当前这个表的这一列中的数据,应该出自于另一个表的哪一列
创建

插入和修改
当我们指定了外键的时候,在插入数据和修改数据的时候都会去做出校验,可以理解为父表约束子表


对父表进行删除或修改操作
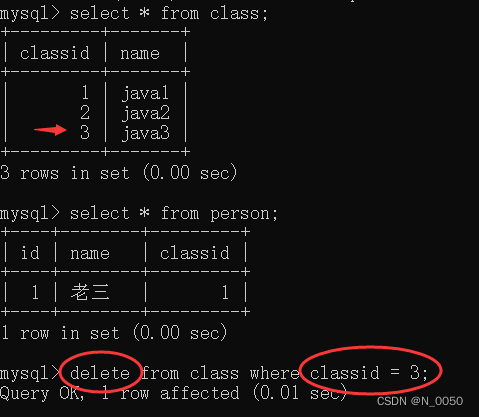

结合上面的操作我们可以理解为两个进行捆绑了的意思一样,比如我们都有的数据不能进行乱动,比如插入、修改、删除等操作,你有我没有的这没什么关系
外键准确来说,是两个表的 列产生关联联系,其他的列是不受影响的!!!
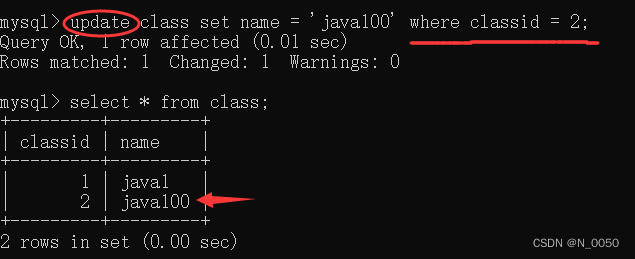
即使用到了,但是不相同的列不受影响
删除父表时,必须先删除子表,否则父表无法删除!!!
错误演示

正常演示
指定外键约束时,要求父表中被关联的这一列,得是 主键 或者 unique(外键用于关联其他表的主键或唯一键)

表的设计
根据实例的需求场景,明确当前要创建几个表,每个表什么样子,这些表之间是否存在一定联系
1.梳理清楚 需求中的“实体”(就是说过的“对象”=>需求中的关键性名词)
一般来说,每个实体,都需要安排一个表,表的列就对应到实体的各个属性
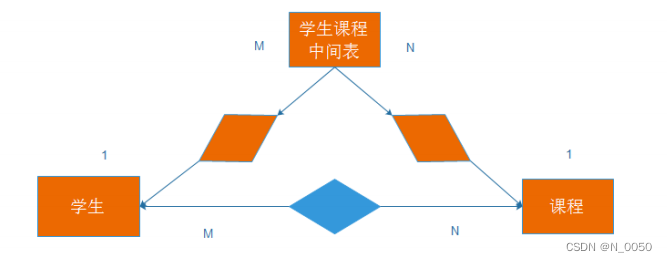
2.再确定好 “实体”之间的关系
一对一:

一对多:
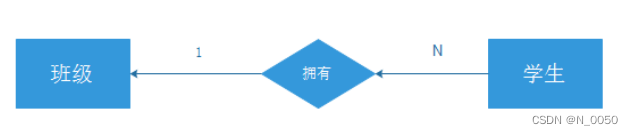
多对多:
查询操作的进阶
查询可以搭配 插入 使用(把查询语句的查询结果,作为插入的数值)
简单点说就是把你在 另外一张表查询出来的结果,插入到你 指定的表 中
insert into 表1 select * from 表2;
先准备两张表
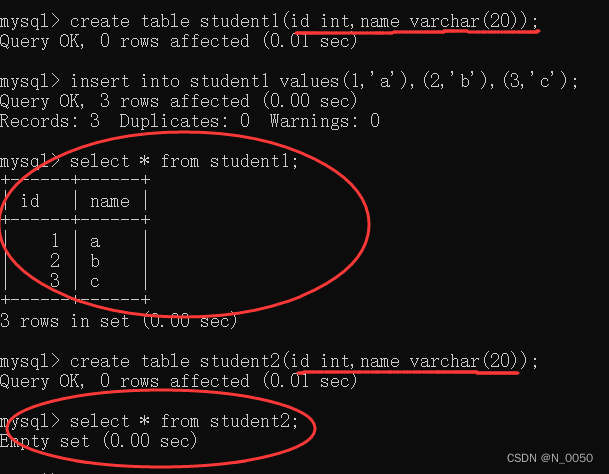
接着我们插入
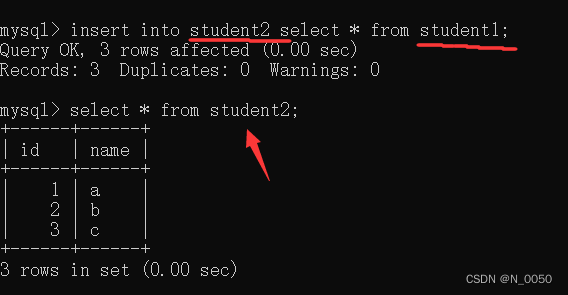
注意:
此处,要求查询出来的结果集合,列数和类型 要和插入的这个表匹配
聚合查询
聚合查询,相当于是在 行 和 行 之间进行运算了
sql中提供了一些“聚合函数”通过聚合函数来完成上述行之间的运算
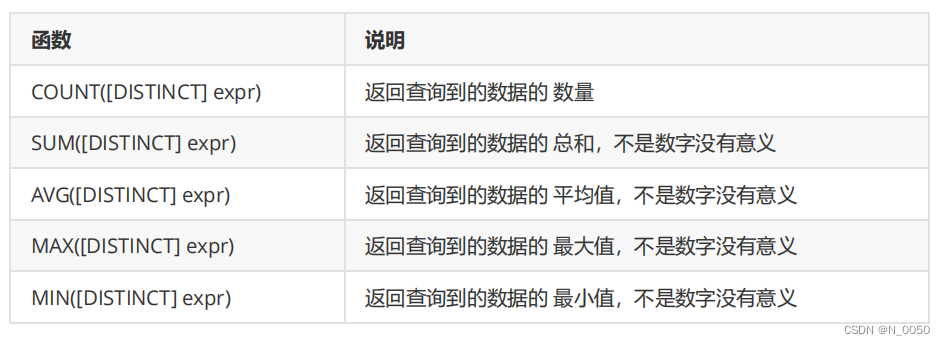
以下这些“聚合函数”要求务必对数字类型进行操作,如果对字符串类型进行操作,会强转成double执行后续的操作
count
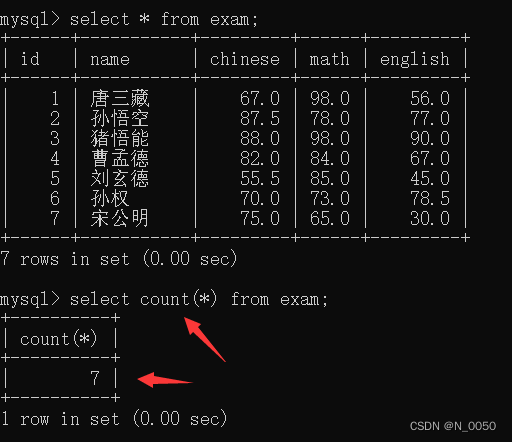
select count(列名) from 表名;
用法
指定列
这里即使我插入一条数据,还是 name这一列 还是只统计了7条,因为有null值会被排除掉
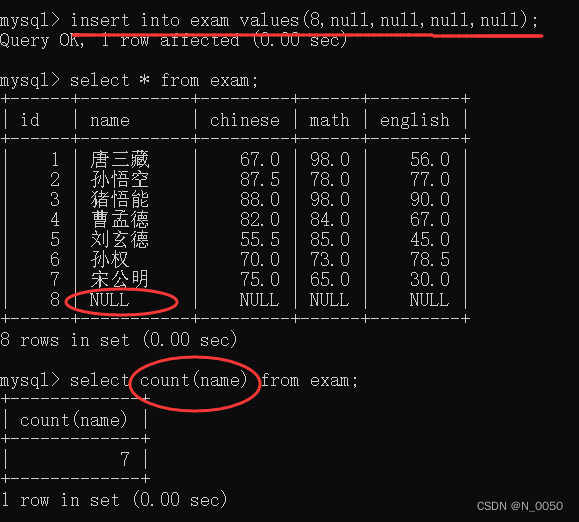
搭配去重使用
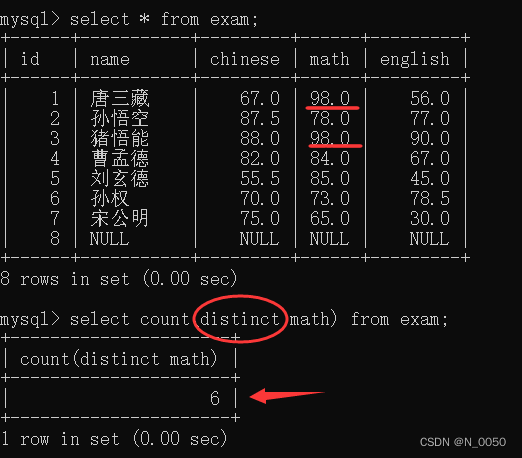
注意格式:

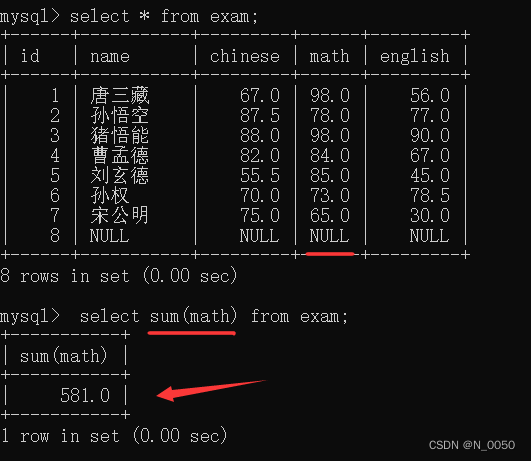
sum
把这一列的 若干行,进行求和(算术运算,只针对数字类型使用)
select sum(列名,列名...) from 表名;
用法
同样有null值会被排除掉
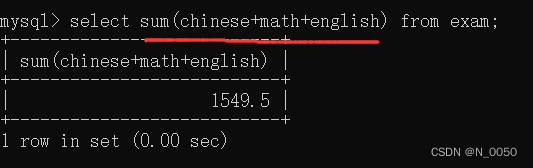
对表达式进行相加
avg:求平均值

max:求最大值

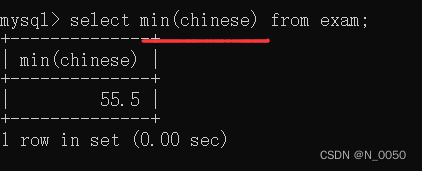
min:求最小值
group by(分组查询)
使用 group by 进行分组(针对指定的列进行分组,把这一列中,值相同的行,分到同一组中,得到若干个组),针对每个分组,再分别进行聚合查询
select 列名,列名... from 表名 group by 列名,列名;
演示

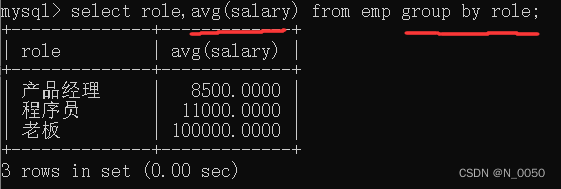
查询每个role对应的平均薪资
根据role这一列进行分组,针对分出来的每一个组再使用avg函数
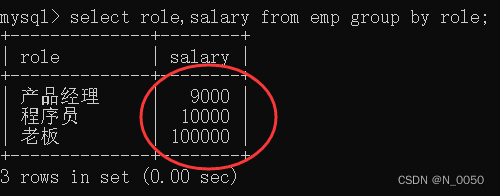
如果针对分组之后,不使用聚合函数,此时的结果就是查询出每一组的某个代表数据
使用group by的时候,还可以搭配条件
比如我们查询每个岗位的平均工资,排除老三

having
group by子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用 WHERE 语句,而需要用having
select 列名,列名... from 表名 group by 列名,列名 having 条件;
使用having描述条件,having一般写在group by的后面
这里我们演示搭配where和having进行查询

联合查询/多表查询
对比之前的查询,则是一次性对多个表中进行查询
多表查询是对多张表的数据取笛卡尔积
笛卡尔积 工作过程:
1.笛卡尔积的列数,是这两个表的列数相加
2.笛卡尔积的行数,是这两个表的行数相乘
笛卡尔积就是多表查询的基础,多表查询在笛卡尔积的基础上再去进行数据的筛选!
内连接
select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其他条件;
select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其他条件;
查看表结构
我们去查询 许仙同学的成绩
1.先进行笛卡尔积(数据太多,就展示这些后面慢慢筛选掉)
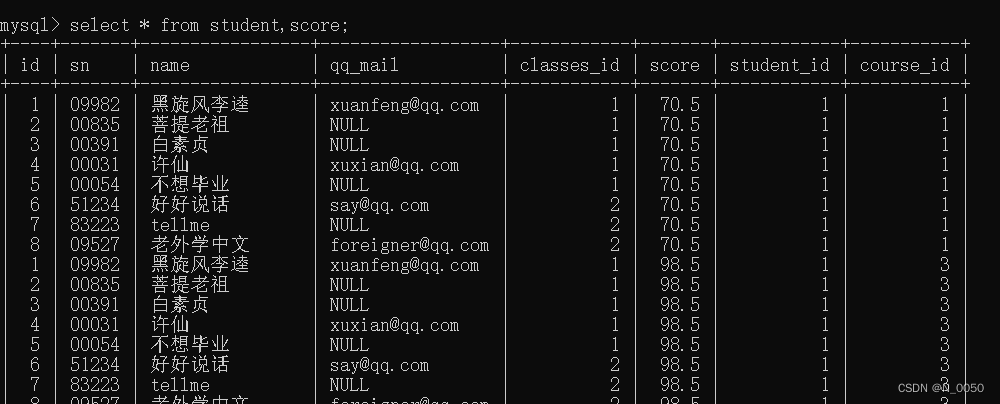
2.下一步加上连接条件,这里刚好是没有重复的列,如果这个id也叫student_id就会出现重复的列,会有问题,所以要这样写 表名.列名 类似java对象访问成员

3.添加条件进行筛选

4.对列进行精简

我们去查询所有同学的总成绩,及同学的个人信息
**同样我们进行笛卡尔积,然后加上连接条件 **

然后进行分组,不加 group by

加group by
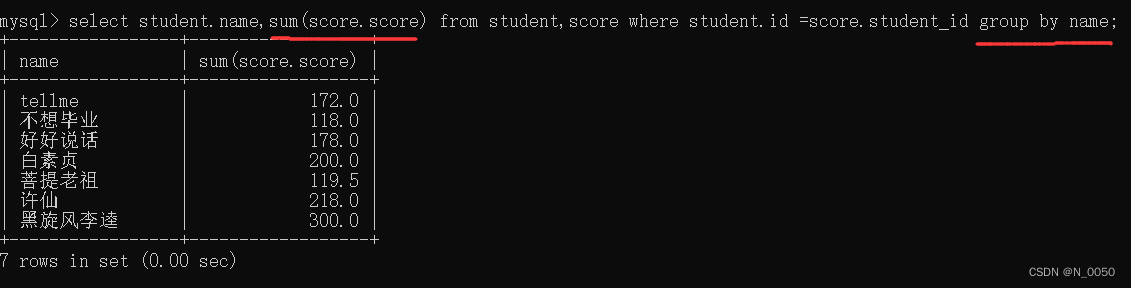
我们会发现不加group by都算到一个人头上了,加了group by就是每个同学对应的总成绩
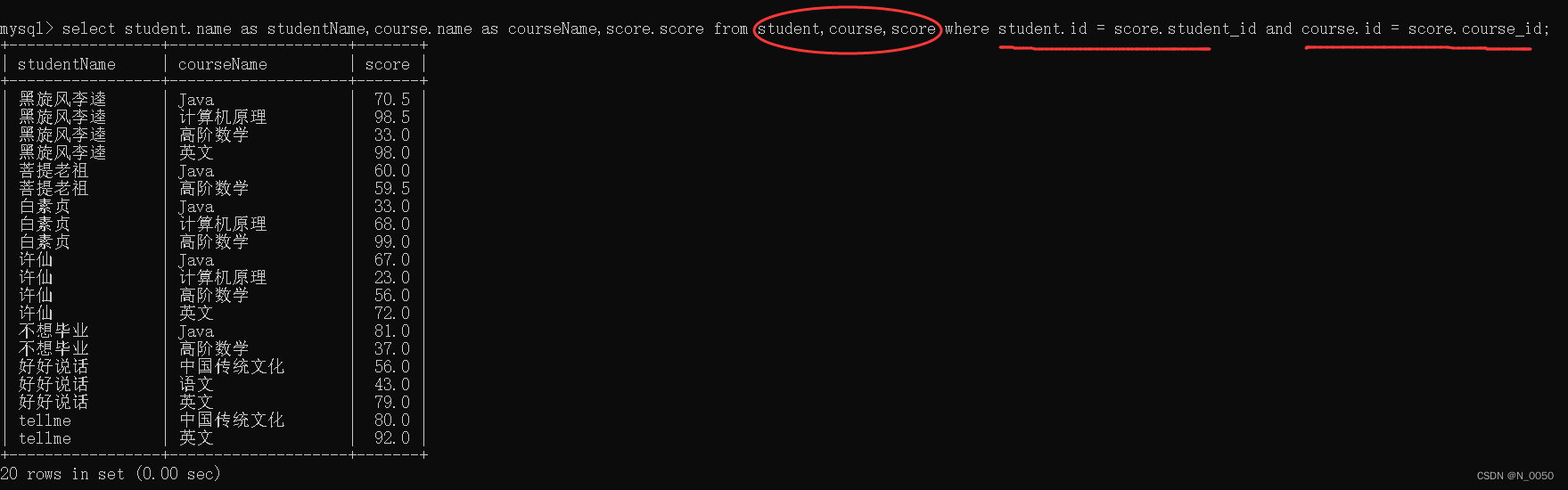
查询每个同学,每门课程课程名字和分数
同样要先笛卡尔积,并且加上连接条件,这里涉及到三张表,需要两个连接条件

然后选择要显示的列
外连接
外连接分为 左外连接 和 右外连接。如果联合查询,左侧的表完全显示我们就说是左外连接;右侧的表完全显示我们就说是右外连接。
首先我们先创建两张表然后进行连接
左外连接:
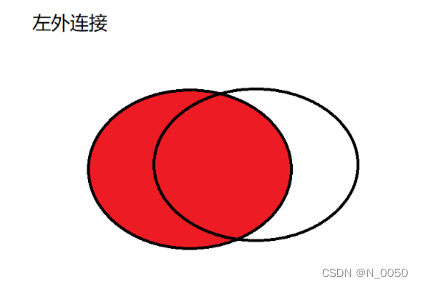
以左侧表为基准,保证左侧表的每个数据都会出现在最终结果里,如果在右侧表中不存在,对应的列就填成null
-- 左外连接,表1完全显示
select 字段名
from 表名1 left join 表名2 on 连接条件;
右外连接:
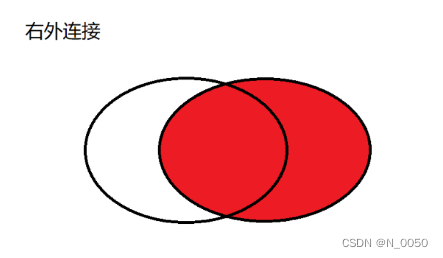
以右侧表为基准,保证右侧表的每个数据都会出现在最终结果里,如果在左侧表中不存在,对应的列就填成null
-- 右外连接,表2完全显示
select 字段 from 表名1 right join 表名2 on连接条件;

全外连接:

自连接
自连接是指在同一张表连接自身进行查询
select * from 表 a1, 表 a2 where a1.id=a2.id;
显示所有“计算机原理”成绩比“Java”成绩高的成绩信息
就是同一张表,自己对自己先进行笛卡尔积,并且注意要为这两个表 命一个别名,as可加可不加
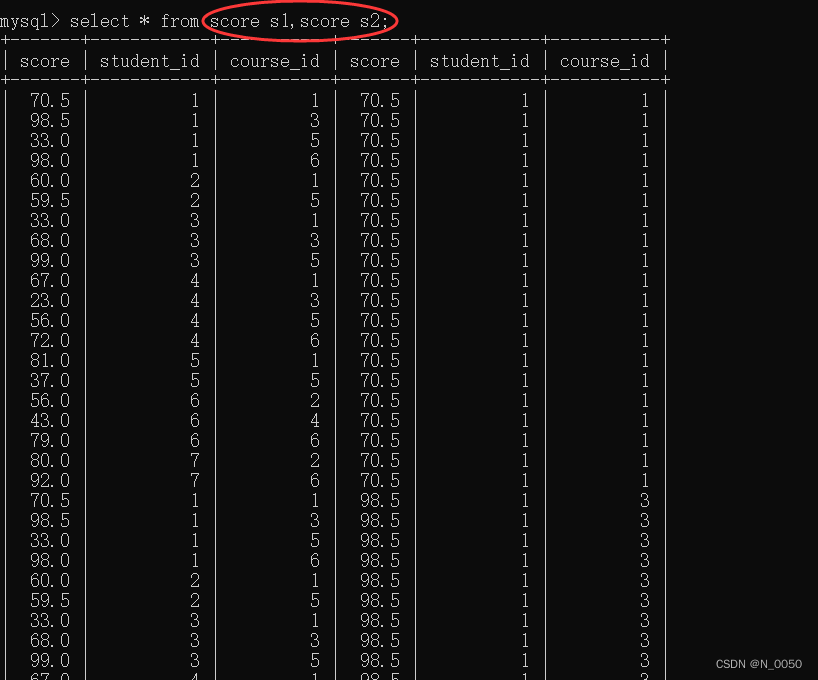
接着加上连接条件,以及我们要求的条件

最后挑选出要显示的列

我们进行优化显示学生的所有信息以及课程名

子查询
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询
select 列名 from 表名 where 列名 =、>、<、in等 (select 列名 from 表名 where 条件);
单行子查询:返回一行记录的子查询
例题:查询与“不想毕业” 同学的同班同学
1.先在student表找出不想毕业同学在哪个班

2.接着在student表找出不想毕业的同班同学

3.接下来就是子查询的关键了,我们把id=1换成我们第一次查询的结果

多行子查询:返回多行记录的子查询
例题:查询“语文”或“英文”课程的成绩信息
1.同样第一步我们在course表找出 语文或英文 的id

2.接着联表查询出语文或英文的成绩信息

3.同样我们把 in 后面的条件替换成一开始查询的结果

合并查询
把多个sql查询的结果集合,合并到一起
select 列名 from 表名 unionselect 列名 from 表名;
例题:查询id小于3,或者名字为“英文”的课程
一般我们的做法是如下

但是 or 只能针对一个表,使用 union 允许两个不同的表,查询结果合并到一起,但是合并的sql的结果集的 列 要匹配,列的个数和类型要一致

union all:
当我们使用 union 的时候发现,它会去重

我们去使用 union all,发现会取消去重

到这就结束了增删改查的进阶操作,知识点还是非常之多,一下子可能消化不了,需要慢慢细品,希望各位能看得懂并且理解进去,我们下一章再见💕
版权归原作者 N_0050 所有, 如有侵权,请联系我们删除。