
1.8.5.6 ALTER TABLE 分区操作
alter 分区操作包括增加分区和删除分区操作,这种分区操作在Spark3.x之后被支持,spark2.4版本不支持,并且使用时,必须在spark配置中加入spark.sql.extensions属性,其值为:org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,在添加分区时还支持分区转换,语法如下:
- 添加分区语法:ALTER TABLE ... ADD PARTITION FIELD
- 删除分区语法:ALTER TABLE ... DROP PARTITION FIELD
具体操作如下:
- 创建表mytbl,并插入数据
val spark: SparkSession = SparkSession.builder().master("local").appName("SparkOperateIceberg")
//指定hadoop catalog,catalog名称为hadoop_prod
.config("spark.sql.catalog.hadoop_prod", "org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.hadoop_prod.type", "hadoop")
.config("spark.sql.catalog.hadoop_prod.warehouse", "hdfs://mycluster/sparkoperateiceberg")
.config("spark.sql.extensions","org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions")
.getOrCreate()
//1.创建普通表
spark.sql(
"""
| create table hadoop_prod.default.mytbl(id int,name string,loc string,ts timestamp) using iceberg
""".stripMargin)
//2.向表中插入数据,并查询
spark.sql(
"""
|insert into hadoop_prod.default.mytbl values
|(1,'zs',"beijing",cast(1608469830 as timestamp)),
|(3,'ww',"shanghai",cast(1603096230 as timestamp))
""".stripMargin)
spark.sql("select * from hadoop_prod.default.mytbl").show()
在HDFS中数据存储和结果如下:
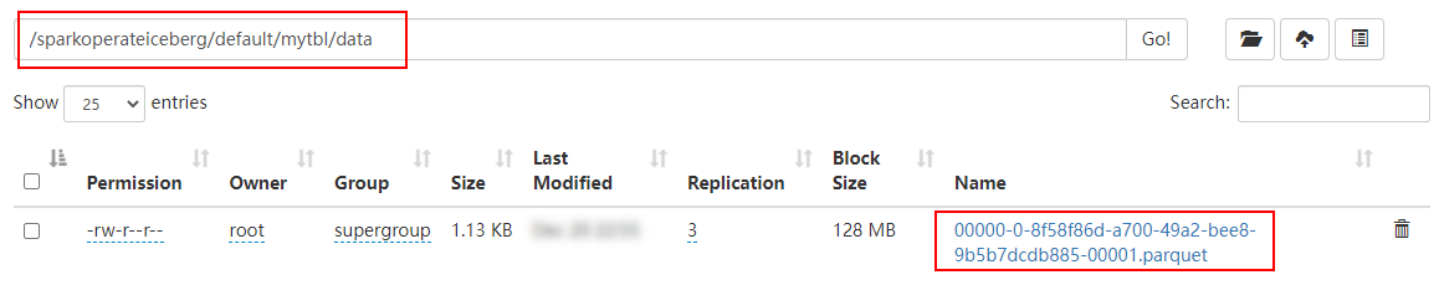

- 将表loc列添加为分区列,并插入数据,查询
//3.将 loc 列添加成分区,必须添加 config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") 配置
spark.sql(
"""
|alter table hadoop_prod.default.mytbl add partition field loc
""".stripMargin)
//4.向表 mytbl中继续插入数据,之前数据没有分区,之后数据有分区
spark.sql(
"""
|insert into hadoop_prod.default.mytbl values
|(5,'tq',"hangzhou",cast(1608279630 as timestamp)),
|(2,'ls',"shandong",cast(1634559630 as timestamp))
""".stripMargin )
spark.sql("select * from hadoop_prod.default.mytbl").show()
在HDFS中数据存储和结果如下:
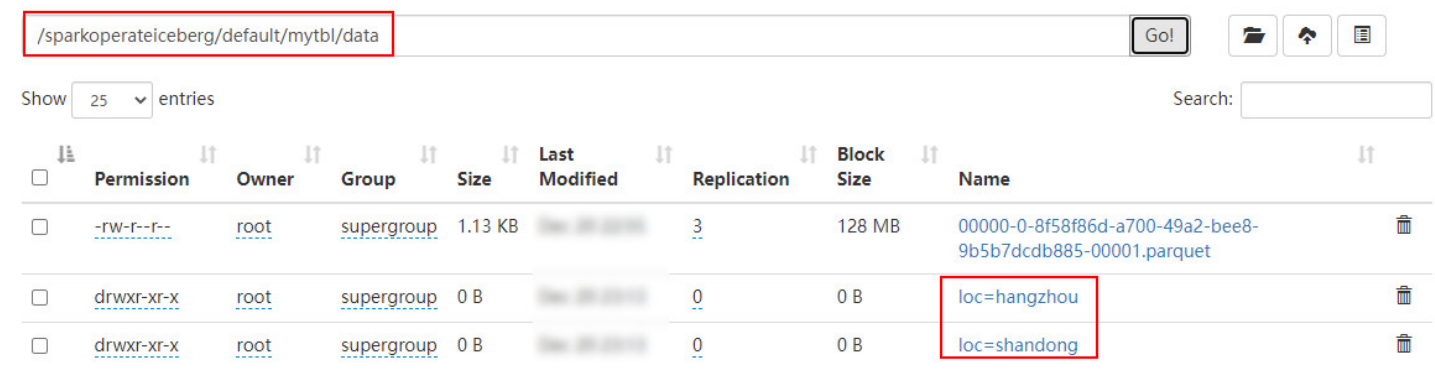

注意:添加分区字段是元数据操作,不会改变现有的表数据,新数据将使用新分区写入数据,现有数据将继续保留在原有的布局中。
我的测试:
测试代码:
package com.shujia.spark.iceberg
import org.apache.spark.sql.SparkSession
object AlterTablePartition {
def main(args: Array[String]): Unit = {
/**
* alter 分区操作包括增加分区和删除分区操作,这种分区操作在Spark3.x之后被支持,spark2.4版本不支持,并且使用时,
* 必须在spark配置中加入spark.sql.extensions属性,
* 其值为:org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,在添加分区时还支持分区转换,语法如下:
* 添加分区语法:ALTER TABLE ... ADD PARTITION FIELD
* 删除分区语法:ALTER TABLE ... DROP PARTITION FIELD
*
*/
val spark: SparkSession = SparkSession
.builder()
.appName("SparkOperateIceberg")
//指定hive catalog, catalog名称为hive_prod
.config("spark.sql.catalog.hive_prod", "org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.hive_prod.type", "hive")
.config("spark.sql.catalog.hive_prod.uri", "thrift://master:9083")
.config("iceberg.engine.hive.enabled", "true")
// 将 loc 列添加成分区,必须添加
.config("spark.sql.extensions","org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions")
.enableHiveSupport()
.getOrCreate()
//1.创建普通表
spark.sql(
"""
| create table if not exists hive_prod.iceberg.repartition1
| (id int,name string,loc string,ts timestamp) using iceberg
|
""".stripMargin)
//2.向表中插入数据,并查询
spark.sql(
"""
|insert into hive_prod.iceberg.repartition1 values
|(1,'zs',"beijing",cast(1608469830 as timestamp)),
|(3,'ww',"shanghai",cast(1603096230 as timestamp))
|
""".stripMargin)
spark.sql("select * from hive_prod.iceberg.repartition1").show()
//3.将 loc 列添加成分区,必须添加 config("spark.sql.extensions",
// "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") 配置
spark.sql(
"""
|alter table hive_prod.iceberg.repartition1 add partition field loc
|
""".stripMargin)
//4.向表 mytbl中继续插入数据,之前数据没有分区,之后数据有分区
spark.sql(
"""
|insert into hive_prod.iceberg.repartition1 values
|(5,'tq',"hangzhou",cast(1608279630 as timestamp)),
|(6,'xx',"hangzhou",cast(1608279631 as timestamp)),
|(2,'ls',"shandong",cast(1634559632 as timestamp))
|
""".stripMargin )
spark.sql("select * from hive_prod.iceberg.repartition1").show()
//spark 提交任务的命令
//spark-submit --master yarn --class com.shujia.spark.iceberg.AlterTablePartition spark-1.0.jar
}
}

- 将ts列进行转换作为分区列,插入数据并查询
//5.将 ts 列通过分区转换添加为分区列
spark.sql(
"""
|alter table hadoop_prod.default.mytbl add partition field years(ts)
""".stripMargin)
//6.向表 mytbl中继续插入数据,之前数据没有分区,之后数据有分区
spark.sql(
"""
|insert into hadoop_prod.default.mytbl values
|(4,'ml',"beijing",cast(1639920630 as timestamp)),
|(6,'gb',"tianjin",cast(1576843830 as timestamp))
""".stripMargin )
spark.sql("select * from hadoop_prod.default.mytbl").show()
在HDFS中数据存储和结果如下:

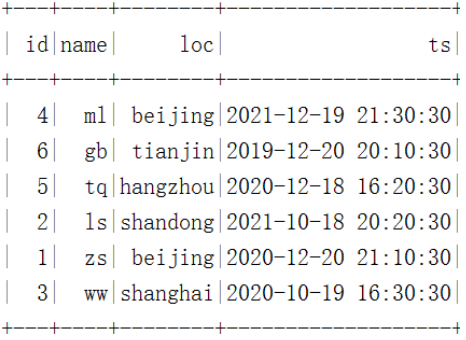
我的测试,在一级分区的基础上再次添加分区
测试代码:
package com.shujia.spark.iceberg
import org.apache.spark.sql.SparkSession
object AlterTable2Partitions {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession
.builder()
.appName("SparkOperateIceberg")
//指定hive catalog, catalog名称为hive_prod
.config("spark.sql.catalog.hive_prod", "org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.hive_prod.type", "hive")
.config("spark.sql.catalog.hive_prod.uri", "thrift://master:9083")
.config("iceberg.engine.hive.enabled", "true")
// 将 loc 列添加成分区,必须添加
.config("spark.sql.extensions","org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions")
.enableHiveSupport()
.getOrCreate()
//5.将 ts 列通过分区转换添加为分区列
spark.sql(
"""
|alter table hive_prod.iceberg.repartition1 add partition field years(ts)
""".stripMargin)
//6.向表 mytbl中继续插入数据,之前数据没有分区,之后数据有分区
spark.sql(
"""
|insert into hive_prod.iceberg.repartition1 values
|(4,'ml',"beijing",cast(1639920630 as timestamp)),
|(4,'mm',"beijing",cast(1639920639 as timestamp)),
|(6,'gb',"tianjin",cast(1576843830 as timestamp))
|
""".stripMargin )
spark.sql("select * from hive_prod.iceberg.repartition1").show()
//spark 提交任务的命令
//spark-submit --master yarn --class com.shujia.spark.iceberg.AlterTable2Partitions spark-1.0.jar
}
}

- 删除分区loc
//7.删除表 mytbl 中的loc分区
spark.sql(
"""
|alter table hadoop_prod.default.mytbl drop partition field loc
""".stripMargin)
//8.继续向表 mytbl 中插入数据,并查询
spark.sql(
"""
|insert into hadoop_prod.default.mytbl values
|(4,'ml',"beijing",cast(1639920630 as timestamp)),
|(6,'gb',"tianjin",cast(1576843830 as timestamp))
""".stripMargin )
spark.sql("select * from hadoop_prod.default.mytbl").show()
在HDFS中数据存储和结果如下:
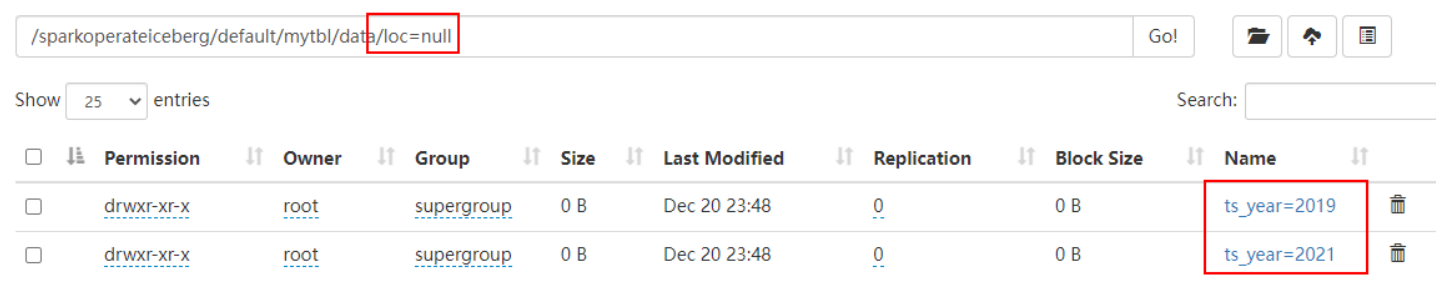
注意:由于表中还有ts分区转换之后对应的分区,所以继续插入的数据loc分区为null
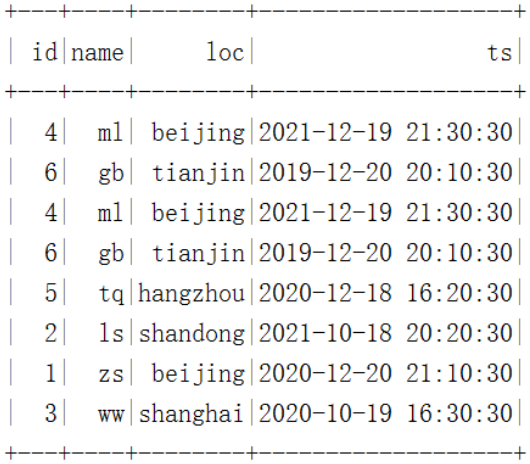
我的测试
测试代码:
package com.shujia.spark.iceberg
import org.apache.spark.sql.SparkSession
object DeleteTablePartition {
def main(args: Array[String]): Unit = {
/**
*
* 删除一个分区
*
*/
val spark: SparkSession = SparkSession
.builder()
.appName("SparkOperateIceberg")
//指定hive catalog, catalog名称为hive_prod
.config("spark.sql.catalog.hive_prod", "org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.hive_prod.type", "hive")
.config("spark.sql.catalog.hive_prod.uri", "thrift://master:9083")
.config("iceberg.engine.hive.enabled", "true")
// 将 loc 列添加成分区,必须添加
.config("spark.sql.extensions","org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions")
.enableHiveSupport()
.getOrCreate()
//7.删除表 mytbl 中的loc分区
spark.sql(
"""
|alter table hive_prod.iceberg.repartition1 drop partition field loc
""".stripMargin)
//8.继续向表 mytbl 中插入数据,并查询
spark.sql(
"""
|insert into hive_prod.iceberg.repartition1 values
|(4,'ml',"beijing",cast(1639920630 as timestamp)),
|(6,'gb',"tianjin",cast(1576843830 as timestamp))
|
""".stripMargin )
spark.sql("select * from hive_prod.iceberg.repartition1").show()
//spark 提交任务的命令
//spark-submit --master yarn --class com.shujia.spark.iceberg.DeleteTablePartition spark-1.0.jar
}
}

- 删除分区years(ts)
//9.删除表 mytbl 中的years(ts) 分区
spark.sql(
"""
|alter table hadoop_prod.default.mytbl drop partition field years(ts)
""".stripMargin)
//10.继续向表 mytbl 中插入数据,并查询
spark.sql(
"""
|insert into hadoop_prod.default.mytbl values
|(5,'tq',"hangzhou",cast(1608279630 as timestamp)),
|(2,'ls',"shandong",cast(1634559630 as timestamp))
""".stripMargin )
spark.sql("select * from hadoop_prod.default.mytbl").show()
在HDFS中数据存储和结果如下:

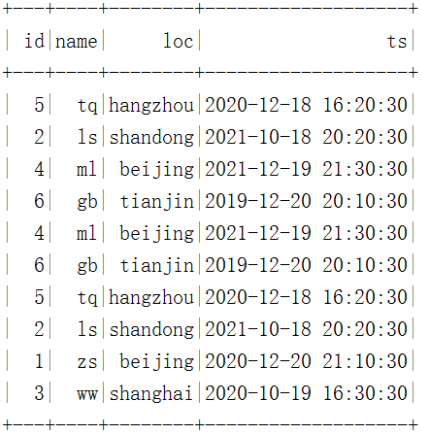
我的测试:
测试代码:
package com.shujia.spark.iceberg
import org.apache.spark.sql.SparkSession
object DeleteTable2Partitions {
def main(args: Array[String]): Unit = {
/**
*
* 删除一个分区之后再次删除一个分区
*
*/
val spark: SparkSession = SparkSession
.builder()
.appName("SparkOperateIceberg")
//指定hive catalog, catalog名称为hive_prod
.config("spark.sql.catalog.hive_prod", "org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.hive_prod.type", "hive")
.config("spark.sql.catalog.hive_prod.uri", "thrift://master:9083")
.config("iceberg.engine.hive.enabled", "true")
// 将 loc 列添加成分区,必须添加
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions")
.enableHiveSupport()
.getOrCreate()
//9.删除表 mytbl 中的years(ts) 分区
spark.sql(
"""
|alter table hive_prod.iceberg.repartition1 drop partition field years(ts)
""".stripMargin)
//10.继续向表 mytbl 中插入数据,并查询
spark.sql(
"""
|insert into hive_prod.iceberg.repartition1 values
|(5,'tq',"hangzhou",cast(1608279630 as timestamp)),
|(2,'ls',"shandong",cast(1634559630 as timestamp))
""".stripMargin )
spark.sql("select * from hive_prod.iceberg.repartition1").show()
//spark 提交任务的命令
//spark-submit --master yarn --class com.shujia.spark.iceberg.DeleteTable2Partitions spark-1.0.jar
}
}

本文转载自: https://blog.csdn.net/weixin_48370579/article/details/127813404
版权归原作者 a-tao必须奥利给 所有, 如有侵权,请联系我们删除。
版权归原作者 a-tao必须奥利给 所有, 如有侵权,请联系我们删除。