
参考链接
Spark编程: Spark SQL基本操作 2020.11.01_df.agg("age"->"avg")-CSDN博客
RDD编程初级实践-CSDN博客
Spark和Hadoop的安装-CSDN博客
Spark SQL 编程初级实践-CSDN博客
1. Spark SQL基本操作
{ "id":1 , "name":" Ella" , "age":36 }
{ "id":2, "name":"Bob","age":29 }
{ "id":3 , "name":"Jack","age":29 }
{ "id":4 , "name":"Jim","age":28 }
{ "id":4 , "name":"Jim","age":28 }
{ "id":5 , "name":"Damon" }
{ "id":5 , "name":"Damon" }
创建employee.json文件
sudo vim employee.json
cat employee.json

启动spark-shell
cd /usr/local/spark/
./bin/spark-shell
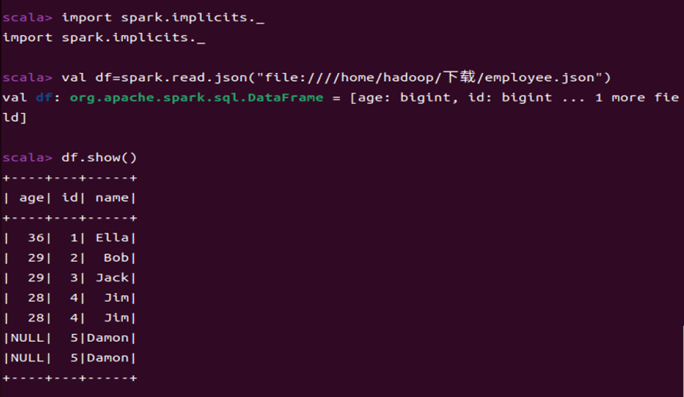
1.1 查询所有数据
import spark.implicits._
val df=spark.read.json("file:home/hadoop/下载/employee.json")
df.show()
import spark.implicits._是Spark的一个工具,帮助 我们将RDD 转换为DataFrame。
spark.read.json是 Apache Spark 中的一个方法,用于从 JSON 文件中读取数据并将其加载到 DataFrame 中。
df.show()用于显示DataFrame中的内容。
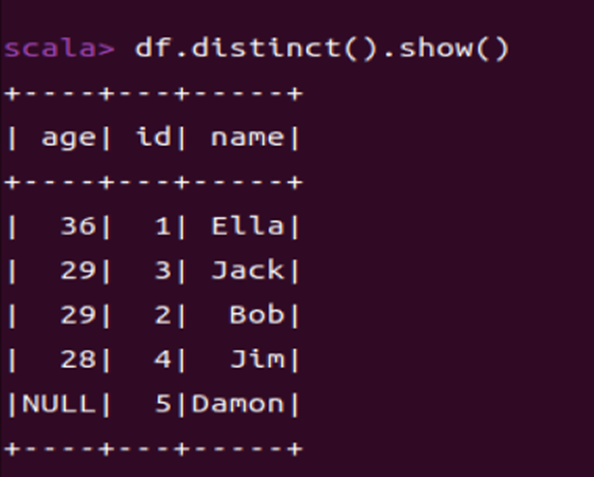
1.2 查询所有数据,并去除重复的数据
df.distinct().show()
** distinct()去重。**
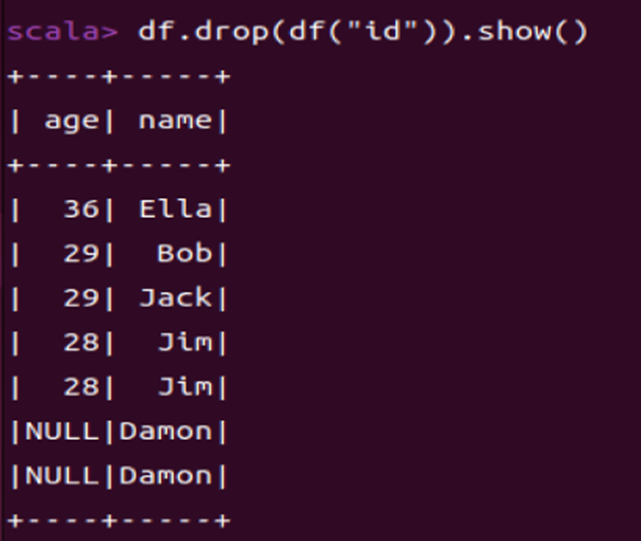
1.3 查询所有数据,打印时去除id字段
df.drop(df("id")).show()
** df.drop()用于删除DataFrame中指定的列。**
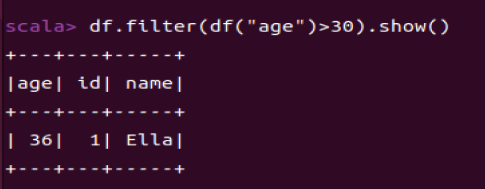
1.4 筛选出age>30的记录
df.filter(df("age")>30).show()
** df.filter()用于根据指定条件过滤DataFrame中的行。**
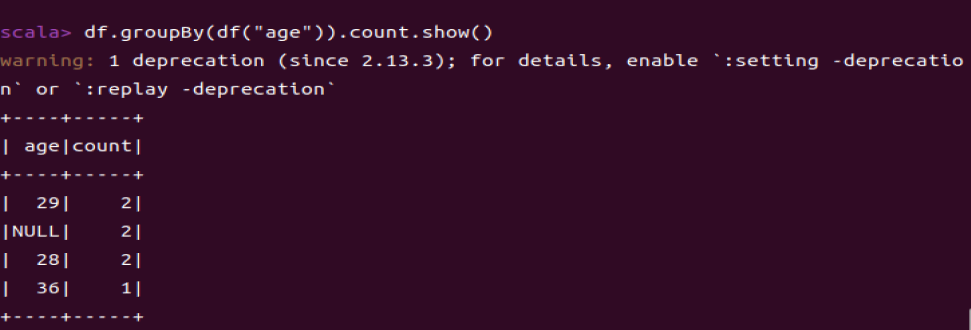
1.5 将数据按age分组
df.groupBy(df("age")).count.show()
df.groupBy()用于根据指定的列对DataFrame进行分组。
df.count().show()用于显示分组后的DataFrame的内容。
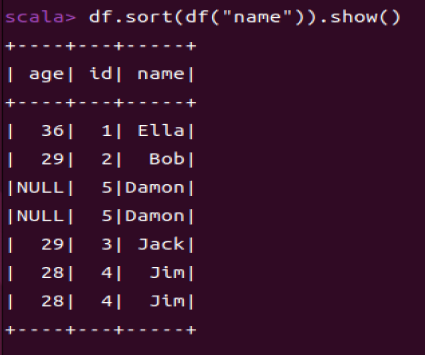
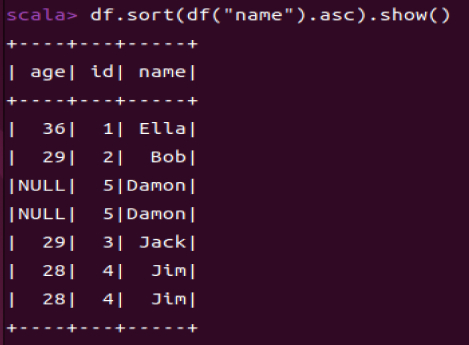
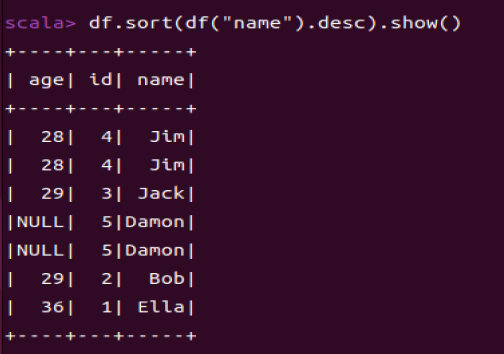
1.6 将数据按name升序排列
df.sort(df("name").asc).show()
df.sort()用于对DataFrame中的行进行排序(默认升序)。
升序asc
降序desc
这里“Ella”比“Bob”小是因为“Ella”字符串实际上是“ Ella”,所以他的第一个字符不是‘E’而是‘ ’,对应的ASCII,‘E’是69,‘B’是66,‘ ’是32.
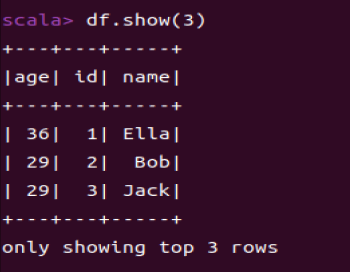
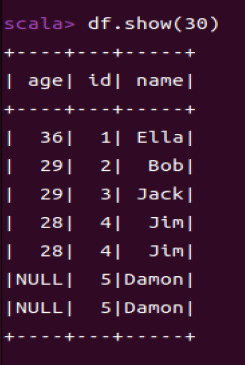
1.7 取出前3行数据
df.show(3)
** df.show(n)用于显示DataFrame的前n行。(n超出后会打印原始的大小)**
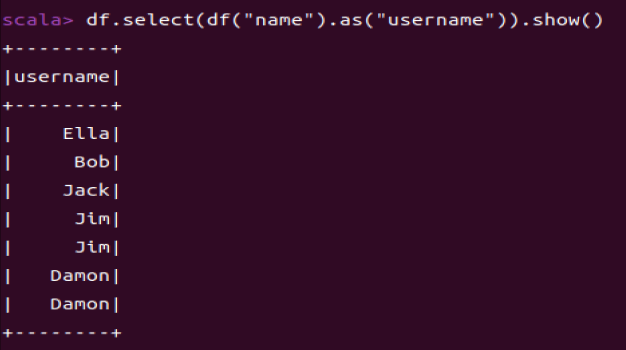
1.8 查询所有记录的name列,并为其取别名为username
df.select(df("name").as("username")).show()
** df.select()用于选择DataFrame中指定的列。**
1.9 查询年龄age的平均值
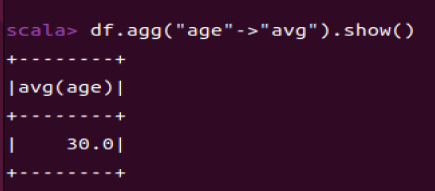
df.agg("age"->"avg").show()
** df.agg()用于对DataFrame进行聚合操作。**
avg平均。
1.10 查询年龄age的最小值
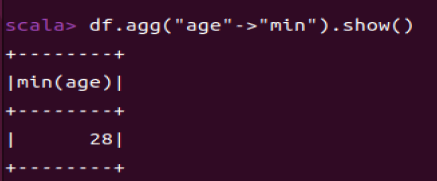
df.agg("age"->"min").show()
min最小。
2.编程实现将RDD转换为DataFrame
1,Ella,36
2,Bob,29
3,Jack,29
创建项目
sudo mkdir -p /example/sparkapp6/src/main/scala
cd /example/sparkapp6/src/main/scala
** 创建employee.txt**
sudo vim employee.txt
cat employee.txt

创建Scala文件
sudo vim ./SimpleApp.scala
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
import org.apache.spark.sql.SparkSession
object SimpleApp {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder
.appName("MyApp")
.getOrCreate()
val peopleRDD = spark.sparkContext.textFile("file:///example/sparkapp6/src/main/scala/employee.txt")
val schemaString = "id name age"
val fields = schemaString.split(" ").map(fieldName => StructField(fieldName, StringType, nullable = true))
val schema = StructType(fields)
val rowRDD = peopleRDD.map(_.split(",")).map(attributes => Row(attributes(0), attributes(1).trim, attributes(2).trim))
val peopleDF = spark.createDataFrame(rowRDD, schema)
peopleDF.createOrReplaceTempView("people")
val results = spark.sql("SELECT id,name,age FROM people")
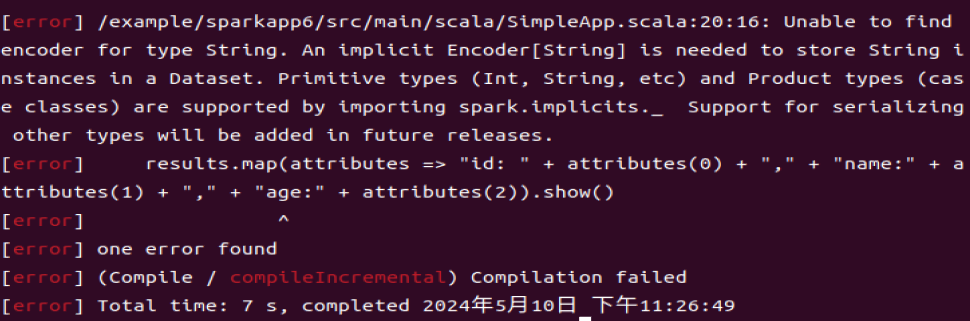
results.map(attributes => "id: " + attributes(0) + "," + "name:" + attributes(1) + "," + "age:" + attributes(2)).show()
}
}
这个代码没成功,继续往下面看。
** 创建.sbt文件**
sudo vim build.sbt
**这里需要的依赖发生了变化,不改会报错。 **
name := "Simple Project"
version := "1.0"
scalaVersion := "2.13.13"
libraryDependencies += "org.apache.spark" %% "spark-core" % "3.5.1"
libraryDependencies += "org.apache.spark" %% "spark-sql" % "3.5.1"
** 打包执行**
/usr/local/sbt/sbt package
spark-submit --class "SimpleApp" ./target/scala-2.13/simple-project_2.13-1.0.jar
 直接启动spark-shell(成功运行是看这里)
直接启动spark-shell(成功运行是看这里)
cd /usr/local/spark/
./bin/spark-shell
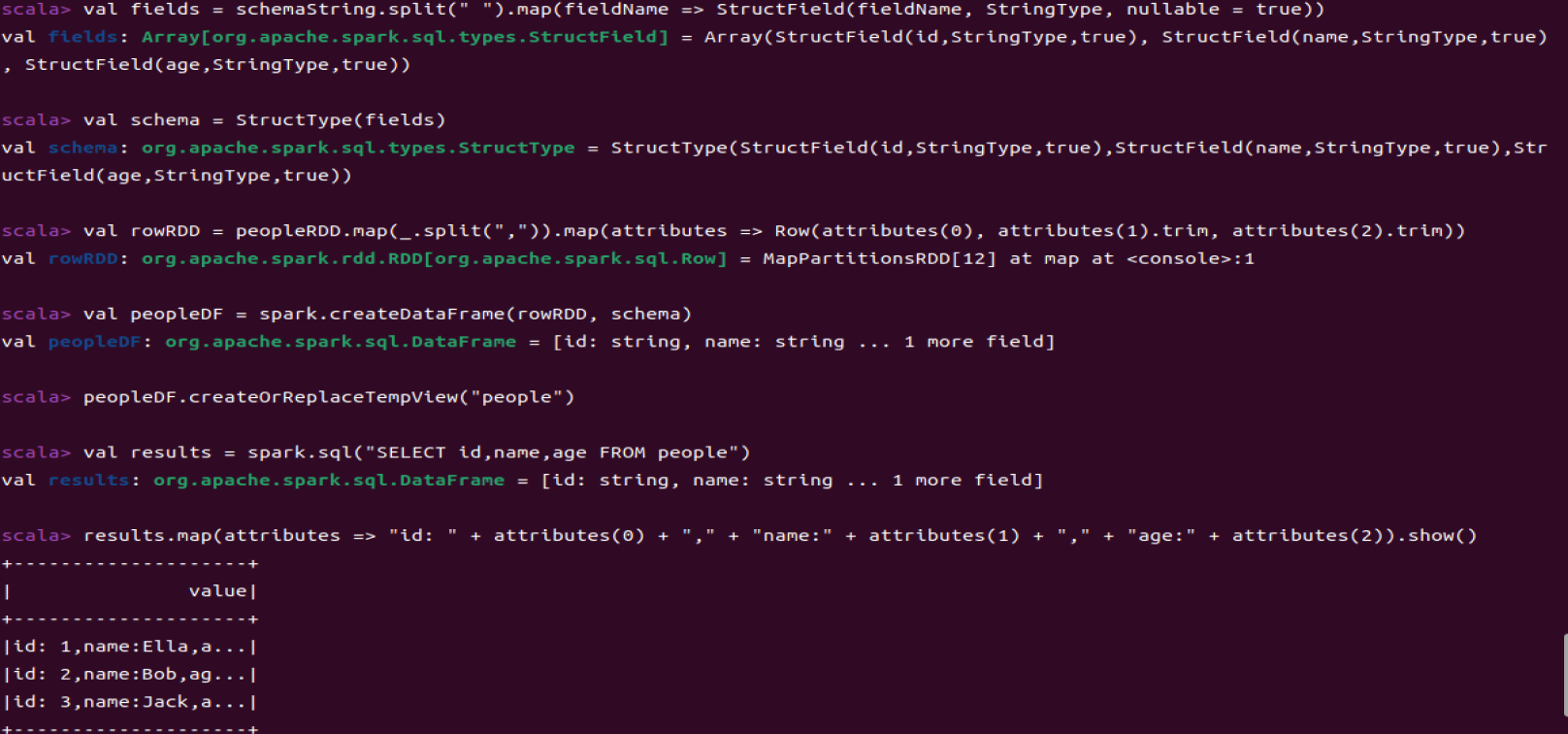
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
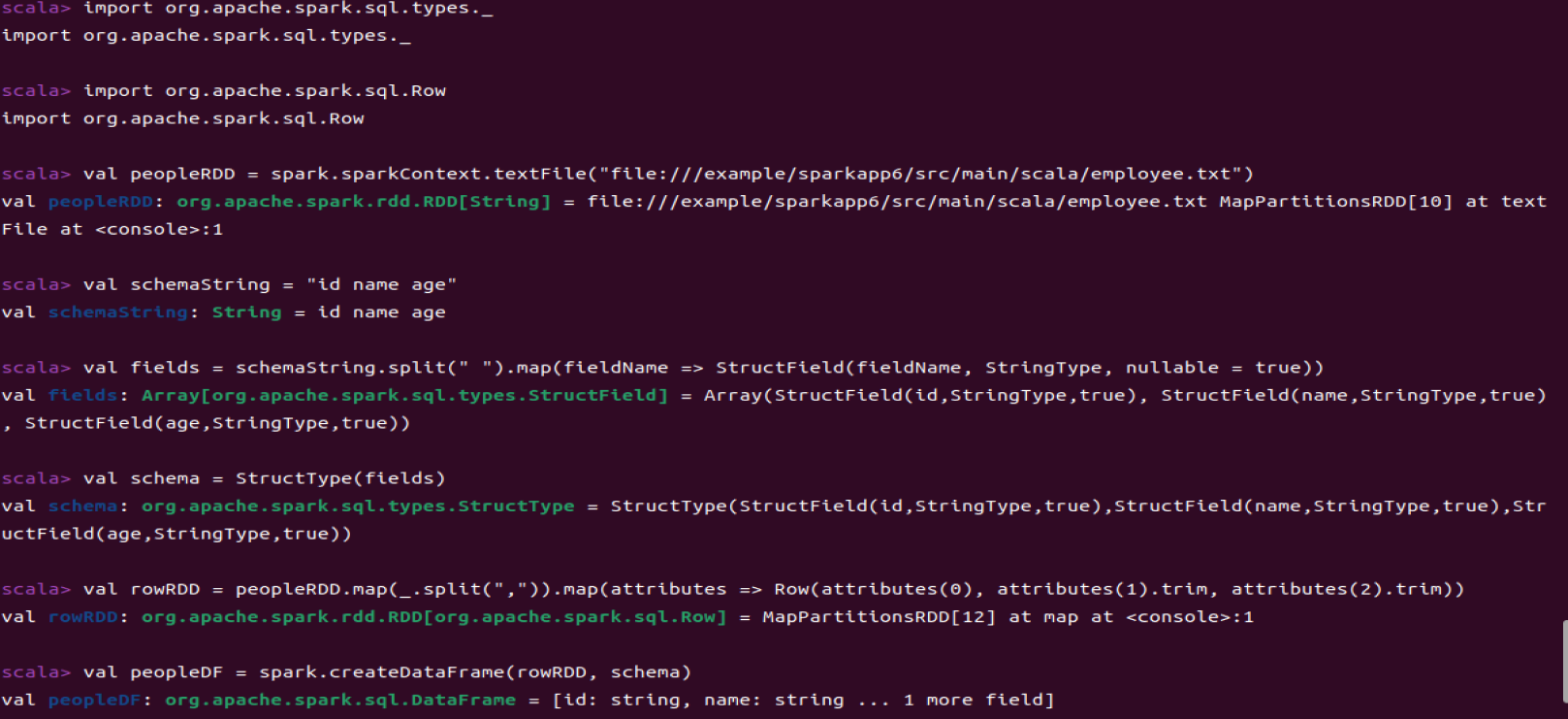
val peopleRDD = spark.sparkContext.textFile("file:///example/sparkapp6/src/main/scala/employee.txt")
val schemaString = "id name age"
val fields = schemaString.split(" ").map(fieldName => StructField(fieldName, StringType, nullable = true))
val schema = StructType(fields)
val rowRDD = peopleRDD.map(_.split(",")).map(attributes => Row(attributes(0), attributes(1).trim, attributes(2).trim))
val peopleDF = spark.createDataFrame(rowRDD, schema)
peopleDF.createOrReplaceTempView("people")
val results = spark.sql("SELECT id,name,age FROM people")
results.map(attributes => "id: " + attributes(0) + "," + "name:" + attributes(1) + "," + "age:" + attributes(2)).show()
scala> import org.apache.spark.sql.types._
import org.apache.spark.sql.types._
scala> import org.apache.spark.sql.Row
import org.apache.spark.sql.Row
scala> val peopleRDD = spark.sparkContext.textFile("file:///example/sparkapp6/src/main/scala/employee.txt")
val peopleRDD: org.apache.spark.rdd.RDD[String] = file:///example/sparkapp6/src/main/scala/employee.txt MapPartitionsRDD[10] at textFile at <console>:1
scala> val schemaString = "id name age"
val schemaString: String = id name age
scala> val fields = schemaString.split(" ").map(fieldName => StructField(fieldName, StringType, nullable = true))
val fields: Array[org.apache.spark.sql.types.StructField] = Array(StructField(id,StringType,true), StructField(name,StringType,true), StructField(age,StringType,true))
scala> val schema = StructType(fields)
val schema: org.apache.spark.sql.types.StructType = StructType(StructField(id,StringType,true),StructField(name,StringType,true),StructField(age,StringType,true))
scala> val rowRDD = peopleRDD.map(_.split(",")).map(attributes => Row(attributes(0), attributes(1).trim, attributes(2).trim))
val rowRDD: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[12] at map at <console>:1
scala> val peopleDF = spark.createDataFrame(rowRDD, schema)
val peopleDF: org.apache.spark.sql.DataFrame = [id: string, name: string ... 1 more field]
scala> peopleDF.createOrReplaceTempView("people")
scala> val results = spark.sql("SELECT id,name,age FROM people")
val results: org.apache.spark.sql.DataFrame = [id: string, name: string ... 1 more field]
scala> results.map(attributes => "id: " + attributes(0) + "," + "name:" + attributes(1) + "," + "age:" + attributes(2)).show()
+--------------------+
| value|
+--------------------+
|id: 1,name:Ella,a...|
|id: 2,name:Bob,ag...|
|id: 3,name:Jack,a...|
+--------------------+
3.编程实现利用DataFrame读写MySQL的数据
安装MySQL
MySQL :: Download MySQL Connector/J (Archived Versions)
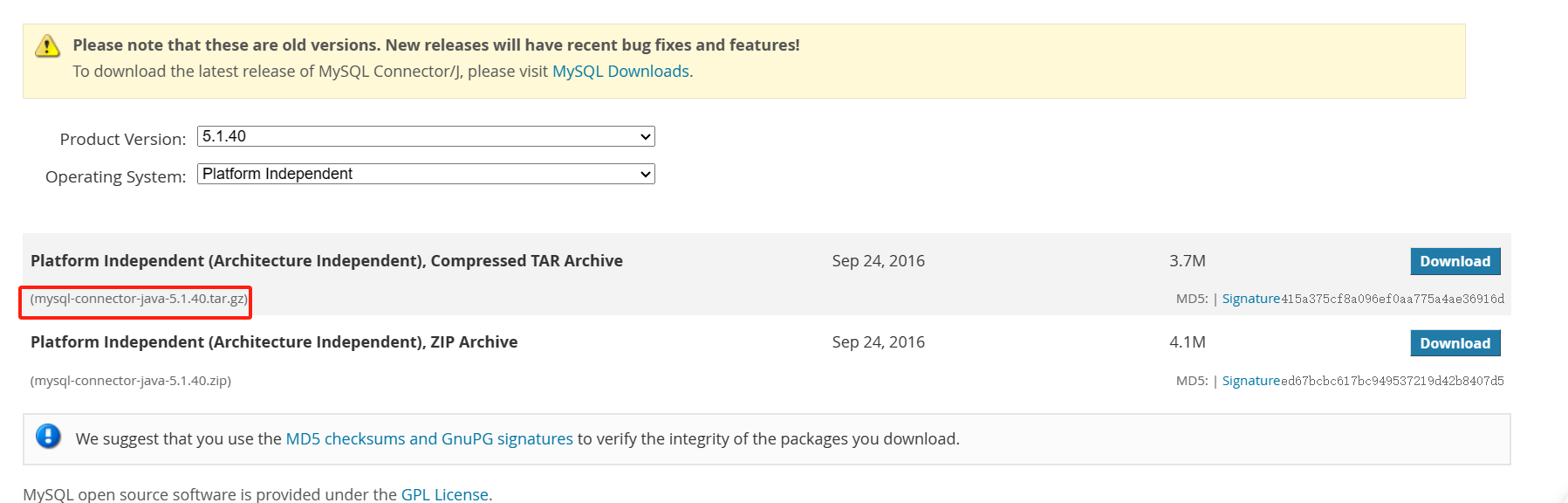
sudo tar -zxf ./mysql-connector-java-5.1.40.tar.gz -C /usr/local
cd /usr/local/
mv mysql-connector-java-5.1.40/ mysql
3.1 在MySQL数据库中新建数据库sparktest,再创建表employee

su root
service mysql start
mysql -u root -p
** 建库**
create database sparktest;

建表
use sparktest;
create table employee(id int(4),name char(20),gender char(4),Age int(4));
mysql> use sparktest;
Database changed
mysql> create table employee(id int(4),name char(20),gender char(4),Age int(4));
Query OK, 0 rows affected, 2 warnings (0.02 sec)

插入数据
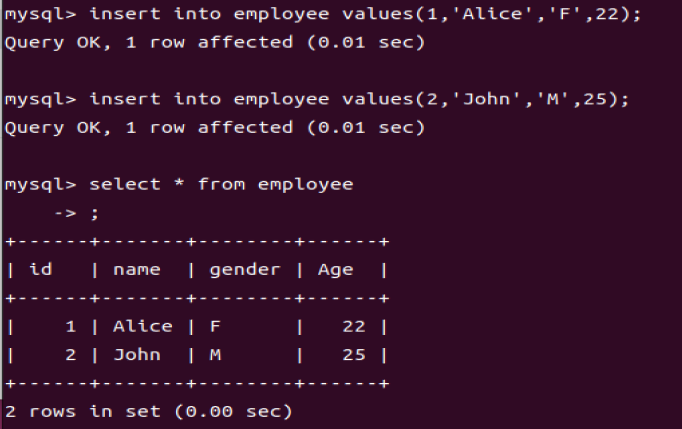
insert into employee values(1,'Alice','F',22);
insert into employee values(2,'John','M',25);
select * from employee;
mysql> insert into employee values(1,'Alice','F',22);
Query OK, 1 row affected (0.01 sec)
mysql> insert into employee values(2,'John','M',25);
Query OK, 1 row affected (0.01 sec)
mysql> select * from employee;
+------+-------+--------+------+
| id | name | gender | Age |
+------+-------+--------+------+
| 1 | Alice | F | 22 |
| 2 | John | M | 25 |
+------+-------+--------+------+
2 rows in set (0.00 sec)
3.2 配置Spark通过JDBC连接数据库MySQL,编程实现利用DataFrame插入
版权归原作者 封奚泽优 所有, 如有侵权,请联系我们删除。