
在本文中,我们将实践
GBase8s
和
MySQL
的跨数据源联合查询,案例中
MySQL
数据源中存放商品信息,
GBase8s
数据源中存放订单信息。 整体架构如下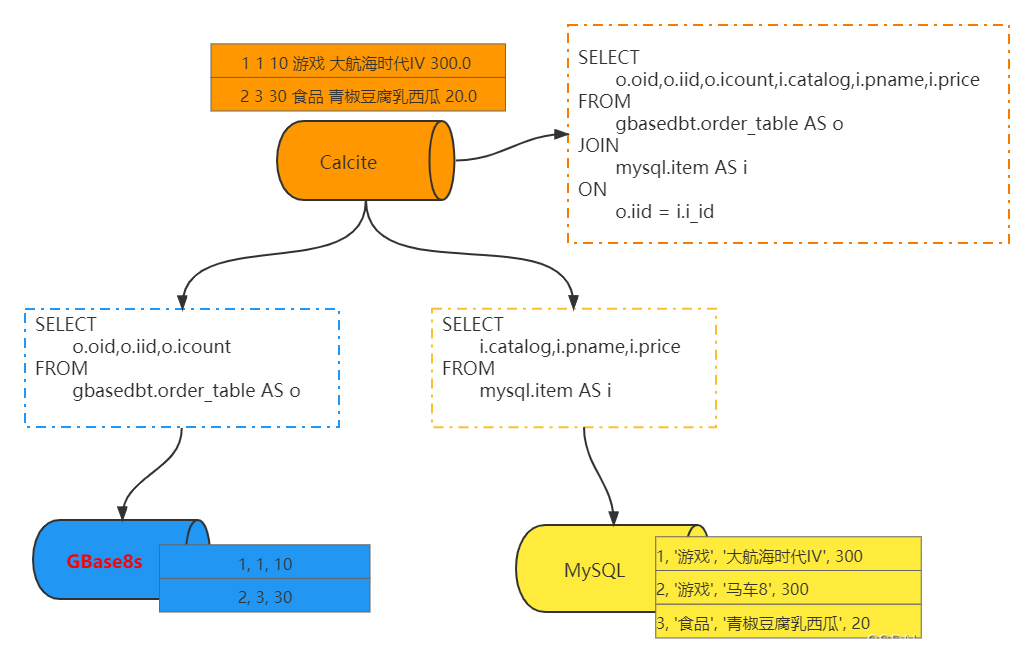
好了,我们开始吧。
环境准备
GBase8s
安装镜像
docker pull liaosnet/gbase8s
启动容器
docker run -itd -p 19088:9088 liaosnet/gbase8s
容器基本信息:
JDBC JAR:/home/gbase/gbasedbtjdbc_3.3.0_2.jar
类名:com.gbasedbt.jdbc.Driver
URL:jdbc:gbasedbt-sqli://IPADDR:19088/testdb:GBASEDBTSERVER=gbase01;DB_LOCALE=zh_CN.utf8;CLIENT_LOCALE=zh_CN.utf8;IFX_LOCK_MODE_WAIT=30;
用户:gbasedbt
密码:GBase123
其中:IPADDR为docker所在机器的IP地址,同时需要放通19088端口。
MySQL
安装镜像
docker pull liaosnet/gbase8s
启动容器
docker run -p 3306:3306 --name mysql -e MYSQL_ROOT_PASSWORD=dafei1288 -d mysql
数据准备
GBase8s
CREATETABLE order_table (
oid INTEGERNOTNULL,
iid INTEGER,
icount INTEGER,PRIMARYKEY(oid)CONSTRAINT order_table_pk
);INSERTINTO order_table (oid, iid, icount)VALUES(1,1,10);INSERTINTO order_table (oid, iid, icount)VALUES(2,3,30);
MySQL
createtable item
(
i_id intauto_incrementprimarykey,
catalog varchar(20)null,
pname varchar(20)null,
price floatnull,constraint item_i_id_uindex
unique(i_id));INSERTINTO test.item (i_id, catalog, pname, price)VALUES(1,'游戏','大航海时代IV',300);INSERTINTO test.item (i_id, catalog, pname, price)VALUES(2,'游戏','马车8',300);INSERTINTO test.item (i_id, catalog, pname, price)VALUES(3,'食品','青椒豆腐乳西瓜',20);
工程准备
创建
maven
工程,目录如下图所示:
添加依赖
<?xml version="1.0" encoding="UTF-8"?><projectxmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>calcite_multi_database</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>17</maven.compiler.source><maven.compiler.target>17</maven.compiler.target></properties><dependencies><dependency><groupId>org.apache.calcite</groupId><artifactId>calcite-core</artifactId><version>1.29.0</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.28</version></dependency><dependency><groupId>com.google.code.gson</groupId><artifactId>gson</artifactId><version>2.8.9</version></dependency><dependency><groupId>gbase</groupId><artifactId>gbasedbt</artifactId><version>330</version><scope>system</scope><systemPath>${project.basedir}/libs/gbasedbtjdbc_3.3.0_2_36477d.jar</systemPath></dependency></dependencies></project>
添加数据源配置文件
multiSource.json
{"defaultSchema":"gbasedbt","schemas":[{"factory":"org.apache.calcite.adapter.jdbc.JdbcSchema$Factory","name":"mysql","operand":{"jdbcDriver":"com.mysql.cj.jdbc.Driver","jdbcUrl":"jdbc:mysql://localhost:3306/test","jdbcUser":"root","jdbcPassword":"dafei1288"},"type":"custom"},{"factory":"org.apache.calcite.adapter.jdbc.JdbcSchema$Factory","name":"gbasedbt","operand":{"jdbcDriver":"com.gbasedbt.jdbc.Driver","jdbcUrl":"jdbc:gbasedbt-sqli://localhost:19088/testdb:GBASEDBTSERVER=gbase01;DB_LOCALE=zh_CN.utf8;CLIENT_LOCALE=zh_CN.utf8;IFX_LOCK_MODE_WAIT=30;","jdbcUser":"gbasedbt","jdbcPassword":"GBase123"},"type":"custom"}],"version":"1.0"}
创建执行程序
MultiSource
使用上面的配置文件,创建
Calcite Jdbc
链接
String filepath = "E:\\working\\GBase\\writting\\calcite_multi_database_select\\calcite_multi_database\\src\\main\\resources\\multiSource.json";
Properties config = new Properties();
config.put("model",filepath);
config.put("lex", "MYSQL");
这里
config.put("lex", "MYSQL");
用于解析外层
SQL
,所以必须保留。使用查询语句
SELECT o.oid,o.iid,o.icount,i.catalog,i.pname,i.price FROM gbasedbt.order_table AS o join mysql.item AS i on o.iid = i.i_id
进行数据查询。
除了执行结果,其实我们也会对执行的逻辑计划感兴趣,那么我们来看看如何将该
SQL
的逻辑计划打印出来
publicstaticvoidprintLogicPlan(String modelPath ,String sql)throwsException{String modelJsonStr =Files.readAllLines(Paths.get(modelPath)).stream().collect(Collectors.joining("\n"));HashMap map =newGson().fromJson(modelJsonStr,HashMap.class);List<Map> schemas =(List<Map>) map.get("schemas");SchemaPlus rootSchema =Frameworks.createRootSchema(true);Schema gbasedbt =JdbcSchema.create(rootSchema,"gbasedbt",(Map<String,Object>)schemas.get(1).get("operand"));Schema mysql =JdbcSchema.create(rootSchema,"mysql",(Map<String,Object>)schemas.get(0).get("operand"));
rootSchema.add("gbasedbt",gbasedbt);
rootSchema.add("mysql",mysql);SqlParser.Config insensitiveParser =SqlParser.configBuilder().setCaseSensitive(false).build();FrameworkConfig config =Frameworks.newConfigBuilder().parserConfig(insensitiveParser).defaultSchema(rootSchema).build();Planner planner =Frameworks.getPlanner(config);SqlNode sqlNode = planner.parse(sql);SqlNode sqlNodeValidated = planner.validate(sqlNode);RelRoot relRoot = planner.rel(sqlNodeValidated);RelNode relNode = relRoot.project();System.out.println(sqlNode.toSqlString(MysqlSqlDialect.DEFAULT));System.out.println();System.out.println(relNode.explain());}
下面是逻辑计划打印的结果,我们不难看出,这里是使用了2个全表扫描,然后再通过
Join
算子,然后进行
project
算子的。其实这个执行不能说效率很高吧,只能说非常慢,如果想做优化,我们以后再开一篇文章。
LogicalProject(OID=[$0], IID=[$1], ICOUNT=[$2], CATALOG=[$4], PNAME=[$5], PRICE=[$6])
LogicalJoin(condition=[=($1, $3)], joinType=[inner])
JdbcTableScan(table=[[gbasedbt, order_table]])
JdbcTableScan(table=[[mysql, item]])
SQL
查询结果如下
oid iid icount catalog pname price
1 1 10 游戏 大航海时代IV 300.0
2 3 30 食品 青椒豆腐乳西瓜 20.0
执行截图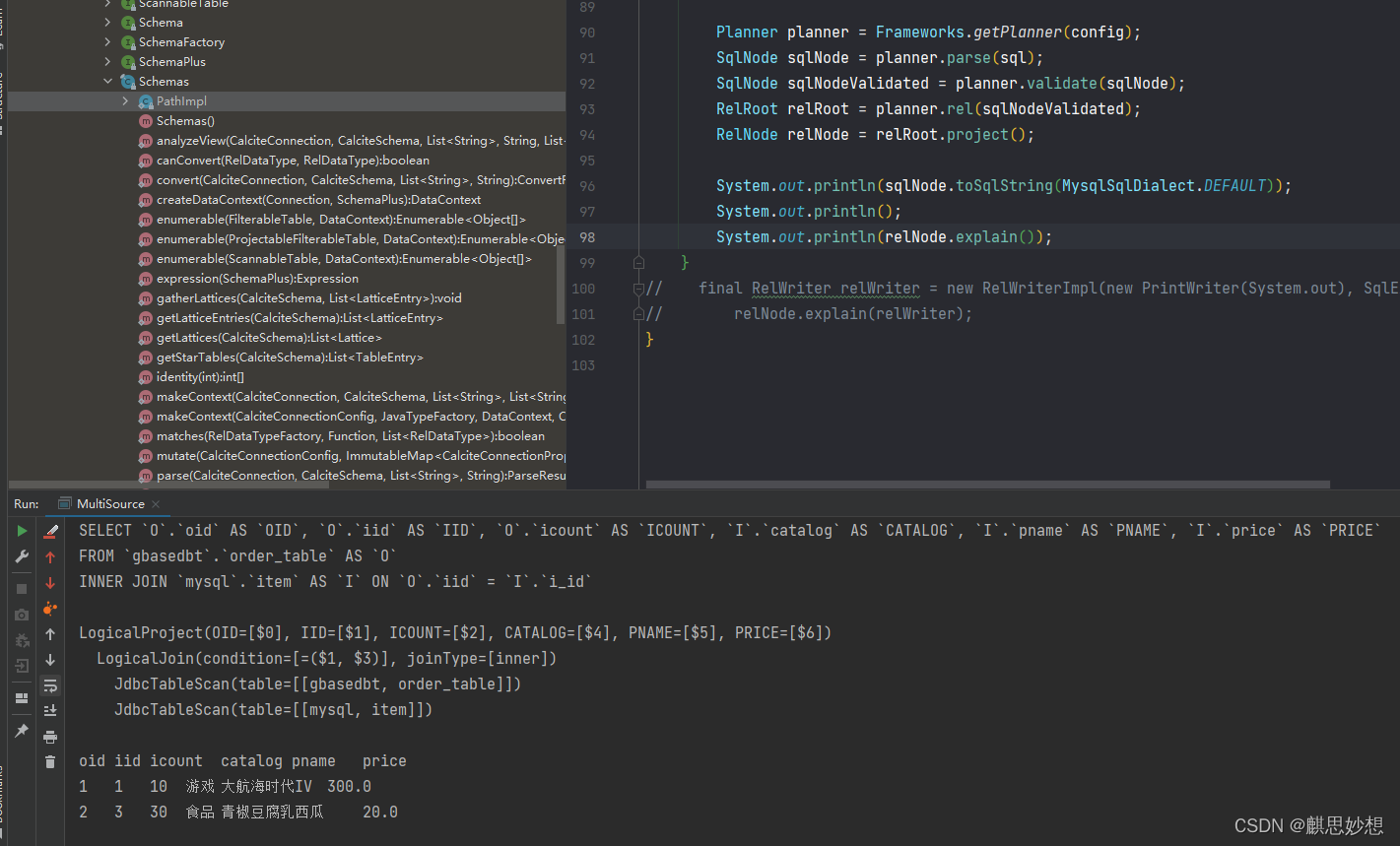
完整代码清单:
packagewang.datahub;importcom.google.gson.Gson;importorg.apache.calcite.adapter.jdbc.JdbcSchema;importorg.apache.calcite.rel.RelNode;importorg.apache.calcite.rel.RelRoot;importorg.apache.calcite.rel.RelWriter;importorg.apache.calcite.rel.externalize.RelWriterImpl;importorg.apache.calcite.schema.Schema;importorg.apache.calcite.schema.SchemaPlus;importorg.apache.calcite.sql.SqlExplainLevel;importorg.apache.calcite.sql.SqlNode;importorg.apache.calcite.sql.dialect.MysqlSqlDialect;importorg.apache.calcite.sql.parser.SqlParser;importorg.apache.calcite.tools.FrameworkConfig;importorg.apache.calcite.tools.Frameworks;importorg.apache.calcite.tools.Planner;importjava.io.PrintWriter;importjava.nio.file.Files;importjava.nio.file.Paths;importjava.sql.*;importjava.util.HashMap;importjava.util.List;importjava.util.Map;importjava.util.Properties;importjava.util.stream.Collectors;publicclassMultiSource{publicstaticvoidmain(String[] args)throwsException{String filepath ="E:\\working\\GBase\\writting\\calcite_multi_database_select\\calcite_multi_database\\src\\main\\resources\\multiSource.json";Properties config =newProperties();
config.put("model",filepath);
config.put("lex","MYSQL");String sql ="SELECT o.oid,o.iid,o.icount,i.catalog,i.pname,i.price FROM gbasedbt.order_table AS o join mysql.item AS i on o.iid = i.i_id";try(Connection con =DriverManager.getConnection("jdbc:calcite:", config)){try(Statement stmt = con.createStatement()){try(ResultSet rs = stmt.executeQuery(sql)){//打印逻辑计划printLogicPlan(filepath,sql);//打印查询结果printRs(rs);}}}}publicstaticvoidprintRs(ResultSet rs)throwsException{ResultSetMetaData rsmd = rs.getMetaData();int count = rsmd.getColumnCount();for(int i =1; i <= count; i++){System.out.print(rsmd.getColumnName(i)+"\t");}System.out.println();while(rs.next()){for(int i =1; i <= count; i++){System.out.print(rs.getString(i)+"\t");}System.out.println();}}publicstaticvoidprintLogicPlan(String modelPath ,String sql)throwsException{String modelJsonStr =Files.readAllLines(Paths.get(modelPath)).stream().collect(Collectors.joining("\n"));HashMap map =newGson().fromJson(modelJsonStr,HashMap.class);List<Map> schemas =(List<Map>) map.get("schemas");SchemaPlus rootSchema =Frameworks.createRootSchema(true);Schema gbasedbt =JdbcSchema.create(rootSchema,"gbasedbt",(Map<String,Object>)schemas.get(1).get("operand"));Schema mysql =JdbcSchema.create(rootSchema,"mysql",(Map<String,Object>)schemas.get(0).get("operand"));
rootSchema.add("gbasedbt",gbasedbt);
rootSchema.add("mysql",mysql);SqlParser.Config insensitiveParser =SqlParser.configBuilder().setCaseSensitive(false).build();FrameworkConfig config =Frameworks.newConfigBuilder().parserConfig(insensitiveParser).defaultSchema(rootSchema).build();Planner planner =Frameworks.getPlanner(config);SqlNode sqlNode = planner.parse(sql);SqlNode sqlNodeValidated = planner.validate(sqlNode);RelRoot relRoot = planner.rel(sqlNodeValidated);RelNode relNode = relRoot.project();System.out.println(sqlNode.toSqlString(MysqlSqlDialect.DEFAULT));System.out.println();System.out.println(relNode.explain());}}
好了,现在我们初步完成了基于
GBase8s
的跨数据源查询工作,下一篇文章我们来说说查询优化。
提前祝广大读者朋友,新春快乐,虎虎生威 …
本文转载自: https://blog.csdn.net/dafei1288/article/details/122663368
版权归原作者 麒思妙想 所有, 如有侵权,请联系我们删除。
版权归原作者 麒思妙想 所有, 如有侵权,请联系我们删除。