
前提
在hadoop上实现统计英语文章单词个数的前提是你在windows系统上可以完成统计英语文章单词个数,大致思路请见手把手教你mapreduce在win11上实现统计英语文章单词出现个数-CSDN博客
一.准备工具
vmware16
centos2003镜像文件
Xmanager Enterprise 5
通过vmware在自己电脑上搭建一个hadoop集群环境,这个大家可以详见站里大佬的,如果实在想要的话我找个时间发个帖子。(对了大家用的虚拟环境是那一个啊,我用的是centos7)
二.过程
1.idea上的操作
在手把手教你mapreduce在win11上实现统计英语文章单词出现个数-CSDN博客这个教程中,我们要对drive进行修改,因为linux环境和windows环境不同,Linux没有想windows一样以c盘,d盘来进行磁盘管理,而是通过一个硬件设备都映射到一个系统的文件来进行磁盘管理。
1.将drive类里面的 设置输入和输出的路径 那一节中将输入输出地址换一下,这样等会在虚拟环境中输入指令时你可以看看args[0]和args[1]分别代指什么
//设置输入和输出的路径
TextInputFormat.setInputPaths(job,new Path(args[0]));
TextOutputFormat.setOutputPath(job,new Path(args[1]));
2.进行打包

3.打包后在左边的监视窗口target文件里有个后缀为.jar的架包,这就是刚刚打包的文件,选中架包,右击,选择复制地址中的最后一项,就会跳转到你架包的文件里面(有的电脑跳不了,就直接复制路径,在文件资源管理器中将路径复制下来,把路径的最后也就是架包名称删掉也可以进入架包所在文件。第三张图)
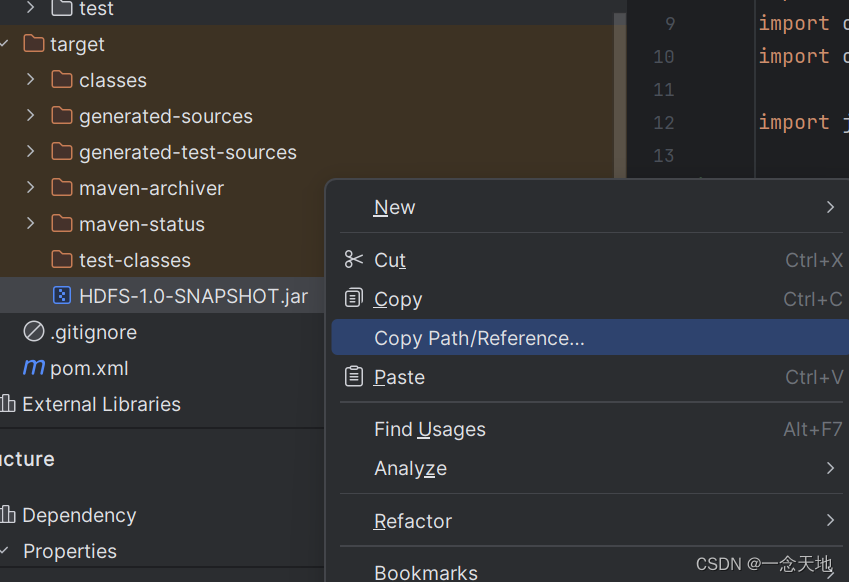


因为待会你要将这个架包名称写在虚拟机上,为方便将名字改一下,这里我改成jar.jar
2.虚拟机上的操作
4.打开虚拟机,在主节点上启动hadoop集群(不同的人在搭建hadoop集群时的名称不同,故路径也有轻微差别,不要全抄,要思考一下)
在这里我推荐使用Xmanager Enterprise 5中的Xshell来链接主节点并输入指令,用过的知道它多么简便,没用过我说什么也不懂

5.将word1.txt文本文件上传到hadoop集群上。首先将文件和架包从windows系统传输到Linux系统上,点击新建文件传输,将windows系统里面的文件拖拽到右边的Linux系统上

6.使用命令将Linux系统上的word1.txt上传到hadoop集群上
hadoop dfs -put /word1.txt /
打开hadoop集群端口,你会看到一个名为word1.txt的文本文档,这就是刚上传到hadoop集群的文件(有的人会说我怎么找不到这个地方,那请你把鼠标选中Utilities,在下拉列表中选择第一个就可以跳转到这个界面)
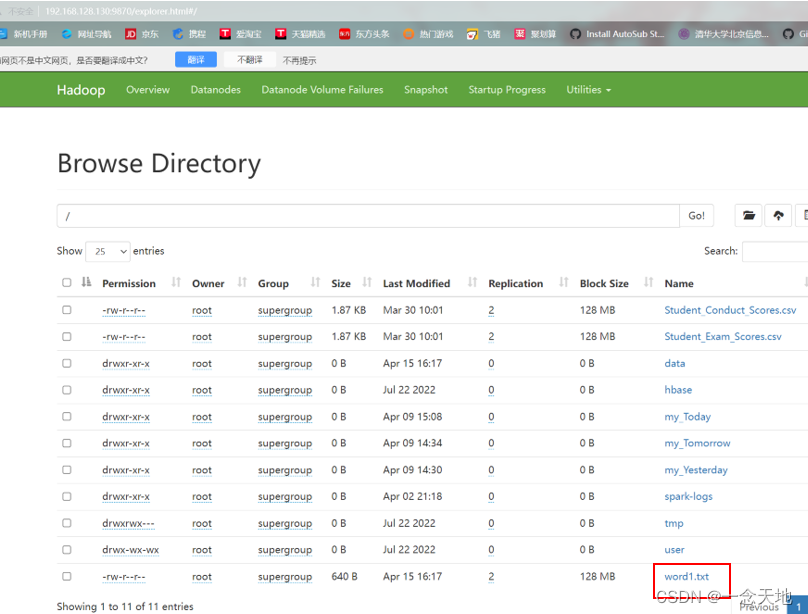
7.在主节点上执行下面指令
[root@master /]# hadoop jar /jar.jar mapreduce.driver /word1.txt /test11
hadoop jar 是运行jar包指令
/jar.jar 是传输到虚拟机上架包所在位置
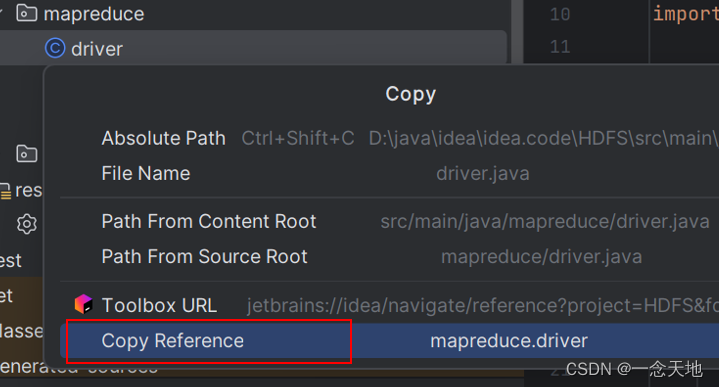
mapreduce.driver 是drive类的包名+类名(这个在idea上选中driver类右击,选中红框里面的内容,接着选第二张图片红框里面的内容就可以了,最后复制上去就可以了,复制时别ctrl+v,右击-->粘贴)

/word1.txt hadoop集群上输入文件的路径
/test11 hadoop集群上输出的具体路径,此路径必须为不存在的
点击回车等待运行结果
8.检查是否成功
打开hadoop集群端口,查看有没有test11这个文件,点开这个文件,看有没有第二张图片里面的内容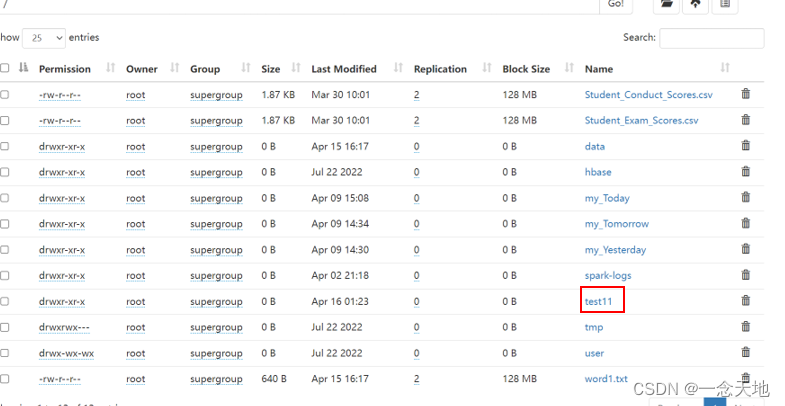

点开显示不出单词和频数,好像是要下载什么插件还是什么别的才能看见,我不清楚,有人知道的话在评论区告诉我一下,你也不能直接点击download下载,这样下载是不会成功的
在主节点上使用指令进行下载
[root@master /]# hadoop dfs -get /test11 /
再通过新建传输将文件拖入到windows上

打开文件就可以看到了

好了,实验就是这么做的,如果有哪个地方做的不对,欢迎大家来和我讨论,我也会及时修改的
版权归原作者 一念天地 所有, 如有侵权,请联系我们删除。