
一、简介
flink 自定义实时数据源使用流处理比较简单,比如 Kafka、MQ 等,如果使用 MySQL、redis 批处理也比较简单
如果需要定时加载数据作为 flink 数据源使用流处理,比如定时从 mysql 或者 redis 获取一批数据,传入 flink 做处理,如下简单实现
二、pom.xml 文件
注意 flink 好多包从 1.15.0 开始不需要指定 Scala 版本,内部自带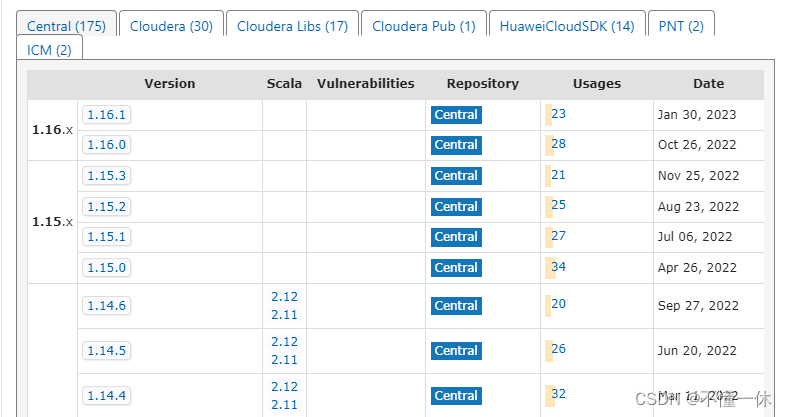
下面 pom 文件有 flink 两个版本 1.16.0 和 1.12.7(Scala:2.12)
<projectxmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.ye</groupId><artifactId>flink-study</artifactId><version>0.1</version><packaging>jar</packaging><name>Flink Quickstart Job</name><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><flink.version>1.16.0</flink.version><!--<flink.version>1.12.7</flink.version>--><target.java.version>1.8</target.java.version><scala.binary.version>2.12</scala.binary.version><maven.compiler.source>${target.java.version}</maven.compiler.source><maven.compiler.target>${target.java.version}</maven.compiler.target><log4j.version>2.17.1</log4j.version></properties><repositories><repository><id>apache.snapshots</id><name>Apache Development Snapshot Repository</name><url>https://repository.apache.org/content/repositories/snapshots/</url><releases><enabled>false</enabled></releases><snapshots><enabled>true</enabled></snapshots></repository></repositories><dependencies><!-- Apache Flink dependencies --><!-- These dependencies are provided, because they should not be packaged into the JAR file. --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!--
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-files</artifactId><version>${flink.version}</version></dependency><!-- Add connector dependencies here. They must be in the default scope (compile). --><!-- Example:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
--><!-- Add logging framework, to produce console output when running in the IDE. --><!-- These dependencies are excluded from the application JAR by default. --><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-slf4j-impl</artifactId><version>${log4j.version}</version><scope>runtime</scope></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-api</artifactId><version>${log4j.version}</version><scope>runtime</scope></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-core</artifactId><version>${log4j.version}</version><scope>runtime</scope></dependency></dependencies><build><plugins><!-- Java Compiler --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.1</version><configuration><source>${target.java.version}</source><target>${target.java.version}</target></configuration></plugin><!-- We use the maven-shade plugin to create a fat jar that contains all necessary dependencies. --><!-- Change the value of <mainClass>...</mainClass> if your program entry point changes. --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.1.1</version><executions><!-- Run shade goal on package phase --><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><createDependencyReducedPom>false</createDependencyReducedPom><artifactSet><excludes><exclude>org.apache.flink:flink-shaded-force-shading</exclude><exclude>com.google.code.findbugs:jsr305</exclude><exclude>org.slf4j:*</exclude><exclude>org.apache.logging.log4j:*</exclude></excludes></artifactSet><filters><filter><!-- Do not copy the signatures in the META-INF folder.
Otherwise, this might cause SecurityExceptions when using the JAR. --><artifact>*:*</artifact><excludes><exclude>META-INF/*.SF</exclude><exclude>META-INF/*.DSA</exclude><exclude>META-INF/*.RSA</exclude></excludes></filter></filters><transformers><transformerimplementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/><transformerimplementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"><mainClass>com.ye.DataStreamJob</mainClass></transformer></transformers></configuration></execution></executions></plugin></plugins><pluginManagement><plugins><!-- This improves the out-of-the-box experience in Eclipse by resolving some warnings. --><plugin><groupId>org.eclipse.m2e</groupId><artifactId>lifecycle-mapping</artifactId><version>1.0.0</version><configuration><lifecycleMappingMetadata><pluginExecutions><pluginExecution><pluginExecutionFilter><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><versionRange>[3.1.1,)</versionRange><goals><goal>shade</goal></goals></pluginExecutionFilter><action><ignore/></action></pluginExecution><pluginExecution><pluginExecutionFilter><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><versionRange>[3.1,)</versionRange><goals><goal>testCompile</goal><goal>compile</goal></goals></pluginExecutionFilter><action><ignore/></action></pluginExecution></pluginExecutions></lifecycleMappingMetadata></configuration></plugin></plugins></pluginManagement></build></project>
三、自定义数据源
使用 Timer 定时任务(当然也可以使用线程池 Executors)自定义数据源,每过五秒随机生成一串字符串
publicclassTimerSinkRichextendsRichSourceFunction<String>{privateConcurrentLinkedQueue<String> queue =newConcurrentLinkedQueue<>();privateboolean flag =true;privateTimer timer;privateTimerTask timerTask;@Overridepublicvoidopen(Configuration parameters)throwsException{super.open(parameters);
timerTask =newTimerTask(){@Overridepublicvoidrun(){// 可以在这块获取 MySQL、redis 等连接并查询数据Random random =newRandom();StringBuilder str =newStringBuilder();for(int i =0; i <10; i++){char ranLowLetter =(char)((random.nextInt(26)+97));
str.append(ranLowLetter);}
queue.add(str.toString());}};
timer =newTimer();// 延时和执行周期参数可以通过构造方法传递
timer.schedule(timerTask,1000,5000);}@Overridepublicvoidrun(SourceContext<String> ctx)throwsException{while(flag){if(queue.size()>0){
ctx.collect(queue.remove());}}}@Overridepublicvoidcancel(){if(null!=timer) timer.cancel();if(null!=timerTask) timerTask.cancel();// 撤销任务时,flink 默认 30 s(不同 flink 版本可能不同)尝试关闭数据源,关闭失败 TaskManager 不能释放 slot,最终导致失败if(queue.size()<=0) flag =false;}}
四、flink 加载数据源并启动
publicclassTimerSinkStreamJob{publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment executionEnvironment =StreamExecutionEnvironment.getExecutionEnvironment();
executionEnvironment.setParallelism(1);DataStreamSource<String> streamSource = executionEnvironment.addSource(newTimerSinkRich());
streamSource.print();
executionEnvironment.execute("TimerSinkStreamJob 定时任务打印数据");}}
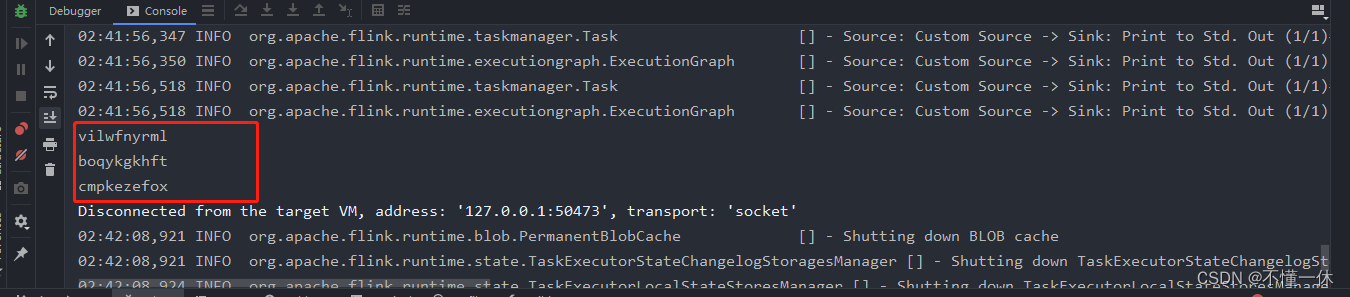
本地测试成功
五、上传 flink 集群
1、flink 1.16.0
启动成功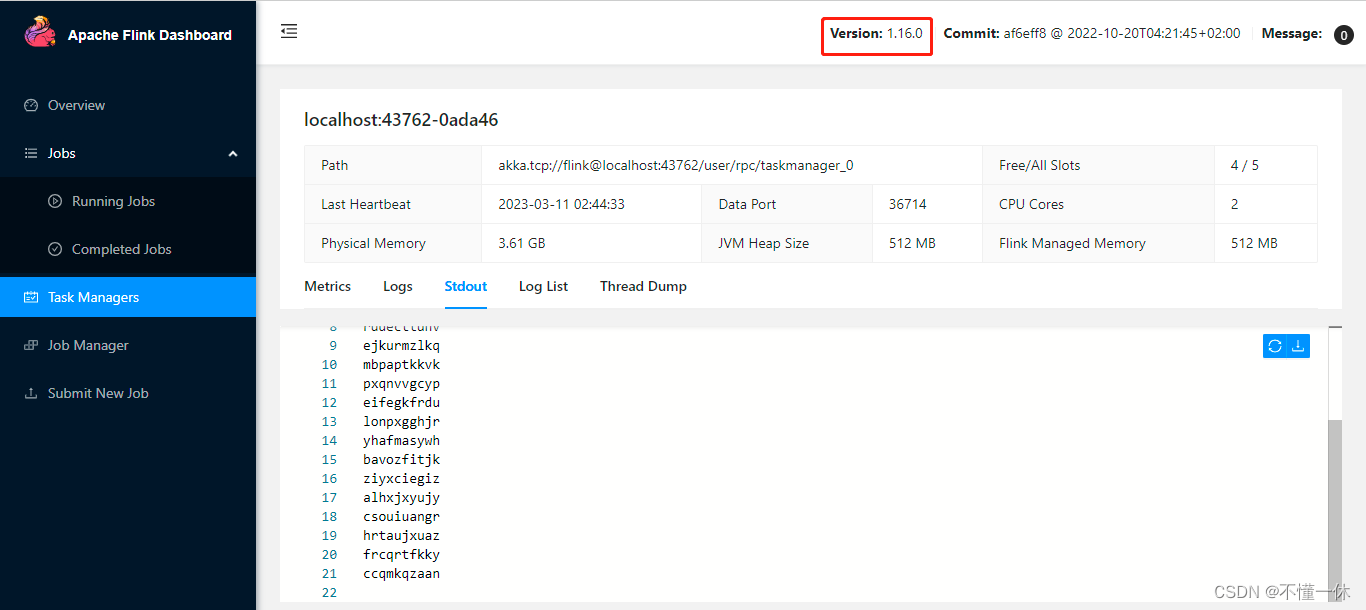
撤销任务成功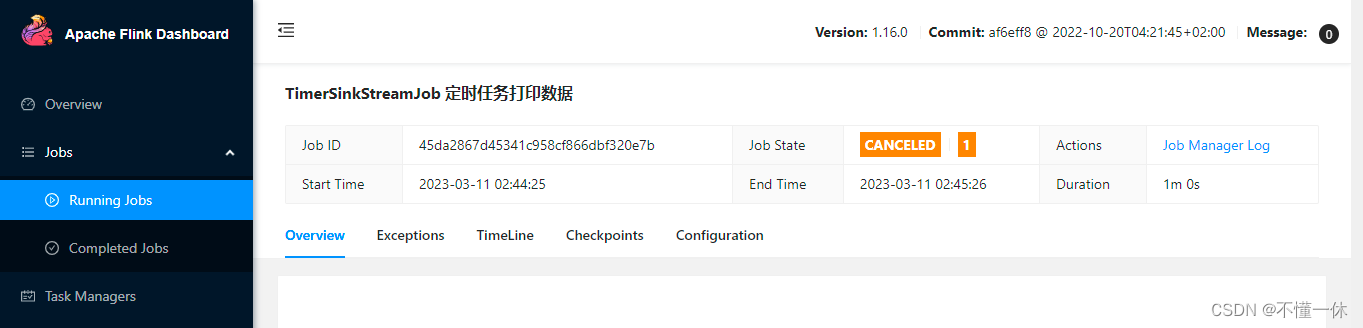
solt 也成功释放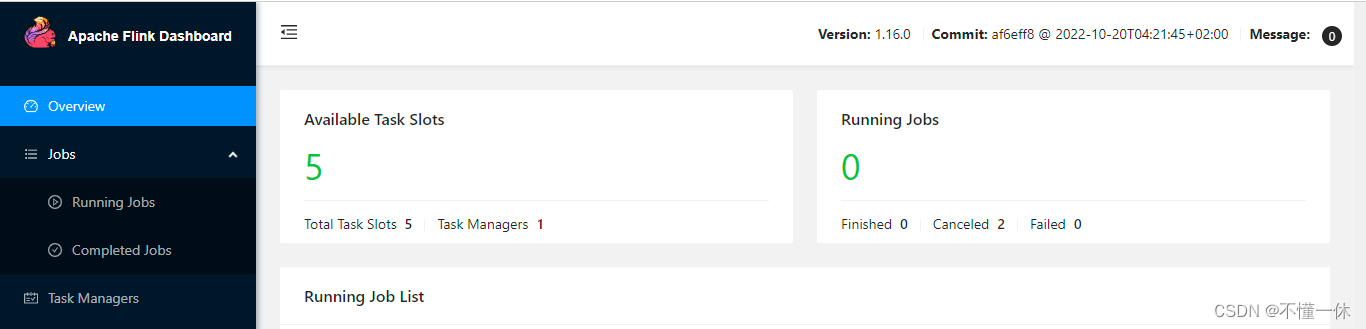
2、flink 1.12.7
启动成功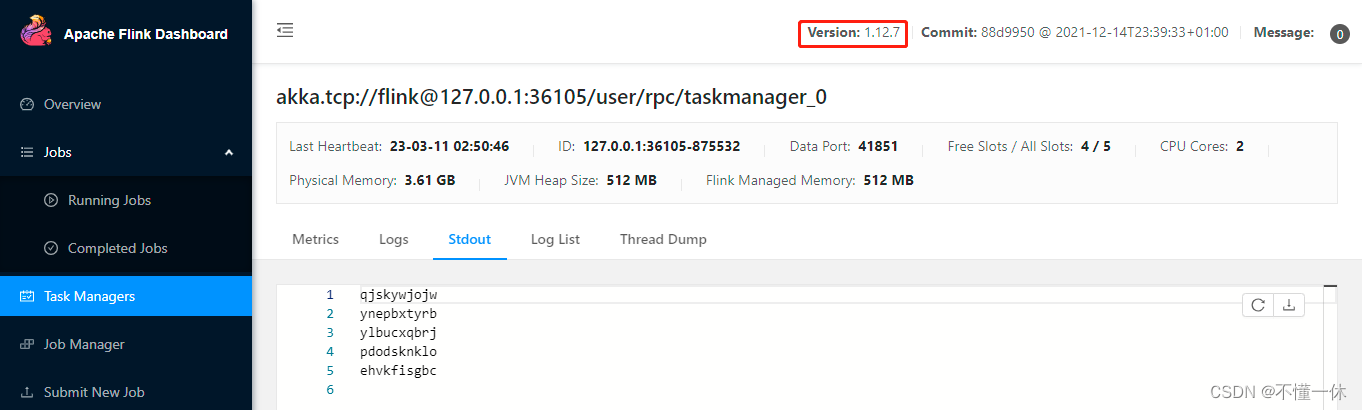
撤销任务当然也没问题,同样能正常释放 slot
当然你也可以不要 open() 方法
publicclassDiySinkRichextendsRichSourceFunction<String>{privateTimerTask timerTask;privateTimer timer;privateboolean flag =true;privateConcurrentLinkedQueue<String> queue =newConcurrentLinkedQueue<>();@Overridepublicvoidrun(SourceFunction.SourceContext<String> ctx)throwsException{
timerTask =newTimerTask(){@Overridepublicvoidrun(){Random random =newRandom();StringBuilder str =newStringBuilder();for(int i =0; i <10; i++){char ranLowLetter =(char)((random.nextInt(26)+97));
str.append(ranLowLetter);}
queue.add(str.toString());}};
timer =newTimer();
timer.schedule(timerTask,1000,5000);while(flag){if(queue.size()>0){
ctx.collect(queue.remove());}}}@Overridepublicvoidcancel(){if(timer !=null) timer.cancel();if(timerTask !=null) timerTask.cancel();if(queue.size()==0) flag =false;}}
以上就是 flink 定时加载数据源的简单实例
本文转载自: https://blog.csdn.net/qq_41538097/article/details/129457023
版权归原作者 不懂一休 所有, 如有侵权,请联系我们删除。
版权归原作者 不懂一休 所有, 如有侵权,请联系我们删除。