
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
在本章中,我们将帮助您设置 Spark,并通过三个简单的步骤开始编写您的第一个独立应用程序。我们将使用本地模式,其中所有处理都在 Spark shell 中的单台机器上完成——这是一种学习框架的简单方法,为迭代执行 Spark 操作提供快速反馈循环。使用 Spark shell,您可以在编写复杂的 Spark 应用程序之前使用小数据集对 Spark 操作进行原型设计,但对于希望获得分布式执行优势的大型数据集或实际工作,本地模式不适合——您需要改为使用 YARN 或 Kubernetes 部署模式。
虽然 Spark shell 仅支持 Scala、Python 和 R,但您可以使用任何受支持的语言(包括 Java)编写 Spark 应用程序并使用 Spark SQL 发出查询。我们确实希望您熟悉您选择的语言。
第 1 步:下载 Apache Spark
首先,进入Spark 下载页面,在步骤 2 的下拉菜单中选择“Pre-built for Apache Hadoop 2.7”,然后单击步骤 3 中的“下载 Spark”链接(图 2-1)。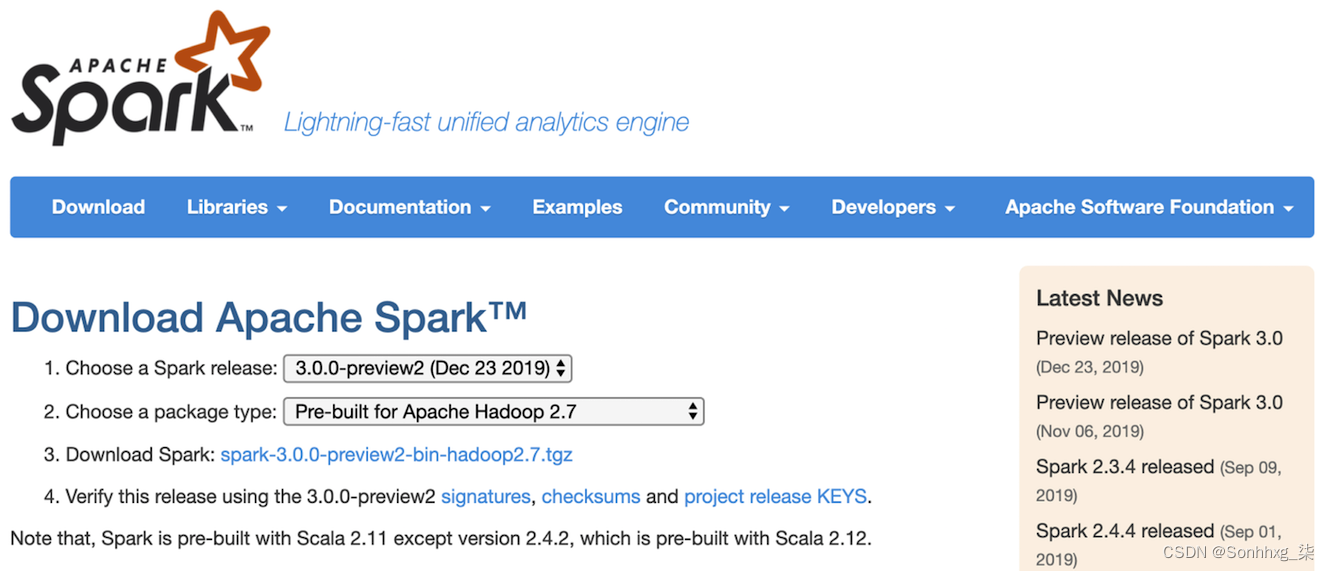
图 2-1。Apache Spark 下载页面
这将下载 tarball spark-3.0.0-preview2-bin-hadoop2.7.tgz,其中包含在笔记本电脑上以本地模式运行 Spark 所需的所有 Hadoop 相关二进制文件。或者,如果您要在现有的 HDFS 或 Hadoop 安装上安装它,您可以从下拉菜单中选择匹配的 Hadoop 版本。如何从源代码构建超出了本书的范围,但您可以在文档中阅读更多相关信息。
笔记
在本书付印时,Apache Spark 3.0 仍处于预览模式,但您可以使用相同的下载方法和说明下载最新的 Spark 3.0。
自 Apache Spark 2.2 发布以来,只关心在 Python 中学习 Spark 的开发人员可以选择从PyPI 存储库安装 PySpark 。如果您只使用 Python 编程,则无需安装运行 Scala、Java 或 R 所需的所有其他库;这使二进制文件更小。要从 PyPI 安装 PySpark,只需运行**
pip install pyspark
**.
**
pip install pyspark[sql,ml,mllib]
可以通过(或者
pip install pyspark[sql]
**如果您只想要 SQL 依赖项)为 SQL、ML 和 MLlib 安装一些额外的依赖项。
笔记
您需要在您的机器上安装 Java 8 或更高版本并设置
JAVA_HOME环境变量。有关如何下载和安装 Java 的说明,请参阅文档。
如果要在解释性 shell 模式下运行 R,则必须安装 R,然后运行
sparkR
. 要使用 R 进行分布式计算,您还可以使用由 R 社区创建的开源项目sparklyr。
Spark 的目录和文件
我们假设您在笔记本电脑或集群上运行某个版本的 Linux 或 macOS 操作系统,本书中的所有命令和说明都将采用这种风格。下载完 tarball 后,
cd
到下载的目录,使用 , 解压 tarball 内容
tar -xf spark-3.0.0-preview2-bin-hadoop2.7.tgz
,然后
cd
进入该目录并查看内容:
$ cd spark-3.0.0-preview2-bin-hadoop2.7
$ ls
LICENSE R RELEASE conf examples kubernetes python yarn
NOTICE README.md bin data jars licenses sbin
让我们简要总结其中一些文件和目录的意图和目的。Spark 2.x 和 3.0 中添加了新项目,并且一些现有文件和目录的内容也发生了变化:
README.md
此文件包含有关如何使用 Spark 外壳、从源代码构建 Spark、运行独立 Spark 示例、仔细阅读 Spark 文档和配置指南的链接以及为 Spark 做出贡献的新详细说明。
bin
顾名思义,此目录包含您将用于与 Spark 交互的大部分脚本,
including
即
Spark shells
(
spark-sql
、
pyspark
、
spark-shell
和
sparkR
)。我们将在本章后面使用这个目录中的这些 shell 和可执行文件来提交一个独立的 Spark 应用程序
spark-submit
,并编写一个脚本,在运行支持 Kubernetes 的 Spark 时构建和推送 Docker 镜像。
sbin
此目录中的大多数脚本都是管理性的,用于以各种部署模式启动和停止集群中的 Spark 组件。部署方式详见第一章表1-1中的备忘单。
Kubernetes
自 Spark 2.4 发布以来,此目录包含 Dockerfile,用于为 Kubernetes 集群上的 Spark 分发创建 Docker 映像。它还包含一个文件,提供有关如何在构建 Docker 映像之前构建 Spark 发行版的说明。
data
该目录包含**.txt*文件,这些文件用作 Spark 组件的输入:MLlib、Structured Streaming 和 GraphX。
examples
对于任何开发人员来说,简化学习任何新平台的旅程的两个必要条件是大量的“操作方法”代码示例和全面的文档。Spark 提供了 Java、Python、R 和 Scala 的示例,您在学习该框架时会想要使用它们。我们将在本章和后续章节中提及其中的一些示例.
第 2 步:使用 Scala 或 PySpark Shell
如前所述,Spark 带有四个广泛使用的解释器,它们的作用类似于交互式“shell”并支持临时数据分析:
pyspark
、
spark-shell
、
spark-sql
和
sparkR
. 在许多方面,如果您有 Python、Scala、R、SQL 或 Unix 操作系统 shell(如 bash 或 Bourne shell)的经验,它们的交互性会模仿您已经熟悉的 shell。
这些 shell 已得到增强,以支持连接到集群并允许您将分布式数据加载到 Spark 工作人员的内存中。无论您是处理千兆字节的数据还是小型数据集,Spark shell 都有利于快速学习 Spark。
要启动 PySpark,请到
cd
bin目录并键入
**pyspark**
. 如果您已经从 PyPI 安装了 PySpark,那么只需键入即可
**pyspark**
:
$ pyspark
Python 3.7.3 (default, Mar 27 2019, 09:23:15)
[Clang 10.0.1 (clang-1001.0.46.3)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
20/02/16 19:28:48 WARN NativeCodeLoader: Unable to load native-hadoop library
for your platform... using builtin-java classes where applicable
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3.0.0-preview2
/_/
Using Python version 3.7.3 (default, Mar 27 2019 09:23:15)
SparkSession available as 'spark'.
>>> spark.version
'3.0.0-preview2'
>>>
要使用 Scala 启动类似的 Spark shell,请到
cd
bin目录并键入
**spark-shell**
:
$ spark-shell
20/05/07 19:30:26 WARN NativeCodeLoader: Unable to load native-hadoop library
for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://10.0.1.7:4040
Spark context available as 'sc' (master = local[*], app id = local-1581910231902)
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.0.0-preview2
/_/
Using Scala version 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_241)
Type in expressions to have them evaluated.
Type :help for more information.
scala> spark.version
res0: String = 3.0.0-preview2
scala>
使用本地机器
现在您已经在本地计算机上下载并安装了 Spark,在本章的剩余部分中,您将在本地使用 Spark 解释性 shell。也就是说,Spark 将以本地模式运行。
笔记
请参阅第 1 章中的表 1-1,了解哪些组件在本地模式下运行的位置。
如前一章所述,Spark 计算表示为操作。然后将这些操作转换为基于 RDD 的低级字节码作为任务,分发给 Spark 的执行器执行。
让我们看一个简短的示例,我们将文本文件作为 DataFrame 读取,显示读取的字符串示例,并计算文件中的总行数。这个简单的示例说明了高级结构化 API 的使用,我们将在下一章中介绍。
show(10, false)
对DataFrame的操作只显示前10行不截断;默认情况下,
truncate
布尔标志是
true
. 这是在 Scala shell 中的样子:
scala> val strings = spark.read.text("../README.md")
strings: org.apache.spark.sql.DataFrame = [value: string]
scala> strings.show(10, false)
+------------------------------------------------------------------------------+
|value |
+------------------------------------------------------------------------------+
|# Apache Spark |
| |
|Spark is a unified analytics engine for large-scale data processing. It |
|provides high-level APIs in Scala, Java, Python, and R, and an optimized |
|engine that supports general computation graphs for data analysis. It also |
|supports a rich set of higher-level tools including Spark SQL for SQL and |
|DataFrames, MLlib for machine learning, GraphX for graph processing, |
| and Structured Streaming for stream processing. |
| |
|<https://spark.apache.org/> |
+------------------------------------------------------------------------------+
only showing top 10 rows
scala> strings.count()
res2: Long = 109
scala>
非常简单。让我们看一个使用 Python 解释性 shell 的类似示例
pyspark
:
$ pyspark
Python 3.7.3 (default, Mar 27 2019, 09:23:15)
[Clang 10.0.1 (clang-1001.0.46.3)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal
reflective access operations
WARNING: All illegal access operations will be denied in a future release
20/01/10 11:28:29 WARN NativeCodeLoader: Unable to load native-hadoop library
for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use
setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3.0.0-preview2
/_/
Using Python version 3.7.3 (default, Mar 27 2019 09:23:15)
SparkSession available as 'spark'.
>>> strings = spark.read.text("../README.md")
>>> strings.show(10, truncate=False)
+------------------------------------------------------------------------------+
|value |
+------------------------------------------------------------------------------+
|# Apache Spark |
| |
|Spark is a unified analytics engine for large-scale data processing. It |
|provides high-level APIs in Scala, Java, Python, and R, and an optimized |
|engine that supports general computation graphs for data analysis. It also |
|supports a rich set of higher-level tools including Spark SQL for SQL and |
|DataFrames, MLlib for machine learning, GraphX for graph processing, |
|and Structured Streaming for stream processing. |
| |
|<https://spark.apache.org/> |
+------------------------------------------------------------------------------+
only showing top 10 rows
>>> strings.count()
109
>>>
要退出任何 Spark shell,请按 Ctrl-D。如您所见,这种与 Spark shell 的快速交互不仅有利于快速学习,也有利于快速原型设计。
在前面的示例中,请注意跨 Scala 和 Python 的 API 语法和签名奇偶校验。在 Spark 从 1.x 的整个演变过程中,这一直是(众多)持久改进之一。
另请注意,我们使用高级结构化 API 将文本文件读入 Spark DataFrame 而不是 RDD。在整本书中,我们将更多地关注这些结构化 API;从 Spark 2.x 开始,RDD 现在被委托给低级 API。
笔记
以高级结构化 API 表示的每个计算都被分解为低级优化和生成的 RDD 操作,然后转换为执行程序的 JVM 的 Scala 字节码。这个生成的 RDD 操作代码是用户无法访问的,也和面向用户的 RDD API 不一样.
第 3 步:了解 Spark 应用程序概念
现在您已经下载了 Spark,以独立模式将其安装在您的笔记本电脑上,启动了 Spark shell,并以交互方式执行了一些简短的代码示例,您已准备好迈出最后一步。
要了解我们的示例代码在后台发生了什么,您需要熟悉 Spark 应用程序的一些关键概念,以及如何将代码转换并作为跨 Spark 执行器的任务执行。我们将从定义一些重要术语开始:
Application
使用其 API 在 Spark 上构建的用户程序。它由集群上的驱动程序和执行程序组成。
SparkSession
提供与底层 Spark 功能交互并允许使用其 API 对 Spark 进行编程的入口点的对象。在交互式 Spark shell 中,Spark 驱动程序
SparkSession
为您实例化 a,而在 Spark 应用程序中,您
SparkSession
自己创建一个对象。
Job
由多个任务组成的并行计算,这些任务响应 Spark 操作(例如
save()
、
collect()
)而产生。
Stage
每个作业都被分成更小的任务集,称为阶段,这些任务相互依赖。
Task
将发送到 Spark 执行器的单个工作或执行单元。
让我们更详细地研究这些概念。
Spark 应用程序和 SparkSession
每个 Spark 应用程序的核心是创建
SparkSession
对象的 Spark 驱动程序。当您使用 Spark shell 时,驱动程序是 shell 的一部分,并且为您创建了
SparkSession
对象(可通过变量 访问
spark
),正如您在启动 shell 时在前面的示例中看到的那样。
在这些示例中,因为您在笔记本电脑上本地启动了 Spark shell,所以所有操作都在本地运行,在单个 JVM 中。但是您可以像在本地模式下一样轻松地启动 Spark shell 以在集群上并行分析数据。命令
spark-shell --help
或
pyspark --help
将向您展示如何连接到 Spark 集群管理器。图 2-2显示了 Spark 在您完成此操作后如何在集群上执行。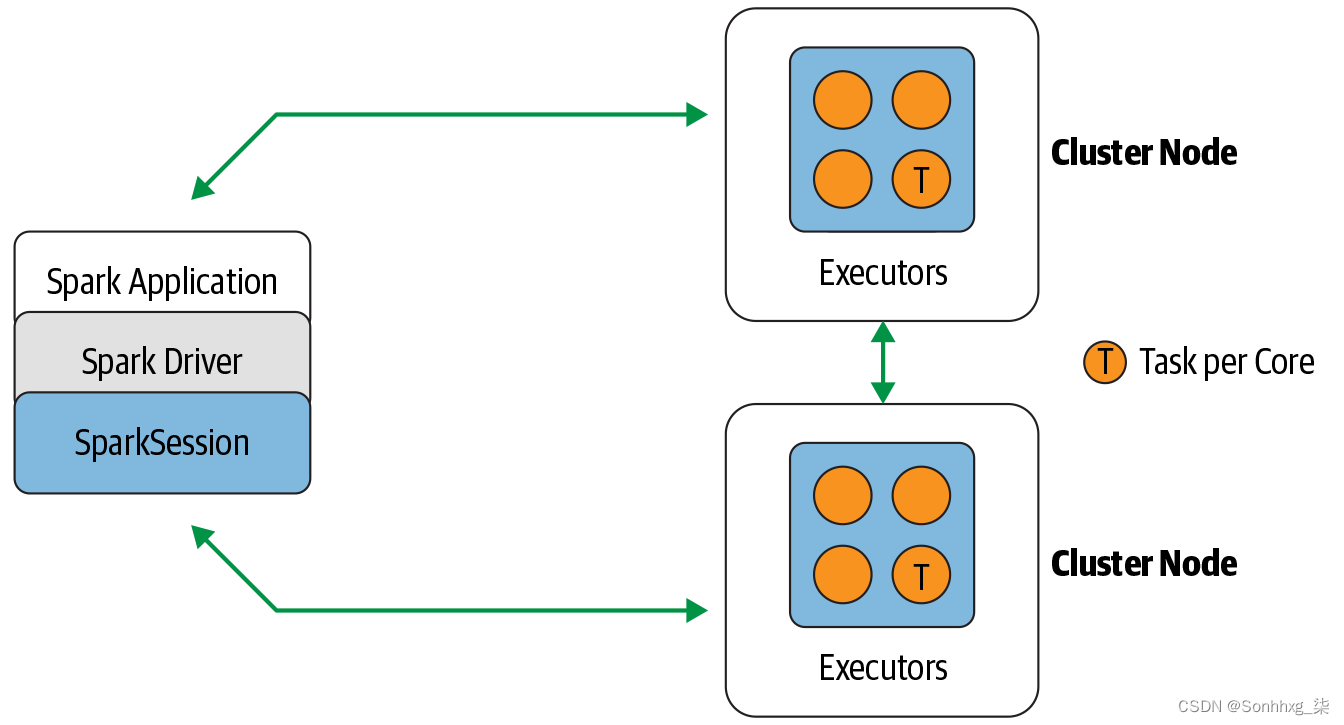
图 2-2。Spark 组件通过 Spark 分布式架构中的 Spark 驱动程序进行通信
拥有
SparkSession
后,您可以使用 API 对 Spark 进行编程以执行 Spark 操作。
Spark Jobs
在与 Spark shell 的交互会话期间,驱动程序将您的 Spark 应用程序转换为一个或多个 Spark 作业(图 2-3)。然后它将每个作业转换为 DAG。这实质上是 Spark 的执行计划,其中 DAG 中的每个节点可以是单个或多个 Spark 阶段。
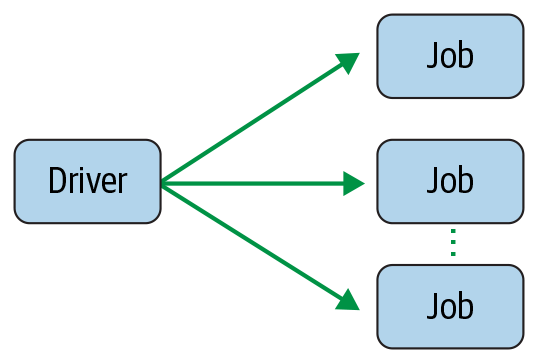
图 2-3。Spark 驱动程序创建一个或多个 Spark 作业
Spark Stages
作为 DAG 节点的一部分,阶段是根据可以串行或并行执行的操作来创建的(图 2-4)。并非所有 Spark 操作都可以在一个阶段发生,因此它们可能会分为多个阶段。阶段通常是在算子的计算边界上划定的,它们决定了 Spark 执行器之间的数据传输。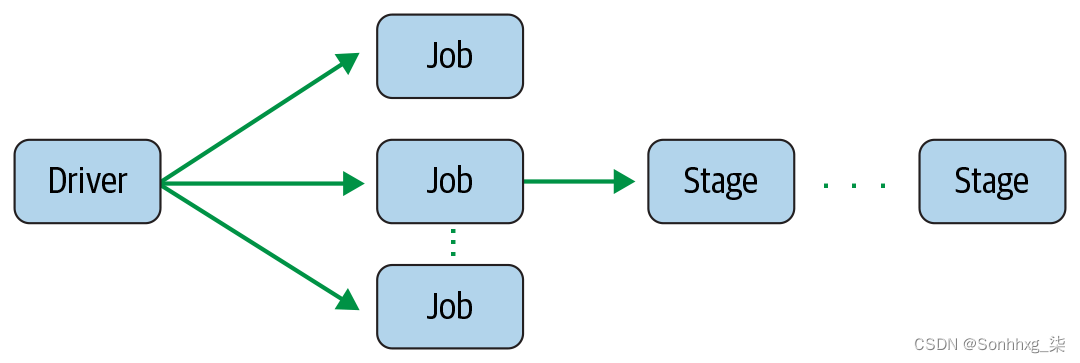
图 2-4。Spark 作业创建一个或多个阶段
Spark Tasks
每个阶段都由 Spark 任务(一个执行单元)组成,然后在每个 Spark 执行器之间进行联合;每个任务都映射到一个核心并处理单个数据分区(图 2-5)。因此,一个 16 核的执行器可以有 16 个或更多的任务在 16 个或更多的分区上并行工作,这使得 Spark 的任务的执行非常并行!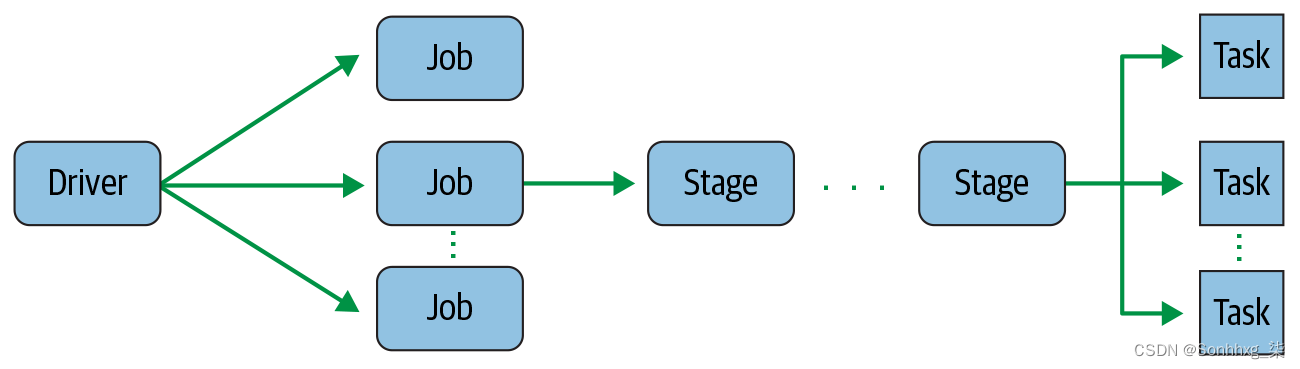
图 2-5。Spark 阶段创建一个或多个要分发给执行者的任务
转换、操作和惰性评估
Spark 对分布式数据的操作可以分为两种类型:转换和动作。Transformations,顾名思义,就是在不改变原始数据的情况下,将 Spark DataFrame 转换为新的 DataFrame,赋予其不变性。换句话说,一个操作比如
select()
或者
filter()
不会改变原来的DataFrame;相反,它将操作的转换结果作为新的 DataFrame 返回。
所有的转换都是惰性计算的。也就是说,它们的结果不是立即计算的,而是作为lineage记录或记忆的。记录的沿袭允许 Spark 在其执行计划的稍后时间重新安排某些转换、合并它们或将转换优化为阶段以更有效地执行。延迟评估是 Spark 延迟执行的策略,直到调用某个操作或“触摸”数据(从磁盘读取或写入磁盘)。
一个动作会触发对所有记录的转换的惰性求值。在图 2-6中,所有的转换 T 都被记录下来,直到动作 A 被调用。每个转换 T 都会产生一个新的 DataFrame。
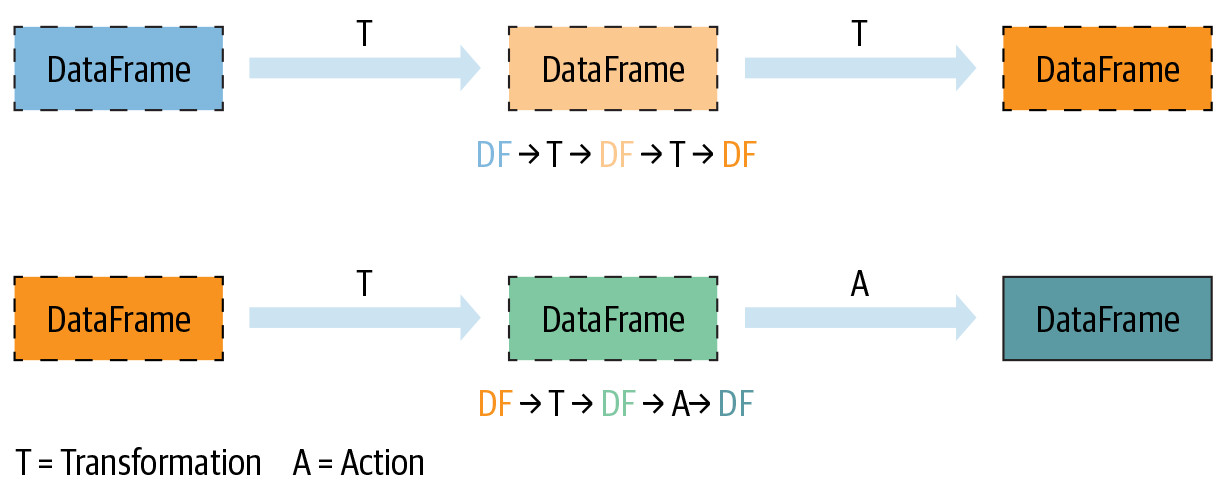
图 2-6。懒惰的转变和急切的行动
虽然惰性评估允许 Spark 通过查看链式转换来优化您的查询,但沿袭和数据不变性提供了容错性。因为 Spark 在其沿袭中记录每个转换,并且 DataFrame 在转换之间是不可变的,所以它可以通过简单地重放记录的沿袭来重现其原始状态,从而在发生故障时具有弹性。
表 2-1列出了一些转换和操作的示例。
表 2-1。作为 Spark 操作的转换和操作TransformationsActions
orderBy()
show()
groupBy()
take()
filter()
count()
select()
collect()
join()
save()
操作和转换有助于 Spark 查询计划,我们将在下一章中介绍。在调用操作之前,不会执行查询计划中的任何内容。下面的例子,在 Python 和 Scala 中都显示,有两个转换
read()
——
filter()
和一个动作——
count()
。该操作触发了作为查询执行计划的一部分记录的所有转换的执行。
filtered.count()
在这个例子中,在 shell 中执行之前什么都不会发生
# In Python
>>> strings = spark.read.text("../README.md")
>>> filtered = strings.filter(strings.value.contains("Spark"))
>>> filtered.count()
20
// In Scala
scala> import org.apache.spark.sql.functions._
scala> val strings = spark.read.text("../README.md")
scala> val filtered = strings.filter(col("value").contains("Spark"))
scala> filtered.count()
res5: Long = 20
狭义和广义的转变
如前所述,转换是 Spark 惰性求值的操作。惰性评估方案的一个巨大优势是 Spark 可以检查您的计算查询并确定它如何优化它。这种优化可以通过加入或流水线化一些操作并将它们分配到一个阶段来完成,或者通过确定哪些操作需要跨集群的洗牌或交换数据来将它们分成多个阶段。
转换可以分为窄依赖或宽依赖。可以从单个输入分区计算单个输出分区的任何转换都是窄转换。例如,在前面的代码片段中,
filter()
和
contains()
表示窄转换,因为它们可以在单个分区上操作并生成结果输出分区而无需任何数据交换。
但是,诸如
groupBy()
或
orderBy()
指示 Spark 之类的转换执行广泛的转换,其中来自其他分区的数据被读入、组合并写入磁盘。如果我们
filtered
通过调用 对前面示例中的 DataFrame进行排序
.orderBy()
,则每个分区都将在本地排序,但我们需要强制对集群中每个执行程序分区的数据进行洗牌,以对所有记录进行排序。与窄转换相比,宽转换需要其他分区的输出来计算最终聚合。
图 2-7说明了这两种依赖关系。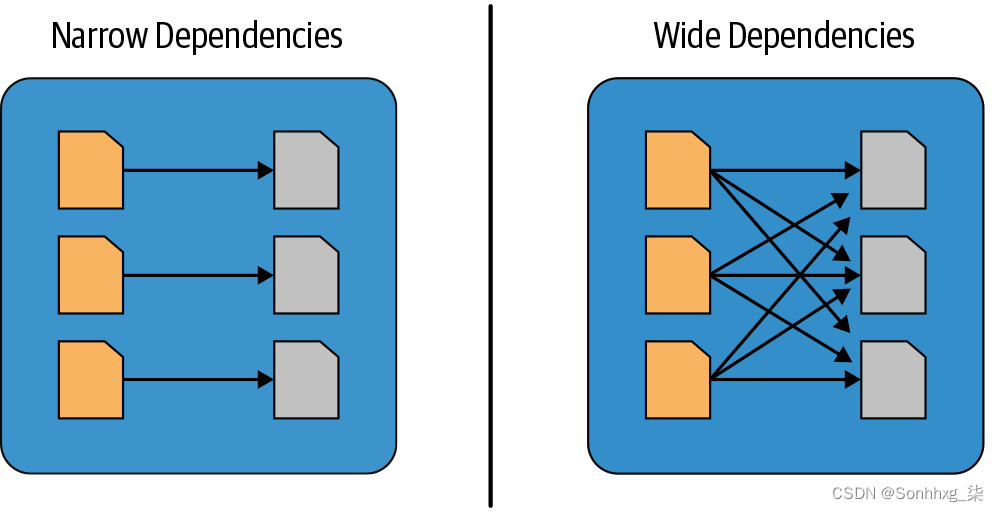
图 2-7。窄与宽转换
Spark用户界面
Spark 包含一个图形用户界面,您可以使用它来检查或监控 Spark 应用程序在其各个分解阶段(即作业、阶段和任务)中的情况。根据 Spark 的部署方式,驱动程序会启动一个 Web UI,默认在端口 4040 上运行,您可以在其中查看指标和详细信息,例如:
- 调度程序阶段和任务列表
- RDD 大小和内存使用情况总结
- 有关环境的信息
- 有关正在运行的执行程序的信息
- 所有 Spark SQL 查询
在本地模式下,您可以在 Web 浏览器中通过http://<localhost>:4040访问此界面。
笔记
当您启动时
spark-shell,部分输出显示要在端口 4040 访问的 localhost URL。
让我们看看上一节中的 Python 示例如何转换为作业、阶段和任务。要查看 DAG 的外观,请单击 Web UI 中的“DAG 可视化”。如图2-8所示,驱动程序创建了一个作业和一个阶段。
图 2-8。我们简单 Python 示例的 DAG
请注意,
Exchange
在 executor 之间交换数据的地方不需要,因为只有一个阶段。阶段的各个操作显示在蓝色框中。
阶段 0 由一项任务组成。如果您有多个任务,它们将并行执行。您可以在 Stages 选项卡中查看每个阶段的详细信息,如图 2-9所示。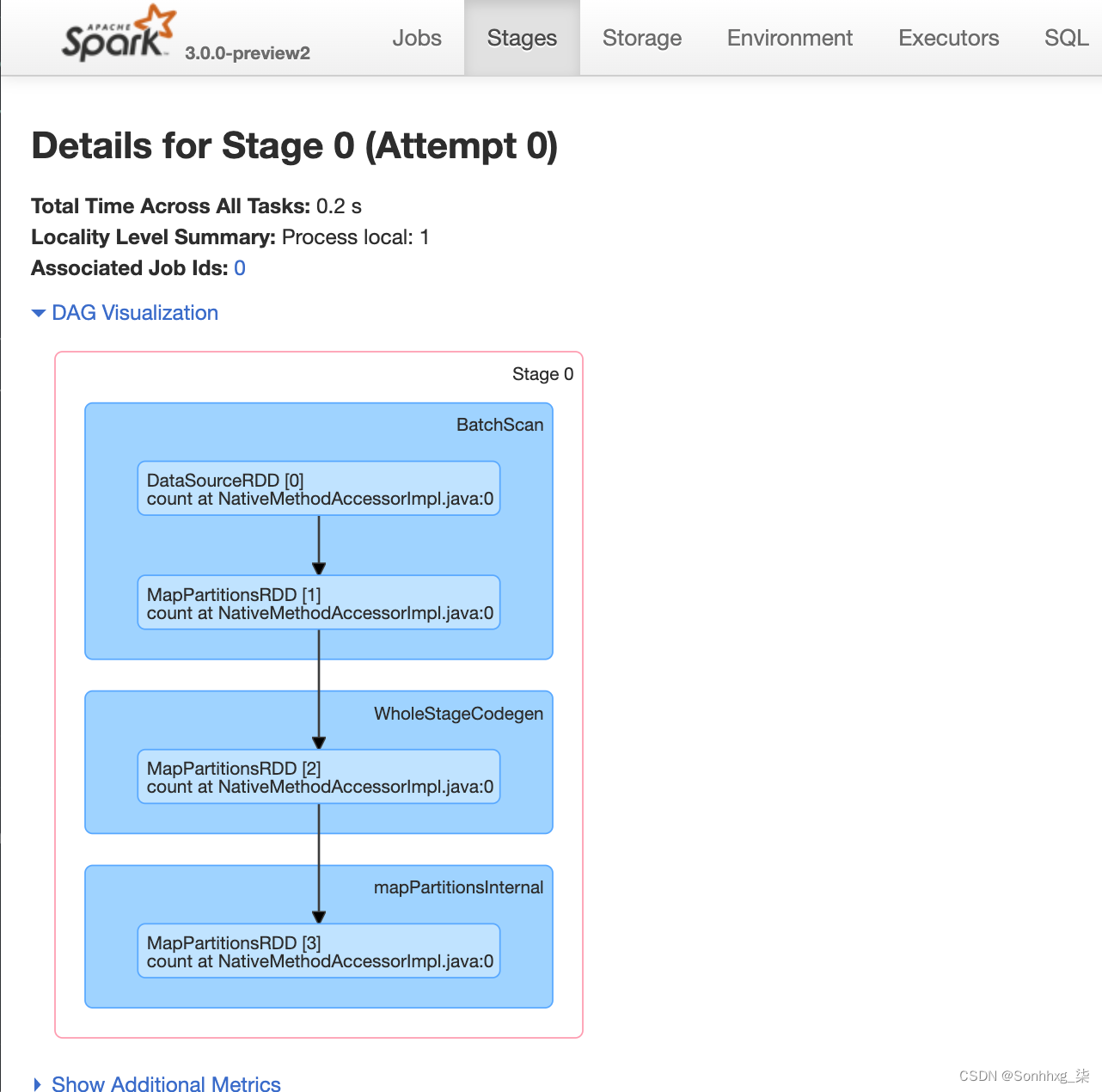
图 2-9。第0阶段的详细信息
我们将在第 7 章更详细地介绍 Spark UI 。现在,只需注意 UI 为 Spark 的内部工作提供了一个微观镜头,作为调试和检查的工具.
DATABRICKS 社区版
Databricks 是一家在云中提供托管 Apache Spark 平台的公司。除了使用本地机器以本地模式运行 Spark 之外,您还可以使用免费的 Databricks 社区版(图 2-10)尝试本章和其他章节中的一些示例。作为 Apache Spark 的学习工具,社区版有很多值得关注的教程和示例。除了使用 Python、R、Scala 或 SQL 编写自己的笔记本外,您还可以导入其他笔记本,包括 Jupyter 笔记本。
图 2-10。Databricks 社区版
要获得一个帐户,请访问Try Databricks – Databricks并按照说明免费试用社区版。注册后,您可以从其GitHub 存储库导入本书的笔记本。
您的第一个独立应用程序
为了便于学习和探索,Spark 发行版为 Spark 的每个组件都提供了一组示例应用程序。欢迎您仔细阅读安装位置中的示例目录,以了解可用的内容。
从本地机器上的安装目录,您可以运行使用命令提供的几个 Java 或 Scala 示例程序之一。例如:
bin/run-example *<class> [params]*
$ ./bin/run-example JavaWordCount README.md
这将在您的控制台上显示消息以及README.md
INFO
文件中每个单词的列表及其计数(计数单词是分布式计算的“Hello, World”)。
为 Cookie Monster 数 M&M
在前面的示例中,我们计算了文件中的单词。如果文件很大,它会分布在一个集群中,分成小块的数据,我们的 Spark 程序将分配计算每个分区中每个单词的任务,并返回最终的聚合计数。但是这个例子已经有点陈词滥调了。
让我们解决一个类似的问题,但使用更大的数据集并使用更多 Spark 的分发功能和 DataFrame API。我们将在后面的章节中介绍这个程序中使用的 API,但现在请耐心等待。
这本书的作者中有一位数据科学家,他喜欢用 M&Ms 烘焙饼干,她奖励她在美国各州的学生,在那里她经常用这些饼干批量教授机器学习和数据科学课程。但显然,她是数据驱动型的,并且希望确保她在不同州的学生的 cookie 中获得正确颜色的 M&Ms(图 2-11)。

图 2-11。M&Ms 按颜色分布(来源:https ://oreil.ly/mhWIT )
让我们编写一个 Spark 程序,它读取一个包含超过 100,000 个条目的文件(其中每一行或每一行都有一个),并计算和汇总每种颜色和状态的计数。这些汇总计数告诉我们每个州学生喜欢的 M&M 巧克力豆的颜色。示例 2-1中提供了完整的 Python 清单。
<*state*, *mnm_color*, *count*>
示例 2-1。计数和汇总 M&Ms(Python 版本)
# Import the necessary libraries.
# Since we are using Python, import the SparkSession and related functions
# from the PySpark module.
import sys
from pyspark.sql import SparkSession
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: mnmcount <file>", file=sys.stderr)
sys.exit(-1)
# Build a SparkSession using the SparkSession APIs.
# If one does not exist, then create an instance. There
# can only be one SparkSession per JVM.
spark = (SparkSession
.builder
.appName("PythonMnMCount")
.getOrCreate())
# Get the M&M data set filename from the command-line arguments
mnm_file = sys.argv[1]
# Read the file into a Spark DataFrame using the CSV
# format by inferring the schema and specifying that the
# file contains a header, which provides column names for comma-
# separated fields.
mnm_df = (spark.read.format("csv")
.option("header", "true")
.option("inferSchema", "true")
.load(mnm_file))
# We use the DataFrame high-level APIs. Note
# that we don't use RDDs at all. Because some of Spark's
# functions return the same object, we can chain function calls.
# 1. Select from the DataFrame the fields "State", "Color", and "Count"
# 2. Since we want to group each state and its M&M color count,
# we use groupBy()
# 3. Aggregate counts of all colors and groupBy() State and Color
# 4 orderBy() in descending order
count_mnm_df = (mnm_df
.select("State", "Color", "Count")
.groupBy("State", "Color")
.sum("Count")
.orderBy("sum(Count)", ascending=False))
# Show the resulting aggregations for all the states and colors;
# a total count of each color per state.
# Note show() is an action, which will trigger the above
# query to be executed.
count_mnm_df.show(n=60, truncate=False)
print("Total Rows = %d" % (count_mnm_df.count()))
# While the above code aggregated and counted for all
# the states, what if we just want to see the data for
# a single state, e.g., CA?
# 1. Select from all rows in the DataFrame
# 2. Filter only CA state
# 3. groupBy() State and Color as we did above
# 4. Aggregate the counts for each color
# 5. orderBy() in descending order
# Find the aggregate count for California by filtering
ca_count_mnm_df = (mnm_df
.select("State", "Color", "Count")
.where(mnm_df.State == "CA")
.groupBy("State", "Color")
.sum("Count")
.orderBy("sum(Count)", ascending=False))
# Show the resulting aggregation for California.
# As above, show() is an action that will trigger the execution of the
# entire computation.
ca_count_mnm_df.show(n=10, truncate=False)
# Stop the SparkSession
spark.stop()
您可以使用您喜欢的编辑器将此代码输入到名为mnmcount.py的 Python 文件中,从本书的GitHub存储库下载mnn_dataset.csv文件,然后使用安装的**bin目录中的脚本将其作为 Spark 作业提交。将您的环境变量设置为您在本地计算机上安装 Spark 的根级目录。
submit-spark
SPARK_HOME
笔记
前面的代码使用 DataFrame API,读起来像高级 DSL 查询。我们将在下一章介绍这个和其他 API;现在,请注意清楚和简单,您可以指示 Spark 做什么,而不是如何去做,这与 RDD API 不同。很酷的东西!
为避免将详细
INFO
消息打印到控制台,请将log4j.properties.template文件复制到log4j.properties并
log4j.rootCategory=WARN
在conf/log4j.properties文件中进行设置。
让我们使用 Python API 提交我们的第一个 Spark 作业(有关代码作用的解释,请阅读示例 2-1中的内联注释):
$SPARK_HOME/bin/spark-submit mnmcount.py data/mnm_dataset.csv
-----+------+----------+
|State| Color|sum(Count)|
+-----+------+----------+
| CA|Yellow| 100956|
| WA| Green| 96486|
| CA| Brown| 95762|
| TX| Green| 95753|
| TX| Red| 95404|
| CO|Yellow| 95038|
| NM| Red| 94699|
| OR|Orange| 94514|
| WY| Green| 94339|
| NV|Orange| 93929|
| TX|Yellow| 93819|
| CO| Green| 93724|
| CO| Brown| 93692|
| CA| Green| 93505|
| NM| Brown| 93447|
| CO| Blue| 93412|
| WA| Red| 93332|
| WA| Brown| 93082|
| WA|Yellow| 92920|
| NM|Yellow| 92747|
| NV| Brown| 92478|
| TX|Orange| 92315|
| AZ| Brown| 92287|
| AZ| Green| 91882|
| WY| Red| 91768|
| AZ|Orange| 91684|
| CA| Red| 91527|
| WA|Orange| 91521|
| NV|Yellow| 91390|
| UT|Orange| 91341|
| NV| Green| 91331|
| NM|Orange| 91251|
| NM| Green| 91160|
| WY| Blue| 91002|
| UT| Red| 90995|
| CO|Orange| 90971|
| AZ|Yellow| 90946|
| TX| Brown| 90736|
| OR| Blue| 90526|
| CA|Orange| 90311|
| OR| Red| 90286|
| NM| Blue| 90150|
| AZ| Red| 90042|
| NV| Blue| 90003|
| UT| Blue| 89977|
| AZ| Blue| 89971|
| WA| Blue| 89886|
| OR| Green| 89578|
| CO| Red| 89465|
| NV| Red| 89346|
| UT|Yellow| 89264|
| OR| Brown| 89136|
| CA| Blue| 89123|
| UT| Brown| 88973|
| TX| Blue| 88466|
| UT| Green| 88392|
| OR|Yellow| 88129|
| WY|Orange| 87956|
| WY|Yellow| 87800|
| WY| Brown| 86110|
+-----+------+----------+
Total Rows = 60
+-----+------+----------+
|State| Color|sum(Count)|
+-----+------+----------+
| CA|Yellow| 100956|
| CA| Brown| 95762|
| CA| Green| 93505|
| CA| Red| 91527|
| CA|Orange| 90311|
| CA| Blue| 89123|
+-----+------+----------+
首先,我们看到每个州的每种 M&M 颜色的所有聚合,然后是仅 CA(首选颜色是黄色)的聚合。
如果你想使用同一个 Spark 程序的 Scala 版本怎么办?API 类似;在 Spark 中,奇偶校验在受支持的语言中得到了很好的保留,语法差异很小. 示例 2-2是该程序的 Scala 版本。看一看,在下一节中,我们将向您展示如何构建和运行应用程序。
示例 2-2。计数和汇总 M&Ms(Scala 版本)
package main.scala.chapter2
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
/**
* Usage: MnMcount <mnm_file_dataset>
*/
object MnMcount {
def main(args: Array[String]) {
val spark = SparkSession
.builder
.appName("MnMCount")
.getOrCreate()
if (args.length < 1) {
print("Usage: MnMcount <mnm_file_dataset>")
sys.exit(1)
}
// Get the M&M data set filename
val mnmFile = args(0)
// Read the file into a Spark DataFrame
val mnmDF = spark.read.format("csv")
.option("header", "true")
.option("inferSchema", "true")
.load(mnmFile)
// Aggregate counts of all colors and groupBy() State and Color
// orderBy() in descending order
val countMnMDF = mnmDF
.select("State", "Color", "Count")
.groupBy("State", "Color")
.sum("Count")
.orderBy(desc("sum(Count)"))
// Show the resulting aggregations for all the states and colors
countMnMDF.show(60)
println(s"Total Rows = ${countMnMDF.count()}")
println()
// Find the aggregate counts for California by filtering
val caCountMnNDF = mnmDF
.select("State", "Color", "Count")
.where(col("State") === "CA")
.groupBy("State", "Color")
.sum("Count")
.orderBy(desc("sum(Count)"))
// Show the resulting aggregations for California
caCountMnMDF.show(10)
// Stop the SparkSession
spark.stop()
}
}
在 Scala 中构建独立应用程序
现在,我们将向您展示如何使用Scala 构建工具 (sbt)构建您的第一个 Scala Spark 程序。
笔记
因为 Python 是一种解释型语言,没有先编译这样的步骤(尽管可以将你的 Python 代码编译成*.pyc*中的字节码),所以这里我们不会进入这一步。有关如何使用 Maven 构建 Java Spark 程序的详细信息,请参阅Apache Spark 网站上的指南。为简洁起见,我们主要介绍 Python 和 Scala 中的示例。
build.sbt是一个规范文件,与 makefile 类似,它描述并指示 Scala 编译器构建与 Scala 相关的任务,例如 jar、包、要解决的依赖项以及在哪里查找它们。在我们的例子中,我们的 M&M 代码有一个简单的 sbt 文件(示例 2-3)。
示例 2-3。sbt 构建文件
// Name of the package
name := "main/scala/chapter2"
// Version of our package
version := "1.0"
// Version of Scala
scalaVersion := "2.12.10"
// Spark library dependencies
libraryDependencies ++= Seq(
"org.apache.spark" %% "spark-core" % "3.0.0-preview2",
"org.apache.spark" %% "spark-sql" % "3.0.0-preview2"
)
假设您已经安装并设置了Java开发工具包 (JDK)和 sbt ,只需一个命令,您就可以构建您的 Spark 应用程序:
JAVA_HOME
SPARK_HOME
$ sbt clean package
[info] Updated file /Users/julesdamji/gits/LearningSparkV2/chapter2/scala/
project/build.properties: set sbt.version to 1.2.8
[info] Loading project definition from /Users/julesdamji/gits/LearningSparkV2/
chapter2/scala/project
[info] Updating
[info] Done updating.
...
[info] Compiling 1 Scala source to /Users/julesdamji/gits/LearningSparkV2/
chapter2/scala/target/scala-2.12/classes ...
[info] Done compiling.
[info] Packaging /Users/julesdamji/gits/LearningSparkV2/chapter2/scala/target/
scala-2.12/main-scala-chapter2_2.12-1.0.jar ...
[info] Done packaging.
[success] Total time: 6 s, completed Jan 11, 2020, 4:11:02 PM
成功构建后,您可以运行 Scala 版本的 M&M 计数示例,如下所示:
$SPARK_HOME/bin/spark-submit --class main.scala.chapter2.MnMcount \
jars/main-scala-chapter2_2.12-1.0.jar data/mnm_dataset.csv
...
...
20/01/11 16:00:48 INFO TaskSchedulerImpl: Killing all running tasks in stage 4:
Stage finished
20/01/11 16:00:48 INFO DAGScheduler: Job 4 finished: show at MnMcount.scala:49,
took 0.264579 s
+-----+------+-----+
|State| Color|Total|
+-----+------+-----+
| CA|Yellow| 1807|
| CA| Green| 1723|
| CA| Brown| 1718|
| CA|Orange| 1657|
| CA| Red| 1656|
| CA| Blue| 1603|
+-----+------+-----+
输出与 Python 运行的输出相同。试试看!
你有它 - 我们的数据科学家作者将非常乐意使用这些数据来决定在她任教的任何州为她的班级烘焙的饼干中使用什么颜色的 M&M。
概括
在本章中,我们介绍了开始使用 Apache Spark 所需的三个简单步骤:下载框架、熟悉 Scala 或 PySpark 交互式 shell,以及掌握高级 Spark 应用程序概念和术语。我们简要概述了您可以使用转换和操作来编写 Spark 应用程序的过程,并简要介绍了使用 Spark UI 检查创建的作业、阶段和任务。
版权归原作者 Sonhhxg_柒 所有, 如有侵权,请联系我们删除。