
Clickhouse的优点.
- 真正的面向列的 DBMS
ClickHouse 是一个 DBMS,而不是一个单一的数据库。它允许在运行时创建表和数据库、加载数据和运行
查询,而无需重新配置和重新启动服务器。
- 数据压缩
一些面向列的 DBMS(InfiniDB CE 和 MonetDB)不使用数据压缩。但是,数据压缩确实提高了性能。
- 磁盘存储的数据
- 在多个服务器上分布式处理
- SQL支持
- 数据不仅按列存储,而且由矢量 - 列的部分进行处理,这使开发者能够实现高 CPU 性能
Clickhouse的缺点
- 没有完整的事务支持,
- 缺少完整的Update/Delete操作,缺少高频率、低延迟的修改或删除已存在数据的能力,仅能用于批量删
除或修改数据
- 聚合结果必须小于一台机器的内存大小:
- 不适合key-value存储,
什么时候不可以用Clickhouse?
- 事物性工作(OLTP)
- 高并发的键值访问
- Blob或者文档存储
- 超标准化的数据
Flink CDC
=========
Flink cdc connector 消费 Debezium 里的数据,经过处理再sink出来,这个流程还是相对比较简单的
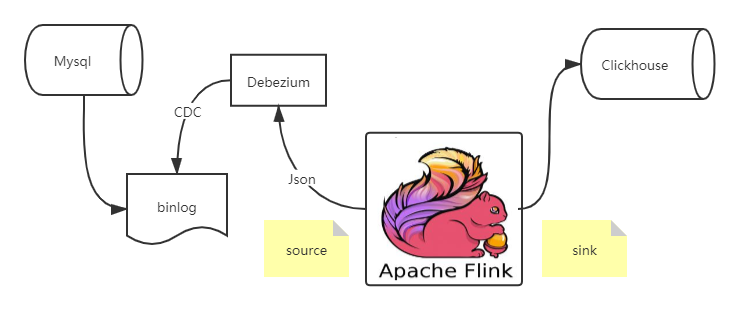
首先创建 Source 和 Sink(对应的依赖引用,在文末)
SourceFunction sourceFunction = MySQLSource.builder()
.hostname(“localhost”)
.port(3306)
.databaseList(“test”)
.username(“flinkcdc”)
.password(“dafei1288”)
.deserializer(new JsonDebeziumDeserializationSchema())
.build();
// 添加 source
env.addSource(sourceFunction)
// 添加 sink
.addSink(new ClickhouseSink());
这里用到的JsonDebeziumDeserializationSchema,是我们自定义的一个序列化类,用于将Debezium输出的数据,序列化
public static class JsonDebeziumDeserializationSchema implements DebeziumDeserializationSchema {
@Override
public void deserialize(SourceRecord sourceRecord, Collector collector) throws Exception {
Gson jsstr = new Gson();
HashMap<String, Object> hs = new HashMap<>();
String topic = sourceRecord.topic();
String[] split = topic.split(“[.]”);
String database = split[1];
String table = split[2];
hs.put(“database”,database);
hs.put(“table”,table);
//获取操作类型
Envelope.Operation operation = Envelope.operationFor(sourceRecord);
//获取数据本身
Struct struct = (Struct)sourceRecord.value();
Struct after = struct.getStruct(“after”);
if (after != null) {
Schema schema = after.schema();
HashMap<String, Object> afhs = new HashMap<>();<
版权归原作者 2301_79055107 所有, 如有侵权,请联系我们删除。