
博客主页:https://tomcat.blog.csdn.net
博主昵称:农民工老王
主要领域:Java、Linux、K8S
期待大家的关注💖点赞👍收藏⭐留言💬

目录
故障详情
最近,在工作中遇到一个问题:某位同事在我维护的k8s集群中部署deployment时一直遇到如下报错:
0/4 nodes are available: 1 node(s) had taint {node-role.kubernetes.io/master: true}, that the pod didn't tolerate, 3 Insufficient memory.
如图所示: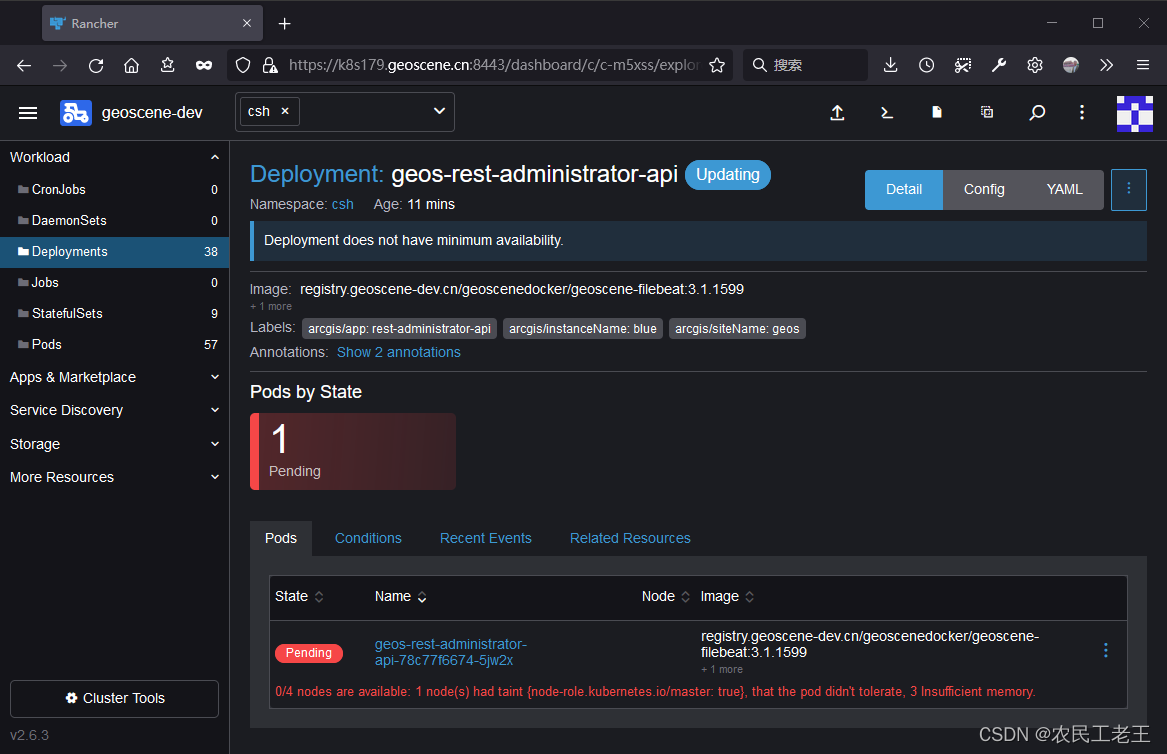
看到这个内存不足的报错后,我就在rancher的dashboard里查看了集群资源的利用情况(本文中的k8s由rancher 2.6部署和托管):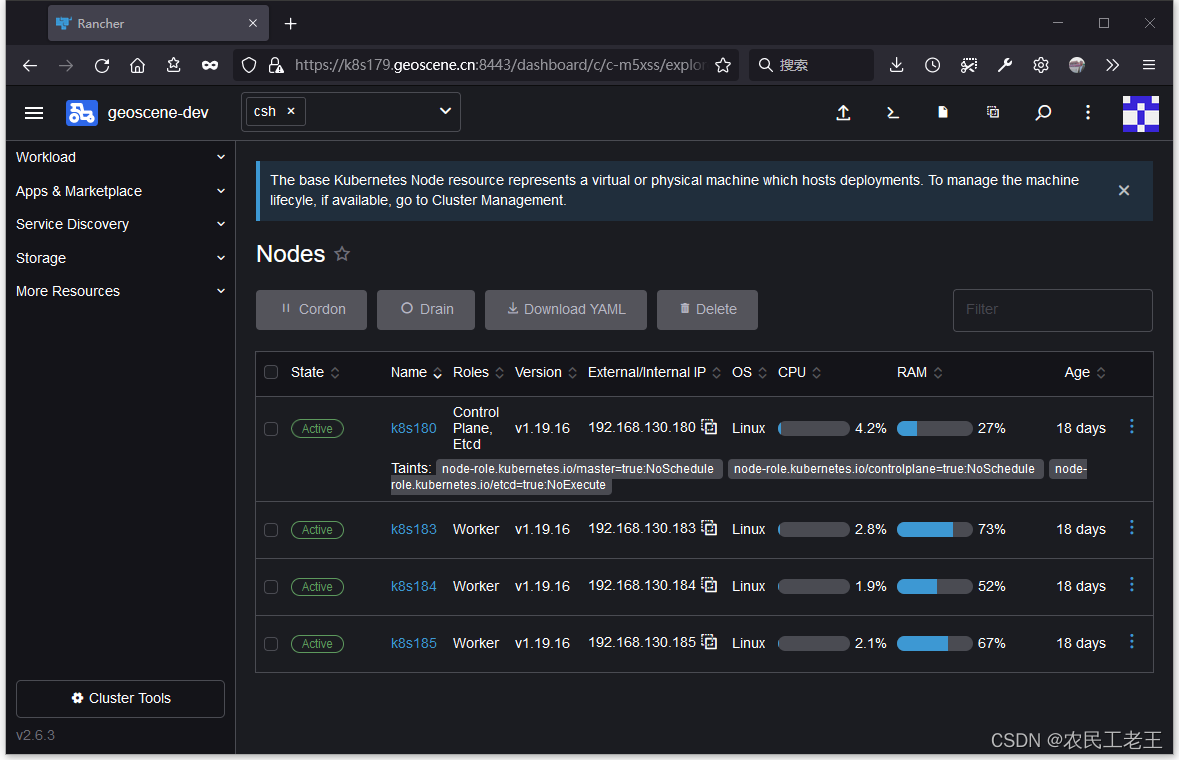
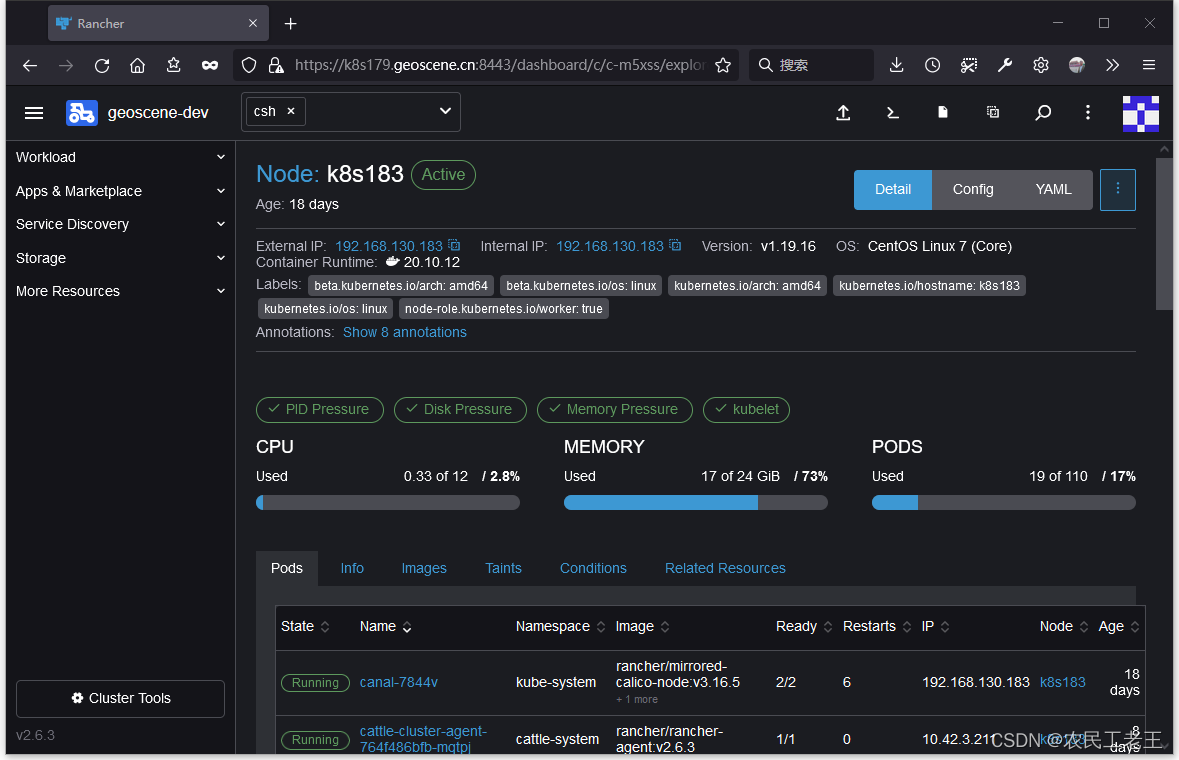
上述页面显示,所有的节点都有比较充裕的内存空间,就连内存消耗最多的机器,都还剩7G。
通过查看yaml中的资源需求,确定了待部署的deployment所需内存仅有1G。
resources:limits:cpu:"1"memory: 2Gi
requests:cpu: 500m
memory: 1Gi
这下就郁闷了,明明内存还有很多,为何却报错内存不足?
分析原因
最终我发现,rancher 2.6 的 dashboard中的内存占用数值 反映的是各个节点的内存实际使用情况,相当于在计算机上用
free
或者
top
命令查看到的数据。而本文中的报错是针对resources.requests中申明的所需内存的数值。
而在rancher 2.5的管理界面中展示的数据为k8s对象申明的所需资源,也就是本文中的报错所提示的不够的资源。如下图所示: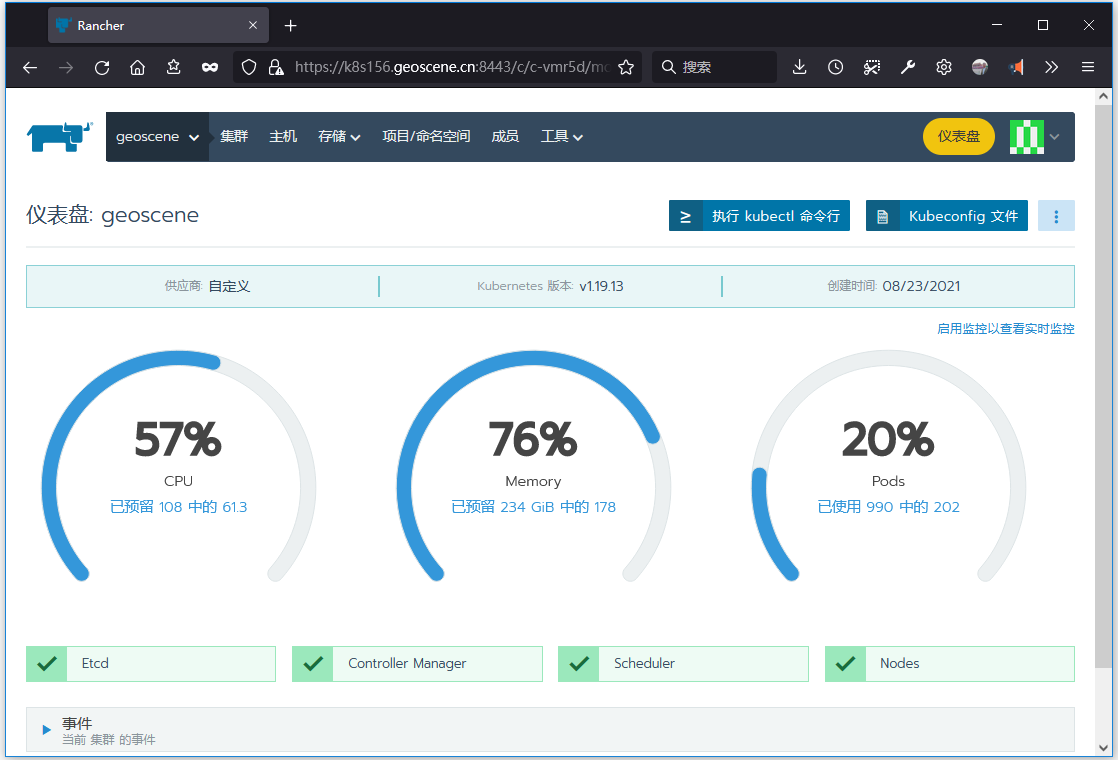
如果不知道这个变化,就容易遇到类似的问题。
部署deployment、statefulSets等各种k8s对象时,在配置文件里添加resources.requests就可以给容器申明所需内存和CPU资源。但全部容器的所需资源之和不能超过集群可用资源的总量。同时,在新部署k8s对象时,必须有一个worker节点的各项剩余资源都大于当前部署的k8s对象申明的所需资源,才能实现部署,否则就会报类似上文中的错误。
进行上述检查的命令是
kubectl describe node
。但该命令返回的信息过于庞杂,如果只是想查看集群的CPU和内存资源的申明占用情况,可以使用下面的指令进行查看和过滤:
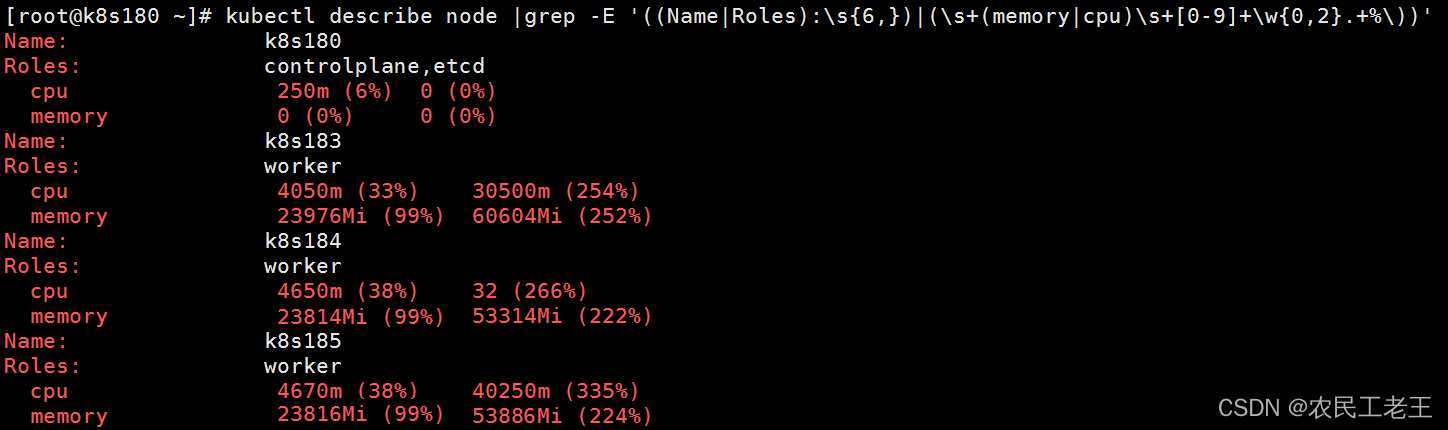
kubectl describe node|grep -E '((Name|Roles):\s{6,})|(\s+(memory|cpu)\s+[0-9]+\w{0,2}.+%\))'
下图是对本文中的k8s集群的检查结果。可以明显地看到,所有的worker节点的内存Requests都已经达到99%,剩余的1%不足1G,因而无法部署上文中的deployment。
解决故障
找到了报错原因,那解决这个故障也就很容易了。以下三个方法都可以消除报错,并实现deployment的安装:
- 清理已安装的k8s对象,既可以删除一部分,也可以将某些对象的requests的值换成一个更小的数。
- 扩容k8s集群。
- 修改待安装的deployment的requests的值,减少申明的所需内存。
如需转载,请注明本文的出处:农民工老王的CSDN博客https://blog.csdn.net/monarch91 。
版权归原作者 农民工老王 所有, 如有侵权,请联系我们删除。