
一、例子说明
1.1、概述
这是个例子,将输入写入kafka,flink消费kafka,并实时写入doris。
1.1、所需环境
软件版本备注kafka_2.12-3.5.0kafka_2.12-3.5.0使用自带的zookeeperflink-1.17.1flink-1.17.1jdk1.8.0_202doris1.2.6 ( Stable )
spring-boot
2.1.17.RELEASE
syslog-kafka-es-avro
spring-boot2.4.5
flink-do-doris
flink-doris-connector-1.17
1.4.0
elasticsearch7.6.2基础目录/home服务器10.10.10.99centos 7.x
1.2、执行流程
①、工具发送数据
②、spring-boot基于netty开启某端口监听,接收发送的消息内容,进行数据清洗、标准化
③、kafka product组件接收上一步产生的数据,已avro格式保存到kafka某topic上。
④、flink实时消费kafka某topic,以流的方式进行处理,输出源设置为doris
⑤、终端数据可在doris的fe页面上实时查询。
二、部署环境
2.1、中间件部署
2.1.1部署kakfa
2.1.1.1 上传解压kafka安装包
将安装包kafka_2.12-3.5.0.tar.gz上传到/home目录
tar -zxvf kafka_2.12-3.5.0.tar.gz
mv kafka_2.12-3.5.0 kafka
2.1.1.2 修改zookeeper.properties
路径:/home/kafka/config/zookeeper.properties
dataDir=/home/kafka/zookeeper
clientPort=2181
maxClientCnxns=0
admin.enableServer=falseadmin.serverPort=8080
2.1.1.3 修改server.properties
路径:/home/kafka/config/server.properties
Licensed to the Apache Software Foundation (ASF) under one or more
contributor license agreements. See the NOTICE file distributed with
this work for additional information regarding copyright ownership.
The ASF licenses this file to You under the Apache License, Version 2.0
(the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
This configuration file is intended for use in ZK-based mode, where Apache ZooKeeper is required.
See kafka.server.KafkaConfig for additional details and defaults
############################# Server Basics #############################
The id of the broker. This must be set to a unique integer for each broker.
broker.id=0
############################# Socket Server Settings #############################
The address the socket server listens on. If not configured, the host name will be equal to the value of
java.net.InetAddress.getCanonicalHostName(), with PLAINTEXT listener name, and port 9092.
FORMAT:
listeners = listener_name://host_name:port
EXAMPLE:
listeners = PLAINTEXT://your.host.name:9092
listeners=PLAINTEXT://:9092
Listener name, hostname and port the broker will advertise to clients.
If not set, it uses the value for "listeners".
advertised.listeners=PLAINTEXT://10.10.10.99:9092
Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details
#listener.security.protocol.map=PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
The number of threads that the server uses for receiving requests from the network and sending responses to the network
num.network.threads=3
The number of threads that the server uses for processing requests, which may include disk I/O
num.io.threads=8
The send buffer (SO_SNDBUF) used by the socket server
socket.send.buffer.bytes=102400
The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes=102400
The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes=104857600
############################# Log Basics #############################
A comma separated list of directories under which to store log files
log.dirs=/home/kafka/kafka-logs
The default number of log partitions per topic. More partitions allow greater
parallelism for consumption, but this will also result in more files across
the brokers.
num.partitions=1
The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
This value is recommended to be increased for installations with data dirs located in RAID array.
num.recovery.threads.per.data.dir=1
############################# Internal Topic Settings #############################
The replication factor for the group metadata internal topics "__consumer_offsets" and "__transaction_state"
For anything other than development testing, a value greater than 1 is recommended to ensure availability such as 3.
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1############################# Log Flush Policy #############################
Messages are immediately written to the filesystem but by default we only fsync() to sync
the OS cache lazily. The following configurations control the flush of data to disk.
There are a few important trade-offs here:
1. Durability: Unflushed data may be lost if you are not using replication.
2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.
3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to excessive seeks.
The settings below allow one to configure the flush policy to flush data after a period of time or
every N messages (or both). This can be done globally and overridden on a per-topic basis.
The number of messages to accept before forcing a flush of data to disk
log.flush.interval.messages=10000
The maximum amount of time a message can sit in a log before we force a flush
log.flush.interval.ms=1000
############################# Log Retention Policy #############################
The following configurations control the disposal of log segments. The policy can
be set to delete segments after a period of time, or after a given size has accumulated.
A segment will be deleted whenever either of these criteria are met. Deletion always happens
from the end of the log.
The minimum age of a log file to be eligible for deletion due to age
log.retention.hours=168
A size-based retention policy for logs. Segments are pruned from the log unless the remaining
segments drop below log.retention.bytes. Functions independently of log.retention.hours.
#log.retention.bytes=1073741824
The maximum size of a log segment file. When this size is reached a new log segment will be created.
#log.segment.bytes=1073741824
The interval at which log segments are checked to see if they can be deleted according
to the retention policies
log.retention.check.interval.ms=300000
############################# Zookeeper #############################
Zookeeper connection string (see zookeeper docs for details).
This is a comma separated host:port pairs, each corresponding to a zk
server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
You can also append an optional chroot string to the urls to specify the
root directory for all kafka znodes.
zookeeper.connect=localhost:2181
Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=18000
############################# Group Coordinator Settings #############################
The following configuration specifies the time, in milliseconds, that the GroupCoordinator will delay the initial consumer rebalance.
The rebalance will be further delayed by the value of group.initial.rebalance.delay.ms as new members join the group, up to a maximum of max.poll.interval.ms.
The default value for this is 3 seconds.
We override this to 0 here as it makes for a better out-of-the-box experience for development and testing.
However, in production environments the default value of 3 seconds is more suitable as this will help to avoid unnecessary, and potentially expensive, rebalances during application startup.
group.initial.rebalance.delay.ms=0
2.1.1.3 启动kafka
①、先启动kafka自带的zookeeper
nohup /home/kafka/bin/zookeeper-server-start.sh /home/kafka/config/zookeeper.properties 2>&1 &
验证启动情况ps -ef | grep zookeeper
②启动kafka
/home/kafka/bin/kafka-server-start.sh -daemon /home/kafka/config/server.properties
验证启动情况
etstat -ntulp | grep 9092
或者ps -ef | grep kafka
2.1.2、部署flink
2.1.2.1 上传解压flink安装包
下载地址https://dlcdn.apache.org/flink/flink-1.17.1/flink-1.17.1-bin-scala_2.12.tgz
下载完成后将flink-1.17.1-bin-scala_2.12.tgz上传到/home目录下,解压并重命名为flink
2.1.2.1 修改flink配置
配置文件路径/home/flink/conf/flink-conf.yaml
################################################################################
Licensed to the Apache Software Foundation (ASF) under one
or more contributor license agreements. See the NOTICE file
distributed with this work for additional information
regarding copyright ownership. The ASF licenses this file
to you under the Apache License, Version 2.0 (the
"License"); you may not use this file except in compliance
with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
################################################################################
#==============================================================================
Common
#==============================================================================
The external address of the host on which the JobManager runs and can be
reached by the TaskManagers and any clients which want to connect. This setting
is only used in Standalone mode and may be overwritten on the JobManager side
by specifying the --host <hostname> parameter of the bin/jobmanager.sh executable.
In high availability mode, if you use the bin/start-cluster.sh script and setup
the conf/masters file, this will be taken care of automatically. Yarn
automatically configure the host name based on the hostname of the node where the
JobManager runs.
jobmanager.rpc.address: localhost
The RPC port where the JobManager is reachable.
jobmanager.rpc.port: 6123
The host interface the JobManager will bind to. By default, this is localhost, and will prevent
the JobManager from communicating outside the machine/container it is running on.
On YARN this setting will be ignored if it is set to 'localhost', defaulting to 0.0.0.0.
On Kubernetes this setting will be ignored, defaulting to 0.0.0.0.
To enable this, set the bind-host address to one that has access to an outside facing network
interface, such as 0.0.0.0.
jobmanager.bind-host: 0.0.0.0
The total process memory size for the JobManager.
Note this accounts for all memory usage within the JobManager process, including JVM metaspace and other overhead.
jobmanager.memory.process.size: 1600m
The host interface the TaskManager will bind to. By default, this is localhost, and will prevent
the TaskManager from communicating outside the machine/container it is running on.
On YARN this setting will be ignored if it is set to 'localhost', defaulting to 0.0.0.0.
On Kubernetes this setting will be ignored, defaulting to 0.0.0.0.
To enable this, set the bind-host address to one that has access to an outside facing network
interface, such as 0.0.0.0.
taskmanager.bind-host: 0.0.0.0
The address of the host on which the TaskManager runs and can be reached by the JobManager and
other TaskManagers. If not specified, the TaskManager will try different strategies to identify
the address.
Note this address needs to be reachable by the JobManager and forward traffic to one of
the interfaces the TaskManager is bound to (see 'taskmanager.bind-host').
Note also that unless all TaskManagers are running on the same machine, this address needs to be
configured separately for each TaskManager.
taskmanager.host: localhost
The total process memory size for the TaskManager.
Note this accounts for all memory usage within the TaskManager process, including JVM metaspace and other overhead.
taskmanager.memory.process.size: 1728m
To exclude JVM metaspace and overhead, please, use total Flink memory size instead of 'taskmanager.memory.process.size'.
It is not recommended to set both 'taskmanager.memory.process.size' and Flink memory.
taskmanager.memory.flink.size: 1280m
The number of task slots that each TaskManager offers. Each slot runs one parallel pipeline.
taskmanager.numberOfTaskSlots: 1
The parallelism used for programs that did not specify and other parallelism.
parallelism.default: 1
The default file system scheme and authority.
By default file paths without scheme are interpreted relative to the local
root file system 'file:///'. Use this to override the default and interpret
relative paths relative to a different file system,
for example 'hdfs://mynamenode:12345'
fs.default-scheme
#==============================================================================
High Availability
#==============================================================================
The high-availability mode. Possible options are 'NONE' or 'zookeeper'.
high-availability.type: zookeeper
The path where metadata for master recovery is persisted. While ZooKeeper stores
the small ground truth for checkpoint and leader election, this location stores
the larger objects, like persisted dataflow graphs.
Must be a durable file system that is accessible from all nodes
(like HDFS, S3, Ceph, nfs, ...)
high-availability.storageDir: hdfs:///flink/ha/
The list of ZooKeeper quorum peers that coordinate the high-availability
setup. This must be a list of the form:
"host1:clientPort,host2:clientPort,..." (default clientPort: 2181)
high-availability.zookeeper.quorum: localhost:2181
ACL options are based on https://zookeeper.apache.org/doc/r3.1.2/zookeeperProgrammers.html#sc_BuiltinACLSchemes
It can be either "creator" (ZOO_CREATE_ALL_ACL) or "open" (ZOO_OPEN_ACL_UNSAFE)
The default value is "open" and it can be changed to "creator" if ZK security is enabled
high-availability.zookeeper.client.acl: open
#==============================================================================
Fault tolerance and checkpointing
#==============================================================================
The backend that will be used to store operator state checkpoints if
checkpointing is enabled. Checkpointing is enabled when execution.checkpointing.interval > 0.
Execution checkpointing related parameters. Please refer to CheckpointConfig and ExecutionCheckpointingOptions for more details.
execution.checkpointing.interval: 3min
execution.checkpointing.externalized-checkpoint-retention: [DELETE_ON_CANCELLATION, RETAIN_ON_CANCELLATION]
execution.checkpointing.max-concurrent-checkpoints: 1
execution.checkpointing.min-pause: 0
execution.checkpointing.mode: [EXACTLY_ONCE, AT_LEAST_ONCE]
execution.checkpointing.timeout: 10min
execution.checkpointing.tolerable-failed-checkpoints: 0
execution.checkpointing.unaligned: false
Supported backends are 'hashmap', 'rocksdb', or the
<class-name-of-factory>.
state.backend.type: hashmap
Directory for checkpoints filesystem, when using any of the default bundled
state backends.
state.checkpoints.dir: hdfs://namenode-host:port/flink-checkpoints
Default target directory for savepoints, optional.
state.savepoints.dir: hdfs://namenode-host:port/flink-savepoints
Flag to enable/disable incremental checkpoints for backends that
support incremental checkpoints (like the RocksDB state backend).
state.backend.incremental: false
The failover strategy, i.e., how the job computation recovers from task failures.
Only restart tasks that may have been affected by the task failure, which typically includes
downstream tasks and potentially upstream tasks if their produced data is no longer available for consumption.
jobmanager.execution.failover-strategy: region
#==============================================================================
Rest & web frontend
#==============================================================================
The port to which the REST client connects to. If rest.bind-port has
not been specified, then the server will bind to this port as well.
rest.port: 8081
The address to which the REST client will connect to
rest.address: 10.10.10.99
Port range for the REST and web server to bind to.
#rest.bind-port: 8080-8090
The address that the REST & web server binds to
By default, this is localhost, which prevents the REST & web server from
being able to communicate outside of the machine/container it is running on.
To enable this, set the bind address to one that has access to outside-facing
network interface, such as 0.0.0.0.
rest.bind-address: 0.0.0.0
Flag to specify whether job submission is enabled from the web-based
runtime monitor. Uncomment to disable.
web.submit.enable: true
Flag to specify whether job cancellation is enabled from the web-based
runtime monitor. Uncomment to disable.
web.cancel.enable: true
#==============================================================================
Advanced
#==============================================================================
Override the directories for temporary files. If not specified, the
system-specific Java temporary directory (java.io.tmpdir property) is taken.
For framework setups on Yarn, Flink will automatically pick up the
containers' temp directories without any need for configuration.
Add a delimited list for multiple directories, using the system directory
delimiter (colon ':' on unix) or a comma, e.g.:
/data1/tmp:/data2/tmp:/data3/tmp
Note: Each directory entry is read from and written to by a different I/O
thread. You can include the same directory multiple times in order to create
multiple I/O threads against that directory. This is for example relevant for
high-throughput RAIDs.
io.tmp.dirs: /tmp
The classloading resolve order. Possible values are 'child-first' (Flink's default)
and 'parent-first' (Java's default).
Child first classloading allows users to use different dependency/library
versions in their application than those in the classpath. Switching back
to 'parent-first' may help with debugging dependency issues.
classloader.resolve-order: child-first
The amount of memory going to the network stack. These numbers usually need
no tuning. Adjusting them may be necessary in case of an "Insufficient number
of network buffers" error. The default min is 64MB, the default max is 1GB.
taskmanager.memory.network.fraction: 0.1
taskmanager.memory.network.min: 64mb
taskmanager.memory.network.max: 1gb
#==============================================================================
Flink Cluster Security Configuration
#==============================================================================
Kerberos authentication for various components - Hadoop, ZooKeeper, and connectors -
may be enabled in four steps:
1. configure the local krb5.conf file
2. provide Kerberos credentials (either a keytab or a ticket cache w/ kinit)
3. make the credentials available to various JAAS login contexts
4. configure the connector to use JAAS/SASL
The below configure how Kerberos credentials are provided. A keytab will be used instead of
a ticket cache if the keytab path and principal are set.
security.kerberos.login.use-ticket-cache: true
security.kerberos.login.keytab: /path/to/kerberos/keytab
security.kerberos.login.principal: flink-user
The configuration below defines which JAAS login contexts
security.kerberos.login.contexts: Client,KafkaClient
#==============================================================================
ZK Security Configuration
#==============================================================================
Below configurations are applicable if ZK ensemble is configured for security
Override below configuration to provide custom ZK service name if configured
zookeeper.sasl.service-name: zookeeper
The configuration below must match one of the values set in "security.kerberos.login.contexts"
zookeeper.sasl.login-context-name: Client
#==============================================================================
HistoryServer
#==============================================================================
The HistoryServer is started and stopped via bin/historyserver.sh (start|stop)
Directory to upload completed jobs to. Add this directory to the list of
monitored directories of the HistoryServer as well (see below).
#jobmanager.archive.fs.dir: hdfs:///completed-jobs/
The address under which the web-based HistoryServer listens.
#historyserver.web.address: 0.0.0.0
The port under which the web-based HistoryServer listens.
#historyserver.web.port: 8082
Comma separated list of directories to monitor for completed jobs.
#historyserver.archive.fs.dir: hdfs:///completed-jobs/
Interval in milliseconds for refreshing the monitored directories.
#historyserver.archive.fs.refresh-interval: 10000
jobmanager debug端口
env.java.opts.jobmanager: "-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5006"
taskmanager debug端口
env.java.opts.taskmanager: "-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5005"
2.1.2.3 flink单节点启动与停止命令
/home/flink/bin/stop-cluster.sh && /home/flink/bin/start-cluster.sh
2.1.3、部署doris
2.1.3.1 下载安装包并上传服务器
官方参考文档地址
快速开始 - Apache Doris
下载地址 Download - Apache Doris
将安装包上传到/home下,解压并重命名为doris
配置
vi /etc/security/limits.conf
- soft nofile 65536
- hard nofile 65536
2.1.3.2 配置doris fe(前端)
配置文件/home/doris/fe/conf/fe.conf
Licensed to the Apache Software Foundation (ASF) under one
or more contributor license agreements. See the NOTICE file
distributed with this work for additional information
regarding copyright ownership. The ASF licenses this file
to you under the Apache License, Version 2.0 (the
"License"); you may not use this file except in compliance
with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing,
software distributed under the License is distributed on an
"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
KIND, either express or implied. See the License for the
specific language governing permissions and limitations
under the License.
#####################################################################
The uppercase properties are read and exported by bin/start_fe.sh.
To see all Frontend configurations,
see fe/src/org/apache/doris/common/Config.java
#####################################################################
the output dir of stderr and stdout
LOG_DIR = ${DORIS_HOME}/log
DATE =
date +%Y%m%d-%H%M%S
JAVA_OPTS="-Xmx8192m -XX:+UseMembar -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=7 -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSClassUnloadingEnabled -XX:-CMSParallelRemarkEnabled -XX:CMSInitiatingOccupancyFraction=80 -XX:SoftRefLRUPolicyMSPerMB=0 -Xloggc:$DORIS_HOME/log/fe.gc.log.$DATE"For jdk 9+, this JAVA_OPTS will be used as default JVM options
JAVA_OPTS_FOR_JDK_9="-Xmx8192m -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=7 -XX:+CMSClassUnloadingEnabled -XX:-CMSParallelRemarkEnabled -XX:CMSInitiatingOccupancyFraction=80 -XX:SoftRefLRUPolicyMSPerMB=0 -Xlog:gc*:$DORIS_HOME/log/fe.gc.log.$DATE:time"
the lowercase properties are read by main program.
INFO, WARN, ERROR, FATAL
sys_log_level = INFO
store metadata, must be created before start FE.
Default value is ${DORIS_HOME}/doris-meta
meta_dir = ${DORIS_HOME}/doris-meta
Default dirs to put jdbc drivers,default value is ${DORIS_HOME}/jdbc_drivers
jdbc_drivers_dir = ${DORIS_HOME}/jdbc_drivers
http_port = 8030
rpc_port = 9020
query_port = 9030
edit_log_port = 9010
mysql_service_nio_enabled = trueChoose one if there are more than one ip except loopback address.
Note that there should at most one ip match this list.
If no ip match this rule, will choose one randomly.
use CIDR format, e.g. 10.10.10.0/24
Default value is empty.
priority_networks = 10.10.10.0/24
Advanced configurations
log_roll_size_mb = 1024
sys_log_dir = ${DORIS_HOME}/log
sys_log_roll_num = 10
sys_log_verbose_modules = org.apache.doris
audit_log_dir = ${DORIS_HOME}/log
audit_log_modules = slow_query, query
audit_log_roll_num = 10
meta_delay_toleration_second = 10
qe_max_connection = 1024
max_conn_per_user = 100
qe_query_timeout_second = 300
qe_slow_log_ms = 5000
2.1.3.3 启动doris fe(前端)
/home/doris/fe/bin/start_fe.sh --daemon
2.1.3.4 配置doris be(后端)
配置文件路径/home/doris/be/conf/be.conf
Licensed to the Apache Software Foundation (ASF) under one
or more contributor license agreements. See the NOTICE file
distributed with this work for additional information
regarding copyright ownership. The ASF licenses this file
to you under the Apache License, Version 2.0 (the
"License"); you may not use this file except in compliance
with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing,
software distributed under the License is distributed on an
"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
KIND, either express or implied. See the License for the
specific language governing permissions and limitations
under the License.
PPROF_TMPDIR="$DORIS_HOME/log/"
if JAVA_OPTS is set, it will override the jvm opts for BE jvm.
#JAVA_OPTS="-Xmx8192m -DlogPath=$DORIS_HOME/log/udf-jdbc.log -Djava.compiler=NONE -XX::-CriticalJNINatives"
since 1.2, the JAVA_HOME need to be set to run BE process.
JAVA_HOME=/path/to/jdk/
INFO, WARNING, ERROR, FATAL
sys_log_level = INFO
ports for admin, web, heartbeat service
be_port = 9060
webserver_port = 8040
heartbeat_service_port = 9050
brpc_port = 8060Choose one if there are more than one ip except loopback address.
Note that there should at most one ip match this list.
If no ip match this rule, will choose one randomly.
use CIDR format, e.g. 10.10.10.0/24
Default value is empty.
priority_networks = 10.10.10.0/24
data root path, separate by ';'
you can specify the storage medium of each root path, HDD or SSD
you can add capacity limit at the end of each root path, separate by ','
eg:
storage_root_path = /home/disk1/doris.HDD,50;/home/disk2/doris.SSD,1;/home/disk2/doris
/home/disk1/doris.HDD, capacity limit is 50GB, HDD;
/home/disk2/doris.SSD, capacity limit is 1GB, SSD;
/home/disk2/doris, capacity limit is disk capacity, HDD(default)
you also can specify the properties by setting '<property>:<value>', separate by ','
property 'medium' has a higher priority than the extension of path
Default value is ${DORIS_HOME}/storage, you should create it by hand.
storage_root_path = ${DORIS_HOME}/storage
Default dirs to put jdbc drivers,default value is ${DORIS_HOME}/jdbc_drivers
jdbc_drivers_dir = ${DORIS_HOME}/jdbc_drivers
Advanced configurations
sys_log_dir = ${DORIS_HOME}/log
sys_log_roll_mode = SIZE-MB-1024
sys_log_roll_num = 10
sys_log_verbose_modules = *
log_buffer_level = -1
palo_cgroups
2.1.3.5 doris启动 be(后端)
/home/doris/be/bin/start_be.sh --daemon
2.1.3.5 doris启动成功验证
curl http://10.10.10.99:8030/api/bootstrap
curl http://10.10.10.99:8040/api/health
执行这两条命令,会输出success信息
2.1.3.6 doris的be在fe上注册
roris兼容mysql协议
因此使用mysql-client执行命令
mysql -h 10.10.10.99 -P 9030 -uroot
ALTER SYSTEM ADD BACKEND "10.10.10.99:9050";最后在重启下be和fe
2.1.3.6 通过doris的fe的Web UI页面创建数据库表
浏览器访问地址
默认用户名是root,默认密码为空
创建测试数据库表
create database example_db;
CREATE TABLE IF NOT EXISTS example_db.demo
(
destroy_dateDATETIME NOT NULL COMMENT "destroy_date",
latitudeDECIMAL NOT NULL COMMENT "精度",
longitudeDECIMAL NOT NULL COMMENT "纬度",
cityVARCHAR(256) COMMENT "city"
)
DUPLICATE KEY(destroy_date,latitude,longitude)
DISTRIBUTED BY HASH(city) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);CREATE TABLE IF NOT EXISTS example_db.log
(
APPVARCHAR(256) COMMENT "应用",
VERSIONVARCHAR(256) COMMENT "VERSION",
APP_PROVARCHAR(256) COMMENT "APP_PRO",
APP_TYPEVARCHAR(256) COMMENT "APP_TYPE",
APP_IPVARCHAR(256) COMMENT "APP_IP",
MSGVARCHAR(256) COMMENT "MSG",
CONTEXTVARCHAR(256) COMMENT "CONTEXT",
TAGVARCHAR(256) COMMENT "TAG",
TIMEVARCHAR(256) COMMENT "TIME",
VENDORVARCHAR(256) COMMENT "VENDOR",
VIDEOVARCHAR(256) COMMENT "VIDEO",
RESULTVARCHAR(256) COMMENT "RESULT",
LEVELVARCHAR(256) COMMENT "LEVEL",
LOGVARCHAR(256) NOT NULL COMMENT "LOG",
NAMEVARCHAR(256) COMMENT "NAME",
MACVARCHAR(256) NOT NULL COMMENT "MAC",
NOTEVARCHAR(256) NOT NULL COMMENT "NOTE",
SERVERVARCHAR(256) NOT NULL COMMENT "SERVER",
UUIDVARCHAR(256) NOT NULL COMMENT "UUID",
CREATE_TIMEDATETIME NOT NULL COMMENT "CREATE_TIME"
)
DUPLICATE KEY(APP,VERSION,APP_PRO)
DISTRIBUTED BY HASH(UUID) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
2.1.4、部署spring-boot的syslog-kafka-es-avro
配置kafka地址
UDP 端口
直接启动
2.1.4.1、syslog-kafka-es-avro基于netty已UDP方式监听syslog
//表示服务器连接监听线程组,专门接受 accept 新的客户端client 连接 EventLoopGroup group = new NioEventLoopGroup(); try { //1、创建netty bootstrap 启动类 Bootstrap serverBootstrap = new Bootstrap(); //2、设置boostrap 的eventLoopGroup线程组 serverBootstrap = serverBootstrap.group(group); //3、设置NIO UDP连接通道 serverBootstrap = serverBootstrap.channel(NioDatagramChannel.class); //4、设置通道参数 SO_BROADCAST广播形式 serverBootstrap = serverBootstrap.option(ChannelOption.SO_BROADCAST, true); serverBootstrap = serverBootstrap.option(ChannelOption.SO_RCVBUF, 1024*1024*1000); //5、设置处理类 装配流水线 serverBootstrap = serverBootstrap.handler(syslogUdpHandler); //6、绑定server,通过调用sync()方法异步阻塞,直到绑定成功 ChannelFuture channelFuture = serverBootstrap.bind(port).sync(); log.info("started and listened on " + channelFuture.channel().localAddress()); //7、监听通道关闭事件,应用程序会一直等待,直到channel关闭 channelFuture.channel().closeFuture().sync(); } catch (Exception e) { log.error("初始化异常",e); } finally { log.warn("netty udp close!"); //8 关闭EventLoopGroup, group.shutdownGracefully(); }
2.1.4.2、syslog-kafka-es-avro已avro格式保存数据到kafka
if (event == null || event.size() == 0) { if (log.isDebugEnabled()) { log.debug("解析数据为空,不执行kafka数据推送 !"); } return; } if (switchKafkaConfiguration != null && switchKafkaConfiguration.isAvroTest()) { log.info("发送kafka前,先将数据转换成二进制,通过接口发送测试"); String filePath= "D:\\conf\\kafka\\demo.avro"; try { AvroProcess avroProcess = AvroProcess.builder(filePath); byte[] bytes = avroProcess.serialize(event); String url = "http://127.0.0.1:8080/bin/receive"; HttpBinaryUtil.remoteInvoke(bytes,url); } catch (IOException e) { throw new RuntimeException(e); } } else{ if (log.isDebugEnabled()) { log.debug("数据发送到kafka"); } sendProcess.innerHandle(event); }
2.1.5、部署spring-boot的flink-do-doris
压缩成flink-do-doris-jar-with-dependencies.jar
通过10.10.10.99:8081 web ui页面提交jar文件
2.1.5.1、flink-do-doris主类
import cn.hutool.core.lang.UUID; import cn.hutool.json.JSONUtil; import org.apache.commons.collections.MapUtils; import org.apache.commons.lang3.StringUtils; import org.apache.doris.flink.cfg.DorisExecutionOptions; import org.apache.doris.flink.cfg.DorisOptions; import org.apache.doris.flink.cfg.DorisReadOptions; import org.apache.doris.flink.sink.DorisSink; import org.apache.doris.flink.sink.writer.RowDataSerializer; import org.apache.flink.api.common.RuntimeExecutionMode; import org.apache.flink.api.common.eventtime.WatermarkStrategy; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.connector.kafka.source.KafkaSource; import org.apache.flink.streaming.api.CheckpointingMode; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.CheckpointConfig; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.ProcessFunction; import org.apache.flink.table.api.DataTypes; import org.apache.flink.table.data.GenericRowData; import org.apache.flink.table.data.RowData; import org.apache.flink.table.data.StringData; import org.apache.flink.table.data.TimestampData; import org.apache.flink.table.types.DataType; import org.apache.flink.util.Collector; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import java.time.LocalDate; import java.util.Map; import java.util.Properties; /** * @author demo */ public class FlinkToDorisApp { private static final Logger log = LoggerFactory.getLogger(FlinkToDorisApp.class); private static final String KAFKA_BOOTSTRAP_SERVERS = "10.10.10.99:9092"; private static final String TOPIC = "demo"; private static final String GROUP_ID = "syslog-process-kafka-flink-doris"; private static final String KAFKA_DATASOURCE_NAME = "kafkaSource"; private static final String DORIS_FE_HOST = "10.10.10.99:8030"; //private static final String DORIS_DB_NAME = "example_db.demo"; private static final String DORIS_DB_NAME = "example_db.log"; /** * doris安装后默认的用户名是root */ private static final String DORIS_USERNAME = "root"; /** * doris安装后默认的是密码是空值 */ private static final String DORIS_PASSWORD = ""; private static final String schema = ""; private static final String[] fields = {}; public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.enableCheckpointing(10000); env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC); env.setParallelism(1); CheckpointConfig checkpointConfig = env.getCheckpointConfig(); checkpointConfig.setCheckpointingMode(CheckpointingMode.AT_LEAST_ONCE); checkpointConfig.setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION); KafkaSource<String> kafkaSource = KafkaUtils.getKafkaSource(KAFKA_BOOTSTRAP_SERVERS, TOPIC, GROUP_ID, schema); DataStreamSource<String> kafkaDS = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), KAFKA_DATASOURCE_NAME); SingleOutputStreamOperator<RowData> jsonDS = kafkaDS.process(new ProcessFunction<String, RowData>() { @Override public void processElement(String json, Context context, Collector<RowData> collector) { try { if (StringUtils.isNotBlank(json)) { Map event = JSONUtil.toBean(json, Map.class); GenericRowData eventData = mapping(event); if (eventData != null) { collector.collect(eventData); } } } catch (Exception e) { throw new RuntimeException(e); } } }); DataStream<RowData> dataStream = jsonDS.forward(); dataStream.print(); DorisSink.Builder<RowData> builder = DorisSink.builder(); DorisOptions.Builder dorisBuilder = DorisOptions.builder(); dorisBuilder.setFenodes(DORIS_FE_HOST) .setTableIdentifier(DORIS_DB_NAME) .setUsername(DORIS_USERNAME) .setPassword(DORIS_PASSWORD); Properties properties = new Properties(); properties.setProperty("format", "json"); properties.setProperty("read_json_by_line", "true"); DorisExecutionOptions.Builder executionBuilder = DorisExecutionOptions.builder(); executionBuilder.setLabelPrefix("label-doris" + UUID.fastUUID()).setStreamLoadProp(properties); DataType[] types = {DataTypes.VARCHAR(256),DataTypes.VARCHAR(256),DataTypes.VARCHAR(256),DataTypes.VARCHAR(256), DataTypes.VARCHAR(256),DataTypes.VARCHAR(256),DataTypes.VARCHAR(256),DataTypes.VARCHAR(256), DataTypes.VARCHAR(256),DataTypes.VARCHAR(256),DataTypes.VARCHAR(256),DataTypes.VARCHAR(256), DataTypes.VARCHAR(256),DataTypes.VARCHAR(256),DataTypes.VARCHAR(256),DataTypes.VARCHAR(256), DataTypes.VARCHAR(256),DataTypes.VARCHAR(256),DataTypes.VARCHAR(256),DataTypes.VARCHAR(256), DataTypes.VARCHAR(256),DataTypes.VARCHAR(256),DataTypes.VARCHAR(256),DataTypes.VARCHAR(256), DataTypes.TIMESTAMP()}; builder.setDorisReadOptions(DorisReadOptions.builder().build()) .setDorisExecutionOptions(executionBuilder.build()) .setSerializer(RowDataSerializer.builder() .setFieldNames(fields) .setType("json") .setFieldType(types).build()) .setDorisOptions(dorisBuilder.build()); boolean test = false; if (test) { DataStream<RowData> source = env.fromElements("") .map((MapFunction<String, RowData>) value -> { GenericRowData genericRowData = new GenericRowData(4); genericRowData.setField(0, StringData.fromString("beijing")); genericRowData.setField(1, 116.405419); genericRowData.setField(2, 39.916927); genericRowData.setField(3, new Long(LocalDate.now().toEpochDay()).intValue()); return genericRowData; }); source.sinkTo(builder.build()); } dataStream.sinkTo(builder.build()); log.info("doris安装后默认的用户名是root,doris安装后默认的密码是空值"); env.execute(); } private static final int TWO_PER_SECOND = 2; private static GenericRowData mapping(Map event) { GenericRowData genericRowData = new GenericRowData(fields.length); for (int i = 0; i < fields.length - TWO_PER_SECOND; i++) { genericRowData.setField(i, StringData.fromString(MapUtils.getString(event, fields[i], ""))); } genericRowData.setField(23, StringData.fromString(UUID.randomUUID().toString())); genericRowData.setField(24, TimestampData.fromEpochMillis(System.currentTimeMillis())); return genericRowData; } }
三、效果验证
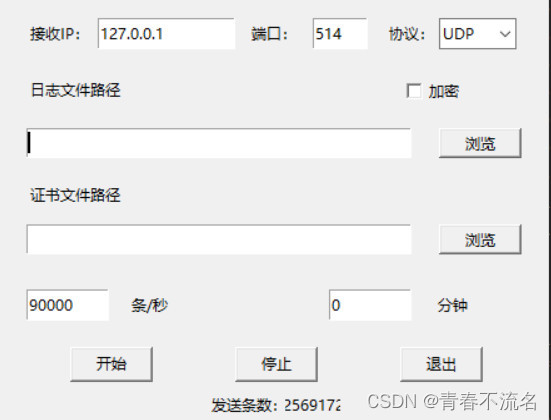
3.1、发送syslog日志,syslog-kafka-es-avro监听处理,存储到kafka
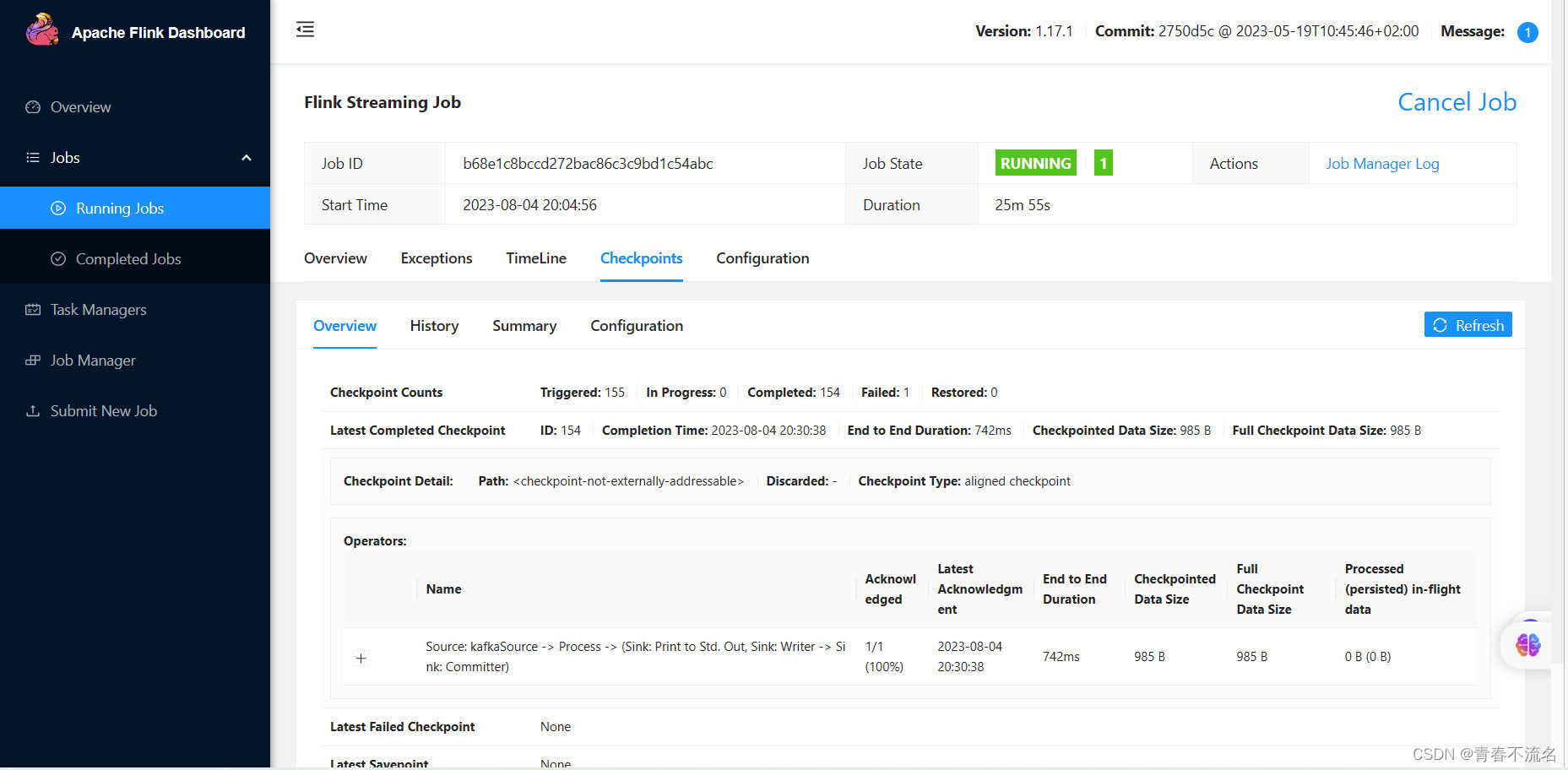
3.2 、查看flink消费kafka

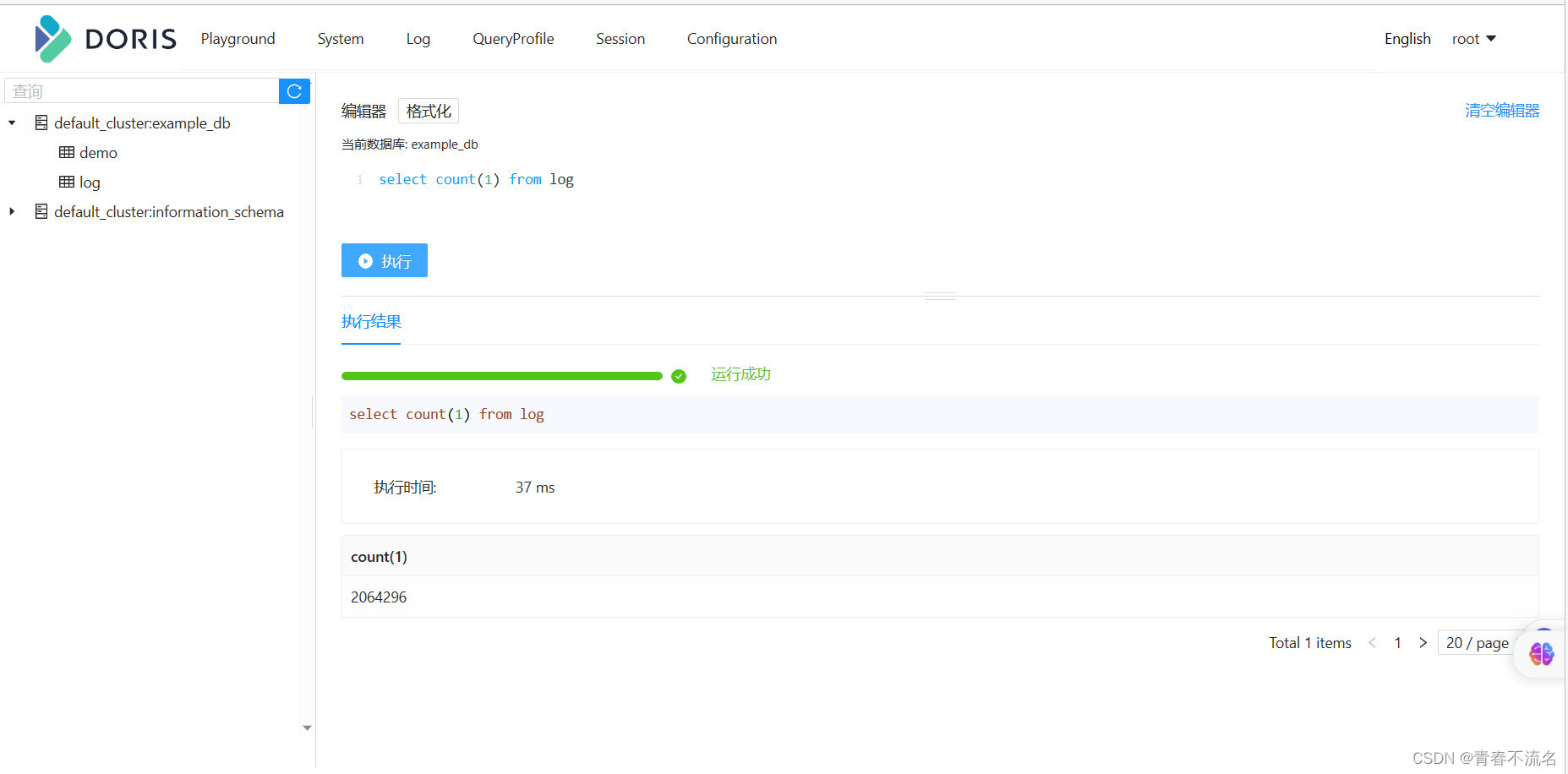
3.3、 在doris上查看入库详情
版权归原作者 青春不流名 所有, 如有侵权,请联系我们删除。