
一、准备工作
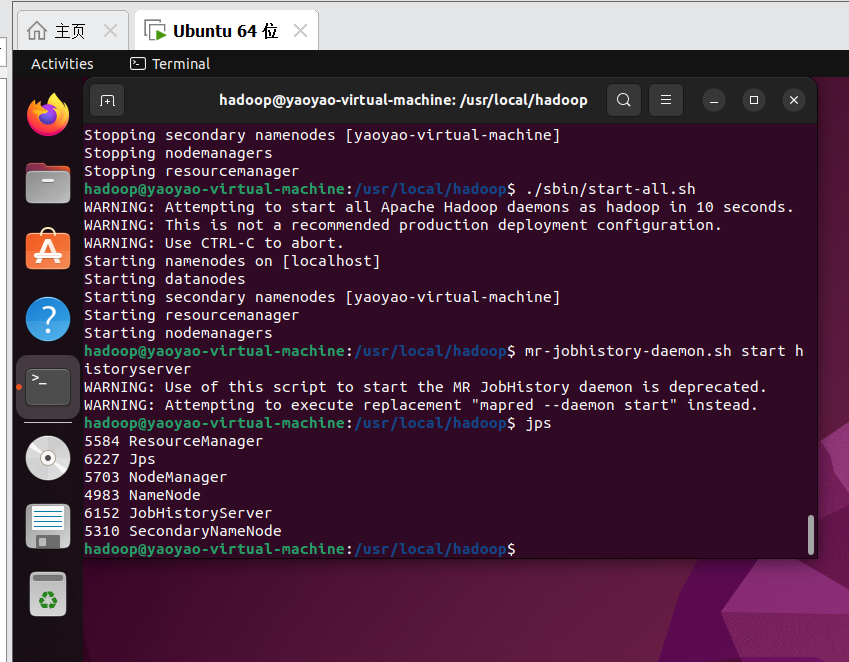
1.1启动Hadoop服务
参见Hadoop在ubuntu虚拟机上的伪分布式部署|保姆级教程的4.7节
二、HDFS常用命令
接着,就愉快地在刚刚的命令行里敲命令啦
1.显示hdfs目录结构
hadoop fs -ls-R /
hadoop fs: 这是Hadoop文件系统命令行的一部分,用于与HDFS进行交互。-ls: 类似于UNIX/Linux中的 ls 命令,用于列出目录内容。-R: 这个参数使得 ls 命令递归地列出所有目录和子目录的内容。没有这个参数,ls 命令只会列出指定目录的直接内容。/: 指定要列出内容的目录路径。在这个命令中,它是根目录。
🌸Tips:这里的Hadoop的目录结构,是指hdfs文件系统的目录结构,而非hadoop这个软件所在的目录结构
根据运行结果我们可以得到以下信息:
1. 目录和权限:
/tmp: 这是一个临时目录,权限设置为drwxrwx---,表明目录的拥有者(hadoop)和其所在的组(supergroup)具有读、写、执行权限,而其他用户没有任何权限。/tmp/hadoop-yarn: 这是存放与Hadoop YARN(资源管理器)相关的临时数据的目录,权限同上。/tmp/hadoop-yarn/staging: 用于存放YARN作业的准备阶段数据的目录,权限同上。/tmp/hadoop-yarn/staging/history: 存放YARN作业历史信息的目录,权限同上。/tmp/hadoop-yarn/staging/history/done:存放已完成的YARN作业历史信息的目录,权限同上。/tmp/hadoop-yarn/staging/history/done_intermediate: 存放正在处理中的YARN作业历史信息的目录,权限设置为 drwxrwxrwt。这里的 t 权限(粘滞位)表明只有文件的拥有者、目录的拥有者或超级用户才能删除或重命名目录中的文件。
2. 所有者和组:
- 所有列出的目录均由用户 hadoop 拥有,并且属于 supergroup 组。
- 在Hadoop生态系统中,supergroup 是一个默认的用户组,通常与HDFS的超级用户(即 Hadoop 的管理员账户,类似于 Unix 系统中的 root 用户)关联。超级用户和属于 supergroup 组的用户通常有着对HDFS上所有文件和目录的全权限,这包括读取、写入和执行权限。3. 大小:
- 所有目录的大小均为 0,这是因为在大多数文件系统中,目录不占用可见的存储空间,或者说目录的大小表示的是目录结构本身的大小,而不是其中包含的文件大小。
2.在hdfs指定目录内创建新目录
hadoop fs -mkdir /yaoyao

3.删除hdfs上指定文件夹(包含子目录等)
hadoop fs -rm-r /yaoyao

4.在hdfs上创建文件和编辑❌
其实我一开始就完全把HDFS当作像
windows
和
linux
那样的文件操作系统了,其实忽略了hdfs的本质:它是一个分布式文件存储系统,专为大文件的存储和处理设计,而非像windows和Linux那样常规的对本地文件进行操作(创建和编辑),因此一般不直接在hdfs上进行文件的创建和编辑。
它的设计理念是:一次写入,多次读取(保证数据的一致性):HDFS不支持文件的随机写入或修改。一旦文件在HDFS上创建和写入,我们不能修改文件的某一部分内容。我们只能追加数据或重写整个文件。
这里的“写入”就是将本地文件写入系统,而非用户自己在Hdfs上创建文件
5.文件写入:将本地数据写入hdfs⭐
文件写入的原理图如下,但是我们写shell命令时,这些原理是由hdfs底层实现的了,我们只需要敲命令就好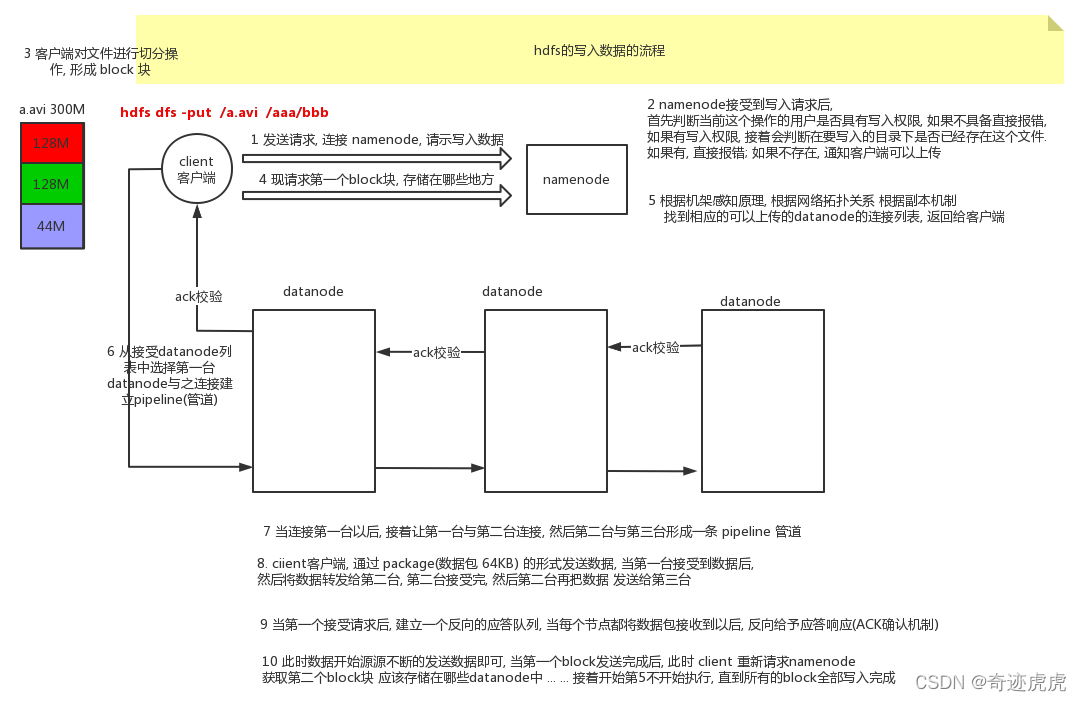
5.1:本地文件准备
我们现在本地系统上创建一个文件,待会把它写入hdfs系统中:
- 先在用户目录下创建一个
hadoop_file的文件夹,待会用来存储要写入到hdfs中的文件
- 在终端打开这个文件夹,创建文件
hello.txt``````touch hello.txt
- 使用vim编辑器:
vim hello.txt> 启动后按>> i>> 进入插入模式,可以开始输入文本。完成后,按>> Esc>> 退出插入模式,输入>> :wq>> 保存并退出vim。>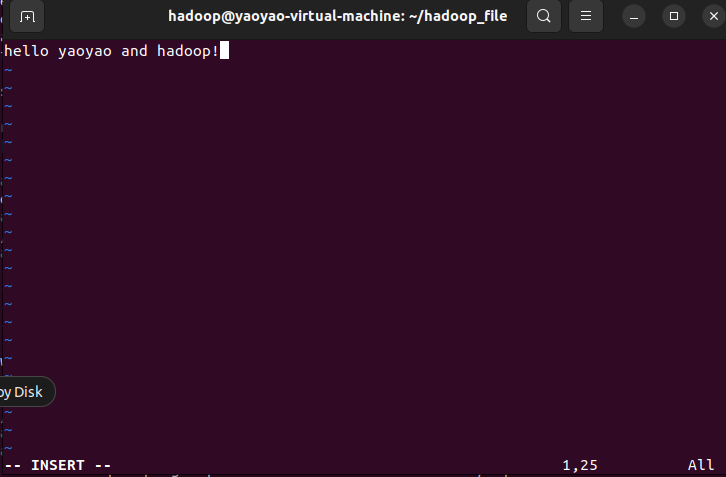
5.2:将本地文件上传到hdfs
有两种命令实现:
-copyFromLocal
hadoop fs -copyFromLocal[本地地址][hadoop目录]
-put
hadoop fs -put[本地地址][hadoop目录]
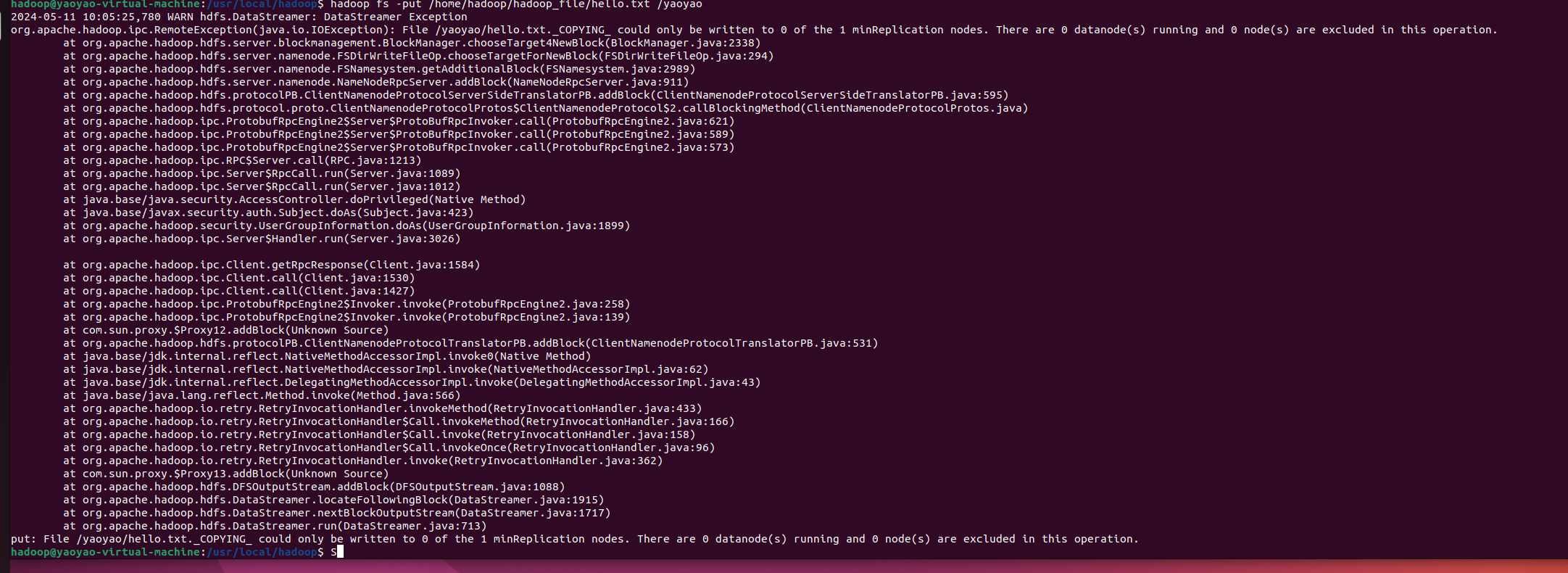
这里对于本地地址一定要清楚
linux
的目录结构: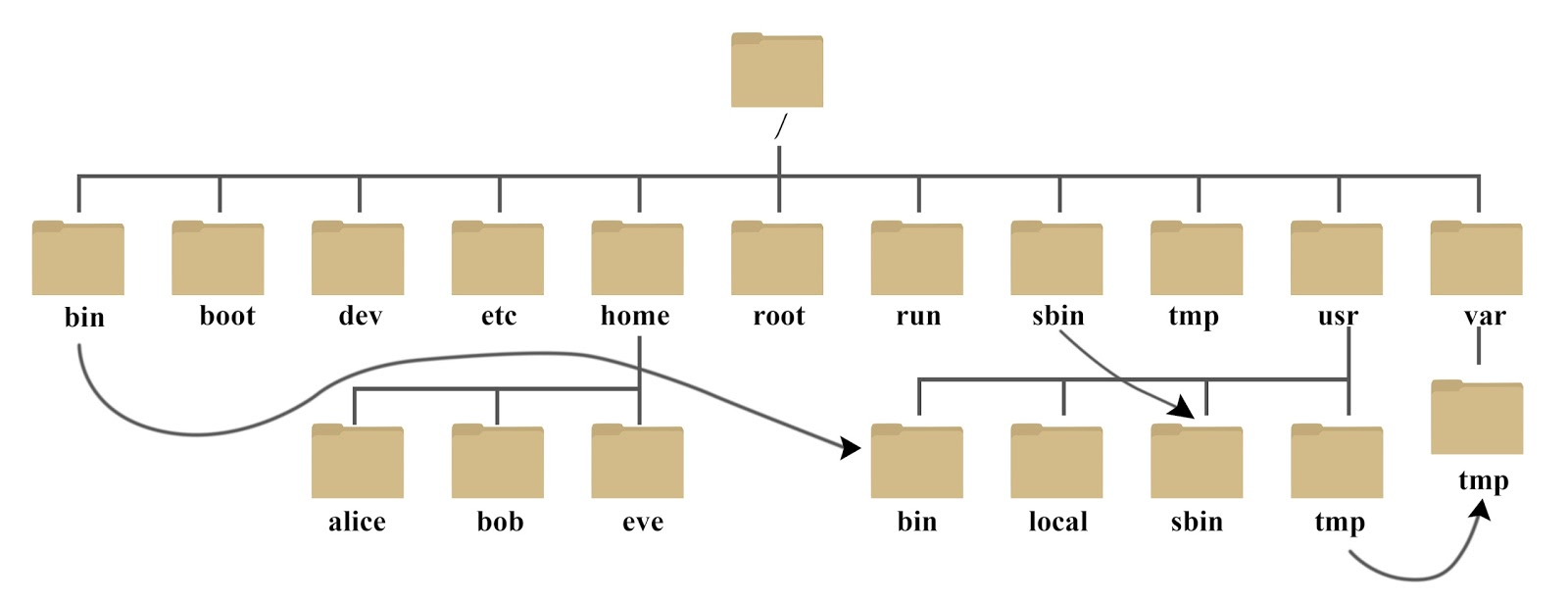
home:
用户的主目录,在 Linux 中,每个用户都有一个自己的目录,一般该目录名是以用户的账号命名的,如上图中的 alice、bob 和 eve。
我在当前用户(用户名为
hadoop
的
home
目录下创建了
hadoop_file
文件夹,那么我们文件的路径应该为:
/home/hadoop/hadoop_file/hello.txt
6.查看指定目录下内容
hadoop fs -ls[hdfs的文件目录]

7.打开查看某个已存在文件
hadoop fs -cat[file_path]

8.在hdfs指定目录下新建一个空文件
hadoop fs -touchz[hdfs的文件路径+文件名]

9.将hdfs上某个文件重命名
hadoop fs -mv /yaoyao/test.txt /yaoyao/test02.txt

10.将hdfs上的文件down到本地⭐
-get``````hadoop fs -get[hdfs目录][本地目录]
-copyToLocal``````hadoop fs -copyToLocal[hdfs目录][本地目录]
11.其他常用命令
-count:显示hdfs目录下的子目录数、文件数、占用字节数、所有文件和目录名,-q 选项显示目录和空间的配额信息。实例代码如下所示:hadoop fs -count /yaoyao命令输出格式为:DIR_COUNT FILE_COUNT CONTENT_SIZE PATH_NAME DIR_COUNT - 2:/yaoyao路径下有2个子目录。 FILE_COUNT - 3:/yaoyao路径下有3个文件。 CONTENT_SIZE - 50:这3个文件的总字节数为50字节。 PATH_NAME - /yaoyao:这是你指定的HDFS路径。
DIR_COUNT - 2:/yaoyao路径下有2个子目录。 FILE_COUNT - 3:/yaoyao路径下有3个文件。 CONTENT_SIZE - 50:这3个文件的总字节数为50字节。 PATH_NAME - /yaoyao:这是你指定的HDFS路径。-df:查看 HDFS 中目录空间的使用情况,使用-df选项查看Hadoop文件系统(HDFS)的磁盘空间使用情况,而-h选项让输出以易读的格式(例如GB、KB)显示。实例代码如下所示:hadoop fs -df-h /yaoyao Filesystem:显示文件系统的名称。这里是 hdfs://localhost:9000,表示这是运行在本地主机上,默认端口为9000的HDFS实例。 Size:显示文件系统的总大小。这里是 38.6 G,表示HDFS的总空间为38.6吉字节(GB)。 Used:显示已经使用的空间大小。这里是 52 K,表示已经有52千字节(KB)的空间被使用。 Available:显示还可用的空间大小。这里是 22.4 G,表示还有22.4吉字节(GB)的空间可用。 Use%:显示已使用的空间百分比。这里是 0%,由于展示的精度问题,实际已使用空间非零(52 KB),但相对于总空间来说非常小,所以使用百分比显示为0%。
Filesystem:显示文件系统的名称。这里是 hdfs://localhost:9000,表示这是运行在本地主机上,默认端口为9000的HDFS实例。 Size:显示文件系统的总大小。这里是 38.6 G,表示HDFS的总空间为38.6吉字节(GB)。 Used:显示已经使用的空间大小。这里是 52 K,表示已经有52千字节(KB)的空间被使用。 Available:显示还可用的空间大小。这里是 22.4 G,表示还有22.4吉字节(GB)的空间可用。 Use%:显示已使用的空间百分比。这里是 0%,由于展示的精度问题,实际已使用空间非零(52 KB),但相对于总空间来说非常小,所以使用百分比显示为0%。-tail:显示一个文件的末尾数据,通常是显示文件最后的 1KB 的数据。-f 选项可以监听文件的变化,当有内容追加到文件中时,-f 选项能够实时显示追加的内容。实例代码如下所示:hadoop fs -tail /yaoyao/hello.txt
本文转载自: https://blog.csdn.net/Yaoyao2024/article/details/138697279
版权归原作者 是瑶瑶子啦 所有, 如有侵权,请联系我们删除。
版权归原作者 是瑶瑶子啦 所有, 如有侵权,请联系我们删除。