
先说简单的使用
CREATE TABLE
cc_test_serde(
idstring COMMENT 'from deserializer',
namestring COMMENT 'from deserializer')ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat';hdfs dfs -put student.json /tmp/spark/job
load data inpath "/tmp/spark/job/student.json" overwrite into table cc_test_serde
select * from cc_test_serde
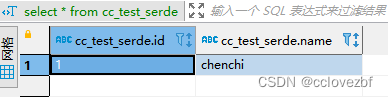
注意点。
1.cdh6.3.2 hive2 版本只用 ROW FORMAT SERDE 即可。
但是cdp需要 ROW FORMAT SERDE /STORED AS INPUTFORMAT/OUTPUTFORMAT
2.这个表的注释貌似是没有用的。
3.我采用的beeline连接不能使用local inpath 需要上传导hdfs
————————————————————————————————————————
csv同理如上。但是csv是要更复杂些的。
以csv数据来说 一般会有表头,而且csv会有quote,也会有escape
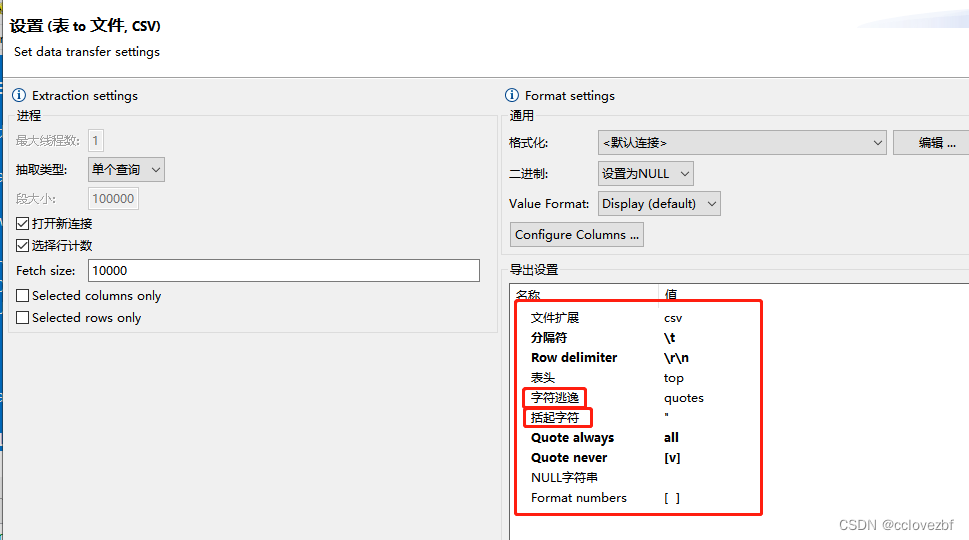
所以会稍微复杂些。稍后一一举例来说
CREATE TABLE
cc_test_csv(
idstring COMMENT 'from deserializer',
namestring COMMENT 'from deserializer')ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.OpenCSVSerde'
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
;hdfs dfs -put -f student.json /tmp/spark/job
load data inpath "/tmp/spark/job/student.json" overwrite into table cc_test_csv
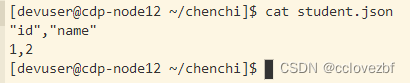
查询结果

差不多load进去了,但是又多了表头,所以我们要去掉表头。
lowb方法 insert overwrite table cc_test_csv select * from cc_test_csv where id!='id'
高级方式 tblproperties("skip.header.line.count"="1")
CREATE TABLE
cc_test_csv(
idstring COMMENT 'id',
namestring COMMENT 'name')ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.OpenCSVSerde'
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
tblproperties("skip.header.line.count"="1")或者
alter table cc_test_csv set tblproperties("skip.header.line.count"="1");

解决了表头问题。
——————————————————————————————————————————
csv问题2,有的csv文件有的数据是有""括起来的
[devuser@cdp-node12 ~/chenchi]$ cat student.json
"id","name"
"1","2"
3,4
5,
,6
"7",
"","8"
load之后好像还是可以的,说明openCSV这个类读的还是挺准的。

那么问题来了。
这里我希望 有的就是字符串"" 有的是null opencsv能不能读出来呢?
比如5, 第二个字段应该是空。 "","8"这里第一个字段是"" 。
在搞清楚这些之前我们需要了解csv的一些基本属性
public static final String SEPARATORCHAR = "separatorChar"; public static final String QUOTECHAR = "quoteChar"; public static final String ESCAPECHAR = "escapeChar"; public static final char DEFAULT_ESCAPE_CHARACTER = '"'; public static final char DEFAULT_SEPARATOR = ','; public static final char DEFAULT_QUOTE_CHARACTER = '"';
分别是 分隔符 括起符 逃逸字符。
这三个是什么意思?默认值又是什么?
括起符默认" 分割符默认是, 关键是这个逃逸字符也是"
括起符顾名思义,csv每一行由多列构成,每一列用""括起来 例如 "a","b"
分隔符就是"a","b"
重点来了 逃逸字符是什么?我也不知道 百度也百不出,但是总归有办法的。
hive 源码 TestOpenCSVSerde

其实逃逸字符本身的目的我认为就是有些字符串千奇百怪,但是我还要保留例如," ' 。
例如 一段字符串只有三列
a,b,c
a,b,c,,,,,d --这个的第三列字符串就是 c,,,,,d
"a","b","c"d"",第三列就是c"d"
如上所示有的字符串就是这样 你有什么办法呢?
两种办法
1.换种思路,csv不是说分割符一定就是,也可以是其他符号比如@,那么a@b@c,,,,,d ,这种对于csvreader来说不就是小菜一碟
有的人又说了@万一我字符串里也有呢?那么能不能@$@#当作分割符。
- 这个就是逃逸字符的用处了。就是逃逸字符的下一个字符逃跑了。举例来说
下载hive源码 org.apache.hadoop.hive.serde2.OpenCSVSerde
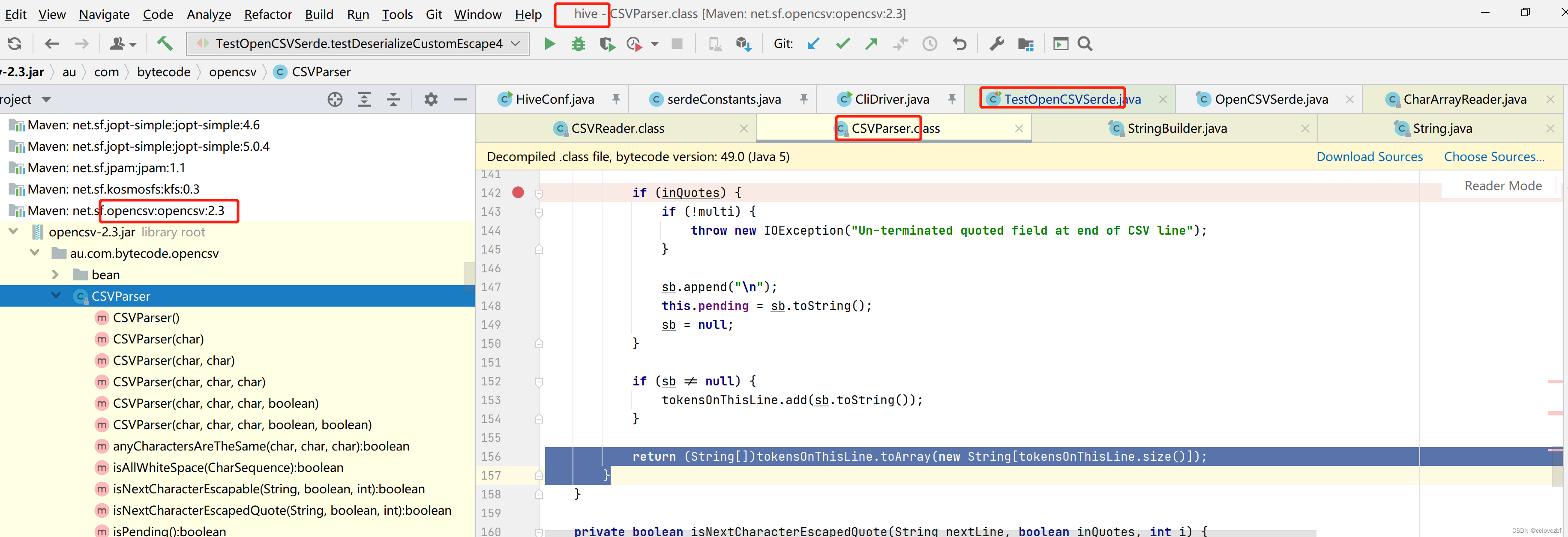
au.com.bytecode.opencsv.CSVParser
for(int i = 0; i < nextLine.length(); ++i) {
char c = nextLine.charAt(i); //把每列的字符串拆分为字符
if (c == this.escape) { //是否等于逃逸字符
if (this.isNextCharacterEscapable(nextLine, inQuotes || this.inField, i)) {
//isNextCharacterEscapable这方法是看 是否括起来了&&(下个字符是quote或者是escape)
//如果是就把下一个字符放到sb里去
sb.append(nextLine.charAt(i + 1));
++i;
} 这里没有else 说明啥也不干。
} else if (c != this.quotechar) { //如果不= quote
if (c == this.separator && !inQuotes) { // 如果=分割符并且没有被quote
tokensOnThisLine.add(sb.toString());
sb.setLength(0);
this.inField = false;
} else if (!this.strictQuotes || inQuotes) {
sb.append(c);
this.inField = true;
}
} else { //这个else 说明当前字符就是quote
if (this.isNextCharacterEscapedQuote(nextLine, inQuotes || this.inField, i)) {
//是否括起来 是否在区域内,下个字符=escape
sb.append(nextLine.charAt(i + 1));
++i;
} else {
//!this.strictQuotes=true,
//然后看当前字符的上一个字符是否=分隔符
//然后看当前字符的下一个字符是否=分隔符
if (!this.strictQuotes && i > 2 && nextLine.charAt(i - 1) != this.separator && nextLine.length() > i + 1 && nextLine.charAt(i + 1) != this.separator) {
//就是看字符是不是空白 空白就啥也不干
if (this.ignoreLeadingWhiteSpace && sb.length() > 0 && this.isAllWhiteSpace(sb)) {
sb.setLength(0);
} else {
sb.append(c);
}
}
//当前字符就是quote 处理完当前字符后 就要处理分割符了
inQuotes = !inQuotes;
}
//是否是在字段内? 这里和上面quote一般来说是一致的 什么情况不一致呢?
this.inField = !this.inField;
}
}
本来想总结下的。想了下有点麻烦。直接上案例
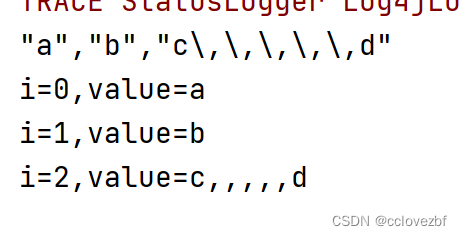
props.setProperty(OpenCSVSerde.QUOTECHAR, "\""); props.setProperty(OpenCSVSerde.SEPARATORCHAR, ","); props.setProperty(OpenCSVSerde.ESCAPECHAR, "\\"); csv.initialize(null, props); final Text in = new Text("\"a\",\"\",\"\\\"c\\\"c\""); final Text in2 = new Text("a,,\\\"c\\\"c"); final Text in3 = new Text("a,,a\\\"c\\\""); final Text in4 = new Text("\"a\",\"\",\"\\\"c\\\"\\,\\\"c\"");
"a","",""c"c"
i=0,value=a
i=1,value=
i=2,value="c"ca,,"c"c
i=0,value=a
i=1,value=
i=2,value=nulla,,a"c"
i=0,value=a
i=1,value=
i=2,value=a"c""a","",""c","c"
i=0,value=a
i=1,value=
i=2,value="c","c
逻辑有点麻烦 我也理的不是特别清楚。
1.能用quote就用quote
2.注意第二个案例如果没有quote。 逃逸字符后面跟着quote如果刚好出现在该字段最前面会出现问题
3.value="" 我也想变成null 但是不行。因为他最开始就是
StringBuilder sb = new StringBuilder(128);
然后 sb.toString=""
为什么第二个案例有个null呢?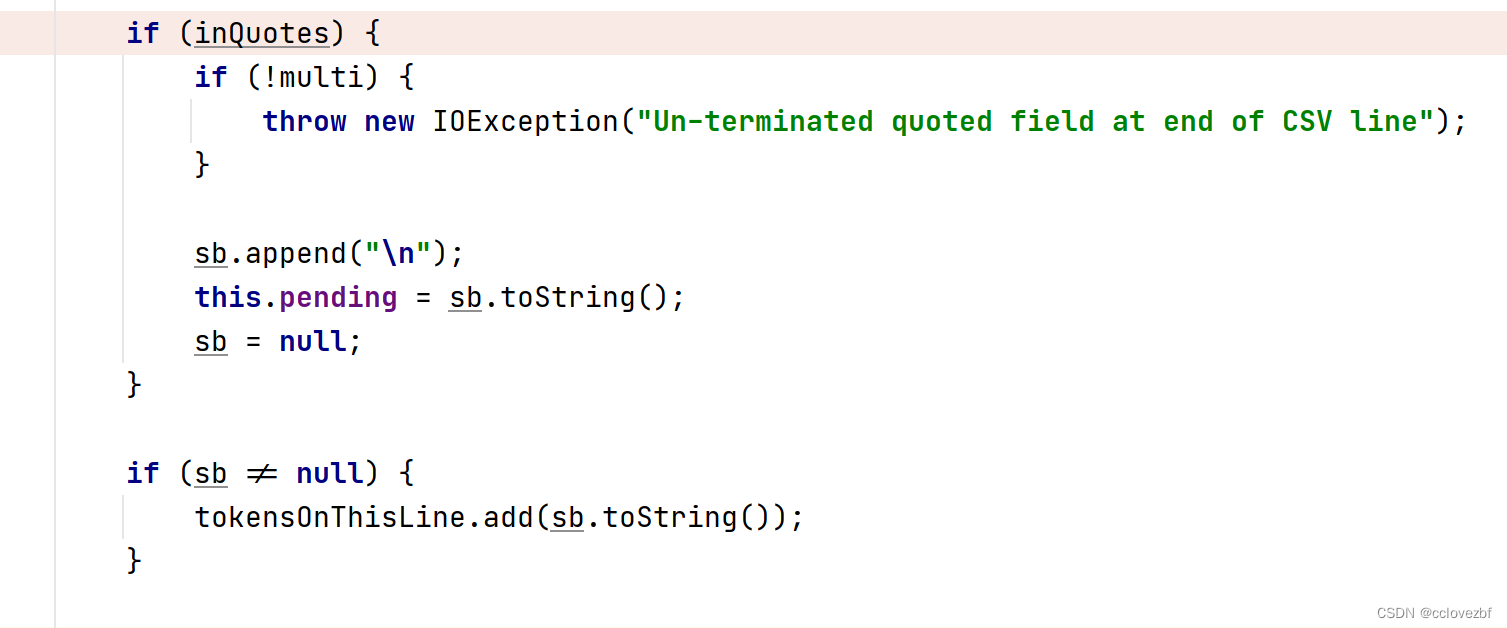
因为第二个案例只被csvreader读取了两段。第三段直接被赋值为null了。
为什么要研究这么多呢?
除了csv json 我们还有没有其他格式的呢? 比如更复杂的json 比如xml(当然这个不太可能)
比如正则,比如其他格式数据甚至说是加密数据
sadfsda1234,12314daafdfa,sqeqd31n12 实际上是 a,b,c
那这种数据我们怎么解析呢? 很简单。。。自定义一种serde......然后放到hive目录下就可以建表的时候自定义serde了。
虽然我没尝试。但是这种方式我觉得也很正常。。不说了又多了一种吹b的方式。
版权归原作者 cclovezbf 所有, 如有侵权,请联系我们删除。