
一 dolphinsheduler调研
支持的任务类型:
任务类型
简介
综述
Shell
Shell脚本
worker 执行该任务的时候,会生成一个临时 shell 脚本,并使用与租户同名的 linux 用户执行这个脚本。
SubProcess
子流程节点
把外部的某个工作流定义当做一个节点去执行。
DependentStored
依赖检查节点
比如 A 流程依赖昨天的 B 流程执行成功,依赖节点会去检查 B 流程在昨天是否有执行成功的实例。
Procedure
储存过程节点
执行储存过程,前提:在该数据库里面创建存储过程,如:
CREATE PROCEDURE dolphinscheduler.test(in in1 INT, out out1 INT)
begin
set out1=in1;
END
SQL
执行相应SQL
数据源为“数据源配置”里确定的,目前支持的数据源有MySQL、PostgreSQL、Hive/Impala、Spark、clickhouse、Oracle、SQLserver、DB2、presto、redshift、athena
Spark
spark应用
worker 支持两个不同类型的 spark 命令提交任务:
(1) spark submit 方式
(2) spark sql 方式
MapReduce
MapReduce程序
worker 会通过使用 Hadoop 命令 hadoop jar 的方式提交任务
Python
Python脚本
worker 执行该任务的时候,会生成一个临时python脚本,并使用与租户同名的 linux 用户执行这个脚本。
Flink
Flink任务
(1)当程序类型为 Java、Scala 或 Python 时,worker 使用 Flink 命令提交任务 flink run。
(2)当程序类型为 SQL 时,worker 使用sql-client.sh 提交任务。
HTTP
http任务
如常见的 POST、GET 等请求类型,此外还支持 http 请求校验等功能
DataX
DataX程序
于 DataX 节点,worker 会通过执行 ${DATAX_HOME}/bin/datax.py 来解析传入的 json 文件。
Pigeon
websocket服务
Conditions
条件节点
根据上游任务运行状态,判断应该运行哪个下游任务。截止目前 Conditions 支持多个上游任务,但只支持两个下游任务。当上游任务数超过一个时,可以通过且以及或操作符实现复杂上游依赖
Switch
判断节点
依据全局变量的值和用户所编写的表达式判断结果执行对应分支。使用 javax.script.ScriptEngine.eval 执行表达式。
SeaTunnel
SeaTunnel 任务类型
会通过 start-seatunnel-spark.sh 或 start-seatunnel-flink.sh 命令解析 config 文件
AmazonEMR
Amazon EMR 任务类型
用于在AWS上操作EMR集群并执行计算任务后台使用 aws-java-sdk 将JSON参数转换为任务对象,提交到AWS,目前支持两种程序类型:
(1)RUN_JOB_FLOW
(2)ADD_JOB_FLOW_STEPS
Apache Zeppelin
Zeppelin任务类型
worker 执行该任务的时候,会通过Zeppelin Cient API触发Zeppelin Notebook Paragraph
Jupyter
Jupyter任务
需要在common.properties配置conda.path,用于创建并执行Jupyter类型任务。worker 执行该任务的时候,会通过papermill执行jupyter note
Hive CLI
hivesql任务
执行任务的worker会通过hive -e命令执行hive SQL脚本语句或者通过hive -f命令执行资源中心中的hive SQL文件
(1)Hive CLI任务插件直接连接HDFS和Hive Metastore来执行hive类型的任务,所以需要能够访问到对应的服务。在生产调度中,Hive CLI任务插件能够提供更可靠的稳定性。
(2)使用Hive数据源的SQL插件不需要在worker节点上有相应的Hive jar包以及Hive和HDFS的配置文件,而且支持 Kerberos认证。但是在生产调度中,若调度压力很大,使用这种方式可能会遇到HiveServer2服务过载失败等问题。
Kubernetes
kubernetes任务
用于在kubernetes上执行一个短时和批处理的任务。worker最终会通过使用kubernetes client提交任务。
MLflow
用于管理机器学习的生命周期,包括实验、可再现性、部署和中心模型注册。
Openmldb
openmldb是开源机器学习数据库,可以连接OpenMLDB集群执行任务
DVC
机器学习版本管理系统
Dinky
Dinky任务
用于创建并执行Dinky类型任务以支撑一站式的开发、调试、运维 FlinkSQL、Flink Jar、SQL。worker 执行该任务的时候,会通过Dinky API触发Dinky 的作业
SageMaker
云机器学习平台
ChunJun
chunjun任务
数据同步任务
Pytorch
机器学习库
官方文档(https://dolphinscheduler.apache.org/zh-cn/docs/3.1.3/%E5%8A%9F%E8%83%BD%E4%BB%8B%E7%BB%8D_menu)
1.1 dolphinsheduler集群部署
1.1.1 需要的环境
(1)三台节点均需部署
JDK
(1.8+),并配置相关环境变量。
(2)需部署数据库,支持
MySQL
(5.7+)或者
PostgreSQL
(8.2.15+)。
(3)需部署
Zookeeper
(3.4.6+)。
(4)三台节点均需安装进程管理工具包
psmisc
。
yum install psmisc
(5)保证三台节点可以互相免密ssh
(6)需要在MySQL或
PostgreSQL上
创建元数据库

(7)生产环境
CPU
内存
硬盘类型
网络
实例数量
4核+
8 GB+
SAS
千兆网卡
1+
以上建议配置为部署 DolphinScheduler 的最低配置,生产环境强烈推荐使用更高的配置,硬盘大小配置建议 50GB+ ,系统盘和数据盘分开
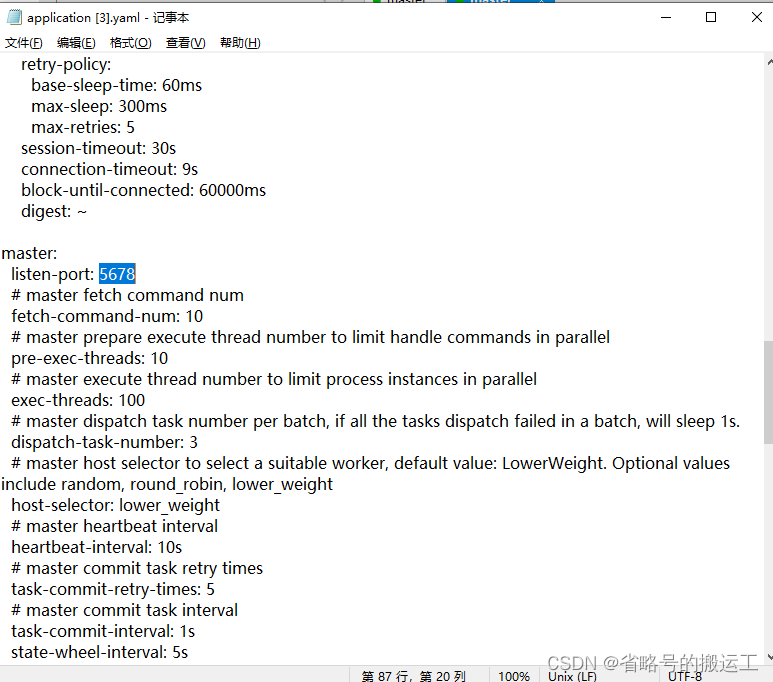
(8)DolphinScheduler正常运行提供如下的网络端口配置:
组件
默认端口
说明
MasterServer
5678
非通信端口,只需本机端口不冲突即可
WorkerServer
1234
非通信端口,只需本机端口不冲突即可
ApiApplicationServer
12345
提供后端通信端口
默认端口可以在安装后的application.yaml修改
1.1.2 dolphinsheduler安装
(1)官网下载安装包(https://github.com/apache/dolphinscheduler/archive/refs/tags/3.1.3.tar.gz)
或打包源码:
./mvnw clean install -Prelease -"Dmaven.test.skip=true"
默认zk3.8版本,若想支持zk3.4打包阶段需加-Dzk-3.4
./mvnw clean install -Prelease -"Dmaven.test.skip=true" -"Dzk-3.4"
注意windows下打包源码在安装时会提示类似无“/t”的报错(忘了截图了),这是因为.sh脚本文件在windows打包时为dos格式,可以下载命令yum –y dos2unix,使用dos2unix将脚本格式转为unix。
(2)上传至服务器后tar –zxvf解压

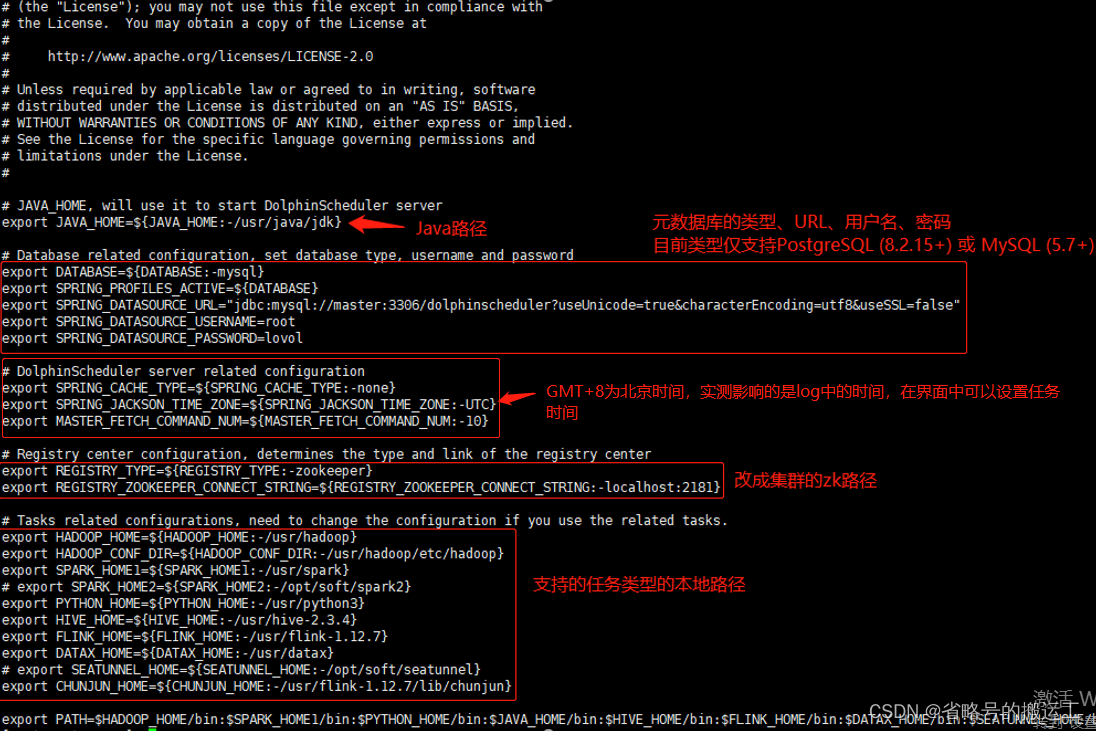
(3)修改dolpinscheduler/bin/env目录下install_env.sh和dolphinscheduler_env.sh
因为部署脚本会通过
scp
的方式将安装需要的资源传输到各个机器上,所以这一步仅需要修改运行
install.sh
脚本的所在机器的配置即可。

(4)初始化数据库
将与数据库版本匹配的mysql-connector的jar包复制到tools/libs下
运行
sh tools/bin/upgrade-schema.sh

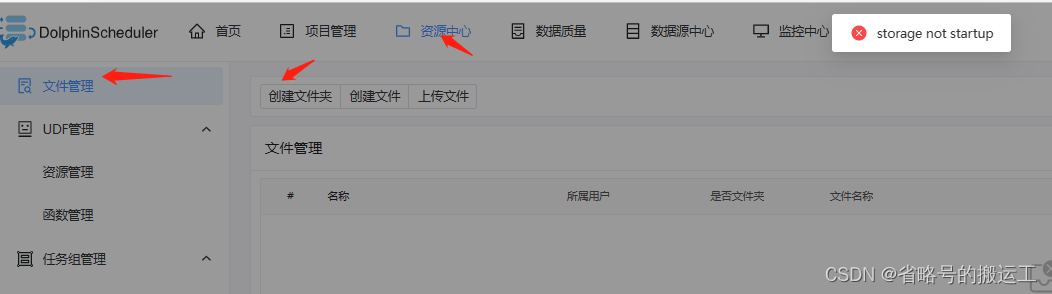
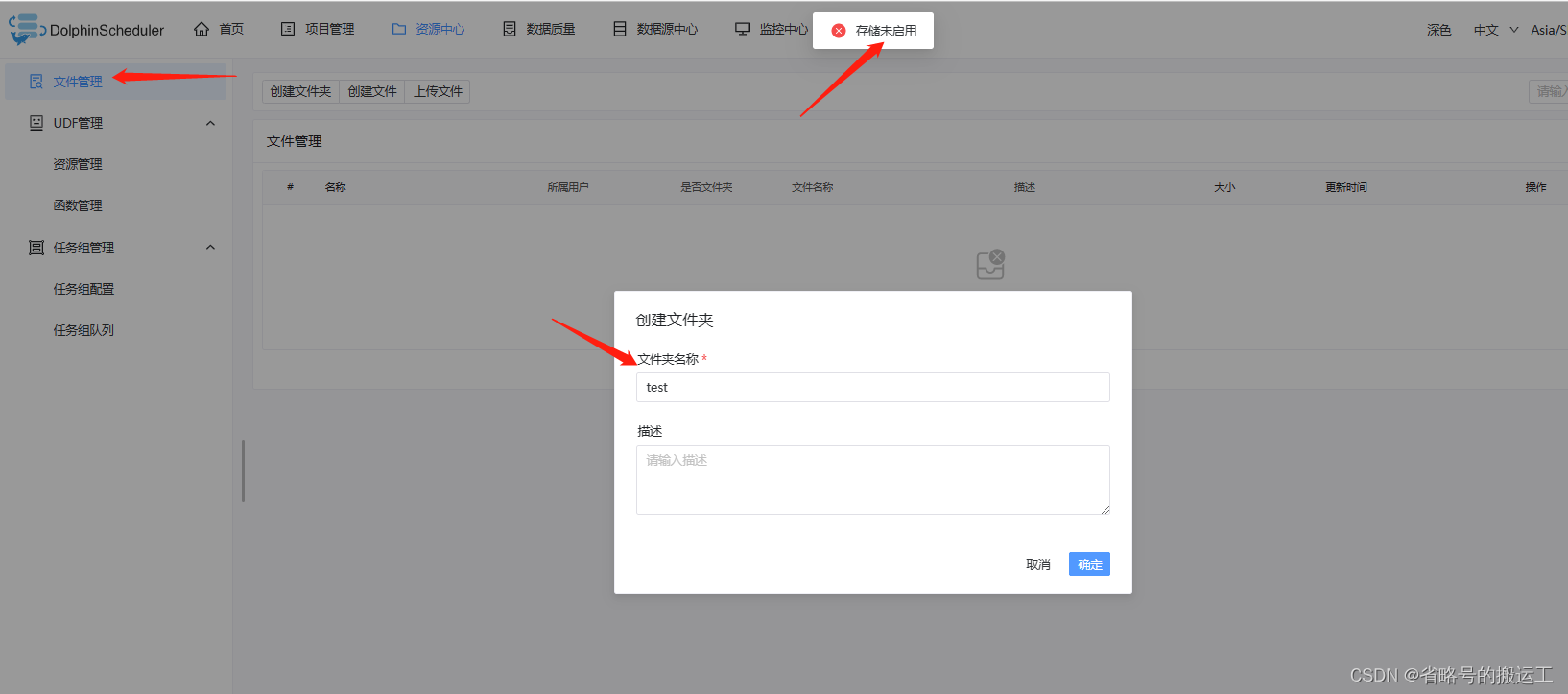
(5)资源中心配置,详见1.1.3,若不进行配置正式使用时会显示储存未开启,资源中心功能无法使用
(6)执行安装文件,需要先启动zookeeper
sh dolphinscheduler/bin/install.sh
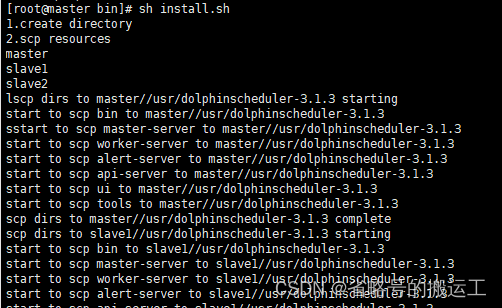
(7)查看前端界面
http://${apiServers}:12345/dolphinscheduler/ui 为web界面访问地址。默认的用户名和密码是 admin/dolphinscheduler123
可能的报错:zk正常,master或worker一段时间后挂掉
master或worker启动一段时间后挂掉,查看log显示zookeeper connect timeout: localhost:2181,但zookeeper集群在线
问题原因
网络或内存原因造成阻塞
解决办法
修改master-server/conf/application.yaml中的block-until-connected为6000ms
增加阻塞直到连接成功的等待时间
1.1.3 资源中心配置
① 资源中心通常用于上传文件、UDF 函数,以及任务组管理等操作。
② 资源中心可以对接分布式的文件存储系统,如Hadoop(2.6+)或者MinIO集群,也可以对接远端的对象存储,如AWS S3或者阿里云 OSS等。
③ 资源中心也可以直接对接本地文件系统。在单机模式下,您无需依赖Hadoop或S3一类的外部存储系统,可以方便地对接本地文件系统进行体验。
④ 除此之外,对于集群模式下的部署,您可以通过使用S3FS-FUSE将S3挂载到本地,或者使用JINDO-FUSE将OSS挂载到本地等,再用资源中心对接本地文件系统方式来操作远端对象存储中的文件。
1、对接本地文件系统
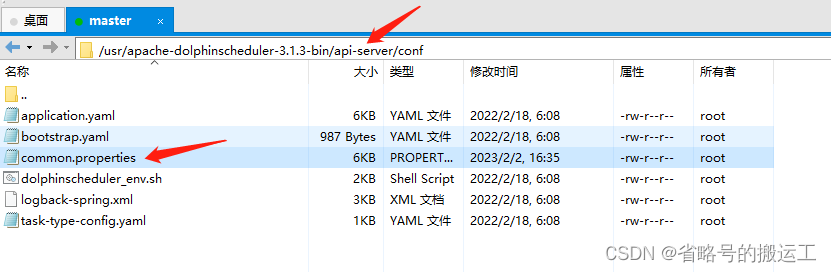
(1)配置common.properties
集群模式或者伪集群模式部署DolphinScheduler,需要配置以下文件:api-server/conf/common.properties 和 worker-server/conf/common.properties
将 resource.storage.upload.base.path 改为本地存储路径,请确保部署 DolphinScheduler 的用户拥有读写权限,例如:resource.storage.upload.base.path=/tmp/dolphinscheduler。当路径不存在时会自动创建文件夹
修改resource.storage.type=HDFS和resource.hdfs.fs.defaultFS=file:///。

user需要有在hdfs根目录创建目录的权限

启动hdfs后再次点击创建文件夹成功创建
2、对接分布式或远端对象存储
在 3.0.0-alpha 版本之后,如果需要使用到资源中心的 HDFS 或 S3 上传资源,我们需要对以下路径的进行配置:api-server/conf/common.properties 和 worker-server/conf/common.properties。
如果 Hadoop 集群的 NameNode 配置了 HA 的话,需要开启 HDFS 类型的资源上传,同时需要将 Hadoop 集群下的
core-site.xml
和
hdfs-site.xml
复制到
worker-server/conf
以及
api-server/conf
,非 NameNode HA 跳过次步骤。
1.2 参数
1.2.1 任务中可能出现的所有参数
任务参数
描述
任务名称
任务的名称,同一个工作流定义中的节点名称不能重复。
运行标志
标识这个节点是否需要调度执行,如果不需要执行,可以打开禁止执行开关。
描述
当前节点的功能描述。
任务优先级
worker线程数不足时,根据优先级从高到低依次执行任务,优先级一样时根据先到先得原则执行。
Worker分组
设置分组后,任务会被分配给worker组的机器机执行。若选择Default,则会随机选择一个worker执行。
任务组名称
任务资源组,未配置则不生效。
组内优先级
一个任务组内此任务的优先级。
环境名称
配置任务执行的环境。
失败重试次数
任务失败重新提交的次数,可以在下拉菜单中选择或者手动填充。
失败重试间隔
任务失败重新提交任务的时间间隔,可以在下拉菜单中选择或者手动填充。
CPU 配额
为执行的任务分配指定的CPU时间配额,单位为百分比,默认-1代表不限制,例如1个核心的CPU满载是100%,16个核心的是1600%。 task.resource.limit.state
最大内存
为执行的任务分配指定的内存大小,超过会触发OOM被Kill同时不会进行自动重试,单位MB,默认-1代表不限制。该功能由 task.resource.limit.state 控制。
超时告警
设置超时告警、超时失败。当任务超过"超时时长"后,会发送告警邮件并且任务执行失败。该功能由 task.resource.limit.state 控制。
资源
任务执行时所需资源文件
前置任务
设置当前任务的前置(上游)任务。
延时执行时间
任务延迟执行的时间,以分为单位
任务中可能出现的参数选项,任务不同参数也不同
1.2.2 内置参数
变量名
声明方式
含义
system.biz.date
${system.biz.date}
日常调度实例定时的定时时间前一天,格式为 yyyyMMdd
system.biz.curdate
${system.biz.curdate}
日常调度实例定时的定时时间,格式为 yyyyMMdd
system.datetime
${system.datetime}
日常调度实例定时的定时时间,格式为 yyyyMMddHHmmss
衍生内置参数
支持代码中自定义变量名,声明方式:${变量名}。可以是引用 "系统参数"
定义基准变量为 $[...],$[yyyyMMddHHmmss] 是可以任意分解组合的,比如:$[yyyyMMdd], $[HHmmss], $[yyyy-MM-dd] 等
也可以通过以下两种方式:
1、使用add_months()函数,该函数用于加减月份, 第一个入口参数为[yyyyMMdd],表示返回时间的格式 第二个入口参数为月份偏移量,表示加减多少个月
后 N 年:$[add_months(yyyyMMdd,12*N)]
前 N 年:$[add_months(yyyyMMdd,-12*N)]
后 N 月:$[add_months(yyyyMMdd,N)]
前 N 月:$[add_months(yyyyMMdd,-N)]
2、直接加减数字 在自定义格式后直接“+/-”数字
后 N 周:$[yyyyMMdd+7*N]
前 N 周:$[yyyyMMdd-7*N]
后 N 天:$[yyyyMMdd+N]
前 N 天:$[yyyyMMdd-N]
后 N 小时:$[HHmmss+N/24]
前 N 小时:$[HHmmss-N/24]
后 N 分钟:$[HHmmss+N/24/60]
前 N 分钟:$[HHmmss-N/24/60]
1.2.3 全局参数
全局参数是指针对整个工作流的所有任务节点都有效的参数,在工作流定义页面-保存中配置。
创建一个shell,内容为返回dt的值

在保存中创建全局变量
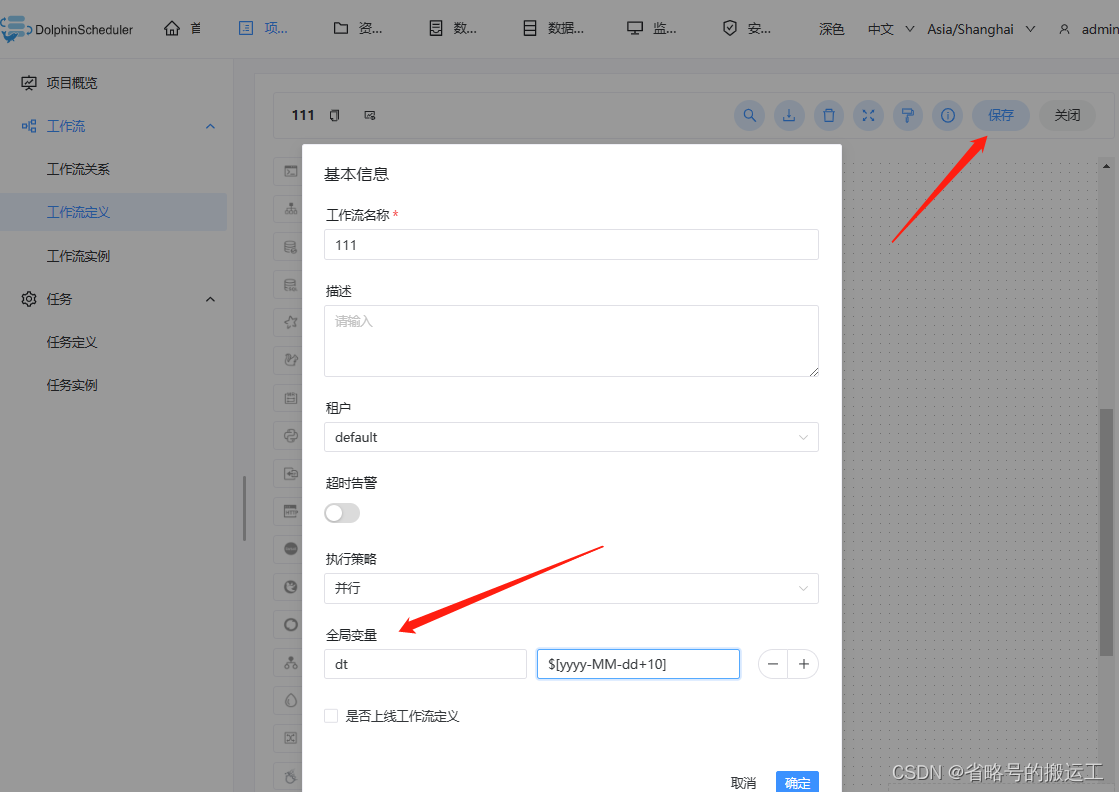
点击查看变量可以发现我们设置的参数

查看日志可以发现“当前日期加十天”可以被正常输出

1.2.4 本地参数
任务中可以设置的自定义参数
IN代表为局部参数,仅能在当前节点使用,OUT表示参数在下游使用
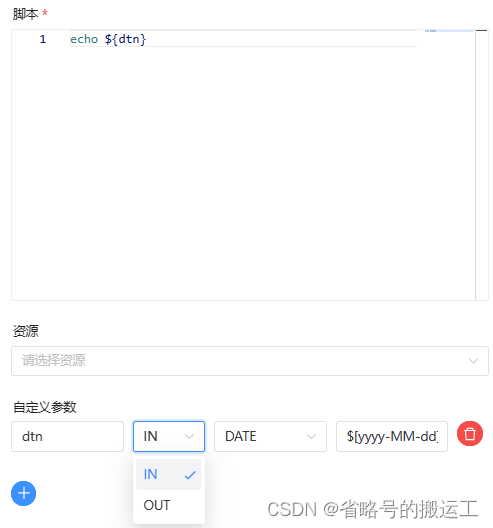
运行后发现

如果想用自定义参数而不是常量值来实现参数 export,并下游任务中使用它们,你可以在通过
setValue
和 自定义参数实现,当你想改变参数的值时可以直接改变 “自定义参数”模块中的值,这让程序更加容易维护。
①Shell 任务中使用语法
echo "#{setValue(set_val_param=${val})}"
②添加新的IN变量用于确认val输入值
③添加OUT变量用于export本地参数set_val_param
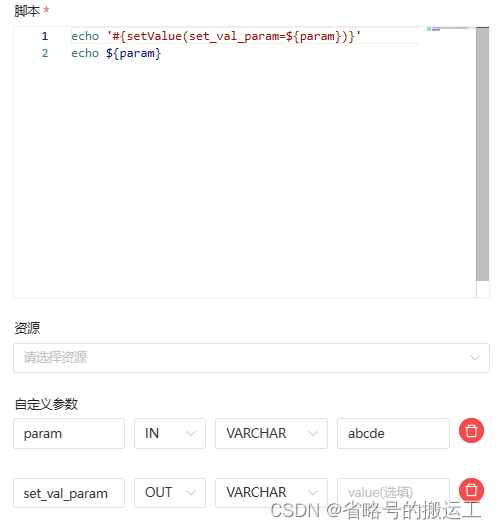
如果想用 bash 变量而不是常量值 export 参数,并在下游任务中使用它们,你可以在通过 setValue 和 Bash 变量实现,它更灵活,例如你动态获取现有的本地 或 HTTP 资源获取设定变量。 可以使用类似的语法:
lines_num=$(wget https://raw.githubusercontent.com/apache/dolphinscheduler/dev/README.md -q -O - | wc -l | xargs)
echo "#{setValue(set_val_var=${lines_num})}"
可能出现的问题:参数无法获取到
实测在同一个任务中,既添加了使用setValue的0非常量参数,又添加了自定义常数参数,如下图,既定义了set_val_param=${param}、set_dt_param=${dt}又定义了flow这样一个常数参数
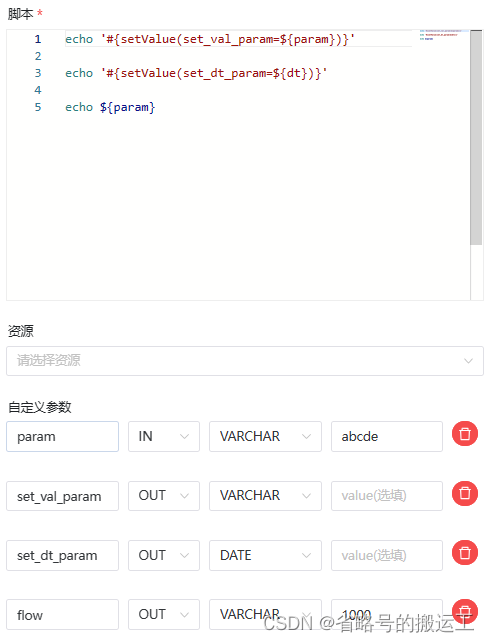
可能导致在后续的调用时取不到flow的值
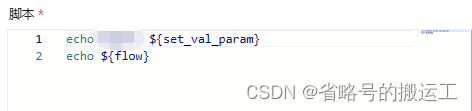

问题原因
未知
解决方法
将常数与非常数的定义分开,在下游任务中均可调用常数参数了

1.2.5 参数传递
DolphinScheduler 提供参数间相互引用的能力,包括:本地参数引用全局参数、上下游参数传递。
本地任务引用全局参数的前提是,你已经定义了全局参数,使用方式和本地参数中的使用方式类似,但是参数的值需要配置成全局参数中的 key,例如上述例子中的dt
echo'#{setValue(set_dt_param=${dt})}'
在下游中可以通过调用set_dt_param获得全局变量的值
DolphinScheduler 允许在任务间进行参数传递,目前传递方向仅支持上游单向传递给下游。目前支持这个特性的任务类型有:
① Shell
② SQL
③ Procedure
④ Python
上游传递的参数可以在下游节点中被更新,
如果定义了同名的传递参数,上游节点的参数将被覆盖。
注:若节点之间没有依赖关系,则局部参数无法通过上游传递。
1.2.6 参数优先级
DolphinScheduler 中所涉及的参数值的定义可能来自三种类型:
① 全局参数:在工作流保存页面定义时定义的变量
② 上游任务传递的参数:上游任务传递过来的参数
③ 本地参数:节点的自有变量,用户在“自定义参数”定义的变量,并且用户可以在工作流定义时定义该部分变量的值
因为参数的值存在多个来源,当参数名相同时,就需要会存在参数优先级的问题。DolphinScheduler 参数的优先级从高到低为:
本地参数 > 上游任务传递的参数 > 全局参数
在上游任务传递的参数中,由于上游可能存在多个任务向下游传递参数,当上游传递的参数名称相同时:
① 下游节点会优先使用值为非空的参数
② 如果存在多个值为非空的参数,则按照上游任务的完成时间排序,选择完成时间最早的上游任务对应的参数
1.3 数据源中心、资源中心、监控中心、安全中心
1.3.1 数据源中心
(1)数据源中心配置的数据源可以直接被任务中的SQL任务调用,换句话说,SQL任务仅支持数据源中心可以配置的数据源
(2)目前支持的数据源有:MySQL、PostgreSQL、Hive/Impala、Spark、clickhouse、Oracle、SQLserver、DB2、presto、redshift、athena
(3)数据源编写与其余同种类型软件都相似,不详细写配置了 ,值得注意的是如果希望在同一个会话中执行多个 HIVE SQL,可以修改配置文件
common.properties
中的配置,设置
support.hive.oneSession = true
。HIVE SQL
support.hive.oneSession
默认值为
false
,多条 SQL 在不同的会话中运行


(未完)1.3.2 资源中心
1、文件管理
创建文件前需要给当前用户配置租户
目前支持的文件类型有:txt、log、sh、bat、conf、cfg、py、java、sql、xml、hql、properties、json、yml、yaml、ini、js
按照3.1.3配置好后便可以使用资源中心功能,普通用户创建的文件管理员也可以使用,管理员用户创建的文件夹只有管理员有权使用,



管理员在安全中心-用户管理界面可以将其他用户创建的资源授权给普通用户,所有用户创建文件时不允许创建同目录下同名文件夹或同名文件

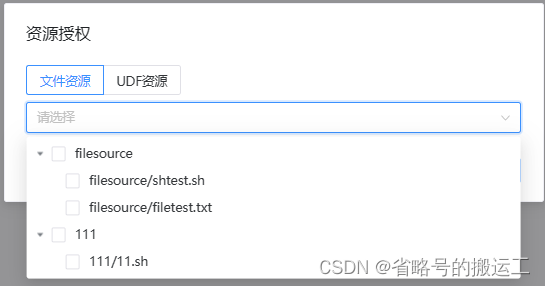
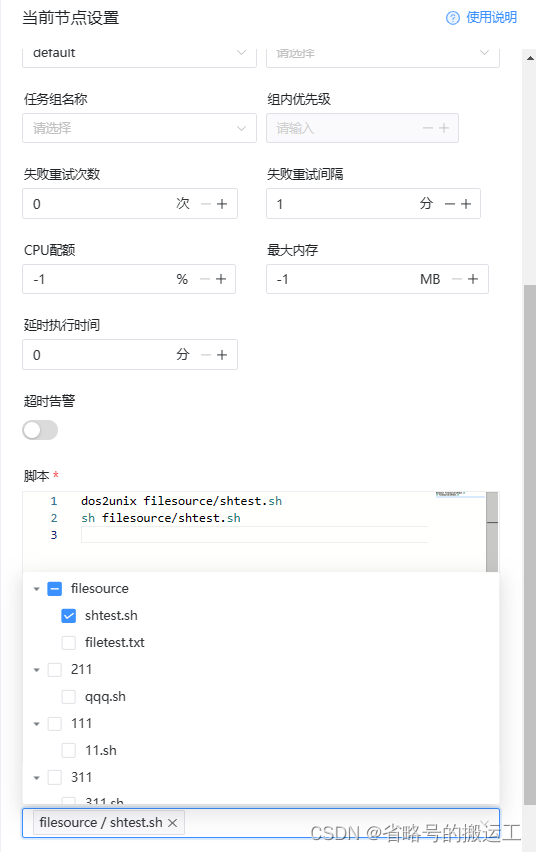
定义shell任务,可以运行定义好的shtest.sh,注意在引用时写全资源所在路径
2、UDF管理
主要用来上传hive的UDF函数,且目前只支持hiveUDF
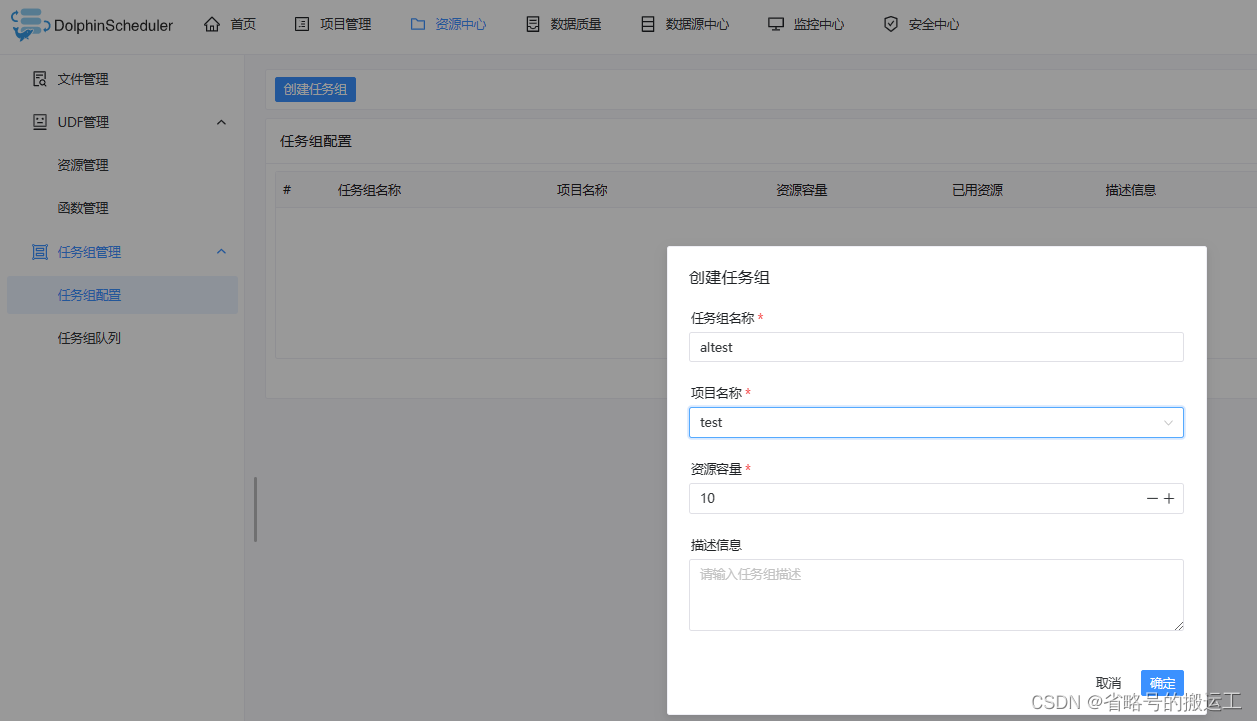
3、任务组管理
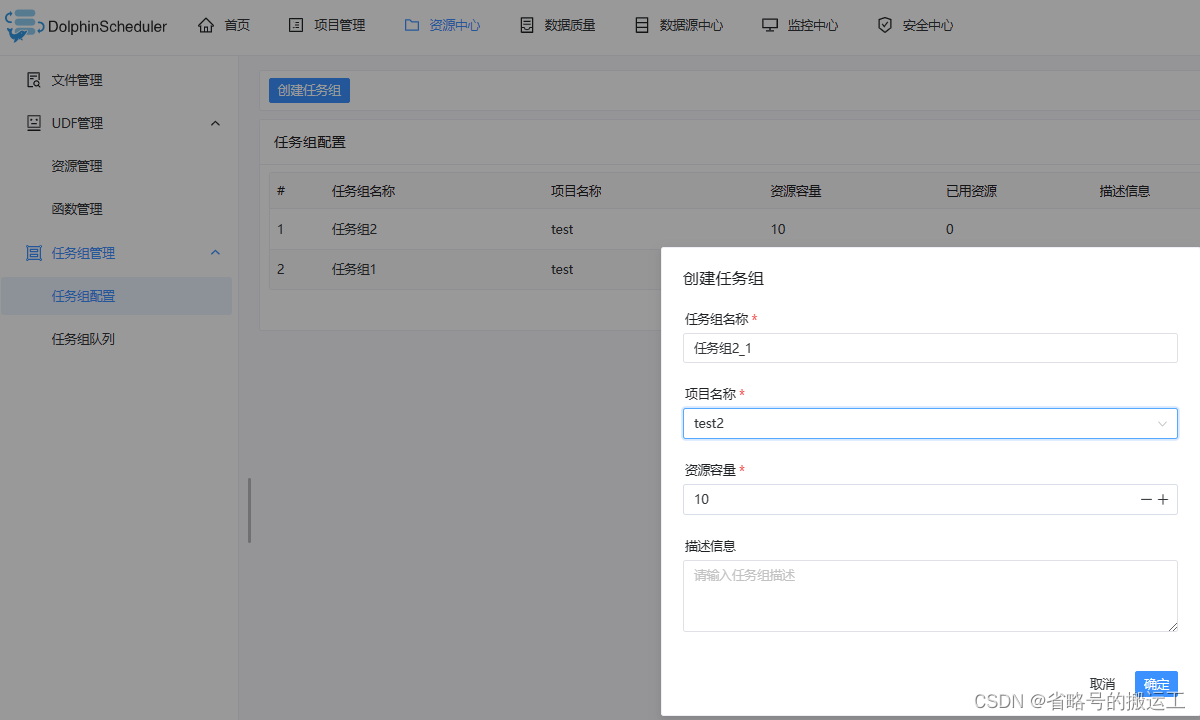
任务组主要用于控制任务实例并发,旨在控制其他资源的压力(也可以控制 Hadoop 集群压力,不过集群会有队列管控)。可在新建任务定义时,配置对应的任务组,并配置任务在任务组内运行的优先级
【任务组名称】:任务组在被使用时显示的名称
【项目名称】:任务组作用的项目,该项为非必选项,如果不选择,则整个系统所有项目均可使用该任务组。
【资源容量】:允许任务实例并发的最大数量
创建任务组

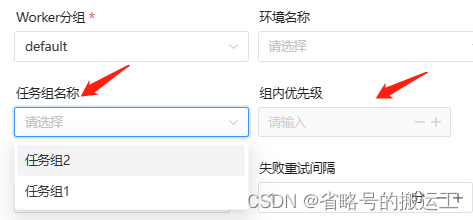
【任务组名称】:任务组配置页面显示的任务组名称,这里只能看到该项目有权限的任务组(新建任务组时选择了该项目),或作用在全局的任务组(新建任务组时没有选择项目)
【组内优先级】:在出现等待资源时,优先级高的任务会最先被 master 分发给 worker 执行,该部分数值越大,优先级越高。

实现逻辑:
① Master 在分发任务时判断该任务是否配置了任务组
② 如果任务没有配置,则正常抛给 worker 运行
③ 如果配置了任务组,在抛给 worker 执行之前检查任务组资源池剩余大小是否满足当前任务运行
④ 如果满足资源,继续运行
⑤ 如果不满足则退出任务分发,等待其他任务结束唤醒
⑥ 当使用任务组资源的任务结束运行后,会释放任务组资源,释放后会检查当前任务组是否有任务等待
⑦ 如果有,则标记优先级最高的任务可以运行,并新建一个可以执行的event。该event中存储着被标记并且可以获取资源的任务id
⑧ 获取任务组资源然后运行。
(未完)1.3.3 监控中心
主要是 master、worker、database 的使用率等信息。
统计管理中几个参数为元数据库中的数据
待执行命令数:统计 t_ds_command 表的数据
执行失败的命令数:统计 t_ds_error_command 表的数据
不过数据过于简单,不如看Grafana指标
1.3.4 安全中心
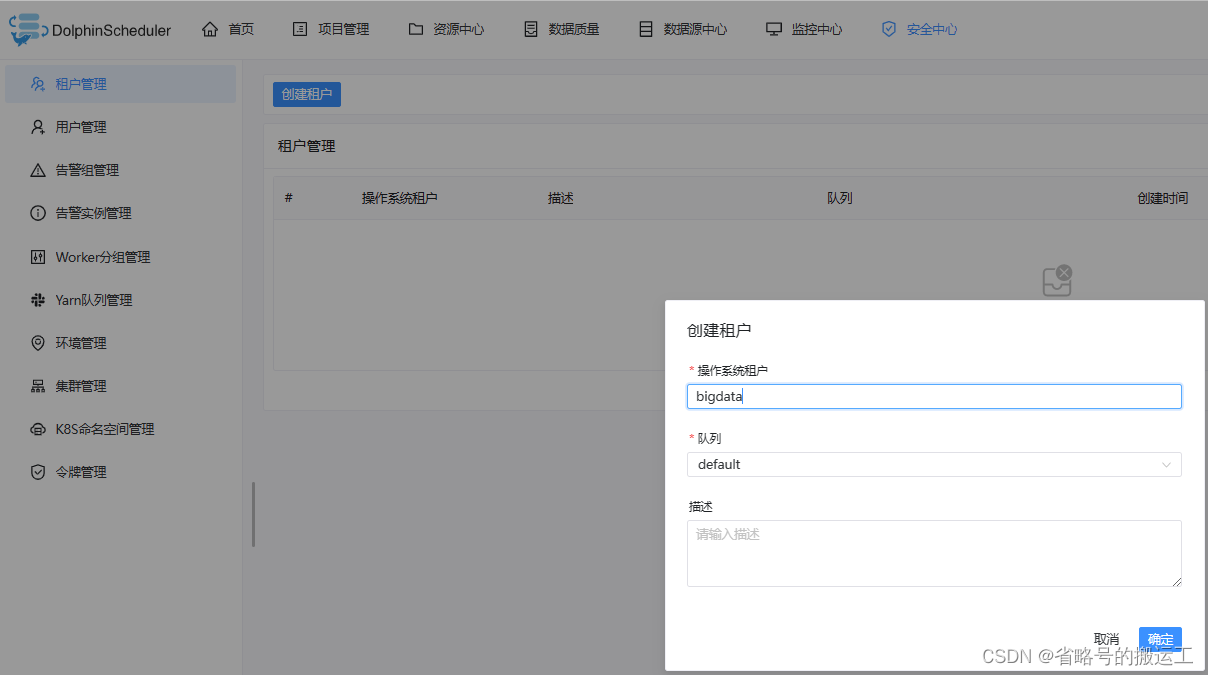
1、租户管理
租户对应的是 Linux 的用户,用于 worker 提交作业所使用的用户。如果 linux 没有这个用户,则会导致任务运行失败。
可以通过修改 worker.properties 配置文件中参数 worker.tenant.auto.create=true 实现当 linux 用户不存在时自动创建该用户。worker.tenant.auto.create=true 参数会要求 worker 可以免密运行 sudo 命令
【操作系统队列】:Linux上 的用户,唯一,不能重复
创建租户
【队列】:为yarn队列管理中创建的队列,后续会提到

2、用户管理
用户分为管理员用户和普通用户
管理员有授权和用户管理、创建项目和工作流定义等权限。
普通用户可以创建项目和对工作流定义的创建,编辑,执行等操作。
注意:如果该用户切换了租户,则该用户所在租户下所有资源将复制到切换的新租户下。
创建普通用户

绑定租户,新用户包括管理员用户都必须绑定租户后才能运行工作流
普通用户的安全中心只有令牌管理一项功能

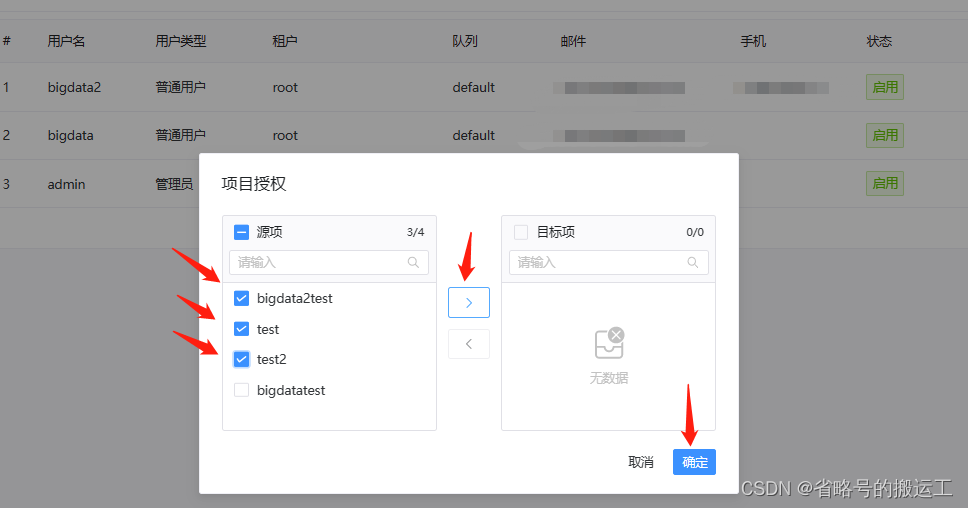
权限管理
管理员用户可以对普通用户授权,权限包括项目、资源、数据源、UDF函数和K8S命名空间

假如管理员A创建了项目a,普通用户B1创建了项目b1,普通用户B2创建了项目b2,那么在A的项目列表中会有项目a、b1、b2;B1的项目列表中有b1;B2的项目列表中有b2。
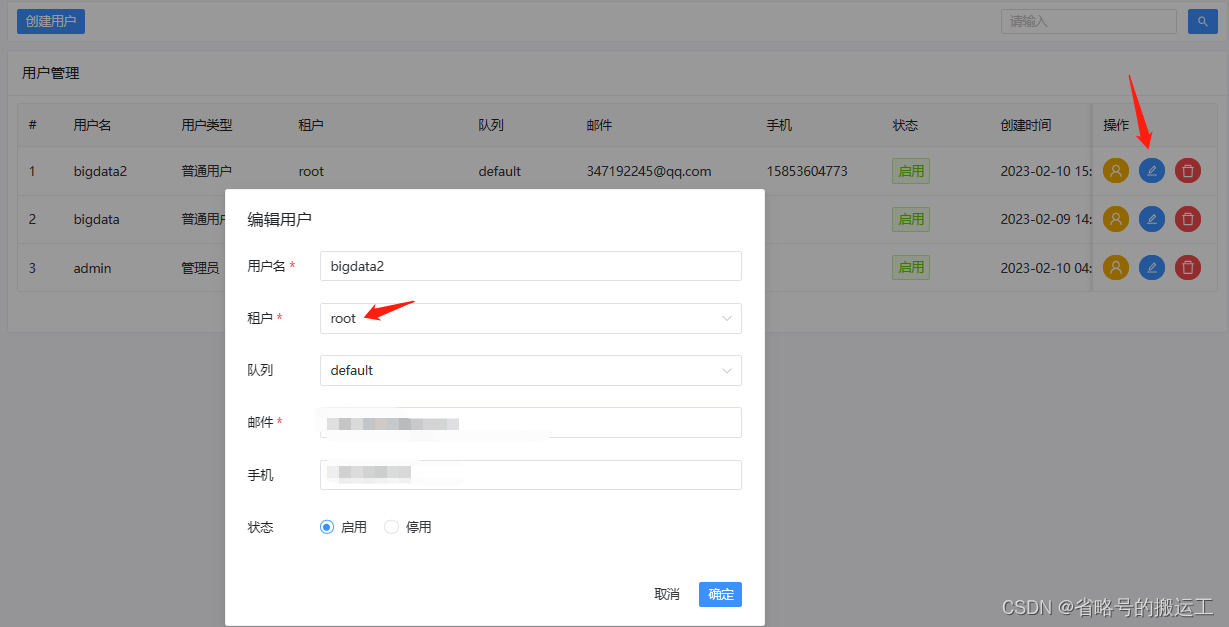
既管理员用户拥有本身和所有普通用户创建项目的权限,普通用户仅有自己创建的项目的权限。而授权可以将任何项目权限赋予普通用户,比如将a,b2赋予B1,则B1可以编辑a、b1、b2项目。
其他的资源、数据源等同理
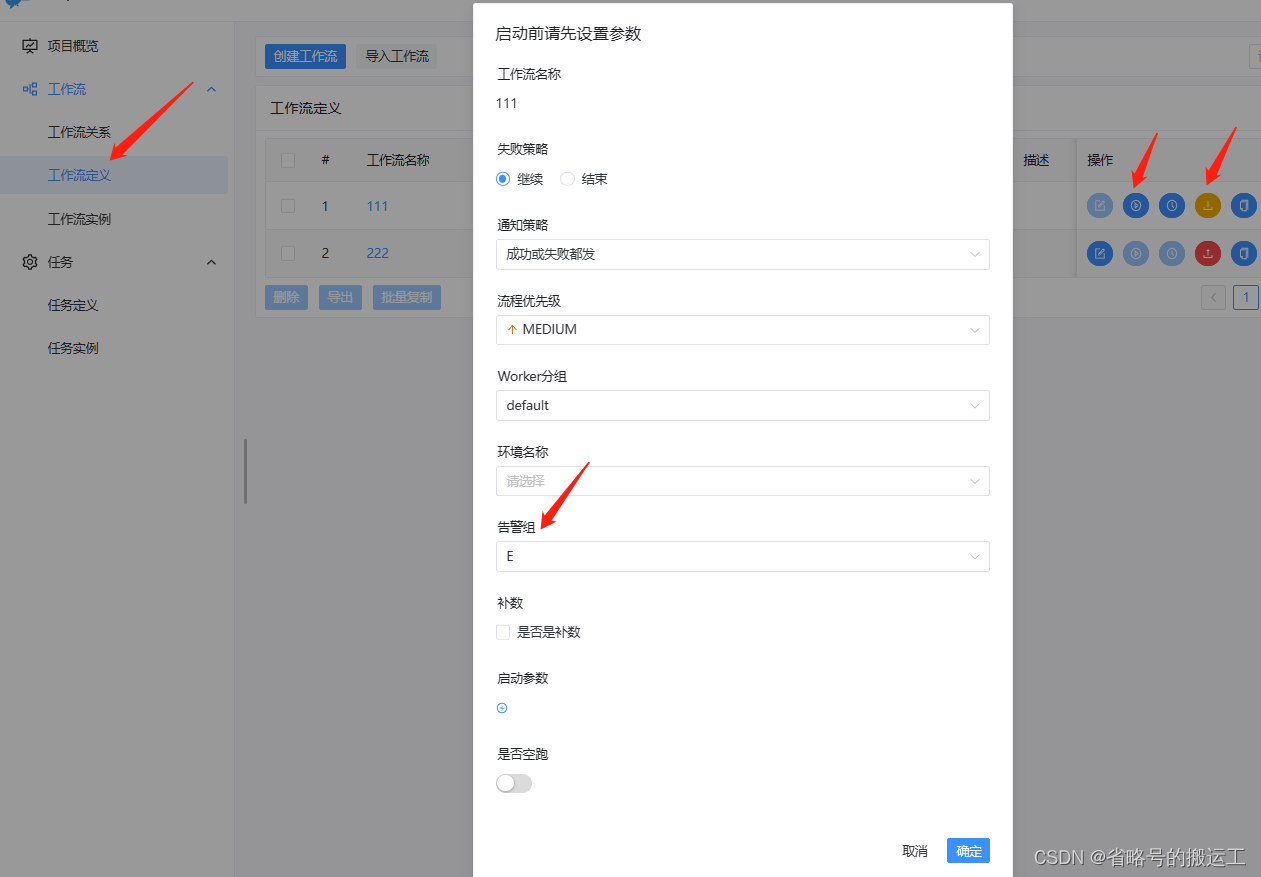
3、警告组管理
创建警告组需要先创建警告实例,见4
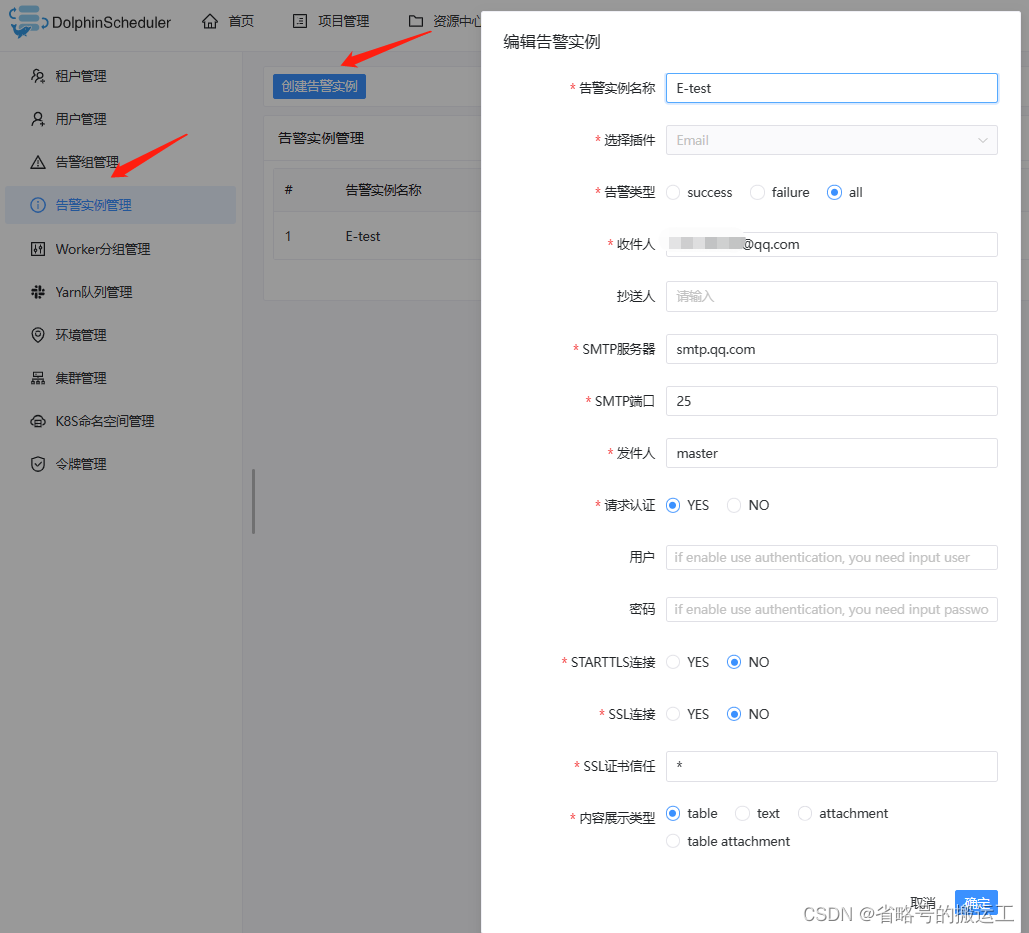
4、警告实例管理
例如QQ邮箱,需要先去设置中开启SMTP服务,邮箱如何开启SMTP可以自行搜索


5、worker分组管理
6、yarn队列管理
此处创建出的队列,可供后续任务进行选择。在dolphinscheduler中创建队列,并不会影响到 Yarn 调度器的队列配置。
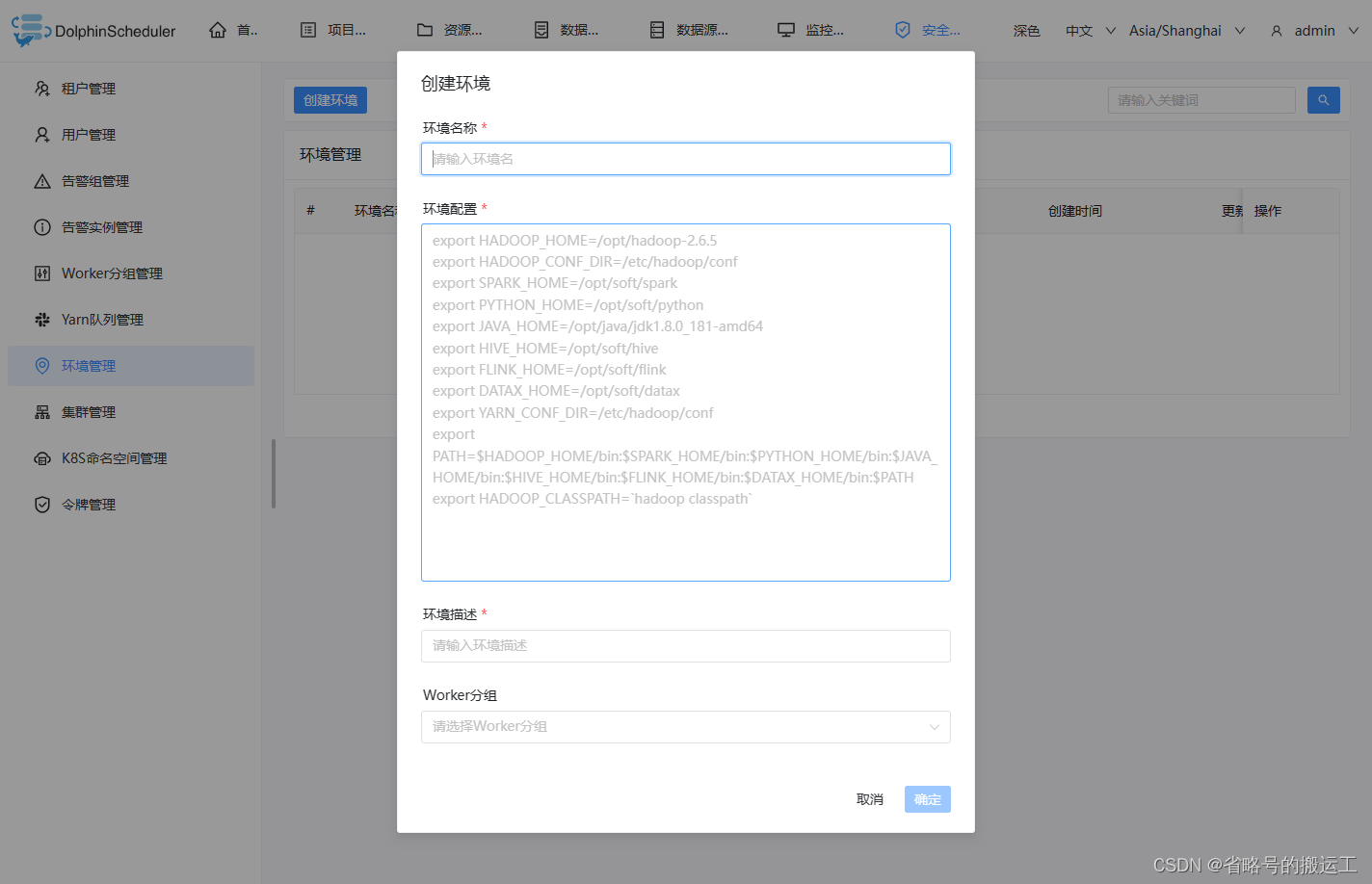
7、环境管理
8、集群管理

1.x-1各任务类型详解
1.x dolphinsheduler简单使用
1.x.1 伪集群模式安装
官网文档中推荐内存大于8g,测试环境不符合要求因此使用伪集群模式试用功能
伪集群模式配置只与集群模式有细微差别
① 修改dolphinscheduler/bin/env/install_env.sh
先前配置好的dolphinscheduler_env.sh可不做修改,配置方法见1.1.2(3),并且保证mysql中数据库已经创建完毕
将之前指定的各节点均指定master即可

② 启动zookeeper
③ 然后sh dolphinscheduler/bin/install.sh安装伪集群模式
④ 全局命令
start-all.sh启动所有服务
stop-all.sh关闭所有服务
status-all.sh查看所有服务状态
dolphinscheduler-daemon.sh 单独操作某个服务,例如:
sh dolphinscheduler-daemon.sh start/stop/status master-server
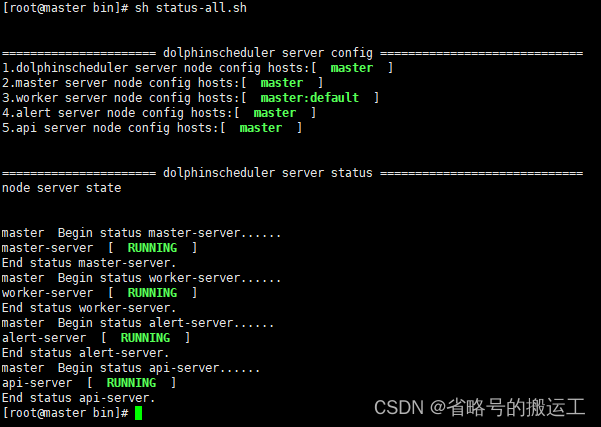
⑤ 同样的方式——见1.1.2(6)——登入web界面,
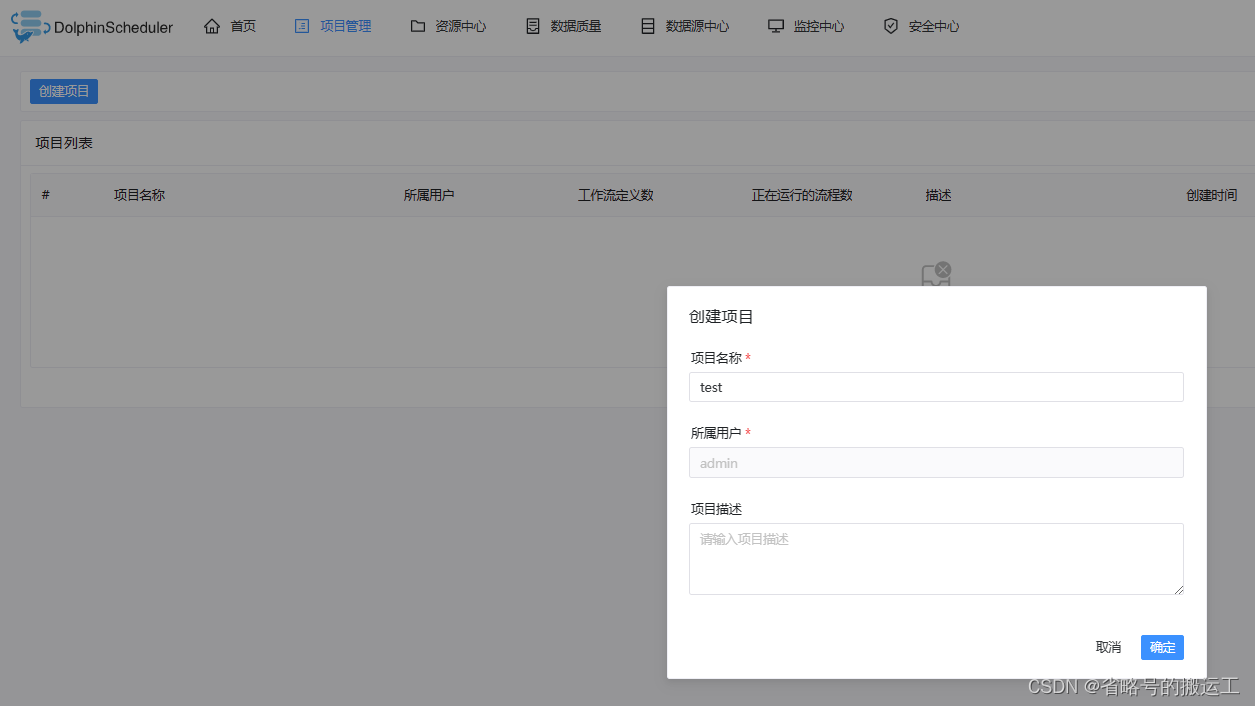
创建项目
创建任务组
创建租户,租户为shell等命令在集群上提交运行的用户,测试可以直接使用root
绑定租户

新建工作流,拖动新建任务
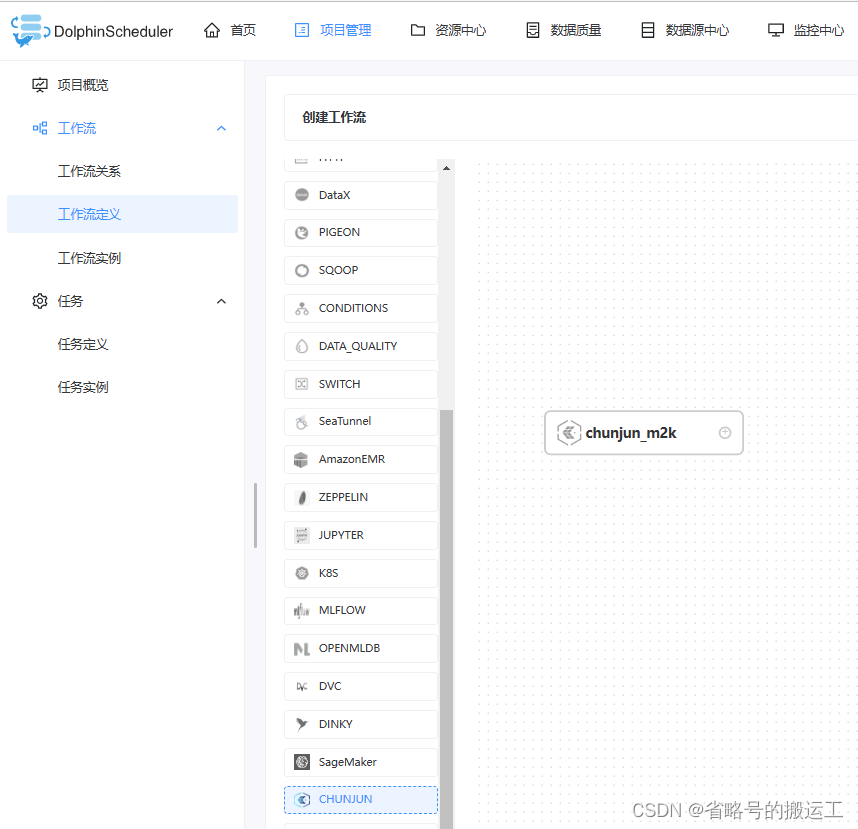
编辑任务
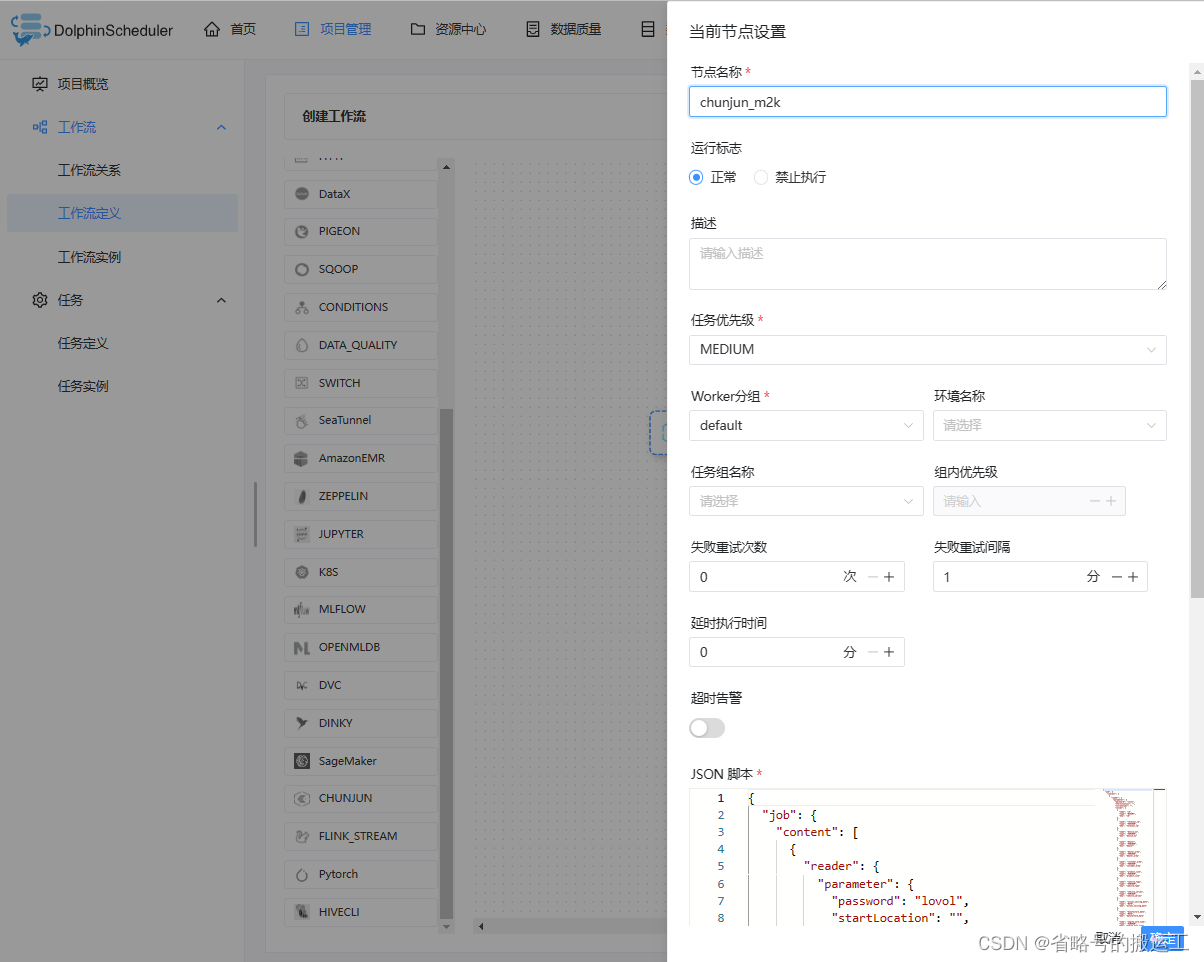

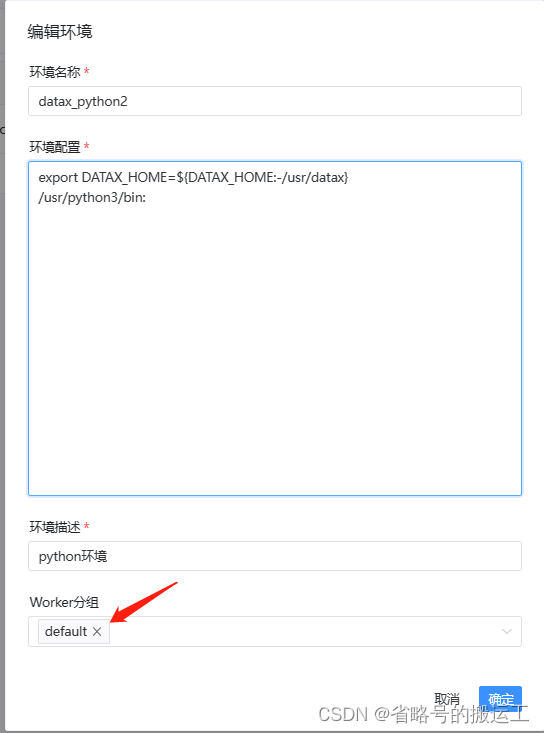
datax为python2版本,注意目录下要有到python2的链接
可能出现的报错(严重):保存空key值Map导致工作流无法编辑
com.fasterxml.jackson.databind.JsonMappingException: Null key for a Map not allowed in JSON (use a converting NullKeySerializer?) (through reference chain: org.apache.dolphinscheduler.api.utils.Result["data"]->org.apache.dolphinscheduler.dao.entity.DagData["taskDefinitionList"]->java.util.ArrayList[2]->org.apache.dolphinscheduler.dao.entity.TaskDefinitionLog["taskParamMap"])
原因:
类似github这个issue
[BUG] 编辑过程时不显示任何内容 ·问题 #12525 ·阿帕奇/海豚调度器 (github.com)
解决办法
目前没有好的解决办法,复制先前工作流实例的内容,删除工作流重新编写
可能出现的报错:chunjun任务无法保存
在任务流包含chunjun任务时无法保存,并提示参数无效
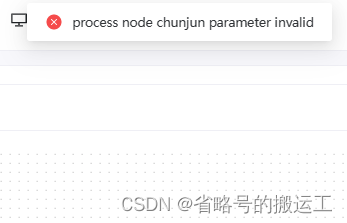
截至2023.02所有版本chunjun任务保存均异常,等待官方后续更新,下文有临时解决办法
[bug] [task-chunjun] can not submit successfully cause check err · Issue #13108 · apache/dolphinscheduler (github.com)
问题原因
chunjun功能上线时间短,源码逻辑可能有问题,customConfig默认为false导致任务无法创建

[错误][UI] 创建工作流包含春君节点失败 ·问题 #11321 ·阿帕奇/海豚调度器 (github.com)
 [fix-11321][ui] fix create workflow contains chunjun node failed · jkhhuse/dolphinscheduler@5062324 (github.com)
[fix-11321][ui] fix create workflow contains chunjun node failed · jkhhuse/dolphinscheduler@5062324 (github.com)
解决办法
方法1、重新编译
(1)修改dolphinscheduler-ui/src/views/projects/task/components/node/tasks/use-chunjun.ts的customConfig为true

[fix-11321][ui] fix create workflow contains chunjun node failed · jkhhuse/dolphinscheduler@5062324 (github.com)
(2)解压安装包,启动zookeeper
(3)复制原本配置好的install_env.sh,dolphinscheduler_env.sh到新bin/env下,执行bin/install_all.sh
打包步骤见1.1.2(1)
运行结束后可以在目录dolphinscheduler-dist/target下找到压缩包
方法2、直接修改编译后的js文件
经过测试,编译后的use-chunjun.js所在路径有两个,
(1)ui文件夹下的 dolphinscheduler/ui/assets/detail-*.js
(2)api文件夹下的 api-server/ui/assets/detail-*.js
detail.js每次编译后缀都不一样,一共只有三个文件,可以依次Ctrl+F


修改完成后按步骤重启dolphinscheduler
进入前端界面后在工作流中创建chunjun任务可以正常保存


点击保存发现保存成功
可能出现的报错:重名class报错
non-compatible bean definition of same name
报错日志
org.springframework.context.annotation.ConflictingBeanDefinitionException: Annotation-specified bean name 'registryClient' for bean class [org.apache.dolphinscheduler.registry.api.RegistryClient] conflicts with existing, non-compatible bean definition of same name and class [org.apache.dolphinscheduler.service.registry.RegistryClient]
问题原因
由于之前版本未删除,就将新版本安装到源路径下,两个版本间存在相同名称的class在不同的包中就会出现同名报错
解决办法:
彻底删除过去版本后再install.sh新版本
可能出现的报错(严重):工作流停止后无法删除,log重复刷屏直至磁盘存满
[ERROR] 2023-02-09 10:53:38.955 +0800 org.apache.dolphinscheduler.server.master.runner.WorkflowExecuteRunnable:[704] - [WorkflowInstance-0][TaskInstance-0] - Start workflow error
java.lang.NullPointerException: null
at java.util.concurrent.ConcurrentHashMap.putVal(ConcurrentHashMap.java:1011)
at java.util.concurrent.ConcurrentHashMap.put(ConcurrentHashMap.java:1006)
at org.apache.dolphinscheduler.server.master.runner.WorkflowExecuteRunna
问题原因
编写工作流后执行,失败后,更改任务的信息,再上线,执行,出现上面错误。
以上方法也不能完全复现,在任务状态为正在执行时点击停止就有概率触发,频繁地重复更改、上下线同一个任务或内存不足等有可能提高该bug几率。
以下issue也是相似问题,但都没有得到解决
[Bug] [Worker] concurrent task response occasional cause status error · Issue #13409 · apache/dolphinscheduler (github.com)(最相似的原因)
[Bug] [dolphinscheduler master] Infinite loop process_instance when status is prepare to stop · Issue #12440 · apache/dolphinscheduler (github.com)
[Bug] [Master] Stopping a workflow does not update task status correctly · Issue #13244 · apache/dolphinscheduler (github.com)
解决办法:
方法1、建议定期备份元数据库的表,最快最彻底解决这个报错的办法是回滚
方法2、或是修改元数据表中相关实例的状态
select t1.task_code,t1.state,t2.state
from
t_ds_task_instance t1
left join
t_ds_process_instance t2
on t1.process_instance_id = t2.id
where t1.task_code='${your_error_task_code}'
update state=7
其中工作流实例t_ds_process_instance,一个工作流实例对应一个或多个任务实例t_ds_task_instance,state
两种方法都不是最佳解决办法,需等待官方版本更新或自行研究修改源码相关逻辑
可能出现的报错:chunjun任务显示成功但并没被提交 initialization of VM
chunjun任务可以正常提交但并不会启动chunjun,显示initialization of VM
问题原因:
正常任务流程:dolphin点击运行->新建临时路径->在临时路径生成任务->执行任务->更新任务pid->删除临时路径
报错流程:dolphin点击运行->新建临时路径->在临时路径生成任务->更新任务pid->删除临时路径->执行任务
由于pid过早更新导致临时任务还没能运行就被标记为运行成功,由于执行任务时任务所在路径已经被删除,在已删除目录下运行则报initialization of VM
chunjun任务提交时生成的临时目录与临时任务如下所示
${CHUNJUN_HOME}/bin/start-chunjun -mode yarn-per-job -jobType sync -job /tmp/dolphinscheduler/exec/process/root/8511129061728/8655529352544_8/55/112/55_112_job.json -chunjunDistDir ${CHUNJUN_HOME}/chunjun-dist -flinkConfDir ${FLINK_HOME}/conf -flinkLibDir ${FLINK_HOME}/lib -hadoopConfDir ${HADOOP_HOME}/etc/hadoop
解决办法
在3.1.4版本已解决上述问题
安装包可能没有更新,请下载源码打包,打包步骤见1.1.2(1)
[Improvement][worker] task instance's pid need to be insert to DB during running · Issue #13201 · apache/dolphinscheduler (github.com)
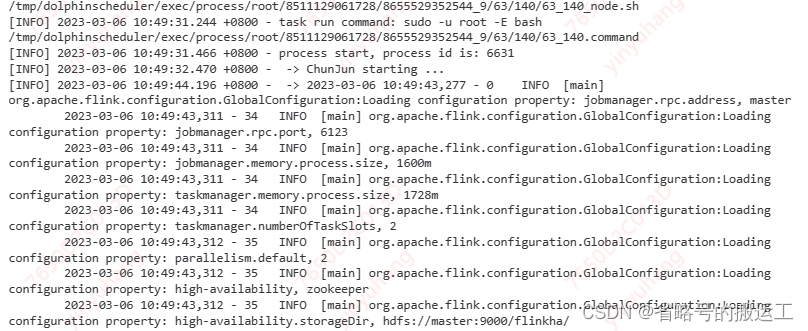
1.x.2 数据同步任务Kafka->MySQL->Kafka
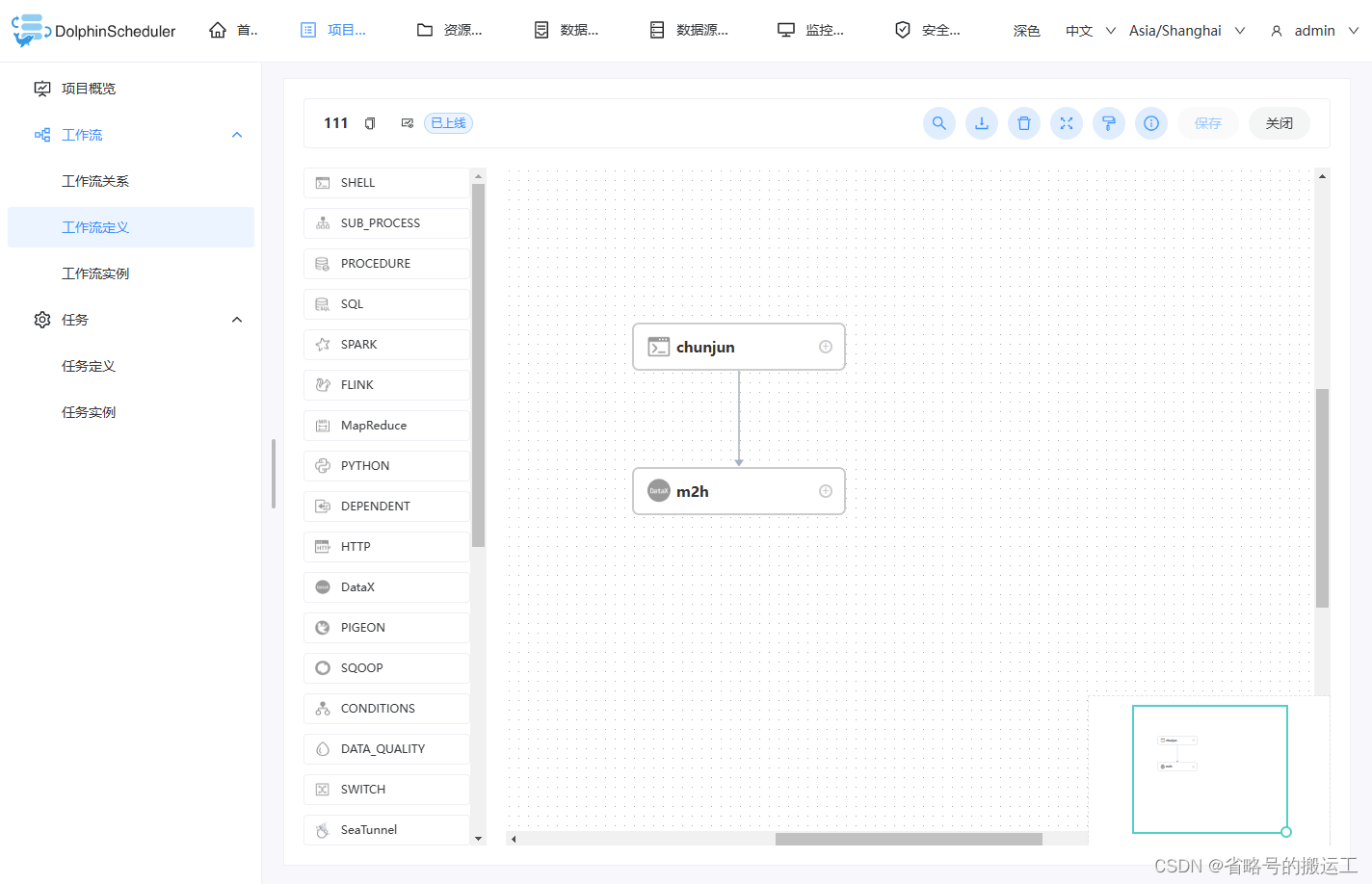
查看dolphinscheduler-api.log

只有在同一worker下才能被任务调用
版权归原作者 省略号的搬运工 所有, 如有侵权,请联系我们删除。