
文章目录
网易云热歌榜
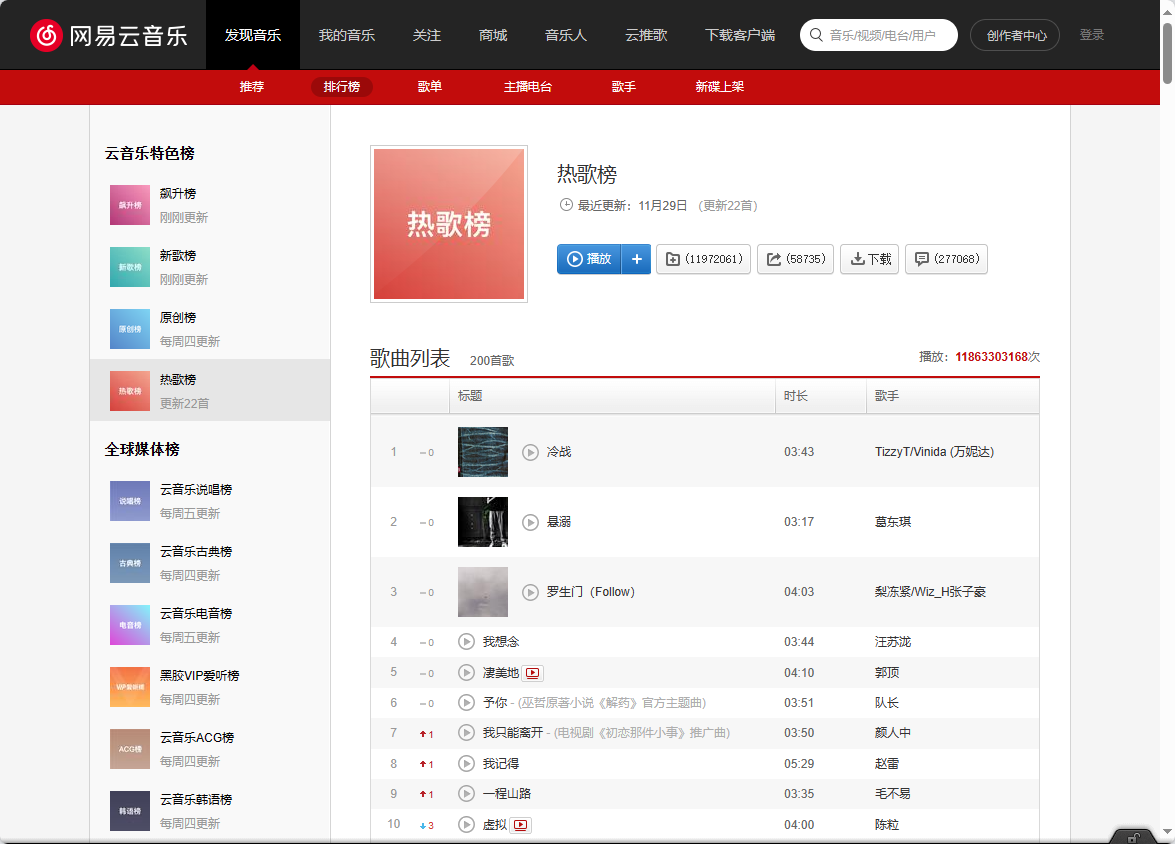
踩坑:frame
F12查看网页源代码发现每一个歌曲都是tr标签包含在唯一的tbody标签内,那我们只要获取到所有的br标签就能得到想要的数据,但测试发现爬取后的数据为空或者找不到元素,最后发现是因为页面中嵌套了frame从而导致定位不到元素。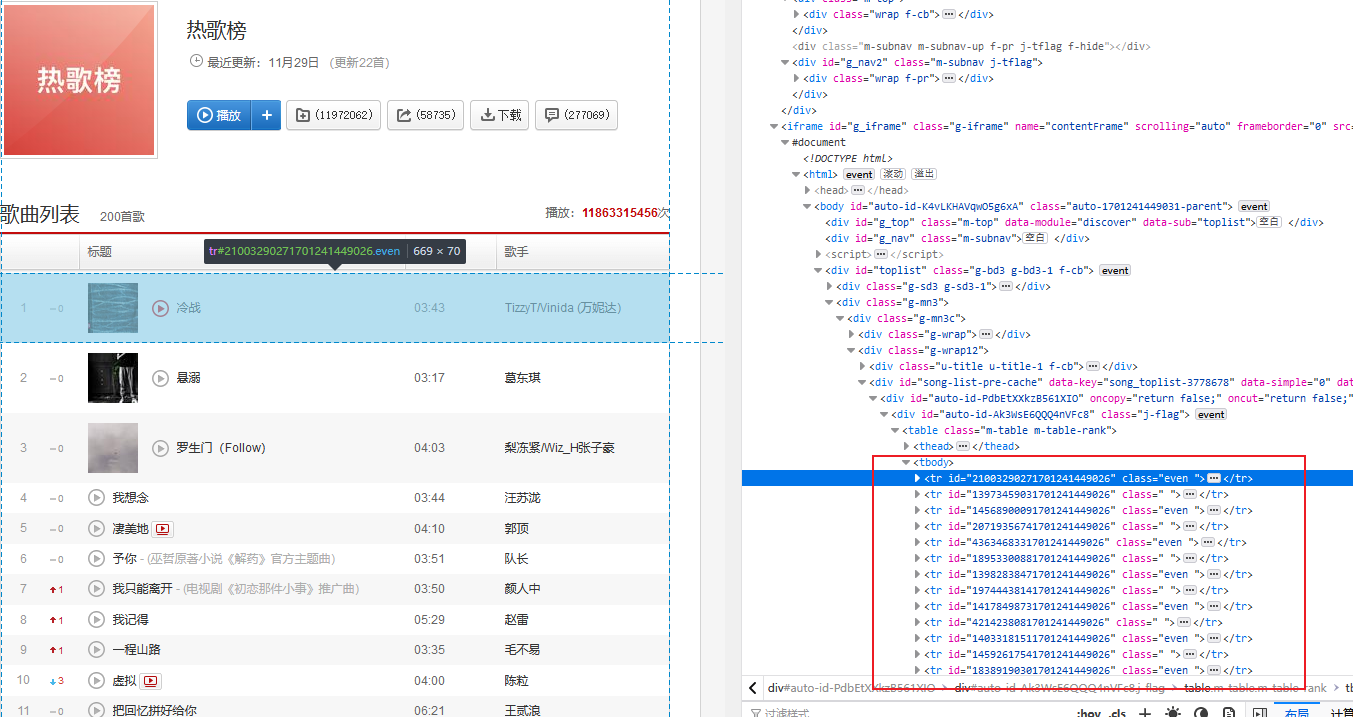
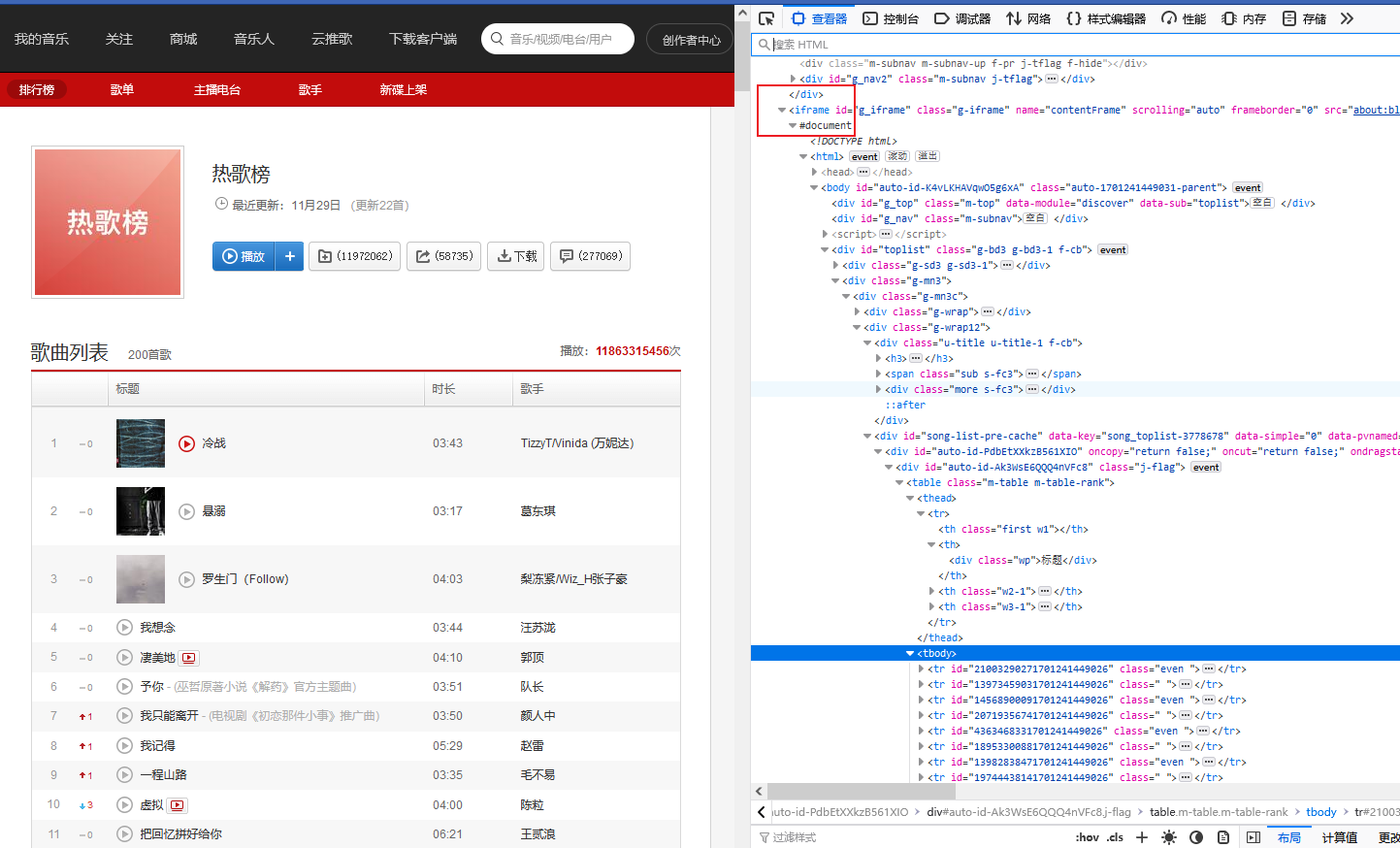
switch_to.frame()
需要使用switch_to.frame()方法来切换页面Frame
driver = webdriver.Edge()
driver.get("https://music.163.com/#/discover/toplist?id=3778678")
driver.switch_to.frame('g_iframe')

完整代码
from selenium import webdriver
from selenium.webdriver.common.by import By
# Edge驱动
driver = webdriver.Edge()# 访问网易云热歌榜
driver.get("https://music.163.com/#/discover/toplist?id=3778678")# switch_to.frame() 方法切换到 iframe 中
driver.implicitly_wait(5)# 隐性等待
driver.switch_to.frame('g_iframe')# 解析网页源代码获取所有 tr 标签
driver.implicitly_wait(3)
tr_list = driver.find_elements(By.XPATH,"//table[@class='m-table m-table-rank']/tbody/tr")# 遍历 tr 标签获取需要的数据for tr in tr_list:try:
num = tr.find_element(By.XPATH,"td/div/span").text
title = tr.find_element(By.XPATH,"td[2]/div/div/div/span/a/b").get_attribute("title")
time = tr.find_element(By.XPATH,"td[3]/span").text
name = tr.find_element(By.XPATH,"td[4]/div").get_attribute("title")except Exception as e:print(e)else:# print(num, title, time, name)
data =f"{num},{title},{time},{name}\n"# 持久化存储withopen("music_top200.csv","a", encoding="utf-8")as fp:
fp.write(data)
运行结果
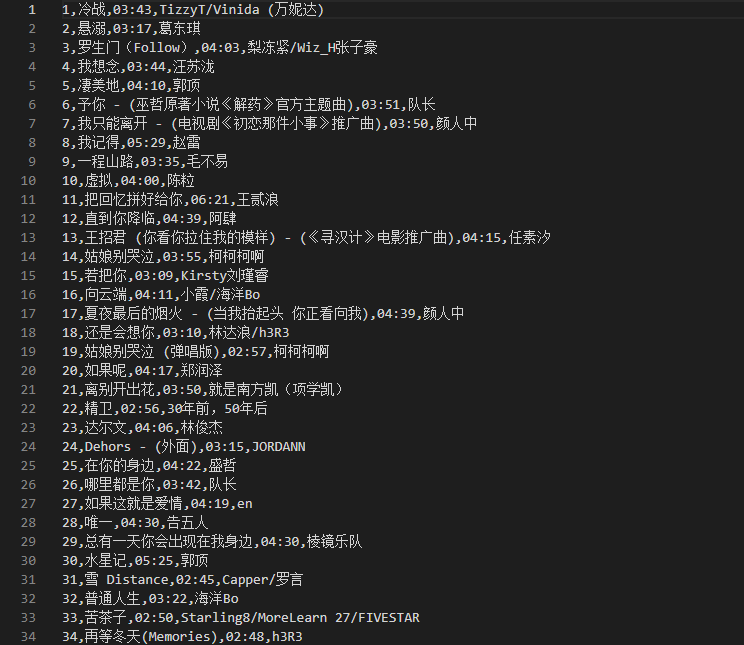
本文转载自: https://blog.csdn.net/weixin_49184448/article/details/134690286
版权归原作者 大数据·流浪法师 所有, 如有侵权,请联系我们删除。
版权归原作者 大数据·流浪法师 所有, 如有侵权,请联系我们删除。