
概念
聚类就是将样本划分为由类似的对象组成的多个类的过程。
注:分类是已知类别,而聚类是未知。
算法介绍
K-means算法
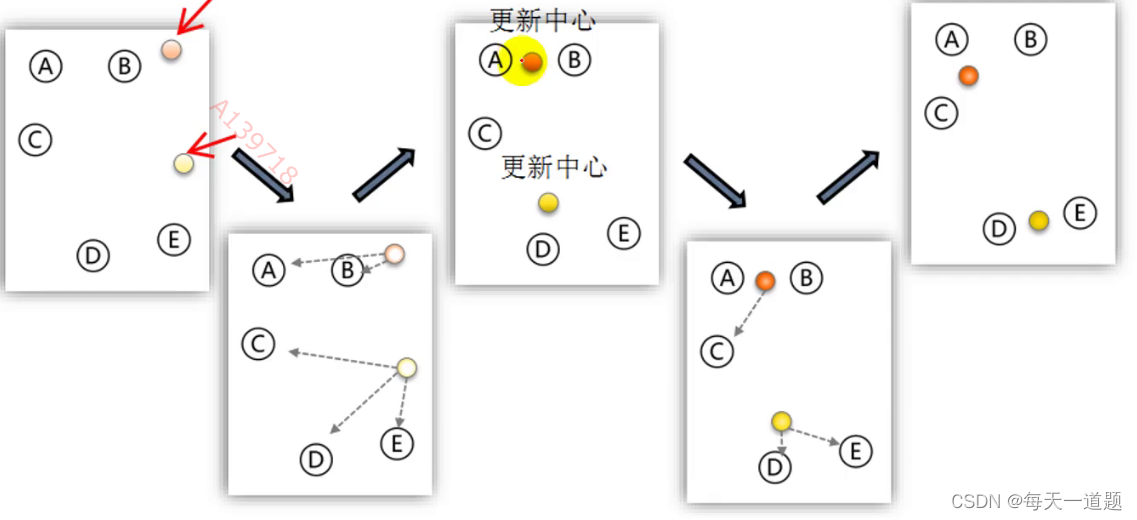
1.指定需要划分的簇的个数K值(类的个数)。
2.随机地选择k个数据对象作为初始的聚类中心(不一定要是我们的样本点)。
3.计算其余的各个数据对象到这K个初始聚类中心的距离,把数据对象划归到距离它最近的那个中心所处在的簇类中。
4.调整新类并且重新计算出新类的中心。
5.循环步骤三和四,看中心是否收敛(不变),如果收敛或达到迭代次数则停止循环。
算法评价
优点:
(1)算法简单,快速。
(2)对处理大数据集,该算法是相对高效率的。
缺点:
(1)要求用户必须事先给出要生成的簇的数目k。
(2)对初始值敏感。
(3)对于孤立点数值敏感。
而K-means++算法可以解决缺点2,3。
K-means++算法
算法优化点
K-means++算法选择初始聚类中心的基本原则是:初始的聚类中心之间的相互距离要尽可能的远。
算法流程
只对K-means算法“初始化K个聚类中心”这一步进行了优化。
(1)随机选取一个样本作为第一个聚类中心。
(2)计算每个样本与当前已有聚类中心的最短距离(即与最近一个聚类中心的聚类),这个值越大,表示被选取作为聚类中心的概率较大;最后,用轮盘法(依据概率大小进行抽选)选出下一个聚类中心。
(3)重复步骤二,直到选出K个聚类中心。选出初始点后,就继续使用标准的K-means算法。
注:如果数据的量纲不一样,必须进行标准化,否则毫无任何意义。
SPSS实现方法
1.导入数据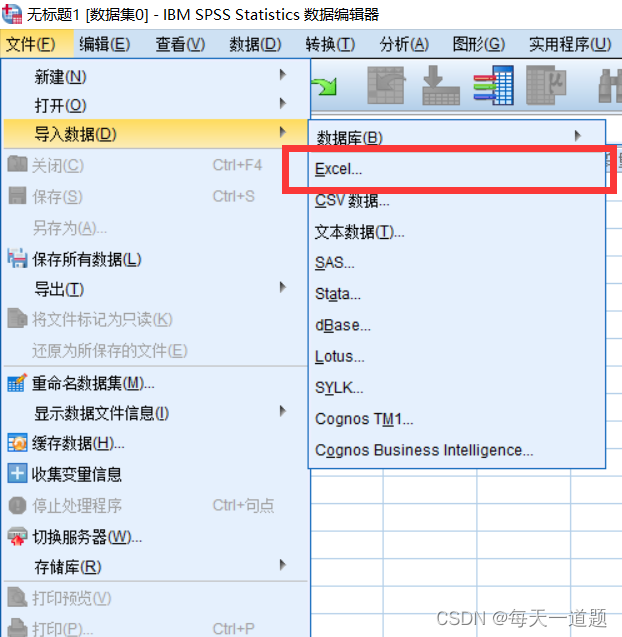
2.选择变量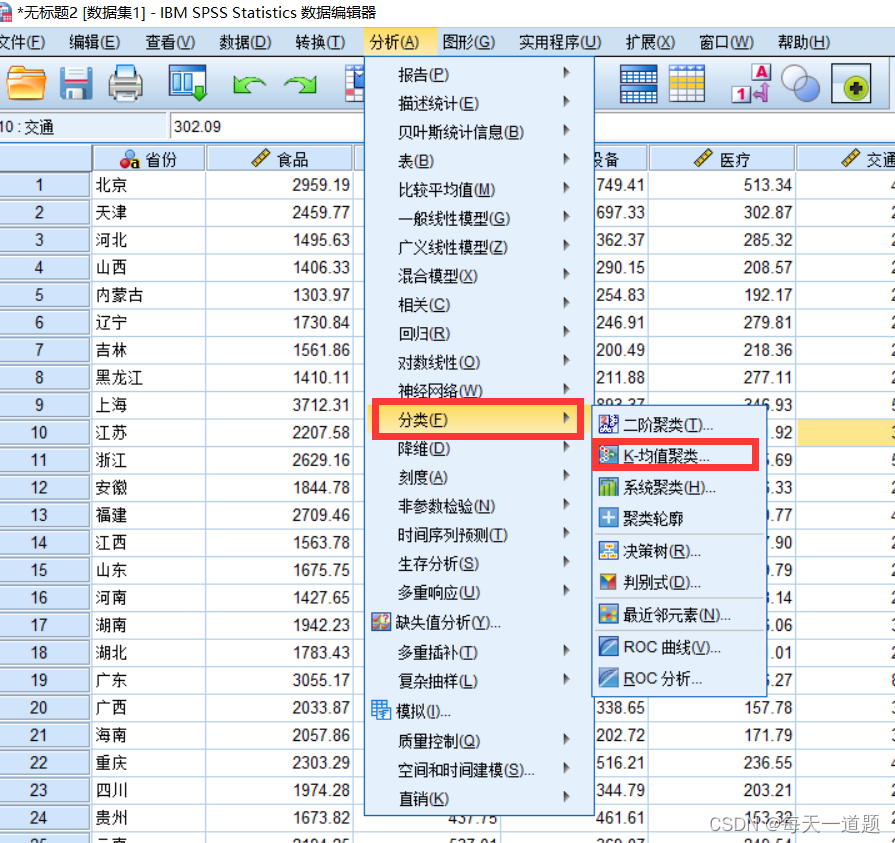
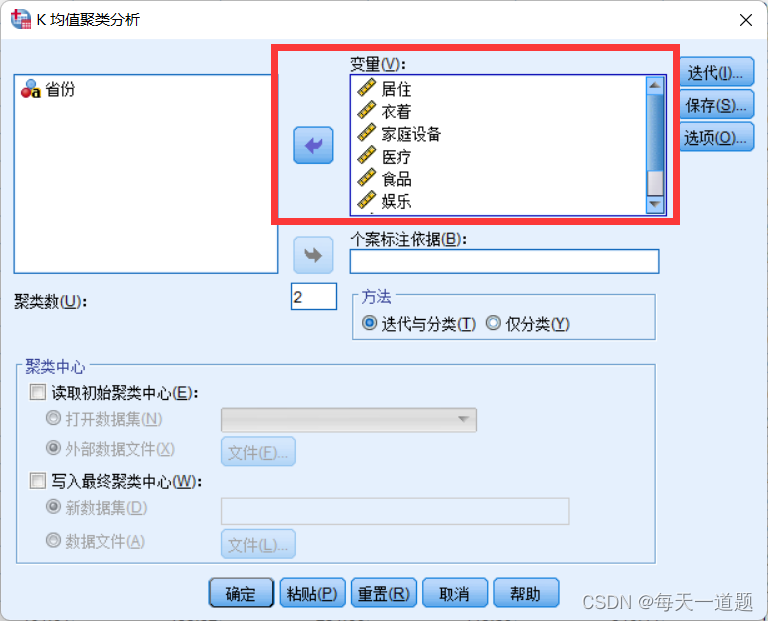
3.选择要聚类的目标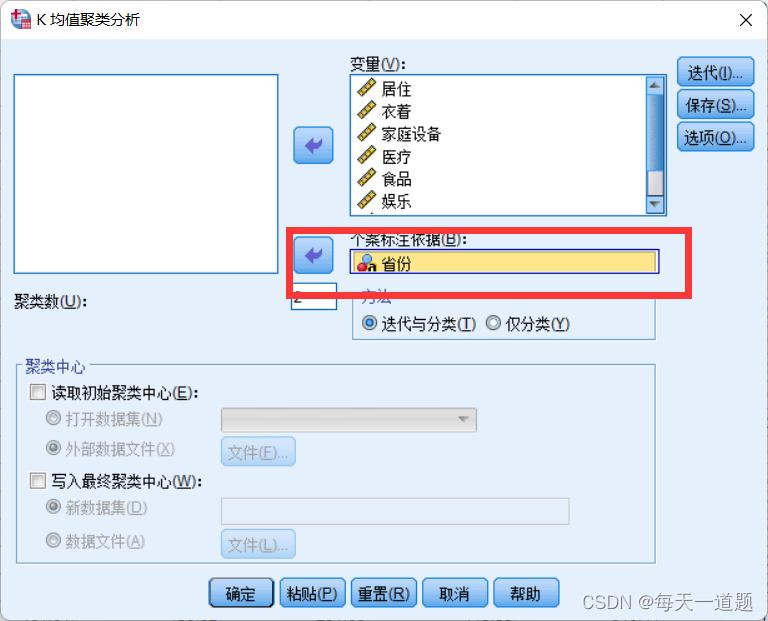
然后点确定即可。
本文转载自: https://blog.csdn.net/weixin_51711289/article/details/126088487
版权归原作者 每天一道题 所有, 如有侵权,请联系我们删除。
版权归原作者 每天一道题 所有, 如有侵权,请联系我们删除。