
Flink chcekpoint作为flink中最重要的部分,是flink精准一次性的重要保证,可以这么说flink之所以这么成功和她的checkpoint机制是离不开的。
之前大概学习了一下flink的checkpoint源码,但是还是有点晕乎乎的,甚至有点不理解我们作业中设置的checkpoint配置flink是如何读取到的,并且他是如何往下传播的。
1.代码中的checkpoint配置
这次我详细屡了一下,方便我们更好理解checkpoint,下面我们先看代码中我们一般是如何配置flink checkpoint的:
// TODO 1. 环境准备
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(4);
// TODO 2. 状态后端设置
env.enableCheckpointing(3000L, CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setCheckpointTimeout(30 * 1000L);
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(3000L);
env.getCheckpointConfig().enableExternalizedCheckpoints(
CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION
);
env.setRestartStrategy(RestartStrategies.failureRateRestart(
3, Time.days(1), Time.minutes(1)
));
env.setStateBackend(new HashMapStateBackend());
env.getCheckpointConfig().setCheckpointStorage(
"hdfs://hadoop102:8020/ck"
);
中间的业务代码省略
// TODO 3. 启动任务
env.execute();
在这里我们可以看到checkpoint的相关配置是调用streamExecutionEnvironment的各种方法配置,那我们代码中的checkpoint配置env肯定是拿到了
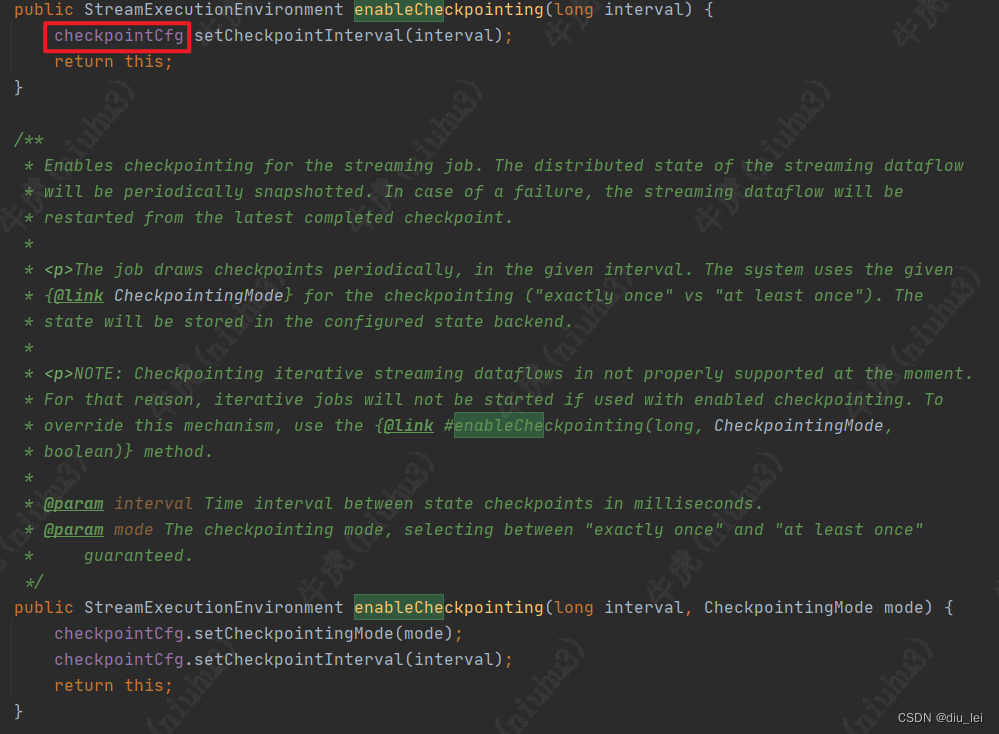
点进enableCheckpointing()方法中可以看到我们配置的checkpint相关参数被streamExecutionEnvironment的一个成员变量checkpointCfg获取到了
 所以下面我们只需要盯着这个checkpointCfg是怎么传到下面的就可以了,下面我们从作业的起点env.execute()方法往下走,下一步flink就要把我们的作业转换成streamGraph了
所以下面我们只需要盯着这个checkpointCfg是怎么传到下面的就可以了,下面我们从作业的起点env.execute()方法往下走,下一步flink就要把我们的作业转换成streamGraph了
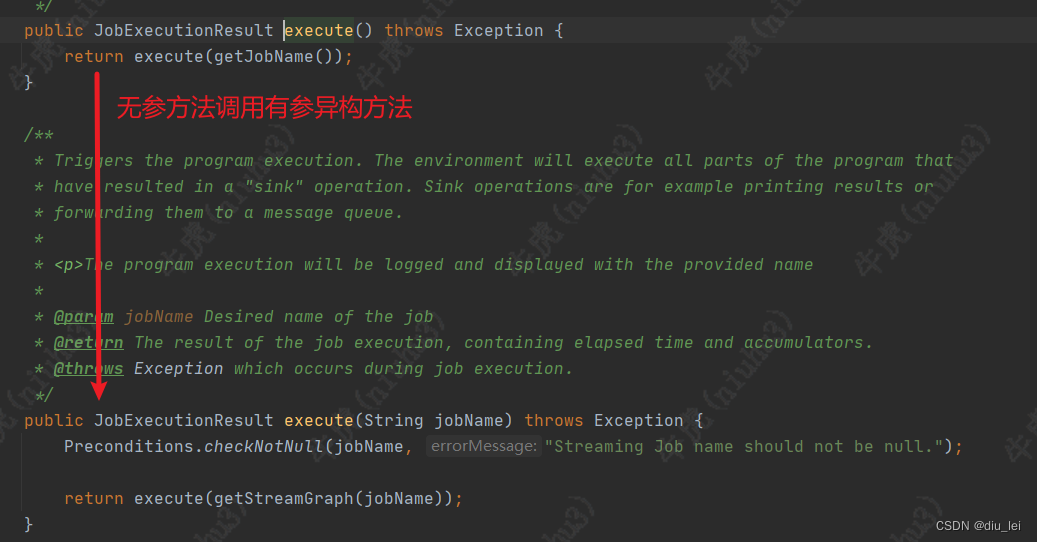 这个方法中调用了getStreamGraph方法,生成作业对应的streamGraph
这个方法中调用了getStreamGraph方法,生成作业对应的streamGraph
2.StreamGraph中的checkpoint配置
上一步我们看到了env.execute(jobName)方法,我们看到了他的方法中调用了getStreamGraph方法,这个方法就是生成StreamGraph的,从下面这个图中我们可以看到首先它利用了getStreamGraphGenerator生成StreamGraphGenerator,然后根据generator生成streamGraph

private StreamGraphGenerator getStreamGraphGenerator() {
if (transformations.size() <= 0) {
throw new IllegalStateException(
"No operators defined in streaming topology. Cannot execute.");
}
final RuntimeExecutionMode executionMode = configuration.get(ExecutionOptions.RUNTIME_MODE);
return new StreamGraphGenerator(transformations, config, checkpointCfg, getConfiguration())
.setRuntimeExecutionMode(executionMode) //设置执行模式,流式或者批处理
.setStateBackend(defaultStateBackend) //设置状态后端
.setSavepointDir(defaultSavepointDirectory) //设置checkpoint文件夹
.setChaining(isChainingEnabled) //是否开启chaining
.setUserArtifacts(cacheFile) //设置用户jar包
.setTimeCharacteristic(timeCharacteristic) //设置时间语义
.setDefaultBufferTimeout(bufferTimeout); //设置buffer超时时间
}
从这个方法体中我们可以看到checkpointCfg被当做参数传给了streamGraphGenerator,并且他还配置了checkpoint和状态后端的相关参数
public StreamGraph generate() {
//checkpointCfg和savepoint的配置被当做参数传给streamGraph
streamGraph = new StreamGraph(executionConfig, checkpointConfig, savepointRestoreSettings);
shouldExecuteInBatchMode = shouldExecuteInBatchMode(runtimeExecutionMode);
configureStreamGraph(streamGraph);
alreadyTransformed = new HashMap<>();
//转换算子,将env的成员变量transformations中的算子遍历出来,塞到streamGraph中
for (Transformation<?> transformation : transformations) {
transform(transformation);
}
for (StreamNode node : streamGraph.getStreamNodes()) {
if (node.getInEdges().stream().anyMatch(this::shouldDisableUnalignedCheckpointing)) {
for (StreamEdge edge : node.getInEdges()) {
edge.setSupportsUnalignedCheckpoints(false);
}
}
}
final StreamGraph builtStreamGraph = streamGraph;
alreadyTransformed.clear();
alreadyTransformed = null;
streamGraph = null;
return builtStreamGraph;
}
在streamGraphGenerator的generate()方法中我们可以看到checkpointCfg作为参数传给了streamGraph,这样streamGraph就拿到了我们的checkpoint配置了
3.JobGraph的checkpoint配置
下面我们先返回streamExecutionEnvironment的execute方法,下面我们要看的是在Jobgraph生产过程中,checkpoint配置是如何传递的,从env.execute()方法经过一系列的方法跳转,最终我们可以看到生成Jobgraph的方法是streamGraph.getJobGraph()

这个方法中调用 StreamingJobGraphGenerator.createJobGraph方法

这个方法中首先创建了一个StreamingJobGraphGenerator.,然后调用其createJobGraph方法
 然后我们详细看一下createJobGraph方法
然后我们详细看一下createJobGraph方法
private JobGraph createJobGraph() {
preValidate(); //预检查checkpoint是否开始等属性
jobGraph.setJobType(streamGraph.getJobType());
jobGraph.enableApproximateLocalRecovery(
streamGraph.getCheckpointConfig().isApproximateLocalRecoveryEnabled());
// Generate deterministic hashes for the nodes in order to identify them across
// submission iff they didn't change.
Map<Integer, byte[]> hashes =
defaultStreamGraphHasher.traverseStreamGraphAndGenerateHashes(streamGraph);
// Generate legacy version hashes for backwards compatibility
List<Map<Integer, byte[]>> legacyHashes = new ArrayList<>(legacyStreamGraphHashers.size());
for (StreamGraphHasher hasher : legacyStreamGraphHashers) {
legacyHashes.add(hasher.traverseStreamGraphAndGenerateHashes(streamGraph));
}
setChaining(hashes, legacyHashes);
setPhysicalEdges();
setSlotSharingAndCoLocation();
setManagedMemoryFraction(
Collections.unmodifiableMap(jobVertices),
Collections.unmodifiableMap(vertexConfigs),
Collections.unmodifiableMap(chainedConfigs),
id -> streamGraph.getStreamNode(id).getManagedMemoryOperatorScopeUseCaseWeights(),
id -> streamGraph.getStreamNode(id).getManagedMemorySlotScopeUseCases());
//配置checkpoint
configureCheckpointing();
//设置savepoint
jobGraph.setSavepointRestoreSettings(streamGraph.getSavepointRestoreSettings());
final Map<String, DistributedCache.DistributedCacheEntry> distributedCacheEntries =
JobGraphUtils.prepareUserArtifactEntries(
streamGraph.getUserArtifacts().stream()
.collect(Collectors.toMap(e -> e.f0, e -> e.f1)),
jobGraph.getJobID());
for (Map.Entry<String, DistributedCache.DistributedCacheEntry> entry :
distributedCacheEntries.entrySet()) {
jobGraph.addUserArtifact(entry.getKey(), entry.getValue());
}
// set the ExecutionConfig last when it has been finalized
try {
jobGraph.setExecutionConfig(streamGraph.getExecutionConfig());
} catch (IOException e) {
throw new IllegalConfigurationException(
"Could not serialize the ExecutionConfig."
+ "This indicates that non-serializable types (like custom serializers) were registered");
}
return jobGraph;
}
在preValidate方法中会检验是否开始了checkpoint,是否支持unalign checkpoint等,在configureCheckpointing()方法中才真正将streamGraph的checkpoint相关配置传给jobGraph
private void configureCheckpointing() {
CheckpointConfig cfg = streamGraph.getCheckpointConfig();
long interval = cfg.getCheckpointInterval();
if (interval < MINIMAL_CHECKPOINT_TIME) {
// interval of max value means disable periodic checkpoint
interval = Long.MAX_VALUE;
}
// --- configure options ---
CheckpointRetentionPolicy retentionAfterTermination;
if (cfg.isExternalizedCheckpointsEnabled()) {
CheckpointConfig.ExternalizedCheckpointCleanup cleanup =
cfg.getExternalizedCheckpointCleanup();
// Sanity check
if (cleanup == null) {
throw new IllegalStateException(
"Externalized checkpoints enabled, but no cleanup mode configured.");
}
retentionAfterTermination =
cleanup.deleteOnCancellation()
? CheckpointRetentionPolicy.RETAIN_ON_FAILURE
: CheckpointRetentionPolicy.RETAIN_ON_CANCELLATION;
} else {
retentionAfterTermination = CheckpointRetentionPolicy.NEVER_RETAIN_AFTER_TERMINATION;
}
// --- configure the master-side checkpoint hooks ---
final ArrayList<MasterTriggerRestoreHook.Factory> hooks = new ArrayList<>();
for (StreamNode node : streamGraph.getStreamNodes()) {
if (node.getOperatorFactory() instanceof UdfStreamOperatorFactory) {
Function f =
((UdfStreamOperatorFactory) node.getOperatorFactory()).getUserFunction();
if (f instanceof WithMasterCheckpointHook) {
hooks.add(
new FunctionMasterCheckpointHookFactory(
(WithMasterCheckpointHook<?>) f));
}
}
}
// because the hooks can have user-defined code, they need to be stored as
// eagerly serialized values
final SerializedValue<MasterTriggerRestoreHook.Factory[]> serializedHooks;
if (hooks.isEmpty()) {
serializedHooks = null;
} else {
try {
MasterTriggerRestoreHook.Factory[] asArray =
hooks.toArray(new MasterTriggerRestoreHook.Factory[hooks.size()]);
serializedHooks = new SerializedValue<>(asArray);
} catch (IOException e) {
throw new FlinkRuntimeException("Trigger/restore hook is not serializable", e);
}
}
// because the state backend can have user-defined code, it needs to be stored as
// eagerly serialized value
final SerializedValue<StateBackend> serializedStateBackend;
if (streamGraph.getStateBackend() == null) {
serializedStateBackend = null;
} else {
try {
serializedStateBackend =
new SerializedValue<StateBackend>(streamGraph.getStateBackend());
} catch (IOException e) {
throw new FlinkRuntimeException("State backend is not serializable", e);
}
}
// because the checkpoint storage can have user-defined code, it needs to be stored as
// eagerly serialized value
final SerializedValue<CheckpointStorage> serializedCheckpointStorage;
if (streamGraph.getCheckpointStorage() == null) {
serializedCheckpointStorage = null;
} else {
try {
serializedCheckpointStorage =
new SerializedValue<>(streamGraph.getCheckpointStorage());
} catch (IOException e) {
throw new FlinkRuntimeException("Checkpoint storage is not serializable", e);
}
}
// --- done, put it all together ---
创建一个JobCheckpointingSettings,用来封装checkpoint的相关配置
JobCheckpointingSettings settings =
new JobCheckpointingSettings(
CheckpointCoordinatorConfiguration.builder()
.setCheckpointInterval(interval)
.setCheckpointTimeout(cfg.getCheckpointTimeout())
.setMinPauseBetweenCheckpoints(cfg.getMinPauseBetweenCheckpoints())
.setMaxConcurrentCheckpoints(cfg.getMaxConcurrentCheckpoints())
.setCheckpointRetentionPolicy(retentionAfterTermination)
.setExactlyOnce(
getCheckpointingMode(cfg) == CheckpointingMode.EXACTLY_ONCE)
.setPreferCheckpointForRecovery(cfg.isPreferCheckpointForRecovery())
.setTolerableCheckpointFailureNumber(
cfg.getTolerableCheckpointFailureNumber())
.setUnalignedCheckpointsEnabled(cfg.isUnalignedCheckpointsEnabled())
.setAlignmentTimeout(cfg.getAlignmentTimeout().toMillis())
.build(),
serializedStateBackend,
serializedCheckpointStorage,
serializedHooks);
//将JobCheckpointingSettings传给JobGraph
jobGraph.setSnapshotSettings(settings);
}
在这个方法中会获取streamGraph的checkpointCfg,创建一个JobcheckpointSettings,并将streamGraph相关的checkpoint配置取出来放进JobcheckpointSettings,JobGraph中负责保存checkpoint相关配置的成员变量是snapshotSettings。
上述两个过程均是在客户端完成的,如果是yarn集群环境,JobGraph生成后,client会创建一个yarn-client用于提交作业,作业提交后,WebmonitorEndpoint的JobsubmitHandler会调用自己的handleRequest方法用于处理提交的作业。
4.ExecutionGraph的checkpoint配置
ExecutionGraph是在jobmaster启动的时候,将jobGraph转换成ExecutionGraph,由于jobmaster启动的过程比较繁琐,所以这边我们分析详细一点,从集群接收到客户端提交的jobGraph开始分析
1.handleRequest
这个方法中主要是获取client那边传过来的JobGraph,jar包和相关的依赖,然后调用dispatcherGateway.submitJob方法提交JobGraph
@Override
protected CompletableFuture<JobSubmitResponseBody> handleRequest(@Nonnull HandlerRequest<JobSubmitRequestBody, EmptyMessageParameters> request, @Nonnull DispatcherGateway gateway) throws RestHandlerException {
final Collection<File> uploadedFiles = request.getUploadedFiles();
final Map<String, Path> nameToFile = uploadedFiles.stream().collect(Collectors.toMap(
File::getName,
Path::fromLocalFile
));
if (uploadedFiles.size() != nameToFile.size()) {
throw new RestHandlerException(
String.format("The number of uploaded files was %s than the expected count. Expected: %s Actual %s",
uploadedFiles.size() < nameToFile.size() ? "lower" : "higher",
nameToFile.size(),
uploadedFiles.size()),
HttpResponseStatus.BAD_REQUEST
);
}
final JobSubmitRequestBody requestBody = request.getRequestBody();
if (requestBody.jobGraphFileName == null) {
throw new RestHandlerException(
String.format("The %s field must not be omitted or be null.",
JobSubmitRequestBody.FIELD_NAME_JOB_GRAPH),
HttpResponseStatus.BAD_REQUEST);
}
//加载Jobgraph
CompletableFuture<JobGraph> jobGraphFuture = loadJobGraph(requestBody, nameToFile);
//获取jar包
Collection<Path> jarFiles = getJarFilesToUpload(requestBody.jarFileNames, nameToFile);
//获取jar包相关的依赖
Collection<Tuple2<String, Path>> artifacts = getArtifactFilesToUpload(requestBody.artifactFileNames, nameToFile);
CompletableFuture<JobGraph> finalizedJobGraphFuture = uploadJobGraphFiles(gateway, jobGraphFuture, jarFiles, artifacts, configuration);
//调用dispatcherGateway的submitJob方法
CompletableFuture<Acknowledge> jobSubmissionFuture = finalizedJobGraphFuture.thenCompose(jobGraph -> gateway.submitJob(jobGraph, timeout));
return jobSubmissionFuture.thenCombine(jobGraphFuture,
(ack, jobGraph) -> new JobSubmitResponseBody("/jobs/" + jobGraph.getJobID()));
}
2.submitJob
dispatcherGateway.submitJob方法是一个抽象方法,他有两个实现Dispatcher和MiniDispatcher,miniDispatcher适用于本地调试调用,这里我们选择Dispatcher的submitJob方法,这个方法里对Jobgraph做了一些判断,jobID是否重复,是否是partialResource等,然后调用其internalSubmitJob方法
@Override
public CompletableFuture<Acknowledge> submitJob(JobGraph jobGraph, Time timeout) {
log.info("Received JobGraph submission {} ({}).", jobGraph.getJobID(), jobGraph.getName());
try {
if (isDuplicateJob(jobGraph.getJobID())) {
return FutureUtils.completedExceptionally(
new DuplicateJobSubmissionException(jobGraph.getJobID()));
} else if (isPartialResourceConfigured(jobGraph)) {
return FutureUtils.completedExceptionally(
new JobSubmissionException(jobGraph.getJobID(), "Currently jobs is not supported if parts of the vertices have " +
"resources configured. The limitation will be removed in future versions."));
} else {
return internalSubmitJob(jobGraph);
}
} catch (FlinkException e) {
return FutureUtils.completedExceptionally(e);
}
}
3.internalSubmitJob
这个方法中调用persistAndRunJob对Job进行持久化并运行,然后处理Job运行的结果
private CompletableFuture<Acknowledge> internalSubmitJob(JobGraph jobGraph) {
log.info("Submitting job {} ({}).", jobGraph.getJobID(), jobGraph.getName());
final CompletableFuture<Acknowledge> persistAndRunFuture = waitForTerminatingJob(jobGraph.getJobID(), jobGraph,
this::persistAndRunJob)
.thenApply(ignored -> Acknowledge.get());
return persistAndRunFuture.handleAsync((acknowledge, throwable) -> {
if (throwable != null) {
cleanUpJobData(jobGraph.getJobID(), true);
ClusterEntryPointExceptionUtils.tryEnrichClusterEntryPointError(throwable);
final Throwable strippedThrowable = ExceptionUtils.stripCompletionException(throwable);
log.error("Failed to submit job {}.", jobGraph.getJobID(), strippedThrowable);
throw new CompletionException(
new JobSubmissionException(jobGraph.getJobID(), "Failed to submit job.", strippedThrowable));
} else {
return acknowledge;
}
}, ioExecutor);
}
4.persistAndRunJob
这里的jobGraphWriter就是用来持久化jobGraph的,然后调用其runJob方法
private void persistAndRunJob(JobGraph jobGraph) throws Exception {
jobGraphWriter.putJobGraph(jobGraph);
runJob(jobGraph, ExecutionType.SUBMISSION);
}
5.runJob
这个方法中主要做了以下几件事:
1.调用createJobManagerRunner方法,创建并启动jobmaster
2.处理Job的运行结果
3.Job执行失败后,清理Job的执行状态文件,移除Job
private void runJob(JobGraph jobGraph, ExecutionType executionType) {
Preconditions.checkState(!runningJobs.containsKey(jobGraph.getJobID()));
long initializationTimestamp = System.currentTimeMillis();
/*TODO 创建并启动JobMaster*/
CompletableFuture<JobManagerRunner> jobManagerRunnerFuture = createJobManagerRunner(jobGraph, initializationTimestamp);
DispatcherJob dispatcherJob = DispatcherJob.createFor(
jobManagerRunnerFuture,
jobGraph.getJobID(),
jobGraph.getName(),
initializationTimestamp);
runningJobs.put(jobGraph.getJobID(), dispatcherJob);
final JobID jobId = jobGraph.getJobID();
//处理Job的运行结果
final CompletableFuture<CleanupJobState> cleanupJobStateFuture = dispatcherJob.getResultFuture().handleAsync(
(dispatcherJobResult, throwable) -> {
Preconditions.checkState(runningJobs.get(jobId) == dispatcherJob, "The job entry in runningJobs must be bound to the lifetime of the DispatcherJob.");
if (dispatcherJobResult != null) {
return handleDispatcherJobResult(jobId, dispatcherJobResult, executionType);
} else {
return dispatcherJobFailed(jobId, throwable);
}
}, getMainThreadExecutor());
//Job执行失败后,清理Job的执行状态文件,然后移除Job
final CompletableFuture<Void> jobTerminationFuture = cleanupJobStateFuture
.thenApply(cleanupJobState -> removeJob(jobId, cleanupJobState))
.thenCompose(Function.identity());
FutureUtils.assertNoException(jobTerminationFuture);
registerDispatcherJobTerminationFuture(jobId, jobTerminationFuture);
}
6.createJobManagerRunner
这个方法中调用了JobManagerFactory.createJobManagerRunner()创建jobmaster,然后调用start方法启动Jobmaster
CompletableFuture<JobManagerRunner> createJobManagerRunner(JobGraph jobGraph, long initializationTimestamp) {
final RpcService rpcService = getRpcService();
return CompletableFuture.supplyAsync(
() -> {
try {
/*TODO 创建JobMaster */
JobManagerRunner runner = jobManagerRunnerFactory.createJobManagerRunner(
jobGraph,
configuration,
rpcService,
highAvailabilityServices,
heartbeatServices,
jobManagerSharedServices,
new DefaultJobManagerJobMetricGroupFactory(jobManagerMetricGroup),
fatalErrorHandler,
initializationTimestamp);
/*TODO 启动JobMaster*/
runner.start();
return runner;
} catch (Exception e) {
throw new CompletionException(new JobInitializationException(jobGraph.getJobID(), "Could not instantiate JobManager.", e));
}
},
ioExecutor); // do not use main thread executor. Otherwise, Dispatcher is blocked on JobManager creation
}
7.ExecutionGraph的生成
jobmaster的启动还是比较麻烦的,中间有比较多的过程,这里我们省略中间一些不重要的过程
1.JobManagerFactory # createJobManagerRunner
2.DefaultJobManagerRunnerFactory # createJobManagerRunner
3.JobManagerRuunerImpl # JobManagerRuunerImpl
4.DefaultJobMasterServiceFactory # createJobMasterService
5.JobMaster # JobMaster ==> createScheduler
6.DefaultSchedulerFactory # createInstance
7.SchedulerBase # createAndRestoreExecutionGraph
在该方法中调用了createExecutionGraph创建executionGraph,并且还创建检查点协调器,负责该job检查点相关的工作
private ExecutionGraph createAndRestoreExecutionGraph(
JobManagerJobMetricGroup currentJobManagerJobMetricGroup,
ShuffleMaster<?> shuffleMaster,
JobMasterPartitionTracker partitionTracker,
ExecutionDeploymentTracker executionDeploymentTracker,
long initializationTimestamp) throws Exception {
ExecutionGraph newExecutionGraph = createExecutionGraph(currentJobManagerJobMetricGroup, shuffleMaster, partitionTracker, executionDeploymentTracker, initializationTimestamp);
final CheckpointCoordinator checkpointCoordinator = newExecutionGraph.getCheckpointCoordinator();
if (checkpointCoordinator != null) {
// check whether we find a valid checkpoint
if (!checkpointCoordinator.restoreInitialCheckpointIfPresent(
new HashSet<>(newExecutionGraph.getAllVertices().values()))) {
// check whether we can restore from a savepoint
tryRestoreExecutionGraphFromSavepoint(newExecutionGraph, jobGraph.getSavepointRestoreSettings());
}
}
return newExecutionGraph;
}
8.ExecutionGraph中checkpoint的配置
schedulerBase#createExecutionGraph: 内部调用了ExecutionGraphBuilder#buildGraph方法,
这个方法中做了很多checkpoint相关的事,比如:
1.获取jobgraph的checkpoint配置
2.创建checkpointIDCounter
3.获取状态后端
4.获取用户自定义的checkpoint钩子
5.将checkpoint的各种参数传入executionGraph
public static ExecutionGraph buildGraph(
@Nullable ExecutionGraph prior,
JobGraph jobGraph,
Configuration jobManagerConfig,
ScheduledExecutorService futureExecutor,
Executor ioExecutor,
SlotProvider slotProvider,
ClassLoader classLoader,
CheckpointRecoveryFactory recoveryFactory,
Time rpcTimeout,
RestartStrategy restartStrategy,
MetricGroup metrics,
BlobWriter blobWriter,
Time allocationTimeout,
Logger log,
ShuffleMaster<?> shuffleMaster,
JobMasterPartitionTracker partitionTracker,
FailoverStrategy.Factory failoverStrategyFactory,
ExecutionDeploymentListener executionDeploymentListener,
ExecutionStateUpdateListener executionStateUpdateListener,
long initializationTimestamp) throws JobExecutionException, JobException {
。。。。。。这部分省略不看。。。。。
// configure the state checkpointing
//获取jobGraph的checkpoint设置
JobCheckpointingSettings snapshotSettings = jobGraph.getCheckpointingSettings();
if (snapshotSettings != null) {
List<ExecutionJobVertex> triggerVertices =
idToVertex(snapshotSettings.getVerticesToTrigger(), executionGraph);
List<ExecutionJobVertex> ackVertices =
idToVertex(snapshotSettings.getVerticesToAcknowledge(), executionGraph);
List<ExecutionJobVertex> confirmVertices =
idToVertex(snapshotSettings.getVerticesToConfirm(), executionGraph);
CompletedCheckpointStore completedCheckpoints;
CheckpointIDCounter checkpointIdCounter;
try {
int maxNumberOfCheckpointsToRetain = jobManagerConfig.getInteger(
CheckpointingOptions.MAX_RETAINED_CHECKPOINTS);
if (maxNumberOfCheckpointsToRetain <= 0) {
// warning and use 1 as the default value if the setting in
// state.checkpoints.max-retained-checkpoints is not greater than 0.
log.warn("The setting for '{} : {}' is invalid. Using default value of {}",
CheckpointingOptions.MAX_RETAINED_CHECKPOINTS.key(),
maxNumberOfCheckpointsToRetain,
CheckpointingOptions.MAX_RETAINED_CHECKPOINTS.defaultValue());
maxNumberOfCheckpointsToRetain = CheckpointingOptions.MAX_RETAINED_CHECKPOINTS.defaultValue();
}
completedCheckpoints = recoveryFactory.createCheckpointStore(jobId, maxNumberOfCheckpointsToRetain, classLoader);
checkpointIdCounter = recoveryFactory.createCheckpointIDCounter(jobId);
}
catch (Exception e) {
throw new JobExecutionException(jobId, "Failed to initialize high-availability checkpoint handler", e);
}
// Maximum number of remembered checkpoints
int historySize = jobManagerConfig.getInteger(WebOptions.CHECKPOINTS_HISTORY_SIZE);
CheckpointStatsTracker checkpointStatsTracker = new CheckpointStatsTracker(
historySize,
ackVertices,
snapshotSettings.getCheckpointCoordinatorConfiguration(),
metrics);
// load the state backend from the application settings
final StateBackend applicationConfiguredBackend;
final SerializedValue<StateBackend> serializedAppConfigured = snapshotSettings.getDefaultStateBackend();
if (serializedAppConfigured == null) {
applicationConfiguredBackend = null;
}
else {
try {
applicationConfiguredBackend = serializedAppConfigured.deserializeValue(classLoader);
} catch (IOException | ClassNotFoundException e) {
throw new JobExecutionException(jobId,
"Could not deserialize application-defined state backend.", e);
}
}
//获取状态后端
final StateBackend rootBackend;
try {
rootBackend = StateBackendLoader.fromApplicationOrConfigOrDefault(
applicationConfiguredBackend, jobManagerConfig, classLoader, log);
}
catch (IllegalConfigurationException | IOException | DynamicCodeLoadingException e) {
throw new JobExecutionException(jobId, "Could not instantiate configured state backend", e);
}
// instantiate the user-defined checkpoint hooks
//初始化用户自定义的checkpoint 钩子
final SerializedValue<MasterTriggerRestoreHook.Factory[]> serializedHooks = snapshotSettings.getMasterHooks();
final List<MasterTriggerRestoreHook<?>> hooks;
if (serializedHooks == null) {
hooks = Collections.emptyList();
}
else {
final MasterTriggerRestoreHook.Factory[] hookFactories;
try {
hookFactories = serializedHooks.deserializeValue(classLoader);
}
catch (IOException | ClassNotFoundException e) {
throw new JobExecutionException(jobId, "Could not instantiate user-defined checkpoint hooks", e);
}
final Thread thread = Thread.currentThread();
final ClassLoader originalClassLoader = thread.getContextClassLoader();
thread.setContextClassLoader(classLoader);
try {
hooks = new ArrayList<>(hookFactories.length);
for (MasterTriggerRestoreHook.Factory factory : hookFactories) {
hooks.add(MasterHooks.wrapHook(factory.create(), classLoader));
}
}
finally {
thread.setContextClassLoader(originalClassLoader);
}
}
final CheckpointCoordinatorConfiguration chkConfig = snapshotSettings.getCheckpointCoordinatorConfiguration();
//将checkpoint的配置传入executionGraph
executionGraph.enableCheckpointing(
chkConfig,
triggerVertices,
ackVertices,
confirmVertices,
hooks,
checkpointIdCounter,
completedCheckpoints,
rootBackend,
checkpointStatsTracker);
}
// create all the metrics for the Execution Graph
metrics.gauge(RestartTimeGauge.METRIC_NAME, new RestartTimeGauge(executionGraph));
metrics.gauge(DownTimeGauge.METRIC_NAME, new DownTimeGauge(executionGraph));
metrics.gauge(UpTimeGauge.METRIC_NAME, new UpTimeGauge(executionGraph));
executionGraph.getFailoverStrategy().registerMetrics(metrics);
return executionGraph;
}
至此checkpoint的相关配置就传入了ExecutionGraph,并且还创建了checkpoint检查点来负责检查点相关的工作,后续就是jobmaster启动后会开启调度,然后给task分配资源,开始task的调度,在作业中实际的创建checkpoint。
版权归原作者 diu_lei 所有, 如有侵权,请联系我们删除。