
概述
Flink 是一个多功能框架,以混合搭配的方式支持许多不同的部署场景。
下图显示了每个 Flink 集群的构建块。
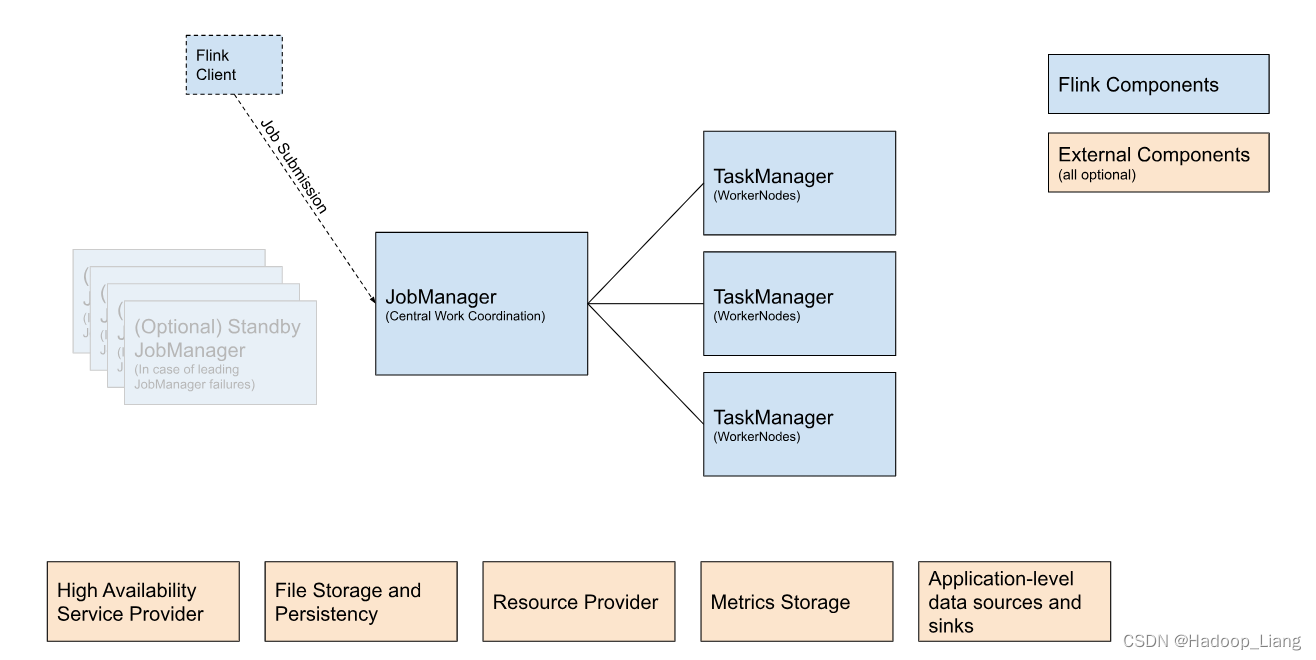
Flink客户端:它获取 Flink 应用程序的代码,将其转换为 JobGraph 并将其提交给 JobManager。
JobManager :是 Flink 中央工作协调组件的名称。它具有针对不同资源提供者的实现,这些实现在高可用性、资源分配行为和支持的作业提交模式方面有所不同。将工作分配到 TaskManager,其中运行实际操作符(例如sources, transformations 和 sinks)。
TaskManager: 是实际执行 Flink 作业工作的服务。
Flink作业提交的一般提交流程如下:

部署模式
在一些应用场景中,对于集群资源分配和占用的方式,可能会有特定的需求。Flink为各种场景提供了不同的部署模式,主要有以下三种:
- Application Mode(应用模式):专门为一个应用程序运行集群。作业的main方法在 JobManager 上执行。支持在应用程序中多次调用“execute”/“executeAsync”。
- Per-Job Mode(Per-Job 模式)(已弃用):专门为一项作业运行一个集群。作业的main方法在客户端运行。
- Session Mode(会话模式):一个 JobManager 实例管理同一 TaskManager 集群的多个作业。
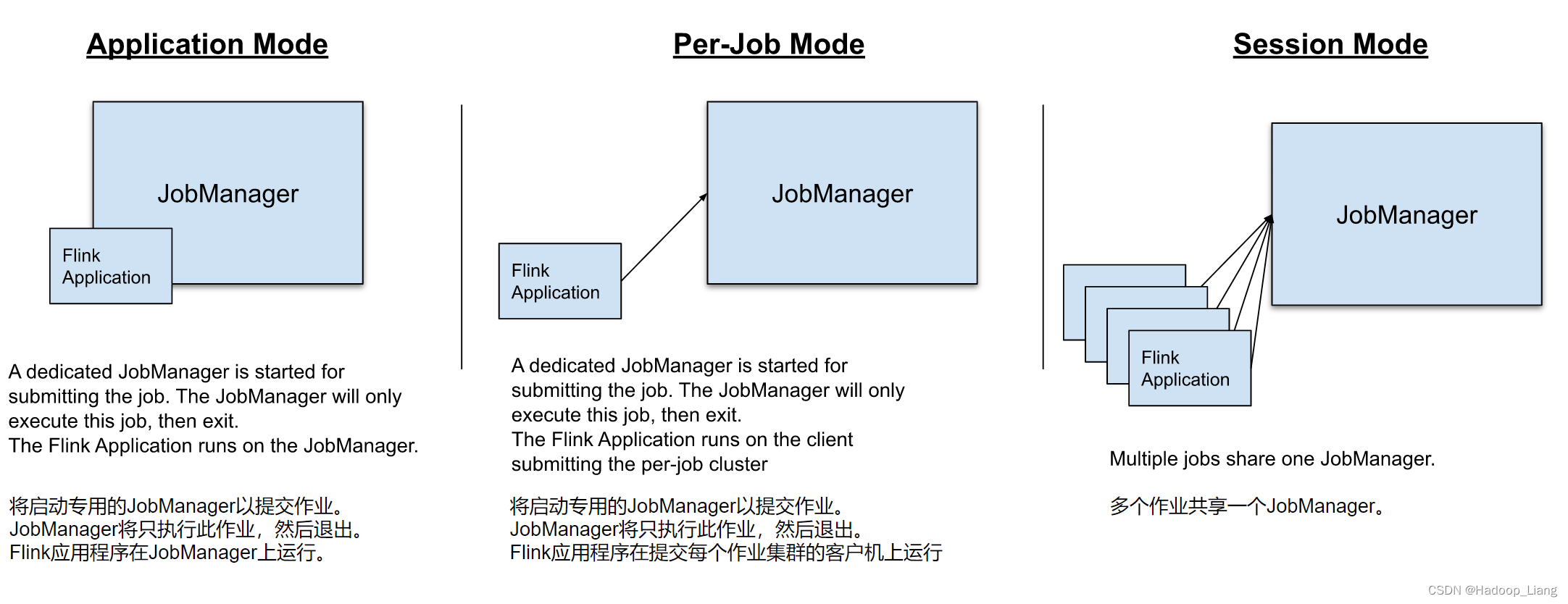
它们的区别主要在于:集群的生命周期以及资源的分配方式;以及应用的main方法到底在哪里执行——客户端(Client)还是JobManager。
会话模式(Session Mode)
会话模式:先启动一个集群,保持一个会话,通过客户端提交作业。集群启动时所有资源就都已经确定,所以所有提交的作业会竞争集群中的资源。
会话模式比较适合于单个规模小、执行时间短的大量作业。
单作业模式(Per-Job Mode)
会话模式因为资源共享会导致很多问题,所以为了更好地隔离资源,我们可以考虑为每个提交的作业启动一个集群,这就是所谓的单作业(Per-Job)模式。
作业完成后,集群就会关闭,所有资源也会释放。这些特性使得单作业模式在生产环境运行更加稳定,所以是实际应用的首选模式需要注意的是,Fink本身无法直接这样运行,所以单作业模式一般需要借助一些资源管理框架来启动集群,比如YARN、Kubernetes(K8S)。
应用模式(Application Mode)
前面提到的两种模式下,应用代码都是在客户端上执行,然后由客户端提交给JobManager的。但是这种方式客户端需要占用大量网络带宽,去下载依赖和把二进制数据发送给JobManager,加上很多情况下我们提交作业用的是同一个客户端,就会加重客户端所在节点的资源消耗。
所以应用模式的解决办法就是,直接把应用提交到JobManger上运行。我们需要为每一个提交的应用单独启动一个JobManager,也就是创建一个集群。这个JobManager只为执行这一个应用而存在,执行结束之后JobManager也就关闭了,这就是所谓的应用模式。
与 Per-Job(已弃用)模式相比,Application 模式允许提交包含多个作业的应用程序。作业执行的顺序不受部署模式的影响,而是受用于启动作业的调用的影响。使用阻塞的execute() 建立一个顺序,这将导致“下一个”作业的执行被推迟,直到“这个”作业完成。使用非阻塞的executeAsync()将导致“下一个”作业在“此”作业完成之前开始。
运行模式(资源管理模式)
在了解了Flink的三种部署模式后,运行Flink作业需要资源,按照运行时使用资源的不同可以分为有三种:Standalone运行模式、Yarn运行模式、K8S运行模式。每种运行模式中,可以有不同的部署模式。
Standalone运行模式
Standalone运行模式:使用Flink集群的资源来运行Flink作业。
三种部署模式中,Standalone运行模式支持会话模式部署和应用模式部署,不支持单作业模式部署。
会话模式部署
提前启动集群,并通过Web页面/flink run命令客户端提交任务(可以多个任务,但是集群资源固定)。
案例:使用会话模式运行一个flink作业,例如:自己编写的WordCount作业,可参考Flink WordCount实践
启动flink standalone集群
[hadoop@node2 ~]$ start-cluster.sh
在node2启动nc命令
[hadoop@node2 ~]$ nc -lk 7777
Web UI提交作业
(1)任务打包完成后,我们打开Flink的WEB UI页面,在右侧导航栏点击“Submit New Job”,然后点击按钮“+ Add New”,选择要上传运行的JAR包,如下图所示。

点击jar包名称,填写主类和并行度信息
主类:org.example.wc.SocketStreamWordCount
并行度:1

点击Submit提交作业

测试
在nc终端发送数据
[hadoop@node2 ~]$ nc -lk 7777
hello world
查看结果

命令行提交作业
命令执行
[hadoop@node2 ~]$ flink run -m node2:8081 -c org.example.wc.SocketStreamWordCount flinkdemo-1.0-SNAPSHOT.jar
测试
[hadoop@node2 ~]$ nc -lk 7777
hello flink
在node3的Task Manager中查看到结果

注意:计算的机器不固定是node3,也可能在其他机器上。
在node3上,命令行查看结果
[hadoop@node3 ~]$ cd $FLINK_HOME/
[hadoop@node3 flink-1.17.1]$ ls
bin conf examples lib LICENSE licenses log NOTICE opt plugins README.txt
[hadoop@node3 flink-1.17.1]$ cd log/
[hadoop@node3 log]$ ls
flink-hadoop-client-node2.log flink-hadoop-taskexecutor-0-node3.log.3
flink-hadoop-client-node3.log flink-hadoop-taskexecutor-0-node3.log.4
flink-hadoop-taskexecutor-0-node3.log flink-hadoop-taskexecutor-0-node3.log.5
flink-hadoop-taskexecutor-0-node3.log.1 flink-hadoop-taskexecutor-0-node3.out
flink-hadoop-taskexecutor-0-node3.log.2
[hadoop@node3 log]$ tail flink-hadoop-taskexecutor-0-node3.out
(hello,1)
(flink,1)
应用模式部署
应用模式下不会提前创建集群,所以不能调用start-cluster.sh脚本。我们可以standalone-job.sh来创建一个JobManager。
具体步骤如下:
(0)准备工作
如果之前开启了集群进程,先关闭之前开启的集群进程
[hadoop@node2 ~]$ stop-cluster.sh
如果之前没有开启集群进程,则不用关闭集群。
在node2中执行以下命令启动netcat。
[hadoop@node2 ~]$ nc -lk 7777
(1)进入到Flink的安装路径下,将应用程序的jar包放到lib/目录下。
[hadoop@node2 ~]$ mv flinkdemo-1.0-SNAPSHOT.jar $FLINK_HOME/lib/
(2)启动JobManager,并指定作业入口。
[hadoop@node2 ~]$ standalone-job.sh start --job-classname org.example.wc.SocketStreamWordCount
Starting standalonejob daemon on host node2.
这里我们直接指定作业入口类,脚本会到lib目录扫描所有的jar包。
查看进程,看到JobManager已经启动
[hadoop@node2 ~]$ jps
5061 StandaloneApplicationClusterEntryPoint
5095 Jps
(3)启动TaskManager
[hadoop@node2 ~]$ taskmanager.sh start
Starting taskexecutor daemon on host node2.
[hadoop@node2 ~]$ jps
5457 Jps
5061 StandaloneApplicationClusterEntryPoint
5429 TaskManagerRunner
[hadoop@node3 log]$ taskmanager.sh start
Starting taskexecutor daemon on host node3.
[hadoop@node3 log]$ jps
3105 TaskManagerRunner
3175 Jps
[hadoop@node4 log]$ taskmanager.sh start
Starting taskexecutor daemon on host node4.
[hadoop@node4 log]$ jps
2708 Jps
2637 TaskManagerRunner
注意:这里在集群里所有机器(node2、node3、node4)都启动TaskManager,也可以按需启动特定的机器作为TaskManager。
(4)发送单词数据
[hadoop@node2 ~]$ nc -lk 7777
hello hadoop
(5)在node2:8081查看结果

Yarn运行模式
使用YARN资源来运行Flink作业。
YARN上部署的过程是:客户端把Flink应用提交给YARN的ResourceManager,Yarn的ResourceManager根据需要分配Yarn的NodeManager上容器。在这些容器上,Flink会部署JobManager和TaskManager的实例。Flink会根据运行在JobManger上的作业所需要的Slot数量动态分配TaskManager资源。
三种部署模式中,YARN运行模式均支持。
(1)配置环境变量,增加环境变量配置如下:
[hadoop@node2 ~]$ sudo vim /etc/profile.d/my_env.sh
添加如下内容
#FLINK YARN MODE NEED USE HADOOP CONF
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_CLASSPATH=`hadoop classpath`
让环境变量生效
[hadoop@node2 ~]$ source /etc/profile
注意:如果只在node2提交作业,只需要在node2上执行,不用分发到其他机器上(如果需要在其他机器操作,也需要设置。)。`符号表示在shell里执行命令。
(2)启动Hadoop集群,包括HDFS和YARN。
[hadoop@node2 ~]$ start-dfs.sh
[hadoop@node3 ~]$ start-yarn.sh
(3)在node2中执行以下命令启动netcat。
[hadoop@node2 ~]$ nc -lk 7777
会话模式部署
YARN的会话模式与独立集群略有不同,需要首先申请一个YARN会话(YARN Session)来启动Flink集群。
YARN Session模式作业提交流程如下:
查看命令帮助
[hadoop@node2 ~]$ yarn-session.sh --help
...
省略若干日志信息输出
...
Usage:
Optional
-at,--applicationType <arg> Set a custom application type for the application on YARN
-D <property=value> use value for given property
-d,--detached If present, runs the job in detached mode
-h,--help Help for the Yarn session CLI.
-id,--applicationId <arg> Attach to running YARN session
-j,--jar <arg> Path to Flink jar file
-jm,--jobManagerMemory <arg> Memory for JobManager Container with optional unit (default: MB)
-m,--jobmanager <arg> Set to yarn-cluster to use YARN execution mode.
-nl,--nodeLabel <arg> Specify YARN node label for the YARN application
-nm,--name <arg> Set a custom name for the application on YARN
-q,--query Display available YARN resources (memory, cores)
-qu,--queue <arg> Specify YARN queue.
-s,--slots <arg> Number of slots per TaskManager
-t,--ship <arg> Ship files in the specified directory (t for transfer)
-tm,--taskManagerMemory <arg> Memory per TaskManager Container with optional unit (default: MB)
-yd,--yarndetached If present, runs the job in detached mode (deprecated; use non-YARN specific option instead)
-z,--zookeeperNamespace <arg> Namespace to create the Zookeeper sub-paths for high availability mode
常用参数解读:
- -d:分离模式,如果你不想让Flink YARN客户端一直前台运行,可以使用这个参数,即使关掉当前对话窗口,YARN session也可以后台运行。
- -jm(--jobManagerMemory):配置JobManager所需内存,默认单位MB。
- -nm(--name):配置在YARN UI界面上显示的任务名。
- -qu(--queue):指定YARN队列名。
- -tm(--taskManager):配置每个TaskManager所使用内存。
启动一个YARN session
[hadoop@node2 ~]$ yarn-session.sh -nm test
...
省略部分日志输出
...
2024-04-16 17:49:09,244 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface node3:37102 of application 'application_1713260243932_0002'.
JobManager Web Interface: http://node3:37102
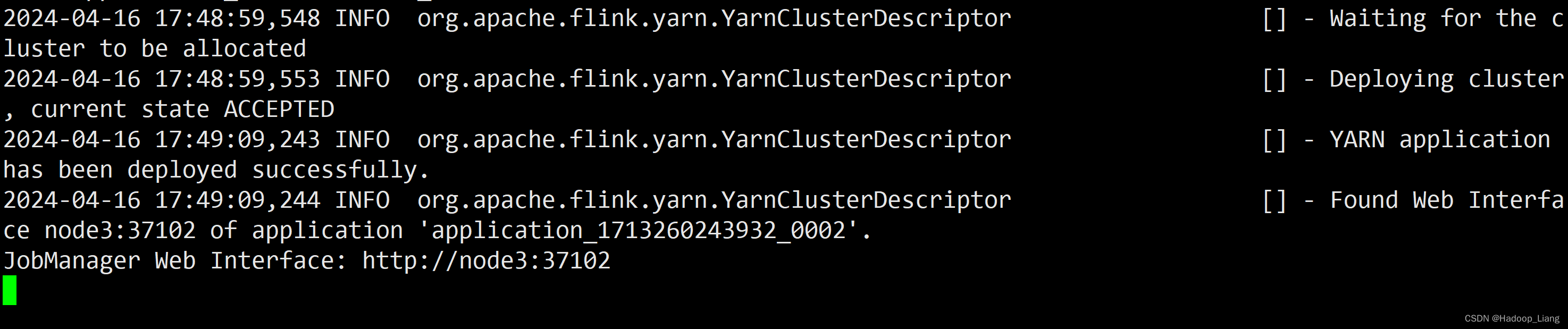
可以看到:YARN Session启动之后会给出一个YARN application ID以及一个Web UI地址(http://node3:37102),Web UI地址是随机的,每次启动Session的Web UI地址也可能不一样。
注意:flink1.17的YARN模式,会自动覆盖之前standalone集群的配置。所以node3也可以作为master节点。
浏览器访问Web UI
node3:37102

通过Web UI提交作业
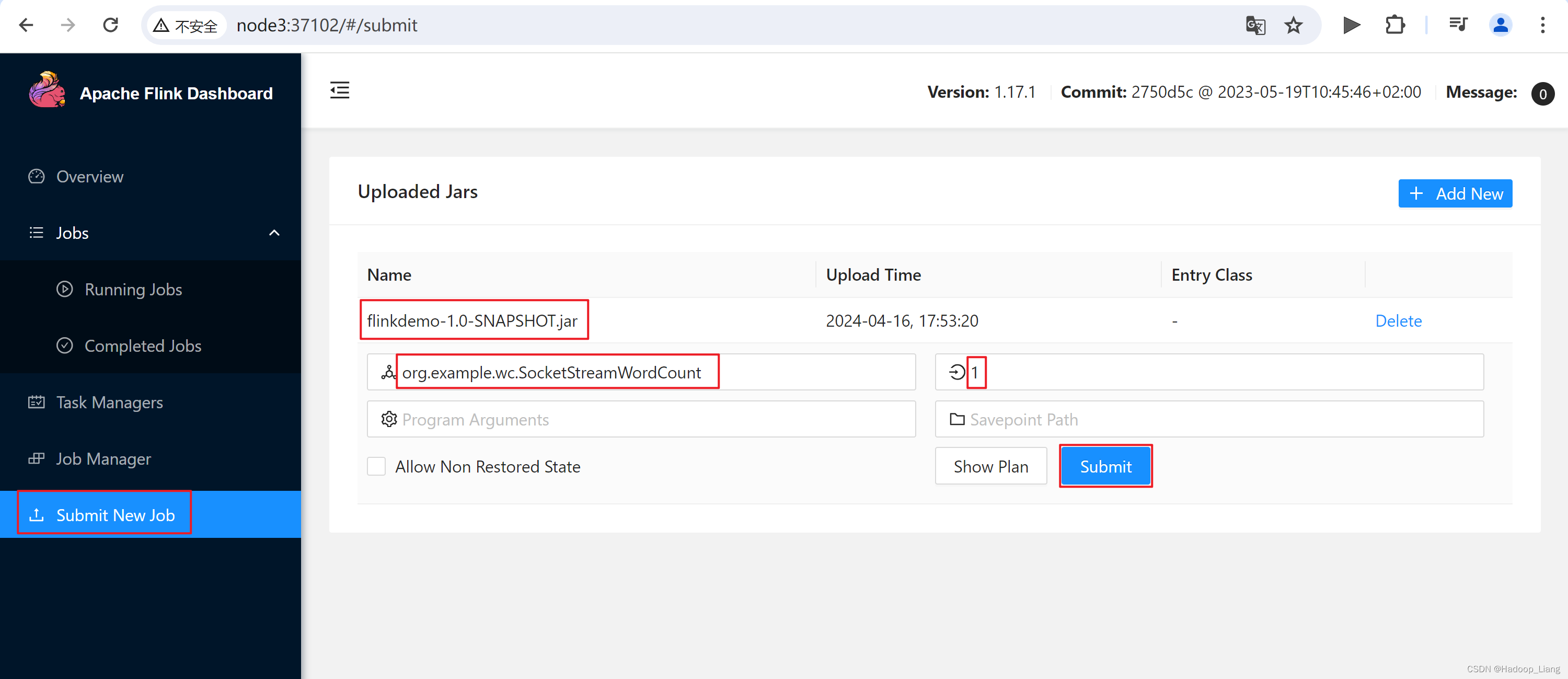
测试
nc发送数据

Web UI查看结果

8088端口查看作业

也可以点击Tracking UI的ApplicationMaster进入Flink Web UI界面
取消作业

通过命令行提交作业
启动yarn-session
[hadoop@node2 ~]$ yarn-session.sh -nm test
...
省略部分输出
...
2024-04-16 20:30:50,602 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface node2:37680 of application 'application_1713270240854_0001'.
JobManager Web Interface: http://node2:37680
查看Web UI

此时还没有可用的Task Managers和Task Slots
将Flink作业jar包上传到node3

将该任务提交到已经开启的Yarn-Session中运行。
[hadoop@node3 ~]$ flink run -c org.example.wc.SocketStreamWordCount -m node2:37680 flinkdemo-1.0-SNAPSHOT.jar

提交作业后,Task Managers 变为1,Total Task Slots也为1

查看正在运行的作业

测试
发送数据
[hadoop@node2 ~]$ nc -lk 7777
hello flink
hello hadoop
刷新结果

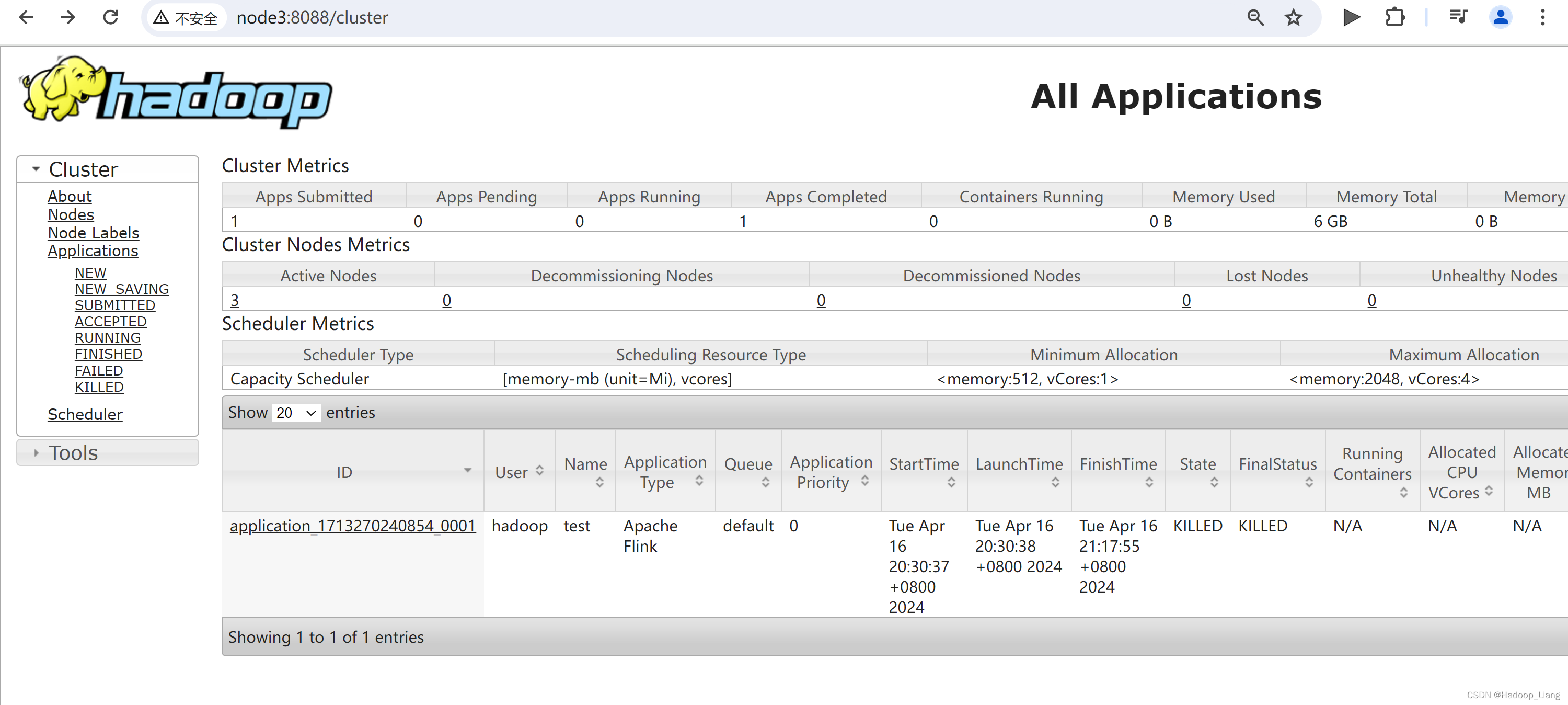
任务提交成功后,可在YARN的Web UI界面查看运行情况。
node3:8088


Web UI查看结果

可以看到,通过8088同样也可以查看到Flink的Web UI,并能查看到作业的运行情况。
查看日志

命令查看日志
[hadoop@node3 ~]$ yarn logs -applicationId application_1713270240854_0001
[hadoop@node3 ~]$ yarn logs -applicationId application_1713270240854_0001 | tail
[hadoop@node3 ~]$ yarn logs -applicationId application_1713270240854_0001 | less
停止session



退回查看应用状态
改成是kill掉session,使用命令停止session更加优雅。
重新开启一个session会话
[hadoop@node2 ~]$ yarn-session.sh -nm test -d
...
2024-04-16 21:25:21,517 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface node2:36883 of application 'application_1713270240854_0002'.
JobManager Web Interface: http://node2:36883
2024-04-16 21:25:21,973 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - The Flink YARN session cluster has been started in detached mode. In order to stop Flink gracefully, use the following command:
$ echo "stop" | ./bin/yarn-session.sh -id application_1713270240854_0002
If this should not be possible, then you can also kill Flink via YARN's web interface or via:
$ yarn application -kill application_1713270240854_0002
Note that killing Flink might not clean up all job artifacts and temporary files.
[hadoop@node2 ~]$
输出日志中看到,优雅地停止flink session的命令是
echo "stop" | ./bin/yarn-session.sh -id application_1713270240854_0002
查看8088端口,多了一个应用
application_1713270240854_0002

优雅地停止flink应用
[hadoop@node2 ~]$ echo "stop" | yarn-session.sh -id application_1713270240854_0002
...
2024-04-16 21:31:48,210 INFO org.apache.hadoop.yarn.client.RMProxy [] - Connecting to ResourceManager at node3/192.168.193.143:8032
2024-04-16 21:31:48,644 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface node2:36883 of application 'application_1713270240854_0002'.
2024-04-16 21:31:49,765 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - Deleted Yarn properties file at /tmp/.yarn-properties-hadoop
2024-04-16 21:31:49,769 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - Application application_1713270240854_0002 finished with state FINISHED and final state SUCCEEDED at 1713274309726
查看作业State为FINISHED,FinalStatus为SUCCEEDED

单作业模式部署
在YARN环境中,由于有了外部平台做资源调度,所以我们也可以直接向YARN提交一个单独的作业,从而启动一个Flink集群。

(1)执行命令提交作业。
在node3提交作业
[hadoop@node3 ~]$ flink run -d -t yarn-per-job -c org.example.wc.SocketStreamWordCount flinkdemo-1.0-SNAPSHOT.jar
------------------------------------------------------------
The program finished with the following exception:
org.apache.flink.client.program.ProgramInvocationException: The main method caused an error: No Executor found. Please make sure to export the HADOOP_CLASSPATH environment variable or have hadoop in your classpath. For more information refer to the "Deployment" section of the official Apache Flink documentation.
at org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:372)
at org.apache.flink.client.program.PackagedProgram.invokeInteractiveModeForExecution(PackagedProgram.java:222)
at org.apache.flink.client.ClientUtils.executeProgram(ClientUtils.java:105)
at org.apache.flink.client.cli.CliFrontend.executeProgram(CliFrontend.java:851)
at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:245)
at org.apache.flink.client.cli.CliFrontend.parseAndRun(CliFrontend.java:1095)
at org.apache.flink.client.cli.CliFrontend.lambda$mainInternal$9(CliFrontend.java:1189)
at org.apache.flink.runtime.security.contexts.NoOpSecurityContext.runSecured(NoOpSecurityContext.java:28)
at org.apache.flink.client.cli.CliFrontend.mainInternal(CliFrontend.java:1189)
at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:1157)
Caused by: java.lang.IllegalStateException: No Executor found. Please make sure to export the HADOOP_CLASSPATH environment variable or have hadoop in your classpath. For more information refer to the "Deployment" section of the official Apache Flink documentation.
因为,此前只在node2设置了环境变量,所以哪台需要以单作业运行,需要设置hadoop相关环境变量。
设置hadoop classpath环境变量后
再次执行
[hadoop@node3 ~]$ flink run -d -t yarn-per-job -c org.example.wc.SocketStreamWordCount flinkdemo-1.0-SNAPSHOT.jar
报错如下
2024-04-16 21:53:16,364 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface node2:42969 of application 'application_1713270240854_0003'.
Job has been submitted with JobID 2da4916c92fe28098976286b72700f6c
Exception in thread "Thread-5" java.lang.IllegalStateException: Trying to access closed classloader. Please check if you store classloaders directly or indirectly in static fields. If the stacktrace suggests that the leak occurs in a third party library and cannot be fixed immediately, you can disable this check with the configuration 'classloader.check-leaked-classloader'.
at org.apache.flink.util.FlinkUserCodeClassLoaders$SafetyNetWrapperClassLoader.ensureInner(FlinkUserCodeClassLoaders.java:184)
at org.apache.flink.util.FlinkUserCodeClassLoaders$SafetyNetWrapperClassLoader.getResource(FlinkUserCodeClassLoaders.java:208)
解决方式:
方法1.配置文件
flink-conf.yaml
添加如下配置,并分发到其他机器。
classloader.check-leaked-classloader: false
方法2.命令行设置
-Dclassloader.check-leaked-classloader=false
这里采用方法2解决。
[hadoop@node3 ~]$ flink run -d -t yarn-per-job -c org.example.wc.SocketStreamWordCount -Dclassloader.check-leaked-classloader=false flinkdemo-1.0-SNAPSHOT.jar
...省略部分输出...
2024-04-16 21:58:45,827 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Cannot use kerberos delegation token manager, no valid kerberos credentials provided.
2024-04-16 21:58:45,845 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Submitting application master application_1713270240854_0004
2024-04-16 21:58:45,908 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl [] - Submitted application application_1713270240854_0004
2024-04-16 21:58:45,909 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Waiting for the cluster to be allocated
2024-04-16 21:58:45,911 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Deploying cluster, current state ACCEPTED
2024-04-16 21:58:54,017 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - YARN application has been deployed successfully.
2024-04-16 21:58:54,018 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - The Flink YARN session cluster has been started in detached mode. In order to stop Flink gracefully, use the following command:
$ echo "stop" | ./bin/yarn-session.sh -id application_1713270240854_0004
If this should not be possible, then you can also kill Flink via YARN's web interface or via:
$ yarn application -kill application_1713270240854_0004
Note that killing Flink might not clean up all job artifacts and temporary files.
2024-04-16 21:58:54,019 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface node4:44661 of application 'application_1713270240854_0004'.
Job has been submitted with JobID ef5ff58d20e6acc616eeb4a2c32352e5
[hadoop@node3 ~]$

点击ApplicationMaster跳到Web UI界面,这里003作业可以跳过去,003和004都在跑,资源不够。停掉003和004,然后,重新启动per-job作业,此时作业ID为005
点击跳转到Flink Web UI界面如下
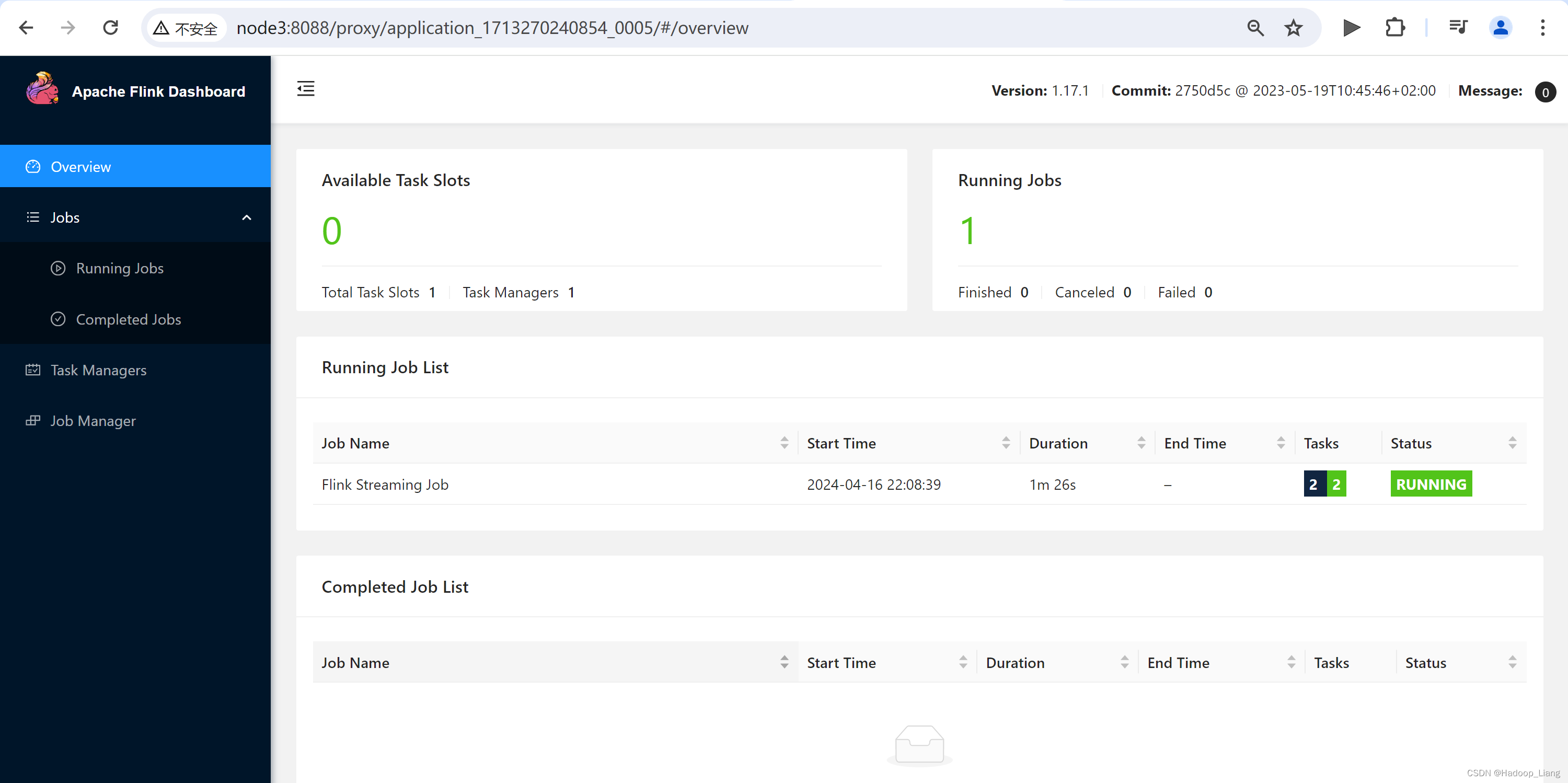
测试
nc发送数据,例如:hello java
查看Web UI结果

可以使用命令行查看或取消作业
查看作业命令:
[hadoop@node3 ~]$ flink list -t yarn-per-job -Dyarn.application.id=application_1713270240854_0005

取消作业命令格式:
flink cancel -t yarn-per-job -Dyarn.application.id=application_xxxx_yy <jobId>
这里的application_XXXX_YY是当前应用的ID,<jobId>是作业的ID。注意如果取消作业,整个Flink集群也会停掉。
具体命令如下:
flink cancel -t yarn-per-job -Dyarn.application.id=application_1713270240854_0005 5ca1a56ec0b15b0a3f5990438dde8430

查看8088端口
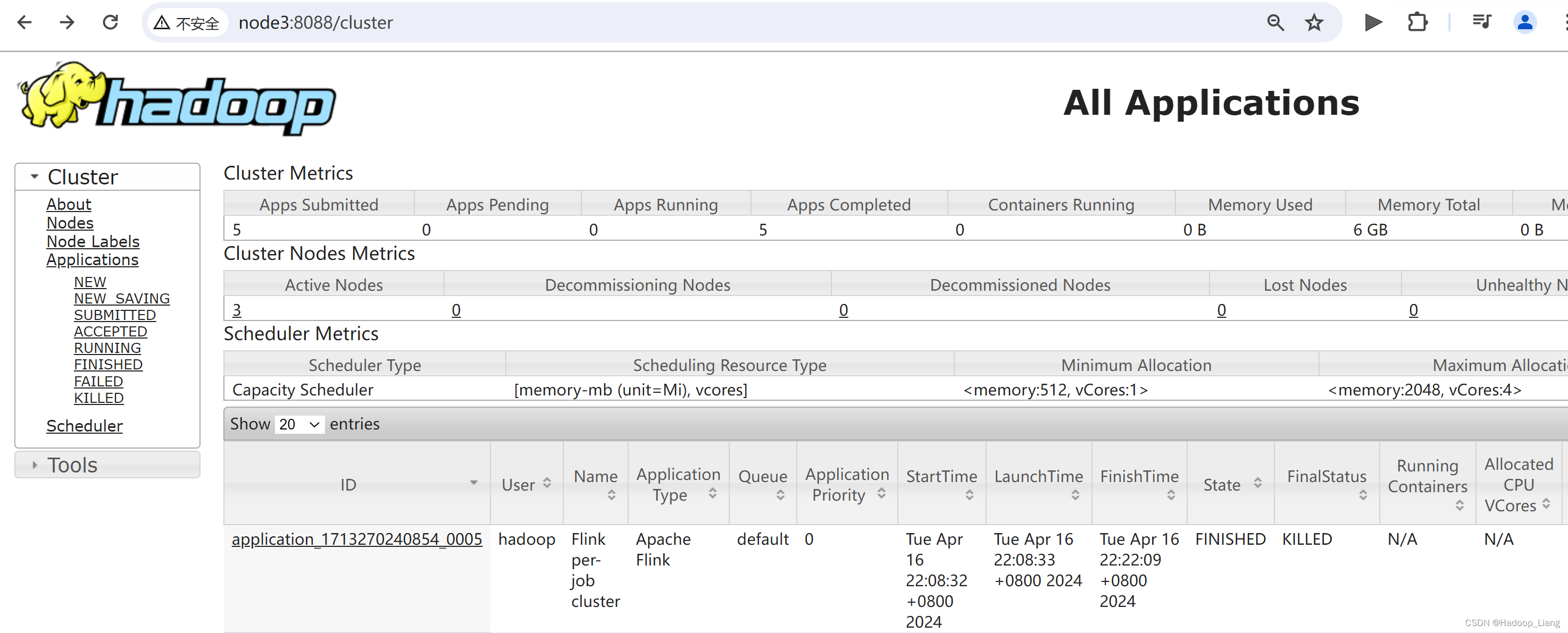
应用模式部署
应用模式部署,允许main()方法在JobManager上执行,这样可以分担Client的压力。
应用模式与单作业模式类似,直接执行flink run-application命令即可。
per-job模式命令
flink run -d -t yarn-per-job -c org.example.wc.SocketStreamWordCount -Dclassloader.check-leaked-classloader=false flinkdemo-1.0-SNAPSHOT.jar
应用模式命令
flink run-application -d -t yarn-application -c org.example.wc.SocketStreamWordCount -Dclassloader.check-leaked-classloader=false flinkdemo-1.0-SNAPSHOT.jar
区别:
1.per-job是run,应用模式是run-application
2.per-job -t是yarn-per-job,应用模式 -t是yarn-application
执行应用模式
[hadoop@node3 ~]$ flink run-application -d -t yarn-application -c org.example.wc.SocketStreamWordCount -Dclassloader.check-leaked-classloader=false flinkdemo-1.0-SNAPSHOT.jar
部分日志如下
测试
nc发送数据
hello flink
查看结果


查看或取消作业命令格式
$ flink list -t yarn-application -Dyarn.application.id=application_XXXX_YY
$ flink cancel -t yarn-application -Dyarn.application.id=application_XXXX_YY <jobId>
查看作业
[hadoop@node3 ~]$ flink list -t yarn-application -Dyarn.application.id=application_1713270240854_0006

取消作业
[hadoop@node3 ~]$ flink cancel -t yarn-application -Dyarn.application.id=application_1713270240854_0006 c09dd8a76391a1264d3b33fec7f80266

优化
把作业需要用到的依赖、插件等资源提前上传到HDFS,作业需要的资源直接从HDFS获取。
可以通过yarn.provided.lib.dirs配置选项指定位置,将flink的依赖上传到远程。
(1)上传flink的lib和plugins到HDFS上
[hadoop@node3 ~]$ hadoop fs -mkdir /flink-dist
[hadoop@node3 ~]$ hadoop fs -put $FLINK_HOME/lib/ /flink-dist
[hadoop@node3 ~]$ hadoop fs -put $FLINK_HOME/plugins/ /flink-dist
[hadoop@node3 ~]$ hdfs dfs -ls /flink-dist
Found 2 items
drwxr-xr-x - hadoop supergroup 0 2024-04-16 22:54 /flink-dist/lib
drwxr-xr-x - hadoop supergroup 0 2024-04-16 22:54 /flink-dist/plugins
[hadoop@node3 ~]$
put操作提示
2024-04-16 22:54:59,200 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
不用管这个提示信息。
(2)上传Flink作业jar包到HDFS
[hadoop@node3 ~]$ hadoop fs -mkdir /flink-jars
[hadoop@node3 ~]$ hadoop fs -put flinkdemo-1.0-SNAPSHOT.jar /flink-jars
(3)提交作业
[hadoop@node3 ~]$ flink run-application -t yarn-application -Dyarn.provided.lib.dirs="hdfs://node2:9820/flink-dist" -c org.example.wc.SocketStreamWordCount hdfs://node2:9820/flink-jars/flinkdemo-1.0-SNAPSHOT.jar
这种方式下,Flink本身的依赖和用户jar可以预先上传到HDFS,而不需要单独发送到集群,这就使得作业提交更加轻量了。

测试
nc发送数据
hello flink
查看结果


查看作业
[hadoop@node3 ~]$ flink list -t yarn-application -Dyarn.application.id=application_1713270240854_0008

取消作业
[hadoop@node3 ~]$ flink cancel -t yarn-application -Dyarn.application.id=application_1713270240854_0008 5656744f88b9384620d93d178859d047


K8S运行模式(了解)
使用K8S资源来运行Flink作业。
容器化部署是如今业界流行的一项技术,基于Docker镜像运行能够让用户更加方便地对应用进行管理和运维。容器管理工具中最为流行的就是Kubernetes(K8S),基本原理与YARN是类似的,具体配置可以参见官网说明,这里我们就不做过多讲解了。
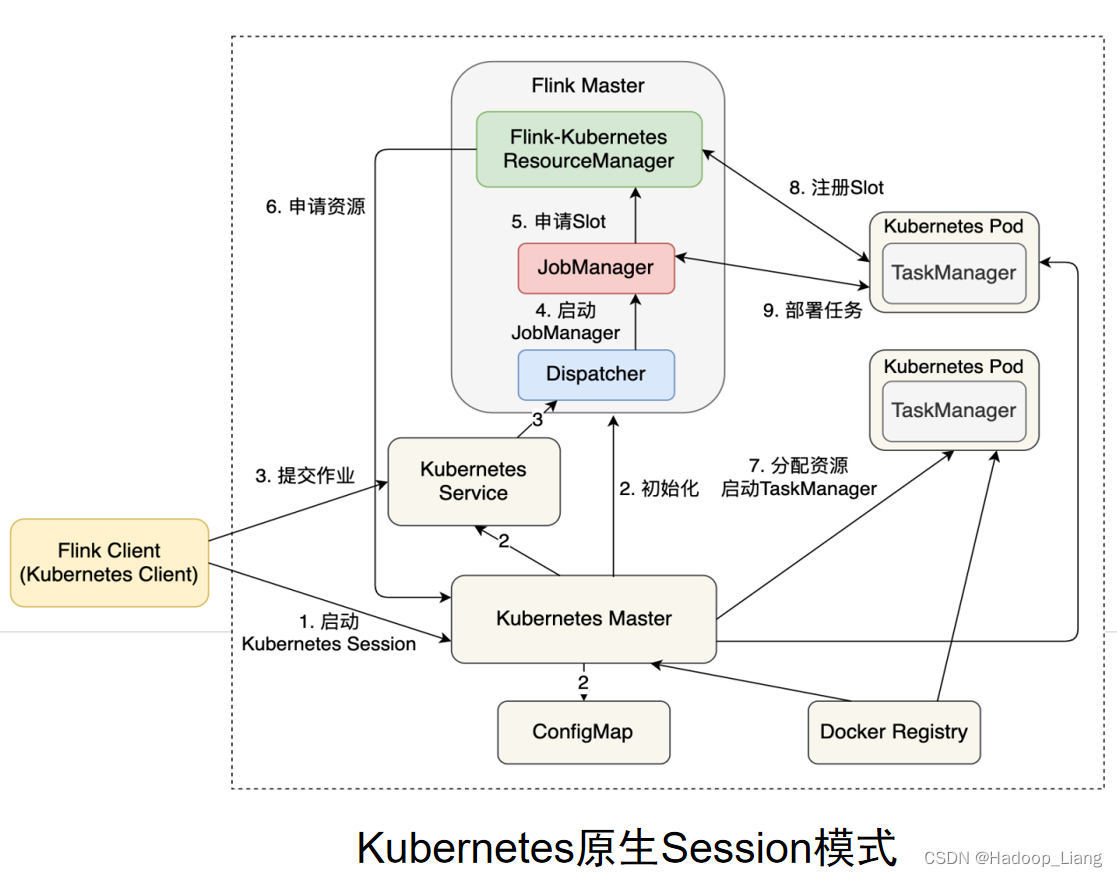
K8S原生Session模式作业提交流程如下:
完成!enjoy it!
版权归原作者 Hadoop_Liang 所有, 如有侵权,请联系我们删除。