
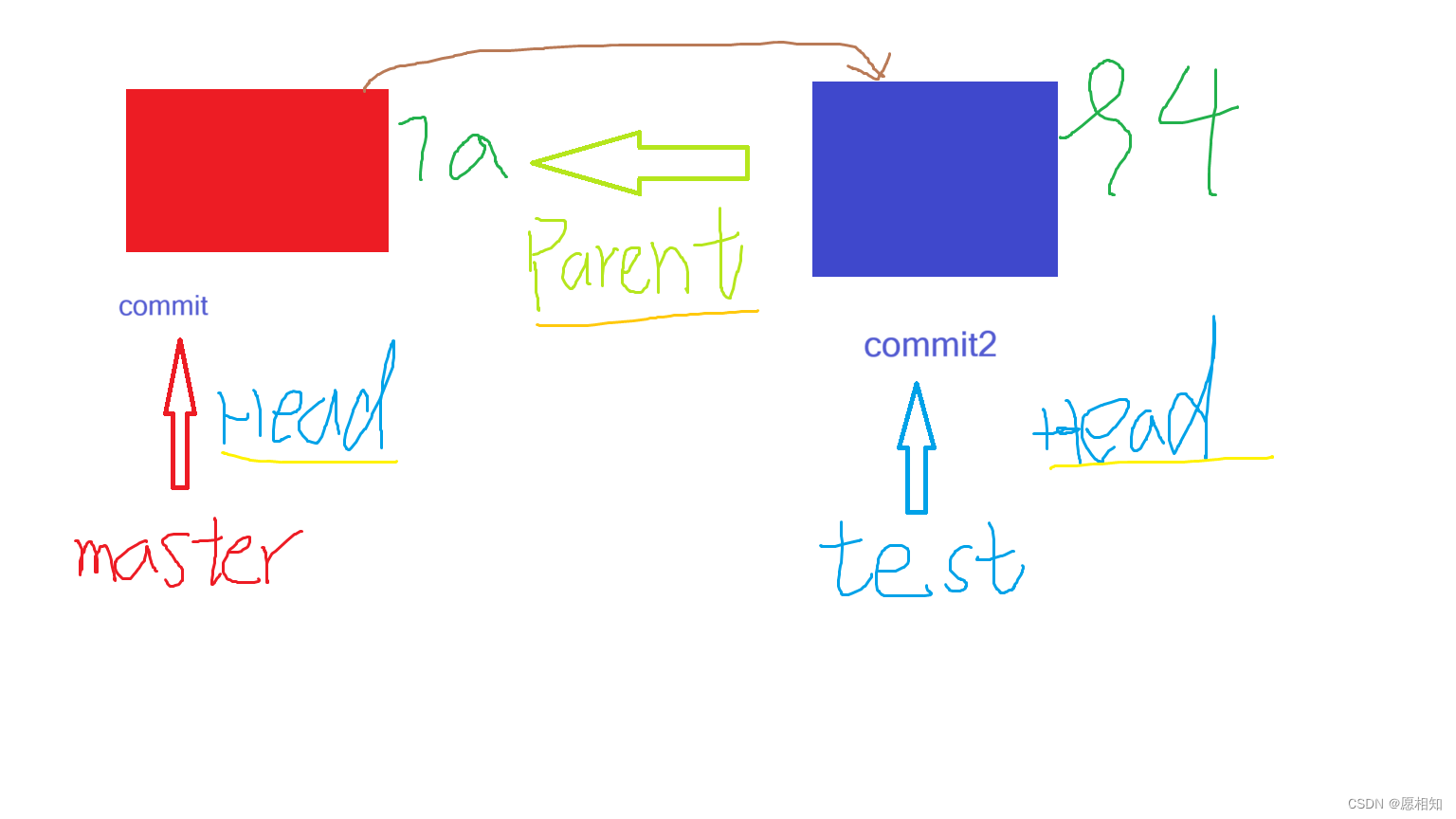
前言:
git 操作指令本身并不复杂,翻来覆去就是几个常用指令,我们反复使用做到孰能生巧就可以了,为什么还要去深究其底层实现原理呢?
放到 git 的学习使用上来说,如果我们不了解 git 底层存储原理,只是死记硬背操作指令的话,其实只能形成一些表层的肌肉记忆并不能做到融会贯通,容易出现了学了又忘,忘了又学,学了又忘的问题.
但是倘若掌握了原理就完全不同了,哪怕一个知识点对应结论忘了也完全不慌,大不了我们基于原理机制,从起点出发重新推导一轮即可
理工科的魅力不就在此吗?文科的东西我们是只能死记硬背,去感受前辈先贤的心境,感受世间万物,但是感觉是一个很玄的东西,我们大部分时候都在进行简单的“记忆” ,但是工科很多东西都有一套底层逻辑的,得出结论更多靠的是“推导”而非“记忆”。在推导之前,我们或许有些“小白”,有些“新手 ”,推导之中可能会遇到各种困难,我们联系自己的各方面知识来尝试,当我们努力一步一步得到结果的时候,整个过程也将会在我们的大脑里串联起来,如同茅塞顿开,醍醐灌顶。
1.探索之路(准备)
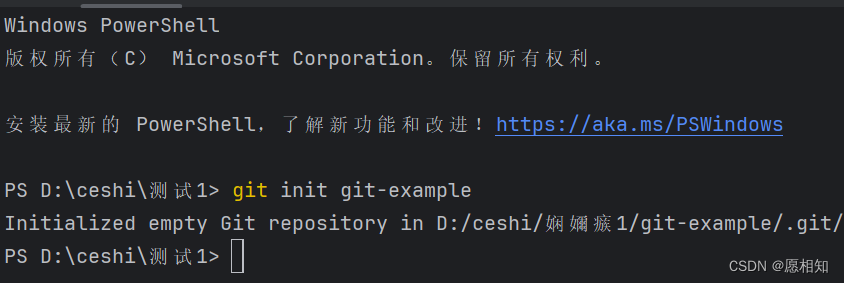
首先,我们打开clion创建了一个新项目,然后打开终端,在终端中输入
“git init git-example” 后自动生成一个git仓库
接下来我们需要写一个脚本来实现监听任务
首先在我们当前这个文件夹下面创建一个“.txt”文件,将以下代码输入:
@echo off
:loop
cls
echo Current time: %time%
tree .git
timeout /t 5 >nul
goto loop
然后将该文件更名为“.bat”文件,这里我们随便取一个名字
然后在该文件夹打开终端,输入命令”**.\1.bat**“运行该脚本
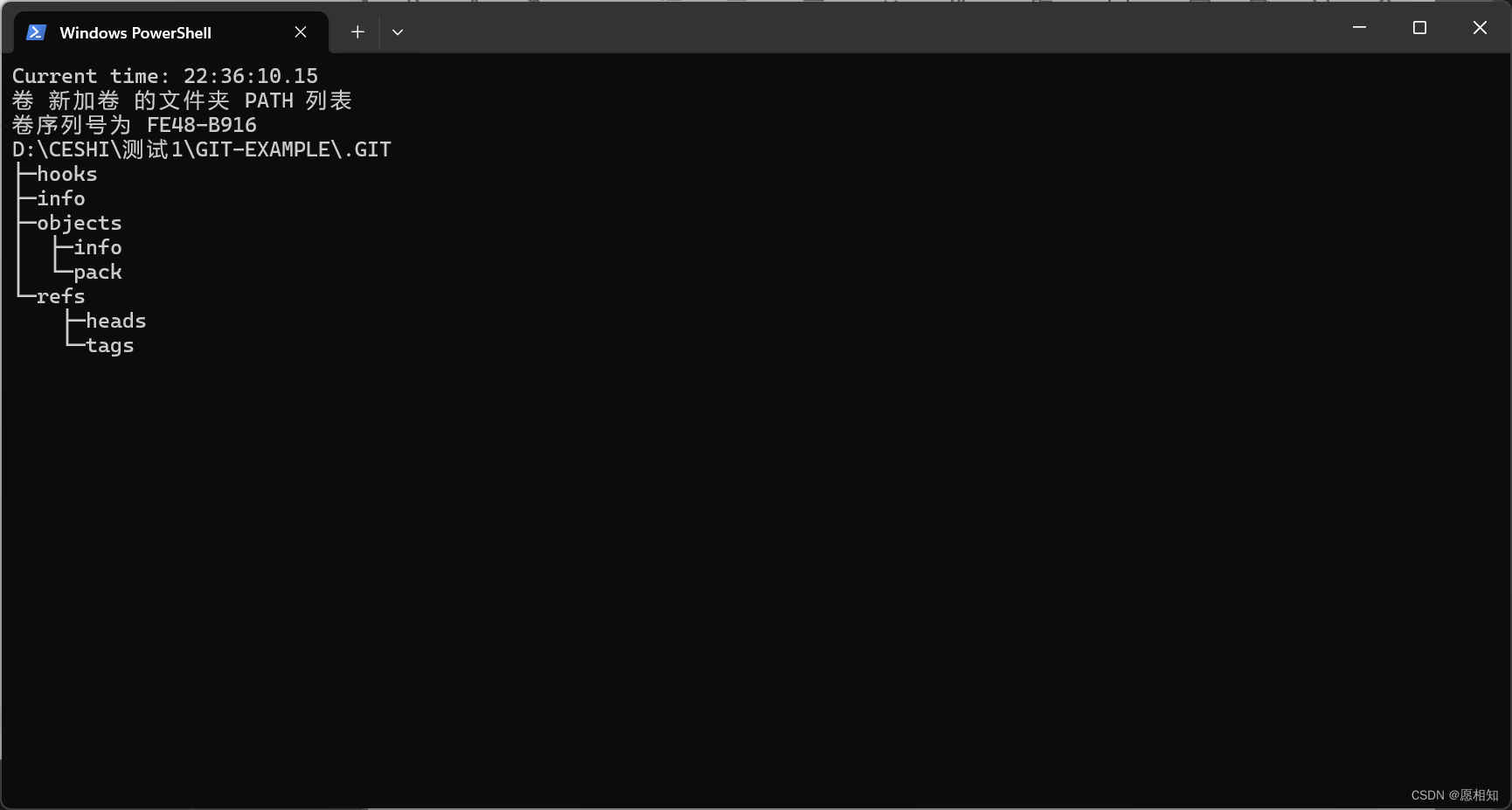
接下来这个脚本便会开始运行
在这个脚本中,
tree .git
会列出
.git
目录的树形结构,
timeout /t 5 >nul
会等待 5 秒,然后脚本会回到
:loop
标签处继续执行,从而实现循环效果
然后我们在该文件夹打开另一个终端,用来开始我们的探索之路
补充(我们发现该脚本显示内容有点少,故而我们修改脚本代码,在tree后面加入“/F”以显示更多文件)
2.开始
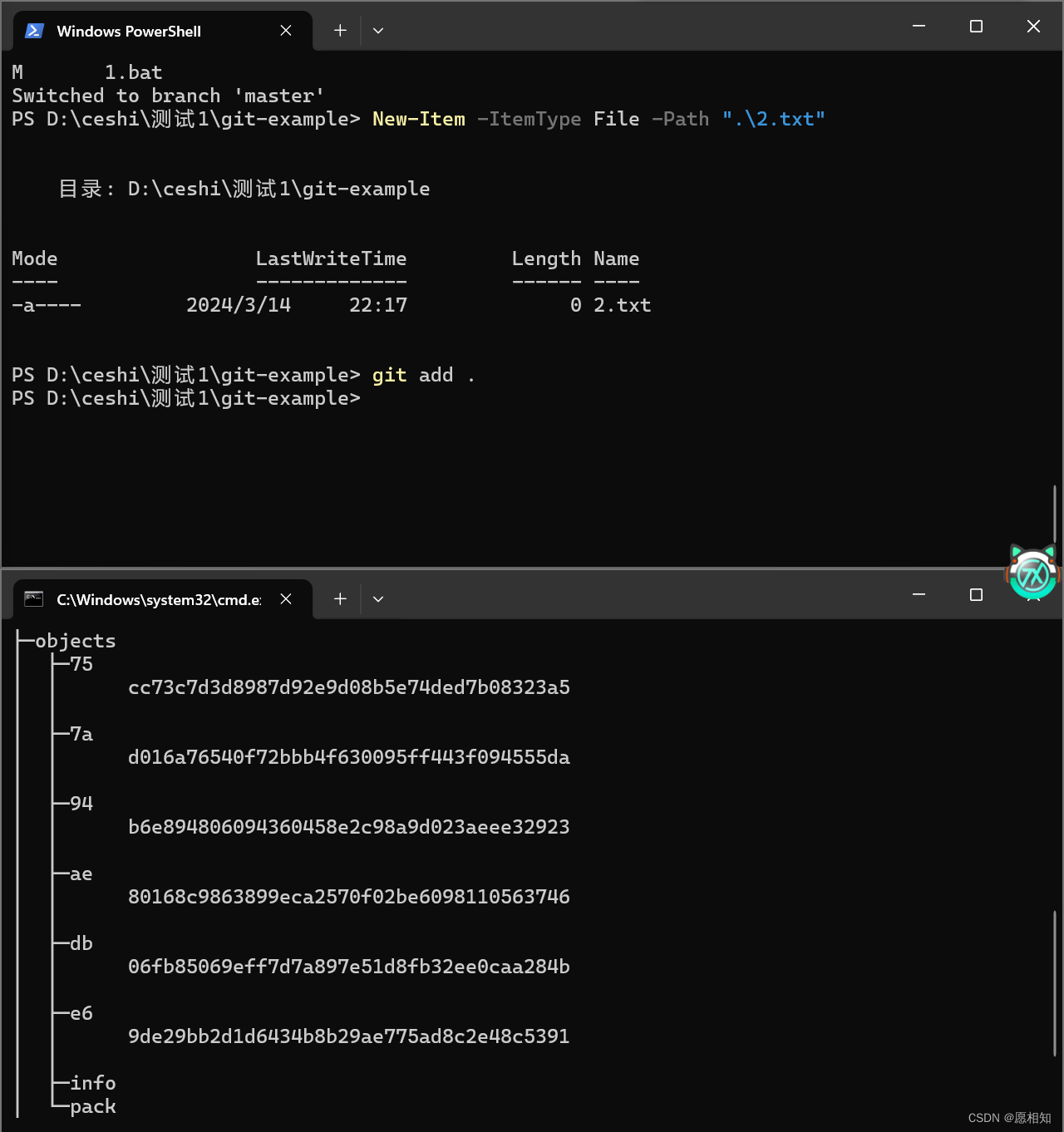
我们输入“git status”来查看一下
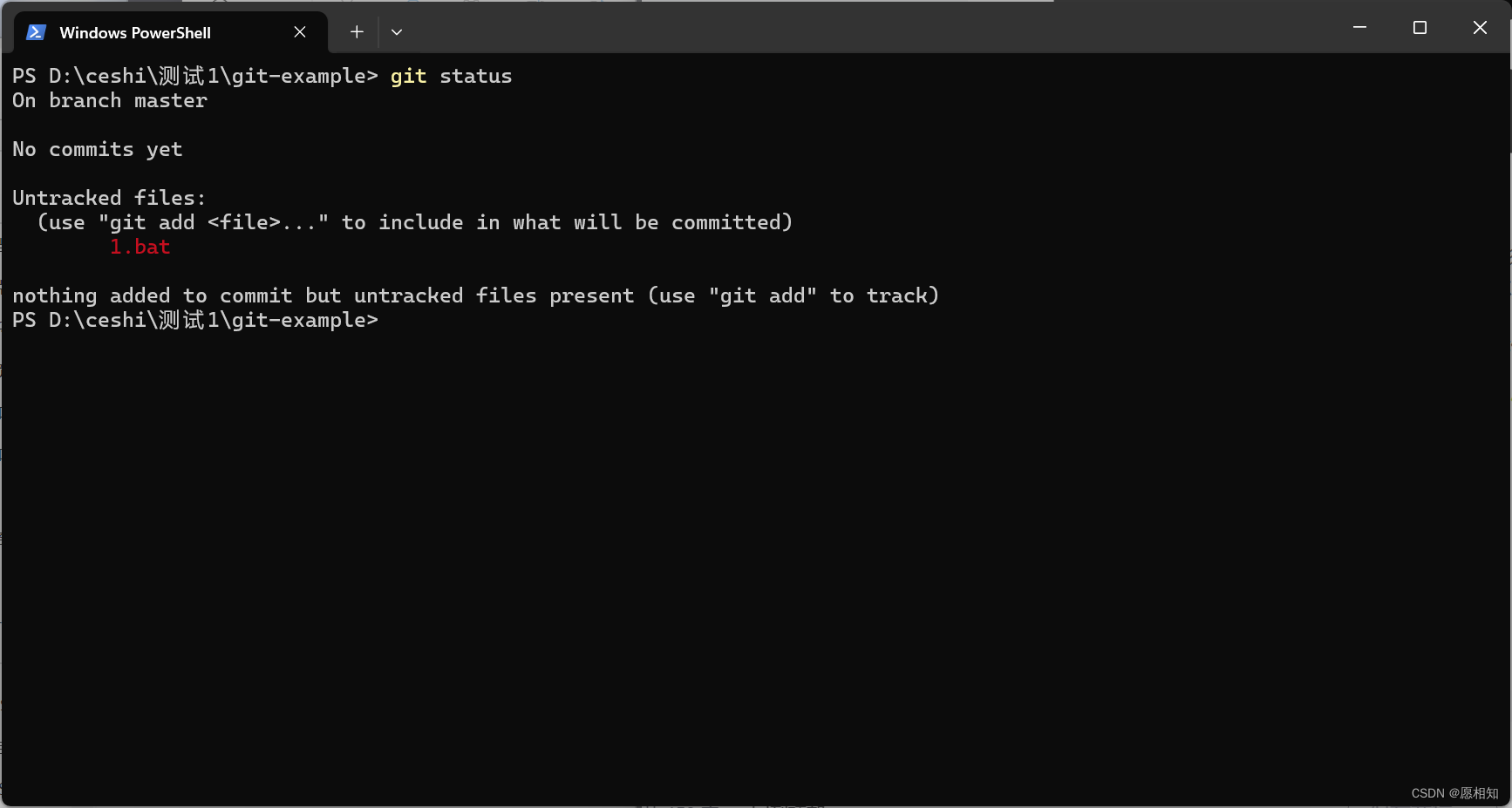
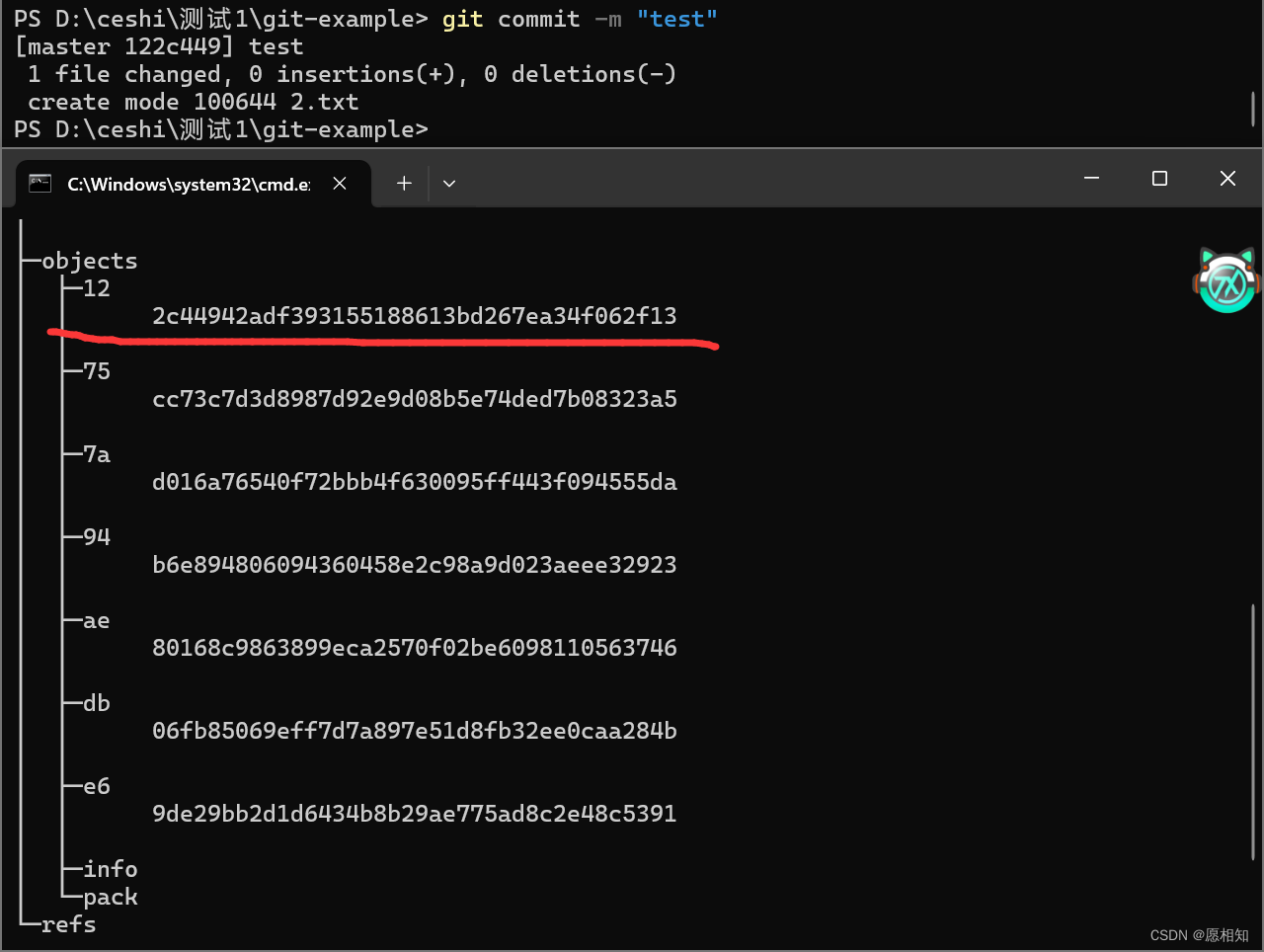
这里显示出来我们刚才增加的脚本,既然如此,我们先进行一次提交,看看会发生什么
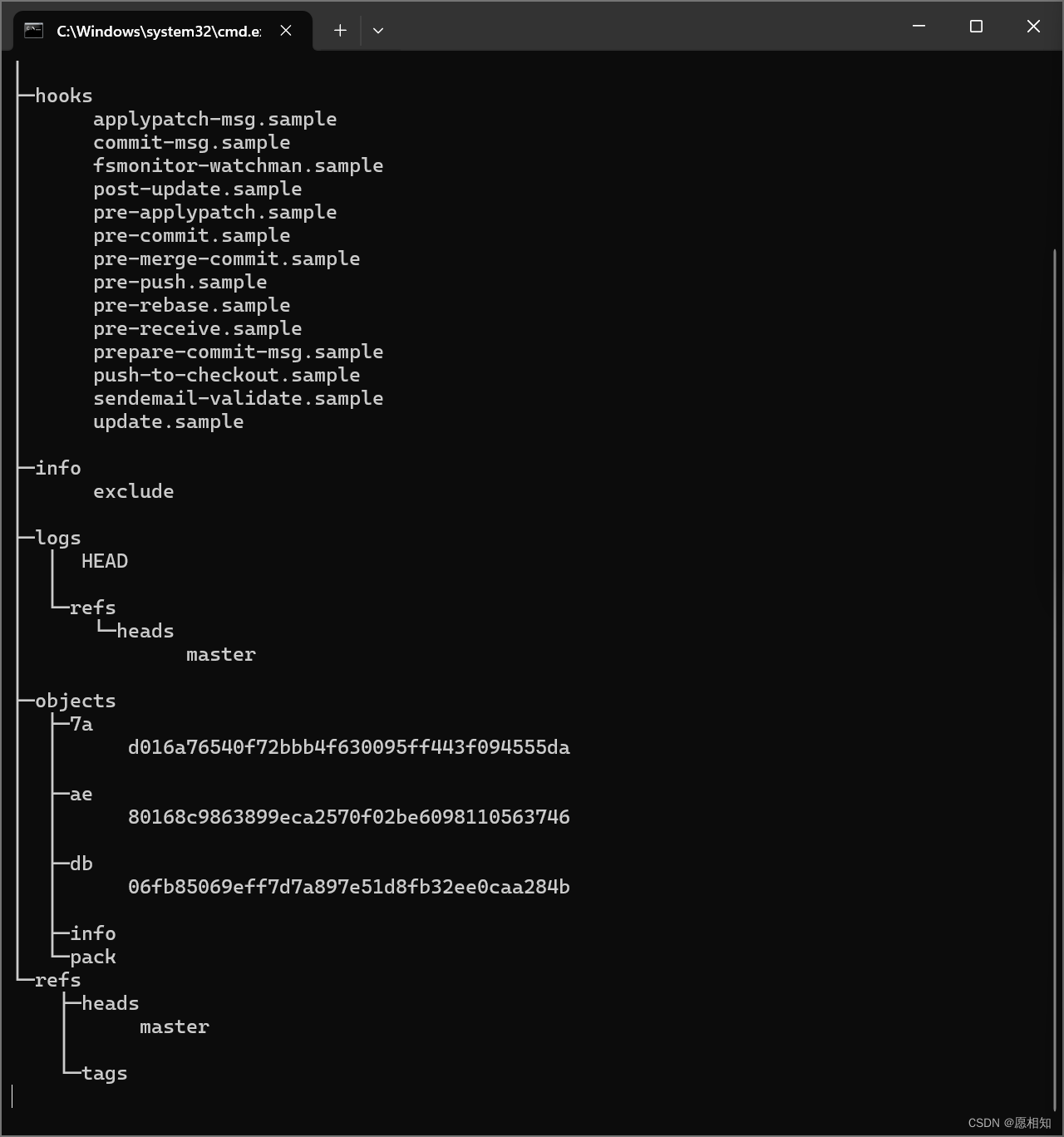
我们发现objects文件夹下多了“7a,ae,db”三个东西,后面多了一串哈希码
使用“git log”来查看一下提交
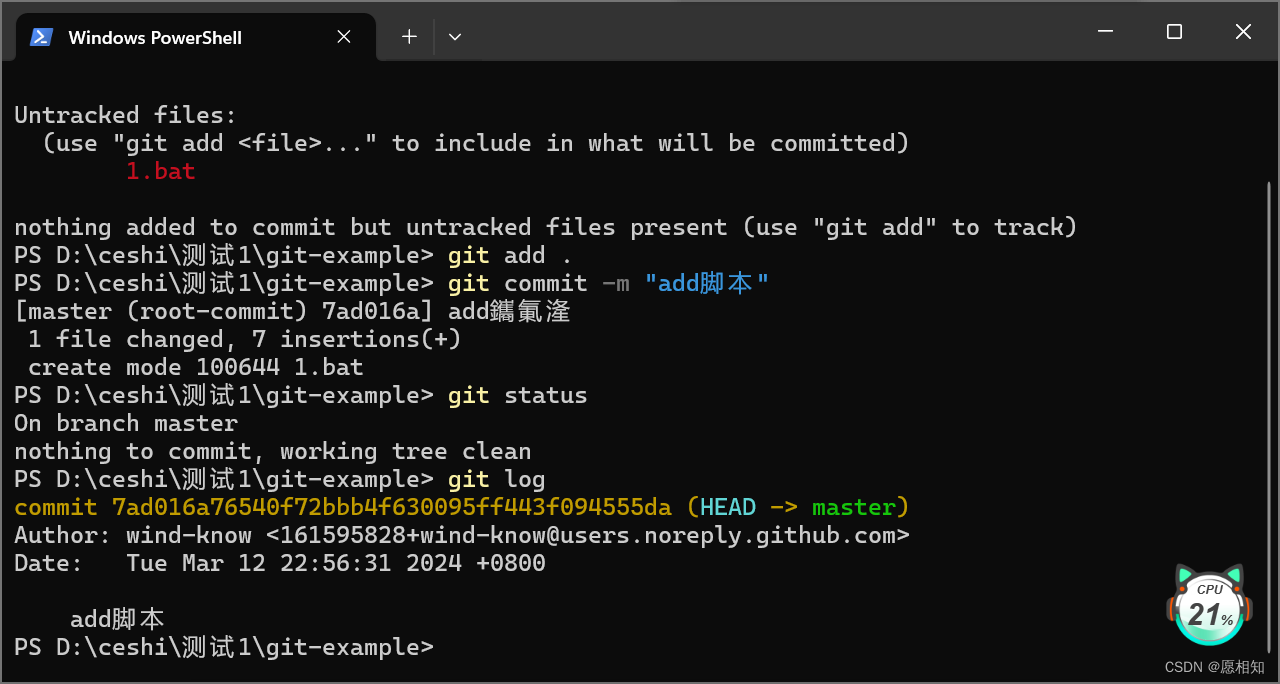
发现我们的提交上面的哈希码和新增的7a之下的哈希码一模一样
这是因为git的仓库存储模型是KV数据库,执行git add指令会向KV数据库追加KV对(KV数据库是一种键值存储数据库(Key-Value Database),它以键值对的形式存储数据。每个键(Key)都是唯一的,并且与一个相应的值(Value)相关联。这种类型的数据库非常简单,通常用于需要高效存储和检索简单数据结构的场景。)这里的key其实就是我们的这个objects下的文件名称,而value就是我们文件的内容
接下来我们使用一个新的命令:
git cat-file
,这是 Git 命令中的一个底层命令,用于查看 Git 对象的内容。Git 使用对象来存储文件的内容和元数据。每个对象都有一个唯一的哈希值标识符,它基于对象的内容和类型计算而得。
在 Git 中,对象的类型指的是对象存储的内容的类型。Git 中有四种主要的对象类型:
- blob(文件对象):blob 对象存储了文件的内容。在 Git 中,文件内容被视为二进制数据块。当你提交文件时,Git 会将文件内容转换成 blob 对象,并根据内容计算出唯一的哈希值。
- tree(树对象):tree 对象存储了文件和子目录的列表,类似于文件系统中的目录。每个树对象包含了文件名、文件模式和指向 blob 或其他树对象的引用。
- commit(提交对象):commit 对象存储了提交的元数据,包括提交作者、提交者、提交时间、提交信息以及指向父提交的引用。每个提交对象也包含了指向一个树对象的引用,代表了该提交的文件快照。
- tag(标签对象):tag 对象存储了标签信息,用于给某个特定的 commit 打标签。标签对象通常包含标签名、标签类型、标签信息和指向提交对象的引用。
这些对象类型在 Git 中起到了不同的作用,并组成了 Git 的基本数据结构。通过这些对象,Git 能够跟踪文件的变化历史、记录项目的状态以及管理分支和标签等信息。
于是,我们接下来输入命令查看一下objects的类型
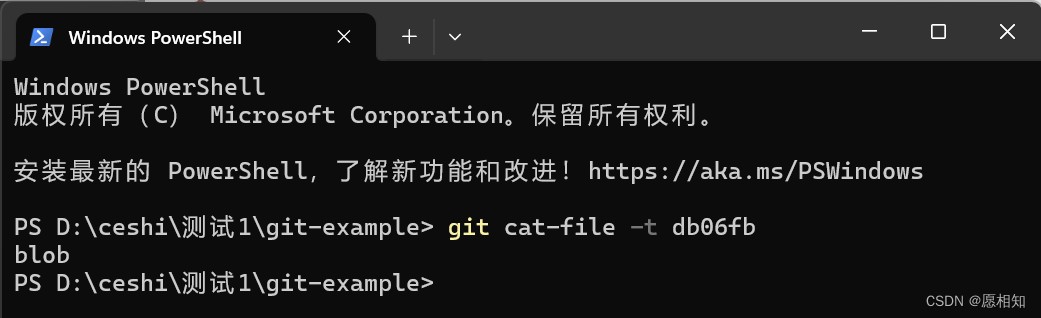
发现他的类型是一个blob型,再使用-p后缀(查看内容)查看一下其中的内容
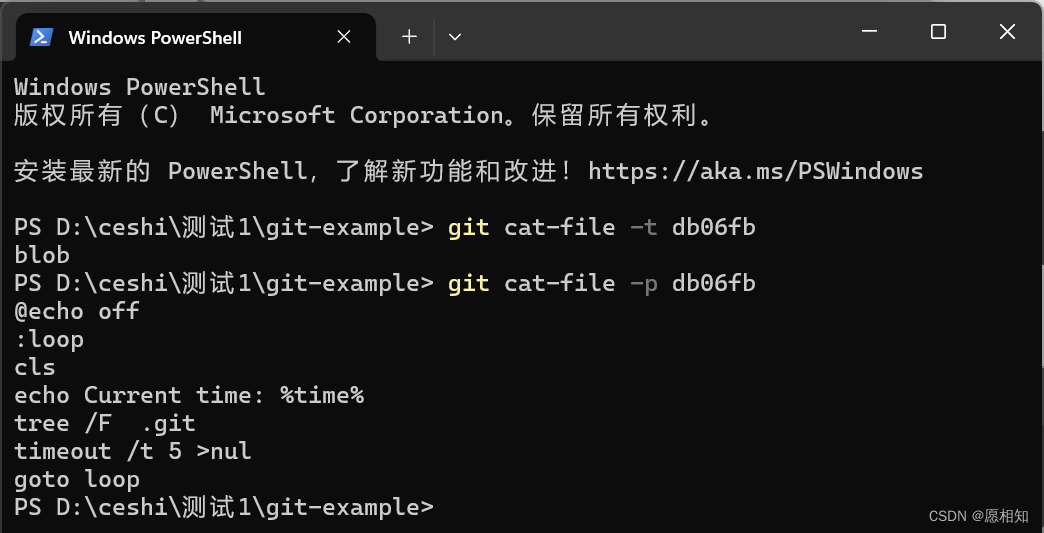
这个新增object 的文件名正是基于文件内容通过 SHA-1哈希算法生成的哈希字符串:1 (input) -> db06f....... (hashed)
需要注意,后续所有在.git/objects目录下新生成的object都是基于这种哈希摘要的规则生成的名称,我们把其名称称为object 的key。
接下来,我们发现还有两个文件在这次进行的:add,commit两个操作中出现了三个文件,如果db对应我们的add,那么剩下两个文件分别对应什么呢
我们继续上面的套路,使用以下命令查看一下他们的类型
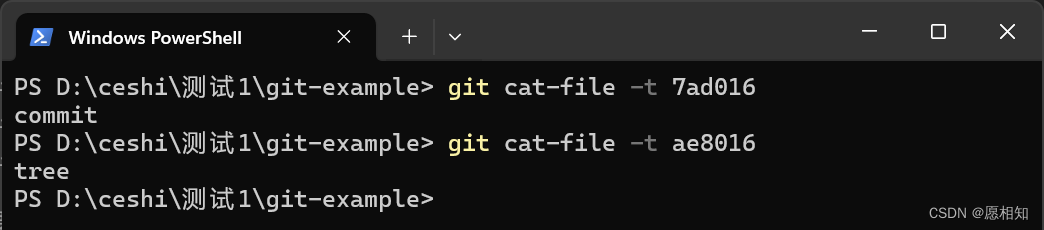
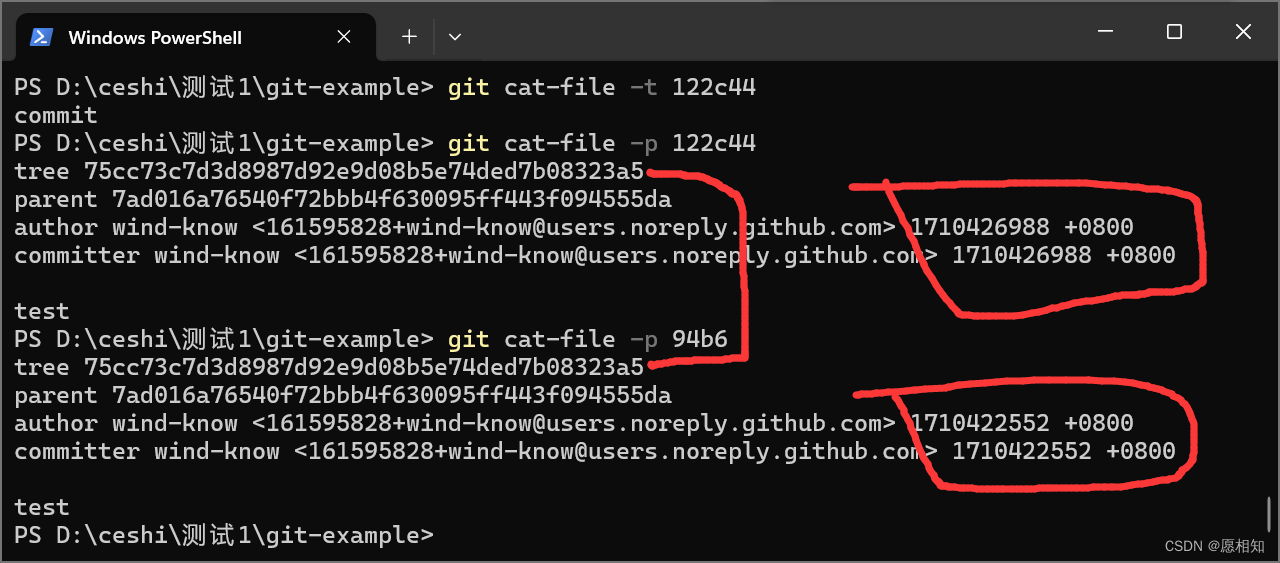
一个是commit文件,一个是tree文件。commit文件代表我们本地仓库一个版本,而tree相当于一个目录,我们每一个文件夹都像是一个树状。查看一下两个文件的内容
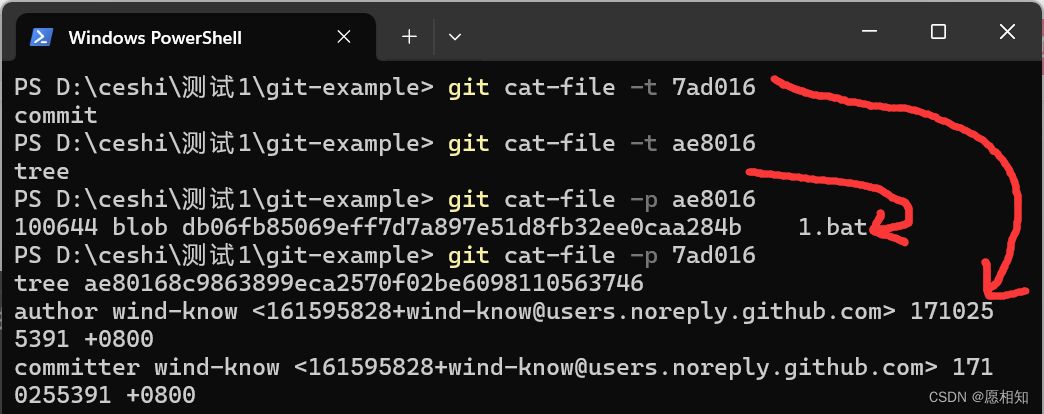
1.我们这个tree(文件夹)
下面有一个blob类型的文件,他的key与上面我们的db对应,这个文件名字叫做1.bat。(这个tree的哈希值是根据本身内容来得到的)
2.而我们的commit有什么呢,
1.这里面存在一个tree类型,这个文件的哈希值为ae,也就是我们上面提到的那个tree对应的key,
2.然后是我们本次提交的分支的作者,他的邮箱,
3.以及执行本次提交者的邮箱,还有提交的时间,
4.以及提交的备注,即我们的-m。
我们可见,我们的一次commit
1.首先先生成一个commit文件,这个文件保存了我们本次提交的信息,提交者,内容等等,然后我们的内容对应的key指向我们下一层级的文件----tree。
2.我们通过key找到tree文件夹后,再通过我们tree文件夹保存的key找到每一个blob文件。
至此,我们明白了一次更新操作所带来的影响。我们再使用cat命令查看一下heat的内容
cat .git/refs/heads/master
在 Git 中,
.git/refs/heads/master
文件存储了指向当前分支最新提交的引用。这个文件中的内容就是当前分支
master
最新提交的哈希值。
 此时head指向了7a文件,也就是commit;
此时head指向了7a文件,也就是commit;
3.继续前进
接下来,我们创建一个新分支,并查看一下新分支指向哪里
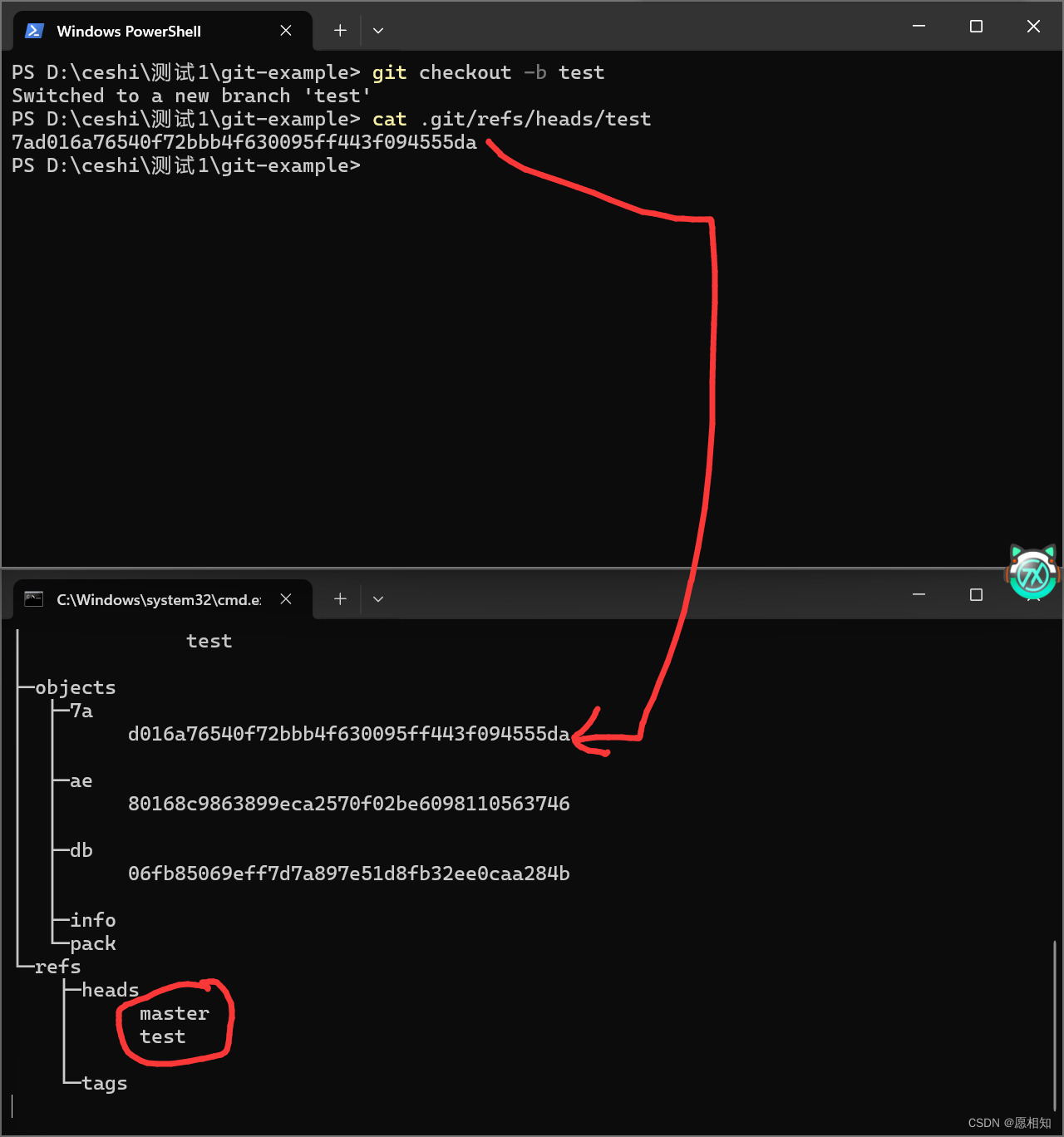
可见,创建新分支之后,heads文件多了一个test文件,并且新分支指向7a这里(因为我们的test是在master刚提交之后新创建的)
我们在1.bat之后创建一个新的2.txt,并使用status查看状态之后add一下
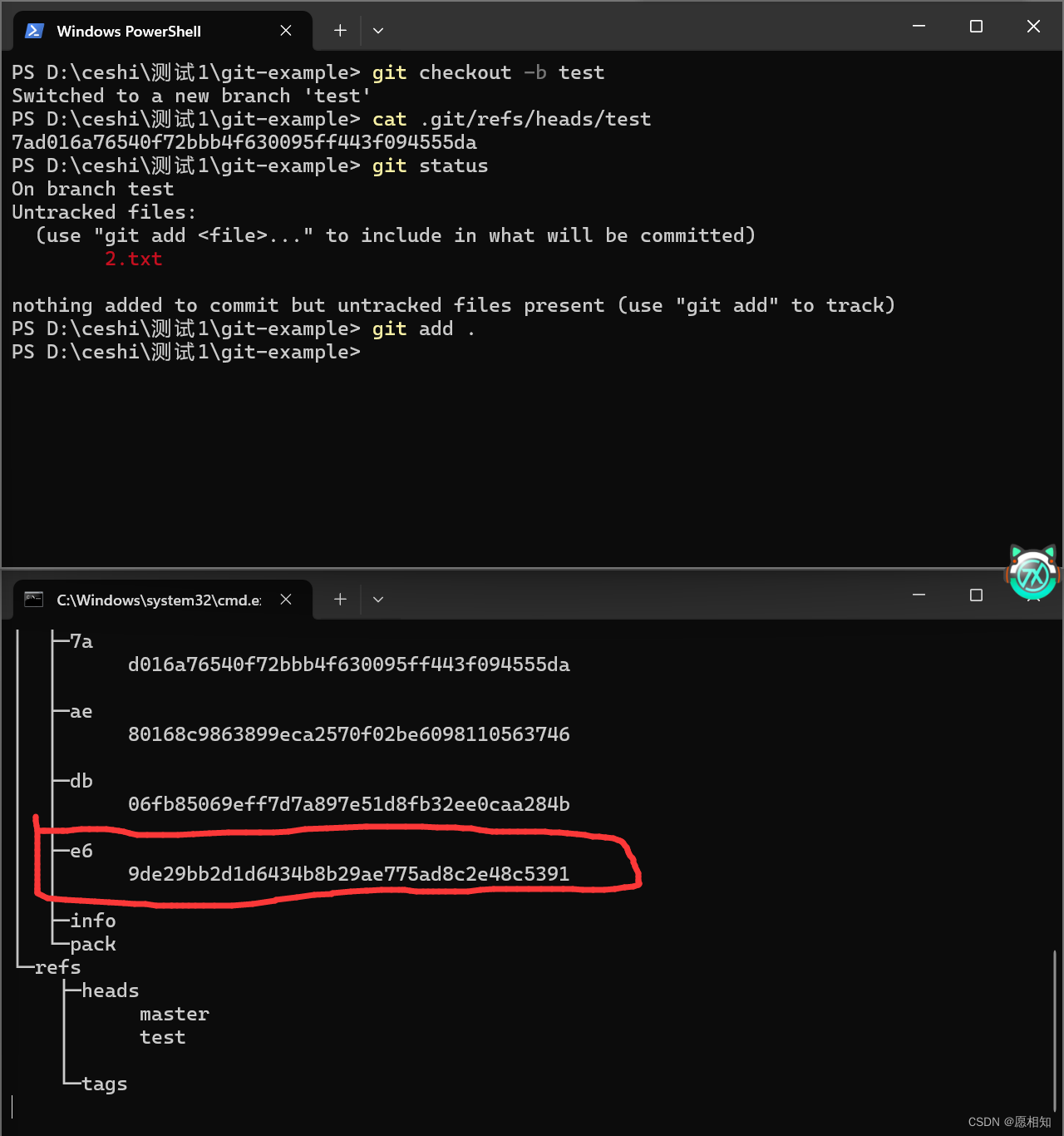 在我们add 2.txt之后多出来了e6blob文件
在我们add 2.txt之后多出来了e6blob文件
我们继续提交
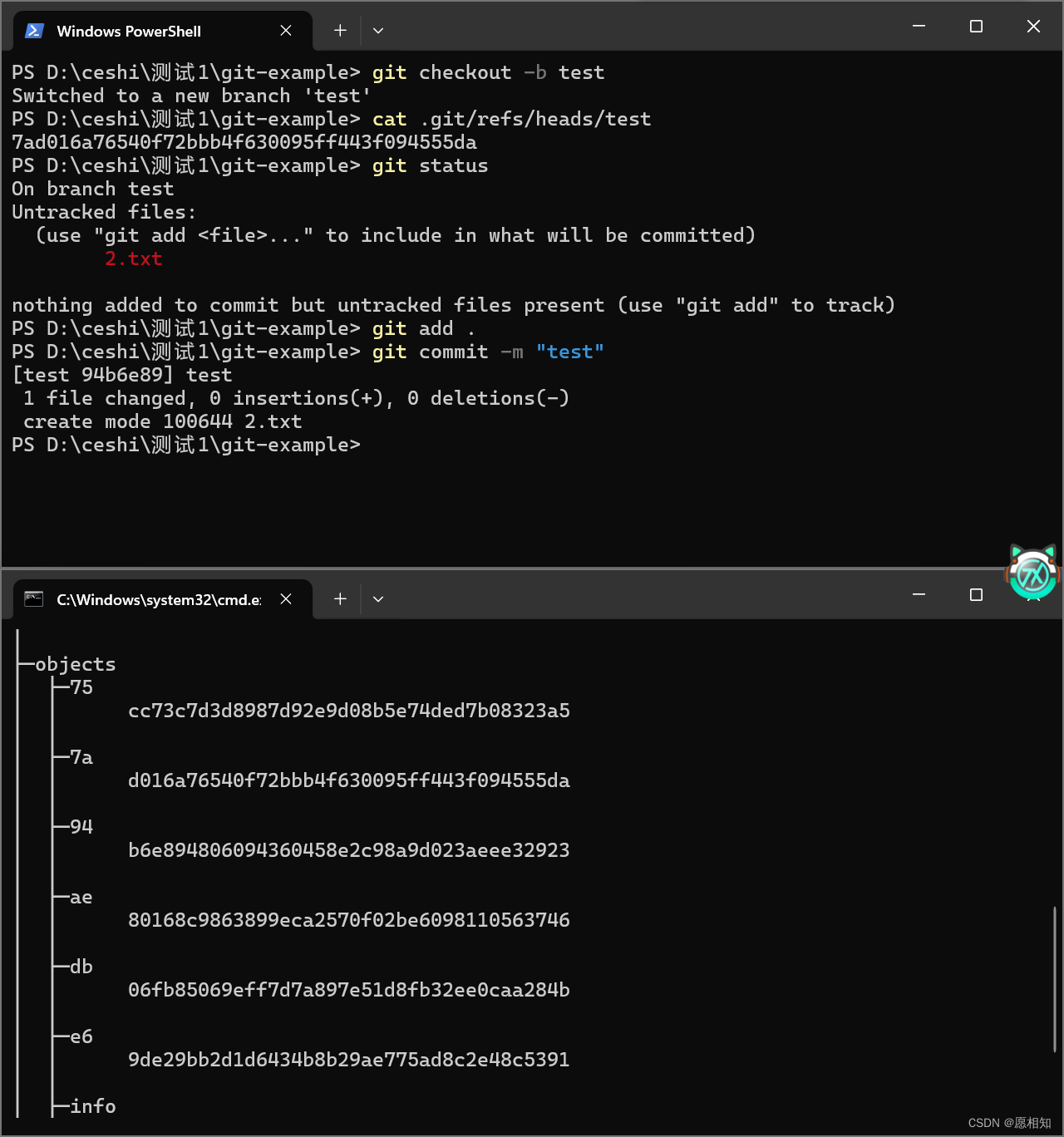 发现多出了94,75两个文件夹,那么此时对他们的类型我们再进行一下测试可知,94为commit,94为tree,e6为blob,并且test分支目前在94这里
发现多出了94,75两个文件夹,那么此时对他们的类型我们再进行一下测试可知,94为commit,94为tree,e6为blob,并且test分支目前在94这里
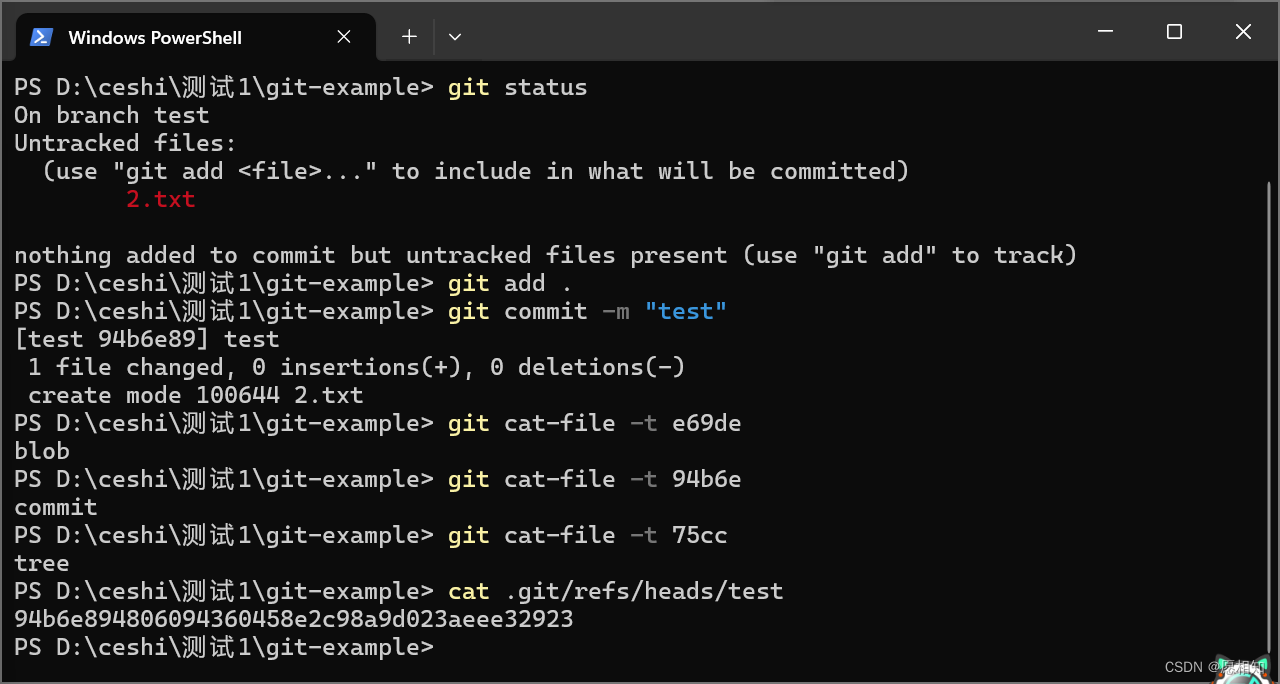
此时,我们来查看一下commit和tree里面的内容
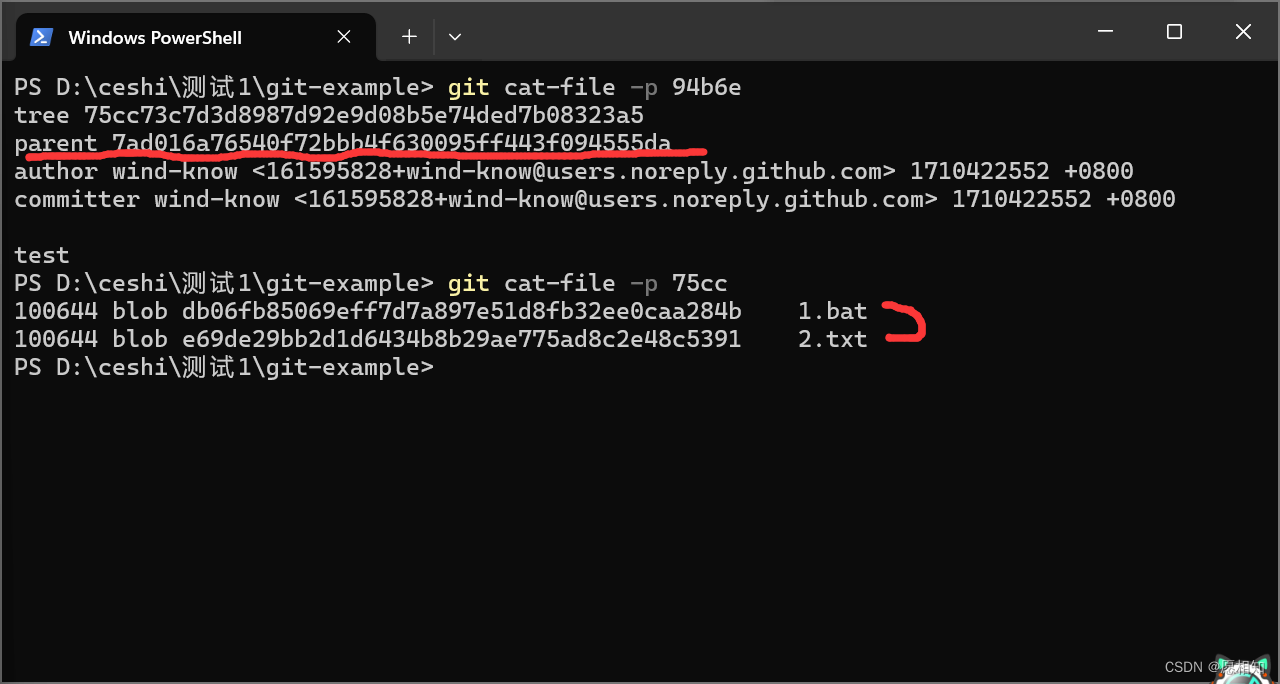
可以发现这一次,我们多出来一个parent(可以理解为指针),哈希码表示刚才的7a提交。显然,这是说这一次提交的“父母”是7a,也就是master的提交。
而我们的tree中,不但有我们提交的2.txt,甚至还有1.bat,并且复用了哈希码,这里我们可以得出结论,在我们的多次提交中,没有改变的文件的指针会进行不断复用同一份储存,不需要进行多次拷贝。
回看上面的parent,我们可以将目前的git视作一个链表的形式
接下来,我们再次切换回master分支,并且使用命令来创建一个和之前一模一样的文件
New-Item -ItemType File -Path "C:\path\to\file.txt"
 我们发现并没有新的objects文件夹出现,这是因为我们的文件与之前一模一样,内容没变,value没变,key也不变
我们发现并没有新的objects文件夹出现,这是因为我们的文件与之前一模一样,内容没变,value没变,key也不变
然后我们进行一次提交,这次提交控制与之前的内容都一样,看看会不会出现新的文件夹
 我们发现,出来了12文件夹,查看类型得知ta是commit类型,于是我们查看一下内容,并尝试与94对比一下
我们发现,出来了12文件夹,查看类型得知ta是commit类型,于是我们查看一下内容,并尝试与94对比一下
我们可以看出来,两个的内容几乎完全一样,所以并没有出现新的tree文件和blob文件,而是直接复用了以前的key,但是因为时间的不同,时间这一内容保存在commit中,所以commit文件的哈希码也不同,这样的就可以很方便的在git使用时解决哈希冲突。
此时的master指向12文件,test因为并未更改,仍然留在94文件。
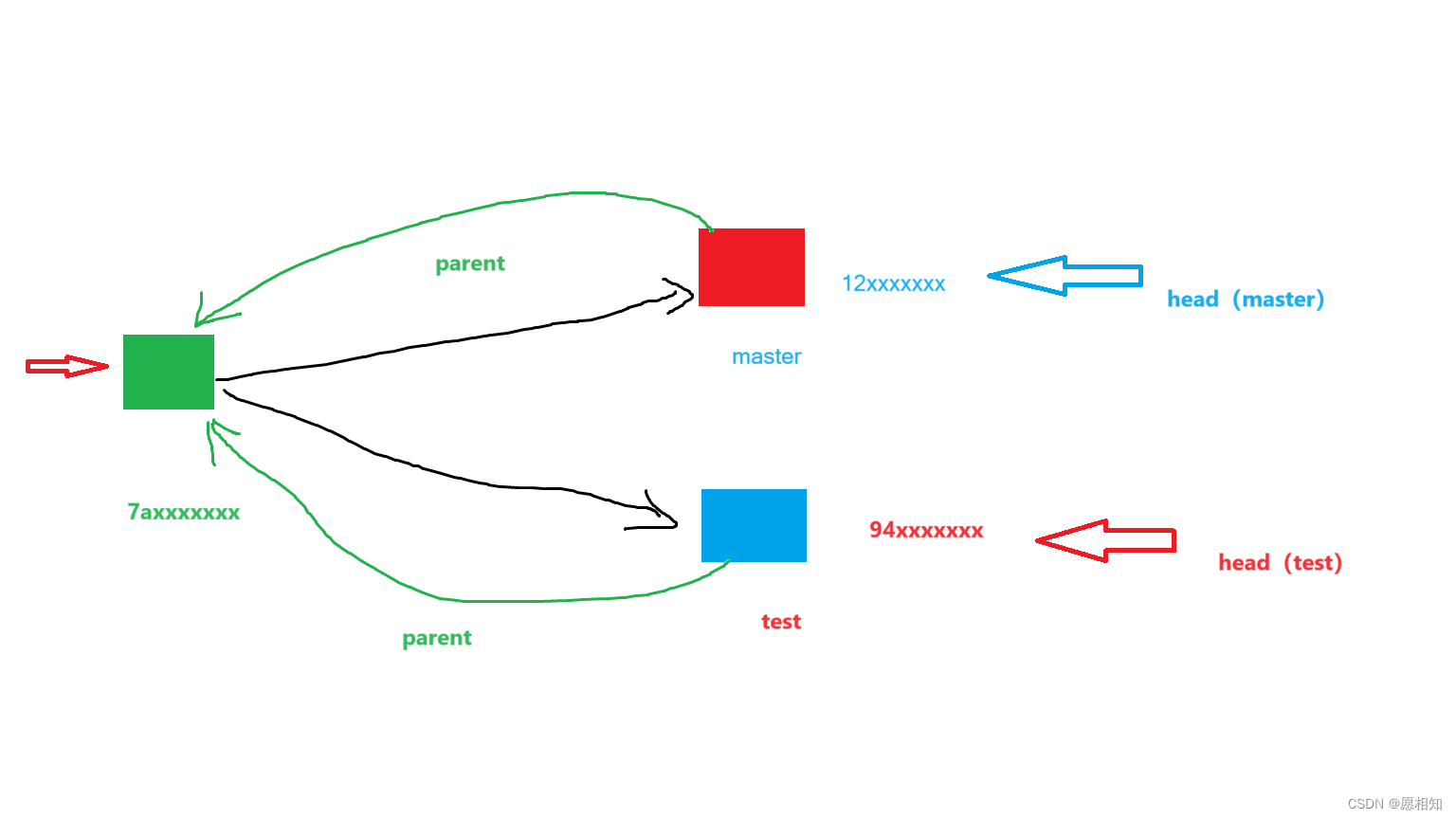
如图,绿色的parent指针指向了7a提交
接下来,我们将刚才测试的两个分支合并,看看会有什么变化
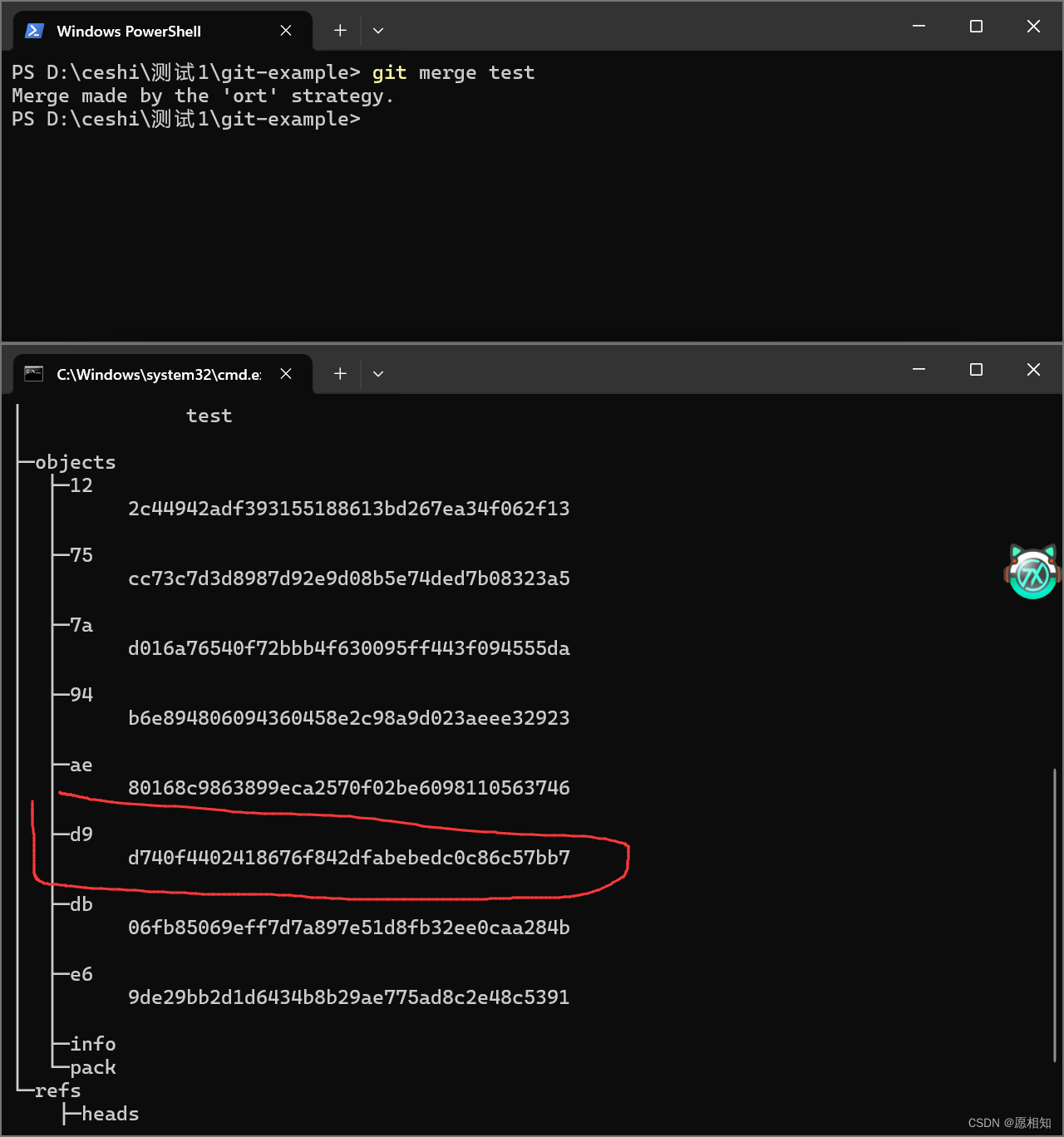
我们可以看到,多出来了一个d9文件,我们查看一下
 这是一个commit文件,我们注意到,他的tree文件与之前一模一样,原因不在复述。同时,我们注意到这个文件的parent指针有两个,分别指向我们test和master的两个commit。
这是一个commit文件,我们注意到,他的tree文件与之前一模一样,原因不在复述。同时,我们注意到这个文件的parent指针有两个,分别指向我们test和master的两个commit。
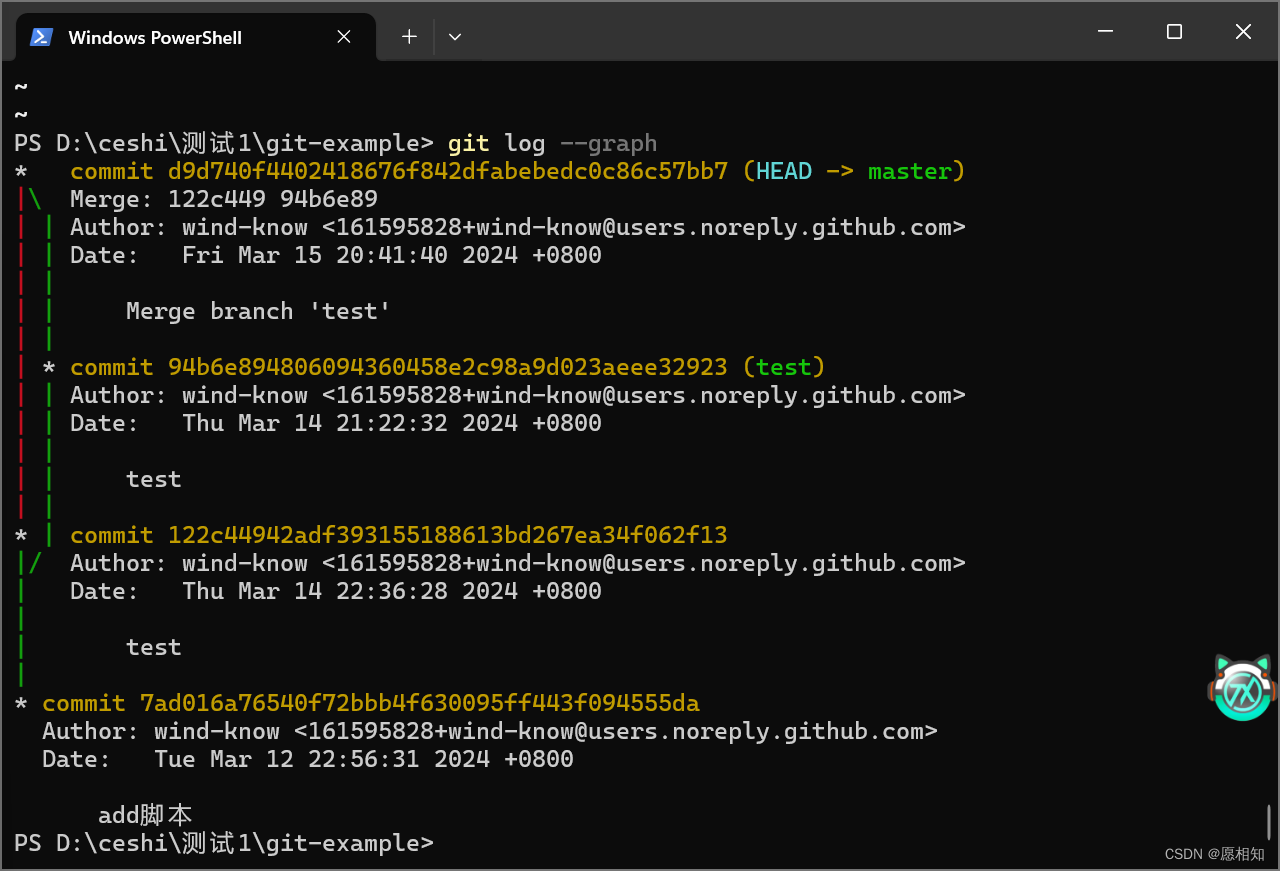 查看一下提交链。
查看一下提交链。
至此,我们是不是更加理解这个merge操作,其实就是新创建了一个提交,这个提交的四个属性根据合并的两个父文件来改变,parent指针则指向两个分支的提交。
通过上面的实测环节,我们零星获得了一些线索,下面我们进行一轮小结:
1.git 底层存储放在 .git/objects 文件夹下,分为 commit、tree、blob 三类 object2.每个 object 以key-value 形式存在: key (文件名)是基于 value 生成的哈希字符串
3.commit object: 对应于每一次的提交行为,内容包含指向前一个 commit object 的 key,当前 commit下 tree 的 key;此外还记录了提交人、时间、摘要等信息
4.tree object: 对应于每个文件夹,记录了文件夹下子 object 的信息, tree 之间可以进行嵌套
5.blob object: 对应为每个文件,value 是文件内容,key 是以文件内容生成的 hash 字符串
6.branch head: 对应为每个分支的头指针,指向该分支下一个 commit object 的 key
4.联合
经过这么多麻烦的小探索,我们是不是可以更好的理解一下git的基本原理。
这里我们先简要概括出两个前辈所总结的重要结论:
- • git 存储模型本质上是一个依赖于哈希算法的 kv 数据库
- • git 版本控制框架在纵向上是以 commit object 组成的链表,在横向上是以 commit object、tree object、blob object 组成的多叉树。
我们从最开始来:
1.哈希散列
哈希散列函数(hash)想比大家都是耳熟能详,这是一种能把原始输入压缩输出成指定规格的无意义字符串的摘要算法.
hash 的核心点包括了:
- • 可重入:相同输入必然产生相同输出
- • 散列性:两个不同输入会被均匀映射到输出域上
- • 存在冲突: 由于输入域远大于输出域,所以可能存在不同输入映射到相同输出
尽管 hash 存在冲突问题,但是在 git 中,使用到的是安全性较高的 SHA-1 哈希算法,输出结果为 160 位 (20字节),具有非常优秀的散列性,因此可以近似认为,只要原始输入内容不同,则输出的结果也一定不同.
2.kv对
git 存储模型本质上是一个依赖哈希算法的 kv 数据库,其中的每一个 kv 对叫作一个 object,自上而下分为 commit、tree、blob 三类 object.
对于每个 kv 对,value 对应的该 object 的具体内容,key 是在 value 基础上通过 SHA-1 算法生成的摘要信息. 由于 SHA-1 的高度散列性,于是可以认为,在这个 kv 数据库中,只要 object 的 value 值不同,那么其 key 值一定也不同,因此在 kv 数据库中就会是两个独立的 object
3.文件链接
我们的每次提交都通过一个个指针来链接起来,同时与文件也链接
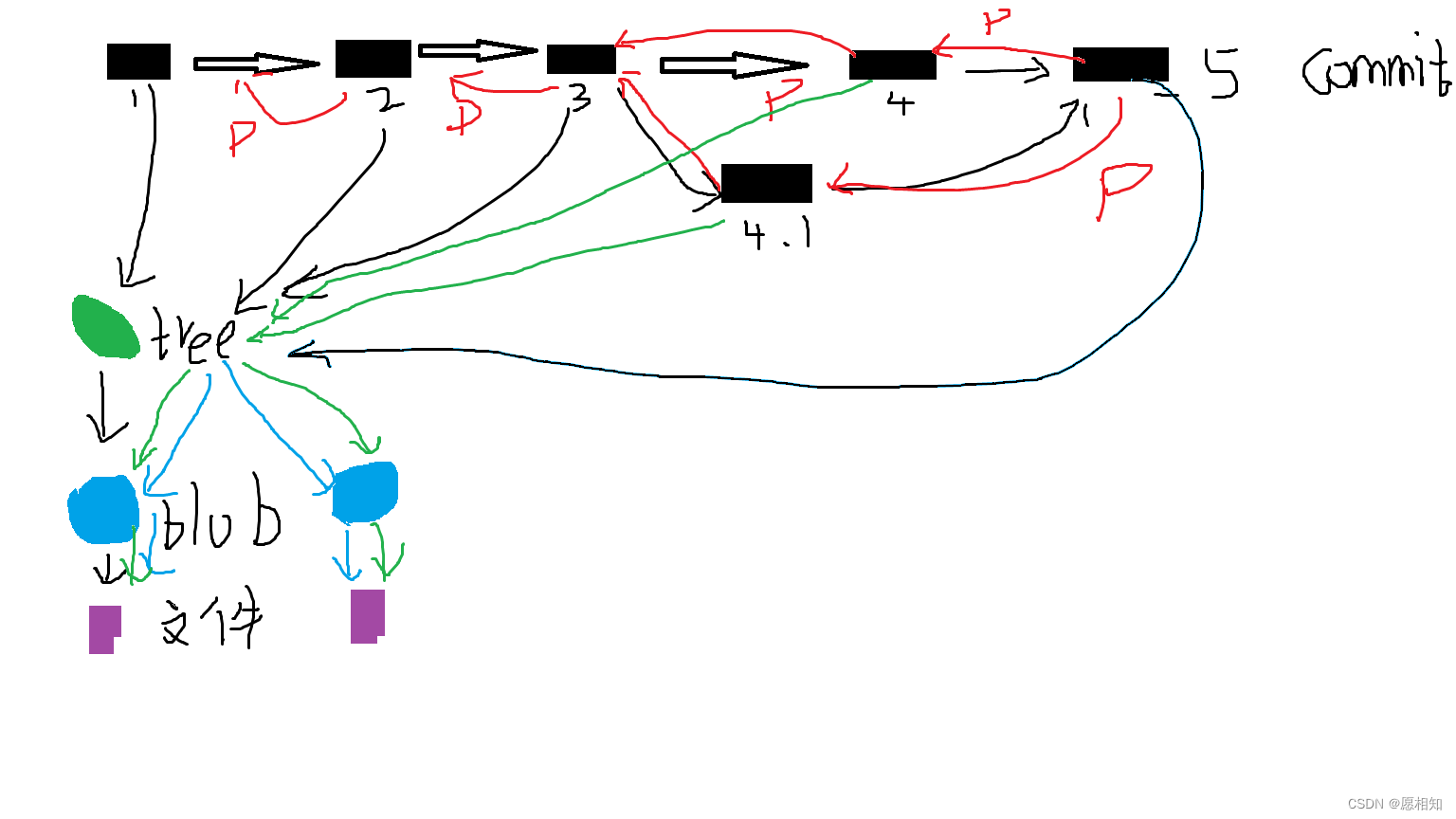
而成链状的逻辑:
- • 每个 commit object 的 key 基于 value 通过 SHA-1 算法生成
- • 每个 commit object 的 value 包含 parent 字段,是指向 parent commit object 的 key
是通过不同的key与parent指针来区别与链接。
而之所以保证不会出现冲突,也正是基于key的获取与parent的指向
I commit 内容安全性
基于以上两点,所有合入版本链达到一定深度的 commit object 内容是无法被篡改的,因为其一旦发生变化,自身对应的 object key 也会变化,其后续节点也会因为 parent 值的变更而需要调整对应的 key 值,最终发生多米诺骨牌效应.
II commit id 全局唯一性
commit object 的 key 又称为 commit id. 由于其是基于提交人、提交时间戳、提交摘要、parent commit id、tree object key 的五维信息取 SHA-1 生成,因此但凡上述任何一项内容有差异,生成的 commit id 都是不同的.
4.远程与本地
对于处在远端的中央仓库,我们每次尝试通过 push 向远端推送一个 commit 时,
远端仓库都会对提交版本的正确性进行校验,校验方式是
沿拟提交 commit object 的 parent 指针向前遍历,
倘若能找到某个 parent commit object 和远端分支上最后一个 commit object 的 key 值相同,才可能允许这次 push 行为,以此保证版本链的连贯性.
意思是我们push时,向回找parent,与远程库来比较,一旦上一个与目前要增加的节点的上一个不同,那就不被允许push上去,在我与实验室伙伴练习远程仓库时,就出现过这种问题,我们“争抢着”去进行push操作。
5.分支
我们可以把分支 branch 理解为一条独立的 commit 版本链( 每次拉分支就是在 commit 链上进行分叉 ) ,branch HEAD 体现为在 commit 版本链上移动的指针,其指向了分支链上某个特定 commit object 的 key.
我们在切换分支或者重置分支 commit id 时,本质上只是在作指针的创建和移动
我们总结 commit、tree、blob 三类 object 特征后可以发现,所谓 git 版本控制的底层模型,本质上就是由一系列链表 + 多叉树组成的:
- • 链表: 由 commit object 组成,通过 parent 指针串联
- • 多叉树: 由 comit、tree、blob 组成. 根节点为 commit object(对应提交记录),枝干节点为 tree object(对应文件夹),叶子节点为 blob object(对应文件)
参考:
万字串讲git版本控制底层原理及实战分享_哔哩哔哩_bilibili
40个powershell命令,让你玩明白windows的powershell命令行_哔哩哔哩_bilibili
特别鸣谢:
【Git】从快照到内容寻址,浅析Git版本管理的实现方式-CSDN博客
版权归原作者 愿相知 所有, 如有侵权,请联系我们删除。