
一、kafka的log日志梳理
日志文件是kafka根目录下的config/server.properties文件,配置log.dirs=/usr/local/kafka/kafka-logs,kafka一部分数据包含当前Broker节点的消息数据(在Kafka中称为Log日志),称为无状态数据,另外一部分存在zookeeper上的称为有状态数据,例如controller的信息,broker的状态等等
broker迁移并不是把这些无状态的数据复制到另一个机器节点上,可以通过一些工具命令,例如bin目录下的 kafka-reassign-partitions.sh都可以帮助进行服务替换
1、topic下的消息是如何存储的
当前只创建了一个partition,所以只有一个topic对应的文件夹,再看看文件文件夹下都有什么

- log文件:实际存储消息的日志文件 ,固定大小1G(由参数log.segment.bytes参数指定),写满后就会新增一个文件,文件名为第一条消息的便宜量
- .index文件和.timeindex文件:都是对应log文件的索引文件,.index是以偏移量为索引来记录对应的.log日志文件中的消息偏移量,而.timeindex则是以时间戳为索引。
另外的两个文件,partition.metadata简单记录当前Partition所属的cluster和Topic。leader-epoch-checkpoint文件参见之前的epoch机制。
这些文件都是二进制文件,可以通过kafka提供的工具命令进行查看
#1、查看timeIndex文件
[oper@worker1 bin]$ ./kafka-dump-log.sh --files /app/kafka/kafka-logs/secondTopic-0/00000000000000000000.timeindex
Dumping /app/kafka/kafka-logs/secondTopic-0/00000000000000000000.timeindex
timestamp: 1661753911323 offset: 61
timestamp: 1661753976084 offset: 119
timestamp: 1661753977822 offset: 175
#2、查看index文件
[oper@worker1 bin]$ ./kafka-dump-log.sh --files /app/kafka/kafka-logs/secondTopic-0/00000000000000000000.index
Dumping /app/kafka/kafka-logs/secondTopic-0/00000000000000000000.index
offset: 61 position: 4216
offset: 119 position: 8331
offset: 175 position: 12496
#3、查看log文件
[oper@worker1 bin]$ ./kafka-dump-log.sh --files /app/kafka/kafka-logs/secondTopic-0/00000000000000000000.log
Dumping /app/kafka/kafka-logs/secondTopic-0/00000000000000000000.log
Starting offset: 0
baseOffset: 0 lastOffset: 1 count: 2 baseSequence: 0 lastSequence: 1 producerId: 7000 producerEpoch: 0 partitionLeaderEpoch: 11 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 0 CreateTime: 1661753909195 size: 99 magic: 2 compresscodec: none crc: 342616415 isvalid: true
baseOffset: 2 lastOffset: 2 count: 1 baseSequence: 2 lastSequence: 2 producerId: 7000 producerEpoch: 0 partitionLeaderEpoch: 11 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 99 CreateTime: 1661753909429 size: 80 magic: 2 compresscodec: none crc: 3141223692 isvalid: true
baseOffset: 3 lastOffset: 3 count: 1 baseSequence: 3 lastSequence: 3 producerId: 7000 producerEpoch: 0 partitionLeaderEpoch: 11 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 179 CreateTime: 1661753909524 size: 80 magic: 2 compresscodec: none crc: 1537372733 isvalid: true
.......
1)、log文件追加记录所有消息
首先:在每个文件内部,Kafka都会以追加的方式写入新的消息日志。position就是消息记录的起点,size就是消息序列化后的长度。Kafka中的消息日志,只允许追加,不支持删除和修改。所以,只有文件名最大的一个log文件是当前写入消息的日志文件,其他文件都是不可修改的历史日志。
然后:每个Log文件都保持固定的大小。如果当前文件记录不下了,就会重新创建一个log文件,并以这个log文件写入的第一条消息的偏移量命名。这种设计其实是为了更方便进行文件映射,加快读消息的效率。
2)、index和timeindex加速读取log消息日志
详细看下这几个文件的内容,就可以总结出Kafka记录消息日志的整体方式:
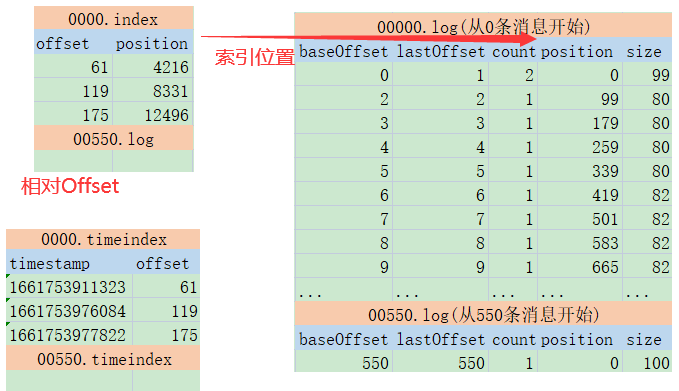
首先:index和timeindex都是以相对偏移量的方式建立log消息日志的数据索引。比如说 0000.index和0550.index中记录的索引数字,都是从0开始的。表示相对日志文件起点的消息偏移量。而绝对的消息偏移量可以通过日志文件名 + 相对偏移量得到。
然后:这两个索引并不是对每一条消息都建立索引。而是Broker每写入40KB的数据,就建立一条index索引。由参数log.index.interval.bytes定制。
log.index.interval.bytes
The interval with which we add an entry to the offset index
Type: int
Default: 4096 (4 kibibytes)
Valid Values: [0,...]
Importance: medium
Update Mode: cluster-wide
index文件的作用类似于数据结构中的跳表,他的作用是用来加速查询log文件的效率。而timeindex文件的作用则是用来进行一些跟时间相关的消息处理。比如文件清理。
这两个索引文件也是Kafka的消费者能够指定从某一个offset或者某一个时间点读取消息的原因。
2、文件清理机制
1)、判断哪些文件过期
- log.retention.check.interval.ms:定时检测文件是否过期。默认是 300000毫秒,也就是五分钟。
- log.retention.hours , log.retention.minutes, log.retention.ms 。 这一组参数表示文件保留多长时间。默认生效的是log.retention.hours,默认值是168小时,也就是7天。如果设置了更高的时间精度,以时间精度最高的配置为准。
- 在检查文件是否超时时,是以每个.timeindex中最大的那一条记录为准。
2)、过期文件处理
- log.cleanup.policy:日志清理策略。有两个选项,delete表示删除日志文件。 compact表示压缩日志文件。
- 当log.cleanup.policy选择delete时,还有一个参数可以选择。log.retention.bytes:表示所有日志文件的大小。当总的日志文件大小超过这个阈值后,就会删除最早的日志文件。默认是-1,表示无限大。
压缩日志文件虽然不会直接删除日志文件,但是会造成消息丢失。压缩的过程中会将key相同的日志进行压缩,只保留最后一条。
3、kafka的文件高效读取机制
1)、kafka的文件结构
Kafka的数据文件结构设计可以加速日志文件的读取。比如同一个Topic下的多个Partition单独记录日志文件,并行进行读取,这样可以加快Topic下的数据读取速度。然后index的稀疏索引结构,可以加快log日志检索的速度。
2)、顺序写磁盘
这个跟操作系统有关,主要是硬盘结构。
对每个Log文件,Kafka会提前规划固定的大小,这样在申请文件时,可以提前占据一块连续的磁盘空间。然后,Kafka的log文件只能以追加的方式往文件的末端添加(这种写入方式称为顺序写),这样,新的数据写入时,就可以直接往直前申请的磁盘空间中写入,而不用再去磁盘其他地方寻找空闲的空间(普通的读写文件需要先寻找空闲的磁盘空间,再写入。这种写入方式称为随机写)。由于磁盘的空闲空间有可能并不是连续的,也就是说有很多文件碎片,所以磁盘写的效率会很低。
kafka的官网有测试数据,表明了同样的磁盘,顺序写速度能达到600M/s,基本与写内存的速度相当。而随机写的速度就只有100K/s,差距比加大。
3)、零拷贝
- 传统的一次硬件IO是这样工作的:先从磁盘中通过DMA拷贝数据到内核态的page cache中,应用程序通过CPU参与从page cache拷贝到应用程序的内存中;再通过CPU参与从应用程序内存拷贝到Socket缓冲区(内核态内存),最后通过DMA拷贝到目标网络位置(DMA拷贝不需要CPU参与)
- mmap文件映射:为了减少拷贝对CPU的利用率,在应用程序端只记录page cache的索引映射,读数据索引的话更快,写数据通过操作系统暴露出来的接口写入,底层由操作系统从page cache借助CPU拷贝到Socket缓冲区,最后通过DMA拷贝到目标网络位置
- sendfile文件传输机制:这种机制可以理解为用户态,也就是应用程序不再关注数据的内容,只是向内核态发一个sendfile指令,要他去复制文件就行了。这样数据就完全不用复制到用户态,从而实现了零拷贝。
4、合理配置刷盘频率
刷盘操作在Linux系统中对应了一个fsync的系统调用,最安全的方式就是写一条数据刷一次盘(显然不可能这样)
Kafka在服务端设计了几个参数,来控制刷盘的频率:
- flush.ms : 多长时间进行一次强制刷盘。
- log.flush.interval.messages:表示当同一个Partiton的消息条数积累到这个数量时,就会申请一次刷盘操作。默认是Long.MAX。
- log.flush.interval.ms:当一个消息在内存中保留的时间,达到这个数量时,就会申请一次刷盘操作。他的默认值是空。如果这个参数配置为空,则生效的是下一个参数。
- log.flush.scheduler.interval.ms:检查是否有日志文件需要进行刷盘的频率。默认也是Long.MAX。
5、客户端消费进度管理
kafka为了实现分组消费的消息转发机制,需要在Broker端保持每个消费者组的消费进度。而这些消费进度,就被Kafka管理在自己的一个内置Topic中。这个Topic就是__consumer__offsets。这是Kafka内置的一个系统Topic,在日志文件可以看到这个Topic的相关目录。Kafka默认会将这个Topic划分为50个分区。
启动一个消费者订阅这个Topic中的消息
bin/kafka-console-consumer.sh --topic __consumer_offsets --bootstrap-server 127.0.0.1:9092 --consumer.config config/consumer.properties --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --from-beginning
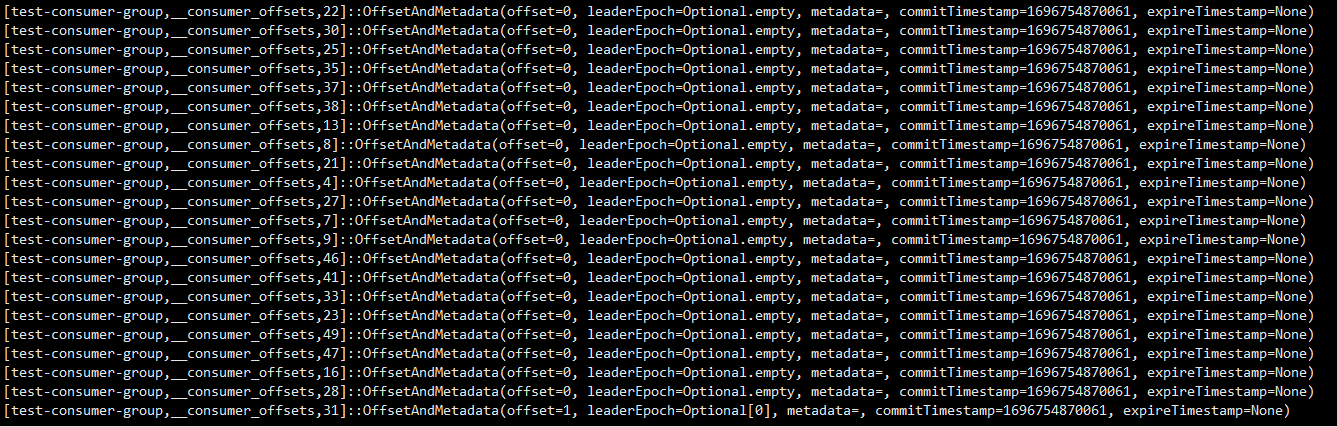
从这里可以看到,Kafka也是像普通数据一样,以Key-Value的方式来维护消费进度。key是groupid+topic+partition,value则是表示当前的offset。
而这些Offset数据,其实也是可以被消费者修改的,在之前章节已经演示过消费者如何从指定的位置开始消费消息。而一旦消费者主动调整了Offset,Kafka当中也会更新对应的记录。
二、kafka生产调优
1、搭建kafka监控平台
生产环境通常会对Kafka搭建监控平台。而Kafka-eagle就是一个可以监控Kafka集群整体运行情况的框架,在生产环境经常会用到。官网地址:EFAK 以前叫做Kafka-eagle,现在用了个简写,EFAK(Eagle For Apache Kafka)
EFAK需要依赖的环境主要是Java和数据库。其中,数据库支持本地化的SQLLite以及集中式的MySQL。生产环境建议使用MySQL。在搭建EFAK之前,需要准备好对应的服务器以及MySQL数据库。
安装过程:以Linux服务器为例。
1、将efak压缩包解压。
tar -zxvf efak-web-3.0.2-bin.tar.gz -C /app/kafka/eagle
2、修改efak解压目录下的conf/system-config.properties。 这个文件中提供了完整的配置,下面只列出需要修改的部分。
######################################
# multi zookeeper & kafka cluster list
# Settings prefixed with 'kafka.eagle.' will be deprecated, use 'efak.' instead
######################################
# 指向Zookeeper地址
efak.zk.cluster.alias=cluster1
cluster1.zk.list=worker1:2181,worker2:2181,worker3:2181
######################################
# zookeeper enable acl
######################################
# Zookeeper权限控制
cluster1.zk.acl.enable=false
cluster1.zk.acl.schema=digest
#cluster1.zk.acl.username=test
#cluster1.zk.acl.password=test123
######################################
# kafka offset storage
######################################
# offset选择存在kafka中。
cluster1.efak.offset.storage=kafka
#cluster2.efak.offset.storage=zk
######################################
# kafka mysql jdbc driver address
######################################
#指向自己的MySQL服务。库需要提前创建
efak.driver=com.mysql.cj.jdbc.Driver
efak.url=jdbc:mysql://worker1:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
efak.username=root
efak.password=root
3、配置EFAK的环境变量
vi ~/.bash_profile
-- 配置KE_HOME环境变量,并添加到PATH中。
export KE_HOME=/app/kafka/eagle/efak-web-3.0.2
PATH=$PATH:#KE_HOME/bin:$HOME/.local/bin:$HOME/bin
--让环境变量生效
source ~/.bash_profile
4、启动EFAK
配置完成后,先启动Zookeeper和Kafka服务,然后调用EFAK的bin目录下的ke.sh脚本启动服务
[oper@worker1 bin]$ ./ke.sh start
-- 日志很长,看到以下内容表示服务启动成功
[2023-06-28 16:09:43] INFO: [Job done!]
Welcome to
______ ______ ___ __ __
/ ____/ / ____/ / | / //_/
/ __/ / /_ / /| | / ,<
/ /___ / __/ / ___ | / /| |
/_____/ /_/ /_/ |_|/_/ |_|
( Eagle For Apache Kafka® )
Version v3.0.2 -- Copyright 2016-2022
*******************************************************************
* EFAK Service has started success.
* Welcome, Now you can visit 'http://192.168.232.128:8048'
* Account:admin ,Password:123456
*******************************************************************
* <Usage> ke.sh [start|status|stop|restart|stats] </Usage>
* <Usage> https://www.kafka-eagle.org/ </Usage>
*******************************************************************
5、访问EFAK管理页面
接下来就可以访问EFAK的管理页面。http://192.168.232.128:8048。 默认的用户名是admin ,密码是123456
关于EFAK更多的使用方式,比如EFAK服务如何集群部署等,可以参考官方文档。
2、合理规划kafka部署环境
机械硬盘:对于准备部署Kafka服务的服务器,建议配置大容量机械硬盘。Kakfa顺序读写的实现方式不太需要SSD这样高性能的磁盘。同等容量SSD硬盘的成本比机械硬盘要高出非常多,没有必要。将SSD的成本投入到MySQL这类的服务更合适。
大内存:在Kafka的服务启动脚本bin/kafka-start-server.sh中,对于JVM内存的规划是比较小的,可以根据之前JVM调优专题中的经验进行适当优化。
脚本中的JVM内存参数默认只申请了1G内存。
[oper@worker1 bin]$ cat kafka-server-start.sh
......
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
fi
......
对于主流的16核32G服务器,可以适当扩大Kafka的内存。例如:
export KAFKA_HEAP_OPTS="‐Xmx16G ‐Xms16G ‐Xmn10G ‐XX:MetaspaceSize=256M ‐XX:+UseG1GC ‐XX:MaxGCPauseMillis=50 ‐XX:G1HeapRegionSize=16M"
高性能网卡:Kafka本身的服务性能非常高,单机就可以支持百万级的TPS。在高流量冲击下,网络非常有可能优先于服务,成为性能瓶颈。并且Kafka集群内部也需要大量同步消息。因此,对于Kafka服务器,建议配置高性能的网卡。成本允许的话,尽量选择千兆以上的网卡。
3、合理优化kafka集群配置
合理配置Partition数量: Kafka的单个Partition读写效率是非常高的,但是,Kafka的Partition设计是非常碎片化的。如果Partition文件过多,很容易严重影响Kafka的整体性能。
控制Partition文件数量主要有两个方面: 1、尽量不要使用过多的Topic,通常不建议超过3个Topic。过多的Topic会加大索引Partition文件的压力。2、每个Topic的副本数不要设置太多。大部分情况下,将副本数设置为2就可以了。
至于Partition的数量,最好根据业务情况灵活调整。partition数量设置多一些,可以一定程度增加Topic的吞吐量。但是过多的partition数量还是同样会带来partition索引的压力。因此,需要根据业务情况灵活进行调整,尽量选择一个折中的配置。
Kafka提供了一个生产者的性能压测脚本,可以用来衡量集群的整体性能。
[oper@worker1 bin]$ ./kafka-producer-perf-test.sh --topic test --num-record 1000000 --record-size 1024 --throughput -1 --producer-props bootstrap.servers=worker1:9092 acks=1
94846 records sent, 18969.2 records/sec (18.52 MB/sec), 1157.4 ms avg latency, 1581.0 ms max latency.
133740 records sent, 26748.0 records/sec (26.12 MB/sec), 1150.6 ms avg latency, 1312.0 ms max latency.
146760 records sent, 29346.1 records/sec (28.66 MB/sec), 1051.5 ms avg latency, 1164.0 ms max latency.
137400 records sent, 27480.0 records/sec (26.84 MB/sec), 1123.7 ms avg latency, 1182.0 ms max latency.
158700 records sent, 31740.0 records/sec (31.00 MB/sec), 972.1 ms avg latency, 1022.0 ms max latency.
158775 records sent, 31755.0 records/sec (31.01 MB/sec), 963.5 ms avg latency, 1055.0 ms max latency.
1000000 records sent, 28667.259123 records/sec (28.00 MB/sec), 1030.44 ms avg latency, 1581.00 ms max latency, 1002 ms 50th, 1231 ms 95th, 1440 ms 99th, 1563 ms 99.9th.
其中num-record表示要发送100000条压测消息,record-size表示每条消息大小1KB,throughput表示限流控制,设置为小于0表示不限流。properducer-props用来设置生产者的参数。
例如合理对数据进行压缩
在生产者的ProducerConfig中,有一个配置 COMPRESSION_TYPE_CONFIG,是用来对消息进行压缩的。
/** <code>compression.type</code> */
public static final String COMPRESSION_TYPE_CONFIG = "compression.type";
private static final String COMPRESSION_TYPE_DOC = "The compression type for all data generated by the producer. The default is none (i.e. no compression). Valid "
+ " values are <code>none</code>, <code>gzip</code>, <code>snappy</code>, <code>lz4</code>, or <code>zstd</code>. "
+ "Compression is of full batches of data, so the efficacy of batching will also impact the compression ratio (more batching means better compression).";
生产者配置了压缩策略后,会对生产的每个消息进行压缩,从而降低Producer到Broker的网络传输,也降低了Broker的数据存储压力。
从介绍中可以看到,Kafka的生产者支持四种压缩算法。这几种压缩算法中,zstd算法具有最高的数据压缩比,但是吞吐量不高。lz4在吞吐量方面的优势比较明显。在实际使用时,可以根据业务情况选择合适的压缩算法。但是要注意下,压缩消息必然增加CPU的消耗,如果CPU资源紧张,就不要压缩了。
关于数据压缩机制,在Broker端的broker.conf文件中,也是可以配置压缩算法的。正常情况下,Broker从Producer端接收到消息后不会对其进行任何修改,但是如果Broker端和Producer端指定了不同的压缩算法,就会产生很多异常的表现。
compression.type
Specify the final compression type for a given topic. This configuration accepts the standard compression codecs ('gzip', 'snappy', 'lz4', 'zstd'). It additionally accepts 'uncompressed' which is equivalent to no compression; and 'producer' which means retain the original compression codec set by the producer.
Type: string
Default: producer
Valid Values: [uncompressed, zstd, lz4, snappy, gzip, producer]
Server Default Property: compression.type
Importance: medium
如果开启了消息压缩,那么在消费者端自然是要进行解压缩的。在Kafka中,消息从Producer到Broker再到Consumer会一直携带消息的压缩方式,这样当Consumer读取到消息集合时,自然就知道了这些消息使用的是哪种压缩算法,也就可以自己进行解压了。但是这时要注意的是应用中使用的Kafka客户端版本和Kafka服务端版本是否匹配。
4、优化kafka客户端使用方式
在使用Kafka时,也需要根据业务情况灵活进行调整,选择最合理的Kafka使用方式。
1、合理保证消息安全
在生产者端最好从以下几个方面进行优化。
- 设置好发送者应答参数:主要涉及到两个参数。- 一个是生产者的ACKS_CONFIG配置。acks=0,生产者不关心Broker端有没有将消息写入到Partition,只发送消息就不管了。acks=all or -1,生产者需要等Broker端的所有Partiton(Leader Partition以及其对应的Follower Partition都写完了才能得到返回结果,这样数据是最安全的,但是每次发消息需要等待更长的时间,吞吐量是最低的。acks设置成1,则是一种相对中和的策略。Leader Partition在完成自己的消息写入后,就向生产者返回结果。、其中acks=1是应用最广的一种方案。但是,如果结合服务端的min.insync.replicas参数,就可以配置更灵活的方式。- min.insync.replicas参数表示如果生产者的acks设置为-1或all,服务端并不是强行要求所有Paritition都完成写入再返回,而是可以配置多少个Partition完成消息写入后,再往Producer返回消息。比如,对于一个Topic,设置他的备份因子replication factor为3,然后将min.insync.replicas参数配置为2,而生产者端将ACKS_CONFIG设定为-1或all,这样就能在消息安全性和发送效率之间进行灵活选择。
- 打开生产者端的幂等性配置:ENABLE_IDEMPOTENCE_CONFIG。 生产者将这个参数设置为true后,服务端会根据生产者实例以及消息的目标Partition,进行重复判断,从而过滤掉生产者一部分重复发送的消息。
- 使用生产者事务机制发送消息:
在打开幂等性配置后,如果一个生产者实例需要发送多条消息,而你能够确定这些消息都是发往同一个Partition的,那么你就不需要再过多考虑消息安全的问题。但是如果你不确定这些消息是不是发往同一个Partition,那么尽量使用异步发送消息机制加上事务消息机制进一步提高消息的安全性。
生产者事务机制主要是通过以下一组API来保证生产者往服务端发送消息的事务性。
// 1 初始化事务
void initTransactions();
// 2 开启事务
void beginTransaction() throws ProducerFencedException;
// 3 提交事务
void commitTransaction() throws ProducerFencedException;
// 4 放弃事务(类似于回滚事务的操作)
void abortTransaction() throws ProducerFencedException;
尤其在与Spring框架整合使用时,通常会将Producer作为一个单例放入到Spring容器中,这时候就更需要注意事务消息使用。实际上SpringBoot集成Kafka时使用的KafkaTemplate就是使用事务消息机制发送的消息。
然后在消费者端。Kafka消费消息是有重试机制的,如果消费者没有主动提交事务(自动提交或者手动提交),那么这些失败的消息是可以交由消费者组进行重试的,所以正常情况下,消费者这一端是不会丢失消息的。但是如果消费者要使用异步方式进行业务处理,那么如果业务处理失败,此时消费者已经提交了Offset,这个消息就无法重试了,这就会造成消息丢失。
因此在消费者端,尽量不要使用异步处理方式,在绝大部分场景下,就能够通过Kafka的消费者重试机制,保证消息安全处理。此时,在消费者端,需要更多考虑的问题,就变成了消费重试机制造成的消息重复消费的问题。
2、消费者防止消息重复消费
回顾一下消费者的实现步骤,通常都是这样的处理流程:
while (true) {
//拉取消息
ConsumerRecords<String, String> records = consumer.poll(Duration.ofNanos(100));
//处理消息
for (ConsumerRecord<String, String> record : records) {
//do business ...
}
//提交offset,消息就不会重复推送。
consumer.commitSync(); //同步提交,表示必须等到offset提交完毕,再去消费下一批数据。
}
在大部分的业务场景下,这不会有什么问题。但是在一些大型项目中,消费者的业务处理流程会很长,这时就会带来一些问题。比如,一个消费者在正常处理这一批消息,但是时间需要很长。Broker就有可能认为消息消费失败了,从而让同组的其他消费者开始重试这一批消息。这就给消费者端带来不必要的幂等性问题。
消费者端的幂等性问题,当然可以交给消费者自己进行处理,比如对于订单消息,消费者根据订单ID去确认一下这个订单消息有没有处理过。这种方式当然是可以的,大部分的业务场景下也都是这样处理的。但是这样会给消费者端带来更大的业务复杂性。
但是在很多大型项目中,消费者端的业务逻辑有可能是非常复杂的。这时候要进行幂等性判断,,因此会更希望以一种统一的方式处理幂等性问题,让消费者端能够专注于处理自己的业务逻辑。这时,在大型项目中有一种比较好的处理方式就是将Offset放到Redis中自行进行管理。通过Redis中的offset来判断消息之前是否处理过。伪代码如下:
while(true){
//拉取消息
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
records.partitions().forEach(partition ->{
//从redis获取partition的偏移量
String redisKafkaOffset = redisTemplate.opsForHash().get(partition.topic(), "" + partition.partition()).toString();
long redisOffset = StringUtils.isEmpty(redisKafkaOffset)?-1:Long.valueOf(redisKafkaOffset);
List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);
partitionRecords.forEach(record ->{
//redis记录的偏移量>=kafka实际的偏移量,表示已经消费过了,则丢弃。
if(redisOffset >= record.offset()){
return;
}
//业务端只需要实现这个处理业务的方法就可以了,不用再处理幂等性问题
doMessage(record.topic(),record.value());
});
});
//处理完成后立即保存Redis偏移量
long saveRedisOffset = partitionRecords.get(partitionRecords.size() - 1).offset();
redisTemplate.opsForHash().put(partition.topic(),"" + partition.partition(),saveRedisOffset);
//异步提交。消费业务多时,异步提交有可能造成消息重复消费,通过Redis中的Offset,就可以过滤掉这一部分重复的消息。。
consumer.commitAsync();
}
将这段代码封装成一个抽象类,具体的业务消费者端只要继承这个抽象类,然后就可以专注于实现doMessage方法,处理业务逻辑即可,不用再过多关心幂等性的问题。
5、生产环境常见问题分析
1)、如何保证消息不丢失
- 生产者发送消息到broker,指定ack为1或者-1,1则是等待写入本地log返回成功还是失败,-1则是所有partition全部写入才会返回,可根据返回信息重试
- broker端可以配置刷盘频率,不可能保证极端情况的数据丢失问题
- 消费者端有重试机制正常情况下不会数据丢失
2)、消息积压问题
同一个topic增加和leader partition数量相同数量的消费者,或者新增一个topic把原来topic的数据发到新的topic上面去消费
3)、如何保证消息顺序
生产者可以通过自定义类实现partitioner接口,来发送消息到同一个partition上,消费者端由于是并行消费的,再加上网络原因并不能保证顺序消费
版权归原作者 高如风 所有, 如有侵权,请联系我们删除。