
需要全部源码和数据集请点赞关注收藏后评论区留言私信~~~
SVM简介
支持向量机(support vector machines, SVM)是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机;SVM还包括核技巧,这使它成为实质上的非线性分类器。SVM的的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。SVM的的学习算法就是求解凸二次规划的最优化算法。
非线性SVM算法原理
对于输入空间中的非线性分类问题,可以通过非线性变换将它转化为某个维特征空间中的线性分类问题,在高维特征空间中学习线性支持向量机。由于在线性支持向量机学习的对偶问题里,目标函数和分类决策函数都只涉及实例和实例之间的内积,所以不需要显式地指定非线性变换,而是用核函数替换当中的内积。核函数表示,通过一个非线性转换后的两个实例间的内积
SVM学习的基本想法是求解能够正确划分训练数据集并且几何间隔最大的分离超平面。如下图所示, w⋅x+b=0 即为分离超平面,对于线性可分的数据集来说,这样的超平面有无穷多个(即感知机),但是几何间隔最大的分离超平面却是唯一的。
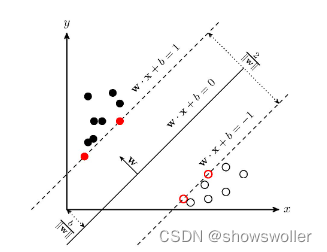
SVM解决非线性问题
实验中用到半环形数据集
结果如下 SVM算法较好的分开了两个区域,强于聚类算法

部分代码如下
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.preprocessing import PolynomialFeatures
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
from sklearn.pipeline import Pipeline
# 生成半环形数据
X, y = make_moons(n_samples=100, noise=0.1, random_state=1)
moonAxe=[-1.5, 2.5, -1, 1.5] #moons数据集的区间
# 显示数据样本
def dispData(x, y, moonAxe):
pos_x0=[x[i,0]for i in range(len(y)) if y[i]==1]
pos_x1=[x[i,1]for i in range(len(y)) if y[i]==1]
neg_x0=[x[i,0]for i in range(len(y)) if y[i]==0]
neg_x1=[x[i,1]for i in range(len(y)) if y[i]==0]
plt.plot(pos_x0, pos_x1, "bo")
plt.plot(neg_x0, neg_x1, "r^")
plt.axis(moonAxe)
plt.xlabel("x")
plt.ylabel("y")
# 显示决策线
def dispPredict(clf, moonAxe):
#生成区间内的数据
d0 = np.linspace(moonAxe[0], moonAxe[1], 200)
d1 = np.linspace(moonAxe[2], moonAxe[3], 200)
xntourf(x0, x1, y_pred, alpha=0.8)
# 1.显示样本
dispData(X, y, moonAxe)
# 2.构建模型组合,整合三个函数
polynomial_svm_clf=Pipeline(
(("multiFeature",PolynomialFeatures(degree=3)),
("NumScale",StandardScaler()),
("SVC",LinearSVC(C=100)))
)
# 3.使用模型组合进行训练
poly类线
dispPredict(polynomial_svm_clf, moonAxe)
# 5.显示图表标题
plt.title('Linear SVM classifies Moons data')
plt.show()
使用SVM进行信用卡欺诈检测
读取数据如下
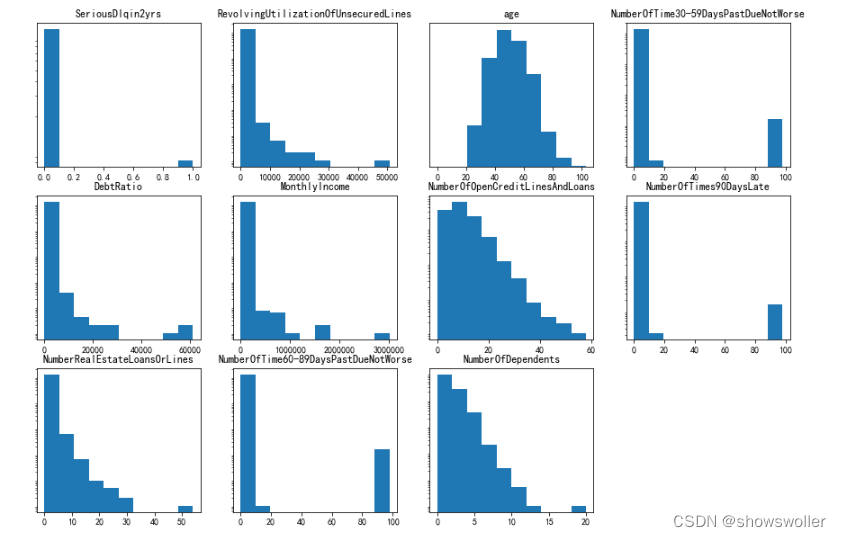
数据可视化如下
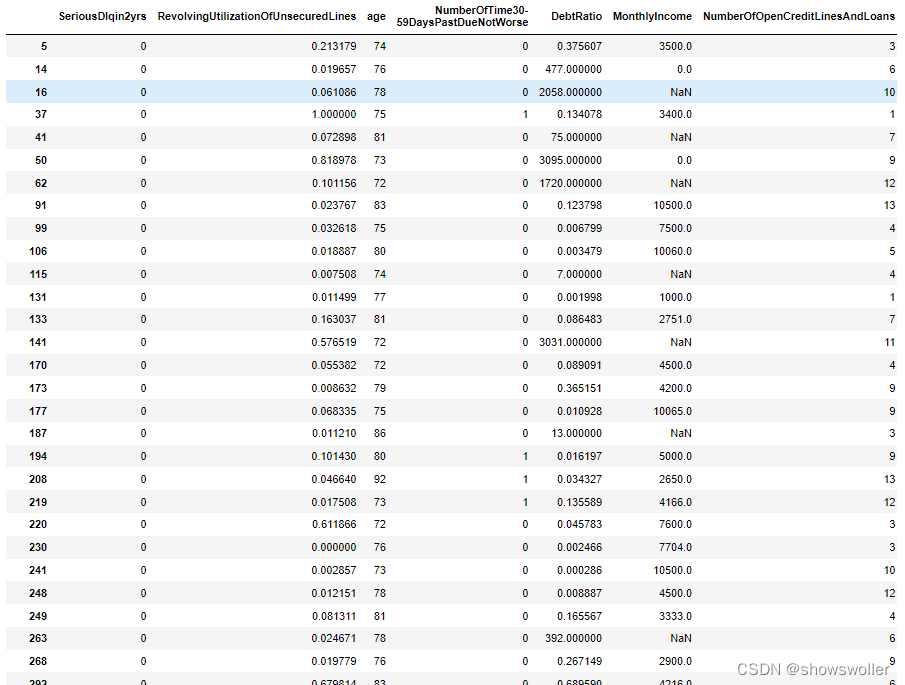
打印出数据中年龄大于70岁的人群信息
预测结果如下
大部分人进行信用卡欺诈的概率还是比较低 精度可以达到百分之九十三左右
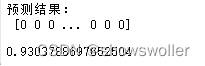
部分代码如下
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
#(1) 载入数据
data = pd.read_csv("data/KaggleCredit2.csv",index_col= 0)
data.dropna(inplace=True)
#(2)对特征列进行标准化
cols = data.columns[1:]
ss = StandardScaler()
data[cols] = ss.fit_transform(data[cols])
#(3)构造数据和标签
X = data.drop('SeriousDlqin2yrs', axis=1) # 数据特征
y = data['SeriousDlqin2yrs'] #标签列
#(4)进行数据切分,测试集占比30%,生成随机数的种子是0
X_train,X_tes
#(5)构建SVM模型
#只使用特征“NumberOfTime60-89DaysPastDueNotWorse”进行SVM分类
from sklearn.svm import SVC
svm = SVC()
svm.fit(X_train[['NumberOfTime60-89DaysPastDueNotWorse']], y_train)
# svm.fit(X_train, y_train) 此句使用的是全部特征,时间耗费长
93%
svm.score(X_test[['NumberOfTime60-89DaysPastDueNotWorse']], y_test)
** 创作不易 觉得有帮助请点赞关注收藏~~~**
本文转载自: https://blog.csdn.net/jiebaoshayebuhui/article/details/128553492
版权归原作者 showswoller 所有, 如有侵权,请联系我们删除。
版权归原作者 showswoller 所有, 如有侵权,请联系我们删除。