
接上篇《37、selenium关于phantomjs的基本使用》
上一篇我们介绍了有关phantomjs的相关知识,但由于selenium已经放弃PhantomJS,本篇我们来学习Chrome的无头版浏览器Chrome Handless的使用。
一、Chrome Headless简介

Chrome Headless是一个无界面的浏览器环境,它是Google Chrome浏览器在59版本之后新增的一种运行模式。与传统的浏览器不同,Chrome Headless可以在后台执行网页操作,而无需显示可见的用户界面。
Chrome Headless提供了一种方便的方式来进行自动化测试、网络爬虫和数据抓取等任务。它通过模拟用户在浏览器中的行为,实现了对网页的自动化操作和交互。在执行过程中,Chrome Headless可以访问和操纵网页的DOM结构、执行JavaScript代码、提交表单、点击按钮等。
由于没有可见的界面,Chrome Headless相比传统浏览器具有一些优势。首先,它更轻量级,节省了系统资源,并且执行速度更快。其次,它稳定性高,不受弹窗、广告或其他干扰因素的影响。此外,Chrome Headless还提供了丰富的调试工具和API,方便开发者进行调试和监控。
使用Selenium框架结合Chrome Headless可以实现自动化测试和网页爬虫等应用场景。开发人员可以利用Selenium的API来编写脚本,控制Chrome Headless执行各种操作,并获取网页内容和处理结果。
二、Chrome Headless安装及使用
1、环境确认
我们使用Chrome Headless之前,首先要确认一下相应的环境是否满足:
(1)Chrome浏览器版本
Unix\Linux操作系统环境下,浏览器版本需要>=59;
Windows操作系统环境下,浏览器版本需要>=60;
(2)软件和框架版本
Python版本>=3.6
Selenium版本>=3.4.*
ChromeDriver>=2.31
2、安装Python和Selenium库
确保我们已经安装了Python,并安装了Selenium库。可以使用命令pip install selenium来进行Selenium库的安装。
3、谷歌浏览器驱动安装
需要安装ChromeDriver,这个我们在学习Selenium框架之前就已经安装过了,这里不再赘述,需要的同学请查看博文《34、selenium基本概念及安装流程》中有关“下载浏览器驱动”的章节。
4、Chrome Headless的使用
和之前使用PhantomJS不同,Chrome Headless已经内置到我们之前下载好的ChromeDriver驱动程序中了,我们只需要设置一下创建ChromeDriver对象的参数即可,将模式改为Headless模式,即可调用Chrome的无头浏览器了。整体需要以下三步:
(1)创建ChromeOptions对象,配置Chrome Headless选项
options = Options()
# 设置Chrome为Headless模式
options.add_argument("--headless")
# 禁用GPU加速
options.add_argument("--disable-gpu")
(2)创建Chrome WebDriver对象,传入ChromeOptions对象
driver = webdriver.Chrome(options=options)
然后使用driver调用需要的API方法即可。
5、Python调用示例
这里以使用Chrome Headless打开百度页面获取其标题为例:
from selenium import webdriver # 导入selenium的webdriver模块
from selenium.webdriver.chrome.options import Options # 导入ChromeOptions模块
# 创建ChromeOptions对象,配置Chrome Headless选项
options = Options()
options.add_argument("--headless") # 设置Chrome为Headless模式
options.add_argument("--disable-gpu") # 禁用GPU加速
# 创建Chrome WebDriver对象,传入ChromeOptions对象
driver = webdriver.Chrome(options=options)
try:
# 打开网页
driver.get("https://www.baidu.com")
print(driver.title) # 打印页面的标题
finally:
# 关闭浏览器
driver.quit()
效果: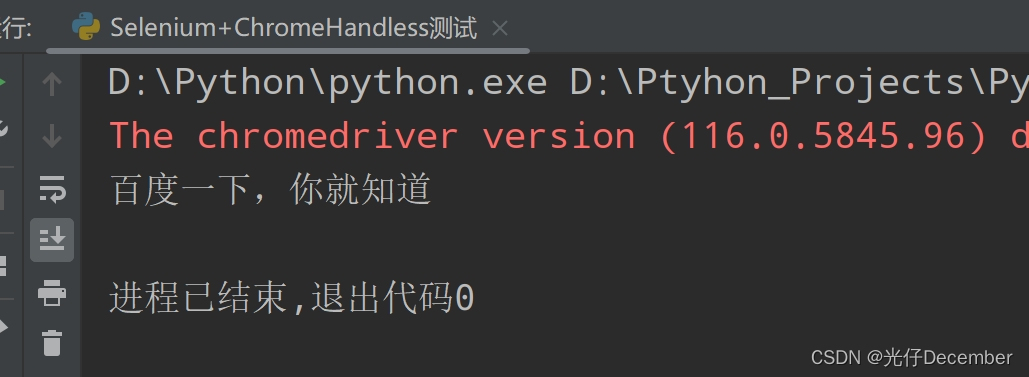
三、Chrome Headless代码实例
和上一篇一样,我们这次通过Chrome Headless来获取百度搜索‘我要学python’的第一个非广告结果,代码如下:
# _*_ coding : utf-8 _*_
# @Time : 2023-10-06 9:04
# @Author : 光仔December
# @File : Selenium+ChromeHandless测试
# @Project : Python基础
from selenium import webdriver # 导入selenium的webdriver模块
from selenium.webdriver.chrome.options import Options # 导入ChromeOptions模块
from selenium.webdriver.common.by import By # 引入By类选择器
# 创建ChromeOptions对象,配置Chrome Headless选项
options = Options()
options.add_argument("--headless") # 设置Chrome为Headless模式
options.add_argument("--disable-gpu") # 禁用GPU加速
# 创建Chrome WebDriver对象,传入ChromeOptions对象
driver = webdriver.Chrome(options=options)
try:
# 打开网页
driver.get("https://www.baidu.com")
print(driver.title) # 打印页面的标题
# (1)通过ID定位百度搜索的按钮
element1 = driver.find_element(By.ID, "su")
# (2)通过名称定位元素(百度的搜索输入框)
element2 = driver.find_element(By.NAME, "wd")
# 给输入框输入字符串“我要学python”
element2.send_keys("我要学python")
element1.click() # 点击搜索
# 使用浏览器隐式等待3秒
driver.implicitly_wait(3)
resultObj = driver.find_element(By.XPATH, "//div[@id=\"content_left\"]//div[@id=\"1\"]")
url = resultObj.get_attribute("mu")
aObj = resultObj.find_element(By.TAG_NAME, "a")
text = aObj.text
# 获取
print("搜索‘我要学python’的第一个非广告结果:")
print("结果标题:", text)
print("地址链接:", url)
finally:
# 关闭浏览器
driver.quit()
效果: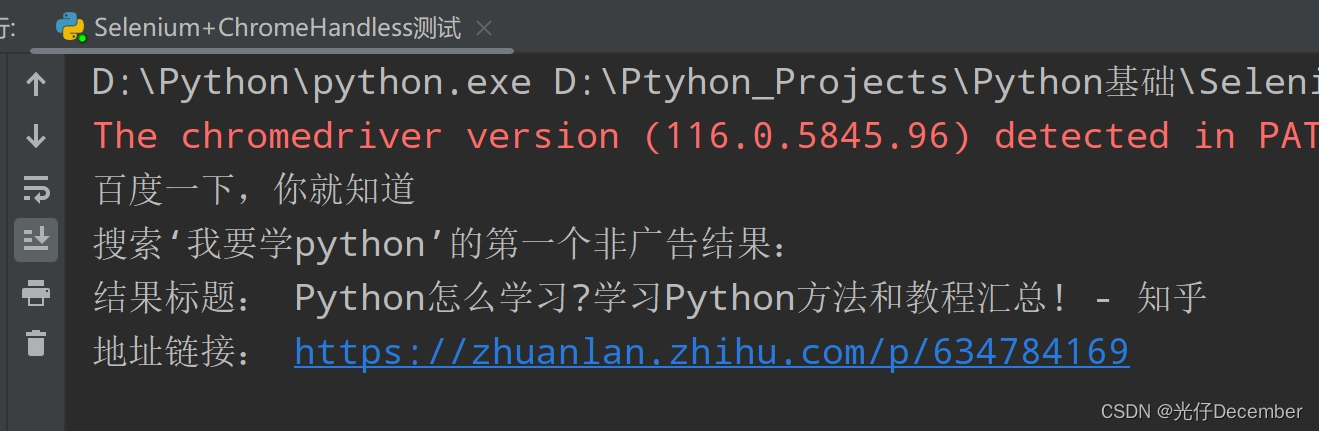
参考:尚硅谷Python爬虫教程小白零基础速通教学视频
转载请注明出处:https://guangzai.blog.csdn.net/article/details/133611724
版权归原作者 光仔December 所有, 如有侵权,请联系我们删除。