
文章目录
1.背景
由于之前一个同事问我mybatisPlus的IService层的saveBatch(Collection entityList)方法批量插入速度实在是太慢了,能否优化下?我过去跟他看了下具体的需求是这样的,一张业务表中有30多万的业务数据,表里的一个字段是一个json的数据字段,要把30多万的数据查出来针对这个json字段解析之后存入另外一张表中,后面他使用了mybatisPlus的IService层的saveBatch发现好慢好慢,,去重是把分页查询出来插入数据的最后一条数据的id存入redis中,每次分页查询数据排序之后id比上一次处理的最后一条数据的id大的数据,如果比该条数据的id小则忽略,后面我给他看了下使用saveBatch插入一批数据1000条大概要好几十分钟的,之前他使用的for循环里面insert每一条处理好的数据,这种是真的非常的慢,慢到你怀疑人生,这个insert方法我在下面的demo中准备数据,往一个表里插入30万条数据的时候使用了下实在是太慢了,后面我使用了一个mybatisPlus的sql注入器的一个批量的方法:
IntegerinsertBatchSomeColumn(Collection<UserEntity> entityList);
使用了该方法之后,在一个测试方法中使用主线程插入模拟的30万数据到一个user的表中只用了:23.209105秒,然后使用多线程异步插入用了:12.1030808秒,这个时间跟机器的性能和网路有关,所以每一次执行这个时间会有所不同的,由于我们使用的数据库是云数据库,所以插入需要走网络,没有使用本地的安装的mysql数据库,使用这个sql批量插入的注入器给那个同事优化了一波之后,他原来使用insertr处理要10个小时后面使用saveBatch也要在2个小时以上,后面优化之后大概估计只要20分钟不到就完了,但是我后面使用这个demo用30万数据,解析一个json字段入库到一张表中是非常快的,就花了10多秒~30多秒的时间就干完了,所以说他那个需求还有优化的空间,后面数据全部跑完之后就不用了,不是我搞所以就能用就行,比原来的效率也是提升了一大截。
2.方案
查询可以使用mybatis的原生sql查询,需要写一个批量插入的方法insert标签中使用foreach遍历一个list然后插入逐条插入数据即可,但是这种需要写大量的代码,还要处理每个插入的字段为空的判断处理,不然遇到插入字段为null就会报错,让人很头疼,所以还是使用mybatisPlus的sql批量注入器基本不需要写啥代码即可实现批量插入操作,而且性能和效率还是杠杆的。
mybatisPlus的IService层的saveBatch为啥慢?看了下它的源码发现底层封装还是比较深,本质上底层还是一条一条的去插入数据,所以才会慢。
mybatisPlus的sql注入器有一下几个可以给我们扩展使用的类:
AlwaysUpdateSomeColumnById根据Id更新每一个字段,全量更新不忽略null字段,解决mybatis-plus中updateById默认会自动忽略实体中null值字段不去更新的问题。InsertBatchSomeColumn真实批量插入,通过单SQL的insert语句实现批量插入DeleteByIdWithFill带自动填充的逻辑删除,比如自动填充更新时间、操作人Upsert更新or插入,根据唯一约束判断是执行更新还是删除,相当于提供insert on duplicate key update支持
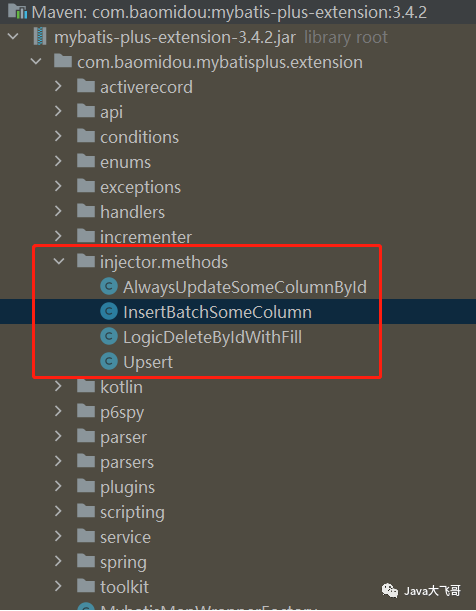
项目中批量sql注入器的使用如下:
新增一个 MySqlInjector类:
packagecom.zlf.sb.demo.sqlinjector;importcom.baomidou.mybatisplus.core.injector.AbstractMethod;importcom.baomidou.mybatisplus.core.injector.DefaultSqlInjector;importcom.baomidou.mybatisplus.extension.injector.methods.InsertBatchSomeColumn;importjava.util.List;publicclassMySqlInjectorextendsDefaultSqlInjector{@OverridepublicList<AbstractMethod>getMethodList(Class<?> mapperClass){List<AbstractMethod> methodList =super.getMethodList(mapperClass);
methodList.add(newInsertBatchSomeColumn());//添加批量插入方法return methodList;}}
将MySqlInjector交给Spring容器管理:新增一个MybatisPlusConfig类如下:
packagecom.zlf.sb.demo.config;importcom.baomidou.mybatisplus.extension.plugins.PaginationInterceptor;importcom.baomidou.mybatisplus.extension.plugins.pagination.optimize.JsqlParserCountOptimize;importcom.zlf.sb.demo.sqlinjector.MySqlInjector;importorg.springframework.context.annotation.Bean;importorg.springframework.context.annotation.Configuration;importorg.springframework.context.annotation.Primary;@ConfigurationpublicclassMybatisPlusConfig{@BeanpublicPaginationInterceptorpaginationInterceptor(){PaginationInterceptor paginationInterceptor =newPaginationInterceptor();// 设置请求的页面大于最大页后操作, true调回到首页,false 继续请求 默认false// paginationInterceptor.setOverflow(false);// 设置最大单页限制数量,默认 500 条,-1 不受限制
paginationInterceptor.setLimit(-1);// 这里也是一个大坑,需要注意的// 开启 count 的 join 优化,只针对部分 left join
paginationInterceptor.setCountSqlParser(newJsqlParserCountOptimize(true));return paginationInterceptor;}@Bean@Primary//批量插入配置publicMySqlInjectormySqlInjector(){returnnewMySqlInjector();}}
UserMapper接口中加入insertBatchSomeColumn方法:
packagecom.zlf.sb.demo.mapper;importcom.baomidou.mybatisplus.core.mapper.BaseMapper;importcom.zlf.sb.demo.entity.UserEntity;importorg.apache.ibatis.annotations.Options;importorg.apache.ibatis.annotations.Param;importorg.apache.ibatis.annotations.Select;importorg.apache.ibatis.cursor.Cursor;importorg.apache.ibatis.mapping.ResultSetType;importorg.springframework.context.annotation.Scope;importorg.springframework.stereotype.Repository;importjava.util.Collection;@Scope("prototype")@RepositorypublicinterfaceUserMapperextendsBaseMapper<UserEntity>{/**
* 批量插入 仅适用于mysql
*
* @param entityList 实体列表
* @return 影响行数
*/IntegerinsertBatchSomeColumn(Collection<UserEntity> entityList);/**
* 统计总数
*
* @return
*/@Select("SELECT count(*) FROM user")IntegercountTotal();/**
* 分页游标查询
*
* @return
*/@Options(resultSetType =ResultSetType.FORWARD_ONLY)@Select("SELECT * FROM user ORDER BY create_time DESC LIMIT #{start}, #{pageSize} ")Cursor<UserEntity>getCursorPageData(@Param("start")Integer start,@Param("pageSize")Integer pageSize);}
准备了两张表:user,user_json_data,user表中有个json_data的字段是一个存json格式数据的字段,然后准备30万的数据,向user表中插入30万条构造的数据,SpringBootDemoApplicationTests中代码如下:
//@TestpublicvoidaddUserDataTest(){StopWatch stopWatch =newStopWatch();// 开始时间
stopWatch.start();int totalData =300000;int splitSize =10000;int splitPages =(totalData + splitSize -1)/ splitSize;/*for (int i = 1; i <= splitPages; i++) {
//起始条数
int firstIndex = (i - 1) * splitSize + 1;
//截止条数
int lastIndex = i * splitSize;
List<UserEntity> userEntityList = new ArrayList<>();
for (int j = firstIndex; j <= lastIndex; j++) {
UserEntity user = new UserEntity();
user.setName("zlf" + j);
user.setAge(j);
JSONObject jo = new JSONObject();
try {
jo.put("name", "zlf" + j);
jo.put("age", j);
} catch (JSONException e) {
throw new RuntimeException(e);
}
//log.info("json:{}",j.toString());
user.setJsonData(jo.toString());
//userMapper.insert(user);
userEntityList.add(user);
}
//userService.saveBatch(userEntityList);
userMapper.insertBatchSomeColumn(userEntityList);
}
// 结束时间
stopWatch.stop();
log.info("执行时长:{}秒", stopWatch.getTotalTimeSeconds());*///执行时长:23.209105秒// 异步ThreadPoolExecutor executor =ThreadPoolService.getInstance();AtomicInteger count =newAtomicInteger(0);CountDownLatch countDownLatch =newCountDownLatch(splitPages);for(int i =1; i <= splitPages; i++){int finalI = i;CompletableFuture.runAsync(()->{//起始条数int firstIndex =(finalI -1)* splitSize +1;//截止条数int lastIndex = finalI * splitSize;List<UserEntity> userEntityList =newArrayList<>();for(int j = firstIndex; j <= lastIndex; j++){UserEntity user =newUserEntity();
user.setName("zlf"+ j);
user.setAge(j);JSONObject jo =newJSONObject();try{
jo.put("name","zlf"+ j);
jo.put("age", j);}catch(JSONException e){thrownewRuntimeException(e);}//log.info("json:{}",j.toString());
user.setJsonData(jo.toString());//userMapper.insert(user);
userEntityList.add(user);}
count.getAndAdd(userEntityList.size());
userMapper.insertBatchSomeColumn(userEntityList);//userService.saveBatch(userEntityList);
countDownLatch.countDown();}, executor);}try{
countDownLatch.await();//保证之前的所有的线程都执行完成,才会走下面的;}catch(InterruptedException e){thrownewRuntimeException(e);}// 结束时间
stopWatch.stop();
log.info("total:{},执行时长:{}秒", count.get(), stopWatch.getTotalTimeSeconds());// total:300000,执行时长:12.1030808秒}
2.1 多线程分页查询 、 生产者消费者模型、多线程sql注入器批量插入
测试用例的方法:
@TestpublicvoidqueryInsertDataTest(){
userService.queryInsertData();}
UserServiceImpl类中的方法:
/**
* 多线程分页查询
* 生产者+消费者模型
* 多线程插入
*/@OverridepublicvoidqueryInsertData(){StopWatch stopWatch =newStopWatch();// 开始时间
stopWatch.start();Page<UserEntity> page =newPage<>(1,10);QueryWrapper<UserEntity> queryWrapper =newQueryWrapper<>();
queryWrapper.lambda().orderByDesc(UserEntity::getCreateTime);Page<UserEntity> pageResult =this.getBaseMapper().selectPage(page, queryWrapper);int pageSize =10000;if(Objects.nonNull(pageResult)){long total = pageResult.getTotal();int pages =(int)((total + pageSize -1)/ pageSize);
log.info("pages:{}", pages);ThreadPoolExecutor executor =ThreadPoolService.getInstance();CountDownLatch countDownLatch1 =newCountDownLatch(pages);CountDownLatch countDownLatch2 =newCountDownLatch(pages);LinkedBlockingQueue<List<UserJsonDataEntity>> linkedBlockingQueue = userJsonDataService.getLinkedBlockingQueue();for(int i =1; i <= pages; i++){try{QueryDoBizProducer queryDoBizProducer =newQueryDoBizProducer(linkedBlockingQueue, i, queryCount, countDownLatch1, pageSize);CompletableFuture.runAsync(queryDoBizProducer, executor);}catch(Exception e){
log.info("异常1:{}", e.getMessage());}}try{
countDownLatch1.await();}catch(InterruptedException e){
log.info("异常2:{}", e.getMessage());}for(int i =1; i <= pages; i++){try{InsertDataConsumer insertDataConsumer =newInsertDataConsumer(linkedBlockingQueue, insertCount, countDownLatch2);CompletableFuture.runAsync(insertDataConsumer, executor);}catch(Exception e){
log.info("异常3:{}", e.getMessage());}}try{
countDownLatch2.await();}catch(InterruptedException e){
log.info("异常4:{}", e.getMessage());}
log.info("queryCount:{}", queryCount);
log.info("insertCount:{}", insertCount);}// 结束时间
stopWatch.stop();
log.info("执行时长:{}秒", stopWatch.getTotalTimeSeconds());// 执行时长:18.903922秒}
自定义单例线程池ThreadPoolService:
packagecom.zlf.sb.demo.service;importjava.util.concurrent.Executors;importjava.util.concurrent.LinkedBlockingDeque;importjava.util.concurrent.ThreadPoolExecutor;importjava.util.concurrent.TimeUnit;/**
* @author zlf
* @description:
* @time: 2022/7/13 10:18
*/publicclassThreadPoolService{/**
* CPU 密集型:核心线程数 = CPU核数 + 1
* <p>
* IO 密集型:核心线程数 = CPU核数 * 2
* <p>
* 注意:IO密集型 (某大厂实战经验)
* 核心线程数 = CPU核数 / (1 - 阻塞系数)
* 例如阻塞系数为0.8 ,CPU核数为 4 ,则核心线程数为 20
*/privatestaticfinalint DEFAULT_CORE_SIZE =Runtime.getRuntime().availableProcessors()*2;privatestaticfinalint MAX_QUEUE_SIZE =100;privatestaticfinalint QUEUE_INIT_MAX_SIZE =200;privatevolatilestaticThreadPoolExecutor executor;privateThreadPoolService(){}// 获取单例的线程池对象publicstaticThreadPoolExecutorgetInstance(){if(executor ==null){synchronized(ThreadPoolService.class){if(executor ==null){
executor =newThreadPoolExecutor(DEFAULT_CORE_SIZE,// 核心线程数
MAX_QUEUE_SIZE,// 最大线程数Integer.MAX_VALUE,// 闲置线程存活时间TimeUnit.MILLISECONDS,// 时间单位newLinkedBlockingDeque<Runnable>(QUEUE_INIT_MAX_SIZE),// 线程队列Executors.defaultThreadFactory()// 线程工厂);}}}return executor;}publicvoidexecute(Runnable runnable){if(runnable ==null){return;}
executor.execute(runnable);}// 从线程队列中移除对象publicvoidcancel(Runnable runnable){if(executor !=null){
executor.getQueue().remove(runnable);}}}
生产者代码:
packagecom.zlf.sb.demo.producer;importcom.alibaba.fastjson.JSONObject;importcom.alibaba.fastjson.TypeReference;importcom.baomidou.mybatisplus.core.conditions.query.QueryWrapper;importcom.baomidou.mybatisplus.extension.plugins.pagination.Page;importcom.zlf.sb.demo.entity.UserEntity;importcom.zlf.sb.demo.entity.UserJsonDataEntity;importcom.zlf.sb.demo.mapper.UserMapper;importcom.zlf.sb.demo.util.SpringUtils;importlombok.extern.slf4j.Slf4j;importjava.util.ArrayList;importjava.util.List;importjava.util.Objects;importjava.util.concurrent.CountDownLatch;importjava.util.concurrent.LinkedBlockingQueue;importjava.util.concurrent.atomic.AtomicInteger;@Slf4jpublicclassQueryDoBizProducerimplementsRunnable{privateLinkedBlockingQueue<List<UserJsonDataEntity>> linkedBlockingQueue;privateAtomicInteger count;privateUserMapper mapper;privatelong current;privateint pageSize;privateCountDownLatch countDownLatch;publicQueryDoBizProducer(LinkedBlockingQueue<List<UserJsonDataEntity>> linkedBlockingQueue,long current,AtomicInteger count,CountDownLatch countDownLatch,int pageSize)throwsException{this.linkedBlockingQueue = linkedBlockingQueue;this.mapper =SpringUtils.getBean(UserMapper.class);this.current = current;this.count = count;this.countDownLatch = countDownLatch;this.pageSize = pageSize;}@Overridepublicvoidrun(){try{Page<UserEntity> page2 =newPage<>(current, pageSize);QueryWrapper<UserEntity> queryWrapper2 =newQueryWrapper<>();
queryWrapper2.lambda().orderByDesc(UserEntity::getCreateTime);Page<UserEntity> pageData = mapper.selectPage(page2, queryWrapper2);if(Objects.nonNull(pageData)){List<UserEntity> records = pageData.getRecords();List<UserJsonDataEntity> list =newArrayList<>();for(UserEntity rs : records){UserJsonDataEntity jd =JSONObject.parseObject(rs.getJsonData(),newTypeReference<UserJsonDataEntity>(){});
list.add(jd);}
linkedBlockingQueue.put(list);
count.getAndAdd(list.size());
log.info("生产者查询数据放入队列完成---->ThreadName:{}",Thread.currentThread().getName());}
countDownLatch.countDown();}catch(Exception e){
e.printStackTrace();
log.error("加入队列异常:{}", e.getMessage());}}}
消费者代码:
packagecom.zlf.sb.demo.consumer;importcn.hutool.core.collection.CollectionUtil;importcom.alibaba.fastjson.JSON;importcom.zlf.sb.demo.entity.UserJsonDataEntity;importcom.zlf.sb.demo.mapper.UserJsonDataMapper;importcom.zlf.sb.demo.util.SpringUtils;importlombok.extern.slf4j.Slf4j;importjava.util.List;importjava.util.concurrent.CountDownLatch;importjava.util.concurrent.LinkedBlockingQueue;importjava.util.concurrent.atomic.AtomicInteger;@Slf4jpublicclassInsertDataConsumerimplementsRunnable{privateLinkedBlockingQueue<List<UserJsonDataEntity>> linkedBlockingQueue;privateAtomicInteger count;privateUserJsonDataMapper mapper;privateCountDownLatch countDownLatch;publicInsertDataConsumer(LinkedBlockingQueue<List<UserJsonDataEntity>> linkedBlockingQueue,AtomicInteger count,CountDownLatch countDownLatch){this.linkedBlockingQueue = linkedBlockingQueue;this.count = count;this.mapper =SpringUtils.getBean(UserJsonDataMapper.class);this.countDownLatch = countDownLatch;}@Overridepublicvoidrun(){if(CollectionUtil.isNotEmpty(linkedBlockingQueue)){try{List<UserJsonDataEntity> dataList = linkedBlockingQueue.take();if(CollectionUtil.isNotEmpty(dataList)){
log.info("dataList:{}", JSON.toJSONString(dataList));
mapper.insertBatchSomeColumn(dataList);
log.info("消费者插入数据完成---->ThreadName:{}",Thread.currentThread().getName());
count.getAndAdd(dataList.size());}
countDownLatch.countDown();}catch(Exception e){
e.printStackTrace();
log.error("消费者插入数据:{}", e.getMessage());}}}}
阻塞队列在UserJsonDataServiceImpl类中:
packagecom.zlf.sb.demo.service.impl;importcom.baomidou.mybatisplus.extension.service.impl.ServiceImpl;importcom.zlf.sb.demo.entity.UserJsonDataEntity;importcom.zlf.sb.demo.mapper.UserJsonDataMapper;importcom.zlf.sb.demo.service.IUserJsonDataService;importlombok.Data;importlombok.extern.slf4j.Slf4j;importorg.springframework.stereotype.Service;importjava.util.List;importjava.util.concurrent.LinkedBlockingQueue;@Data@Service@Slf4jpublicclassUserJsonDataServiceImplextendsServiceImpl<UserJsonDataMapper,UserJsonDataEntity>implementsIUserJsonDataService{privateLinkedBlockingQueue<List<UserJsonDataEntity>> linkedBlockingQueue =newLinkedBlockingQueue<>();}
这种方式如果数据量太大了阻塞队列中的存储了太多的数据,有可能OOM,30万数据本地跑一点压力都没有,轻轻松松就搞定了,但是数据量太大就需要JVM调下优了,这种方式不用管是spring的事务管理,如果使用mysql数据spring的事务传播级别是:ISOLATION_REPEATABLE_READ,可重复读:可以防止脏读和不可重复读,但是幻读仍可能发生,如果使用oracle数据库spring的事务传播级别是:ISOLATION_READ_COMMITTED,读已提交,可防止脏读,幻读和不可重复读仍可能发生,所以事务默认即可。
2.2 游标查询sql注入器批量插入
测试用例:
@TestpublicvoidcursorQueryInsertData(){
userService.cursorQueryInsertData();}
UserServiceImpl类中的方法:
/**
* 游标查询
*/@OverridepublicvoidcursorQueryInsertData(){StopWatch stopWatch =newStopWatch();// 开始时间
stopWatch.start();int total = userMapper.countTotal();if(total >0){int pageSize =10000;int pages =(total + pageSize -1)/ pageSize;for(int i =1; i <= pages; i++){List<UserJsonDataEntity> userJsonDataEntities =newArrayList<>();int start =(i -1)* pageSize;try(SqlSession sqlSession = sqlSessionFactory.openSession();Cursor<UserEntity> pageCursor = sqlSession.getMapper(UserMapper.class).getCursorPageData(start, pageSize)){int currentIndex = pageCursor.getCurrentIndex();
log.info("currentIndex1:{}", currentIndex);Iterator<UserEntity> iterator = pageCursor.iterator();while(iterator.hasNext()){UserEntity userEntity = iterator.next();// log.info("userEntity:{}", JSON.toJSONString(userEntity));UserJsonDataEntity jd =com.alibaba.fastjson.JSONObject.parseObject(userEntity.getJsonData(),newTypeReference<UserJsonDataEntity>(){});
userJsonDataEntities.add(jd);}}catch(Exception e){
log.error("游标分页查询异常:{}", e.getMessage());}
log.info("userJsonDataEntities:{}", userJsonDataEntities.size());
userJsonDataMapper.insertBatchSomeColumn(userJsonDataEntities);}}// 结束时间
stopWatch.stop();
log.info("执行时长:{}秒", stopWatch.getTotalTimeSeconds());//执行时长:39.5655331秒}
2.3 多线程分页查询 、 生产者消费者模型、多线程往ES中按时间维度划分的索引中写入数据
查询user表中的数据可以按照时间段查询,可以根据年、月查询,然后多线程查询出一批数据之后根据原始数据创建一个ES的索引,将各个时间段的数据存放在各自的索引中,这样根据时间段划分数据到对应的索引上,在多线程往ES各自时间段的索引中写入数据的时候就可以并发并行的去操作各自的索引,而不是去并发的去操作一个索引,这是需要特别注意的一点,使用ES要特别注意:有事务场景下不要使用ES,要控制好并发,不要并发的去操作一个索引,这种一定会翻车的。将数据写入到ES各自的索引后,可以根据时间段去从各自的索引中查数据,这种极大的提高了效率和性能,有兴趣的可以去尝试下这个方案。
2.4 查询数据量较小的情况采用List分片的方法
查询数据量小的情况下可以将查询结果的List分片多线程处理每一个分片的数据
2.4.1 使用 Google 的 Guava 框架实现分片
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>31.0.1-jre</version>
</dependency>
importcom.google.common.collect.Lists;importjava.util.Arrays;importjava.util.List;/**
* Guava 分片
*/publicclassPartitionByGuavaExample{// 原集合privatestaticfinalList<String> OLD_LIST =Arrays.asList("唐僧,悟空,八戒,沙僧,曹操,刘备,孙权".split(","));publicstaticvoidmain(String[] args){// 集合分片List<List<String>> newList =Lists.partition(OLD_LIST,3);// 打印分片集合
newList.forEach(i ->{System.out.println("集合长度:"+ i.size());});}}
2.4.2 使用 Apache 的 commons 框架实现分片
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-collections4</artifactId>
<version>4.4</version>
</dependency>
importorg.apache.commons.collections4.ListUtils;importjava.util.Arrays;importjava.util.List;/**
* commons.collections4 集合分片
*/publicclassPartitionExample{// 原集合privatestaticfinalList<String> OLD_LIST =Arrays.asList("唐僧,悟空,八戒,沙僧,曹操,刘备,孙权".split(","));publicstaticvoidmain(String[] args){// 集合分片List<List<String>> newList =ListUtils.partition(OLD_LIST,3);
newList.forEach(i ->{System.out.println("集合长度:"+ i.size());});}}
2.4.3 使用国产神级框架 Hutool 实现分片
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.7.14</version>
</dependency>
importcn.hutool.core.collection.ListUtil;importjava.util.Arrays;importjava.util.List;publicclassPartitionByHutoolExample{// 原集合privatestaticfinalList<String> OLD_LIST =Arrays.asList("唐僧,悟空,八戒,沙僧,曹操,刘备,孙权".split(","));publicstaticvoidmain(String[] args){// 分片处理List<List<String>> newList =ListUtil.partition(OLD_LIST,3);
newList.forEach(i ->{System.out.println("集合长度:"+ i.size());});}}
2.4.4 自定义实现分片
if(listServiceResult.isSucceed()&& listServiceResult.getData().size()>0){List<AgentAO> resultData = listServiceResult.getData();int totalSize = listServiceResult.getData().size();// 总记录数int pageCount =0;// 页数int pageSize =50;// 每页50条if(totalSize <50){
pageCount =1;}int mod = totalSize % pageSize;if(pageCount >0){
pageCount = totalSize / pageSize +1;}else{
pageCount = totalSize / pageSize;}for(int i =0; i < pageCount; i++){List<AgentAO> subList1 =shipLogic(resultData, pageCount, pageSize, i, mod);if(CollectionUtil.isNotEmpty(subList1)){// TODO 处理数据}}}
切分数据的两个方法:
/**
* 切割数据
*
* @param data
* @param pageCount
* @param pageSize
* @param i
* @param mod
* @return
*/privateList<AgentAO>shipLogic(List<AgentAO> data,int pageCount,int pageSize,int i,int mod){List<AgentAO> subList;int startIndex =0;int endIndex =0;if(pageCount ==1){return data;}else{if(mod ==0){
startIndex = i * pageSize;
endIndex =(i +1)* pageSize -1;}else{
startIndex = i * pageSize;if(i == pageCount -1){
endIndex = i * pageSize + mod;}else{
endIndex =(i +1)* pageSize;}}}System.out.println("startIndex="+ startIndex +",endIndex="+ endIndex);
subList = data.subList(startIndex, endIndex);return subList;}/**
* 切割数据
* 使用 JDK 8 中提供 Stream 实现分片
*/private<T>List<List<T>>splitList(List<T> list,int batchSzie){if(CollectionUtils.isEmpty(list)){returnnull;}if(list.size()<= batchSzie){returnArrays.asList(list);}int limit =(list.size()+ batchSzie -1)/ batchSzie;List<List<T>> splitList =Stream.iterate(0, n -> n +1).limit(limit).parallel().map(a -> list.stream().skip(a * batchSzie).limit(batchSzie).parallel().collect(Collectors.toList())).collect(Collectors.toList());return splitList;}publicstaticvoidmain(String[] args){List<String> data =newArrayList<>();for(int i=0;i<1000;i++){
data.add(String.valueOf(i));}MessagePlanService ms =newMessagePlanService();List<List<String>> result = ms.splitList(data,500);System.out.println(result.size());for(int j=0;j<result.size();j++){List<String> d = result.get(j);for(int g=0;g<d.size();g++){System.out.println(d.get(g));}}}
mybatisPlus将一个List结果转换为一个Page分页对象:
if(CollectionUtils.isNotEmpty(wmOfpk)){
pageInfo.setTotal(wmOfpk.size());// 计算总页数
pages =(wmOfpk.size()+ whiteListPageDTO.getSize()-1)/ whiteListPageDTO.getSize();
pageInfo.setPages(pages);if(pageInfo.getCurrent()> pages){
pageInfo.setCurrent(pages);}long start =(pageInfo.getCurrent()-1)* whiteListPageDTO.getSize();long end = pageInfo.getCurrent()* whiteListPageDTO.getSize();if(start !=0){
start = start -1;}if(pageInfo.getCurrent()== pages){
end = wmOfpk.size()-1;}return pageInfo.setRecords(wmOfpk.subList((int) start,(int) end));}else{
pageInfo.setTotal(0);
pageInfo.setPages(0);return pageInfo.setRecords(null);}
3.总结
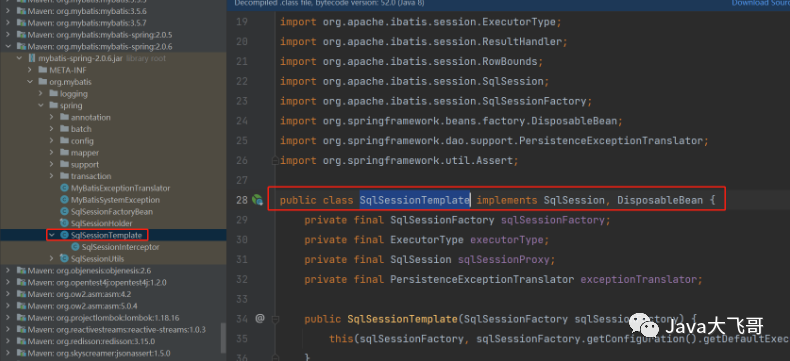
原来我使用多线程写入遇到了事务问题,导致插入到表中的数据每次执行都会少了,后面才知道是myBatis使用的是DefaultSqlSession获取会话的这个类是不安全,所以我才使用mybatis-Spring包下面的的这个SqlSessionTemplate的类提供的方法,自己写了一个原生的mybatis的批量更新的方法,Dao层的Mapper没有集成myBatisPlus的BaseMapper,批量方法就是要处理全部的字段,然后有插入的实体中空的字段没有做判断的就会报错,所以需要判空:
<updateid="updateBatch"parameterType="java.util.List"><foreachcollection="list"item="item"index="index"open=""close=""separator=";">
update xxxxxxxx
<trimprefix="set"suffixOverrides=","><iftest=" item.id != null ">
id = #{item.id, jdbcType=INTEGER},
</if><iftest=" item.xxxxx != null ">
xxxxx = #{item.xxxxx, jdbcType=INTEGER},
</if><iftest="item.xxxxx != null and item.xxxx.trim() neq ''">
order_no = #{item.xxxx, jdbcType=VARCHAR},
</if></trim><where>
id = #{item.id, jdbcType=INTEGER}
</where></foreach></update>
然后调用可以成功的插入:
//批量更新数据 Dao类的全路径String updateStatement ="com.dytzxxxxxxxx.xxxxxx.updateBatch";try{if(CollectionUtils.isNotEmpty(noResult)&& records1.containsAll(noResult)){
log.info("==========不需要更新的数据=========={}", JSON.toJSONString(noResult));
records1.removeAll(noResult);}if(CollectionUtils.isNotEmpty(records1)){
log.info("==========批量更新开始==========");
sqlSessionTemplate.update(updateStatement, records1);
log.info("==========批量更新结束==========");}}catch(Exception e){
e.getStackTrace();
log.error("==========批量更新异常=========={}",ExceptionUtils.getMessage(e));}
这个是有查询和写入多线程环境下都查询和修改到同一条数据的情况就会出问题,最莫名奇妙的问题就是使用mybaitsPlus的save方法还是saveBatch方法在多线程环境下读写数据会出现报错,单线批量后的数据变少了,原因就是mybaitsPlus使用的DefaultSqlSession,这个类是不安全的,使用使用mybatis-Spring包下面的的这个SqlSessionTemplate的类session是安全的,原因是每次去获取session都加了jvm的(synchronized)锁,保证了获取session不出现并发操作,使用这个类之后在使用多线程来跑就会直接报错,错误就是提示:有的线程没有获取到session而导致调用方法报错,所以使用mybatis-Spring包下面的的这个SqlSessionTemplate写批量更新不能使用多线程操作,这个也是我之前遇到的坑,希望对大家有帮助,请关注点赞加收藏,一键三连哦。
4.Demo百度网盘
链接:https://pan.baidu.com/s/1MY41EPIccpJs-ijwdCBTPw
提取码:3iy1
版权归原作者 大飞哥~BigFei 所有, 如有侵权,请联系我们删除。