

**你好,我是安然无虞。 **
文章目录
- 索引:怎么提高查询的速度?
- 索引是什么?- 单字段索引- - 如何创建单字段索引?- 单字段索引的作用- 如何选择索引字段?- 组合索引- - 如何创建组合索引?- 组合索引的原理- 总结索引
- 索引相关面试题
- MySQL索引的底层实现- 索引创建原则- 索引优缺点- 索引失效场景

索引:怎么提高查询的速度?
在超市信息系统刚刚开始运营的时候,因为数据量很少,每一次的查询都能很快拿到结果。但是,系统运转时间长了以后,数据量不断地累积,变得越来越庞大,很多查询的速度就变得特别慢。这个时候,我们就采用了 MySQL 提供的高效访问数据的方法—— 索引,有效地解决了这个问题,甚至之前的一个需要 8 秒钟才能完成的查询,现在只用 0.3 秒就搞定了,速度提升了 20 多倍。
那么,索引到底是啥呢?该怎么使用呢?
索引是什么?
直白点说就是,我们看书的时候,书会在前面添加目录,我们可以通过目录,快速定位到我们想要看的章节。
MySQL中的索引,其实就相当于书中的目录,它是帮助MySQL系统快速检索数据的一种存储结构。我们可以在索引中按照查询条件,检索索引字段的值,然后快速定位数据记录的位置,这样就不需要遍历整个数据表了。而且,数据表中的记录越多,速度提升越明显。
举个例子,进一步解释一下索引的作用。
mysql>desc demo.trans;+---------------+----------+------+-----+---------+-------+| Field |Type|Null|Key|Default| Extra |+---------------+----------+------+-----+---------+-------+| itemnumber |int| YES | MUL |NULL||| quantity |text| YES ||NULL||| price |text| YES ||NULL||| transdate |datetime| YES | MUL |NULL||| actualvalue |text| YES ||NULL||| barcode |text| YES ||NULL||| cashiernumber |int| YES | MUL |NULL||| branchnumber |int| YES | MUL |NULL||| transuniqueid |text| YES ||NULL||+---------------+----------+------+-----+---------+-------+9rowsinset(0.02 sec)
某个门店的销售流水表有400万条数据,现在我要查一下商品编号是100的商品在2020-12-12这一天的销售情况,查询的代码如下:
mysql>select-> quantity,price,transdate
->from-> demo.trans
->where-> transdate >'2020-12-12'->and transdate <'2020-12-13'->and itemnumber =100;+----------+--------+---------------------+| quantity | price | transdate |+----------+--------+---------------------+|1.000|220.00|2020-12-1219:45:36||1.000|220.00|2020-12-1208:56:37|+----------+--------+---------------------+2rowsinset(8.08 sec)
可以看到,结果总共有2条记录,可是却花了8秒钟,非常慢。同时,这里并没有做表的关联,只是简单的单表查询,而且只是一个门店几个月的数据而已。如果总部把所有门店的数据汇总到一起,查询速度更慢,这样的查询效率,我们肯定是不能接受的。
如何解决这个问题呢?这时候,我们就可以给数据表添加索引。
单字段索引
MySQL支持单字段索引和组合索引,而单字段索引比较常用,我们先来学习下创建单字段索引的方法。
如何创建单字段索引?
创建单字段索引一般有3种方式:
- 通过create语句直接给已经存在的表创建索引;
- 可以在创建表的同时创建索引;
- 可以通过修改表来创建索引。
直接给数据表创建索引的语法如下:
createindex 索引名 ontable 表名 (字段);
创建表的同时创建索引的语法如下:
createtable 表名
(
字段 数据类型
...
{ index|key } 索引名 (字段))
修改表时创建索引的语法如下所示:
altertable 表名 add { index|key} 索引名 (字段);
注意:给表设定主键约束或者唯一性约束的时候,MySQL会自动创建主键索引或唯一性索引。
举个例子,我们可以给表demo.trans创建索引如下:
mysql >createindex index_trans on demo.trans (transdate(10));
Query OK,0rows affected (1 min 8.71 sec)Records: 0 Duplicates: 0Warnings: 0
mysql>select-> quantity,price,transdate
->from-> demo.trans
->where-> transdate >'2020-12-12'->and transdate <'2020-12-13'->and itemnumber =100;+----------+--------+---------------------+| quantity | price | transdate |+----------+--------+---------------------+|1.000|220.00|2020-12-1219:45:36||1.000|220.00|2020-12-1208:56:37|+----------+--------+---------------------+2rowsinset(0.30 sec)
可以看到,加了索引之后,这一次我们只用了 0.3 秒,比没有索引的时候,快了 20 多倍。这么大的差距,说明索引对提高查询的速度确实很有帮助。那么,索引是如何做到这一点的呢?下面我们来学习下单字段索引的作用原理。
单字段索引的作用
要想知道MySQL中索引是怎么起作用的,我们需要借助explain关键字。
explain关键字能够查看SQL语句的执行细节,包括表的加载顺序,表示如何建立连接的,以及索引的使用情况等。
mysql>explainselect-> quantity,price,transdate
->from-> demo.trans
->where-> transdate >'2020-12-12'->and transdate <'2020-12-13'->and itemnumber =100;+----+-------------+-------------+------------+-------+-------------------+-------------------+---------+------+------+----------+-----------------------------------------------+| id | select_type |table| partitions |type| possible_keys |key| key_len | ref |rows| filtered | Extra |+----+-------------+-------------+------------+-------+-------------------+-------------------+---------+------+------+----------+-----------------------------------------------+|1|SIMPLE| trans |NULL| range | index_trans | index_trans |6|NULL|5411|10.00|Usingindex condition;Usingwhere;Using MRR |+----+-------------+-------------+------------+-------+-------------------+-------------------+---------+------+------+----------+-----------------------------------------------+1rowinset,1 warning (0.00 sec)
解释一下代码里的关键内容:
- type=range: 表示使用索引查询特定范围的数据记录
- rows=5411:表示需要读取的记录数
possible_keys=index_trans:表示可以选择的索引是 index_transkey=index_trans:表示实际选择的索引是 index_trans- extra=Using index condition;Using where;Using MRR:这里面的信息对 SQL 语句的执行细节做了进一步的解释,包含了 3 层含义:第一个是执行时使用了索引,第二个是执行时通过 where 条件进行了筛选,第三个是使用了顺序磁盘读取的策略。
我们发现,有了索引之后,MySQL在执行SQL语句的时候多了一种优化的手段。也就是说,在查询的时候,可以先通过查询索引快速定位,然后再找到对应的数据进行读取,这样就大大提高了查询的速度。
如何选择索引字段?
在刚刚的查询中,我们是选择 transdate(交易时间)字段来当索引字段,为啥不选别的字段呢?这是因为,交易时间是查询条件。MySQL 可以按照交易时间的限定“2020 年 12 月 12 日”,在索引中而不是数据表中寻找满足条件的索引记录,再通过索引记录中的指针来定位数据表中的数据。这样,索引就能发挥作用了。
不过,itemnumber 字段也是查询条件,能不能用 itemnumber 来创建一个索引呢?我们来试一试:
mysql>createindex index_trans_itemnumber on demo.trans (itemnumber);
Query OK,0rows affected (43.88 sec)
Records: 0 Duplicates: 0Warnings: 0
然后看看效果:
mysql>select-> quantity,price,transdate
->from-> demo.trans
->where-> transdate >'2020-12-12'-- 对交易时间的筛选,可以在transdate的索引中定位->and transdate <'2020-12-13'->and itemnumber =100;-- 对商品编号的筛选,可以在itemnumber的索引中定位+----------+--------+---------------------+| quantity | price | transdate |+----------+--------+---------------------+|1.000|220.00|2020-12-1219:45:36||1.000|220.00|2020-12-1208:56:37|+----------+--------+---------------------+2rowsinset(0.38 sec)
我们发现,用itemnumber创建索引之后,查询速度和之前的差不多,基本在同一个数量级。
我们用explain关键字查看一下:
mysql>explainselect-> quantity,price,transdate
->from-> demo.trans
->where-> transdate >'2020-12-12'->and transdate <'2020-12-13'->and itemnumber =100;-- 对itemnumber 进行限定+----+-------------+-------------+------------+------+------------------------------------------------+------------------------------+---------+-------+------+----------+-------------+| id | select_type |table| partitions |type| possible_keys |key| key_len | ref |rows| filtered | Extra |+----+-------------+-------------+------------+------+------------------------------------------------+------------------------------+---------+-------+------+----------+-------------+|1|SIMPLE| trans |NULL| ref | index_trans,index_trans_itemnumber | index_trans_itemnumber |5| const |1192|0.14|Usingwhere|+----+-------------+-------------+------------+------+------------------------------------------------+------------------------------+---------+-------+------+----------+-------------+1rowinset,1 warning (0.01 sec)
我们发现,“possible_keys= index_trans,index_trans_itemnumber ”,就是说 MySQL 认为可以选择的索引确实有 2 个,一个是用 transdate 字段创建的索引 index_trans,另一个是用 itemnumber 字段创建的索引 index_trans_itemnumber。
key= index_trans_itemnumber, 说明 MySQL 实际选择使用的索引是 itemnumber 字段创建的索引 index_trans_itemnumber。而 rows=1192,就表示实际读取的数据记录数只有 1192 个,比用 transdate 创建的索引 index_trans 的实际读取记录数要少,这就是 MySQL 选择使用 itemnumber 索引的原因。
建议:在选择索引字段的时候,要选择那些经常被用来做筛选条件的字段。
这样做才能发挥索引的作用,提升检索的效率。
组合索引
在实际工作中,有时会遇到比较复杂的数据表,这种表包括的字段比较多,经常需要通过不同的字段筛选数据,特别是数据表中包含多个层级信息。比如我们的销售流水表就包含了门店信息、收款机信息和商品信息这 3 个层级信息。门店对应多个门店里的收款机,每个收款机对应多个从这台收款机销售出去的商品。我们经常要把这些层次信息作为筛选条件,来进行查询。这个时候单字段的索引往往不容易发挥出索引的最大功效,可以使用组合索引。
现在,先看看单字段索引的效果,我们分别用 branchnumber 和 cashiernumber 来创建索引:
mysql>createindex index_trans_branchnumber on demo.trans (branchnumber);
Query OK,0rows affected (41.49 sec)
Records: 0 Duplicates: 0Warnings: 0
mysql>createindex index_trans_cashiernumber on demo.trans (cashiernumber);
Query OK,0rows affected (41.95 sec)
Records: 0 Duplicates: 0Warnings: 0
有了门店编号和收款机编号的索引,现在我们就尝试一下以门店编号、收款机编号和商品编号为查询条件,来验证一下索引是不是起了作用。
mysql>select-> itemnumber,quantity,price,transdate
->from-> demo.trans
->where-> branchnumber =11and cashiernumber =1-- 门店编号和收款机号为筛选条件->and itemnumber =100;-- 商品编号为筛选条件+------------+----------+--------+---------------------+| itemnumber | quantity | price | transdate |+------------+----------+--------+---------------------+|100|1.000|220.00|2020-07-1109:18:35||100|1.000|220.00|2020-09-0621:21:58||100|1.000|220.00|2020-11-1015:00:11||100|1.000|220.00|2020-12-2514:28:06||100|1.000|220.00|2021-01-0920:21:44||100|1.000|220.00|2021-02-0810:45:05|+------------+----------+--------+---------------------+6rowsinset(0.31 sec)
结果有 6 条记录,查询时间是 0.31 秒,跟只创建商品编号索引差不多。下面我们就来查看一下执行计划,看看新建的索引有没有起作用。
mysql>explainselect-> itemnumber,quantity,price,transdate
->from-> demo.trans
->where-> branchnumber =11and cashiernumber =1->and itemnumber =100;+----+-------------+-------+------------+------+---------------------------------------------------------------------------+------------------------+---------+-------+------+----------+-------------+| id | select_type |table| partitions |type| possible_keys |key| key_len | ref |rows| filtered | Extra |+----+-------------+-------+------------+------+---------------------------------------------------------------------------+------------------------+---------+-------+------+----------+-------------+|1|SIMPLE| trans |NULL| ref | index_trans_itemnumber,index_trans_branchnumber,index_trans_cashiernumber | index_trans_itemnumber |5| const |1192|20.50|Usingwhere|+----+-------------+-------+------------+------+---------------------------------------------------------------------------+------------------------+---------+-------+------+----------+-------------+1rowinset,1 warning (0.01 sec)
MySQL 有 3 个索引可以用,分别是用 branchnumber 创建的 index_trans_branchnumber、用 cashiernumber 创建的 index_trans_cashiernumber 和用 itemnumber 创建的 index_trans_itemnumber。
最后,MySQL 还是选择了 index_trans_itemnumber,实际筛选的记录数是 1192,花费了 0.31 秒。
为什么 MySQL 会这样选呢?这是因为,优化器现在有 3 种索引可以用,分别是商品编号索引、门店编号索引和收款机号索引。优化器发现,商品编号索引实际搜索的记录数最少,所以最后就选择了这种索引。
所以,
如果有多个索引,而这些索引的字段同时作为筛选字段出现在查询中的时候,MySQL 会选择使用最优的索引来执行查询操作。
能不能让这几个筛选字段同时发挥作用呢?这就用到组合索引了。组合索引,就是包含多个字段的索引。MySQL 最多支持由 16 个字段组成的组合索引。
如何创建组合索引?
创建组合索引的语法结构与创建单字段索引相同,不同的是相比单字段索引,组合索引使用了多个字段。
直接给数据表创建索引的语法如下:
createindex 索引名 ontable 表名 (字段1,字段2,……);
创建表的同时创建索引:
createtable 表名
(
字段 数据类型,...
{ index|key} 索引名 (字段1, 字段2,...))
修改表时创建索引:
altertable 表名 add { index|key } 索引名 (字段1, 字段2,...);
现在,针对刚刚的查询场景,我们就可以通过创建组合索引,发挥多个字段的筛选作用。
具体做法是,我们给销售流水表创建一个由 3 个字段 branchnumber、cashiernumber、itemnumber 组成的组合索引,如下所示:
mysql>createindex Index_branchnumber_cashiernumber_itemnumber on demo.trans (branchnumber,cashiernumber,itemnumber);
Query OK,0rows affected (59.26 sec)
Records: 0 Duplicates: 0Warnings: 0
有了组合索引,刚刚的查询速度就更快了:
mysql>select-> itemnumber,quantity,price,transdate
->from-> demo.trans
->where-> branchnumber =11and cashiernumber =1->and itemnumber =100;+------------+----------+--------+---------------------+| itemnumber | quantity | price | transdate |+------------+----------+--------+---------------------+|100|1.000|220.00|2020-07-1109:18:35||100|1.000|220.00|2020-09-0621:21:58||100|1.000|220.00|2020-11-1015:00:11||100|1.000|220.00|2020-12-2514:28:06||100|1.000|220.00|2021-01-0920:21:44||100|1.000|220.00|2021-02-0810:45:05|+------------+----------+--------+---------------------+6rowsinset(0.00 sec)
几乎是一瞬间就完成了,我们来看看MySQL的执行计划:
mysql>explainselect-> itemnumber,quantity,price,transdate
->from-> demo.trans
->where-- 同时筛选门店编号、收款机号和商品编号-> branchnumber =11and cashiernumber =1->and itemnumber =100;+----+-------------+-------+------------+------+-----------------------------------------------------------------------------------------------------------------------+---------------------------------------------+---------+-------------------+------+----------+-------+| id | select_type |table| partitions |type| possible_keys |key| key_len | ref |rows| filtered | Extra |+----+-------------+-------+------------+------+-----------------------------------------------------------------------------------------------------------------------+---------------------------------------------+---------+-------------------+------+----------+-------+|1|SIMPLE| trans |NULL| ref | index_trans_itemnumber,index_trans_branchnumber,index_trans_cashiernumber,index_branchnumber_cashiernumber_itemnumber | index_branchnumber_cashiernumber_itemnumber |15| const,const,const |6|100.00|NULL|+----+-------------+-------+------------+------+-----------------------------------------------------------------------------------------------------------------------+---------------------------------------------+---------+-------------------+------+----------+-------+1rowinset,1 warning (0.01 sec)
这个查询,MySQL可以用到的索引有4个:
- index_trans_itemnumber
- index_trans_branchnumber
- index_trans_cashiernumber
- index_branchnumber_cashiernumber_itemnumber(我们刚刚用branchnumber, cashiernumber, itemnumber创建的组合索引)
MySQL 选择了组合索引,筛选后读取的记录只有6条。组合索引被充分利用,筛选更加精准,所以非常快。
组合索引的原理
组合索引的多个字段是有序的,遵循左对齐的原则。比如我们创建的组合索引,排序的方式是 branchnumber、cashiernumber 和 itemnumber。因此,筛选的条件也要遵循从左向右的原则,如果中断,那么,断点后面的条件就没有办法利用索引了。
比如说我们刚才的条件,branchnumber = 11 AND cashiernumber = 1 AND itemnumber = 100,包含了从左到右的所有字段,所以可以最大限度使用全部组合索引。
假如把条件换成“cashiernumber = 1 AND itemnumber = 100”,由于我们的组合索引是按照 branchnumber、cashiernumber 和 itemnumber 的顺序建立的,最左边的字段 branchnumber 没有包含到条件当中,中断了,所以这个条件完全不能使用组合索引。
类似的,如果筛选的是一个范围,如果没有办法无法精确定位,也相当于中断。比如“branchnumber > 10 AND cashiernumber = 1 AND itemnumber = 100”这个条件,只能用到组合索引中 branchnumber>10 的部分,后面的索引就都用不上了。
我们来看看 MySQL 的运行计划:
mysql>EXPLAINSELECT-> itemnumber,quantity,price,transdate
->FROM-> demo.trans
->WHERE-> branchnumber >10AND cashiernumber =1AND itemnumber =100;+----+-------------+-------+------------+------+-----------------------------------------------------------------------------------------------------------------------+------------------------+---------+-------+------+----------+-------------+| id | select_type |table| partitions |type| possible_keys |key| key_len | ref |rows| filtered | Extra |+----+-------------+-------+------------+------+-----------------------------------------------------------------------------------------------------------------------+------------------------+---------+-------+------+----------+-------------+|1|SIMPLE| trans |NULL| ref | index_trans_itemnumber,index_trans_branchnumber,index_trans_cashiernumber,index_branchnumber_cashiernumber_itemnumber | index_trans_itemnumber |5| const |1192|20.50|Usingwhere|+----+-------------+-------+------------+------+-----------------------------------------------------------------------------------------------------------------------+------------------------+---------+-------+------+----------+-------------+1rowinset,1 warning (0.02 sec)
可见,MySQL没有选择组合索引,而是选择了itemnumber创建的普通索引index_trans_itemnumber。因为如果只使用组合索引的一部分,效果没有单字段索引那么好。
总结索引
索引可以非常显著的提高数据查询的速度,数据表里包含的数据越多,效果越显著。我们应该选择经常被用做筛选条件的字段来创建索引,这样才能通过索引缩小实际读取数据表中数据的范围,发挥出索引的优势。如果有多个筛选的字段,而且经常一起出现,也可以用多个字段来创建组合索引。
如果要删除索引,可以用:
dropindex 索引名 on 表名;
当然, 有的索引不能用这种方法删除,比如主键索引,我们就必须通过修改表来删除索引。语法如下:
altertable 表名 dropprimarykey;
最后再来谈谈索引的成本:
索引能够提升查询的效率,但是创建索引是有成本的,主要有2个方面,一个存储空间的开销,还有一个是数据操作上的开销。
存储空间的开销,是指索引需要单独占用存储空间;数据操作上的开销,是指一旦数据表有变动,无论是插入一条新数据,还是删除一条旧数据,甚至是修改数据,如果涉及索引字段,都需要对索引本身进行修改,以确保索引能够指向正确的记录。
因此,索引也不是越多越好,创建索引有存储开销和操作开销,需要综合考量。
索引相关面试题
MySQL索引的底层实现
MySQL索引底层什么实现的?B+树的特点?还有哪些树?为什么不用其他树?
索引其实是一种数据结构,能够帮助我们快速的检索数据库中的数据。
索引结构可以采用哪些数据结构?
除了InnoDB存储引擎所采用的B+树结构,索引结构还可以采用哪些数据结构呢?
- 链表:查找时是线性遍历,效率太低。
- 普通二叉搜索树:可能退化成线性结构,这时查找还是线性遍历。
- AVL树和红黑树:虽然保证了二叉树是绝对或近似平衡的,不会退化成线性结构,但AVL树和红黑树都是二叉树结构,这就意味着树的层高会比较高,而查询数据时都是从根结点开始向下进行查找的,这也就意味着在查询过程中需要遍历更多结点,如果这些结点还没有被加载到Buffer Pool中,这时就需要进行更多次的IO操作,所以最终没有选择其作为索引结构。
- 哈希表:官方的索引实现方式中MySQL是支持HASH的,只不过InnoDB和MyISAM存储引擎并不支持。哈希表的优点就是它的时间复杂度是O(1) 的,但哈希表也有一个缺点就是不利于进行数据的范围查找。
B树 VS B+树
B+树是B树的一种变形结构,那为什么我们没有采用普通的B树作为索引结构呢?
- 首先,普通B树中的所有结点中都同时包括索引信息和数据信息,由于一个Page的大小是固定的,因此非叶子结点中如果包含了数据信息,那么这些结点中能够存储的索引信息一定会变少,这时这棵树形结构一定会变得更高更瘦,当查询数据时就可能需要与磁盘进行更多次的IO操作。
- 其次,普通B树中的各个叶子结点之间没有连接起来,这将不利于进行数据的范围查找,而B+树的各个叶子结点之间是连接起来的,当我们进行范围查找时,直接先找到第一个数据然后继续向后遍历找到之后的数据即可,因此将各个叶子结点连接起来更有利于进行数据的范围查找。
索引创建原则
索引创建的原则如下:时刻要记住,创建索引的目的就是为了提高查询的效率。
- 比较频繁作为查询条件的字段应该创建索引。
- 唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件。
- 更新非常频繁的字段不适合创建索引。
- 不会出现在where子句中的字段不应该创建索引。
索引优缺点
MySQL索引的优缺点
- 索引的优缺点
优点:
- 提高数据检索的效率,降低数据库IO成本。
- 通过索引对数据进行排序,降低数据的排序成本,降低CPU的消耗。
缺点:
- 建立索引需要占用物理空间
- 会降低表的增删改的效率,因为每次对表记录进行增删改,需要进行动态维护索引,导致增删改时间变长
索引失效场景
索引失效场景
索引失效情况1:非最左匹配
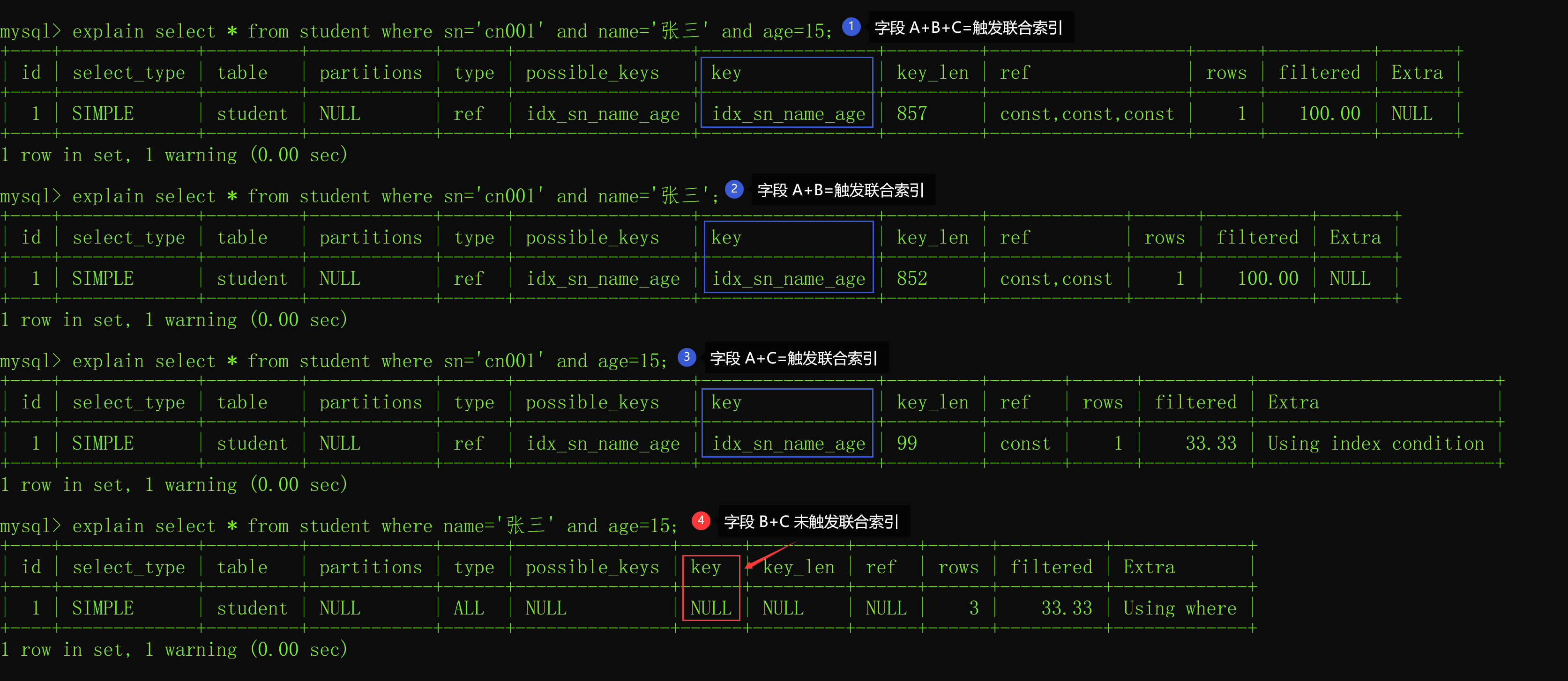
最左匹配原则指的是,以最左边的为起点字段查询可以使用联合索引,否则将不能使用联合索引。 我们本文的联合索引的字段顺序是 sn + name + age,我们假设它们的顺序是 A + B + C,以下联合索引的使用情况如下:
从上述结果可以看出,如果是以最左边开始匹配的字段都可以使用上联合索引,比如:
- A+B+C
- A+B
- A+C 其中:A 等于字段 sn,B 等于字段 name,C 等于字段 age。
而 B+C 却不能使用到联合索引,这就是最左匹配原则。
- 索引失效情况2:错误模糊查询
模糊查询 like 的常见用法有 3 种:
- 模糊匹配后面任意字符:like ‘张%’
- 模糊匹配前面任意字符:like ‘%张’
- 模糊匹配前后任意字符:like ‘%张%’
而这 3 种模糊查询中只有第 1 种查询方式可以使用到索引,具体执行结果如下:
- 索引失效情况3:列运算
如果索引列使用了运算,那么索引也会失效,如下图所示:
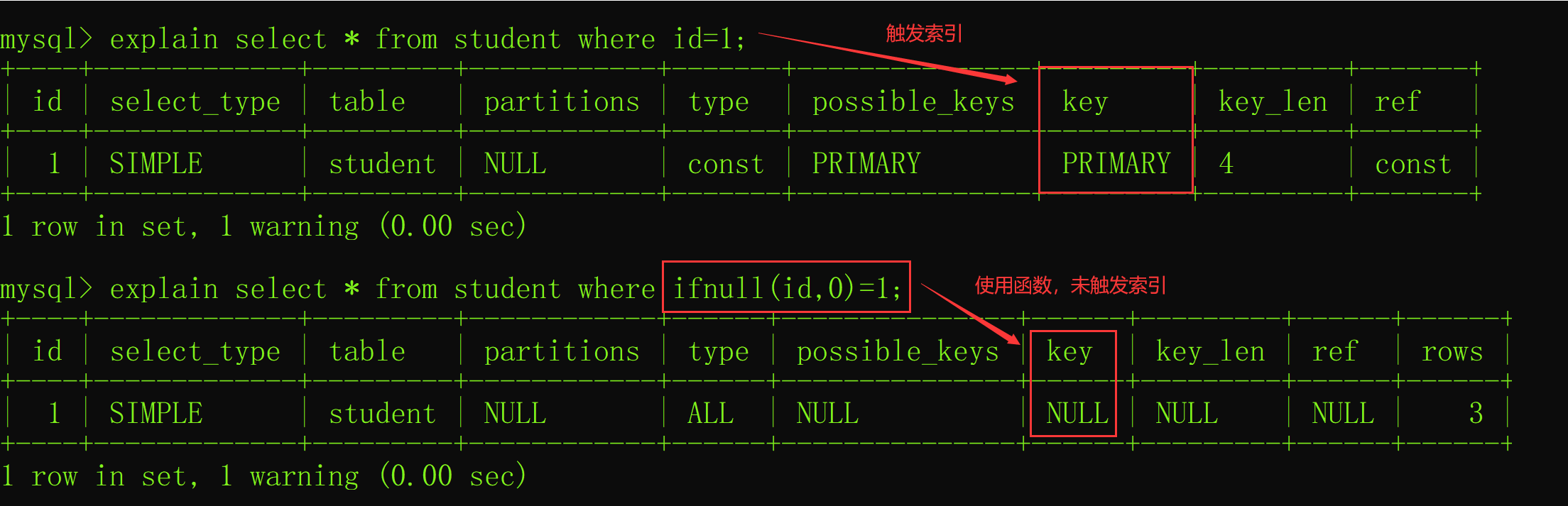
- 索引失效情况4:使用函数
查询列如果使用任意 MySQL 提供的函数就会导致索引失效,比如以下列使用了 ifnull 函数之后的执行计划如下:
- 索引失效情况5:类型转换
如果索引列存在类型转换,那么也不会走索引,比如 address 为字符串类型,而查询的时候设置了 int 类型的值就会导致索引失效,如下图所示:
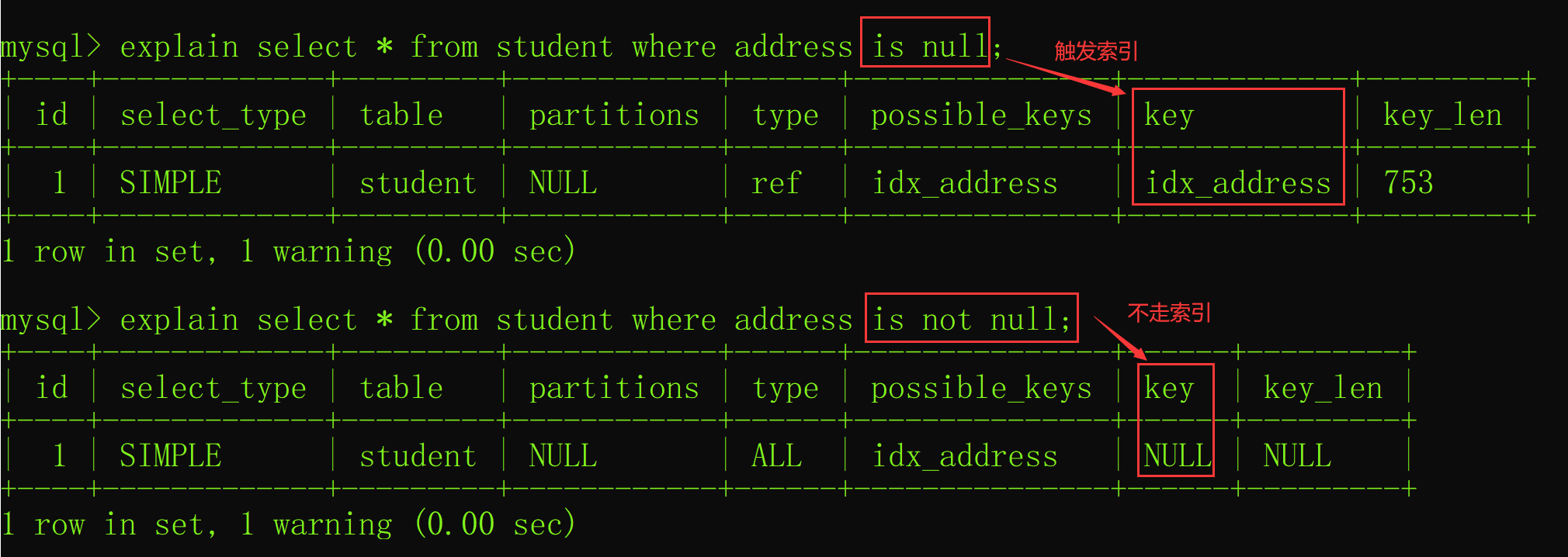
- 索引失效情况6:使用 is not null
当在查询中使用了 is not null 也会导致索引失效,而 is null 则会正常触发索引的,如下图所示:



导致 MySQL 索引失效的常见场景有以下 6 种:
联合索引不满足最左匹配原则。模糊查询最前面的为不确定匹配字符。索引列参与了运算。索引列使用了函数。索引列存在类型转换。索引列使用 is not null 查询。
**遇见安然遇见你,不负代码不负卿。 ****谢谢老铁的时间,咱们下篇再见~ **
版权归原作者 安然无虞 所有, 如有侵权,请联系我们删除。