
一、找到你想要爬取的内容
1.在笔记中打开检查,可以在“预览”中找到小红书的评论内容
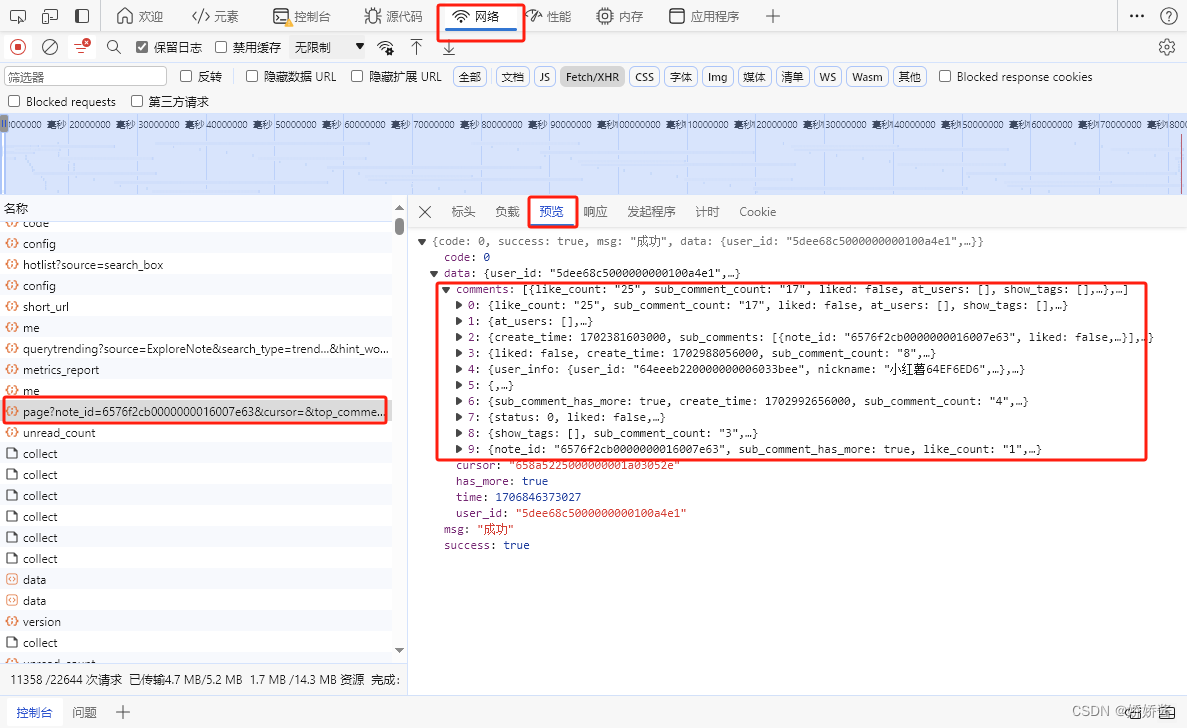
2.找到想要的请求后,在“标头”里找到你需要的URL、Cookie、User-Agent



二、写代码
import requests
from time import sleep
import csv
import random
def main(page, file, cursor):
url = f'https://edith.xiaohongshu.com/api/sns/web/v2/comment/page?note_id=6576f2cb0000000016007e63&cursor={cursor}&top_comment_id=&image_formats=jpg,webp'
headers = {
'Cookie':'*********', #用自己的Cookie,需要是登录后的Cookie
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0',
}
try:
csvwriter.writerow(('评论内容',))
while page < 7: #爬取7页的评论
if cursor != '' : #评论第一页的url中的cursor是空,请求后返回的数据里会有第二页的cursor,做个循环更新url中的cursor,这样就可以实现翻页了。
url = f'https://edith.xiaohongshu.com/api/sns/web/v2/comment/page?note_id=6576f2cb0000000016007e63&cursor={cursor}&top_comment_id=&image_formats=jpg,webp'
resp = requests.get(url, headers=headers)
data = resp.json()
cursor = data['data']['cursor']
page += 1
for i in data['data']['comments'] :
print('爬取内容:', i['content'])
try:
csvwriter.writerow((i['content'],)) #参数后面要带个逗号,不带逗号在csv中是一格一个字
except:
continue #有的评论中有无法写入的表情包会报错,用try+except把这些评论过滤掉
sleep(3 + random.random())
except:
print("当前网页爬取失败")
return
if __name__ == '__main__' :
cursor=''
with open('red_comment.csv', 'a', newline='', encoding='gbk') as file:
csvwriter = csv.writer(file)
main(0,file, cursor)
sleep(3 + random.random())
三、爬取结果

本文转载自: https://blog.csdn.net/sayafeijiao/article/details/136023302
版权归原作者 娇娇酱 所有, 如有侵权,请联系我们删除。
版权归原作者 娇娇酱 所有, 如有侵权,请联系我们删除。