
Kafka的机器数量
Kafka机器数量 = 2 * (峰值生产速度 * 副本数 / 100)+ 1。生产速度单位M/S,与100的单位一致。
副本数设定
一般设为2个或3个,很多企业设为2个。
副本的优势:提高可靠性;劣势:增加了网络IO传输。
Kafka压测
Kafka自带压测脚本。可以在压测时查看到那个地方出现了瓶颈(CPU,内存,网络IO)。一般都是网络IO。
Kafka日志报错时间
默认7天,生产环境建议3天。
Kafka中数据量计算
每天总数据量100G,每天产生1亿条日志,1亿/24/60/60=1150条/秒
平均每秒:1150条
低谷每秒钟:50条
高峰每秒钟:(2-20倍)2300-23000条
每条日志大小:0.5k-2k(取1k)
每秒多少数据量:2M-20M
Kafka硬盘大小
每天的数据量100G*2个副本 * 3天 / 70%
Kafka监控
开源的监控器:KafkaManager、KafkaMonitor、KafkaEagle
Kafka分区数
- 创建只有一个分区的topic
- 测试这个topic的producer吞吐量和consumer吞吐量
- 假设他们的值分别是Tp和Tc,单位可以是MB/s。
- 然后假设总的目标吞吐量是Tt,那么分区数=Tt/min(Tp,Tc)。 例如:producer吞吐量=20m/s;consumer吞吐量=50m/s,期望吞吐量100m/s;分区数=100/20 = 5分区。分区数一般设置为3-10个,且一般不超过集群机器数量。
Topic数量
通常情况下,多少个日志类型就多少个Topic。也有对日志类型进行合并的。
Kafka的ISR副本同步队列
ISR(In-Sync Replicas)副本同步队列。ISR中包括Leader和Follower。如果Leader进程挂掉,会在ISR队列中选择一个作为新的Leader(通常是选择ISR靠前的)。由replic.lag.max.messages(延迟条数)replica.lag.time.max.ms(延迟时间)两个参数决定一台服务器是否可以加入ISR队列。在0.10版本移除了replica.lag.max.messages参数,防止服务频繁的进去队列。
任意一个维度超过了阈值就会把Follower踢出ISR,进入OSR列表。新加入的Follower也会先存放在OSR中。
Kafka分区分配策略
在Kafka内部存在两种默认的分区分配策略:Range和RoundRobin。
Range是默认策略。Range是对每个Topic而言的(即一个Topic一个Topic分),首先对同一个Topic里面的分区按序号进行排序,并对消费者按照字母顺序进行排序。然后用Partition分区的个数除以消费者总线程数来决定每个消费者线程消费几个分区的数据。如果除不尽,那前几个消费者线程会多消费一个分区。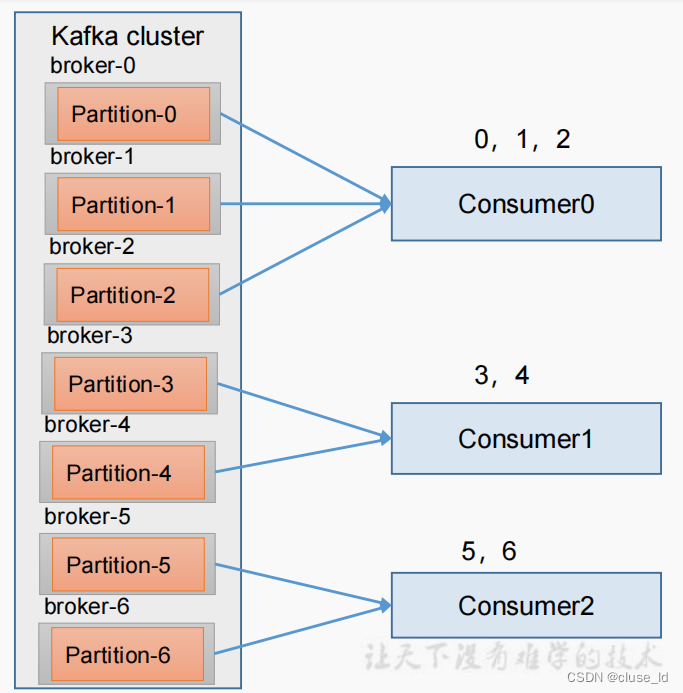
例如:我们有 10 个分区,两个消费者(C1,C2),3 个消费者线程,10 / 3 = 3 而且除 不尽。
C1-0 将消费 0, 1, 2, 3 分区
C2-0 将消费 4, 5, 6 分区
C2-1 将消费 7, 8, 9 分区
这样有一个隐患,当Topic数量变多了的时候,第一个消费者都会多消费一个分区,这样容易导致数据倾斜。
RoundRobin与Range主要的区别是:RoundRobin是针对整个集群中所有Topic而言的;RoundRobin是通过轮询分区策略分配partition的。
将所有主题分区组成 TopicAndPartition 列表,然后对 TopicAndPartition 列表按 照 hashCode 进行排序,最后按照轮询的方式发给每一个消费线程。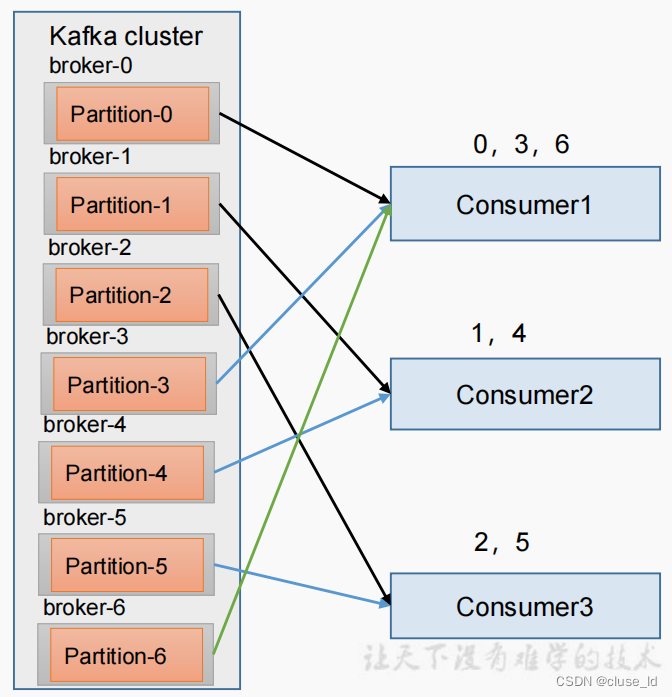
Kafka挂掉
- Flume记录
- 日志有记录
- 短期没事
Kafka丢不丢数据
Ack = 0,相当于异步发送,消息发送完毕即增加offset,继续生产。会丢数据
Ack = 1,leader收到leader replica 对一个消息的接受ack才增加offset,然后继续生产。可能丢数据
Ack = -1,leader收到所有replica对一个消息的接受ack才增加offset,然后继续生产。
Kafka数据重复
幂等性 + ack-1 + 事务
Kafka 数据重复,可以再下一级:SparkStreaming、redis 或者 Hive 中 dwd 层去重,去重 的手段:分组、按照 id 开窗只取第一个值;
Kafka消息数据积压,Kafka消费能力不足怎么处理?
- 如果是Kafka消费能力不足,则可以考虑增加Topic的分区数,并且同时提升消费者组的消费者数量,消费者数=分区数。
- 如果是下游数据处理不及时:提高每批次拉取的数量。批次拉取数据过少,使处理的数据小于生产的数据,也会造成数据积压。
Kafka高效读写数据
- Kafka本身是分布式集群,同时采用分区技术,并发度高。
- 顺序写磁盘。Kafka的producer生产数据,写入log文件中,写的过程是一直追加到文件末端,为顺序写。同样的磁盘,顺序写能到600M/s,而随机写只有100K/s。
- 零拷贝技术 由于Kafka不关心传输的数据具体内容,所以我们可以将从内核空间拷贝数据到应用程序和从应用程序拷贝数据到内核空间这两个拷贝过程忽略,这就是Kafka的零拷贝。
Kafka单条日志传输大小
Kafka对于消息体的大小默认单条最大值是1M但是我们应用场景中,常常会出现一条消息大于1M,如果不对Kafka进行配置,则会出现生产者 无法将消息推送到Kafka或消费者无法去消费Kafka中的数据。这时我们就要对Kafka进行以下配置:server.properties
replica.fetch.max.bytes: 1048576# broker 可复制的消息的最大字节数, 默认为 1M
message.max.bytes: 1000012# kafka 会接收单个消息 size 的最大限制, 默认为 1M 左右# 注意:message.max.bytes 必须小于等于 replica.fetch.max.bytes,否则就会导致 replica 之 间数据同步失败。
Kafka过期数据清理
保证数据没有引用(没人消费他)
日志清理保存的策略只有delete和compact两种
log.cleanup.policy = delete 启动删除策略
log.cleanup.policy = compact 启动压缩策略
Kafka可以按照时间消费数据
Map<TopicPartition,OffsetAndTimestamp> startOffsetMap =KafkaUtil.fetchOffsetsWithTimestamp(topic, sTime, kafkaProp);
Kafka消费者角度考虑是拉取数据还是推送数据
拉取数据
Kafka中数据是有序的吗
单分区有序;多分区,分区间无序;
扩展: kafka producer 发送消息的时候,可以指定 key: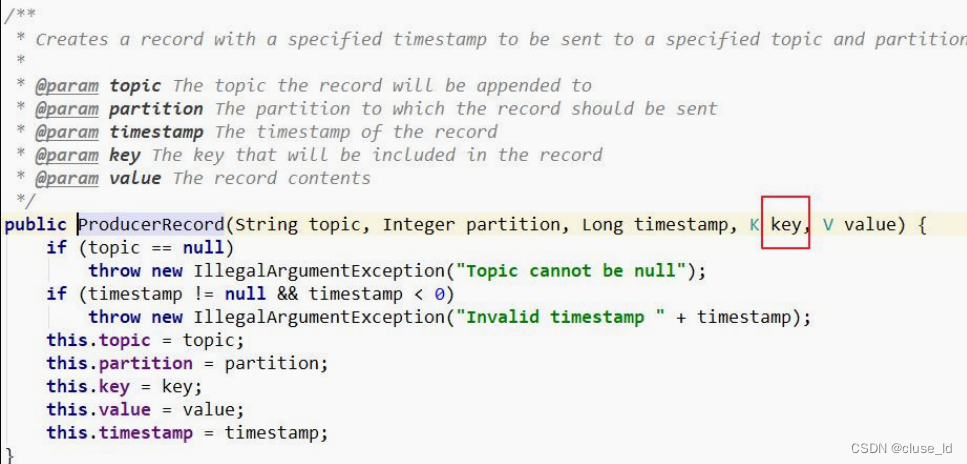
这个 key 的作用是为消息选择存储分区,key 可以为空,当指定 key 且不为空的时候, Kafka 是根据 key 的 hash 值与分区数取模来决定数据存储到那个分区。
有序解决方案:同一张表的数据 放到 同一个 分区
=> ProducerRecord 里传入 key,会根据 key 取 hash 算出分区号
=> key 使用表名,如果有库名,拼接上库名
版权归原作者 cluse_ld 所有, 如有侵权,请联系我们删除。