
一、自定义通信协议
通信协议:通信双方事先商量好的暗语。在TCP网络编程中,发送方和接收方的数据包格式都是二进制,发送方先将对象转化为二进制流发送给接收方,接收方获取二进制流后根据协议解析成对象。
当前通用的协议包括:HTTP、HTTPS、JSON-RPC、FTP、IMAP、Protobuf等。考虑到通信协议兼容性好、易于维护,在满足业务场景和性能需求时推荐采用通用协议,通信协议不满足要求时可以自定义通信协议。自定义通信协议的好处在于:
- 极致性能:通用协议考虑了很多兼容性的问题,性能有所损失。
- 扩展性:自定义协议更好扩展,更好满足业务需求。
- 安全性:通信协议是公开的,很多漏洞已经被黑客攻破。对于自定义协议,黑客需要先破解协议内容。
一个完备的通信协议需要具备以下基本要素:
- 魔数:通信的一个暗号,通常采用固定的几个字节表示。用于防止任何人随便向服务器的端口上发送数据。接收方接收到数据后会先解析出魔书,如果魔书和约定的不匹配,认为是非法数据,直接关闭连接或者采取其他措施以增强系统的安全防护
- 协议版本号:随着业务需求的变化,协议可能需要对结构或者字段进行改动,不同版本的协议对应的解析方法也不同
- 序列化算法:表示数据发送方如何将请求对象转化为二进制流,以及如何再将二进制流转为对象
- 报文类型:不同的业务场景中,报文可能存在不同的类型。如,RPC框架中有请求、响应、心跳等类型的报文;IM即时通信中有登录、创建群聊、发送消息、接收消息、退出群聊等类型的报文
- 长度域字段:代表请求数据的长度,接收方根据该字段获取完整的报文
- 请求数据:序列化后的二进制流
- 状态:表示请求是否正常。一般由调用方设置。如:一次RPC调用失败,状态字段可以被服务提供方设置为异常状态
- 保留字段:为了应对协议升级的可能性,预留的若干字段
以下是一个较为通用的协议示例:
+---------------------------------------------------------------+
| 魔数 2byte | 协议版本号 1byte | 序列化算法 1byte | 报文类型 1byte |
+---------------------------------------------------------------+
| 状态 1byte | 保留字段 4byte | 数据长度 4byte |
+---------------------------------------------------------------+
| 数据内容 (长度不定) |
+---------------------------------------------------------------+
二、Netty中自定义通信协议
Netty提供了丰富的编解码抽象类,用于我们更为方便地基于这些抽象类扩展实现自定义通信协议。
Netty编码类抽象类:
- MessageToByteEncoder类:将消息对象编码为二进制流
- MessageToMessageEncoder类:将一种消息类型编码为另一种消息类型
Netty解码类抽象类:
- ByteToMessageDecoder/ReplyingDecoder类:将二进制流解码为消息对象
- MessageToMessageDecoder类:将一种消息类型编码为另一种消息类型
Netty中的编解码器分为一次编解码和二次编解码。以解码为例,一次解码器用于解决TCP拆包/粘包问题,解析得到字节数据。如果需要对解析后的字节数据做对象转换,需要使用二次解码器。同理,编码器是相反过程。
- 一次编解码器:MessageToByteEncoder、ByteToMessageDecoder/ReplyingDecoder
- 二次编解码器:MessageToMessageEncoder、MessageToMessageDecoder
抽象编码类
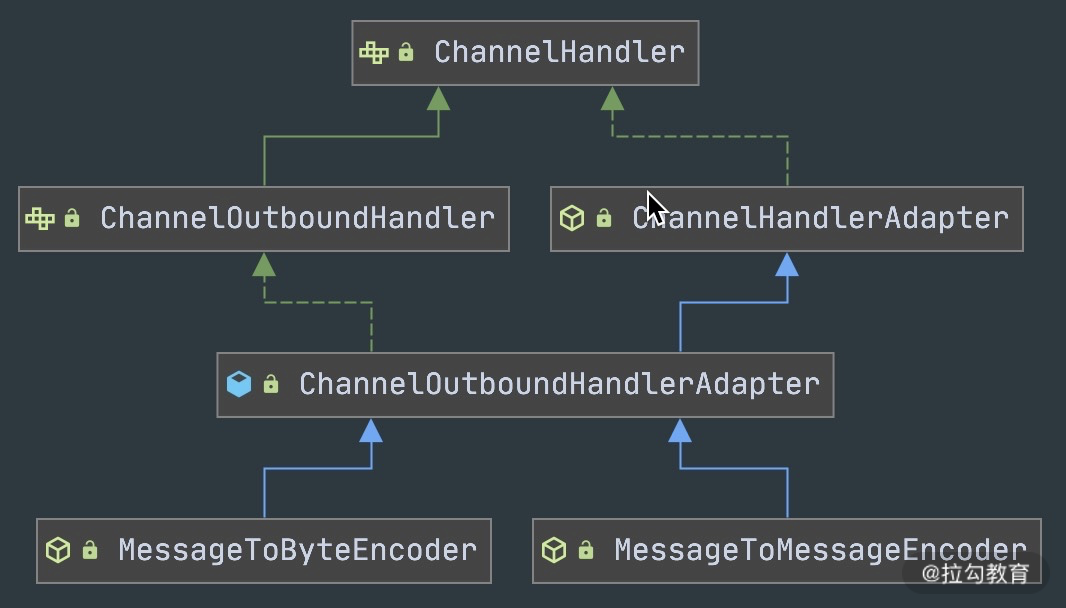
抽象编码类是ChannelOutboundHandler的抽象实现,处理的是出站数据
MessageToByteEncoder类
MessageToByteEncoder重写了ChannelOutboundHandler的write()方法,该方法内的encode()抽象方法用于数据编码,仅需要继承MessageToByteEncoder类并实现encode()即可自定义编码逻辑。
@Overridepublicvoidwrite(ChannelHandlerContext ctx,Object msg,ChannelPromise promise)throwsException{ByteBuf buf =null;try{if(acceptOutboundMessage(msg)){// 1. 消息类型是否匹配@SuppressWarnings("unchecked")I cast =(I) msg;
buf =allocateBuffer(ctx, cast, preferDirect);// 2. 分配 ByteBuf 资源try{encode(ctx, cast, buf);// 3. 执行 encode 方法完成数据编码}finally{ReferenceCountUtil.release(cast);}if(buf.isReadable()){
ctx.write(buf, promise);// 4. 向后传递写事件}else{
buf.release();
ctx.write(Unpooled.EMPTY_BUFFER, promise);}
buf =null;}else{
ctx.write(msg, promise);}}catch(EncoderException e){throw e;}catch(Throwable e){thrownewEncoderException(e);}finally{if(buf !=null){
buf.release();}}}
write()方法的主要逻辑如下:
- acceptOutboundMessage判断是否有匹配的消息类型,如果匹配需要执行编码,如果不匹配直接传递给下一个ChannelOutboundHandler
- 分配ByteBuf资源,默认使用堆外内存
- 调用子类的encode()方法进行编码,编码成功,会通过调用ReferenceCountUtil.release(cast)自动释放
- 如果ByteBuf可读,说明成功编码得到数据,然后写入下一个ChannelOutboundHandler;否则释放ByteBuf资源,向下传递空的ByteBuf对象
编码器无需关注拆包/粘包问题,以下为一个自定义编码类:
publicclassStringToByteEncoderextendsMessageToByteEncoder<String>{@Overrideprotectedvoidencode(ChannelHandlerContext channelHandlerContext,String data,ByteBuf byteBuf)throwsException{
byteBuf.writeBytes(data.getBytes());}}
MessageToMessageEncoder类
与MessageToByteEncoder类似,同样可以继承MessageToMessageEncoder类并实现encode()方法实现自定义编码。但是MessageToMessageEncoder用于将一个格式的消息转换为另一个格式的消息,这里的第二个Message可以是任意一个对象,如果该对象是ByteBuf类型,MessageToMessageEncoder的实现逻辑基本上与MessageToByteEncoder一致
MessageToMessageEncoder的实现类包括:StringEncoder、LineEncoder、Base64Encoder等。以StringEncoder类为例,查看encode()方法:将CharSequence类型转换为ByteBuf类型,结合StringDecoder可以实现String类型的编解码。
@Overrideprotectedvoidencode(ChannelHandlerContext ctx,CharSequence msg,List<Object> out)throwsException{if(msg.length()==0){return;}
out.add(ByteBufUtil.encodeString(ctx.alloc(),CharBuffer.wrap(msg), charset));}
抽象解码类
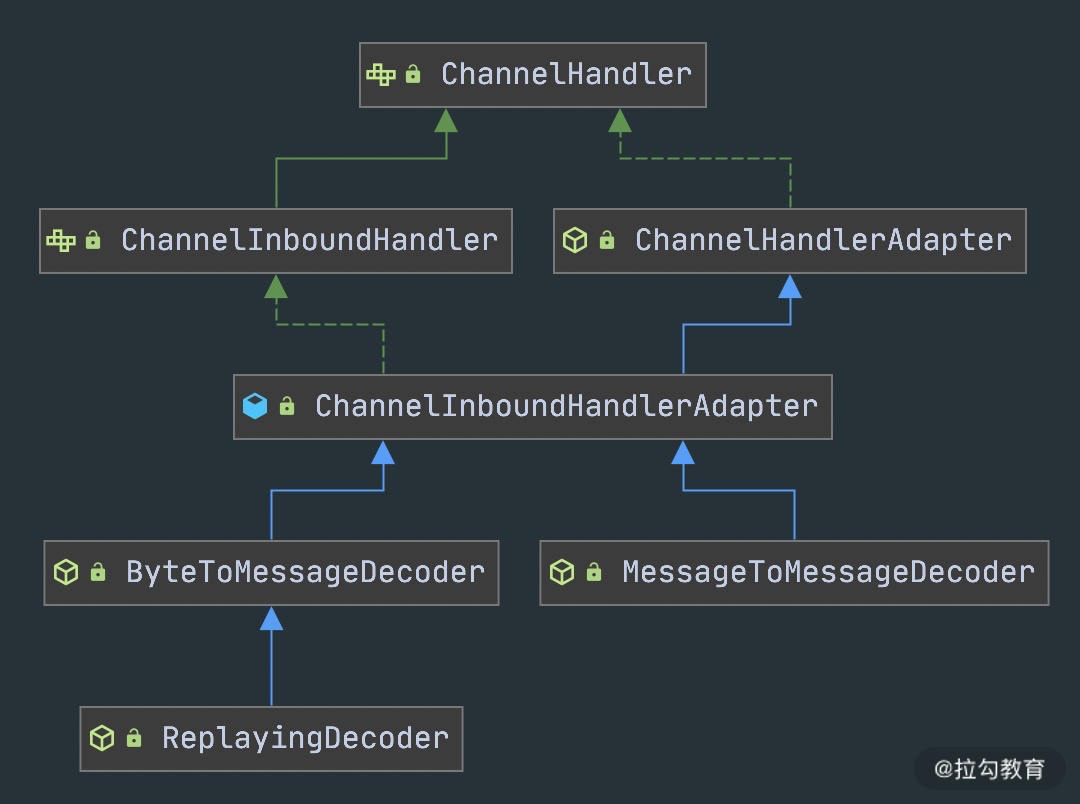
抽象解码类是ChannelInboundHandler的抽象类实现,处理的是入站数据。解码器需要考虑拆包/粘包问题。由于接收方可能没有收到完整消息,解码框架需要对入站的数据做缓冲操作,直至收到完整的消息。
ByteToMessageDecoder类
publicabstractclassByteToMessageDecoderextendsChannelInboundHandlerAdapter{protectedabstractvoiddecode(ChannelHandlerContext ctx,ByteBuf in,List<Object> out)throwsException;protectedvoiddecodeLast(ChannelHandlerContext ctx,ByteBuf in,List<Object> out)throwsException{if(in.isReadable()){decodeRemovalReentryProtection(ctx, in, out);}}}
ByteToMessageDecoder类中包含decode()抽象方法,可以通过继承ByteToMessageDecoder并实现该方法完成自定义解码。decode()在调用时需要传入ByteBuf以及用来添加解码后消息的List列表。由于拆包/粘包问题,ByteBuf中可能包含多个有效报文,或者不够一个完整的报文,因此Netty会重复会调用decode()方法,直到解码出新的完整报文可以添加到List中,或者ByteBuf中没有更多可读的数据为止。如果List不为空,将会传递给下一个ChannelInboundHandler。
ByteToMessageDecoder中还有一个decodeLast()方法,该方法会在Channel关闭后被调用一次,主要用于处理ByteBuf最后剩余的字节数据。Netty中decodeLast()方法默认只是简单调用一下decode()方法,有特殊也无需求也可以重写decodeLast()。
ByteToMessageDecoder有一个抽象子类ReplyingDecoder,他封装了缓冲区的管理,读取缓冲区时无需再对字节长度进行校验。因为如果没有足够长度的字节数据,ReplyingDecoder会终止解码操作。一般不推荐使用ReplyingDecoder类,因为其性能相较直接使用ByteToMessageDecoder要慢。
MessageToMessageDecoder类
该类的作用与ByteToMessageDecoder类似,都是将一种消息解码为另一种消息,但是第一个Message可以是任意一个对象,而且MessageToMessageDecoder不会对数据报文进行缓存。推荐先使用ByteToMessageDecoder解析TCP协议,解决拆包/粘包问题,然后用MessageToMessageDecoder做数据对象的转换。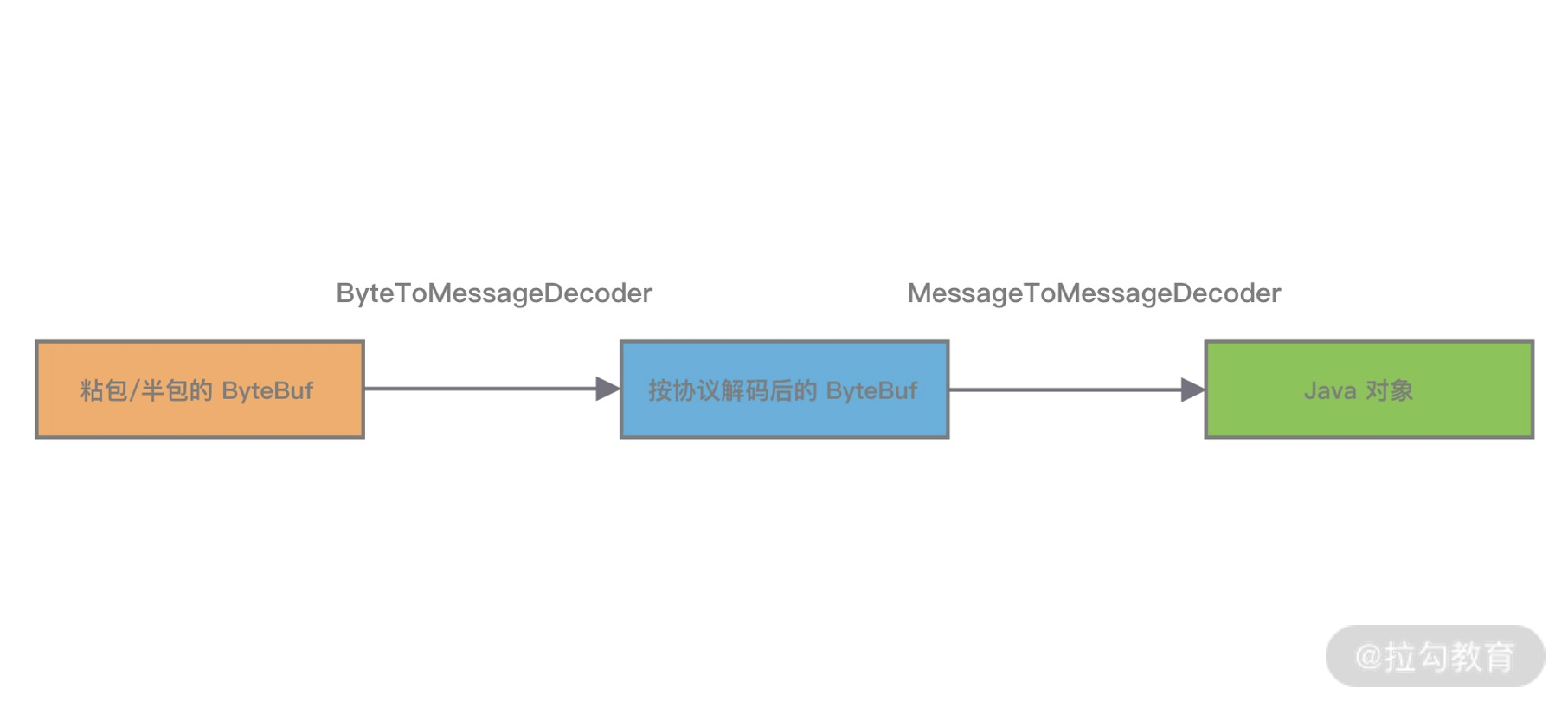
版权归原作者 爱打羽球的程序猿 所有, 如有侵权,请联系我们删除。