
01-2023年02月-月度考核汇报
2月份完成项目情况
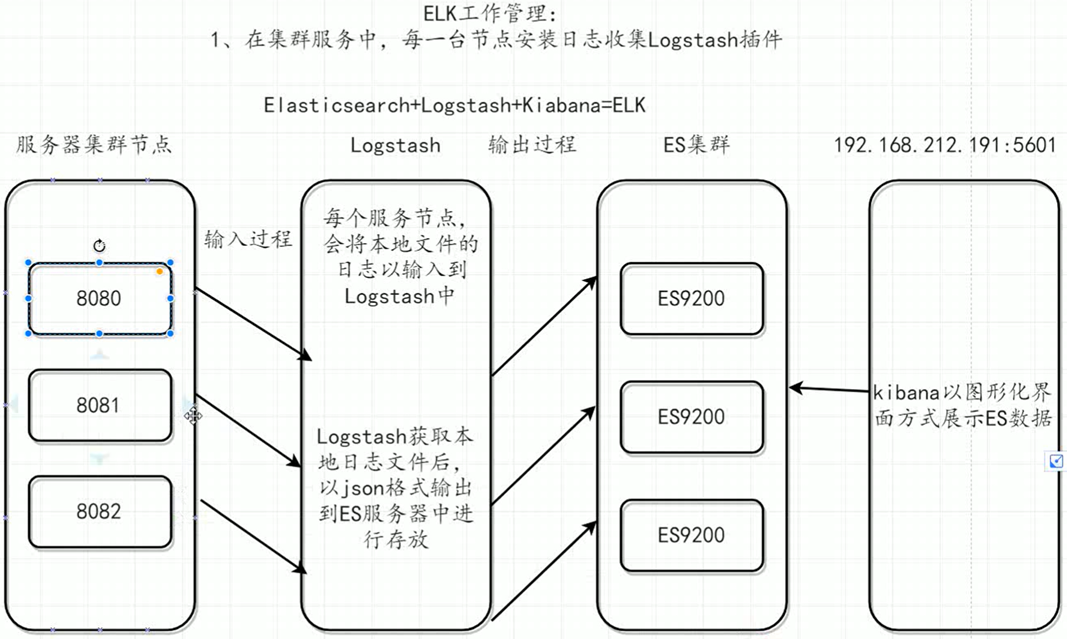
MySQL数据同步到ElasticSearch任务进展(Windows系统):
通过logstash加载mysql.conf配置文件的方式实现了
在MySQL数据库进行增改后于一分钟内将数据状态同步至ES中。
2月份学习情况
本月主要学习了以下内容:
①
ElasticSearch:索引库维护、集群、Postman工具的使用、Java客户端操作索引库、SpringData操作ES集群②
Springboot+ElasticSearch构建博客检索系统,logstash与kibana的安装及使用。③
Hadoop:MapReduce、HDFS、Hive、FineBI实现可视化报表。
3月份学习计划
本月计划学习以下内容:
①
主要学习内容①
Logstash实现MySQL与ES的数据同步,在MySQL数据库中进行增删改操作后,数据状态能够及时反馈至ES中;②
Logstash获取es日志文件后,将数据以json格式输出到es中进行存放;③
SpringData操作ElasticSearch;④
在linux上部署es。②
次要学习内容①
Apache Spark,大数据快速计算引擎;②
SVN、Git、Docker,项目版本管理工具、项目打包。
老师点评
无!
02-2023年03月-月度考核汇报
项目完成情况
Linux服务器中MySQL数据库数据同步ElasticSearch
①
安装线上运行版本的软件:jdk11、elk-8.5.1(es、logstash、kibana)、node.js-14.21.3、esHead插件;②
连接线上测试数据库进行测试:通过logstash加载配置文件的方式,将MySQL数据同步到es中,并在kibana中进行查看到了数据增改的同步效果;③
拍摄虚拟机快照保存虚拟机状态;④
详细记录elk安装过程及启动步骤。
投入实际生产时可通过scp命令将本地生产环境拷贝至实际开发环境,为后续生产环境作准备。
本月学习内容
①
Git①
Git简介及安装使用;Git连接远程仓库;Git分支;②
Linux①
Windows安装Ubuntu版本Linux系统;②
复习Linux常用命令;③
复习Linux用户和权限知识点;④
复习Linux实用操作;⑤
Linux系统软件安装。③
Hadoop①
Hadoop集群搭建,scp命令、集群常用脚本。②
Hadoop-HDFS,客户端API。③
Hadoop-MapReduce,MR序列化。④
Hadoop-Yarn,生产环境核心参数配置、配置多队列的容量调度器。⑤
Hadoop-生产调优手册,HDFS集群压测。
①
Git①
Git****简介及安装使用:安装Git与TortoiseGit,测试本地仓库中文件的增删改;②
Git****连接远程仓库:GitHub远程仓库、本地仓库推送至远程、克隆远程仓库;③
Git****分支:使用Idea使用Idea将工程添加到本地仓库、使用Idea克隆仓库并同步代码、在Idea中使用git的分支。②
Linux①
Windows安装Ubuntu版本Linux****系统:对比Ubuntu与Cent OS的差异;②
复习Linux常用命令:ls、cd、pwd、mkdir、touch、cat、more、cp、mv、rm、which、find、grep、wc、echo、tail、vim、su、sudo、groupadd、useradd、usermod、userdel、getent、chmod、chown;③
复习Linux用户和权限知识点:su、sudo、groupadd、useradd、usermod、userdel、getent、chmod、chown;④
复习Linux实用操作:软件安装方式、systemctl、端口、进程管理、环境变量;⑤
Linux****系统软件安装:MySQL、Tomcat、Nginx、RabbitMQ、Redis、ElasticSearch。③
Hadoop** *①
Hadoop*集群搭建,**scp命令、集群常用脚本(xsync文件分发、集群启停脚本、查看三台服务器Java进程脚本)。②Hadoop-HDFS****,shell操作、客户端API(API创建文件夹:URI、Configuration、FileSystem)、core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml。
③Hadoop-MapReduce****,MR序列化(Mapper、Reducer和Driver)、在实体类中实现序列化和反序列化方法、数据压缩。
④Hadoop-Yarn****,查看日志及节点状态、生产环境核心参数配置、配置多队列的容量调度器。
⑤Hadoop-*生产调优手册,HDFS核心参数、HDFS集群压测、HDFS多目录*。
下月学习计划
01、Hadoop
①复习hadoop中的重要知识点,重点复习HDFS、MapReduce、Yarn的使用。
②阅读书籍《 Hadoop权威指南_第四版_中文版》,以便对hadoop有更深的理解。02、Spark(重点学习内容)
Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。学习spark教程,重点掌握以下内容:
①Spark Core:最基础与最核心的功能
②Spark SQL:操作结构化数据的组件。
③Spark Streaming:实时数据进行流式计算的组件。
④Spark Mllib:机器学习算法库。
⑤Spark GraphX:Spark 面向图计算提供的框架与算法库。03、Flink(次要学习内容)
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行状态计算。
①flink部署及架构;
②Data Stream API;
③flink处理函数。04、kafka(次要学习内容)
Kafka是一个分布式的基于发布/订阅模式的消息队列,主要应用于大数据实时处理领域。
①生产者消费者模式实现;
②外部系统集成;
③生产调优方法。
老师点评
zyh老师:不局限于结构化数据,尝试流式数据等各种数据的同步。
hj老师:学习Flinkcdc。
基于 Flink SQL CDC 的实时数据同步方案-阿里云开发者社区
版权归原作者 延锋L 所有, 如有侵权,请联系我们删除。