
文章目录
前言
本文用于参考学习,请执行配置好scrapy环境后再进行编程实操
代码
pip install scrapy==2.5.1
pip install Twisted==22.10.0
单题效果: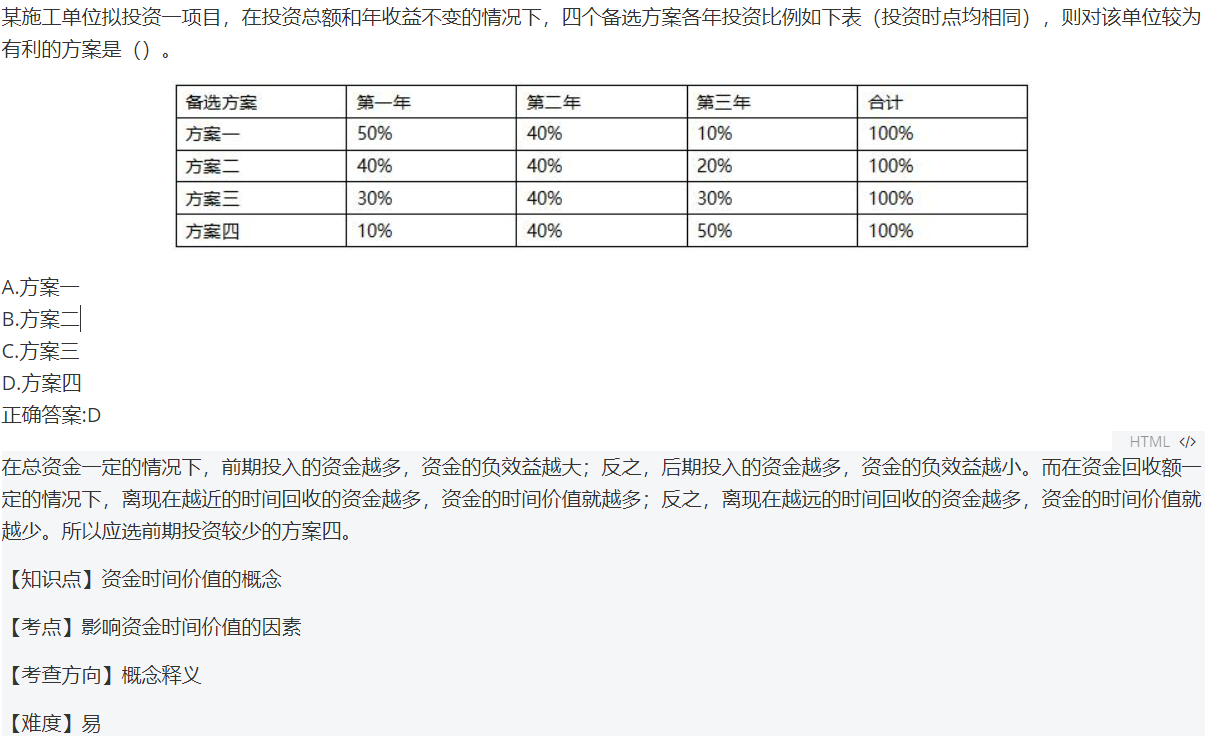
一、新建scrapy文件+配置setting
在配置好scrapy环境后在编译器终端参考如下图片中步骤建立一个scrapy文件。
注意:
- scrapy startproject 文件夹的名字
- scrapy genspider 爬虫文件名 爬取的网站域名(比如百度就是baidu.com)
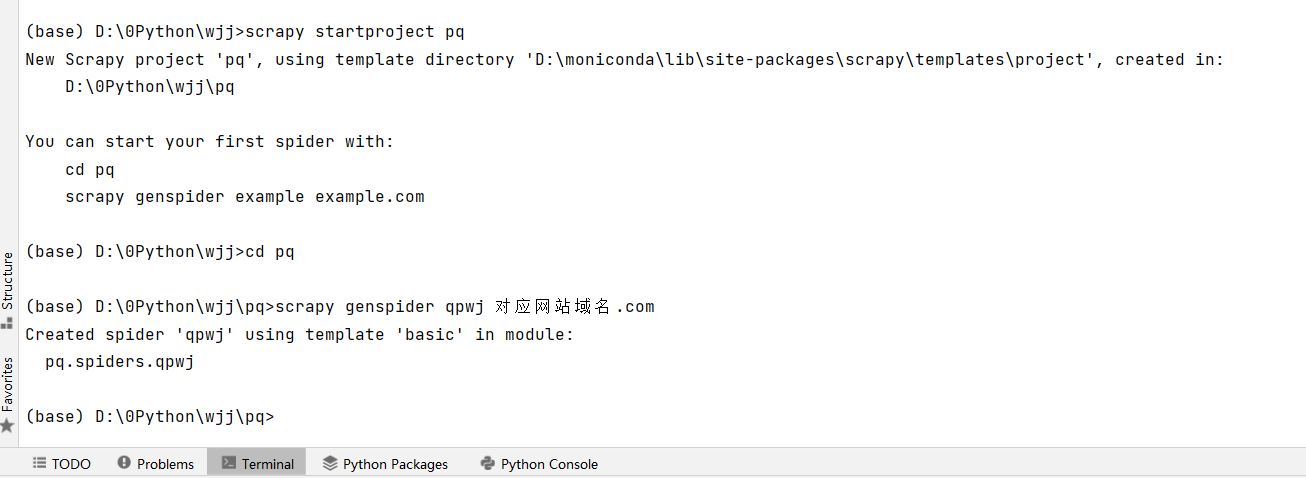
创建结果:
只需了解:
其中qpwj.py文件就是scrapy genspider 爬虫文件名 爬取的网站域名 —命令创建的,用来对网站的源代码进行解析(提取数据)
pipelines.py:数据管道,进行数据存储。
settings:配置scrapy文件,协调爬虫工作。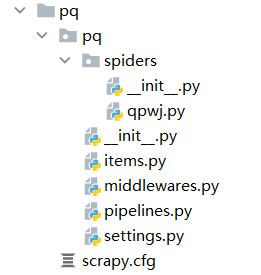
然后做这一步:
本案例setting文件中做如下配置,个别对应值自己去浏览器中查:
USER_AGENT ="*****"#浏览器中可查,按F12打开开发者模式点击network刷新网页点击网页文件找到USER_AGENT进行复制
ROBOTSTXT_OBEY =False#属于君子协议,改成False,就是爬,不管别人肯不肯
LOG_LEVEL ="WARNING"#少点无用的信息
DOWNLOAD_DELAY =3#这个一定要配好,控制延迟,不要太快,保护网站不崩
COOKIES_ENABLED =False#取消cook的自动维护
DEFAULT_REQUEST_HEADERS ={'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8','Accept-Language':'en',"Cookie":"****"#自己给个cookie,登录网站就会得到}
ITEM_PIPELINES ={#pipelines.py文件中的类的执行优先级,数字小的先执行'Problem.pipelines.ProblemPipeline':300,'Problem.pipelines.PICPipeline':299}
IMAGES_STORE ="./"# 给一个当前文件夹作为路径做参考来存储文件
两种方式新建执行srapy文件
- 新建一个runner.py(和scrapy.cfg同等级)文件:
#运行时右键run该文件就能执行Scrapy了#tip:#scrapy genspider 爬虫文件名 爬取的网站域名from scrapy.cmdline import execute
if __name__ =='__main__':
execute("scrapy crawl pqwj".split())#注意pqwj替换为你的文件名
2.终端输入:
scrapy crawl pqwj
二、确定&分析需求
把这个网站所有的题目都爬下来,分类存放,文件格式(markdown),对于题目图片也存放一份在对应文件夹中。
确定文件分类形式:

直接举例:
一、资金时间价值的概念中的20道题目要都存放在一、资金时间价值的概念.md文件中,并且把图片都存放在同等级的img文件夹中
文件路径:
工程类/一级建造师/1Z101000工程经济/1Z101010资金时间价值的计算及应用/1Z101011利息的计算/一、资金时间价值的概念/一、资金时间价值的概念.md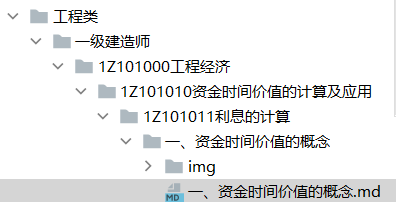
三、获取文件路径
发现first+second路径,而且有a标签,a标签中的href值是要用来进行拼接后来网页跳转的网址: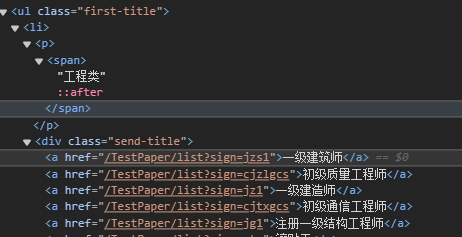
例如对含有一级建筑师文本的a标签进行href提取后进行网址拼接得到:
https://ks.wangxiao.cn/TestPaper/list?sign=jzs1
跳转到: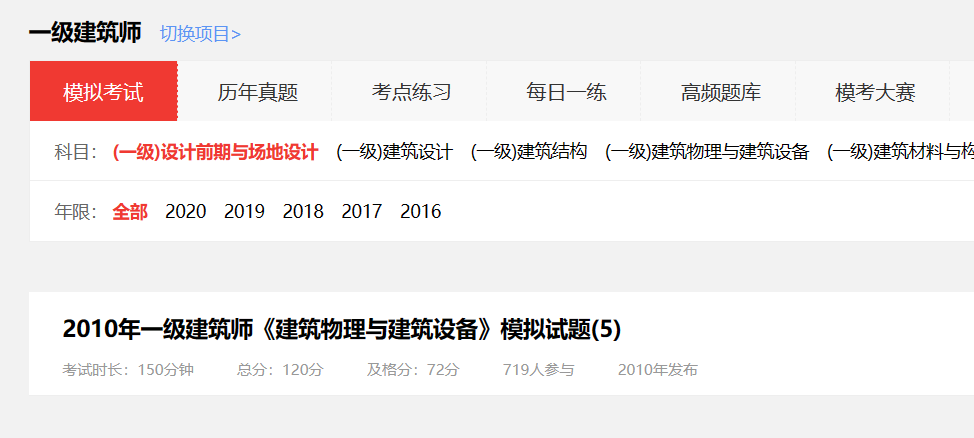
而我们的需求是跳转到:
https://ks.wangxiao.cn/exampoint/list?sign=jzs1
两个网址一对比:
拿到的跳转网址:
https://ks.wangxiao.cn/TestPaper/list?sign=jzs1
目标:
https://ks.wangxiao.cn/exampoint/list?sign=jzs1
就差一个单词,观察其他网址是否也是如此,回答为:YES
那么:
进行一级目录和二级目录提取,并且向这些类目下的考点链接发送请求(拼接路径后进行替换单词)
for i in all_li:
onetitle = i.xpath(".//p/span//text()").extract_first()
li_all_a=i.xpath(".//div[@class='send-title']/a")for j in li_all_a:
twotitle = j.xpath(".//text()").extract_first()
twourl = resp.urljoin(j.xpath("./@href").extract_first()).replace("TestPaper","exampoint")yield scrapy.Request(
url=twourl,
callback=self.Plistparse,
meta={"one":onetitle,"two": twotitle
})
观察题库&分析源码&拿下路径
访问题库后一点开,发现它的文件路径这样的:
题目路径有的深有的浅:
工程类\一级建造师\1Z101000工程经济\1Z101010资金时间价值的计算及应用\1Z101011利息的计算\一、资金时间价值的概念\一、资金时间价值的概念.md
工程类\一级建造师\1Z101000工程经济\现金流量图的计算\现金流量图的计算.md
这个怎么办?难道一套网页路径结构,就要写一套代码吗?
NO NO NO
可以先拿最里面的路径名:
比如:工程类\一级建造师\1Z101000工程经济\1Z101010资金时间价值的计算及应用\1Z101011利息的计算\一、资金时间价值的概念\一、资金时间价值的概念.md (.md这个文件名啊)
最里面的路径名:一、资金时间价值的概念
然后再从这个路径往外一层层的去拿路径名。
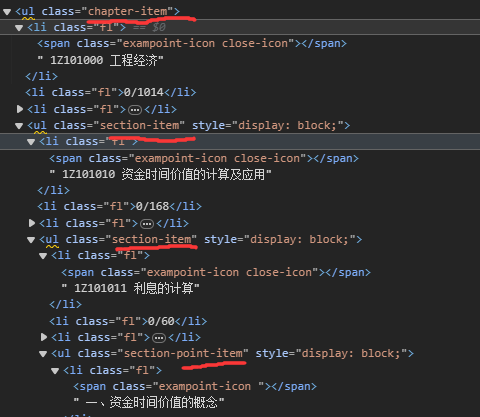
观察发现所有最里层的路径名都会放在类名为section-point-item的ul下第一个li中:
那我们就可以拿下所有的ul(section-point-item)让后进行遍历,一个个的去获取完整路径:
ul(section-point-item)的上层路径名都存放在ul[@class=‘section-item’ or @class=‘chapter-item’]ul类名为section-item或者chapter-item的标签中的第一个li中。
利用语句
i指的是ul(section-point-item)
i.xpath("./ancestor::ul[@class='section-item' or @class='chapter-item']")
会获得一个列表:
比如:一、资金时间价值的概念
会得到:
[1Z101000工程经济,1Z101010资金时间价值的计算及应用,1Z101011利息的计算]
对应得从外到里的关系:
all_sectionpointitem=resp.xpath(".//ul[@class='section-point-item']")
onetitle=resp.meta["one"]
twotitle=resp.meta["two"]if all_sectionpointitem:for i in all_sectionpointitem:
thretitle="".join(i.xpath("./li[1]//text()").extract()).strip().replace(" ","")#top sign的作用见下文
top="".join(i.xpath("./li[2]//text()").extract()).strip().split("/")[1]
sign="".join(i.xpath("./li[3]/span/@data_sign").extract()).strip().replace(" ","")
subsign="".join(i.xpath("./li[3]/span/@data_subsign").extract()).strip().replace(" ","")
r =[onetitle, twotitle]
fj = i.xpath("./ancestor::ul[@class='section-item' or @class='chapter-item']")for j in fj:
p_name="".join(j.xpath("./li[1]//text()").extract()).strip().replace(" ","")
r.append(p_name)
r.append(thretitle)
dir_path="/".join(r)
跳转做题,拿下题目

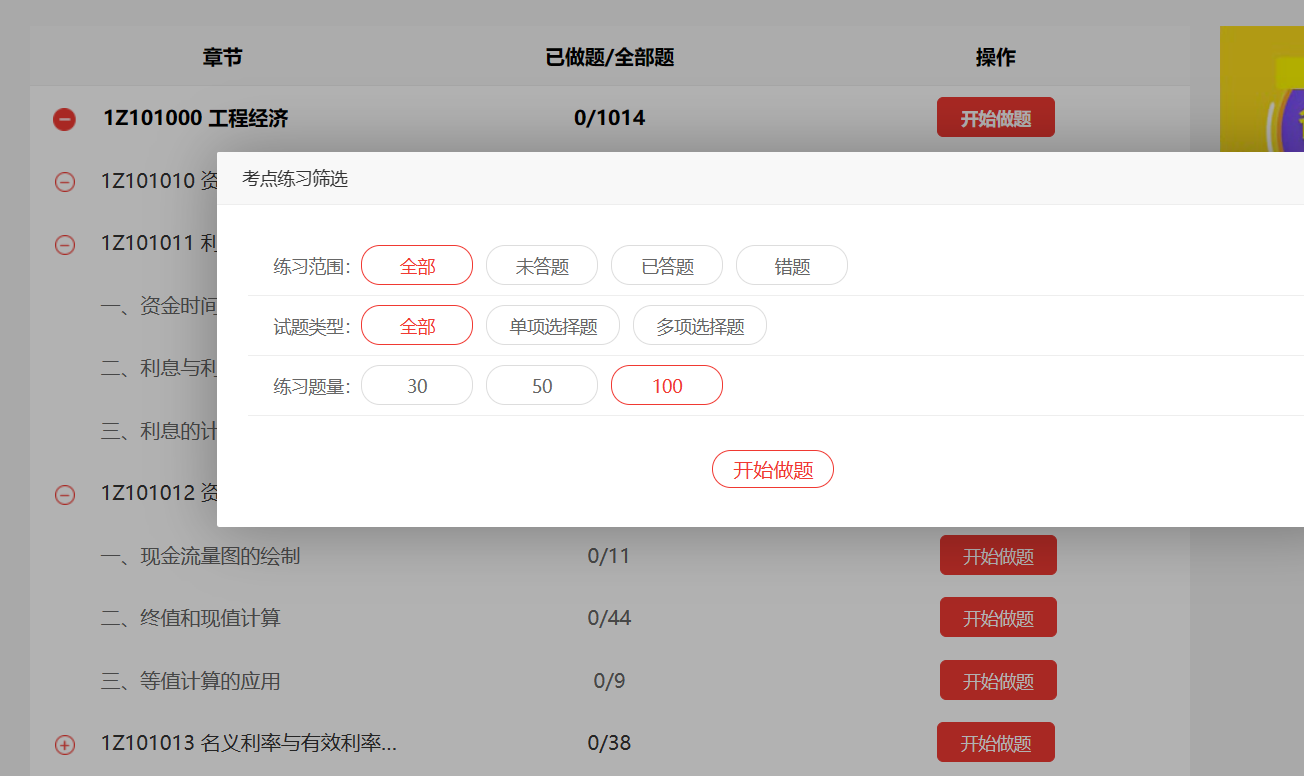
观察源码发现源码中两个网页没有可以发生跳转的链接,开始抓包:
在接收数据中发现POST请求:
题目数据存放在json中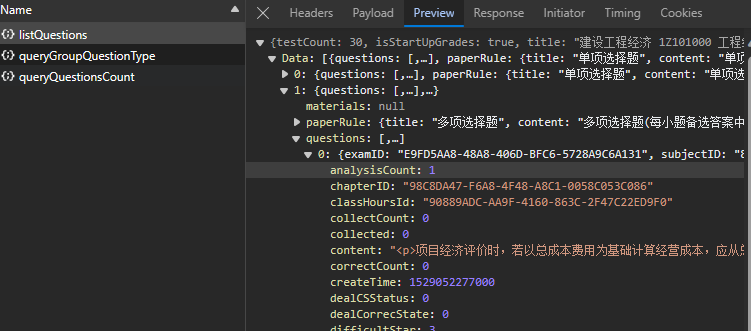
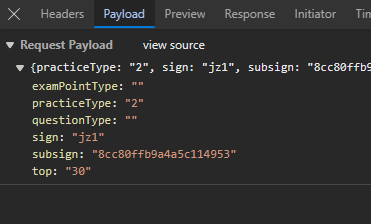

观察多个网页的请求发现:
Payload中:
examPointType:""(不变)
practiceType:"2" (不变)
questionType:"" (不变)
sign:"jz1"(变化)
subsign:"8cc80ffb9a4a5c114953" (变化)
top:"30" (题目数量)
那top、sign、subsign在哪找呢?
观察
top: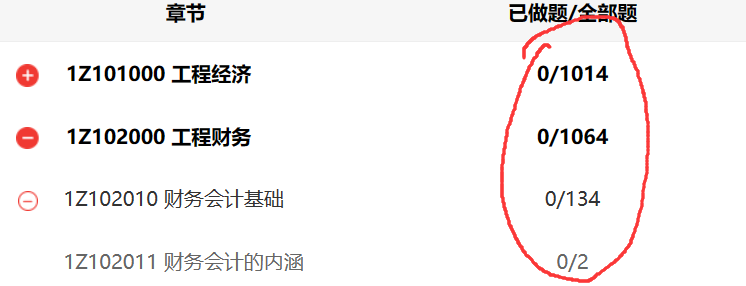
sign、subsign: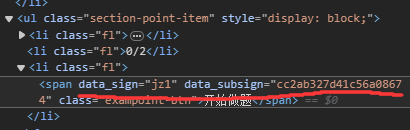
那么就有法发送请求获取题目数据了:
data={"examPointType":"","practiceType":"2","questionType":"","sign": sign,"subsign": subsign,"top": top
}yield scrapy.Request(
url="https://ks.wangxiao.cn/practice/listQuestions",
method="POST",
body = json.dumps(data),
callback=self.parse_qu,
dont_filter=True,
headers={"Content-Type":"application/json; charset=UTF-8"},
meta={"LJ":dir_path,"filename":thretitle
})
处理Json格式的题目数据
观察json文件格式发现在Data下存在多个字典每个字典下的questions(选择题)或者materials(材料题)键值内存放着题目信息。
#使用data.get("questions") 不存在"questions"键值就不会报错#使用data["questions"] 不存在"questions"键值会报错
data.get("questions")
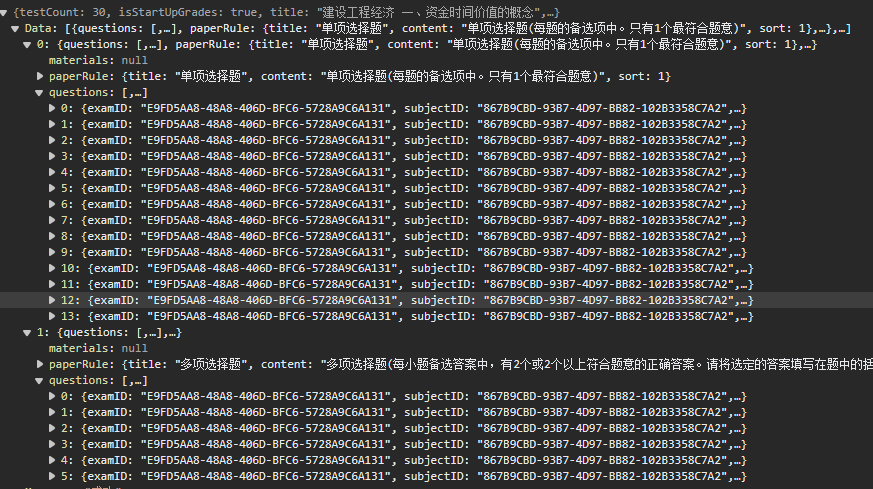
Datas = resp.json()#将json格式数据转为python对象
datas = Datas["Data"]#先从列表中拿下"Data"键下的题目数据for data in datas:#遍历datas列表,列表中存在一个个字典
questions = data.get("questions")#获取"questions"键下的值,一个列表if questions:for q in questions:#遍历列表,进行题目数据提取
s=self.process_q(q)#发送数据进行存储yield{"path":resp.meta["LJ"],"name":resp.meta["filename"],"tm":s}else:
materials = data.get("materials")#数据存放在"materials"列表中for mater in materials:
mater_content = mater["material"]['content']
questions = mater['questions']
qs =[]for q in questions:
q_info = self.process_q(q)
qs.append(q_info)
mater_content=mater_content+"\n\n"+qs
#发送数据进行存储yield{"path":resp.meta["LJ"],"name":resp.meta["filename"],"tm":mater_content}
defprocess_q(self,q):
tm = q["content"]#题目内容
op = q['options']#题目选项
jx = q['textAnalysis']#题目解析
op_list =[]
r_list =[]for o in op:
xxx = o["content"]
xx = o["name"]+"."+ o["content"]
op_list.append(xx)if o["isRight"]==1:if o["name"]in"ABCDEFGHJK":
r_list.append(o["name"])else:
xxx = xxx +"\n"
r_list.append(xxx)else:pass
s = tm +"\n"+"\n".join(op_list)+"\n"+"正确答案:"+"".join(r_list)+"\n"+ jx+"\n"#组合题目内容,s就是一条完整的题目数据return s
s的内容示例(含图片的会有标签):
关于资金时间价值的说法,正确的是( )。
A.资金周转速度的加快,对提升资金的时间价值有利
B.资金的时间价值与资金的使用时间长短无关
C.资金的时间价值与资金的数量无关
D.资金总额一定,前期投入越多,资金的正效益越大
正确答案:A
影响资金时间价值的因素很多,其中主要有以下几点:
1.资金的使用时间。在单位时间的资金增值率一定的条件下,资金使用时间越长,则资金的时间价值越大;使用时间越短,则资金的时间价值越小。B选项错误。
2.资金数量的多少。在其他条件不变的情况下,资金数量越多,资金的时间价值就越多;反之,资金的时间价值则越少。C选项错误。
3.资金投入和回收的特点。在总资金-定的情况下,前期投入的资金越多,资金的负效益越大;反之,后期投入的资金越多,资金的负效益越小。而在资金回收额一-定的情况下,离现在越近的时间回收的资金越多,资金的时间价值就越多;反之,离现在越远的时间回收的资金越多,资金的时间价值就越少。D选项错误。
4.资金周转的速度。资金周转越快,在一定的时间内等量资金的周转次数越多,资金的时间价值越多;反之,资金的时间价值越少。A选项正确。
【知识点】资金时间价值的概念
【考察方向】概念释义
【难易程度】易
存储数据
存数据时pipelines要导入的包:
import os
import scrapy
from lxml import etree
from scrapy.pipelines.images import ImagesPipeline
首先我们要考虑,材料题的数据中存在图片,我们得把图片下下来存放在对应文件夹里,并且对s中img标签进行src地址替换,让它根据本地文件路径显示图片。(注意是相对路径)
优先级较高的步骤,下载题目素材:
#ImagesPipeline ---继承ImagesPipeline中的方法get_media_requests、file_path、item_completed进行##方法重写classPICPipeline(ImagesPipeline):#发送下载请求defget_media_requests(self, item, info):
jxq=etree.HTML(item['tm'])#xpath定位
srcs = jxq.xpath("//img/@src")for s in srcs:yield scrapy.Request(url=s,meta={"path":item['path'],"f_name":item['name'],"src":s},dont_filter=True)#确定文件保存位置和文件名字deffile_path(self, request, response=None, info=None,*, item=None):
path = request.meta['path']
f_name = request.meta['f_name']
wj_name = request.meta['src']
real_name = wj_name.split("/")[-1]return path+"/"+"img"+"/"+real_name
#下载结果处理---resultsdefitem_completed(self, results, item, info):#print(results)for i in results:
status = i[0]#下载状态-True --False
dic = i[1]if status:
src = dic['url']
wzpath = dic['path'].split("/")[-2:]
path = wzpath[0]+"/"+wzpath[1]
item['tm']= item['tm'].replace(src,path)print("替换为本地图片成功")return item #一定return item将数据传递下去
优先级较低的步骤,把题目存下来:
defprocess_item(self, item, spider):
d_path = item['path']
f_name = item['name']#如果文件路径不存在ifnot os.path.exists(d_path):# 创建它
os.makedirs(d_path)#完整路径
real_path = d_path+"/"+f_name+".md"
f=open(real_path,mode="a",encoding="UTF-8")#写入题目
f.write(item['tm'])
f.write("\n\n")
f.close()print("存下一道题目!")return item
版权归原作者 秋刀鱼_(:з」∠)_别急 所有, 如有侵权,请联系我们删除。