
1、数据类型-Data Type
定义程序中可以使用的数据类型,使用前要先定义;利用
**TYPES**语句声明数据类型,只能在该程序中使用。
TYPES可用来声明TABLE、WORK、AREA的数据,不占内存
示例:
TYPES:BEGIN OF ty_table.
TYPES: name_first TYPE but000-name_first.
TYPES: name_last TYPE but000-name_last.
INCLUDE TYPE zibf_s_006.
TYPES: END OF ty_table.
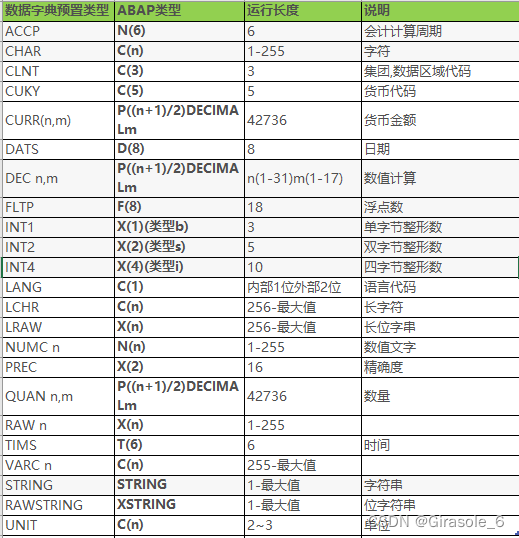
ABAP基本数据类型:


2、数据变量:
数据变量是在程序中参照数据类型定义的值。
常用方法是用
**Data**语句定义变量。
注意:变量实际指数据对象,数据对象在程序执行期间占用内存空间

3、DATA语句:
用于定义数据变量,变量名可以包含_, 长度最长30位。
DATA <变量名>(长度) TYPE <数据类型> VALUE <初始值>
TYPE——定义变量数据类型LIKE——定义与前一个变量相同类型变量VALUE——设置变量初始值LENGTH——指定变量字段长度,仅适用【C/N/P/X】类型DECIMALS——指定1-14位小数,仅适用【P】类型CONSTANTS——声明变量。【
CONSTANT <变量名>(长度) TYPE <数据类型> VALUE <默认值>
】WRITE——输出变量。【WRITE / <变量>.多个加“:”】
指针类型定义:
** FIELD-SYMBOLS: **<data1>
TYPE any.
类型转换——
**DESCRIBE FIELD **<data1>
TYPE any.
**TABLES:**定义数据表、视图、结构体。
4、数据类型转换:
浮点数——转换成char类型
function
QSS0_FLTP_TO_CHAR_CONVERSIONchar类型——转换成浮点数
function
QSS0_CHAR_FLTP_CONVERSION

5、判断字符串数据类型是否为数字
function NUMERIC_CHECK

注:【如果是纯数字 没有小数点,这么判断是可以的(注意NUMC是会自动补0的,仅用于判断类型没问题),但是如果有小数就会变成CHAR】
另一种判断方法:
IF cl_abap_matcher=>matches(
pattern = '^(-?[1-9]\d*(.\d*[1-9])?)|(-?0.\d*[1-9])$'
text = '数字' ) = abap_true.
ENDIF.
6、
**最常用的系统变量有:**
SY-SUBRC: 系统执行某指令后,表示执行成功与否的变量,’0’ 表示成功
SY-UNAME: 当前使用者登入SAP的USERNAME;
SY-DATUM: 当前系统日期;(SY-DATLO)
SY-UZEIT: 当前系统时间;(SY-TIMLO)
SY-TCODE: 当前执行程序的Transaction code
SY-REPID: ABAP 程式名,目前的主程式
SY-CPROG: ABAP 程式名
SY-SYSID: R/3 系統,R/3 系統名稱,
SY-UCOMM: 画面,PAI 驱动的功能代码,一般用來參照定义变量
SY-INDEX : 当前LOOP循环过的次数 READ TABLE it_po INDEX 1 此時變量值1
** SY-TABIX:** 当前处理的是internal table 的第几笔
7、字符串操作关键字
拼接——CONCATENATEstr1 str2 into strSEPARATED BY ' '. 【SEPARATED BY 指的是两个字符串合并按照指定空格或其他符号 】【CONCATENATEstr1 str2 into str RESPECTING BLANKS 运用是会在拼接时保留字符串前后空格】
拆分——SPLITstrATspaceinto str1 str2. 【按照space空格或者其他符号进行拆分】
去除空格——CONDENSEstr.【每个连接字符串中间会保留一个空格】【后面加“NO-GAPS”所有空格去除】
转换——TRANSLATEstrTO UPPER/LOWER CASE. 【大小写转换】
STR = 'Barbcbdbarb'.TRANSLATE STR
USING 'ABBAabba'.
取字符串长度—— **STRLEN**.【len = strlen( str ) 长度获取数据类型必须是C/N/D/T】

截取字符串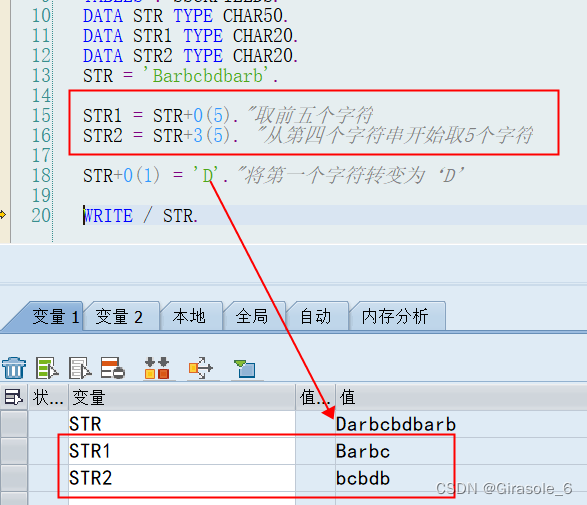
8、字符串操作符号
操作符
说明
示例
含义
CO
操作字符串1中每个字符都在操作字符串2中存在,则表达式为true,反之为false.表达式为true时sy-fdpos = 操作字符串1的长度 ,为false时,sy-fdpos = 操作字符串1中不在操作字符串2中的字符所在作字符串1中第一个位置。
s1 CO s2
如果s1仅包含s2中的字符,逻辑表达式为真
CN
操作字符串1中不是每个字符都在操作字符串2中存在,则表达式为true,反之为false.表达式为false时sy-fdpos = 操作字符串1的长度 ,为true时,sy-fdpos = 操作字符串1中不在操作字符串2中的字符所在作字符串1中第一个位置。
s1 CN s2
如果s1还包含s2之外的字符,逻辑表达式为真
CA
操作字符串1中任意字符在操作字符串2中存在,则表达式为true,sy-fdpos = 第一个出现在操作字符串2中的字符所在操作字符串1中的第一个位置。反之为false ,sy-fdpos = 操作字符串1长度。
s1 CA s2
如果s1包含任何一个s2中的字符,逻辑表达式为真
NA
操作字符串1中任意字符在操作字符串2中不存在,则表达式为true,sy-fdpos = 操作字符串1长度。反之为false ,sy-fdpos = 第一个出现在操作字符串2中的字符所在操作字符串1中的第一个位置。
s1 NA s2
如果s1不包含s2的任何字符,逻辑表达式为真
CS
操作字符串1中任意字符串在操作字符串2中存在,则表达式为true,sy-fdpos = 第一个出现在操作字符串2中的字符串的第一个字符所在操作字符串1中的第一个位置。反之为false ,sy-fdpos = 操作字符串1长度。如果操作字符串1为空操作字符串2不空则表达式为false,sy-fdpos = 0.
s1 CS s2
如果s1包含字符串s2,逻辑表达式为真
NS
操作字符串1中任意字符串在操作字符串2中不存在,则表达式为true,sy-fdpos = 操作字符串1长度。反之为false ,sy-fdpos = 第一个出现在操作字符串2中的字符串的第一个字符所在操作字符串1中的第一个位置。
s1 NS s2
如果s1不包含字符串s2,逻辑表达式为真
CP
操作字符串1与操作字符串2中字符完全匹配,操作字符串2中输入通配符 “*”代表任意字符串,“+”任意字符。如果匹配则表达式为true,sy-fdpos = 操作字符串1中与操作字符串2中除操作通配符外的第一个字符位置。反之为false ,sy-fdpos =操作字符串1的长度。
s1 CP s2
如果s1包含模式s2,逻辑表达式为真
NP
操作字符串1与操作字符串2中字符不完全匹配,操作字符串2中输入通配符 “*”代表任意字符串,“+”任意字符。如果匹配则表达式为true,sy-fdpos =操作字符串1的长度。反之为false ,sy-fdpos = 操作字符串1中与操作字符串2中除操作通配符外的第一个字符位置。
s1 NP s2
如果s1不包含模式s2,逻辑表达式为真
注:****【CO,CN,CA,NA比较时区分大小写,且尾部空格也在比较范围之内,CS,NS,CP,NP比较时忽略尾部空格且不区分大小写,比较结束后,如果结果为真,SY-FDPOS将给出s2在s1中的偏移量信息.模式表示可以使用通配符,”*”用于替代任何字符串,”+”用于替代单个字符.】
option可以取以下值:
'EQ' , 'NE' 等于,不等于
'GT' , 'LT' 大于 ,小于
'GE' , 'LE' 大于等于,小于等于
'CP' , 'NP'
'BT' , 'NB'
9、算术运算关键字与函数
数字运算:
ABS, 返回绝对值, ABS(-100)renturn 100SIGN, 返回符号, 负数return -1, 0 return 0, 整数return 1CEIL, 返回不小于该值的最小整数, ceil*1.3) ceil(1.7) 返回最小整数2FLOOR, 返回不大于该值的最大整数, floor(1.3) ceil(1.7) 返回整数1TRUNC取整, trunc(1.3) trunc(1.7)返回整数1FRAC取小数, frac('2.9') 返回0.9DIV—— c = a div b,得到的c的值就是a除b的商。/—— c = a / b,如果c是i数据类型的,这个语法会进行四舍五入的。MOD—— c = a mod b,得到的c的值的就是a除b的余数。
浮点函数:
ACOS/ASIG/ATAN/COS/SIN/TAN三角函数COSH/SIGNH/TANH 双曲线函数EXP 指数函数LOG 自然对数函数, 以e为底LOG10 常用对数函数, 以10为底SQRT 平方根函数, 开方
结构体计算:ADD-CORRESPONDING(加)、ADD TO
SUBTRACT-CORRESPONDING(减)、subtract <n>from <m> m-n
MULTIPLAY-CORRESPONDING(乘)、MULTIPLY <M> BY<N>
DIVIDE-CORRESPONDING(除)。DIVIDE<M> BY<N> M/N
10、内表与数据表操作关键字
APPEND:将结构内容附加到内部表。本操作仅可针对标准表进行。 【COLLECT[ INTO ] 计算字段之和】append <wa>
to <itab> “ 不带表头行的填充append <itab> “ 带隐式表头行的填充
APPEND LINES OF:将内部表中若干行的内容附加到另一个标准表。INSERT:将结构内容插入内部表、数据库表。(数据库表、内表不存在的数据)INSERT INTO dbtab
VALUES wa.INSERT INTO dbtab
FROM wa.INSERT dbtab
FROM TABLES itab.INSERT dbtab
FROM TABLE itab
ACCEPTING DUPLICATE KEYS. 【ACCEPTING DUPLICATE的效果是:若出现关键字相同,返回4,并跳过其再更新所有的其他。】MODIFY:利用结构内容覆盖内部表行。MODIFY dbtab
FROM wa.MODIFY dbtab
FROM TABLE itab.UPDATE:将结构更新到数据库表中(数据库表、内表中已经存在的数据)UPDATE dbtab
SET f1=g1 ... fn=gn
WHERE .
UPDATE dbtab
FROM wa.UPDATE dbtab
SET f1=g1 ... fi=gi [WHERE ].
UPDATE target
FROM TABLE itab.MOVE: 整体复制内表,目标内表原有内容被覆盖。MOVE <itab1>
TO <itab2> 不带表头行的内表之间进行复制MOVE <itab1>[]
TO <itab2>[]. 带表头行的内表之间进行复制MOVE <itab1>
TO <itab2>[]. 不带表头行的内表复制到带表头行的内表MOVE-CORRESPONDING <itab1>
TO <itab2> 复制内表1中与内表2具有相同结构的字段进行复制,同样适用于工作区SORT:排序ASCENDING和DESCENDING指定升序还是降序排列,如果不指定,缺省排序方式是升序 SORT <itab>[ASCENDING | DESCENDING] [AS TEXT
] 【TEXT按照字段排序,不指定按照内部编码或语言首字母字符排序】READ TABLE:将表行内容复制给结构。(WITH KEY :数据关键字;WITH TABLE KEY:表关键字)READ TABLE [INTO ]
WITH KEY [BINARY SEARCH].READ TABLE [INTO ]
INDEX .LOOP AT .. . ENDLOOP:LOOP 语句会将内部表的表行逐行放置到在INTO 子句中指定的结构内。在LOOP 中,可输出或更改结构的当前内容,并写回表中。Loop at <itab>
into <wa> .<statement block>endloop. “ 带表头行的内表循环操作
Loop at <itab> .
<statement block>endloop. “ 不带表头行内表操作
循环体的MODIFY,DELETE等语句不必指定
INDEX项,系统默认处理当前行 .如果不需要读取所有的内表行,可以使用WHERE选项进行限制
LOOP AT <itab> [WHERE <conditions>]DELETE:删除内部表中满足逻辑条件<condition> 的所有行。DELETE FROM dbtab
WHERE . 删除单行数据或DELETE dbtab
FROM wa.DELETE FROM dbtab
WHERE . 删除多行数据:DELETE dbtab
[CLIENT SPECIFIED] FROM TABLE itab.DELETE .在循环中删除行
DELETE INDEX
. 用索引删除行DELETE ADJACENT DUPLICATE ENTRIES FROM [COMPARING ].
删除邻近的 重复条目DELETE [
FROM 1>] [
TO 2>] [
WHERE ].删除选定行CLEAR/REFRESH/FREE:清空数据clear itab. 清表头(如果没有表头,清表体) 保存内存区
clear itab[]. 清表体 保存内存区
refresh itab. =
clear itab[]. 清表体 保存内存区free itab. 清表体 同时释放内存区
11、数据库关联关系
- INNER JOIN (内联):两个表a,b 相连接,取出符合连接条件的字段
- LEFT JOIN (左联):先返回左表的所有行,再加上符合连接条件的匹配行
- RIGHT JOIN (右联):先返回右表的所有行,再加上符合连接条件的匹配行

版权归原作者 Girasole_6 所有, 如有侵权,请联系我们删除。