
文章目录
Hadoop 入门及简单使用
1. 介绍
官方原话为:
The Apache™ Hadoop® project develops open-source software for reliable, scalable, distributed computing.
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
翻译过来就是hadoop贡献了一个可靠,大规模,分布式的计算开源软件(通常一个公司开发出产品在第一句话都要吹一下的,还都是一堆听起来很高大尚的专业术语😄),hadoop同时是一个允许使用简单的编程模型来处理分布式大数据集的框架,后面的你可以理解为是分布式统一的优点,这里不再详细分析,有兴趣的可以去了解一下分布式相关的技术。
2. 下载
2.1 官网下载
hadoop官网下载
目前最新的版本为3.3.4,当然你也可以用低一点的版本,我比较喜欢新一点的事物,但新版本可能不是很稳定,所以如果不是强迫症患者,建议下载低版本,我目前使用的是3.3.4,还没有出现什么问题.
2.2 网盘下载
我也将3.3.4版本的hadoop安装包分享出来了,有需要的可以自取
hadoop3.3.4
3.安装
3.1 上传并解压
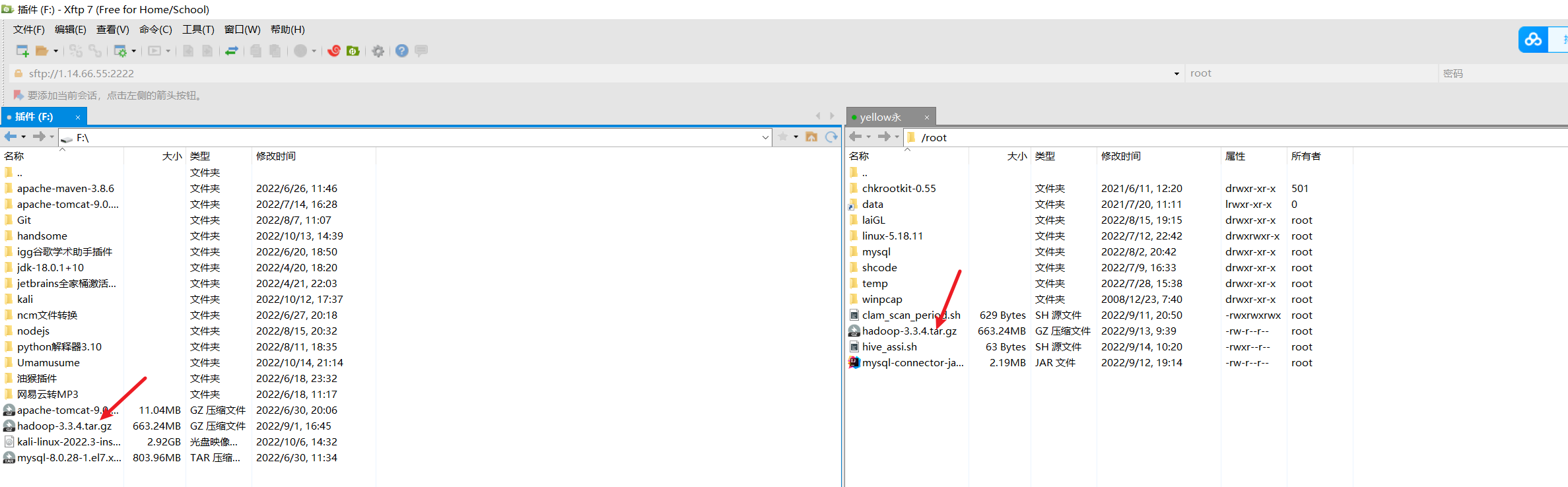
首先将压缩包通过FTP软件上传到自己的Linux服务器上,我这里使用的是xshell配套的xftp软件进行上传,也可以通过其他软件或者宝塔上传。
上传完后选择一个合适并且方便找到的目录进行解压,命令为:
tar -zxvf hadoop-3.3.4.tar.gz
之后会得到一个文件夹,(博主是一个有洁癖的人,一般安装完后会把压缩包文件夹删掉,至少删了可以多少释放点空间)

3.2 配置环境变量
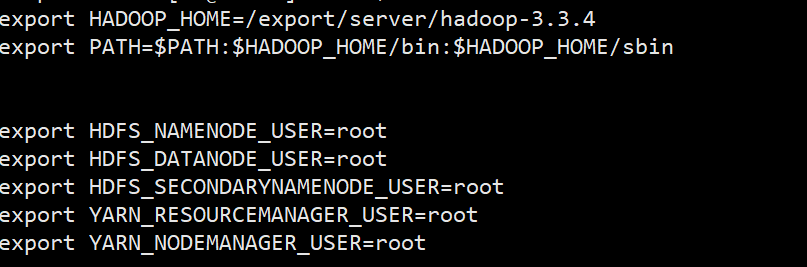
在/etc/profile文件里面新增这些选项,注意第一行的路径改成自己解压后的hadoop文件夹路径
到此恭喜你安装已经完成了
4. 配置hadoop
4.1 配置core-site.xml文件
首先进去刚刚解压好的目录hadoop-3.3.4,并进入etc文件夹
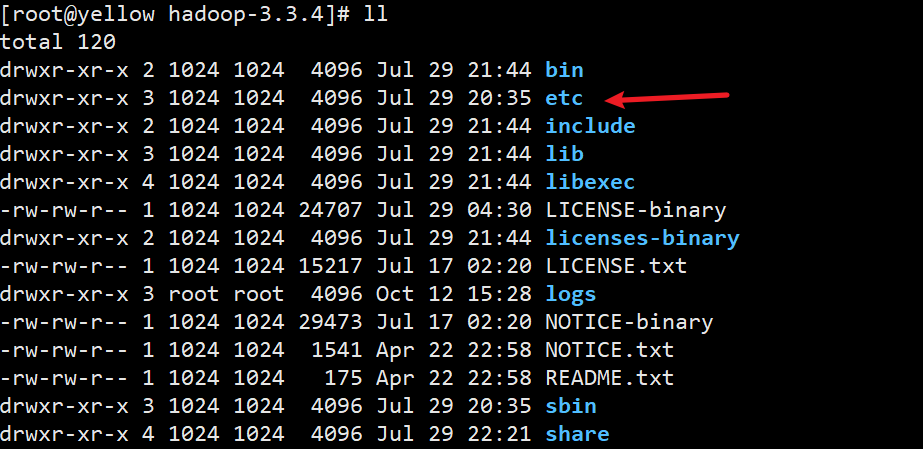
并找到core-site.xml文件,进去之后你会看到很多文件,但是不要慌张,我们要配置的也就6个文件😏
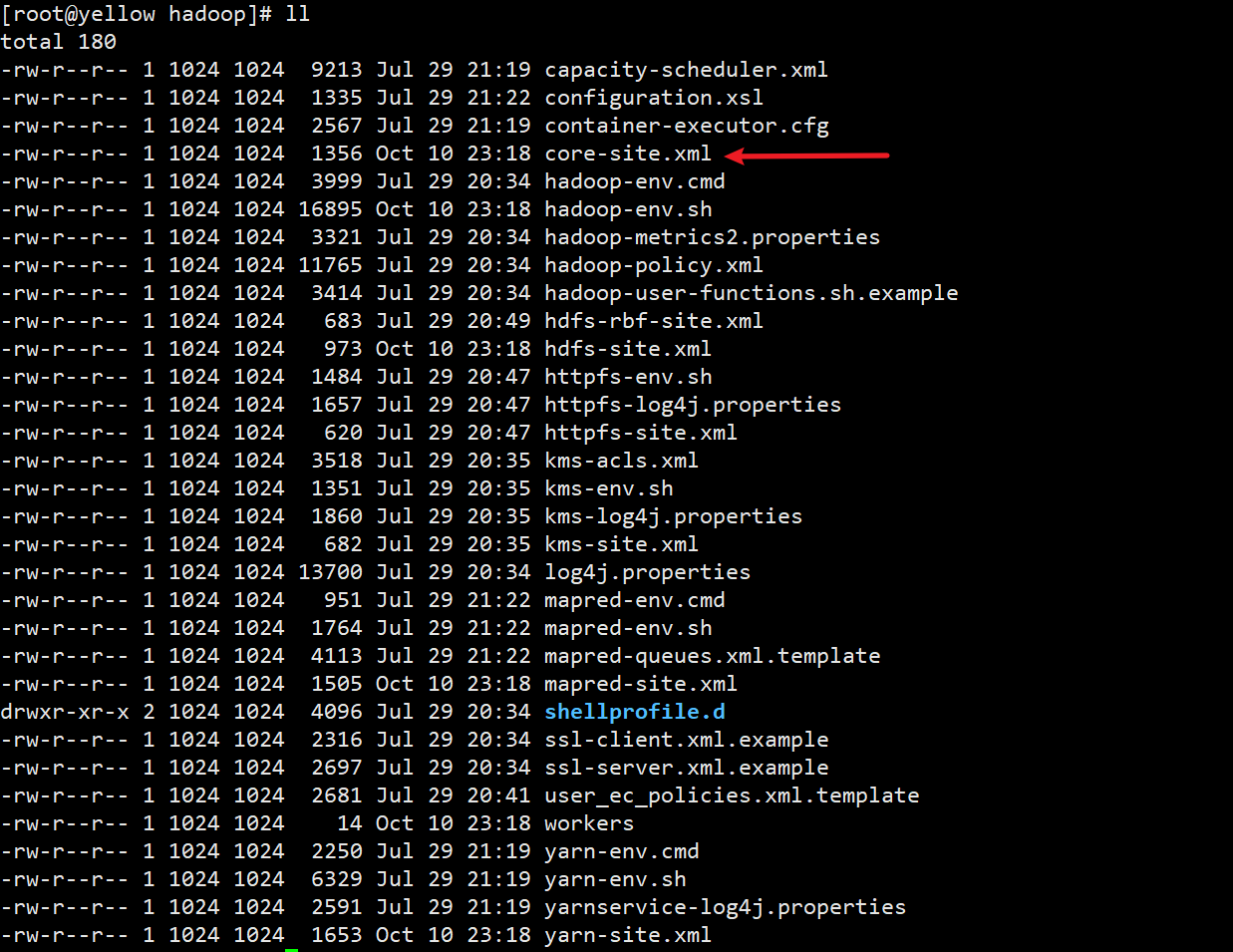
在此之前先介绍一下各个配置的作用
namevalueDescriptionfs.defaultFShdfs://csx:8020定义HadoopMaster的URI和端口,默认是9000 (也可以说指定namenode的地址)hadoop.tmp.dir/export/data/hadoop-3.3.4指定hadoop数据的存储目录,最好自己创建一个hadoop.http.staticuser.userroot-配置HDFS网页登录使用的静态用户为roothadoop.proxyuser.root.hosts*配置该hadoop(superUser)允许通过代理访问的主机节点 ,表示所有主机节点hadoop.proxyuser.root.groups配置该hadoop(superUser)允许通过代理用户所属组(这个估计暂时用不到)fs.trash.interval1440设置垃圾回收时间间隔
按照下面的配置就可以了:
<configuration><property><name>fs.defaultFS</name><value>hdfs://csx:8020</value></property><property><name>hadoop.tmp.dir</name><value>/export/data/hadoop-3.3.4</value></property><property><name>hadoop.http.staticuser.user</name><value>root</value></property><property><name>hadoop.proxyuser.root.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.root.groups</name><value>*</value></property><property><name>fs.trash.interval</name><value>1440</value></property></configuration>
4.2 配置hadoop-env.sh

除了红色箭头标记出来的之外,其他的套模板就行
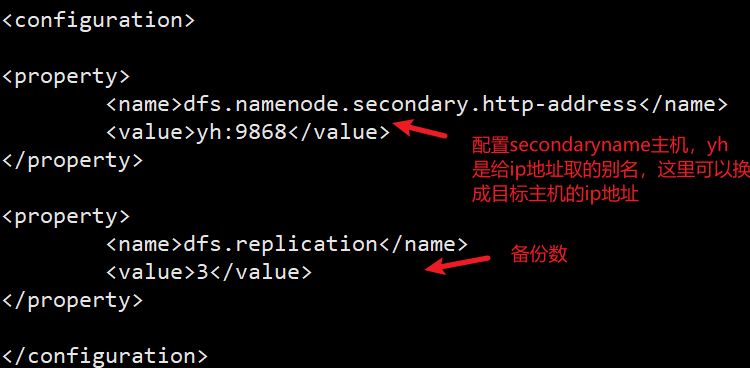
4.3 配置hdfs-site.xml
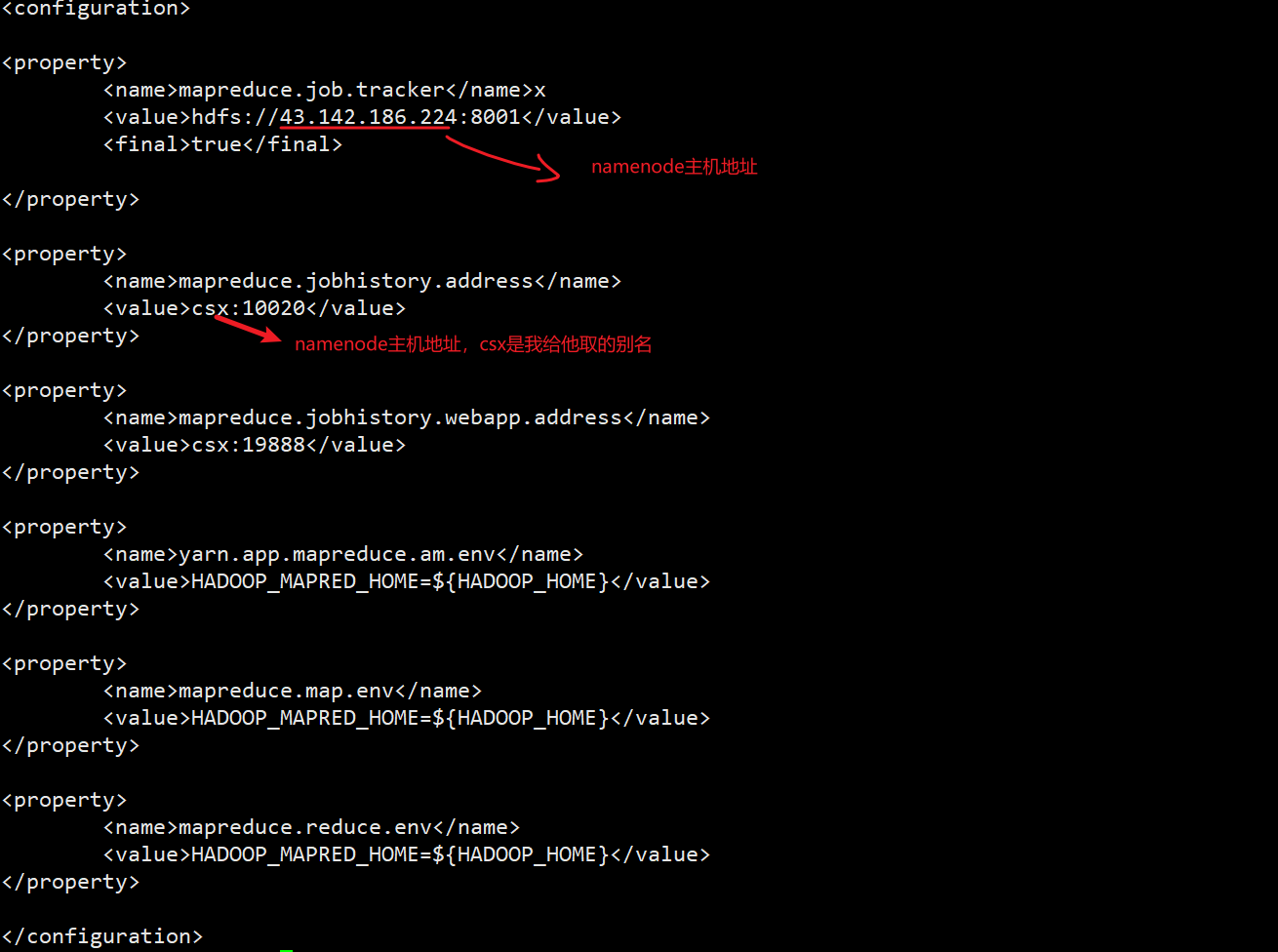
4.4 配置mapred-site.xml
4.5 配置works
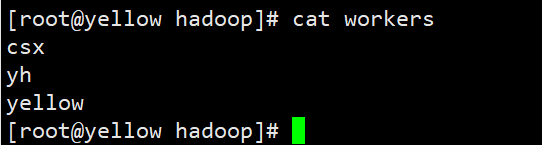
csx是主机namenode的别名,yh和yellow是子主机,这里首先要在hosts文件下配置解析
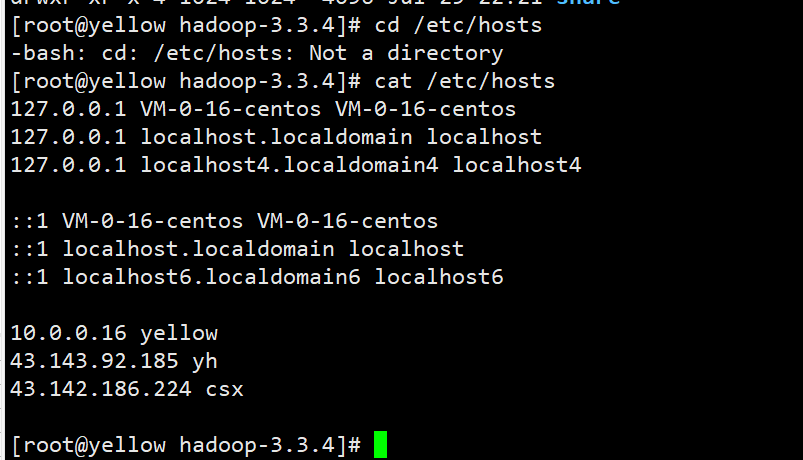
这里有个问题,就是yellow主机,也就是我当前配置的这台主机(因为我这里有三台机器,yellow是我的一个子主机,csx是namenode),开始我都是写的公网地址,后面配置ssh免密登录后他就自己给我改成了内网地址,这里我猜想是某些地方自己做了优化,但总之不影响使用,一开始就填公网也行,到时候如果他自己转换成内网地址也没有影响。
4.6 配置yarn-site.xml
<configuration><property><name>yarn.resourcemanager.hostname</name><value>csx</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value></property><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property><property><name>yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage</name>y
<value>95.0</value></property><property><name>yarn.nodemanager.resource.memory-mb</name><value>2048</value></property><property><name>yarn.log-aggregation-enable</name><value>true</value></property><property><name>yarn.log.server.url</name><value>http://csx:19888/jobhistory/logs</value></property><property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value></property></configuration>
像我这样写就行了,其中csx换成自己的namenode别名(hosts文件配置的那个)。
4.7 拷贝配置到其他子主机
scp hadoop-3.3.4 root@yh:$PWD
yh是你的子主机,可以换成ip地址,$PWD代表当前主机下的当前目录,因为我三台主机为了方便管理集群
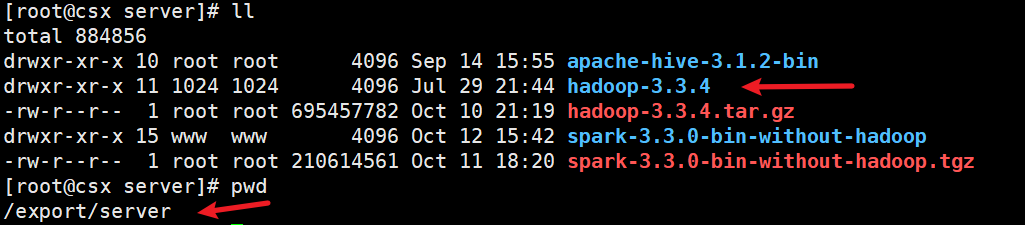
都是放在了/export/server目录下。通过拷贝这样其他两个主机就可以不用重复配置了。ps:使用这个命令需要配置三台主机ssh免密登录,具体操作可以看我的博客yellow永博客,(如果想再其他主机按照上面一步一步配置也可以,就不用拷贝了😺,就是有点小麻烦)
拷贝后的效果:
ok,到此配置完结撒花!😢
5.格式化namenode
注意:格式化操作只能进行一次!如果多次format除了造成数据丢失外,还会导致hdfs集群主从角色之间互不识别。只有通过删除所有机器hadoop.tmp.dir目录重新format解决
- 首次启动HDFS必须对其进行格式化操作
- format 本质上是初始化工作,进行HDFS清理和准备工作
- 命令:
hdfs namenode -format
成功格式化效果如下
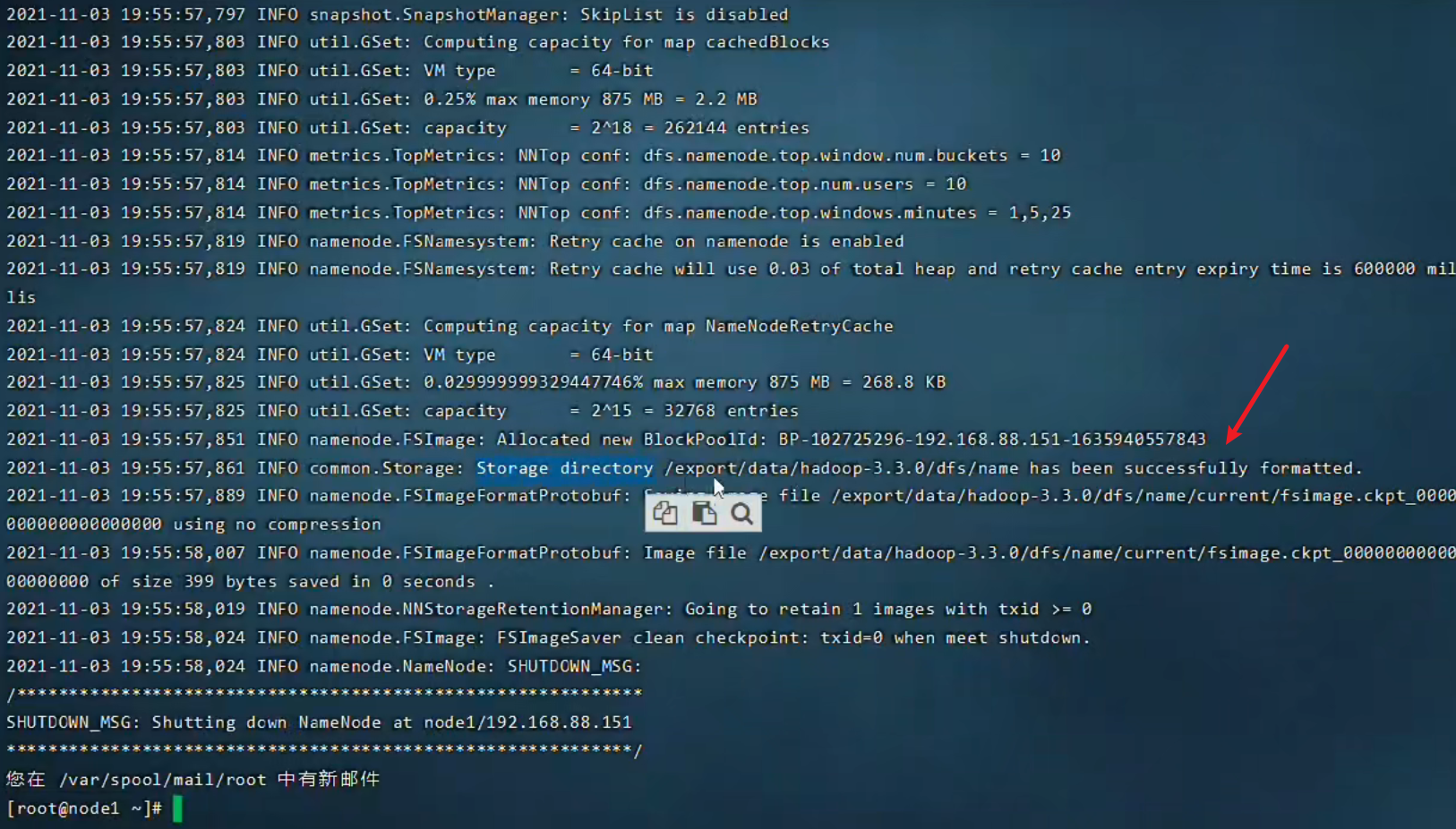
这里面包含了配置文件内的很多信息,细心的朋友可以好好研究一下
6.启动集群
虽然有很多单独启动单独停止的命令,但如果想偷懒,就用下面的命令,达到群起群停的效果
start-all.sh
stop-all.sh
用jps命令查看启动效果
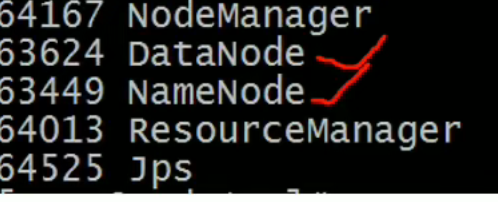
主节点的启动效果(namenode)
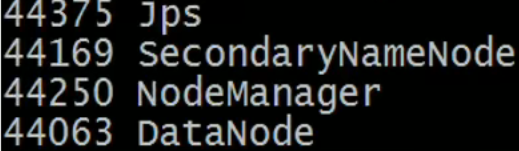
从节点一的启动效果
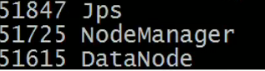
从节点二的启动效果
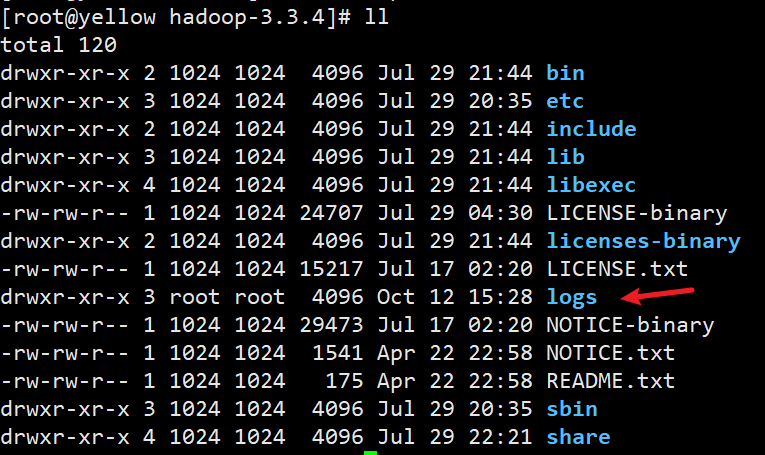
在hadoop目录下可以查看启动日志,方便排查错误,如果不会看日志的小伙伴可以直接复制错误找度娘!
常见的错误就是端口没开放,包括防火墙以及如果你用的是云服务器,还要去对应的控制台开启安全组端口,云服务器厂商提供
安全组也是为了主机的安全(作为一个经常被入侵的可怜人深有体会!)
7.访问web网页
如果前面配置正确并且能正确显示节点,现在你就可以访问hdfs网页了!
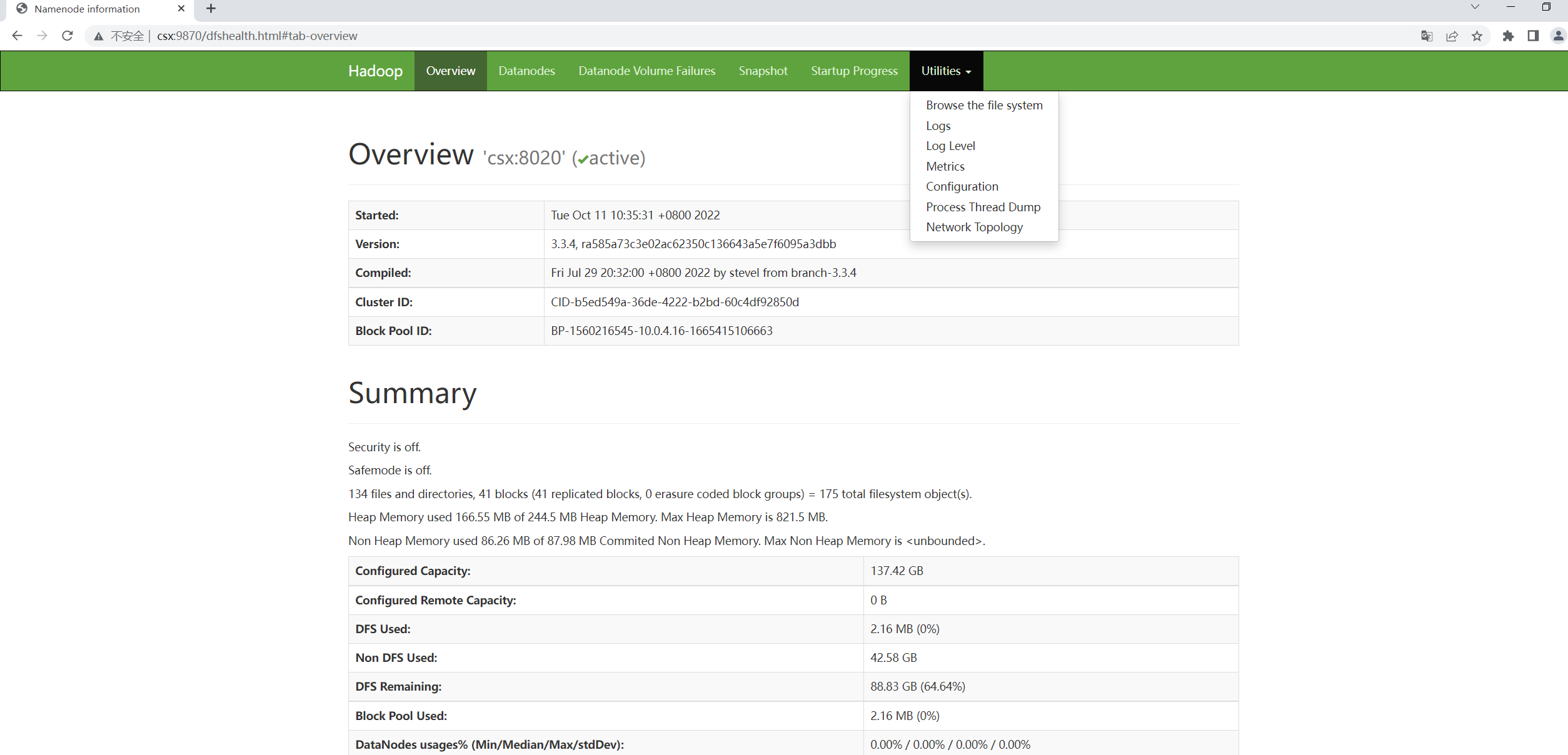
这里的csx就是namenode节点的别名(我windows也配了hsots文件的,也可以直接写ip,毕竟博主是个懒人)
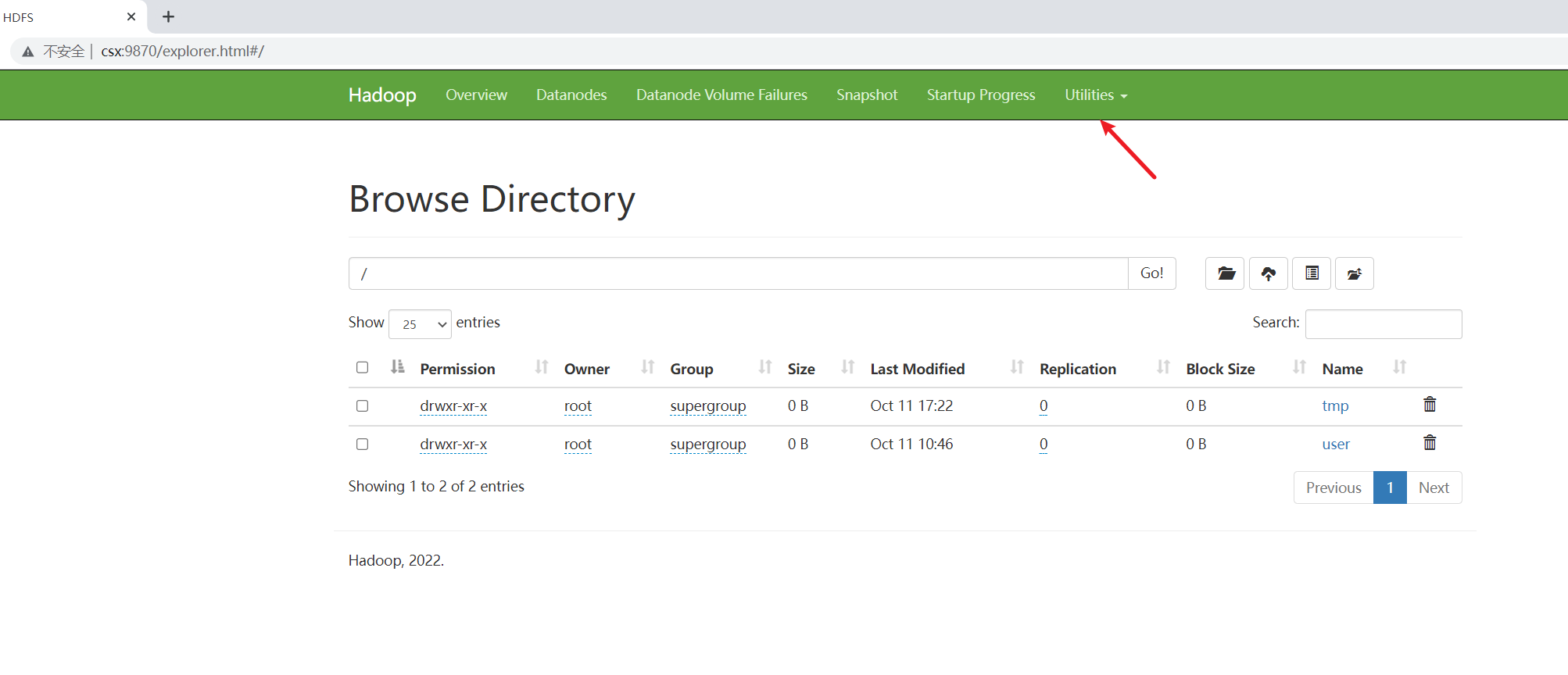
按照图示点进来出现下面这样的效果就大功告成了!
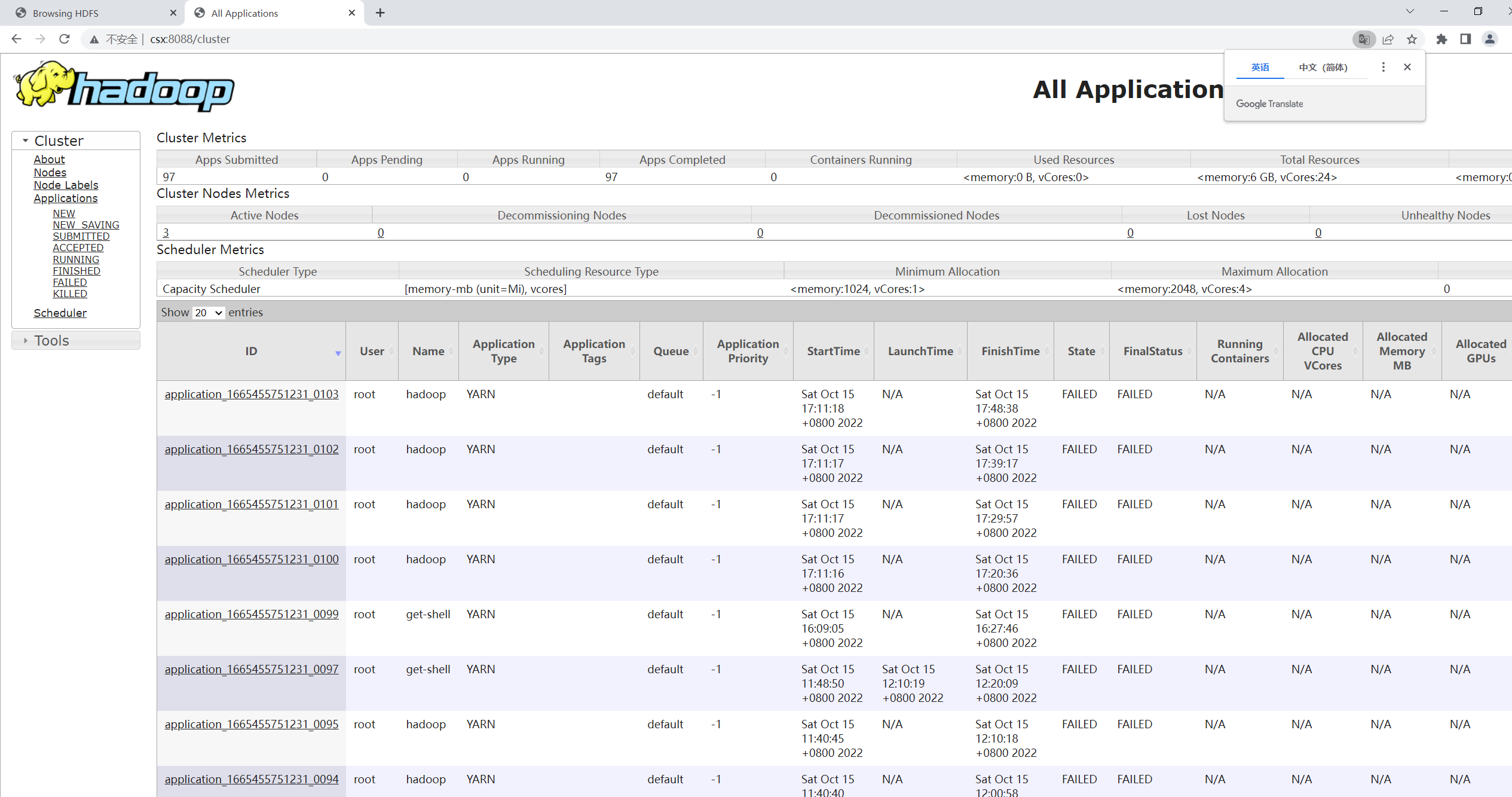
输入namenode:8088,就是yarn集群界面,这里可以查看后台运行任务的状态(初始配置是比较干净的,这是博主运行很多次之后的样子),因为本篇主要讲配置,就不讲相应的功能了
8.hadoop初体验
下面我们来计算一下PI值
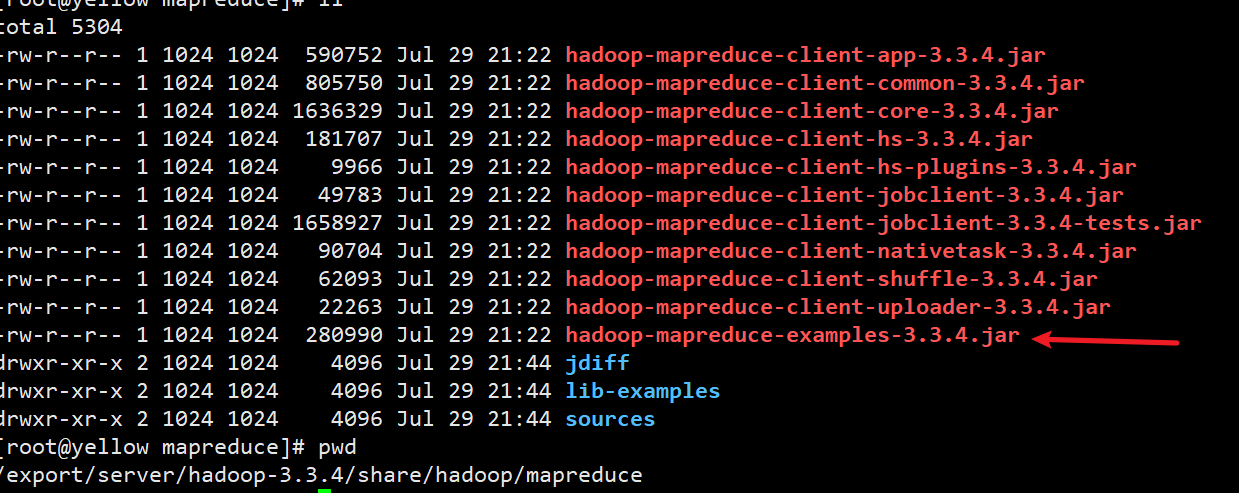
hadoop官方为我们提供了一个示例包
hadoop jar hadoop-mapreduce-examples-3.3.4.jar pi 100100
如果嫌等待时间过长,可以写为
hadoop jar hadoop-mapreduce-examples-3.3.4.jar pi 22
不过精度会下降(这就体现了一个好的计算引擎的重要性)
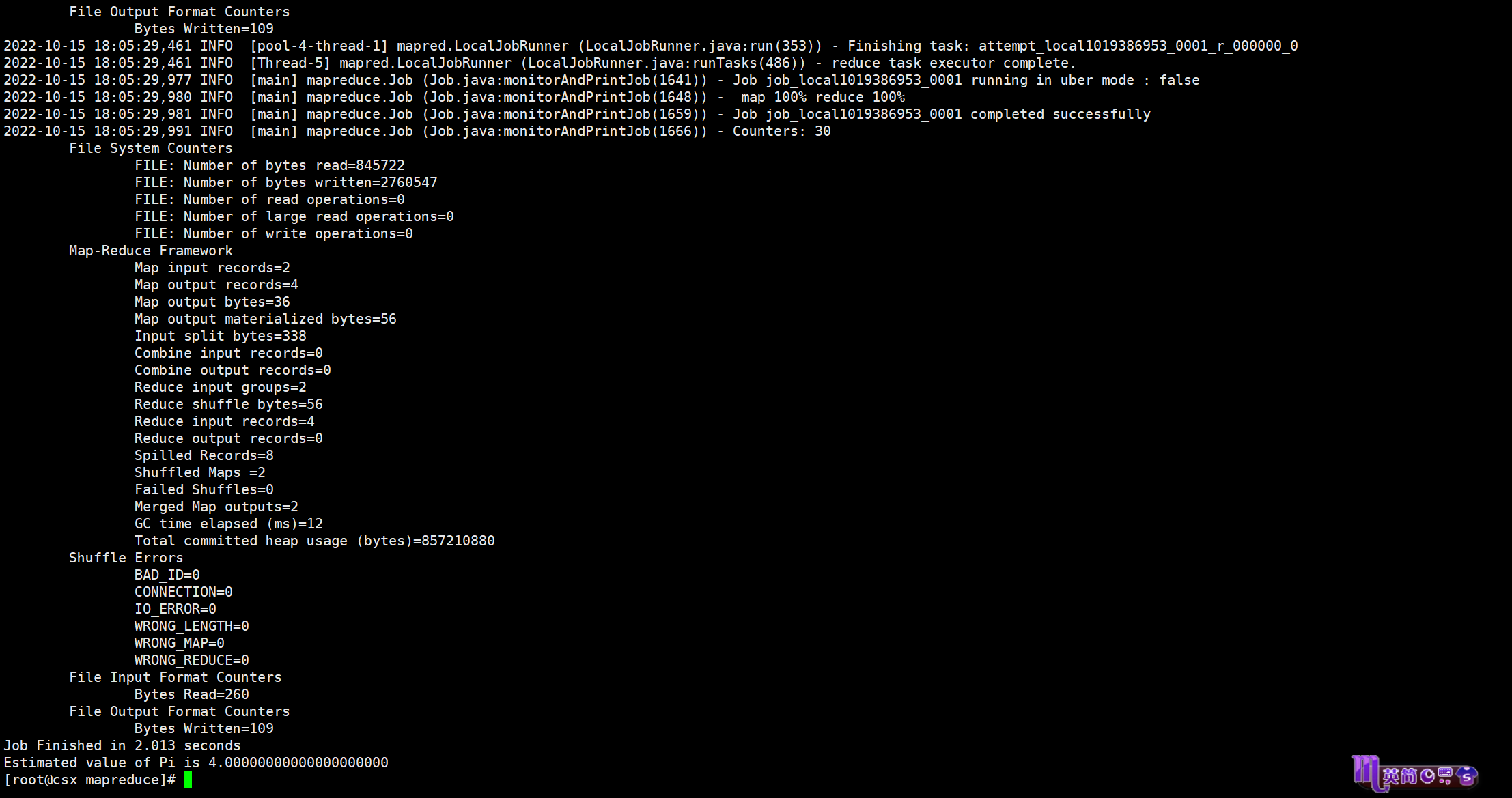
pi 2 2的效果如上,至此hadoop就搭建完成了。后续我会继续出关于hadoop以及编程方面的其他知识,我一直相信那句话:当你知道的越多,不知道的也就越多
,欢迎关注我的博客
yellow永的博客
版权归原作者 凛如霜雪 所有, 如有侵权,请联系我们删除。