
一、集群节点信息如何更新?
EurekaServer节点启动的时候,DefaultEurekaServerContext.init()方法调用PeerEurekaNodes.start()方法,start方法中resolvePeerUrls()会从配置文件读取serviceUrl属性值获得集群最新节点信息,通过updatePeerEurekaNodes()方法将最新节点信息更新到PeerEurekaNodes类的属性peerEurekaNodes和peerEurekaNodeUrls中。
PeerEurekaNodes.start()还提供了一个更新节点信息的定时任务,每隔PeerEurekaNodesUpdateIntervalMs (默认10min) 时间执行一次。

针对上述这个过程,需要注意的是(网上很多文章表述有误):peerEurekaNodesUpdateIntervalMs这个参数并不是集群节点注册信息的同步间隔时间。为什么这么说呢?我们可以看上图中的定时任务peersUpdateTask做了什么事情即可,其实只要看updatePeerEurekaNodes(resolvePeerUrls())做了什么即可。
通过源码跟踪:resolvePeerUrls()方法默认即执行了EndpointUtils.getServiceUrlsFromConfig(),即从配置文件读取服务节点urls信息。updatePeerEurekaNodes()方法则把获取得到的urls与之前urls信息进行对比,该新增的放到新增list,该删除的放到删除list,如果既没有新增的节点也没有待删除的节点,则返回不做任何处理。下面是代码:
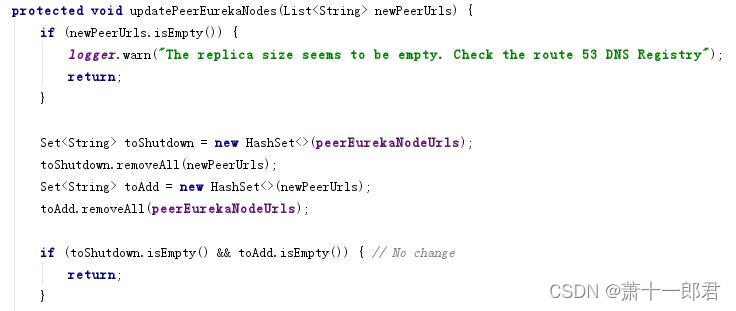
针对要删除的节点,处理方式是从节点列表移除,同时调用该节点的shutDown方法;针对要新增的节点,则加入到节点列表中,并创建新的节点,调用方法createPeerEurekaNode(String peerEurekaNodeUrl);创建节点最终调用了构造方法:
new PeerEurekaNode(registry, targetHost, peerEurekaNodeUrl, replicationClient, serverConfig);
上述构造方法会从服务其他节点获取注册服务信息同步到新创建的服务节点中。
那么接下来就要问第二个问题了。
二、注册服务信息如何在集群节点中同步?
注册服务信息在集群节点中的同步有两种场景:一种是新增服务节点如何从其他服务节点同步服务注册信息;另一种是稳定的集群中,各节点之间是如何同步服务注册信息。
我们先来看第一种场景,新增节点如何从其他服务节点同步服务注册信息。
(1)Eureka Server节点启动时的服务同步
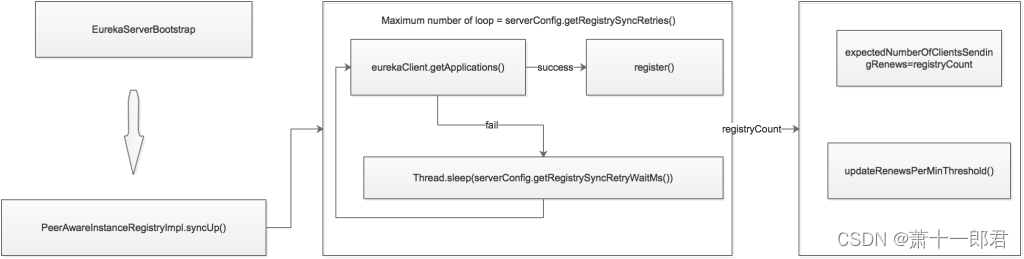
Eureka Server启动时,EurekaServerBootStrap调用PeerAwareInstanceRegistryImpl.syncUp(),同步注册服务信息。
// Copy registry from neighboring eureka node
int registryCount = this.registry.syncUp();
this.registry.openForTraffic(this.applicationInfoManager, registryCount);
syncUp()进行注册服务信息的同步:
/**
* Populates the registry information from a peer eureka node. This
* operation fails over to other nodes until the list is exhausted if the
* communication fails.
*/
@Override
public int syncUp() {
// Copy entire entry from neighboring DS node
int count = 0;
for (int i = 0; ((i < serverConfig.getRegistrySyncRetries()) && (count == 0)); i++) {
if (i > 0) {
try {
Thread.sleep(serverConfig.getRegistrySyncRetryWaitMs());
} catch (InterruptedException e) {
logger.warn("Interrupted during registry transfer..");
break;
}
}
Applications apps = eurekaClient.getApplications();
for (Application app : apps.getRegisteredApplications()) {
for (InstanceInfo instance : app.getInstances()) {
try {
if (isRegisterable(instance)) {
register(instance, instance.getLeaseInfo().getDurationInSecs(), true);
count++;
}
} catch (Throwable t) {
logger.error("During DS init copy", t);
}
}
}
}
return count;
}
首先会从EurekaClient.getApplications获取所有的注册服务信息,然后调用register()进行服务注册。
如果同步失败,则会sleep serverConfig.getRegistrySyncRetryWaitMs()后,再次进行同步。
同步完成后,调用PeerAwareInstanceRegistryImpl.openForTraffic()方法,进行自我保护阀值的计算:
public void openForTraffic(ApplicationInfoManager applicationInfoManager, int count) {
// Renewals happen every 30 seconds and for a minute it should be a factor of 2.
this.expectedNumberOfClientsSendingRenews = count;
updateRenewsPerMinThreshold();
logger.info("Got {} instances from neighboring DS node", count);
logger.info("Renew threshold is: {}", numberOfRenewsPerMinThreshold);
this.startupTime = System.currentTimeMillis();
if (count > 0) {
this.peerInstancesTransferEmptyOnStartup = false;
}
DataCenterInfo.Name selfName = applicationInfoManager.getInfo().getDataCenterInfo().getName();
boolean isAws = Name.Amazon == selfName;
if (isAws && serverConfig.shouldPrimeAwsReplicaConnections()) {
logger.info("Priming AWS connections for all replicas..");
primeAwsReplicas(applicationInfoManager);
}
logger.info("Changing status to UP");
applicationInfoManager.setInstanceStatus(InstanceStatus.UP);
super.postInit();
}
至此,Eureka Server启动时的节点复制就进行完了。
备注
最大同步重试次数=serverConfig.getRegistrySyncRetries(),默认5次。
同步失败后每次同步的间隔时间=serverConfig.getRegistrySyncRetryWaitMs(),默认30s。
如果启动时同步服务注册信息失败,一段时间不对外提供服务注册功能,waitTimeInMsWhenSyncEmpty,默认5min。
第二种场景:
(2)Eureka Server接收到Register、renew、cancel时的服务同步
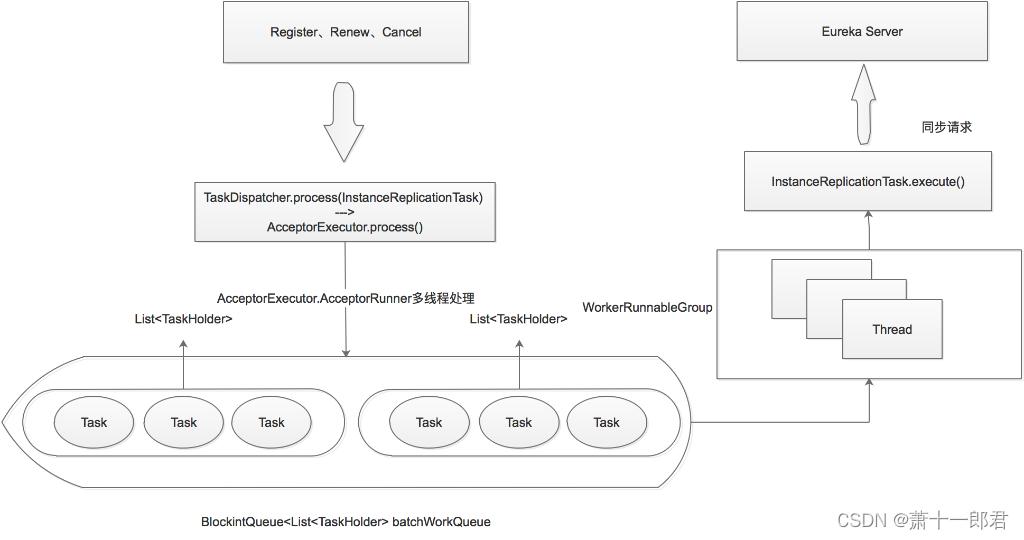
处理Register、renew、cancel同步时比较复杂,包括好几个队列的转换处理以及异常处理。这里算是个简图吧,省略了队列的转换和异常处理。
Eureka Server接收到Register、renew或cancel事件后,执行向其他节点同步:
/**
* Replicates all eureka actions to peer eureka nodes except for replication
* traffic to this node.
*
*/
private void replicateToPeers(Action action, String appName, String id,
InstanceInfo info /* optional */,
InstanceStatus newStatus /* optional */, boolean isReplication) {
Stopwatch tracer = action.getTimer().start();
try {
if (isReplication) {
numberOfReplicationsLastMin.increment();
}
// If it is a replication already, do not replicate again as this will create a poison replication
if (peerEurekaNodes == Collections.EMPTY_LIST || isReplication) {
return;
}
for (final PeerEurekaNode node : peerEurekaNodes.getPeerEurekaNodes()) {
// If the url represents this host, do not replicate to yourself.
if (peerEurekaNodes.isThisMyUrl(node.getServiceUrl())) {
continue;
}
replicateInstanceActionsToPeers(action, appName, id, info, newStatus, node);
}
} finally {
tracer.stop();
}
}
/**
* Replicates all instance changes to peer eureka nodes except for
* replication traffic to this node.
*
*/
private void replicateInstanceActionsToPeers(Action action, String appName,
String id, InstanceInfo info, InstanceStatus newStatus,
PeerEurekaNode node) {
try {
InstanceInfo infoFromRegistry = null;
CurrentRequestVersion.set(Version.V2);
switch (action) {
case Cancel:
node.cancel(appName, id);
break;
case Heartbeat:
InstanceStatus overriddenStatus = overriddenInstanceStatusMap.get(id);
infoFromRegistry = getInstanceByAppAndId(appName, id, false);
node.heartbeat(appName, id, infoFromRegistry, overriddenStatus, false);
break;
case Register:
node.register(info);
break;
case StatusUpdate:
infoFromRegistry = getInstanceByAppAndId(appName, id, false);
node.statusUpdate(appName, id, newStatus, infoFromRegistry);
break;
case DeleteStatusOverride:
infoFromRegistry = getInstanceByAppAndId(appName, id, false);
node.deleteStatusOverride(appName, id, infoFromRegistry);
break;
}
} catch (Throwable t) {
logger.error("Cannot replicate information to {} for action {}", node.getServiceUrl(), action.name(), t);
}
}
以Register为例(逻辑是一样的),Eureka Server循环遍历其他节点,然后调用node.register(info):
/**
* Sends the registration information of {@link InstanceInfo} receiving by
* this node to the peer node represented by this class.
*
* @param info
* the instance information {@link InstanceInfo} of any instance
* that is send to this instance.
* @throws Exception
*/
public void register(final InstanceInfo info) throws Exception {
long expiryTime = System.currentTimeMillis() + getLeaseRenewalOf(info);
batchingDispatcher.process(
taskId("register", info),
new InstanceReplicationTask(targetHost, Action.Register, info, null, true) {
public EurekaHttpResponse<Void> execute() {
return replicationClient.register(info);
}
},
expiryTime
);
}
这里执行TaskDispatcher的process,实际底层转到了AcceptorExecutor.process():
acceptorExecutor.process(id, task, expiryTime);
然后acceptorExecutor里会开启内部线程AcceptorRunner进行处理,处理逻辑有点复杂(包括队列的转换和异常处理),最终将处理好的结果放到BlockingQueue> batchWorkQueue中。
TaskExecutors中会在内部开启WokerRunnable线程组(ThreadGroup),循环poll batchWorkQueue队列中的Task,然后调用InstanceReplicationTask的execute方法,将register事件推送到其他Eureka Server节点。
public void run() {
try {
while (!isShutdown.get()) {
List<TaskHolder<ID, T>> holders = getWork();
metrics.registerExpiryTimes(holders);
List<T> tasks = getTasksOf(holders);
ProcessingResult result = processor.process(tasks);
switch (result) {
case Success:
break;
case Congestion:
case TransientError:
taskDispatcher.reprocess(holders, result);
break;
case PermanentError:
logger.warn("Discarding {} tasks of {} due to permanent error", holders.size(), workerName);
}
metrics.registerTaskResult(result, tasks.size());
}
} catch (InterruptedException e) {
// Ignore
} catch (Throwable e) {
// Safe-guard, so we never exit this loop in an uncontrolled way.
logger.warn("Discovery WorkerThread error", e);
}
}
register、renew、cancel的处理逻辑一样,只不过调用的同步接口不同罢了。
版权归原作者 萧十一郎君 所有, 如有侵权,请联系我们删除。