
记录一下自己前段时间解决的问题!
首先启动hadoop:
start-all.sh
然后就将hive中的这四个架包拷贝到flume的lib目录下:
拷贝过去:
cp/opt/hive/hcatalog/share/*/opt/flume/lib/
启动hive元数据服务,窗口不要关:
在hive中建表,根据你要采集的数据字段进行建表,并开启orc支持: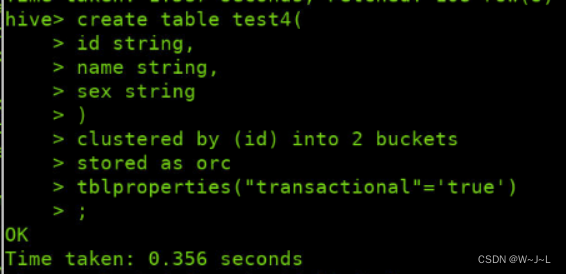
Hive命令行查询orc表时,需要激活以下配置,在hive中输入:
set hive.support.concurrency = true;set hive.exec.dynamic.partition.mode = nonstrict;set hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
接着就是开始配置你的flume文件,在添加输入文件的编码格式为GBK(主要还是取决于你文件的编码),不然会报错。配置如下: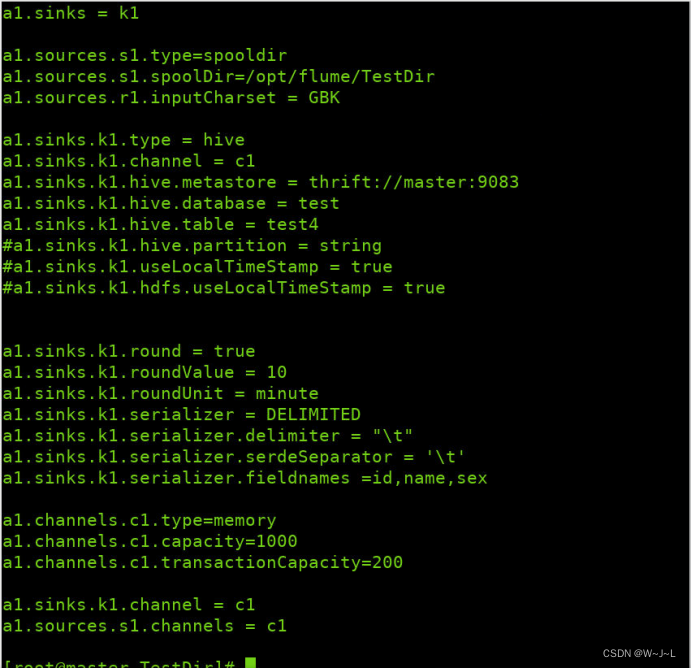
开启flume:
./flume-ng agent -n a1 -c conf -f /opt/flume/conf/one.conf -Dflume.root.lodder=INFO,console
其中-Dflume.root.lodder=INFO,console可不要,是日志打印:
将待采集的数据发给到监控文件目录下:
Flume开始工作: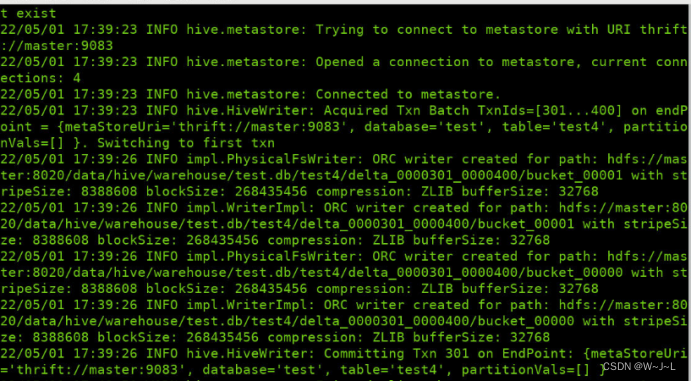
最后去hive表中查看结果: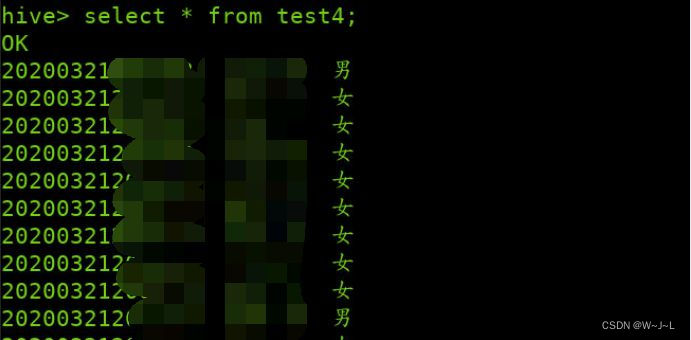
OK,搞定!
下面是我在过程中遇到的一些问题:
ip地址为master(xx.xx.xx.xx)而不是127.0.0.1
这里将通道从源获取或提供给接收器的最大事件数值设置大一些,来满足你自己的需求。如果是100则会报错。
每天扣扣脑袋,敲敲代码,还是挺有意思的呢!
本文转载自: https://blog.csdn.net/weixin_52136304/article/details/125018327
版权归原作者 W~J~L 所有, 如有侵权,请联系我们删除。
版权归原作者 W~J~L 所有, 如有侵权,请联系我们删除。