
概述:
1、zookeeper是一个开源的分布式的服务协调框架(Apache项目)
2、zookeeper从设计模式的角度来理解:是一个基于观察者模式的分布式服务管理框架,他负责存储和管理大家都关心的数据,然后接收观察者的注册,一旦这些数据发生变化,zookeeper就将负责通知已经在zookeeper是哪个注册的那些观察者做出相应的反应。
特点
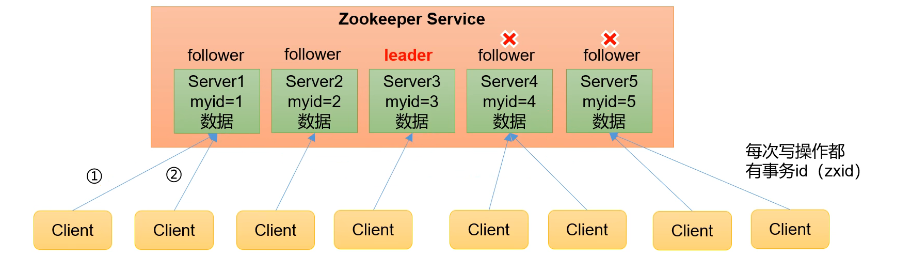
1、zookeeper为一个领导者(Leader),多个跟随者(Follower)组成的集群 。
2、集群中只要有半数以上节点存活,zookeeper集群就能正常服务,所以zookeeper适合安装奇数台服务器。
3、全局数据一致:每个Server(服务节点)保存一份相同的数据副本,Client无论连接到哪个server,数据都是一致的。
4、更新请求顺序执行,比如来自同一个客户端的多个请求,更新执行顺序按照其发送的前后顺序依次执行。
5、数据更新原子性,依次数据要么更新成功,要么失败。
6、实时性,在一定时间范围内,Client能读到最新的数据。
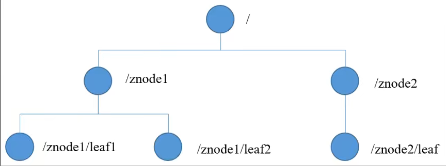
数据结构:
zookeeper数据模型的结构与Unix文件系统很类似,整体上可以看作是一颗树,每个节点称为一个ZNode,每一个ZNode默认能够存储1MB(配置信息)的数据,每个ZNode都可以通过其路径唯一标识。
应用场景:
统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等等。
统一配置管理:
① 一般要求一个集群中,所有节点的配置信息是一致的,比如kafuka集群。
② 对配置文件修改后希望能够快速同步到各个节点上。
③ 可将配置信息写入zookeeper上的ZNode。
④ 各个客户端服务器监听这个ZNode
⑤ 一但ZNode中的数据被修改,zookeeper将通知各个客户端服务器。
统一集群管理:
① 分布式环境中,实时掌握每个节点的状态是必要的、可以根据节点实时状态做出调整
② zookeeper可将节点信息写入zookeeper上的一个ZNode。
③ 监听这个ZNode可获取它的实时状态变化。
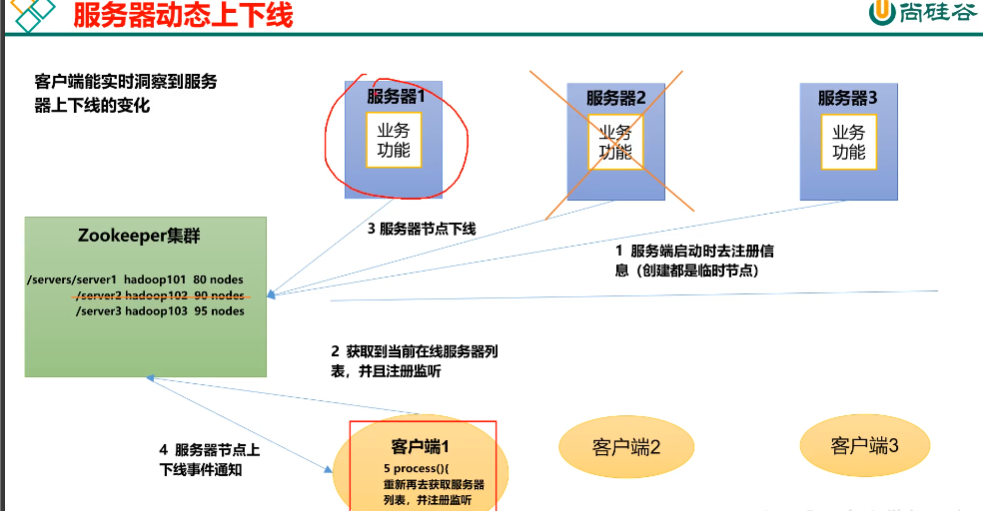
服务器节点动态上下线:
① 如果某台服务节点下线,能随时洞察到变化,并进行通知
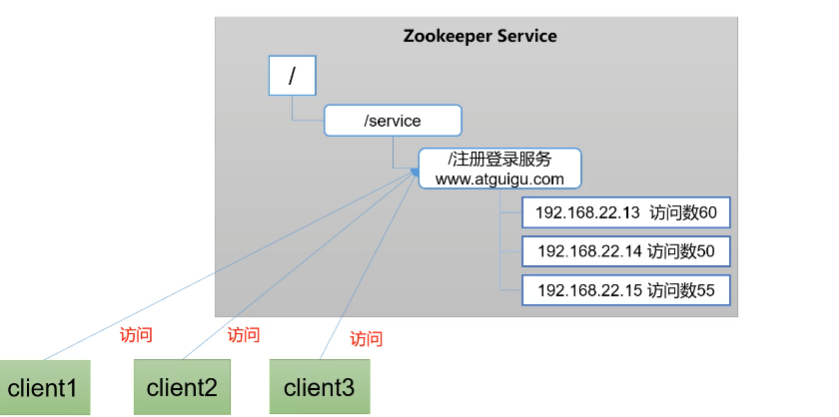
软负载均衡:
①在zookeeper中记录每台服务器的访问数,让访问数据最少的服务器去处理最新的客户端请求
Zookeeper安装
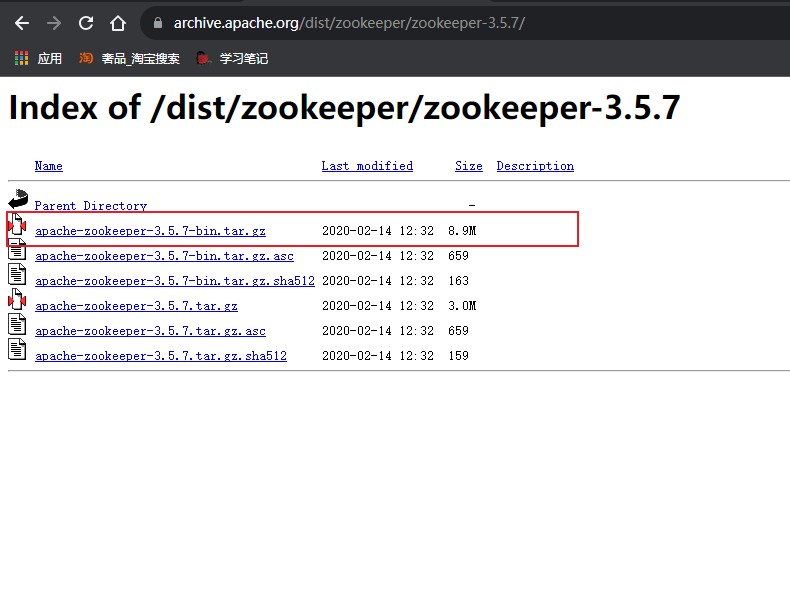
zookeeper下载地址:Index of /dist/zookeeper
正式生产环境比较稳定的版本:3.5.7
安装:(需要提前安装Java环境,这里自行百度,很简单)
1.将apache-zookeeper-3.5.7-bin.tar.gz包使用 xftp工具上传到Linux中的/opt/software目录下

2.使用命令:
# 指定将zookeeper解压安装到/opt/module目录下
tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module/
3.修改文件名,一般zookeeper的文件名太长我们手动修改一下
# 指定将zookeeper解压安装到/opt/module目录下
tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module/
4.修改 /opt/module/zookeeper-3.5.7/conf,也就是zookeeper安装目录下conf目录中的配置文件名称
# 原文件名称
-rw-r--r--. 1 502 games 922 2月 7 2020 zoo_sample.cfg
# 使用mv命令修改
[root@node1-zookeep conf]# mv zoo_sample.cfg zoo.cfg
[root@node1-zookeep conf]# ll
总用量 12
-rw-r--r--. 1 502 games 535 5月 4 2018 configuration.xsl
-rw-r--r--. 1 502 games 2712 2月 7 2020 log4j.properties
# 修改后的文件名称
-rw-r--r--. 1 502 games 922 2月 7 2020 zoo.cfg
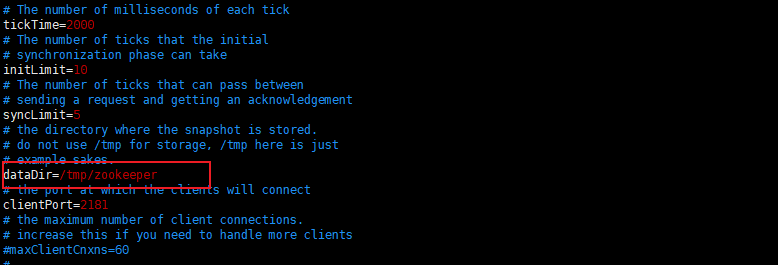
5.使用vim编辑zoo.cfg配置文件,这里主要先修改zookeeper快照目录,目录中存在的/tmp/**目录只是官方的示例,需要我们自己创建目录存放
5.1创建存储目录(我放在zookeeper的安装目录下 /opt/module/zookeeper-3.5.7):
# 创建‘zkData’目录
[root@node1-zookeep zookeeper-3.5.7]# mkdir zkData
# 进入目录后,查看当前创建目录所在位置
[root@node1-zookeep zkData]# pwd
/opt/module/zookeeper-3.5.7/zkData
# 查看目录下所有文件
[root@node1-zookeep zookeeper-3.5.7]# ll
总用量 32
drwxr-xr-x. 2 502 games 232 2月 10 2020 bin
drwxr-xr-x. 2 502 games 70 9月 20 00:18 conf
...
drwxr-xr-x. 2 root root 6 9月 20 00:18 zkData
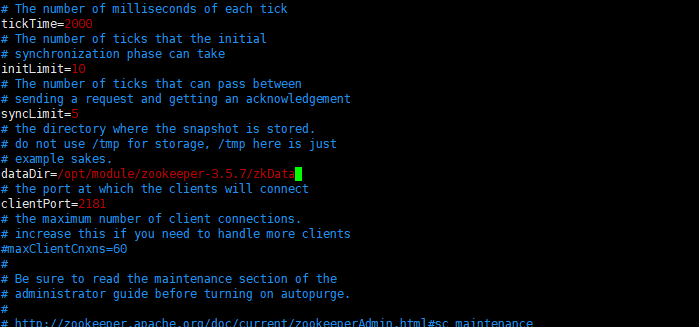
5.2将创建的目录所在位置配置到zoo.cfg文件中
启动zookeeper服务端:
# 1.进入zookeeper安装目录的bin目录中
[root@node1-zookeep zkData]# cd ../bin
# 2.查看服务对应的可执行文件
[root@node1-zookeep bin]# ls
README.txt zkCli.cmd zkEnv.cmd zkServer.cmd zkServer.sh zkTxnLogToolkit.sh
zkCleanup.sh zkCli.sh zkEnv.sh zkServer-initialize.sh zkTxnLogToolkit.cmd
# 3.使用./文件名 start 命令启动zookeeper服务
[root@node1-zookeep bin]# ./zkServer.sh start
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
# 4.查看zookeeper启动服务的进程
[root@node1-zookeep bin]# jps -l
8743 sun.tools.jps.Jps
8728 org.apache.zookeeper.server.quorum.QuorumPeerMain
[root@node1-zookeep bin]#
# 5.查看zookeeper状态
[root@node1-zookeep bin]# ./zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
# 6.启动服务使用的配置文件位置
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
# 本地模式
Mode: standalone
启动zookeeper客户端:
# 1.查看zookeeper 中的bin目录
[root@node1-zookeep bin]# ls
README.txt zkCli.cmd zkEnv.cmd zkServer.cmd zkServer.sh zkTxnLogToolkit.sh
zkCleanup.sh zkCli.sh zkEnv.sh zkServer-initialize.sh zkTxnLogToolkit.cmd
# 2.启动zookeeper客户端,注意不需要start命令,直接启动即可
[root@node1-zookeep bin]# ./zkCli.sh
/usr/bin/java
Connecting to localhost:2181
2023-09-20 00:31:47,347 [myid:] - INFO [main:Environment@109] - Client environment:zookeeper.version=3.5.7-f0fdd52973d373ffd9c86b81d99842dc2c7f660e, built on 02/10/2020 11:30 GMT
2023-09-20 00:31:47,349 [myid:] - INFO [main:Environment@109] - Client environment:host.name=node1-zookeep
2023-09-20 00:31:47,349 [myid:] - INFO [main:Environment@109] - Client environment:java.version=1.8.0_382
2023-09-20 00:31:47,351 [myid:] - INFO [main:Environment@109] - Client environment:java.vendor=Red Hat, Inc.
2023-09-20 00:31:47,351 [myid:] - INFO [main:Environment@109] - Client environment:java.home=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.382.b05-1.el7_9.x86_64/jre
...
退出zookeeper客户端:
# 退出客户端 quit 命令
[zk: localhost:2181(CONNECTED) 3] quit
WATCHER::
WatchedEvent state:Closed type:None path:null
2023-09-20 00:36:28,568 [myid:] - INFO [main:ZooKeeper@1422] - Session: 0x1000028a4700001 closed
2023-09-20 00:36:28,568 [myid:] - INFO [main-EventThread:ClientCnxn$EventThread@524] - EventThread shut down for session: 0x1000028a4700001
停止zookeeper服务:
# 1.停止zookeeper
[root@node1-zookeep bin]# ./zkServer.sh stop
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Stopping zookeeper ... STOPPED
# 2.再次查看进程,zookeeper已经不存在了
[root@node1-zookeep bin]# jps -l
8953 sun.tools.jps.Jps
zoo.cfg文件配置参数:
# The number of milliseconds of each tick
# 通信心跳时间,zookeeper服务器与客户端心跳时间,单位:毫秒
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
# Leader与Follower初始通信时限(第一次两者建立通信的时候能容忍的最多的心跳次数 tickTime的数量)
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
# Leader与Follower同步通信时限,两者之间时间如果超过 syncLimit * tickTime
# Leader 认为 Follower 已经挂掉,从服务器列表中删除Follwer
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
# 保存zookeeper中的数据。
# 注意:默认的tmp目录,容易被Linux系统定期删除,所以一般不使用默认的tmp目录
dataDir=/opt/module/zookeeper-3.5.7/zkData
# the port at which the clients will connect
# 客户端连接端口,通常不做修改
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
# 客户端最大连接数
#maxClientCnxns=60
zookeeper集群
实现集群的高可用。实际生产环境的集群搭建,需要我们使用Zookeeper的协调服务(如心跳机制)来保证集群节点的高可用,并实现故障节点自动切换、数据自动迁移。
当前演示的为在三台服务器(192.168.188.135(节点一),192.168.188.136(节点二),192.168.188.137(节点三))上安装部署zookeeper(每台安装步骤同上)
1.配置服务器编号
①在创建好的 /opt/module/zookeeper-3.5.7/zkData 目录下创建一个myid的文件
添加myid文件时,一定要在Linux里面创建,在notepad或者使用xftp用文本编辑创建很可能会导致乱码
# 使用vi 命令创建myid文件,并且在文件中添加与server对应的编号
# 注意上下不要有空行,左右不要有空格!
[root@node1-zookeep zkData]# vi myid
[root@node1-zookeep zkData]# cat myid
1
②拷贝安装配置好的zookeeper目录到其他服务器上,这里有两种方式,
- 方式一:直接拷贝zookeeper的安装目录或者按照上面单点的安装方式在多太服务器上进行安装。(比较繁琐)
- 方式二:使用xsync 集群分发脚本(或者使用scp -r 目录名 目标IP地址 目标目录的方式依次分发也可以)如果知道怎么使用xsync,请看这里集群分发脚本xsync简单使用-CSDN博客
# 拷贝zookeeper安装到多太服务器
[root@node1-zookeep zkData]# xsync zookeeper-3.5.7
③ 完成之后将每台服务器上的myid文件设置对应唯一标识
# 节点一的myid文件改为为1
[root@node1-zookeep zookeeper-3.5.7]# vim zkData/myid
[root@node1-zookeep zookeeper-3.5.7]# cat zkData/myid
1
# 节点二的myid文件改为为2
[root@node1-zookeep zookeeper-3.5.7]# vim zkData/myid
[root@node1-zookeep zookeeper-3.5.7]# cat zkData/myid
2
# 节点三的myid文件改为为3
[root@node1-zookeep zookeeper-3.5.7]# vim zkData/myid
[root@node1-zookeep zookeeper-3.5.7]# cat zkData/myid
3
2.添加配置
补充:配置IP映射名(可以不配置,但是建议还是配置好,配置 IP 映射名可以提高集群的可维护性和可扩展性。它使得节点更易于识别和引用,并且在节点的 IP 地址发生变化时也能保持一致。)
配置IP映射的方式:
- 打开每个zookeeper服务器节点的主机文件,一般在位置在: /etc/hosts
- 在每个节点的主机文件最后,添加以下条目:
# IP地址 主机名(自己定义)
- 将 IP地址 替换为节点的实际 IP 地址,将 主机名 替换为您希望使用的节点主机名。确保在每个节点上都添加了相同的条目,并将每个节点的 IP 地址和主机名一一对应。
#例如,假设您有三个节点,节点1 的 IP 地址为 192.168.0.1,节点2 的 IP 地址为 192.168.0.2,节点3 的 IP 地址为 192.168.0.3,您可以在每个节点的主机文件中添加以下条目:
192.168.0.1 node1_zookeeper
192.168.0.2 node2_zookeeper
192.168.0.3 node3_zookeeper
# 保存并关闭每个节点的主机文件。
在 ZooKeeper 配置文件 zoo.cfg 中的 server.X 配置项中,使用相应的主机名替代 IP 地址,以便引用节点。
这样配置后,ZooKeeper 节点将使用主机名来通信和交流,而不是直接使用 IP 地址。
①在每一个节点服务器上的zookeeper配置文件(../conf/zoo.cfg)中增加如下配置
# 如果配置IP的映射就使用hostname
server.1=node1_zookeeper:2888:3888
server.2=node2_zookeeper:2888:3888
server.3=node3_zookeeper:2888:3888
# 如果没有配置,就直接使用服务的IP即可
server.1=192.168.188.135:2888:3888
server.2=192.168.188.136:2888:3888
server.3=192.168.188.137:2888:3888
②# 配置详解 server.A=B:C:D
**A**:是一个数字,表示这是第几号服务器,就是myid中写的唯一标识,集群模式下配置一个文件myid,这个文件在zkData目录下,这个文件里面有一个数据就是A的值,zookeeper启动时读取该文件,拿到里面的数据与zoo.cfg里面的配置信息做对你,从而判断是哪个server
**B**:每个节点服务器的地址,如果修改了hostname(/etc/hostname),那么使用配置好的hostname,如果没有修改,那么就直接使用IP
**C**:是这个Follower服务器与集群中的Leader服务器交换信息的端口;
**D**:万一集群中的Leader服务器挂了,需要一个端口来重新选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口
③ 然后在各个服务器节点上配置环境变量(不配置也可以,对集群环境没有影响,不过这样就无法全局访问了,自己根据需求选择)
# vim 命令编辑profile文件
[root@node1-zookeep conf]# vim /etc/profile
#在profile文件最末尾添加如下配置:
# zookeeper envionment variables
export ZOOKEEPER_HOME=/opt/module/zookeeper-3.5.7
export PATH=$ZOOKEEPER_HOME/bin:$PATH
# 激活环境变量 source /etc/profile
[root@node1-zookeep /]# source /etc/profile
④开放防火墙端口,如果关闭防火墙或者开放端口,可能会导致节点之间连接失败导致启动失败。
- 启动Firewalld服务:sudo systemctl start firewalld
- 停止Firewalld服务:sudo systemctl stop firewalld
- 设置开机启动:sudo systemctl enable firewalld
- 停止开机启动:sudo systemctl disable firewalld
- 查看状态:sudo firewall-cmd --state
- 查看所有开放端口:sudo firewall-cmd --list-ports
- 开放端口:sudo firewall-cmd --add-port=端口号/协议 --permanent(永久开放) - 例如:sudo firewall-cmd --add-port=80/tcp --permanent(永久开放)
- 移除开放端口:sudo firewall-cmd --remove-port=端口号/协议 --permanent(例如:sudo firewall-cmd --remove-port=80/tcp --permanent)
- 重新加载配置:sudo firewall-cmd --reload
# 开放指定端口
[root@node1-zookeep conf]# sudo firewall-cmd --add-port=2888/tcp
success
[root@node1-zookeep conf]# sudo firewall-cmd --add-port=3888/tcp
success
[root@node1-zookeep conf]# sudo firewall-cmd --add-port=2181/tcp
success
或
# 直接关闭防火墙(正式环境不建议)
[root@node1-zookeep conf]# sudo systemctl stop firewalld
success
3.启动服务
1.如果是配置了环境的启动方式,三个节点全部启动zkServer
# 使用zkServer.sh start 即可
[root@node1-zookeep zookeeper-3.5.7]# zkServer.sh start
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
# 补充:
# 停止命令:zkServer.sh stop
# 重启命令zkServer.sh restart
2.没有配置环境的启动方式,三个节点全部启动zkServer
# 进入zookeeper的安装目录
[root@node1-zookeep ~]# cd /opt/module/zookeeper-3.5.7/bin
# 查看可执行文件
[root@node1-zookeep bin]# ls
README.txt zkCli.cmd zkEnv.cmd zkServer.cmd zkServer.sh zkTxnLogToolkit.sh
zkCleanup.sh zkCli.sh zkEnv.sh zkServer-initialize.sh zkTxnLogToolkit.cmd
# 使用 ‘./要执行的文件 start’
[root@node1-zookeep bin]# ./zkServer.sh start
# 补充
# 停止命令: ./zkServer.sh stop
# 重启命令: ./zkServer.sh restart
3.查看集群各节点状态
# 查看集群节点状态
[root@node1-zookeep ~]# zkServer.sh status
#一个节点输出如下:
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Client port found: 2182. Client address: localhost.
Mode: leader
#另外两个节点输出如下:
[root@node1-zookeep ~]# zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Client port found: 2182. Client address: localhost.
Mode: follower
有一台服务器的zk Mode为leader ,另外两台服务器的zk Mode为follower,如果配置了observer节点,则会有一台服务器的zk Mode为observer。
4.查看日志
zookeeper选举机制
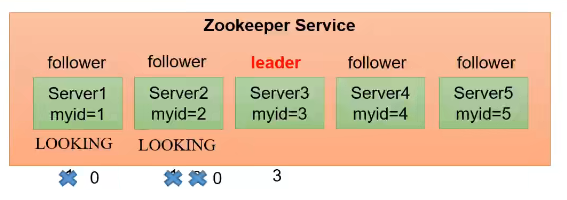
投票会优先投给myid比自己大的服务器节点,直到出现leader
服务器1启动:
投票结果:服务器1 :1票
不够半数以上(3票),选举无法完成,服务器1状态保持为LOOKING.
服务器2 启动:
投票结果:服务器1 :0票,服务器2 :2票
不够半数以上(3票),选举无法完成,服务器1和2状态保持为LOOKING.
服务器3 启动:
投票结果:服务器1 :0票,服务器2 :0票,服务器3 :3票
此时有服务器票数超过半数(3票),选举服务器3为Leader,服务器1和2状态保持为Following ,服务器三为Leading.
服务器4 启动:
投票结果:服务器1和2 :0票,服务器2 :0票,服务器3 :3票,服务器4:1票
此时服务器1,2,3已经不是LOOKING状态,leader已经产生,即使服务器4的myid更大,也不会更改选票。
服务器5启动:
同服务器4一样。
- SID:服务器ID,用来标识一胎zookeeper几圈中的机器,每台机器的SID不能重复,和myid一致。
- ZXID:事务id,zxid是一个事务id,用来标识一次服务器状态的变更,在某一时刻集群中的每台机器的zxid值不一定完全一致,这和zookeeper服务器对于客户端更新请求的处理逻辑有关。
- Epoch:每个Leader的任期代号,如果没有Leader时同一轮投票过程中的逻辑时钟值是相同的。每投完一次票这个数据就会增加
1.当zookeeper集群各种的一胎服务器出现两种情况之一,就会开始进入Leader选举:
- 服务器初始化启动。
- 服务器运行期间无法和Leader保持连接
2.当一台机器进入Leader选举流程时,机器试图去选举Leader时,当前集群就会处于以下两种情况:
- 集群中本来就存在一个Leader: 但是某台节点服务器因为连接不上而试图去选举Leader时,会被告知当前服务器的Leader信息,对于该机器来说,仅仅需要和Leader机器建立连接,并进行状态同步即可
- 集群中确实不存在Leader:如果LEader意外挂掉,因此就会从新开始选举,此时选举的规则为: - EPOCH(任期代号)大的直接选举为Leader- EPOCH(任期代号)相同,事务ID大的选举为Leader- 如果任期代号、事务ID还是没有选举出来的话,服务器ID大的选举为Leader
zookeeper启动停止脚本
1.创建一个文件(我放在/usr/local/bin,一般会在/home/bin目录下,自行选择)
# 查看当前所在目录
[root@node1-zookeep bin]# pwd
/usr/local/bin
# 创建zk.sh文件
[root@node1-zookeep bin]# vim zk.sh
zookeeper执行脚本编写(zk.sh文件)
#!/bin/bash
# 传入的命令
case $1 in
"start"){
# 循环集群中所有节点
for i in node1-zookeeper node2-zookeeper node3-zookeeper
do
# 输出信息
echo "------------------$i start ----------------------"
# 通过ssh 执行,ssh $i "zookeeper安装目录下的执行文件"
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh start"
done
};;
"stop"){
for i in node1-zookeeper node2-zookeeper node3-zookeeper
do
echo "------------------$i stop ----------------------"
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh stop"
done
};;
"status"){
for i in node1-zookeeper node2-zookeeper node3-zookeeper
do
echo "------------------$i status ----------------------"
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh status"
done
};;
esac
2.增加脚本的执行权限(直接给最大权限所有用户能访问,有限制不同用户需求自己研究Linux权限)
# 添加前
[root@node1-zookeep bin]# ll
-rw-r--r--. 1 root root 822 9月 21 05:21 zookeeper.sh
# 添加执行权限
[root@node1-zookeep bin]# chmod 777 zookeeper.sh
# 添加后
[root@node1-zookeep bin]# ll
-rwxrwxrwx. 1 root root 822 9月 21 05:21 zookeeper.sh
3.执行集群脚本
- zookeeper集群执行停止脚本
[root@node1-zookeep bin]# zookeeper.sh stop
------------------node1-zookeeper stop ----------------------
root@node1-zookeeper's password:
# 这里我没有配置免密,如果提示就输入自己的登录密码就好
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Stopping zookeeper ... STOPPED
------------------node2-zookeeper stop ----------------------
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Stopping zookeeper ... STOPPED
------------------node3-zookeeper stop ----------------------
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Stopping zookeeper ... STOPPED
- zookeeper集群执行启动脚本
[root@node1-zookeep bin]# zookeeper.sh start
------------------node1-zookeeper start ----------------------
root@node1-zookeeper's password:
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
------------------node2-zookeeper start ----------------------
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
------------------node3-zookeeper start ----------------------
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
- 启动状态下,执行zookeeper集群状态(status)脚本
root@node1-zookeep bin]# zookeeper.sh status
------------------node1-zookeeper status ----------------------
root@node1-zookeeper's password:
# 这里我没有配置免密,如果提示就输入自己的登录密码就好
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Client port found: 2182. Client address: localhost.
Mode: follower
------------------node2-zookeeper status ----------------------
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Client port found: 2182. Client address: localhost.
Error contacting service. It is probably not running.
------------------node3-zookeeper status ----------------------
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Client port found: 2182. Client address: localhost.
Mode: leader
zookeeper客户端命令行
1.连接客户端
# 查看可执行文件
[root@node1-zookeep bin]# ls
README.txt zkCli.cmd zkEnv.cmd zkServer.cmd zkServer.sh zkTxnLogToolkit.sh
zkCleanup.sh zkCli.sh zkEnv.sh zkServer-initialize.sh zkTxnLogToolkit.cmd
# 启动本地客户端的命令
[root@node1-zookeep bin]# zkCli.sh
/usr/bin/java
Connecting to localhost:2181
2023-09-21 08:12:06,571 [myid:] - INFO [main:Environment@109] - Client environment:zookeeper.version=3.5.7-f0fdd52973d373ffd9c86b81d99842dc2c7f660e, built
...
启动远程客户端(其他节点)
# 这里我们以启动节点2做演示
[root@node1-zookeep bin]# zkCli.sh -server node2_zookeeper:2181
/usr/bin/java
Connecting to node2_zookeeper:2181
2023-09-21 08:18:06,417 [myid:] - INFO [main:Environment@109] - Client environment:zookeeper.version=3.5.7-f0fdd52973d373ffd9c86b81d99842dc2c7f660e, built on 02/10/2020 11:30 GMT
...
2.节点类型
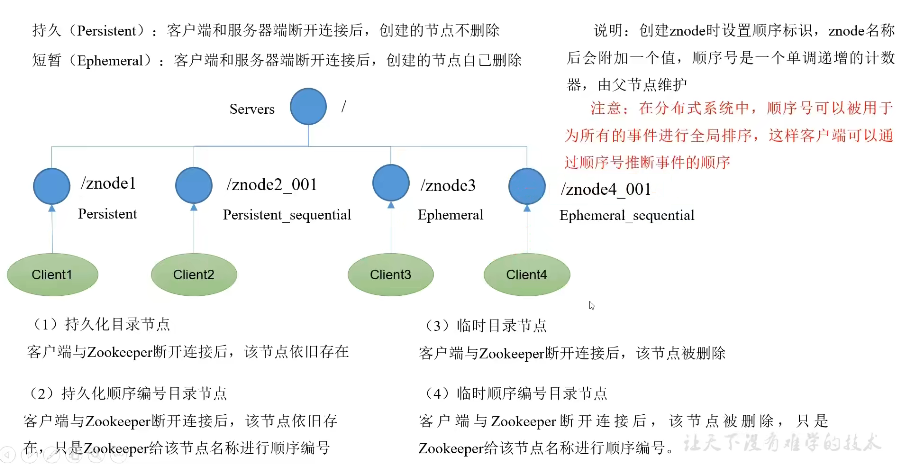
创建持久节点:
- 如果是正常创建持久节点,使用create 节点名称 内容 即可,如: create /test01 "this is test node"
- 如果是创建携带编号的持久节点,则添加[ -s ]参数即可: create -s /test01 "this is test node"
# 创建一个节点名为test01,内容是this is test node
[zk: node2-zookeeper:2181(CONNECTED) 5] create /test01 "this is test node"
Created /test01
# 使用ls 查看所有节点
[zk: node2-zookeeper:2181(CONNECTED) 6] ls /
[test01, zookeeper]
# 也可以创建有多个层级的节点
# 如:在test01中再次创建一个demo01节点,内容是this is second level
[zk: node2-zookeeper:2181(CONNECTED) 7] create /test01/demo01 "this is second level"
Created /test01/demo01
# 查看所有节点
[zk: node2-zookeeper:2181(CONNECTED) 8] ls /
[test01, zookeeper]
# 查看test01中demo01
[zk: node2-zookeeper:2181(CONNECTED) 9] ls /test01
[demo01]
# 获取到test01中的信息
[zk: node2-zookeeper:2181(CONNECTED) 10] get -s /test01
this is test node
cZxid = 0xa00000006 #创建节点时的事务ID
ctime = Thu Sep 21 09:46:24 CST 2023 #创建时间
mZxid = 0xa00000006 #最后一次创建的事务ID
mtime = Thu Sep 21 09:46:24 CST 2023 #后一次事务的时间
pZxid = 0xa00000007 #子节点的事务ID
cversion = 1 #版本号
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0 #零时节点
dataLength = 17 # 数据长度
numChildren = 1 #对应的子节点个数:一个demo01子节点
创建零时节点:
# 创建零时节点,需要携带参数[-e]
[zk: node2-zookeeper:2181(CONNECTED) 12] create -e /test03 "...点"
Created /test03
# 创建携带编号的零时节点,需要携带参数[-e]和[-s]
[zk: node2-zookeeper:2181(CONNECTED) 13] create -e -s /test02 "临时节点"
Created /test020000000002
#查看创建的节点
[zk: node2-zookeeper:2181(CONNECTED) 15] ls /
[test01, test03, test020000000002, zookeeper]
#获取带参数的零时节点和不带参数的零时节点的内容
[zk: node2-zookeeper:2181(CONNECTED) 18] get /test020000000002
临时节点
[zk: node2-zookeeper:2181(CONNECTED) 19] get /test03
临时节点
# 或添加[-s]参数查看不带参数的零时节点的完整信息
[zk: node2-zookeeper:2181(CONNECTED) 20] get -s /test03
临时节点
cZxid = 0xa00000008
ctime = Thu Sep 21 10:06:00 CST 2023
mZxid = 0xa00000008
mtime = Thu Sep 21 10:06:00 CST 2023
pZxid = 0xa00000008
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x20003eee5910000
dataLength = 12
numChildren = 0
# 退出客户端
[zk: node2-zookeeper:2181(CONNECTED) 21] quit
WATCHER::
WatchedEvent state:Closed type:None path:null
2023-09-21 10:15:57,436 [myid:] - INFO [main...
# 再次连接
[root@node1-zookeeper bin]# zkCli.sh -server node2-zookeeper:2181
/usr/bin/java
Connecting to node2-zookeeper:2181
2023-09-21 10:16:06,267 [myid:] - INFO [main:Environment@109] - Client environment:zookeeper.version=3.5.7-f0fdd52973d373ffd9c86b81d99842dc2c7f660e, built on 02/10/2020 11:30 GMT
2023-09-21 10:16:06,268 [myid:] - INFO [main:Environment@109] - Client environment:host.name=node1-zookeeper
2023-09-21 10:16:06,269 [myid:] - INFO...
# 查看节点
[zk: node2-zookeeper:2181(CONNECTED) 0] ls /
[test01, zookeeper]
# 发现创建的test03和test020000000002零时节点不在了
- 一旦zookeeper客户端断开再次连接,零时节点就不存在了
修改节点的值
# 查看所有节点
[zk: node2-zookeeper:2181(CONNECTED) 0] ls /
[test01, zookeeper]
# 获取test01的值
[zk: node2-zookeeper:2181(CONNECTED) 1] get /test01
this is test node
# 修改test01节点的值为 "这是一个节点",有时候输入中文是显示为“...”
[zk: node2-zookeeper:2181(CONNECTED) 2] set /test01 "这是一个节点"
# 再次获取
[zk: node2-zookeeper:2181(CONNECTED) 3] get /test01
这是一个节点
3.监听器
- 首先有一个main()线程,在main线程中创建zookeeper客户端,这时就会创建两个线程,一个负责网络连接通信(connnet),一个负责监听(listener)。
- 通过connect线程将注册的监听事件发送给zookeeper。
- 在zookeeper的注册监听器列表中奖注册的监听事件添加到列表中。
- zookeeper监听到有数据或路径变化,就会将这个消息发送给listener
- listener线程内部调用了process()方法。
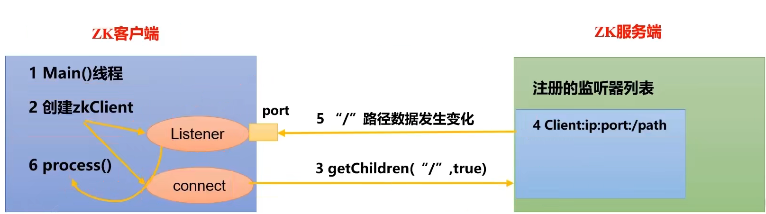
注意:每次设置监听时,无论是监听数据还是监听节点变化,注册一次监听只会有一次生效,如果需要再次监听,需要再次注册
① 监听数据的变化
#在node3_zookeeper中创建var_watch节点
[zk: localhost:2181(CONNECTED) 0] create /var_watch "...听"
Created /var_watch
#查看创建好的var_watch节点
[zk: localhost:2181(CONNECTED) 1] get -s /var_watch
测试监听
# 查看所有节点
[zk: localhost:2181(CONNECTED) 3] ls /
[test01, var_watch, zookeeper]
# 使用get -w [被监听的节点] 命令进行监听
[zk: localhost:2181(CONNECTED) 4] get -w /var_watch
测试监听
...
#在node2_zookeeper中修改该var_watch的值
[zk: localhost:2181(CONNECTED) 0] set /var_watch "............了"
#此时在node3_zookeeper中有消息提示:
[zk: localhost:2181(CONNECTED) 5]
WATCHER::
WatchedEvent state:SyncConnected type:NodeDataChanged path:/var_watch
②监听节点数量增减的变化
# 在node3_zookeeper中:
# 因为我们在上面刚创建了var_watch节点,里面只有一条数据,并没有子节点
# 所以我们直接使用 ls -w [被监听的节点] 命令来监听节点的变化
[zk: localhost:2181(CONNECTED) 5] ls -w /var_watch
# 我们在node2_zookeeper中给var_watch新增一个子节点,
[zk: localhost:2181(CONNECTED) 1] create /var_watch/watch01
Created /var_watch/watch01
#此时在node3_zookeeper中有消息提示:
[zk: localhost:2181(CONNECTED) 6]
WATCHER::
WatchedEvent state:SyncConnected type:NodeChildrenChanged path:/var_watch
③节点删除与查看
# 查看当前所有节点
[zk: localhost:2181(CONNECTED) 3] ls /
[test01, var_watch, zookeeper]
# 节点一中存在一个子节点
[zk: localhost:2181(CONNECTED) 4] ls /test01
[demo01]
# 直接删除,会提示该节点不是空的,需要先将子节点删除
[zk: localhost:2181(CONNECTED) 5] delete /test01
Node not empty: /test01
# 删除test01的子节点
[zk: localhost:2181(CONNECTED) 6] delete /test01/demo01
# 删除后
[zk: localhost:2181(CONNECTED) 7] ls /test01
[]
④递归删除:删除当前节点及所有子节点
# 查看var_watch节点,也存在一个子节点
[zk: localhost:2181(CONNECTED) 10] ls /var_watch
[watch01]
# 使用deleteall [path] 删除该节点和其子节点
[zk: localhost:2181(CONNECTED) 11] deleteall /var_watch
[zk: localhost:2181(CONNECTED) 12] ls /
[zookeeper]
zookeeper客户端API(Java)
1.创建一个java的Maven工程,在POM文件中添加与自己的zookeeper版本一致的依赖
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.5.7</version>
</dependency>
2.使用
/**
* 客户端API测试
*/
public class zkClient {
/**
* 1.如果配置了主机映射名则使用映射名,如果没有就使用IP地址
* 2.如果是单点,则直接写对应的映射名或IP和端口号,如果是集群,
* 那么把对应集群中需要连接节点的映射名或IP、端口写上,注意不能有任何空格
*
*/
private String connectString = "node1-zookeeper:2181,node1-zookeeper:2181,node1-zookeeper:2181";
/**
* 连接超时时间
*
*/
private int sessionTimeOut = 40000;
private ZooKeeper zooKeeper;
@Before
public void init() throws IOException {
zooKeeper = new ZooKeeper(connectString, sessionTimeOut, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
}
});
}
@Test
public void test01() throws InterruptedException, KeeperException {
zooKeeper.create("/java_Client_test",//创建的路径
"使用Java操作的".getBytes(),//数据
ZooDefs.Ids.OPEN_ACL_UNSAFE,//完全开放的ACL
CreateMode.PERSISTENT//不带编号的持久节点
);
}
}
3.可能出现
org.apache.zookeeper.KeeperException$ConnectionLossException: KeeperErrorCode = ConnectionLoss for /java_Client_test
原因及解决方式:
- connectString错误,IP或者IP映射名、端口错误
- sessionTimeOut的超时时间太短,可以适当延长
- zookeeper服务没有启动,这是最low的错误
- centOS防火墙没关闭(或者是没有开放端口)
- 没有配置Windows的hosts文件,默认位置在 C:\Windows\System32\drivers\etc,找到hosts文件,在里面添加(根据自己的IP和映射名):
# VMware_CentOS7_zookeeper192.168.188.135 node1-zookeeper192.168.188.136 node2-zookeeper192.168.188.137 node3-zookeeper
案例:服务器动态上下线
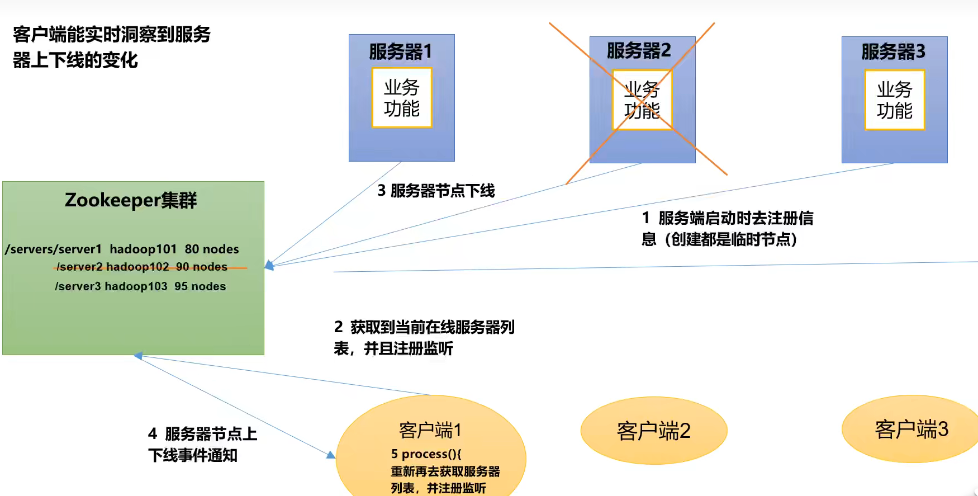
①:客户端
package com.moyuwanjia.study_zookeeper.demo01.case1;
import com.sun.org.apache.xpath.internal.SourceTree;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
/**
* 服务器动态上下线注册:client
*/
public class DistributeClient {
private String connectString = "node1-zookeeper:2181,node1-zookeeper:2181,node1-zookeeper:2181";
private Integer sessionTimeOut = 4000;
private ZooKeeper zooKeeper;
public static void main(String[] args) throws IOException, InterruptedException, KeeperException {
DistributeClient distributeClient = new DistributeClient();
// 1.建立连接
distributeClient.Build();
// 2.获取存在的服务节点名称
distributeClient.getServers();
// 3.模拟程序服务一直在运行
distributeClient.bussiness();
}
private void bussiness() throws InterruptedException {
Thread.sleep(Long.MAX_VALUE);
}
private void Build() throws IOException {
zooKeeper = new ZooKeeper(connectString, sessionTimeOut, event -> {
try {
getServers();
} catch (InterruptedException e) {
throw new RuntimeException(e);
} catch (KeeperException e) {
throw new RuntimeException(e);
}
});
}
public void getServers() throws InterruptedException, KeeperException {
List<String> children = zooKeeper.getChildren("/servers", true);
ArrayList<String> servers = new ArrayList<>();
for (String child : children) {
byte[] data = zooKeeper.getData("/servers/" + child, false, null);
servers.add(new String(data));
}
System.out.println(servers);
}
}
② 服务端
package com.moyuwanjia.study_zookeeper.demo01.case1;
import org.apache.zookeeper.*;
import java.io.IOException;
/**
* 服务器动态上下线注册:server
*
*/
public class DistributeServer {
private String connectString = "node1-zookeeper:2181,node1-zookeeper:2181,node1-zookeeper:2181";
private Integer sessionTimeOut = 4000;
private ZooKeeper zooKeeper;
public static void main(String[] args) throws IOException, InterruptedException, KeeperException {
DistributeServer distributeServer = new DistributeServer();
// 1.获取连接
distributeServer.Build();
// 2.创建服务名
distributeServer.createNodeServer(args[0]);
// 模拟程序服务一直在运行
distributeServer.bussiness();
}
private void bussiness() throws InterruptedException {
Thread.sleep(Long.MAX_VALUE);
}
private void Build() throws IOException {
zooKeeper = new ZooKeeper(connectString, sessionTimeOut, new Watcher() {
@Override
public void process(WatchedEvent event) {
}
});
}
/**
* 创建一个携带编号的临时节点
* @param serverName
* @throws InterruptedException
* @throws KeeperException
*/
private void createNodeServer(String serverName) throws InterruptedException, KeeperException {
String s = zooKeeper.create("/servers/" + serverName, serverName.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
System.out.println(serverName + "is online");
}
}
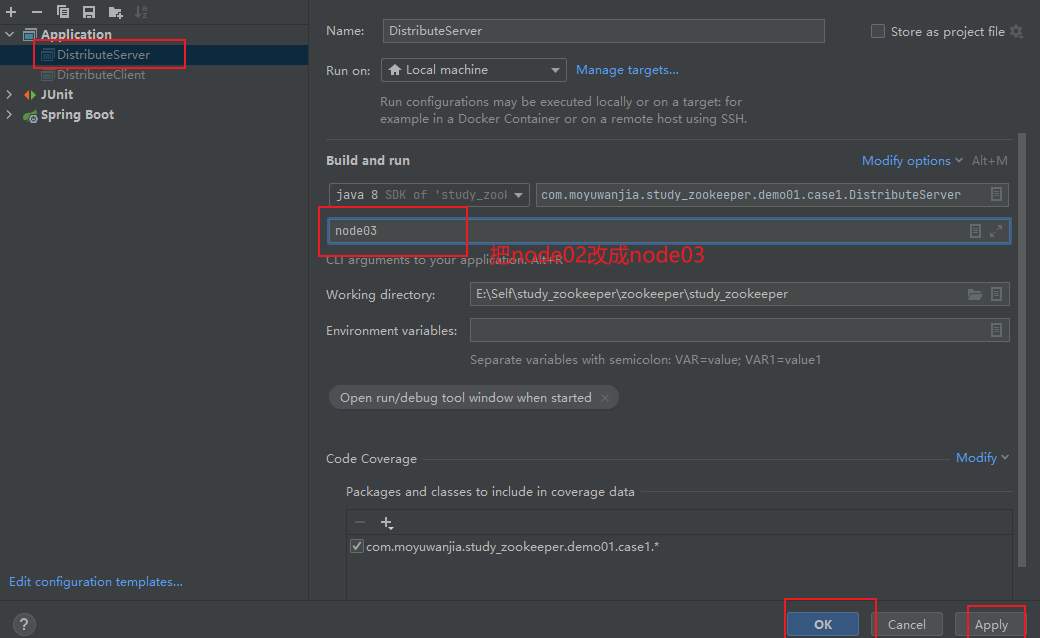
④ 启动客户端,再启动服务端,在启动服务端的时候,我们需要传递一个参数模拟服务节点名称:点击编辑配置 -> 选择运行服务端的主程序->填入参数(Program arguments)-> 点击Apply -> ok
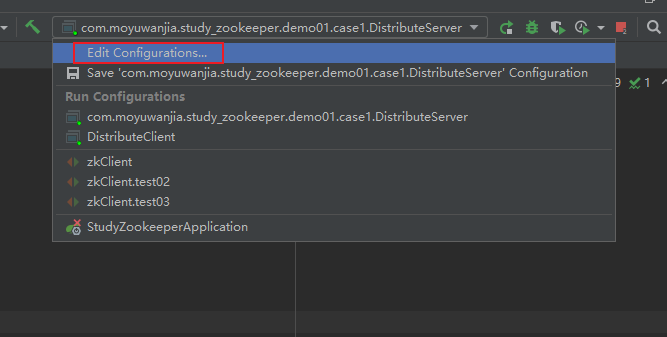
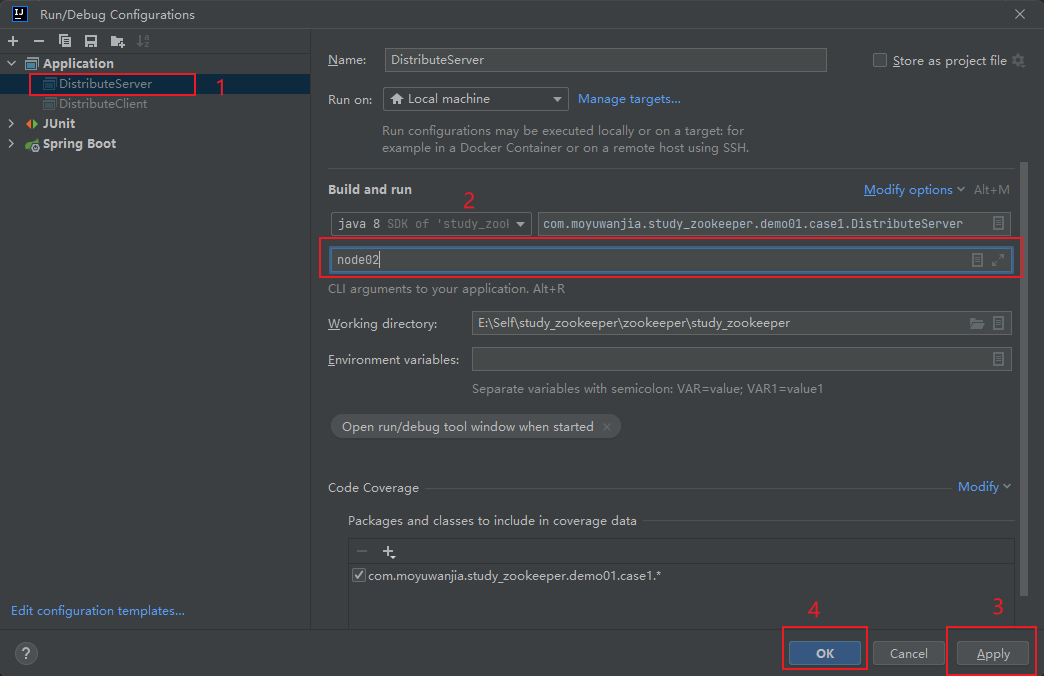
⑤演示结果:
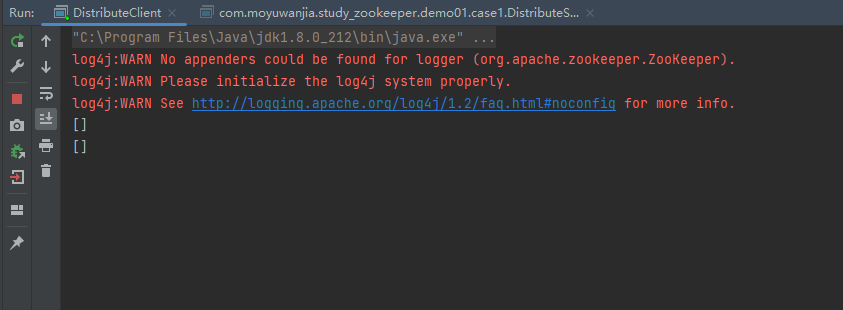
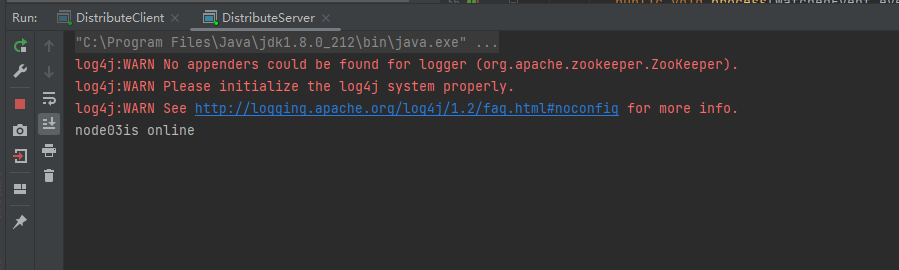
1.客户端启动
2.服务端node02启动
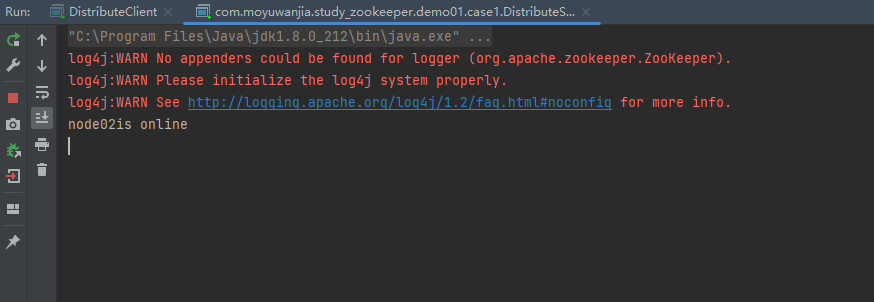
此时的客户端就监听到node02已经上线
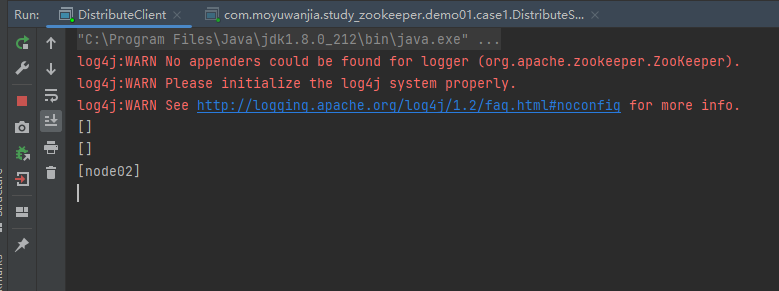
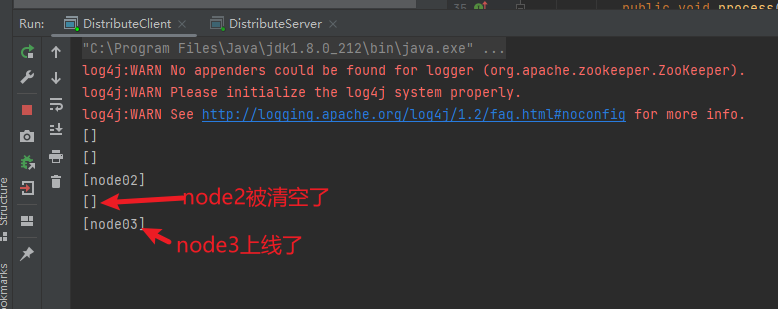
3.把服务端传递的参数node2改为node3,然后再重启服务端
服务端:
此时的客户端已经监听到node2已下线,node3已上线
案例:zookeeper分布式锁
package com.moyuwanjia.study_zookeeper.demo01.case2;
import org.apache.zookeeper.*;
import org.apache.zookeeper.data.Stat;
import java.io.IOException;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.CountDownLatch;
/**
* 测试案列: zk分布式锁
*/
public class DistributedLock {
private String connectString = "node1-zookeeper:2181,node1-zookeeper:2181,node1-zookeeper:2181";
private Integer sessionTimeOut = 4000;
private ZooKeeper zooKeeper;
private CountDownLatch connectLatch = new CountDownLatch(1);
private CountDownLatch waitLatch = new CountDownLatch(1);
// 记录前一个节点的路径
private String waitPath;
// 记录当前节点
private String currentMod;
public DistributedLock() throws IOException, InterruptedException, KeeperException {
// 获取连接
zooKeeper = new ZooKeeper(connectString, sessionTimeOut, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
// connectLatch 如果连接上zookeeper就释放
if (watchedEvent.getState() == Event.KeeperState.SyncConnected) {
connectLatch.countDown();
}
// waitLatch 需要释放
if (Event.EventType.NodeDeleted == watchedEvent.getType() && watchedEvent.getPath().equals(waitPath)) {
waitLatch.countDown();
}
}
});
// 等待zk获取到连接,再往下执行(阻塞等待)
connectLatch.await();
// 判断根节点是否存咋,不存在则创建
Stat exists = zooKeeper.exists("/locks", false);
if (exists == null) {
// 创建根节点
zooKeeper.create("/locks", "locks".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
}
/**
* 添加锁的方法
*/
public void Lock() throws InterruptedException, KeeperException {
//创建带序号的零时节点
currentMod = zooKeeper.create("/locks/" + "seq-", null, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
// 判断创建的节点是否是最小的序号节点,如果是则获取到锁,如果不是,监听他的前一个序号比他小的节点
List<String> children = zooKeeper.getChildren("/locks", false);
//判断是否只存在一个节点
if (children.size() == 1) {
return;
} else {
//存在多个节点,先将其进行排序
Collections.sort(children);
//查找当前创建的节点的所在位置
String thisNodeName = currentMod.substring("/locks/".length());
//通过节点名获取节点位置
int index = children.indexOf(thisNodeName);
if (-1 == index) {
System.out.println("数据错误");
} else if (index == 0) {
// 如果当前创建的节点位置在第一个,则直接获取锁即可
return;
} else {
// 监听前一个节点
waitPath = "/locks/" + children.get(index - 1);
zooKeeper.getData(waitPath, true, null);
// 等待监听
waitLatch.await();
return;
}
}
}
/**
* 释放锁的方法
*/
public void unLock() throws InterruptedException, KeeperException {
zooKeeper.delete(currentMod, -1);
System.out.println("释放锁");
}
}
/**
* 测试锁:
* 同时有三个线程获取锁,看看是否能同时获取到?
* 通过结果我们看到,三个线程同时获取锁,一旦被某个线程获取到锁,就会被抢占,其他线程无法获取,只有等待其他线程将其释放掉,才能再次被获取!!
*
*/
class DistributedLockTest {
public static void main(String[] args) throws IOException, InterruptedException, KeeperException {
final DistributedLock lock1 = new DistributedLock();
final DistributedLock lock2 = new DistributedLock();
final DistributedLock lock3 = new DistributedLock();
new Thread(() -> {
try {
lock1.Lock();
System.out.println("线程1启动,获取到锁");
// 等待之后释放锁
Thread.sleep(5* 1000);
lock1.unLock();
} catch (InterruptedException | KeeperException e) {
throw new RuntimeException(e);
}
}).start();
new Thread(() -> {
try {
lock2.Lock();
System.out.println("线程2启动,获取到锁");
// 等待之后释放锁
Thread.sleep(5* 1000);
lock2.unLock();
} catch (InterruptedException | KeeperException e) {
throw new RuntimeException(e);
}
}).start();
new Thread(() -> {
try {
lock3.Lock();
System.out.println("线程3启动,获取到锁");
// 等待之后释放锁
Thread.sleep(5*1000);
lock3.unLock();
} catch (InterruptedException | KeeperException e) {
throw new RuntimeException(e);
}
}).start();
}
}
Curator 框架实现分布式锁
使用原生的java API 开发存在的问题
- 会话连接时异步的,需要自己去处理。比如使用CountDownLatch
- Watch 需要重复的注册,不然不会生效
- 开发的复杂性比较高
- 不支持多借点的删除和创建。需要自己递归等等
Curator是一个专门解决分布式锁的框架,解决了原生Java API开发分布式遇到的问题。
- 使用
<dependency> <groupId>org.apache.curator</groupId> <artifactId>curator-framework</artifactId> <version>4.3.0</version></dependency> <dependency> <groupId>org.apache.curator</groupId> <artifactId>curator-recipes</artifactId> <version>4.3.0</version></dependency><dependency> <groupId>org.apache.curator</groupId> <artifactId>curator-client</artifactId> <version>4.3.0</version></dependency>
演示
package com.moyuwanjia.study_zookeeper.demo01.case3;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.recipes.locks.InterProcessMutex;
import org.apache.curator.retry.ExponentialBackoffRetry;
/**
* 使用Curator 实现分布式锁
*/
public class CuratorLockTest {
public static void main(String[] args) {
// 创建分布式锁1
InterProcessMutex locks1 = new InterProcessMutex(getCuratorFramework(), "/locks");
InterProcessMutex locks2 = new InterProcessMutex(getCuratorFramework(), "/locks");
InterProcessMutex locks3 = new InterProcessMutex(getCuratorFramework(), "/locks");
new Thread(() ->{
try {
locks1.acquire();
System.out.println(Thread.currentThread() + "获取到锁");
locks1.acquire();
System.out.println(Thread.currentThread() + "再次获取到锁");
Thread.sleep(5*1000);
// 可重入锁
locks1.release();
System.out.println(Thread.currentThread() + "释放锁");
locks1.release();
System.out.println(Thread.currentThread() + "再次获释放锁");
} catch (Exception e) {
throw new RuntimeException(e);
}
}).start();
new Thread(() ->{
try {
locks2.acquire();
System.out.println(Thread.currentThread() + "获取到锁");
locks2.acquire();
System.out.println(Thread.currentThread() + "再次获取到锁");
Thread.sleep(5*1000);
locks2.release();
System.out.println(Thread.currentThread() + "释放锁");
locks2.release();
System.out.println(Thread.currentThread() + "再次获释放锁");
} catch (Exception e) {
throw new RuntimeException(e);
}
}).start();
new Thread(() ->{
try {
locks3.acquire();
System.out.println(Thread.currentThread() + "获取到锁");
locks3.acquire();
System.out.println(Thread.currentThread() + "再次获取到锁");
Thread.sleep(5*1000);
locks3.release();
System.out.println(Thread.currentThread() + "释放锁");
locks3.release();
System.out.println(Thread.currentThread() + "再次获释放锁");
} catch (Exception e) {
throw new RuntimeException(e);
}
}).start();
}
public static CuratorFramework getCuratorFramework(){
// 重试策略(重试时长、重试次数)
ExponentialBackoffRetry exponentialBackoffRetry = new ExponentialBackoffRetry(3000, 3);
CuratorFramework client = CuratorFrameworkFactory.builder().connectString("node1-zookeeper:2181,node1-zookeeper:2181,node1-zookeeper:2181")
.connectionTimeoutMs(2000)
.sessionTimeoutMs(2000)
.retryPolicy(exponentialBackoffRetry).build();
client.start();
System.out.println("---------------------------zookeeper 启动成功-------------------------");
return client;
}
}
常见问题:


若有收获,就点个赞吧
版权归原作者 摸鱼丸加 所有, 如有侵权,请联系我们删除。