
一、为什么是MapReduce?
世间的计算无非就两种形式——Map & Reduce,而Reduce 又依赖 Map实现
Map: 以一条记录为单位做映射,只关心一条记录中的某个字段。它是一种映射,将数据映射为kv的形式,相同的key为一组。一条记录可以转化为另一条或另N条记录。
Reduce: 以一组数据为单位做计算。在Reduce方法内按要求迭代计算这一组数据。
MapReduce通过 kv联系在一起。
二、MapReduce流程介绍:
MapReduce流程图:
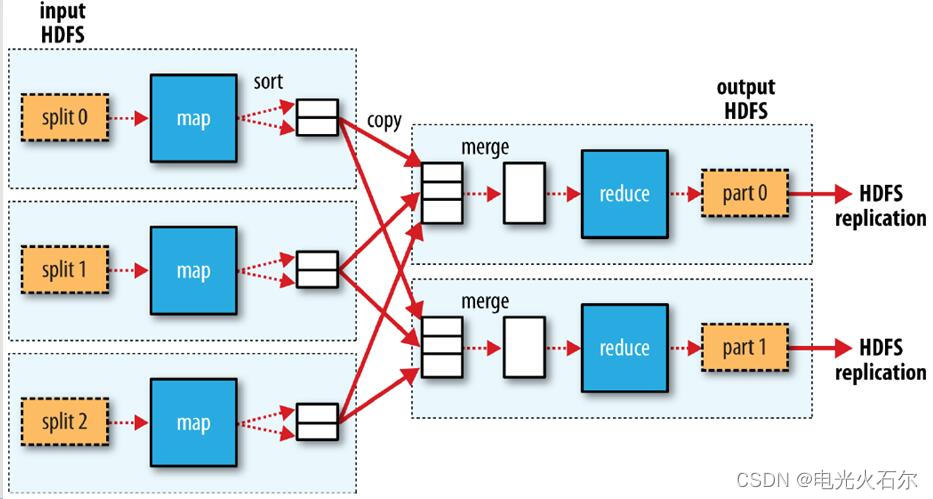
split()控制并行度(控制力度):一共500M数据,你要5个100M并行,还是100个5M并行。split()会格式化记录,处理后的记录交给map方法处理。一个split()对应一个map。
MR:数据以一条记录为单位经过map方法映射成kv,归并排序后,相同的key为一组。这一组数据调用一次Reduce()(Reduce()从每个map()方法中取出相同k的记录组成一组),在方法内迭代计算着一组数据。
三、MapReduce中的shuffle:
下面是一个map进程的详细展开图:
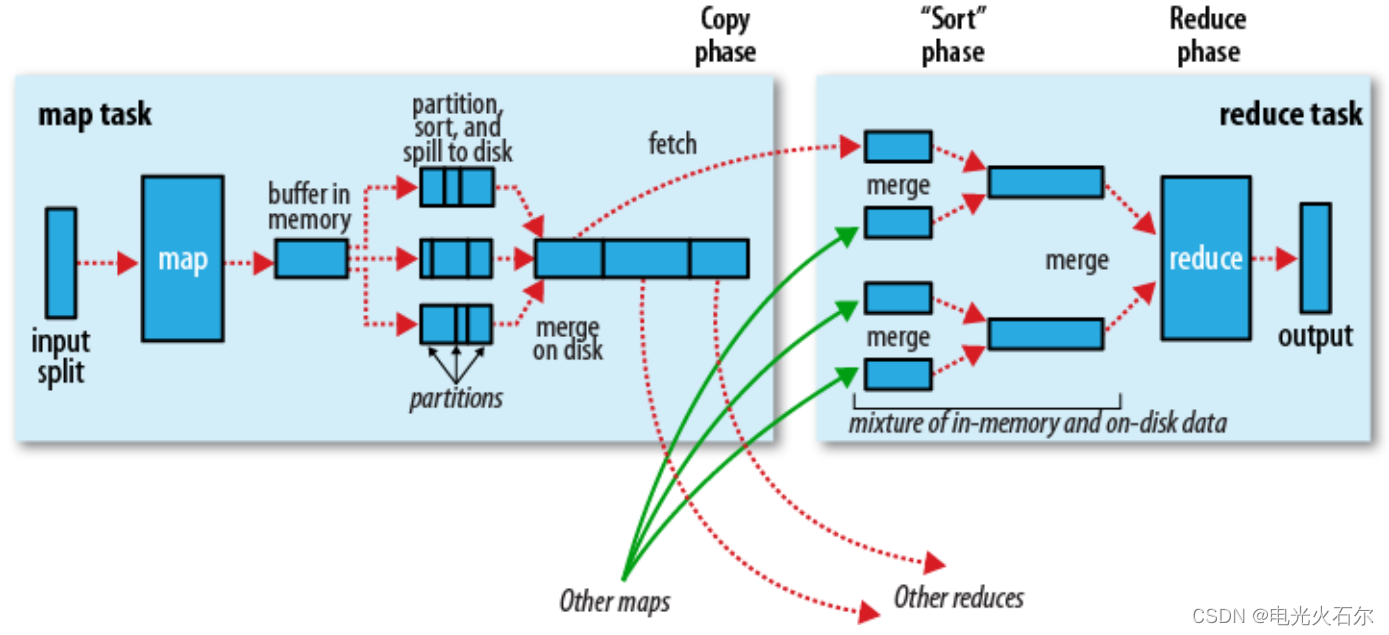
在上图中
引入分区(partition)概念,一个记录经过一个map()映射成kv,再通过k计算出p 得到一条记录(k, v ,p)相同分区p的记录保存在同一个文件中。一个reduce处理一个分区。
**buffer in memory: **
经过map()方法的记录会存储在本地磁盘中,而一条记录读取一次磁盘显然提高了I/O成本,消耗很多时间。因此这个缓冲区的存在就是让记录先存储在缓冲区中,缓冲区满后再溢写进磁盘。
partition, sort, and spill to disk:
内存缓冲区溢写磁盘时:做一个2次排序,先排分区p,再排相同k。
为什么排序分区p:假设分区p乱序,有n条记录,一个reduce读取一个分区。reduce进程需要从磁盘中读取n次(读取到不是自己分区的记录则换一个reduce读取)。而如果分区p有序,每个reduce可以一口气读取属于自己分区的那一整块记录,大大降低I/O成本。而k排序同样是为了降低I/O成本,这里不再赘述。
欢迎大佬批评指正~
版权归原作者 电光火石尔 所有, 如有侵权,请联系我们删除。