
一、前言
在之前的博客中,讲解了 **Linux的基本指令**:指令详解 ,但是呢,在我们常见的项目编译中肯定会**包含很多代码文件**,只会运用 **指令** 是不够滴,所以本次博客我们来介绍一下如何使用 **make/Makefile** 实现**项目的自动化构建**。
- 大部分老铁都应该知道如何在Linux上编译C语言代码,而且清楚了可执行文件**
a.out的由来,是从 -test.c经过预编译到test.i-test.i经过编译到test.s-test.s经过汇编到test.o-test.o经过链接到a.out** - 如果有老铁还不清楚的可看看这篇 编译+链接 的过程,是不是觉得很冗余复杂,我们平常做做练习还好,但若是到了那些大型工程中,可是具有上千、上万条代码,若是一次编译完成之后又修改了源代码,接着又想进行编译,此时便需要重新敲入指令,那会使得工作量变得很大。可是在VS中,我们可以无限地修改自己的代码,然后随时编译运行,不需要考虑这些复杂的原理
- 那Linux中有没有这样的一站式操作呢,那就是【make/Makefile】👈
** 二、make / Makefile背景介绍**
首先我们来介绍一下什么是make/Makefile,以及它们之间的关系
** 🥝Makefile是干什么的?**
Makefile 是一个**
文件**。它是一个工程文件的编译规则,它记录了原始码如何编译的详细信息、描述了整个工程的编译链接等规则。Makefile 带来的好处就是——“自动化编译"。一旦写好,只需要一个make命令,整个工程完全自动编译,极大的提高了软件开发的效率🚀
🎯先来看一下Makefile的【语法】:
target(目标文件):文件1 文件2(依赖文件列表) //依赖关系
<Tab>gcc -o 欲建立的执行文件 目标文件1 目标文件2 ///依赖方法
command
...
...
- target就是我们想要建立的信息,一般称作**
目标文件。而后面的依赖文件列表**就是具有相关性的 object files,也就是目标文件所依赖的文件(可以是一个或多个,也可以没有)
🎯然后看一下Makefile的【规则】:
- 目标文件与依赖文件列表文件之间要使用冒号隔开**
目标文件:依赖文件列表**- target可以是一个目标文件、执行文件,甚至可以是一个标签【后面会提到的伪目标】
- 依赖方法前面必须加Tab空格键
- 依赖方法以gcc为例,也可以是其他的shell指令【command】
💪会不会写Makefile ,从一个侧面说明了一个人是否具备完成大型工程的能力💪
** 🍇make又是什么?**
- make是一个**
命令工具,是一个解释makefile中指令**的命令工具,一般来说,大多数的IDE都有这个命令,比如:Delphi 的 make,Visual C++的nmake,Linux下GNU的make。可见,Makefile都成为了一种在工程方面的编译方法
【总结一下】:make 一条命令,makefile 是一个文件,两个搭配使用,完成**项目自动化构建👈 **
**三、demo实现【见见猪跑🐖】 **
了解可什么是make/Makefile之后,我们就来用一用它们
- 刚才说到make命令是用来解释 Makefile 中指令的,所以我们需要创建一个。我喜欢用大写的Makefile,当然你写成 makefile 也是可以的
- 这里直接**
vim Makefile**即可,进入编辑界面,如果有不懂vim的,可以看看我的文章---------- - Vim 的超详细使用

- 此时我们可以再创建一个**
test.c**,作为源文件,然后开始往里面写内容 - 现在我要通过gcc去编译这个test.c的文件,然后生成一个我自己命名的【mytest】这个可执行文件,此时我们只需要在Makefile写上这两行即可
mytest:test.c
gcc -o mytest test.c

- 然后回到命令行,我们来执行一下这个**
make指令,它就是自动在当前源文件的所在路径下搜寻Makefile,并解释里面命令。之后若是我们需要去编译任何文件,只需要在Makefile**里面做一个添加即可,怎么样,是不是很方便
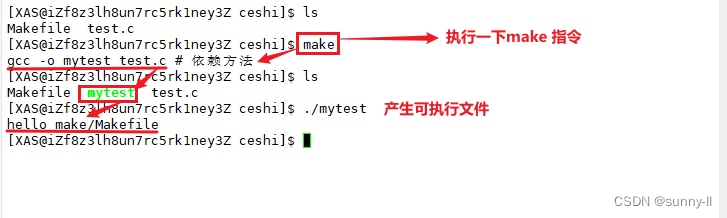
看到了 make / Makefile 的基本实现过程,我们再来说一下 它的原理吧!!!
** 四、依赖关系与依赖方法**
通过小小的demo,想必你已经感受到了【自动化构建工具】的强大,我们来仔细看看Makefile中的指令为何要如此书写✍
1、概念理清
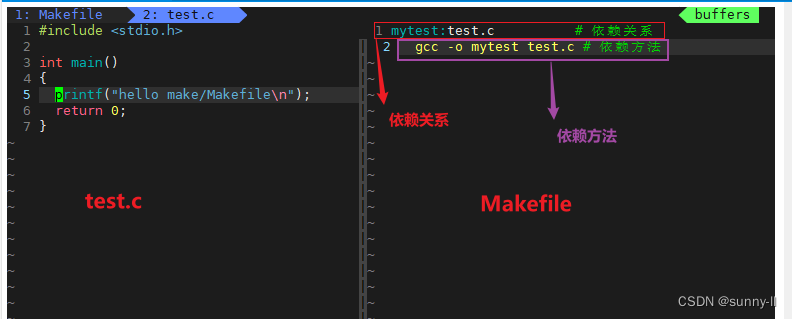
对于
mytest:test.c,冒号左侧是目标文件,右侧是它的依赖文件,所以就可以说它们之间存在一种【依赖关系】,只有test.c存在才可以有mytest那要如何通过test.c去生成mytest呢❓ 此时就需要使用到下面的这句gcc指令**
gcc -o mytest test.c** 👉它叫做【依赖方法】
** 2、感性理解【父与子👨】**
就这么说还是不太好理解,我们举个父与子的生活小案例来帮助理解
今天呢,是这个月的12号的了,家里面在月初给你的2000块钱差不多也花完了,于是这两天只能吃土,此时你打开微信后看到和老爸的聊天框,于是就想着和老爸要点钱【毕竟儿子向父亲要钱天经地义😀】
- 这里的老爸和儿子指的就是**
[依赖关系]** - 儿子向老爸要钱指的就是**
[依赖方法]**

下面辨析几种依赖关系与依赖方法
❌**错误的依赖方法 **
- 此时你打电话和你老爸说:“我是你儿子,你帮我写作业。”
- 以上这句话就是依赖关系正确,但是依赖方法不正确。老爸帮儿子写作业无法执行
所以只有依赖关系不行,还得有正确的依赖方法
❌错误的依赖关系
- 此时你拿起室友的手机和他爸爸打电话说:“我是你儿子,你给我点零花钱。”
- 以上这句话就是依赖方法正确,但是依赖关系不正确。因为别人的老爸没义务给你钱
依赖方法对了,但是依赖关系不对也不行
✔️ 正确的依赖关系与依赖方法
- 经历了种种挫折后,你重新拿起手机说:“老爸,我是你儿子,可以给我点零花钱吗?”
- 上面这种说法就是完全正确的依赖关系与依赖方法
完成一件事,必须得有正确的依赖关系 + 正确的依赖方法
**3、深层理解【程序的翻译环境 + 栈的原理】 **
看完了【依赖关系】与【依赖方法】的感性理解,相信你对它们有了一定程度的认识,接下去深入地来了解一下它们之间的关系
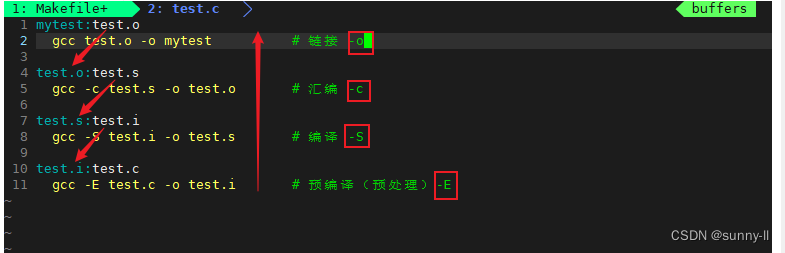
1 mytest:test.o
2 gcc test.o -o mytest
- 开头提到过源程序是如何经过一步步的编译来形成可执行文件的吗,因为可执行文件**
mytest是依赖于汇编后的目标文件test.o的,但是现在我们没有这个文件,因此就要去倒推一下如何获取这个test.o** - 对于**
test.o来说,它依赖于test.s**这个经过编译之后文件,可是【test.s】不存在,所以跳转到下一条依赖关系
3 test.o:test.s
4 gcc -c test.s -o test.o
- 对于**
test.s来说,它依赖于test.i**这个经过预编译之后的文件,可是【test.i】不存在,所以跳转到下一条依赖关系
5 test.s:test.i
6 gcc -S test.i -o test.s
- 对于**
test.i来说,它依赖于test.c**这个源文件,查找后发现源文件存在,于是开始执行gcc命令
7 test.i:test.c
8 gcc -E test.c -o test.i
以下就是我们需要在Makefile中修改的【依赖关系】与【依赖方法】
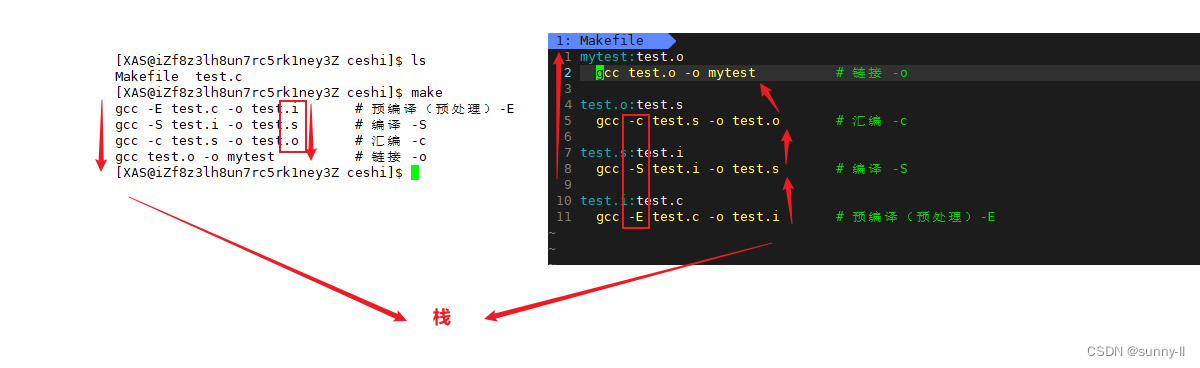
- 最后来到命令行中执行一下【make】命令,便完成了所有的编译,对于之前一步步地写这个编译的过程,真的是来得方便很多

- 因为只有当执行完了最后一条命令后生成了【test.i】的文件之后才可以一一往上继续执行,这种反着来的执行逻辑就相当于是我们在数据结构中学过的栈,有一个先进后出的逻辑
那这个Makefile这么牛,我们将 gcc编译 的顺序修改一下,会发生什么呢?
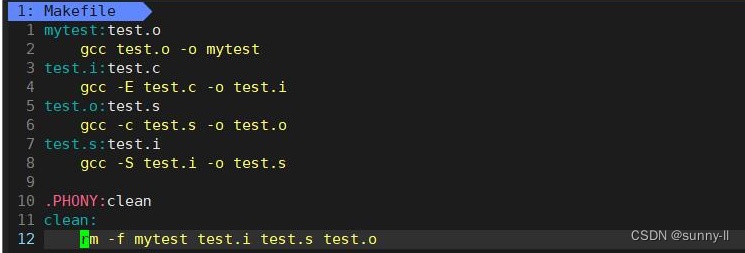
- 可是呢,当我再去**
make的时候,却发现这个执行的顺序还是按照没打乱之前的位置,这说明了一点:make会自动推导Makefile中的依赖关系形成栈式结构**
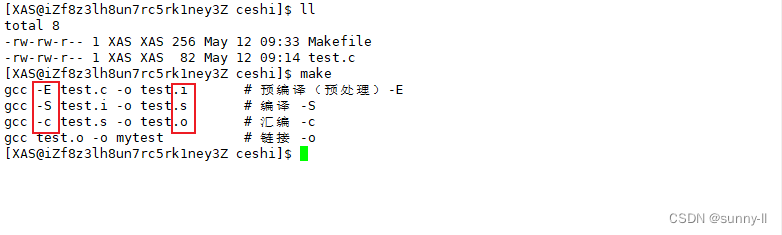
【总结一下】:在 [依赖关系] 中,若是目标文件所依赖的文件不存在,就将这个依赖方法入栈,转到下一组**[依赖关系],依次循环往复,直到当前目标文件所依赖的文件存在时,就进行出栈,开始执行依赖方法。最后获取的便是那个我们最初想要的目标文件,即使Makefile中的编译顺序发生了变化,make也会去做一个自动推导的工作**
** 五、多学一招:项目清理**
** 1、演示与原理讲解**
平时我们在进行各种操作之后目录中都会出现很多文件,此时当我们不想要这些文件的时候,就得去一一删除,显得尤为麻烦,如果编译可以使用**Makefile来自动化构建,那清理项目中的文件可不可以呢,我们来看看 **
- 此时我们在**
Makefile**中增加一个【清理】功能

- 来看一下是否可以达到清理的目的
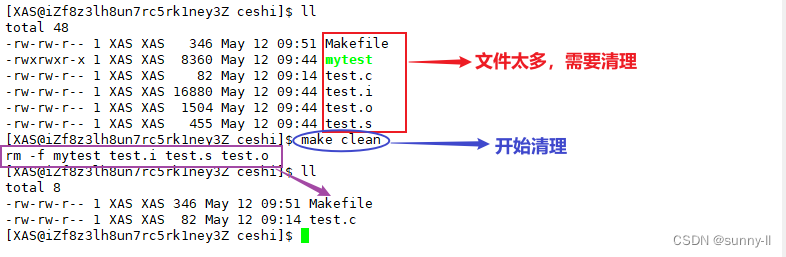
- 当我想使用清理功能的时候,并没有像自动化编译那样直接**
make,而是在make后面加上了一个clean**,这是为什么呢? - 新加上的**
.PHONY是什么?它对clean**而言意味着什么?
我们带着这些问题一起进入【伪目标】------ .PHONY 的学习📖
** 2、.PHONY伪目标的作用**
- .PHONY是一个伪目标,Makefile中将** .PHONY 放在一个目标前就是指明这个目标是伪文件目标。其作用就是防止在Makefile中定义的执行命令的目标和工作目录下的实际文件出现名字冲突**
- 也就是下面这句,此时的clean被**
.PHONY修饰了,那么它就可以反复执行它的依赖方法**
.PHONY:clean
- 可以看到对于目标文件**
clean来说,它的依赖文件列表为空**,上面我们也有提到过它可以为空
11 clean:
12 rm -f mytest test.i test.s test.o
所以只要你一直使用【make clean】,它便会反复地执行**
rm -f mytest test.i test.s test.o**.PHONY 配置项的目标clean并不是其他文件生成的实际文件,使make命令会自动绕过隐含规则搜索过程,也就是说执行命令**
make clean会自动忽略名为"clean"文件的存在,因此声明.PHONY配置项会改善性能,并且不需要担心实际同名文件存在与否**😮【通俗一点说】:**.PHONY修饰的目标clean并不是某个依赖项生成的实际文件**,因此make命令不再去搜寻当前文件夹下是否有clean文件,这样少去做一些事,自然会改善性能,并且不用担心当前文件夹下是否有同名的文件
我们到命令行中来验证一下⌨️

- 可以看到,我进行了三次make clean,不过其实在第一次执行的时候,就已经达成了我们清理的目的,可是后面还可以继续执行,这其实就是**.PHONY**修饰起的作用
- 其实对于【clean】来说,不加修饰其实也是可以辺反复执行的,这点我们在本模块开头的时候有说到过。我现在将这个修饰去掉,来试试看

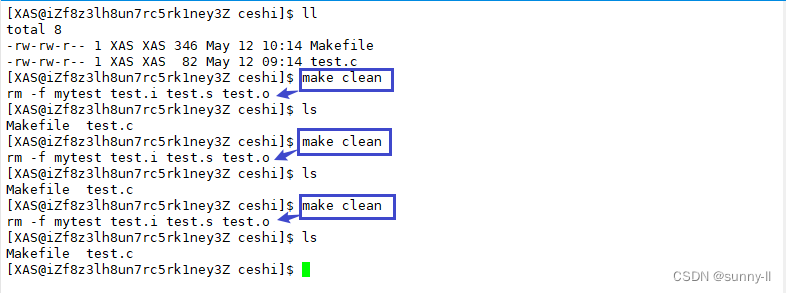
- 可以看到,即使是去掉了**
.PHONY**做修饰之后一样是可以反复执行
那就有同学问:这是为什么呢?**为何clean不加
.PHONY修饰也可以多次执行**
- 原因就在于它的依赖对象为空,当我们需要生成这个【clean】目标文件的时候就不需一些文件必须要存在,因此就可以一直**
[clean]**
** 3、.PHONY伪目标的原理 **
- 可是呢,对于其他的指令就不行了,例如我们上面说到过的gcc去编译一个文件的过程

- 我们试着在【mytest】前面加上一个**
.PHONY**的修饰试试

- 然后再去试试能不能进行反复使用【这里给读者详细解释一下**
.PHONY**修饰的原理】
我们来详细分析一下,首先可以清楚的是加上**
.PHONY修饰之后便可以多次make,但是可以看到在编译的过程中进行make的时候所执行的指令不太相同,只有
gcc test.o -o mytest**这一句,却少了如何产生【test.o】的过程,这是为何呢

- 因为在经过一次make之后,gcc对【test.c】进行了预编译、编译、汇编,最后生成了【test.o】,那它就已经在那里了,在此中间我们没有再对源文件进行再度修改,在编译的时候,其实会去查看目标对象和依赖对象的生成时间,若是依赖对象的生成时间要早于目标对象,说明它还没有被重新修改过,所以无需再度去重新编译生成(这一块在后面make的工作原理中细讲)
- 因此我们再去make的话gcc是不会重新编译的,可以当我去修改了一下【test.c】这个源文件之后,再度去make一下的话gcc又会对这个源文件进行一个重新的全过程编译。
**❗编译这一块比较复杂,需要重点理解❗ **
- 不过其实可以看出,每次去修改一下就重新编译全部的文件,也是挺繁琐的。所以我们在开发的时候一般不给编译生成的目标文件带**
.PHONY**的修饰,就防止其被多次重复编译
【总结一下】:
📚 **
.PHONY修饰的是伪目标,对于伪目标来说,它可以被反复执行**
📚 **
.PHONY修饰的一定能被反复执行,但是能被反复执行的不一定被
.PHONY修饰**
** 六、make的工作原理分析**
1、再谈make与Makefile
- 通过【ldd】去查看**
make指令的动态依赖关系**,我们可以发现 make指令 也是依赖于标准的C库,而我们在Makefile中写得也都是一些指令,因此使用make指令才可以对Makefile中的内容做一个识别

因此我们可以得出一个结论
👉**
make是专门给【Makefile】写的一个命令,在执行make的时候,就会自动在你当前目录下去搜索
Makefile**这个文件,搜索之后打开,然后对它里面的内容做分析
那 make 是如何进行分析** Makefile** 的呢,有什么规则吗❓
make扫描Makefile文件时会默认执行第一组依赖关系和依赖方法
还记得我们 - 在获取**
mytest这个目标对象的时候都是直接使用的【make】吗;- 而在获取clean**这个目标对象时却用的是【make clean】那你是否会感到疑惑为何不使用【make mytest】就可以获取到吗,就是因为默认执行的就是第一组的依赖关系和依赖方法
我们可以试着把【clean】和【mytest】调个位置

- 可以看到,在调换了位置之后我们直接【make】的话获取的就是clean对象了,想要去使用gcc编译源文件生成可执行文件就需要用到【make mytest】。
- 不过也并不是第一组依赖关系和依赖方法就一定要直接【make】,我们使用【make clean】也是可以用的
** 2、探究make的判断机制🔍**
好,我们来深入探讨一下刚才遗留下的问题:make究竟是如何知道我们的可执行文件是否需要重新编译呢❓
- 再来回顾一下,当我们执行完一次【make】获取**
mytest**这个目标文件后,第二次再去执行【make】指令就不会其效果了,这是为何呢?

- 我们可以将源文件和可执行文件当做是一条时间轴。对于**
可执行文件来收,它生成的时间一定是晚于源文件**的【因为中间要经过一系列编译 + 链接的过程】
- 我们可以通过【stat】这个指令来查看源文件和可执行文件的所有属性,不过要观察的还是其中一个叫做ACM时间 - Access: 最后一次访问该文件的时间- Change:最后一次改变该文件属性或状态的时间- Modify:最近一次修改文件内容的时间【比较的是这个时间】
- 可以很清晰地看出**10
:30:14是要早于11:20:57**的。所以【make】指令才会不起作用。所以它就是通过这个 Modify 时间来进行对比才能判断出是否需要重新编译

** 七、Makefile小知识📚**
本模块来拓展一下有关make/Mailefile里的一些小知识
Makefile文件保存了编译器和链接器的参数选项,并且描述了所有源文件之间的关系。make程序会读取makefile文件中的数据,然后根据规则调用编译器,汇编器,链接器产生最后的输出
Makefile里主要包含了五个东西:显式规则、隐晦规则、变量定义、文件指示和注释
- 【显式规则】:如何生成一个或多个目标文件;
- 【隐晦规则】:make有自动推导的功能,所以隐晦的规则可以让我们比较粗糙地简略地书写✍makefile,比如源文件与目标文件之间的时间关系判断之类;
- 【变量定义】:在makefile中可以定义变量,当makefile被执行时,其中的变量都会被扩展到相应的引用位置上,通常使用 $(var) 表示引用变量;
- 【文件指示】:包含在一个makefile中引用另一个makefile,类似C语言中的include;
- 默认的情况下,make命令会在当前目录下按顺序找寻文件名为**
、“GNUmakefile”
、“makefile”“Makefile”
**的文件
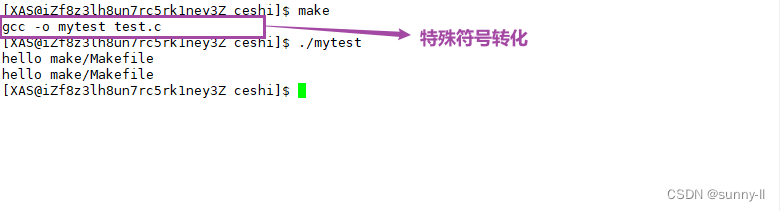
- 我们可以在Makefile中添加一些特殊符号,就可以起到一些特殊的功能
- 即这个**
$@和$^**,前者表示:左侧被编译的所有内容,即【目标文件】,后者表示:之后所有内容,即【依赖文件】

- 此时,当我们再去**
make的时候,就可以发现这个特殊符号自动替换成了:**两侧的【目标文件】和【依赖文件】
接下去我再来介绍一种 Makefile 中的特殊文件
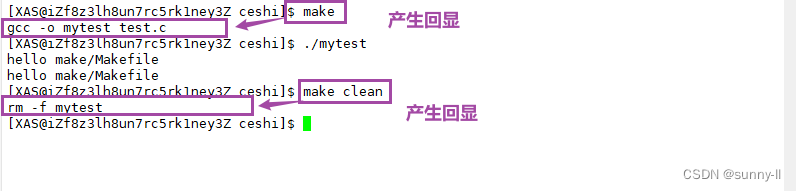
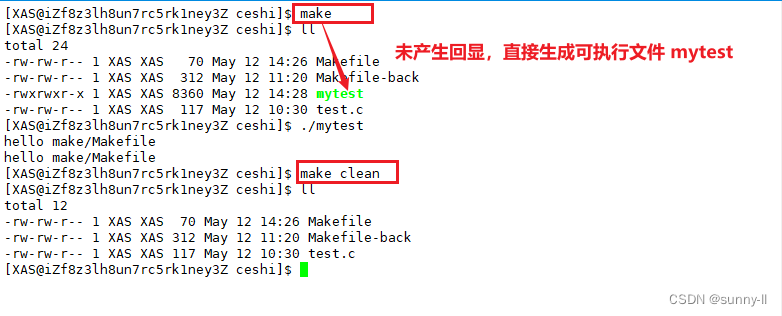
- 写了这么多【make】,你是否感觉每次都会出现回显很麻烦呢?能不能像我们在敲普通指令的时候一样,直接给出结果呢?
- 这里我们就可以在执行的命令行前加上这个**
@**
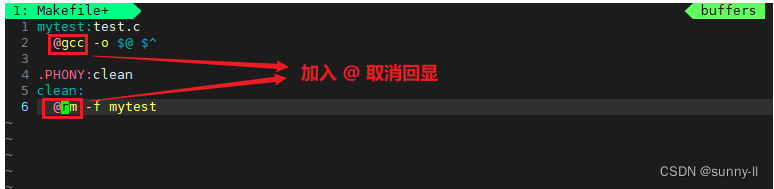
- 此时当我们在【make】和【make clean】的时候就不会产生任何回显了,可以达到一样的效果
** 八、总结与提炼**
最后我们来总结一下本文所学习的内容📖
本文我们学习了Linux下的项目自动化构建工具** -
make/Makefile
**
- 首先清楚了【Makefile】它是一个文件,我们可以在里面写入一些编译的规则。而【make】则是一个命令,它可以用来解析Makefile中的内容
- 接着,在通过初次写一个小案例去接触make/Makefile的时候我们了解到了【依赖关系】和【依赖方法】,不仅感性地去理解了它们,而且深入地清楚了它们的底层实现逻辑是基于数据结构中的栈
- 然后,不仅仅局限于一个目标文件,我们又学了一招,知道了如何去清理项目中的文件,知道了**.PHONY修饰的文件叫做【伪目标文件】**
- 最后,我们通过再度触及make/Makefile,真正搞清楚了它们之间的关系,也了解到make在判断一个文件是否需要重新编译的时候是基于比较源文件与目标文件的【Modify时间】
** 九、共勉**
**以下就是我对【Linux】makefile自动化编译 的理解,如果有不懂和发现问题的小伙伴,请在评论区说出来哦,同时我还会继续更新对 Linux--进程 的理解,请持续关注我哦!!!!! **

版权归原作者 sunny-ll 所有, 如有侵权,请联系我们删除。