
文章目录
朋友们好啊,我是秋刀鱼,一名爱写bug的Java专栏博主~
不小心时间就到了四月初,距离蓝桥杯省赛只剩下不到一周的时间,很多同学到现在一定会很焦虑不知道从何开始巩固与温习,“学了很多但感觉好像又没有学、做了很多题但仍旧不知道如何解题 ”逐渐成为了常态。
对此在本篇中我将罗列出比较重要的知识点,从如何使用Eclipse到经典算法题目的解析,与大家一起度过最后的冲刺环节,这也算是我对于这段时间学习知识的总结,希望能对你有所帮助。

⚔ Eclipse篇
正所谓“工欲善其事,必先利其器”,Eclipse作为蓝桥杯官方指定的IDE软件,学会使用其最基础的操作是必不可少的一环。废话不多说,现在就来看看如何使用Eclipse。
🗡 Eclipse创建文件
1、工具栏中左键文件图标:
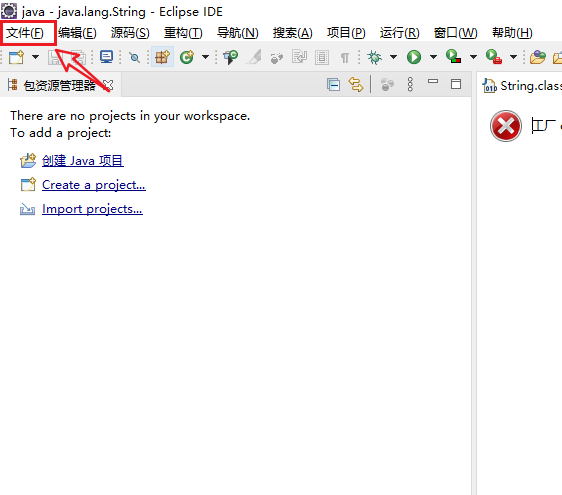
2、选择新建后选择新建一个Java项目:
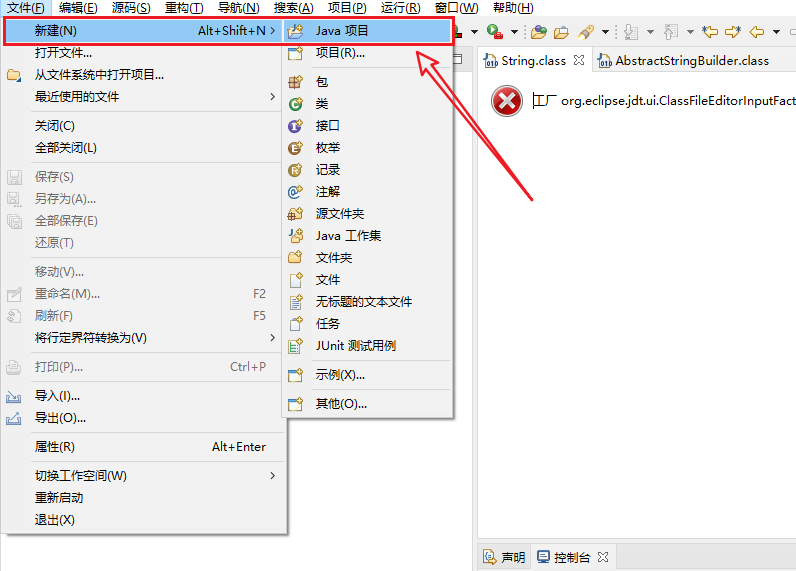
**3、自己起一个项目名,同时修改JRE环境为
JavaSE-1.8
,创建项目完成**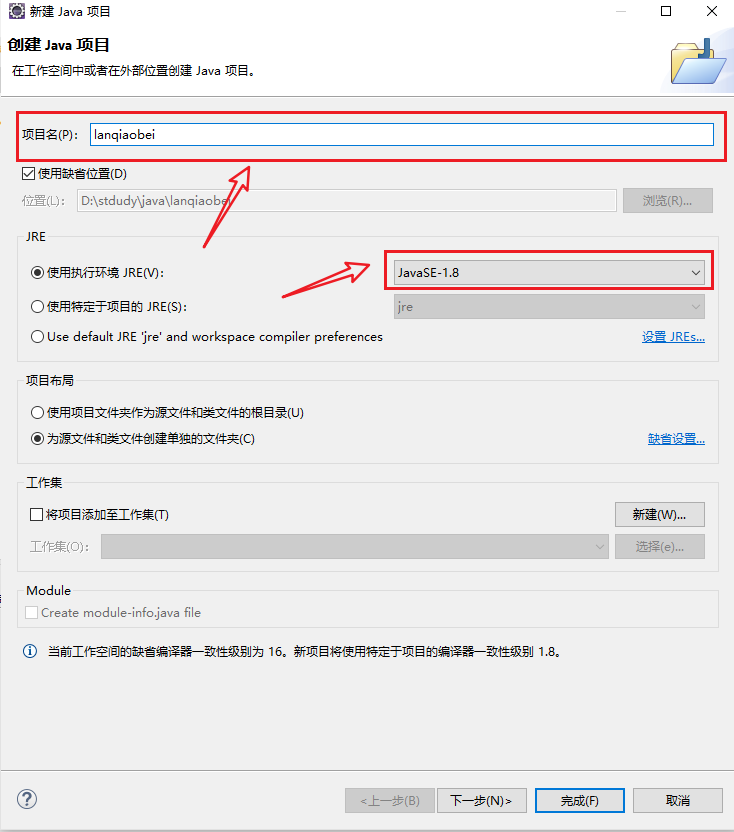
4、右击项目中的
src
文件,选择创建一个类文件
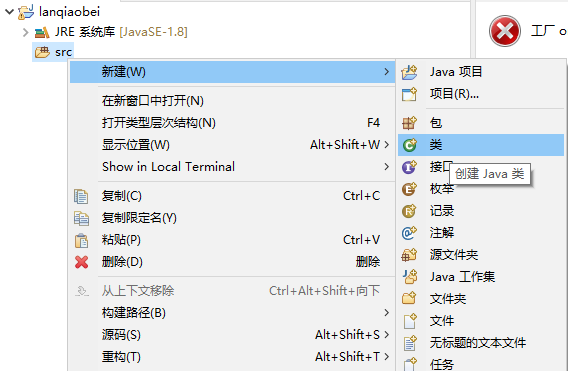
5、输入类文件信息,一定要注意:类文件名称必须是 Main且包名必须为空!不符合要求会导致比赛时提交代码无效!
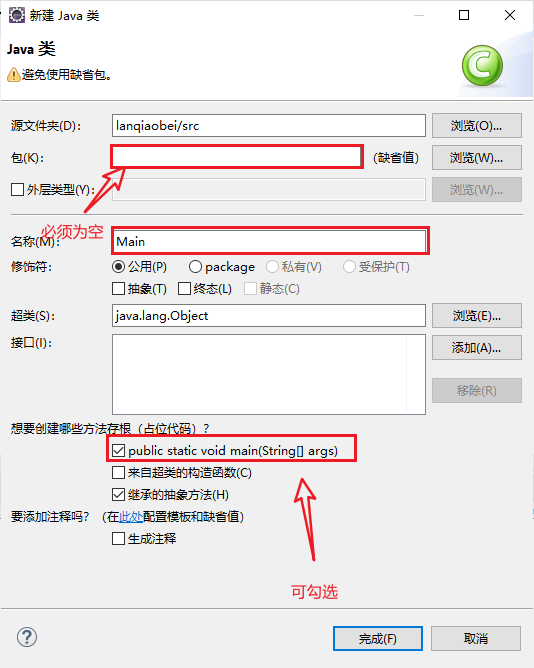
点击“完成”后文件创建完成!
🗡 Eclipse自动生成简单类
做题时可能会要求自己编写一个类,就例如BFS遍历需要存储遍历信息时。如果自己编写一个类需要实现
构造器
、实现
get
与
set
方法,如果需要调试还可能要实现
toString
方法,甚至有的情况下还需要实现
HashCode
与
equals
方法。
这些代码如果手工编写需要浪费大量宝贵的时间和精力。Eclipse为我们提供了快速生成简单类的方法。
首先创建一个类
Node
,给定类中的属性:
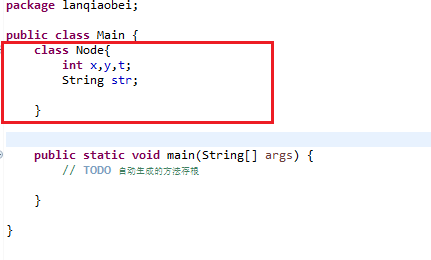
将鼠标在Node类范围内任意位置点击一次。这一步很重要,提示Eclipse在哪一个类中生成方法。
选中右上角的“源码”,可以看到如下的生成策略:
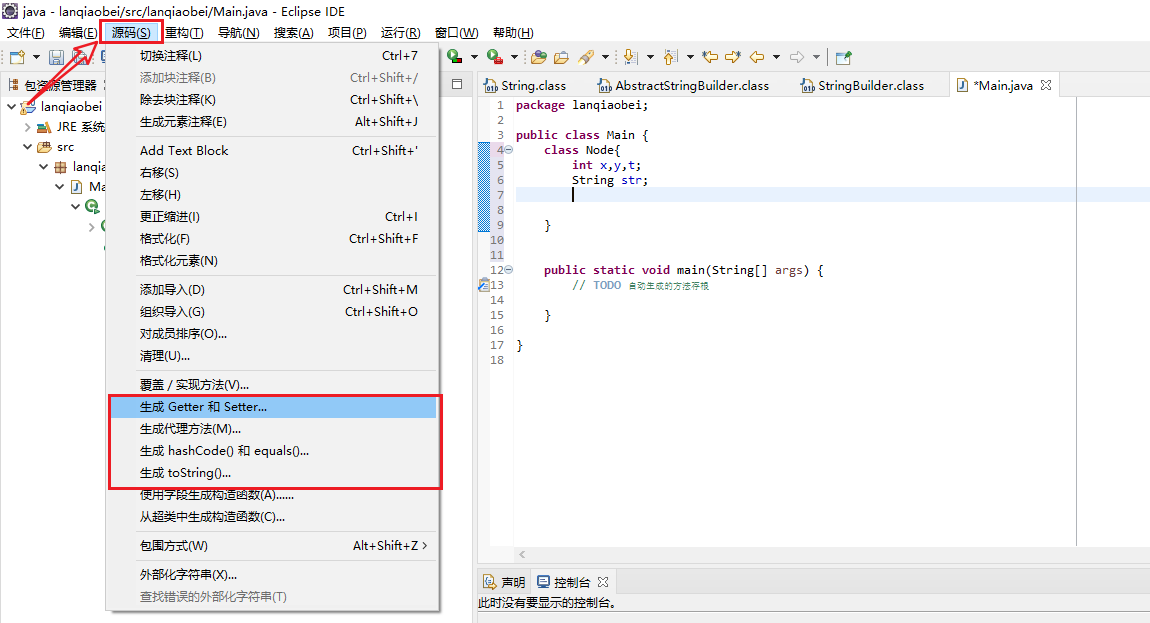
这里就用
toString
方法举例,其余方法均类似。点击“生成toString()”,可以看到Node类中的所有属性,修改属性是否被选中即表示该属性值是否会在
toString()
方法中显示。接着我们点击“生成”
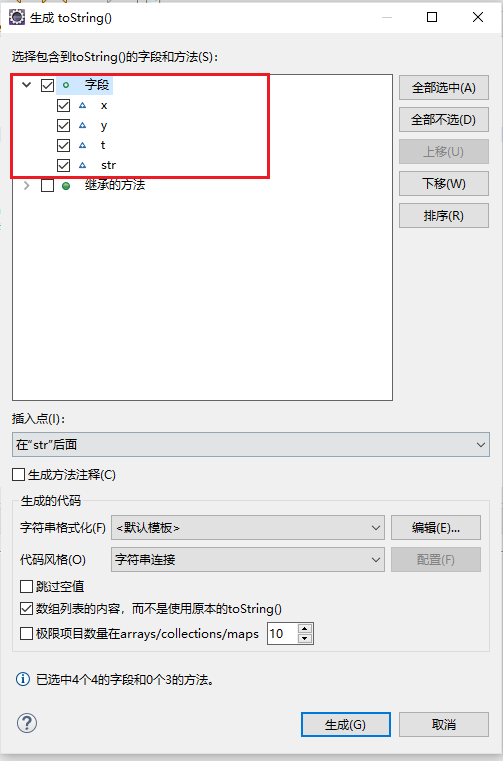
可以看到
toString()
方法生成成功!
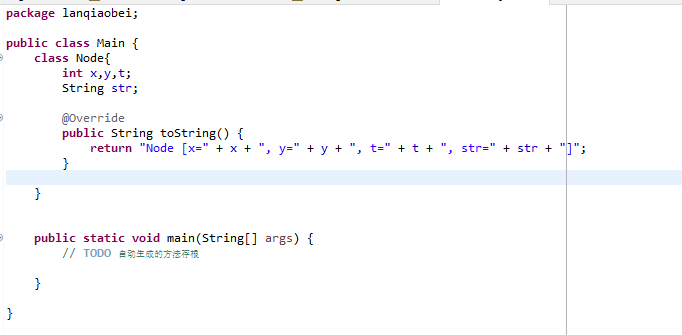
如果仅仅是为了得到一个默认的覆盖Object中的
toString
、
hashCode
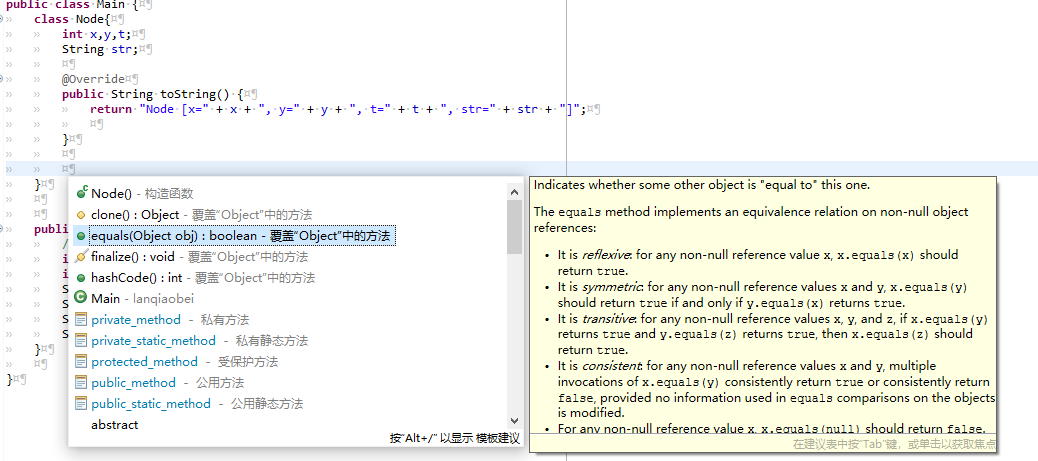
…方法,使用快捷键
alt+?
就能够实现:
🗡 Eclipse常用快捷键
ctrl 快捷键
ctrl+c\v\x:复制\粘贴\剪切ctrl+z:撤回ctrl+a:全选ctrl+f:呼出查找菜单,同时可根据需求替换文本。ctrl+1:修复代码,常用在编译前查错,类似于idea中的alt+Enter快速提示ctrl+/: 注释当前行ctrl+d:删除当前行ctrl+shift+Enter:在当前行上插入一行ctrl+Enter:当前行下插入一行ctlr+m:代码页面全屏显示ctrl+shift+f:美化代码格式(强迫症福音)
Alt快捷键
alt+/:单词补全alt+↑\↓:该行向上\下移动alt+←\→:光标移动到上一次\下一次编辑的页面位置Ctrl+Alt+↓:复制当前行到下一行(复制增加)Ctrl+Alt+↑:复制当前行到上一行(复制增加)alt+?:快速重写方法
其他快捷键
- 全局 单步返回
F7 - 全局 单步跳过
F6 - 全局 单步跳入
F5 - 全局 单步跳入选择
Ctrl+F5 - 全局 调试上次启动
F11 - 全局 继续
F8
🗡 Eclipse中Debug调试
算法编写时结果错误往往需要花费大量的时间调试,而使用Debug方式启动能够帮助我们快速找到代码中各个变量的属性值与语句的执行情况。
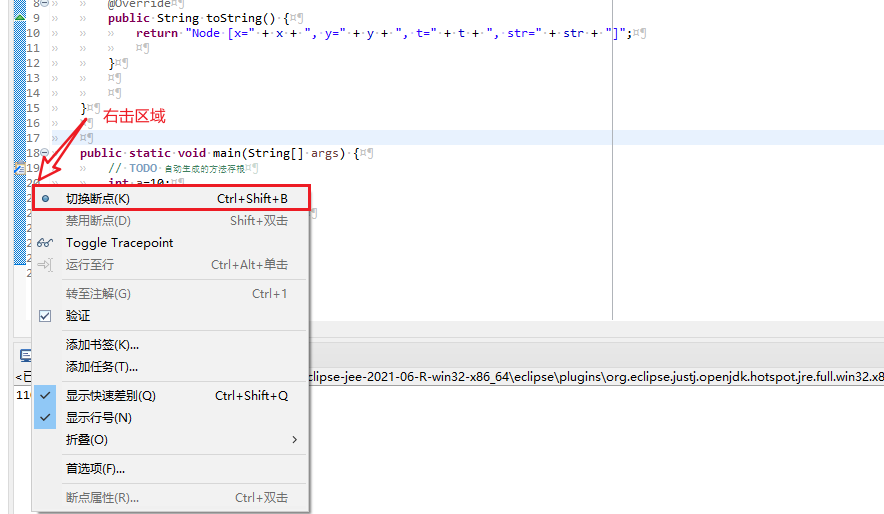
添加、删除断点
“断点”是用户所指定的程序中断的位置,作用于一个语句。如果使用Debug方式启动,程序在即将执行打上断点的语句之前时会终止下来,并将当前程序中所有使用的变量值拷贝到内存的一块区域中,方便用户检查。
Eclipse中可以在需要打断点语句的前面区域,单击鼠标“右键”,选择“切换断点”来添加、删除一个断点。当程序运行到断点之前,程序就会终止
开启窗口
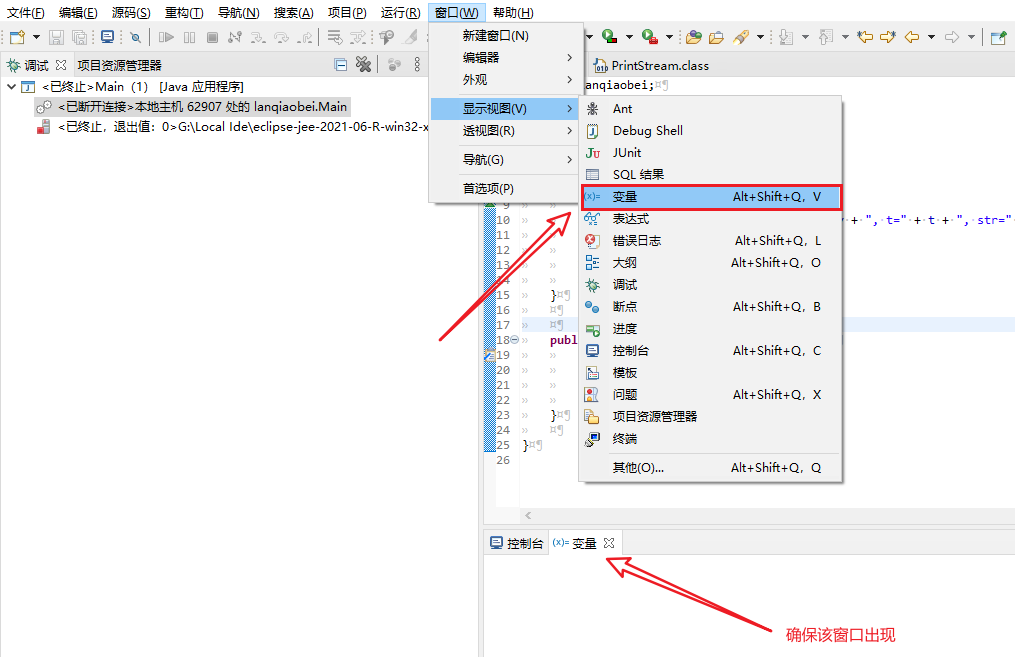
在开始断点调试之前,选择窗口->显示视图->变量,实现变量栏,确保能够在接下来的调试中能够观察变量数据。如果选择后没有出现变量栏,可以在Eclipse右侧工具栏中查看。
断点调试
确保前面的工作完成后,在需要调试的程序语句出打上断点,开始调试。就拿下面这部分代码调试举例:
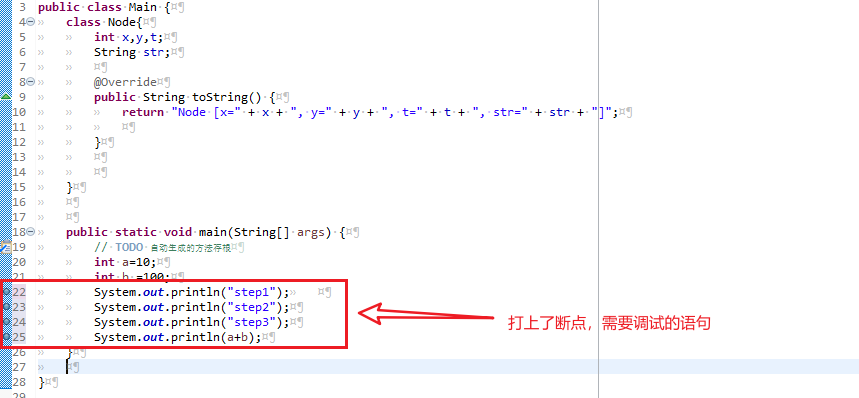
Debug方式启动的方式有很多,我推荐使用工具栏中的“调试”按钮启动:

启动完成之后,程序在执行完语句
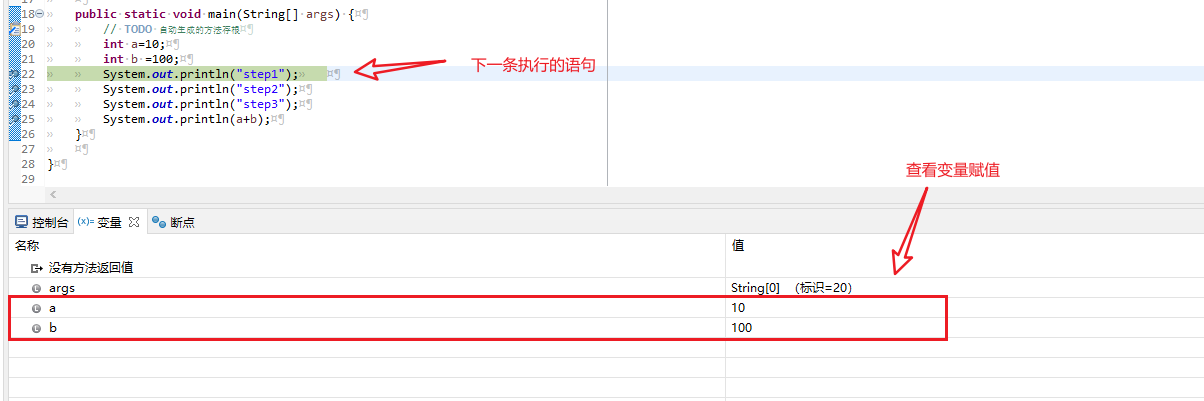
int b =100
后遇到了断点,程序被终止,下一条需要执行的语句使用了绿色高亮。同时可以通过“变量”栏查看当前所有变量的赋值情况:
如果希望程序继续运行,可以使用所说的快捷键方式,同样也可以在工具栏中选择继续运行的方式:
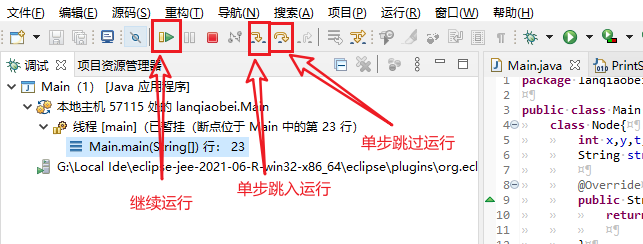
- 继续运行:继续运行直到程序结束或遇到下一个断点(推荐)
- 单步跳入运行:执行下一个语句,包括非本页面函数语句(不推荐)
- 单步跳过运行:执行下一个语句,不包括非本页面语句(推荐)
总结
程序返回结果不对需要调试时,通常将断点打在可能执行会出现问题的语句上。如果问题语句较多,推荐使用 “单步跳过运行” 调试,如果问题语句较少,推荐使用“继续运行”调试。
⚔ 数据篇
算法离不开数据,蓝桥杯作为OI赛制的比赛,数据的输入、输出是算法中极为重要的一环。
🗡 输入、输出重定向
有时做填空题,输入的字符串太多,可以将输入的数据暂时放在与
src
同一目录的文件中,通过 FileInputStream 进行重定向读取。同时如果输出的结果值太多而不好观察,也可以使用 PrintStream 重定向输入,将数据输出到文件中。

读取、重定向代码如下:
import java.io.BufferedInputStream;import java.io.BufferedReader;import java.io.File;import java.io.FileInputStream;import java.io.FileNotFoundException;import java.io.FileOutputStream;import java.io.FileReader;import java.io.InputStream;import java.io.PrintStream;import java.io.Reader;import java.util.Scanner;publicclassMain{publicstaticvoidmain(String[] args)throws FileNotFoundException {// 读取文件
File file =newFile("input.txt");
FileInputStream stream =newFileInputStream(file);
System.setIn(stream);// 创建输出文件
File outFile =newFile("output.txt");
PrintStream outputStream =newPrintStream(outFile);
System.setOut(outputStream);
Scanner cin =newScanner(System.in);// 每一行分割符
cin.useDelimiter(" ");while(cin.hasNext()){
System.out.println(cin.next());}}}
🗡 快速读取、写出模板
快速读取相较于使用
Scanner
读取数据速度更快,效率更高,甚至有的题目在大量输入的情况下只有使用快速读取才能AC!
快读、快写的模板有很多,这里我附上我常用的模板:
import java.io.BufferedReader;import java.io.BufferedWriter;import java.io.IOException;import java.io.InputStreamReader;import java.io.OutputStreamWriter;import java.io.PrintWriter;import java.io.StreamTokenizer;publicclassMain{// 快读、快写类publicstaticclasscin{static PrintWriter printWriter =newPrintWriter(newOutputStreamWriter(System.out));static BufferedReader reader =newBufferedReader(newInputStreamReader(System.in));static StreamTokenizer cin =newStreamTokenizer(reader);staticpublicintnextInt()throws IOException {
cin.nextToken();return(int)cin.nval;}staticpubliclongnextLong()throws IOException{
cin.nextToken();return(long)cin.nval;}staticpublicdoublenextDouble()throws IOException{
cin.nextToken();return cin.nval;}staticpublic String nextLine()throws IOException{return reader.readLine();}}publicstaticvoidmain(String[] args)throws IOException {try{// 主函数编写区域int val = cin.nextInt();long lval = cin.nextLong();double dval = cin.nextDouble();
String str = cin.nextLine();
cin.printWriter.println(val+" "+lval+" "+dval+" "+str);return;}finally{// 不能遗漏!!!
cin.printWriter.close();}}}
有两点需要注意:
cin.nextLine()方法可能读取上一行的回车符,如果在调用该方法之前有未捕获的回车符,需要注意以下。一般是添加cin.nextLine()接收回车符后,再读取内容。PrintWriter输出时存在一个缓冲区,如果需要完成输出即清空缓冲区的内容,需要将该输出流关闭。如果没有关闭该流就退出程序,那么输出的结果将不会显示。如果怕遗漏这一点的话可以使用try - finaly包住主函数部分,将关闭流的操作放入finally中。
🗡 数组排序
数组排序在蓝桥杯解题中出现率非常之高,甚至去年的一道大题就是基于数组排序来实现,因此非常重要!这里只是简单例举了Java中自带的
Arrays
类实现了对于数组的排序,对于堆排序、快排序、基数排序…还望同学能够自行学习。
1、Arrays.sort(int[] a)
这种形式是对一个数组的所有元素进行排序,并且是按从小到大的顺序:
import java.util.Arrays;publicclassMain{publicstaticvoidmain(String[] args){int[] a ={9,8,7,2,3,4,1,0,6,5};
Arrays.sort(a);for(int i =0; i < a.length; i ++){
System.out.print(a[i]+" ");}}}
运行结果如下:
0123456789
2、Arrays.sort(int[] a, int fromIndex, int toIndex)
这种形式是对数组部分排序,也就是对数组a的下标从fromIndex到toIndex-1的元素排序,注意:下标为toIndex的元素不参与排序哦!
import java.util.Arrays;publicclassMain{publicstaticvoidmain(String[] args){int[] a ={9,8,7,2,3,4,1,0,6,5};
Arrays.sort(a,0,3);for(int i =0; i < a.length; i ++){
System.out.print(a[i]+" ");}}}
//上例只是把 9 8 7排列成了7 8 97892341065
3、public static void sort(T[] a,int fromIndex, int toIndex, Comparator<? super T> c)
上面有一个拘束,就是排列顺序只能是从小到大,如果我们要从大到小,就要使用这种方式
读者只需要读懂下面的例子就可以了,其实就是多了一个Comparator类型的参数而已。
需要注意的是:如果需要制定排序方式,那么数组类型就不能是基础类型
import java.util.Arrays;import java.util.Comparator;publicclassMain{publicstaticvoidmain(String[] args){//注意,要想改变默认的排列顺序,不能使用基本类型(int,double, char)//而要使用它们对应的类
Integer[] a ={9,8,7,2,3,4,1,0,6,5};//定义一个自定义类MyComparator的对象
Comparator cmp =newMyComparator();
Arrays.sort(a, cmp);for(int i =0; i < a.length; i ++){
System.out.print(a[i]+" ");}}}//Comparator是一个接口,所以这里我们自己定义的类MyComparator要implents该接口//而不是extends ComparatorclassMyComparatorimplementsComparator<Integer>{@Overridepublicintcompare(Integer o1, Integer o2){//如果o1小于o2,我们就返回正值,如果o1大于o2我们就返回负值,//这样颠倒一下,就可以实现反向排序了if(o1 < o2){return1;}elseif(o1 > o2){return-1;}else{return0;}}}
运行结果如下:
9876543210
🗡 Calender类
蓝桥杯比赛中经常出现的有关日期问题的题目,通常需要大量的代码判断日期,非常不方便。Java为我们封装好了日历类Calender省去了大量的代码编写,使用该类能够让日期问题变得十分简单~
创建Calender实例
使用 Calender 的工厂方法 :
Calender.getInstance()
获取Calender实例:
publicstaticvoidmain(String[] args)throws IOException {
Calendar calendar = Calendar.getInstance();}
Calender类字段说明
Calender字段需要额外注意,有的字段常量值与日常使用有所区别:
字段名称含义取值范围补充说明YEAR年INF指定年份MONTH月
[
0
,
11
]
[0,11]
[0,11]**1月对应值为0,2月对应值为1…**DATE日[1,X]X代表该月拥有的天数。
等价于
DAY_OF_MONTH
HOUR_OF_DAY小时[0,23]24小时制HOUR小时[0,11]12小时制,通常搭配
AM_PM
使用
AM_PM
为1:上午
AM_PM
为0:下午MINUTE分钟[0,59]指示一小时中的分钟SECOND秒钟[0,59]指示一小时中的秒钟DAY_OF_WEEK周[1,7]值为1表示为周日,为2表示为周一…DAY_OF_YEAR日[1,365]一年的第多少天
上面标记为红色的字段,一定要注意与现实生活中使用的不同。
设置Calender时间
Calendar 中
set
和
get
时间都是通过在参数中填入不同的字段来实现的,
这里设置时间为2001年10月23日12时12分12秒 举例说明
publicstaticvoidmain(String[] args)throws IOException {
Calendar calendar = Calendar.getInstance();
calendar.set(Calendar.YEAR,2001);// 月份需要注意对应!!
calendar.set(Calendar.MONTH,9);
calendar.set(Calendar.DATE,23);
calendar.set(Calendar.HOUR_OF_DAY,12);
calendar.set(Calendar.MINUTE,12);
calendar.set(Calendar.SECOND,12);}
同时按照代码执行的顺序,位于后方日历的设置会覆盖前面日历的设置,就例如:
publicstaticvoidmain(String[] args)throws IOException {
Calendar calendar = Calendar.getInstance();// 前面修改年份的设置
calendar.set(Calendar.YEAR,2001);
calendar.set(Calendar.MONTH,9);
calendar.set(Calendar.DATE,23);
calendar.set(Calendar.HOUR_OF_DAY,12);
calendar.set(Calendar.MINUTE,12);
calendar.set(Calendar.SECOND,12);
calendar.set(Calendar.WEEK_OF_YEAR,3);// 一个修改年份的设置
calendar.set(Calendar.YEAR,2021);
System.out.println(calendar.getTime());}
运行出来的结果为:
Mon Jan 1112:12:12 CST 2021
Calender获取值
publicstaticvoidmain(String[] args)throws IOException {
Calendar calendar = Calendar.getInstance();
calendar.get (Calendar.YEAR);//年
calendar.get (Calendar.MONTH)+1;//月 ,1月对应0,2月对应1,因此需要+1
calendar.get (Calendar.DATE);//日
calendar.get (Calendar.HOUR_OF_DAY);//时
calendar.get (Calendar.MINUTE);//分
calendar.get (Calendar.SECOND);//秒
calendar.get (Calendar.DAY_OF_WEEK);//星期,周日是1,剩下自己推算)}
Calender运算
add:该运算能让某字段对应值加或减某一个值,对应日期的加减计算。
calendar.add (Calendar.YEAR,1);//年
calendar.add (Calendar.MONTH,1);//月
calendar.add (Calendar.DATE,1);//日
calendar.add (Calendar.HOUR_OF_DAY,-1);//时
calendar.add (Calendar.MINUTE,1);//分
calendar.add (Calendar.SECOND,1);//秒
calendar.add (Calendar.DATE,7);//周
⚔ 算法篇
终于准备工作完成,来到了最重要的算法环节。算法篇将会出现一些使用频率极高的模板,一些题目可以直接套用模板解题。同时还选择了每一个专题较有代表性的题目,并附上其解析。题目来自于LeetCode官网、Acwing官网、蓝桥杯官网。
望大侠能认真思考,从头来过。
🗡 字符串
KMP算法模板
KMP算法在蓝桥杯历届真题中出现的并不多,但仍旧是很重要的算法。
// 获取next数组publicstaticint[]getNext(String ps){char[] p = ps.toCharArray();int[] next =newint[p.length];
next[0]=-1;int j =0;int k =-1;while(j < p.length -1){if(k ==-1|| p[j]== p[k]){
next[++j]=++k;}else{
k = next[k];}}return next;}// KMP算法查找publicstaticintKMP(String ts, String ps){char[] t = ts.toCharArray();char[] p = ps.toCharArray();int i =0;// 主串的位置int j =0;// 串的位置int[] next =getNext(ps);while(i < t.length && j < p.length){if(j ==-1|| t[i]== p[j]){// 当j为-1时,要移动的是i,当然j也要归0
i++;
j++;}else{// i不需要回溯了// i = i - j + 1;
j = next[j];// j回到指定位置}}if(j == p.length){return i - j;}else{return-1;}}
🗡 二分
二分查找常用模板
upper_bound
- 参数要求- 查找参数:
valeftue- 有序数组:arightright- 查找区间:[left,right) - 功能描述:
upperight_bound使用二分的方式返回有序数组中第一个严格大于valeftue的索引位置,如果该值不存在则返回right
代码如下
publicstaticintupper_bound(int[] arr,int left,int right,int value){while(left < right){int mid = left +(right - left)/2;if(arr[mid]<= value){
left = mid +1;}else{
right = mid;}}return left;}
lower_bound
- 参数要求- 查找参数:
value- 有序数组:arr- 查找区间:[left,right) - 功能描述:
lower_bound使用二分的方式返回有序数组中第一个大于等于value的索引位置,如果该值不存在则返回right
代码如下
publicstaticintlower_bound(int[] arr,int left,int right,int value){while(left < right){int mid = left +(right - left)/2;if(arr[mid]< value){
left = mid +1;}else{
right = mid;}}return left;}
二分判断类问题
打包
题目传送门🎢
问题描述
Lazy有N个礼物需要打成M个包裹,邮寄给M个人,这些礼物虽然很便宜,但是很重。Lazy希望每个人得到的礼物的编号都是连续的。为了避免支付高昂的超重费,他还希望让包裹的最大重量最小。
输入格式
一行两个整数N和M。
一行N个整数,表示N个礼物的重量。输出格式
一个整数,表示最小的最大重量。
样例输入
3 2
1 1 2
共有N个礼物,需要进行M次打包,希望让每个人得到的包裹连续且最大重量最小,假设所有礼物的总重量为sum ,所有礼物中最重的礼物为max ,那么答案只有能可能出现[max,sum] 这个区间内部,我们可以给定一个属于区间[max,sum]的一个重量
T
a
r
g
e
t
Target
Target为每个包裹可以装入的最大重量。
那么我们如何判断最大重量下能够进行M次打包呢?因为打包的礼物必须是连续的,因此从第一个礼物开始遍历,看看最大重量下 N 个礼物需要打多少个包,如果小于等于M,说明每个包最大重量为
T
a
r
g
e
t
Target
Target是能够装下,符合题意。题目要求尽量获得最小的重量,这里使用二分的方法,左区间:max,右区间:sum,封装函数
j
u
d
g
e
judge
judge判断能够打包 ,取区间中间值mid,如果judge判断为true,说明mid下能满足题意,right=mid,否则left=mid+1,直到遍历出结果
举个栗子:
加入礼物重量分别是:1,2,3,4,5 ,要打成3个包裹,最大值是5,和是15,也答案只有可能在[5,15]这个范围内,那么二分枚举中间值
T a r g e t Target Target=(5+15)/2 =10,那么10这个最大重量是否合适呢?因为礼物只能连续打包,因此打包为:【1,2,3,4】【5】只需要两个包,但是题目中给定最大打包数量是3个,要求最小最大重量,显然3个包的情况下最大重量可以更小,也就是说答案的区间缩小到[5,10],同理枚举Target=(5+10)/2 = 7,礼物打包为:【1,2,3】【4】【5】,打包数量为3个,题给定的打包数量也是3个,那么7就是最终答案了吗?不一定因为5,6两种情况还没有枚举,此时答案区间缩小为[5,7],接着枚举6,打包为【1,2,3】【4】【5】,打包数量为3个,缩小区间为[5,6],最后枚举5,【1,2】【3】【4】【5】,打包数量为4个,超过了题目给定的打包数量,也就是说答案ans>5,因此缩小区间为[6,6],最终得到答案。
代码
import java.util.Scanner;publicclassMain{publicstaticvoidmain(String[] args){
Scanner cin=newScanner(System.in);int num = cin.nextInt();int pack = cin.nextInt();int[]weight=newint[num];int right=0,left=0;for(int i=0;i<num;++i){
weight[i]=cin.nextInt();
right+=weight[i];}int mid=0;//二分查找while(left<right){
mid=(left+right)/2;if(judge(weight,mid,pack)){
right = mid;}else{
left=mid+1;}}
System.out.println(left);}privatestaticbooleanjudge(int[] weight,int mid,int pack){//curWeight 保存当前这个包的重量int curWeight=0;//curPack 保存的需要打包数量int curPack=1;for(int val:weight){// 如果超出了所给定的最大打包数量,返回falseif(val>mid){returnfalse;}
curWeight+=val;// 超过了单个包的最大重量,打一个新的包if(curWeight>mid){
curWeight=val;
curPack+=1;}}return curPack<=pack;}}
扫地机器人
题目描述
题目传送门🚀
小明公司的办公区有一条长长的走廊,由 N 个方格区域组成,如下图所示。
走廊内部署了 K 台扫地机器人,其中第 台在第 Ai 个方格区域中。已知扫地机器人每分钟可以移动到左右相邻的方格中,并将该区域清扫干净。
请你编写一个程序,计算每台机器人的清扫路线,使得
- 它们最终都返回出发方格,
- 每个方格区域都至少被清扫一遍,
- 从机器人开始行动到最后一台机器人归位花费的时间最少。
注意多台机器人可以同时清扫同一方块区域,它们不会互相影响。
输出最少花费的时间。 在上图所示的例子中,最少花费时间是 6。第一台路线:2-1-2-3-4-3-2,清 扫了 1、2、3、4 号区域。第二台路线 5-6-7-6-5,清扫了 5、6、7。第三台路线 10-9-8-9-10,清扫了 8、9 和 10。
输入格式:
第一行输入两个整数:N、K
第二行输入K个整数,表示扫地机器人的位置
输出格式:
输出一个整数,表示移动步数最多的机器人移动的步数
案例:
输入:
10 3
3 5 8
输出:
6
说明:
总移动步数最少的方案为:
1号机器人路线:3->2->1->2->3->4->3
2号机器人路线:5->6->7->6->5
3号机器人路线:8->9->10->9->8

题目中要求给出最多的机器人移动步数,例如上例中最左侧机器人的移动距离步数是最多的:共移动了六格,不难发现除了其开始所在的方格之外,一共清扫了 3 个方格,进一步推导不难得出,移动的步数 = 除开始所在方格外连续清洗方格数的两倍。
为什么能够除去开始所在的方格呢?
移动到开始时方格所消耗的步数为0,所以可以不予考虑。
那么我将所求转换为:除其所在方格外擦洗最多连续(每次只能移动一格)方格的数目 * 2.
那么我们设机器人最多连续擦洗的方格数为
n
u
m
num
num ,取两个极端的情况,如果所有方格都被放置了一个机器人,也就是说
n
u
m
num
num 只有可能是 0 ,因为所有机器人不需要移动就能完成擦洗任务;如果一共
N
N
N 个方格,只有一台机器人,那么该机器人需要擦洗所有方格,
n
u
m
=
N
−
1
num = N - 1
num=N−1,也就是说
n
u
m
∈
[
0
,
N
−
1
]
num\in[0,N-1]
num∈[0,N−1]。
知道了区间范围,可以使用二分的方法,令
m
i
d
mid
mid为中间值,假设答案
m
i
d
mid
mid能够满足清洗条件,此时答案区间就能缩减为:
n
u
m
∈
[
0
,
m
i
d
]
num\in[0,mid]
num∈[0,mid],否则答案区间缩减为:
n
u
m
∈
[
m
i
d
+
1
,
N
−
1
]
num\in[mid+1,N-1]
num∈[mid+1,N−1],继续遍历直到找到答案。

拿上面的例子举例,此时枚举的答案值为:**
m
i
d
mid
mid** 。
check
函数核心的思想:每一台机器人优先清洗左侧方格,如果还有剩余次数:清洗右侧方格直到次数为0或右侧有其他机器人。
对于第一台机器人
R
1
R_1
R1 ,
R
1
R_1
R1 左侧没有其他机器人,但是其左侧有方块没有被清理。如果这时右侧机器人
R
2
R_2
R2帮他清理左侧方格,这**显然不符合我们希望找到最小的机器人移动最大步数这个前提**,、左侧区域只能够由
R
1
R_1
R1 来清洗才能保证最小值,其余的任何机器人都无法帮助
R
1
R_1
R1清洗该区域。如果另左侧需要清理方格数量 为
r
e
d
red
red ,会有下面两种情况:
- 如果 r e d > m i d red > mid red>mid,说明 m i d mid mid 答案下无法清理,因此直接返回
false。 - 否则, R 1 R_1 R1 能够清左侧的方块,此时
mid-red表示能够清理的方块数目减少。但是如果剩余的最大清理次数,为了尽可能使用完 m i d mid mid 次,此时 R 1 R_1 R1可以向右侧清理 m i d − r e d mid-red mid−red 格,让 R 2 R_2 R2需要清理的左侧需要清理的方格尽可能的少。我们能够根据 R 1 R_1 R1 与 R 2 R_2 R2的间隔值与 R 1 R_1 R1帮助清理的方格数能够算出 遍历到 R 2 R_2 R2 时的 r e d red red 值。循环判断 R 2 R_2 R2 能够完成清理…
最终根据
check
的范围值不断缩小区间,最终获得答案值为:
l
∗
2
l *2
l∗2
// 1:无需package// 2: 类名必须Main, 不可修改import java.io.*;import java.util.Arrays;publicclassMain{// m 为当前的最大擦洗次数publicstaticbooleancheck(int n,int m,int[]robots){// 左侧长度int red = robots[0];for(int i =0; i < robots.length;++i){if(m < red){returnfalse;}int num = m - red;// 计算距离下一个机器人的长度
red =(i == robots.length -1? n : robots[i +1])- robots[i]-1;// 能帮助右侧机器人清扫if(num >0){
red = Math.max(0, red - num);}}return red ==0;}publicstaticvoidmain(String[] args)throws IOException {
PrintWriter writer =newPrintWriter(newOutputStreamWriter(System.out));
BufferedReader reader =newBufferedReader(newInputStreamReader(System.in));
StreamTokenizer in =newStreamTokenizer(reader);int n,k;int[] robots;
in.nextToken();
n =(int) in.nval;
in.nextToken();
k =(int) in.nval;
robots =newint[k];for(int i =0; i < k;++i){
in.nextToken();// 更改为存储索引
robots[i]=(int) in.nval -1;}// 按照机器人的索引位置排序
Arrays.sort(robots);int l, r;// 开始的区间范围 [0,n-1]
l=0;
r =(n -1);while(l < r){int m = l +(r - l)/2;if(check(n, m, robots)){
r = m;}else{
l = m +1;}}
System.out.println(l <<1);
writer.flush();}}
🗡 递归
DFS – 深度优先遍历
全排列
普通版
- 全排列
- 参数要求 - 全排列数组:
nums - 功能描述:
permute方法采用回溯的思想生成全排列并返回
classSolution{// 全排列结果
List<List<Integer>>back;int[] nums;voidswap(int idx1,int idx2){int temp = nums[idx1];
nums[idx1]=nums[idx2];
nums[idx2]=temp;}publicvoiddfs(int l,int r){if(l==r){
List<Integer>temp=newArrayList<>();for(int val:nums){
temp.add(val);}
back.add(temp);return;}for(int i=l;i<r;++i){swap(i,l);dfs(l+1,r);swap(i,l);}}public List<List<Integer>>permute(int[] nums){
back=newArrayList<List<Integer>>();this.nums=nums;dfs(0,nums.length);return back;}}
进阶版
- 全排列 II
- 题目要求:确保得到的全排列没有重复的排列方式,例如:[1,2,2] 的全排列中:[2,2,1] 只能出现一次
- 参数要求 - 全排列数组:
nums
classSolution{boolean[] vis;public List<List<Integer>>permuteUnique(int[] nums){
List<List<Integer>> ans =newArrayList<List<Integer>>();
List<Integer> perm =newArrayList<Integer>();
vis =newboolean[nums.length];
Arrays.sort(nums);backtrack(nums, ans,0, perm);return ans;}publicvoidbacktrack(int[] nums, List<List<Integer>> ans,int idx, List<Integer> perm){if(idx == nums.length){
ans.add(newArrayList<Integer>(perm));return;}for(int i =0; i < nums.length;++i){// 如果是11这种情况,假设第一个1是a1 第二个1是b1,如果需要保证不会重复选择,即按照a1b1的次序而不会出现 b1a1 的次序,那么选择b1之前a1必须是已经选择的状态,即vis[i-1]==1if(vis[i]||(i >0&& nums[i]== nums[i -1]&&!vis[i -1])){continue;}
perm.add(nums[i]);
vis[i]=true;backtrack(nums, ans, idx +1, perm);
vis[i]=false;
perm.remove(idx);}}}
组合总数
组合总数类型题目通常给定一个数组和一个目标值,返回使用数组中的元素组合为目标值的所有方案。
解题的核心思想是回溯,遍历每一种可能的选择方法最终将得到的方案返回。
普通版
- 组合总和
核心思路:普通组合问题其本质就是回溯问题,每一次选择都可以选择继续取本位置的数或取下一位的数值。
- 参数需求: -
candidates:可选择数值数组-target:目标值
classSolution{
List<List<Integer>>ans;
List<Integer>path;voiddfs(int val,int idx,int target,int[]candidates){// 剪枝if(val>target||idx==candidates.length){return;}if(val==target){
ans.add(newArrayList<>(path));return;}// 该数值不取dfs(val,idx+1,target,candidates);
path.add(candidates[idx]);// 继续取该数值dfs(val+candidates[idx],idx,target,candidates);
path.remove(path.size()-1);}public List<List<Integer>>combinationSum(int[] candidates,int target){
path=newArrayList<>();
ans=newArrayList<>();dfs(0,0,target,candidates);return ans;}}
进阶版
- 组合总和 II
如果选中的组合不能重复且每一个数值只能使用一次,那么要如何解题呢?
核心思想:对数组进行排序,排序后选择时每一层选中每一个数值第一次出现的位置,也就是说同一个数值不会在一层中重复出现。为了防止重复使用,每次遍历后下一层的起点是本层遍历元素的下一个元素。
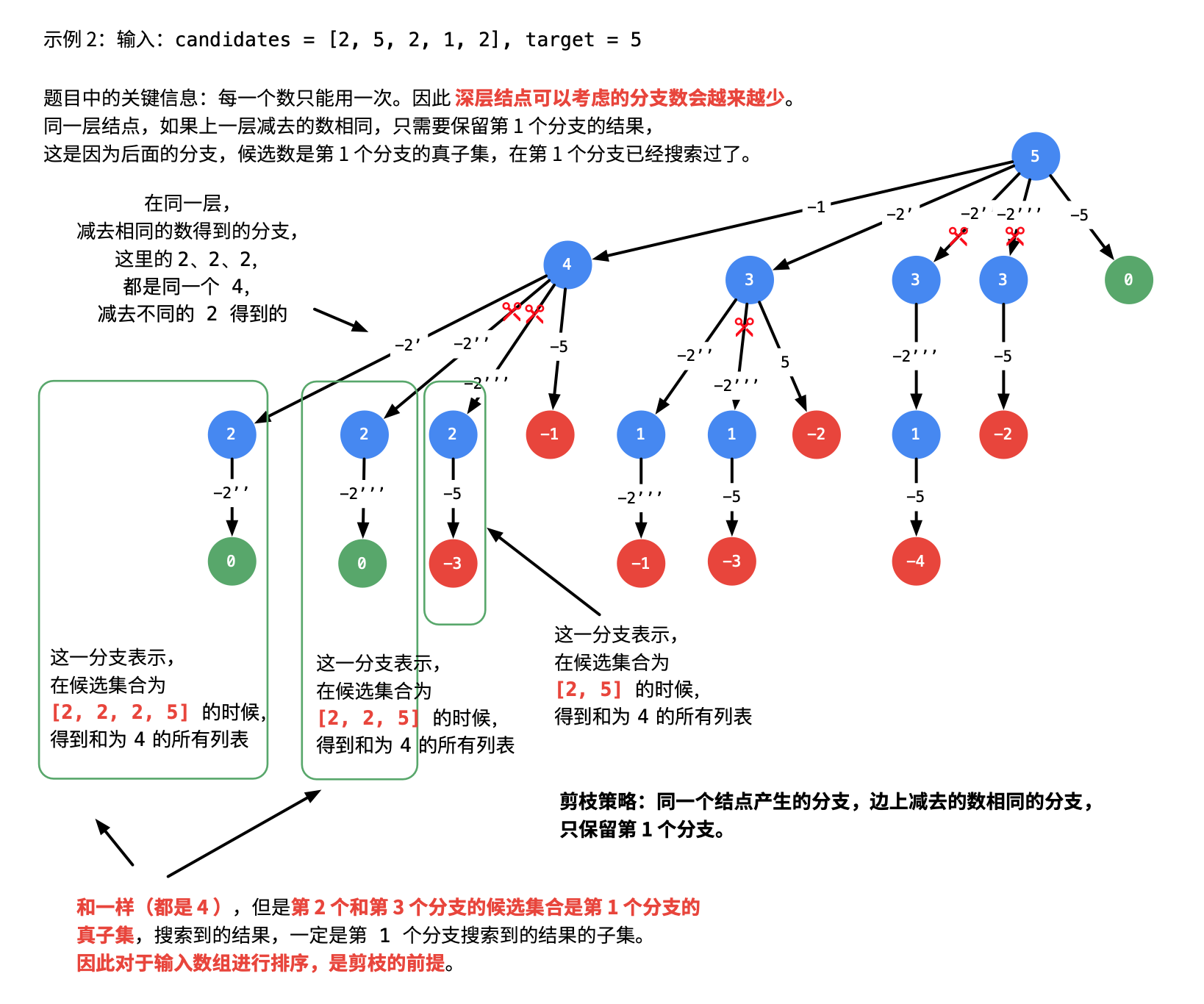
- 参数需求: -
candidates:可选择数值数组-target:目标值
classSolution{int[] used;
List<List<Integer>>ans;
List<Integer>path;voiddfs(int[]candidates,int target,int idx,int val){if(val==target){
ans.add(newArrayList<>(path));return;}for(int i=idx;i<candidates.length;++i){// 剪枝if(val+candidates[i]>target){break;}// 如果多个值相同,只选择第一个if(i>idx && candidates[i]==candidates[i-1]){continue;}
path.add(candidates[i]);// 每次遍历其右侧元素dfs(candidates,target,i+1,val+candidates[i]);
path.remove(path.size()-1);}}public List<List<Integer>>combinationSum2(int[] candidates,int target){
Arrays.sort(candidates);int n = candidates.length;
used=newint[n];
ans=newArrayList<>();
path=newArrayList<>();dfs(candidates,target,0,0);return ans;}}
全球变暖
你有一张某海域NxN像素的照片,".“表示海洋、”#"表示陆地,如下所示:
7........##.....##........##...####....###........其中"上下左右"四个方向上连在一起的一片陆地组成一座岛屿。例如上图就有2座岛屿。
由于全球变暖导致了海面上升,科学家预测未来几十年,岛屿边缘一个像素的范围会被海水淹没。具体来说如果一块陆地像素与海洋相邻(上下左右四个相邻像素中有海洋),它就会被淹没。
例如上图中的海域未来会变成如下样子:
…
…
…
…
…#…
…
…请你计算:依照科学家的预测,照片中有多少岛屿会被完全淹没。
【输入格式】
第一行包含一个整数N。 (1 <= N <= 1000)
以下N行N列代表一张海域照片。照片保证第1行、第1列、第N行、第N列的像素都是海洋。
【输出格式】
一个整数表示答案。【输入样例】
7........##.....##........##...####....###........资源约定:
峰值内存消耗(含虚拟机) < 256M
CPU消耗 < 1000ms
这道题跟我做过的LeetCode上的一道题很像,如果感兴趣的朋友可以练练手:岛屿的数量
开始时我的解题思路是,先求出岛屿的数量,在将挨着水的陆地涂为其他字符,再次求出岛屿的数量,最后相间得到消失的岛屿数量。一提交好家伙超时了。。。
核心的思路是深度、广度优先遍历的方式,定义
p
r
e
pre
pre存储变暖前的岛屿数量,定义
a
f
t
e
r
after
after存储变暖后的岛屿数量。
使用
f
o
r
for
for 循环找到符号
#
,表示该位置是属于岛屿的位置,此时发现了一座岛执行:
pre+=1
,从这个位置开始遍历与该位置相连接的所有没有遍历到的岛屿方块。如果遍历到的岛屿方块邻接水域,那么将该岛屿方块值置为
K
,否则置为
W
(值任意取看自己的喜好)。如果该方块在判断后没有被邻接水域,说明该岛屿没有被完全淹没,可以返回一个大于0的常数,此时
after+=1
。
最终
pre-after
就是结果值。
import java.io.*;publicclassMain{privatestaticfinalint[][] DIRECTS =newint[][]{{1,0},{-1,0},{0,1},{0,-1}};publicstaticintislands(char[][] picture,int x,int y){int bk =0;int n = picture.length;// 判断是否邻接水域for(int[] direct : DIRECTS){int nx = x + direct[0];int ny = y + direct[1];if(nx <0|| ny <0|| nx >= n || ny >= n || picture[nx][ny]!='.'){continue;}
picture[x][y]='K';}// 判断变暖后任然是岛屿if(picture[x][y]=='#'){
picture[x][y]='W';++bk;}for(int[] direct : DIRECTS){int nx = x + direct[0];int ny = y + direct[1];if(nx <0|| ny <0|| nx >= n || ny >= n){continue;}// 继续遍历没有遍历过的岛屿if(picture[nx][ny]=='#'){
bk +=islands(picture, nx, ny);}}return bk;}publicstaticvoidmain(String[] args)throws IOException {
PrintWriter writer =newPrintWriter(newOutputStreamWriter(System.out));
BufferedReader reader =newBufferedReader(newInputStreamReader(System.in));
StreamTokenizer in =newStreamTokenizer(reader);int n;char[][] pictures;
in.nextToken();
n =(int)in.nval;
pictures =newchar[n][n];for(int i =0; i < n;++i){
pictures[i]= reader.readLine().toCharArray();}int pre =0, after =0;for(int i =0; i < n;++i){for(int j =0; j < n;++j){if(pictures[i][j]=='#'){++pre;if(islands(pictures, i, j)>0){++after;}}}}
writer.println((pre - after));
writer.flush();}}
BFS – 广度优先遍历
迷宫问题
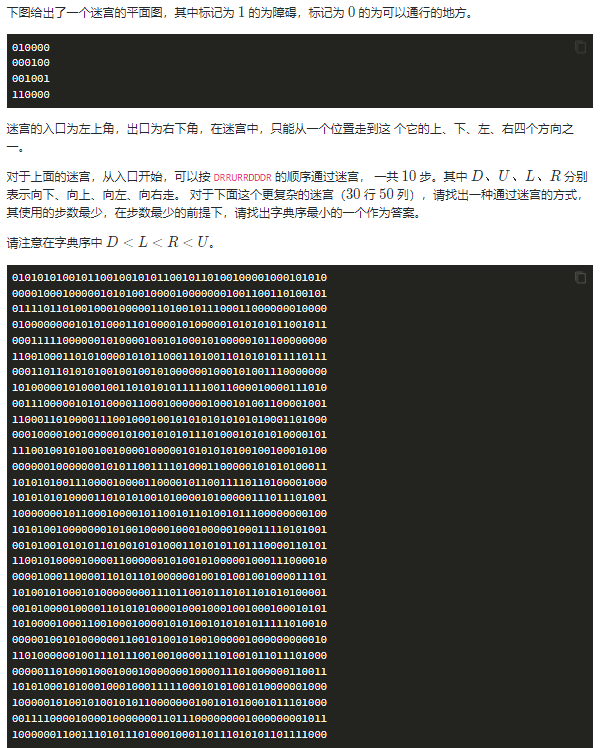
☔️解题思路
剖析题目关键字:步数最少 返回结果的字典序最小
对于迷宫问题常规解法是 bfs或 dfs算法,为了尽快得到最少的步数,这里使用 bfs 算法
为了返回的字典序最小,bfs遍历时依次按照:D、L、R、U的顺序遍历,返回的结果一定是字典序最小的。
为了不重复到达一个点影响程序性能,可以使用used数组将遍历过的点进行标记,同样也可以将遍历过的点由0该为1防止重复遍历。
⭐️注意:
我的代码中使用了Java流读取同路径下的file.txt文件,如果没有创建该文件写入数据请先创建文件!!!
import java.io.BufferedReader;import java.io.FileReader;import java.io.IOException;import java.util.LinkedList;import java.util.Queue;// 1:无需package// 2: 类名必须Main, 不可修改publicclassMain{publicstaticclassNode{
StringBuilder paths;int x;int y;Node(int x,int y,StringBuilder str){this.x = x;this.y = y;
paths = str;}}staticchar[][] arr =newchar[100][100];staticint[][] directs =newint[][]{{1,0},{0,-1},{0,1},{-1,0}};staticchar[] directChar =newchar[]{'D','L','R','U'};staticint n, m;publicstaticvoidmain(String[] args)throws IOException {// 读取数据
BufferedReader stream =newBufferedReader(newFileReader("file.txt"));
String str;while((str = stream.readLine())!= null){
m = str.length();
arr[n++]= str.toCharArray();}
Queue<Node> queue =newLinkedList<>();
queue.add(newNode(0,0,newStringBuilder()));while(!queue.isEmpty()){
Node cur = queue.poll();int curx = cur.x;int cury = cur.y;
StringBuilder s = cur.paths;if(curx == n -1&& cury == m -1){
System.out.println(s);return;}
arr[curx][cury]='1';for(int i =0; i <4; i++){int nx = curx + directs[i][0];int ny = cury + directs[i][1];if(nx <0|| ny <0|| nx >= n || ny >= m || arr[nx][ny]=='1'){continue;}
StringBuilder ss =newStringBuilder(s);
ss.append(directChar[i]);
queue.add(newNode(nx, ny, ss));}}}}
🗡 图论
常用模板
Dijkstra算法
Dijkstra常常用于解决单源的最短路径问题,时间复杂度为:
O
(
N
2
)
O(N^2)
O(N2),其核心思路是贪心算法。
- 参数需求: -
path:存储点与点的路径关系,点与点之间无法直接到达距离为INF-from:起点索引位置-to:终点索引位置 - 功能描述: - 从
from点到to点的最短距离,如果无法到达则返回 -1
finalint INF = Integer.MIN_VALUE /2;publicintdijstra(int path[][],int from,int to){int n = path.length;//dist[]保存距离的最小值int[] dist =newint[n];//used存储使用情况boolean[] used =newboolean[n];//初始化
Arrays.fill(dist, INF);
dist[from]=0;//开始遍历for(int i =0; i < n; i++){//存储下一个结点编号int x =-1;//遍历寻找最短且没有被使用的结点for(int y =0; y < n; y++){if(!used[y]&&(x ==-1|| dist[y]< dist[x])){
x = y;}}
used[x]=true;//更新距离for(int iz =0; iz < n; iz++){
dist[iz]= Math.min(dist[iz], path[x][iz]+ dist[x]);}}int ans =-1;for(int val : dist){
ans = Math.max(INF, val);}return ans == INF ?-1: ans;}
Floyd算法
Floyd常常用于解决多源最短路径问题,时间复杂度为:
O
(
N
3
)
O(N^3)
O(N3)。
- 参数需求: -
path:存储点与点的路径关系,点与点之间无法直接到达距离为INF - 功能描述: - 将
path数组存储所有点到目标点的最短距离,如果无法到达值为INF
finalint INF = Integer.MIN_VALUE /2;publicvoidfloyd(int path[][]){int n = path.length;for(int z =0; z < n;++z){for(int i =0; i < n;++i){for(int j =0; j < n;++j){
path[i][j]= Math.min(path[i][j], path[i][z]+ path[z][j]);}}}}
拓扑排序
拓扑排序常用于有向、无向图中查询是否有环路,时间复杂度为:
O
(
n
2
)
O(n^2)
O(n2)
- 参数要求-
path:存储点与点的路径关系,点与点之间无法直接到达距离为INF - 功能描述- 判断
path数组存储的图中是否存在环路,如果存在返回true
finalint INF = Integer.MIN_VALUE /2;booleantopSort(int[][]path){int n = path.length;//存放入度int[] inNode =newint[n];int cnt =0;
Queue<Integer> queue =newLinkedList<>();//查询入度for(int i =0; i < n;++i){for(int j =0; j < n;++j){if(path[i][j]!= INF){
inNode[j]++;}elseif(path[j][i]!= INF){
inNode[i]++;}}}//找到入度为0的点for(int i =0; i < n;++i){if(inNode[i]==0){
queue.add(i);++cnt;}}//遍历while(!queue.isEmpty()){int idx = queue.poll();//遍历其能够到达的点for(int i =0; i < n;++i){if(path[idx][i]!= INF){--inNode[i];if(inNode[i]==0){
queue.add(i);++cnt;}}}}// 判断是否所有结点都被遍历?如果不是则存在环return cnt != n;}
网络延迟时间
题目传送门🚀
有
n个网络节点,标记为
1到
n。
给你一个列表
times,表示信号经过 有向 边的传递时间。
times[i] = (ui, vi, wi),其中
ui是源节点,
vi是目标节点,
wi是一个信号从源节点传递到目标节点的时间。
现在,从某个节点
K发出一个信号。需要多久才能使所有节点都收到信号?如果不能使所有节点收到信号,返回
-1示例 1:
输入:times = [[2,1,1],[2,3,1],[3,4,1]], n = 4, k = 2 输出:2示例 2:
输入:times = [[1,2,1]], n = 2, k = 1 输出:1示例 3:
输入:times = [[1,2,1]], n = 2, k = 2 输出:-1提示:
1 <= k <= n <= 1001 <= times.length <= 6000times[i].length == 31 <= ui, vi <= nui != vi0 <= wi <= 100- 所有
(ui, vi)对都 互不相同(即,不含重复边)
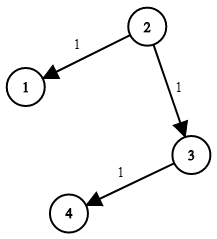
一道有向图寻找最短路径的模板题,根据题目给定的数据存储点与点的可达距离于数组
path
中,两个无法直接到达的点距离为
INF
。现在给定了一个起始点
k
,求出到所有点的最短路径的最大值,就是网络延迟的最长时间。
这里我列出两种最短路径算法的AC代码提供学习。但因为这道题是单源最短路径求解问题,使用
dijkstra
算法时间消耗会更低,这点需要留意。
Dijstra算法AC
classSolution{publicintnetworkDelayTime(int[][] times,int n,int k){finalint INF = Integer.MAX_VALUE /2;int[][] path =newint[n][n];for(int i =0; i < n;++i){
Arrays.fill(path[i], INF);}for(int i=0;i< times.length;++i){
path[times[i][0]-1][times[i][1]-1]=times[i][2];}//dist[]保存距离的最小值int[]dist=newint[n];
Arrays.fill(dist,INF);
dist[k-1]=0;boolean[]used=newboolean[n];for(int i=0;i<n;i++){int x=-1;for(int y=0;y<n;y++){if(!used[y]&&( x ==-1||dist[y]< dist[x])){
x = y;}}
used[x]=true;for(int iz=0;iz<n;iz++){
dist[iz]=Math.min(dist[iz],path[x][iz]+dist[x]);}}int ans=Arrays.stream(dist).max().getAsInt();return ans==INF?-1:ans;}}
Floyd算法AC
import java.util.Arrays;classSolution{int[][]path;finalint INF = Integer.MAX_VALUE/2;publicintnetworkDelayTime(int[][] times,int n,int k){
path=newint[n+1][n+1];for(int i=1;i<=n;++i){
Arrays.fill(path[i], INF);
path[i][i]=0;}for(int[]time:times){
path[time[0]][time[1]]=time[2];}for(int z=1;z<=n;++z){for(int i=1;i<=n;++i){for(int j=1;j<=n;++j){
path[i][j]=Math.min(path[i][j],path[i][z]+path[z][j]);}}}int M =-1;for(int i=1;i<=n;++i){
M = Math.max(path[k][i],M);}return M==INF?-1:M;}}
发现环
题目传送门🚀
解题思路:
一道典型的双向拓扑排序问题:
- 定义
inNode[]存储每一个节点的入度,因为网络路径是双向路径,因此在添加一条新的路径时,路径两端的点入度都需要加上一 - 定义
arr[][]存储路径,arr[from][0]=to || arr[from][1] =to都能表示from节点与to节点相连接- 为什么需要的是一个二维数组呢?因为路径中增加了一条线路,导致必定会有一个结点与两个结点相连接,因此使用一个二维数组来存储
对于拓扑排序,定义一个队列存储遍历的元素,首先将入度为1的边缘结点放入队列中,并使其入度减小1,随后在队列中取出结点的索引,遍历该结点相连的结点,使其入度减小1,如果入度为1则将该相连的结点加入队列中,最终入度>1的结点,也就是没有被存入队列的结点,就是环中的结点。
// 1:无需package// 2: 类名必须Main, 不可修改import java.io.*;import java.util.LinkedList;import java.util.Queue;publicclassMain{publicstaticvoidmain(String[] args)throws IOException {
PrintWriter writer =newPrintWriter(newOutputStreamWriter(System.out));
BufferedReader reader =newBufferedReader(newInputStreamReader(System.in));
StreamTokenizer in =newStreamTokenizer(reader);
in.nextToken();int n =(int) in.nval;int[][] arr =newint[n +1][2];int[] inNode =newint[n +1];for(int i =1; i <= n;++i){
in.nextToken();int to =(int) in.nval;
in.nextToken();int from =(int) in.nval;// 入度+1
inNode[to]++;
inNode[from]++;// 保存方向if(arr[from][0]!=0){
arr[from][1]=to;}else{
arr[from][0]= to;}if(arr[to][0]!=0){
arr[to][1]=from;}else{
arr[to][0]= from;}}
Queue<Integer> queue =newLinkedList<>();for(int i =1; i <= n;++i){// 将入度为1的元素放入队列if(inNode[i]==1){
queue.add(i);
inNode[i]--;}}while(!queue.isEmpty()){int cur = queue.poll();// 遍历其相邻结点for(int t =0; t <=1;++t){int nx = arr[cur][t];if(nx !=0){
arr[cur][t]=0;
inNode[nx]--;if(inNode[nx]==1){
queue.add(nx);}}}}for(int i =1; i <= n;++i){if(inNode[i]>1){
writer.print(i +" ");}}
writer.flush();}}
🗡 动态规划
动态规划是蓝桥杯中的一大难点与重点,这里博主只是将举例动态规划较基础的背包问题,篇幅有限望读者能进行深入地学习。
背包部分题目来自于ACWING官网,题解部分是以前写的一点。
0-1背包
题目传送门🚀
有 N 件物品和一个容量是 VV 的背包。每件物品只能使用一次。
第 i 件物品的体积是 vi,价值是 wi。
求解将哪些物品装入背包,可使这些物品的总体积不超过背包容量,且总价值最大。
输出最大价值。输入格式
第一行两个整数,N,V用空格隔开,分别表示物品数量和背包容积。
接下来有 N 行,每行两个整数 vi,wi,用空格隔开,分别表示第 i 件物品的体积和价值。
输出格式
输出一个整数,表示最大价值。
数据范围
0<N,V≤1000
0<vi,wi≤1000输入样例
4 5 1 2 2 4 3 4 4 5输出样例:
8
(1)状态
dp[i][j]
定义:前 i 个物品,背包容量 j 下的最优解(最大价值):
- 当前的状态依赖于之前的状态,可以理解为从初始状态
dp[0][0] = 0开始决策,有 N 件物品,则需要 N 次决 策,每一次对第 i 件物品的决策,状态dp[i][j]不断由之前的状态更新而来。
(2)当前背包容量不够(
j < v[i]
),没得选,因此前 ii 个物品最优解即为前 i−1 个物品最优解:
- 对应代码:
dp[i][j] = dp[i - 1][j]。
(3)当前背包容量够,可以选,因此需要决策选与不选第 i 个物品:
- 选:
dp[i][j] = dp[i - 1][j - v[i]] + w[i]。 - 不选:
dp[i][j] = dp[i - 1][j]。 - 我们的决策是如何取到最大价值,因此以上两种情况取
max()。
import java.util.Scanner;classMain{publicstaticvoidmain(String[] args){
Scanner cin =newScanner(System.in);int n = cin.nextInt();int m = cin.nextInt();int[] values =newint[n];int[] weight =newint[n];for(int i =0; i < n; i++){
weight[i]= cin.nextInt();
values[i]= cin.nextInt();}int[][] dp =newint[n +1][m +1];for(int i =1; i <= n;++i){for(int j =0; j <= m;++j){if(j >= weight[i -1]){
dp[i][j]= Math.max(dp[i -1][j - weight[i -1]]+ values[i -1], dp[i -1][j]);}else{
dp[i][j]= dp[i -1][j];}}}
System.out.println(dp[n][m]);}}
同时还能进行空间压缩,对于
dp[i][j]=Math.max(dp[i-1][j-weight[i-1]]+values[i-1],dp[i-1])
,( i , j ) 对应的值仅仅取决于
i
−
1
i-1
i−1 行值的大小,且
j
j
j 的值取决于
j
−
w
e
i
g
h
t
[
i
−
1
]
j-weight[i-1]
j−weight[i−1] 的大小,也就是说在一维数组下已经知道
i
−
1
i-1
i−1 行的数据,计算第
i
i
i 行数据时只要其
j
−
w
e
i
g
h
t
[
i
−
1
]
j-weight[i-1]
j−weight[i−1] 也就是其左侧数据不被覆盖,就能够获得该行的值。代码如下:
import java.util.Scanner;classMain{publicstaticvoidmain(String[] args){
Scanner cin =newScanner(System.in);int n = cin.nextInt();int m = cin.nextInt();int[] values =newint[n];int[] weight =newint[n];for(int i =0; i < n; i++){
weight[i]= cin.nextInt();
values[i]= cin.nextInt();}int[] dp =newint[m +1];for(int i =1; i <= n;++i){for(int j = m; j >=0;--j){if(j >= weight[i -1]){
dp[j]= Math.max(dp[j - weight[i -1]]+ values[i -1], dp[j]);}}}
System.out.println(dp[m]);}}
完全背包
题目传送门🚀
有 N 种物品和一个容量是 V 的背包,每种物品都有无限件可用。
第 i 种物品的体积是 vi,价值是 wi。
求解将哪些物品装入背包,可使这些物品的总体积不超过背包容量,且总价值最大。
输出最大价值。输入格式
第一行两个整数,N,V,用空格隔开,分别表示物品种数和背包容积。
接下来有 N 行,每行两个整数 vi,wi,用空格隔开,分别表示第 i 种物品的体积和价值。
输出格式
输出一个整数,表示最大价值。
数据范围
0<N,V≤1000
0<vi,wi≤1000输入样例
4 5 1 2 2 4 3 4 4 5输出样例:
10
(1)状态
dp[i][j]
定义:前 i 个物品,背包容量 j 下的最优解(最大价值),相较于0-1背包,完全背包能够多次选择某一件物品,也就是说能够通过多一次循环来解决选择问题:
import java.util.Scanner;publicclassMain{publicstaticvoidmain(String[] args){
Scanner cin =newScanner(System.in);int n = cin.nextInt();int m = cin.nextInt();int[] values =newint[n];int[] weight =newint[n];for(int i =0; i < n; i++){
weight[i]= cin.nextInt();
values[i]= cin.nextInt();}int[][] dp =newint[n +1][m +1];for(int i =1; i <= n;++i){for(int j =0; j <= m;++j){// 遍历选择的次数for(int k =0; k * weight[i -1]<= j;++k){
dp[i][j]= Math.max(dp[i][j], dp[i -1][j - k * weight[i -1]]+ k * values[i -1]);}}}
System.out.println(dp[n][m]);}}
但是通过观察可以得到:
d
p
[
i
,
j
]
=
m
a
x
(
d
p
[
i
−
1
]
[
j
]
,
d
p
[
i
−
1
]
[
j
−
v
]
+
w
,
d
p
[
i
−
1
]
[
j
−
2
v
]
+
2
w
,
d
p
[
i
−
1
]
[
j
−
3
v
]
+
3
w
,
.
.
.
)
dp[i,j] = max(dp[i-1][j],dp[i-1][j-v]+w,dp[i-1][j-2v]+2w,dp[i-1][j-3v]+3w,...)
dp[i,j]=max(dp[i−1][j],dp[i−1][j−v]+w,dp[i−1][j−2v]+2w,dp[i−1][j−3v]+3w,...)
d
p
[
i
,
j
−
v
]
=
m
a
x
(
d
p
[
i
−
1
]
[
j
−
v
]
,
d
p
[
i
−
1
]
[
j
−
2
v
]
+
w
,
d
p
[
i
−
1
]
[
j
−
3
v
]
+
2
w
,
.
.
.
)
dp[i,j-v]=max(dp[i-1][j-v],dp[i-1][j-2v]+w,dp[i-1][j-3v]+2w,...)
dp[i,j−v]=max(dp[i−1][j−v],dp[i−1][j−2v]+w,dp[i−1][j−3v]+2w,...)
由上两式,可得出如下递推关系:
dp[i][j]=max(dp[i][j-v]+w , dp[i-1][j])
有了上面的关系,那么其实k循环可以不要了,核心代码优化成这样:
for(int i =1; i <= n;++i){for(int j =0; j <= m;++j){
dp[i][j]= dp[i -1][j];if(j >= weight[i -1]){
dp[i][j]= Math.max(dp[i][j], dp[i][j - weight[i -1]]+ values[i -1]);}}}
所以最终的代码简化为:
import java.util.Scanner;publicclassMain{publicstaticvoidmain(String[] args){
Scanner cin =newScanner(System.in);int n = cin.nextInt();int m = cin.nextInt();int[] values =newint[n];int[] weight =newint[n];for(int i =0; i < n; i++){
weight[i]= cin.nextInt();
values[i]= cin.nextInt();}int[] dp =newint[m +1];for(int i =1; i <= n;++i){for(int j = weight[i -1]; j <= m;++j){
dp[j]= Math.max(dp[j], dp[j - weight[i -1]]+ values[i -1]);}}
System.out.println(dp[m]);}}
多重背包
题目传送门🚀
有 N种物品和一个容量是 V 的背包。
第 i 种物品最多有 s 件,每件体积是 vi,价值是 wi。
求解将哪些物品装入背包,可使物品体积总和不超过背包容量,且价值总和最大。
输出最大价值。输入格式
第一行两个整数,N,V,用空格隔开,分别表示物品种数和背包容积。
接下来有 N 行,每行三个整数 vi,wi,si,用空格隔开,分别表示第 i 种物品的体积、价值和数量。
输出格式
输出一个整数,表示最大价值。
数据范围
0<N,V≤100
0<vi,wi,si≤100输入样例
4 5 1 2 3 2 4 1 3 4 3 4 5 2输出样例:
10
方法1、拆分
多重背包问题其本身可以简化为01背包问题,既然给定了每一个物品最大数量,那么可以假设总共有最大数量个物品,就可以将其简化为01背包问题。
import java.util.Scanner;publicclassMain{finalstaticint N =100005;publicstaticvoidmain(String[] args){
Scanner cin =newScanner(System.in);int n = cin.nextInt();int m = cin.nextInt();int cnt =0;int[] values =newint[N];int[] weight =newint[N];while(n-->0){int w = cin.nextInt();int v = cin.nextInt();int num = cin.nextInt();while(num-->0){++cnt;
weight[cnt]= w;
values[cnt]= v;}}// 直接套用 0-1背包板子int[] dp =newint[m +1];for(int i =1; i <= cnt;++i){for(int j = m; j >= weight[i];--j){
dp[j]= Math.max(dp[j], dp[j - weight[i]]+ values[i]);}}
System.out.println(dp[m]);}}
方法2、二进制优化
方法一时间复杂度是
O
(
n
3
)
O(n^3)
O(n3),如果数据量过大就可能导致超时,因此介绍方法2使用**二进制优化算法**。
假设拿取某一个物品的数量为 n ,因为 n 是一个正整数因此一定有其二进制表示形式,假设
n
=
5
n=5
n=5 ,用二进制表示就是 101 ,可以将**二进制的每一位看成一组**,
n
=
5
n = 5
n=5 就相当于拿了两组分别是 100 与 001 ,那么与方法1类似的可以按照组拆分方法,将不同的组当做一个新的物品,最终使用01背包解决。
如果仍然不是很能理解的话,取这样一个例子:要求在一堆苹果选出n个苹果。我们传统的思维是一个一个地去选,选够n个苹果就停止。这样选择的次数就是n次
二进制优化思维就是:现在给出一堆苹果和10个箱子,选出n个苹果。将这一堆苹果分别按照1,2,4,8,16,…512分到10个箱子里,那么由于任何一个数字x ∈[1,1023]对应的二进制位均都可以从这10个箱子里的苹果数量表示出来,这样选择的次数就是 ≤10次 。
同样的,如果一个物品最大可取数量为 10,按照二进制拆分为:
【
1
,
2
,
4
,
3
】
【1,2,4,3】
【1,2,4,3】 ,按照分苹果中的逻辑,
[
1
,
10
]
[1,10]
[1,10] 的任意一个数一定能由一组或多组相加而得来!
利用二进制优化,时间复杂度就从
O
(
n
3
)
O(n^3)
O(n3)降到
O
(
n
2
l
o
g
S
)
O(n^2logS)
O(n2logS)
import java.util.Scanner;publicclassMain{finalstaticint N =100005;publicstaticvoidmain(String[] args){
Scanner cin =newScanner(System.in);int n = cin.nextInt();int m = cin.nextInt();int cnt =0;int[] values =newint[N];int[] weight =newint[N];while(n-->0){int w = cin.nextInt();int v = cin.nextInt();int num = cin.nextInt();// k即是当前组拿取数量for(int k =1; k <= num; k <<=1){
weight[++cnt]= k * w;
values[cnt]= k * v;
num -= k;}// 剩余物品无法继续分组,单独成为一组if(num >0){
weight[++cnt]= num * w;
values[cnt]= num * v;}}
n = cnt;// 套用 01背包模板int[] dp =newint[m +1];for(int i =1; i <= n;++i){for(int j = m; j >= weight[i];--j){
dp[j]= Math.max(dp[j], dp[j - weight[i]]+ values[i]);}}
System.out.println(dp[m]);}}
【蓝桥杯】 算法提高 和谐宿舍2
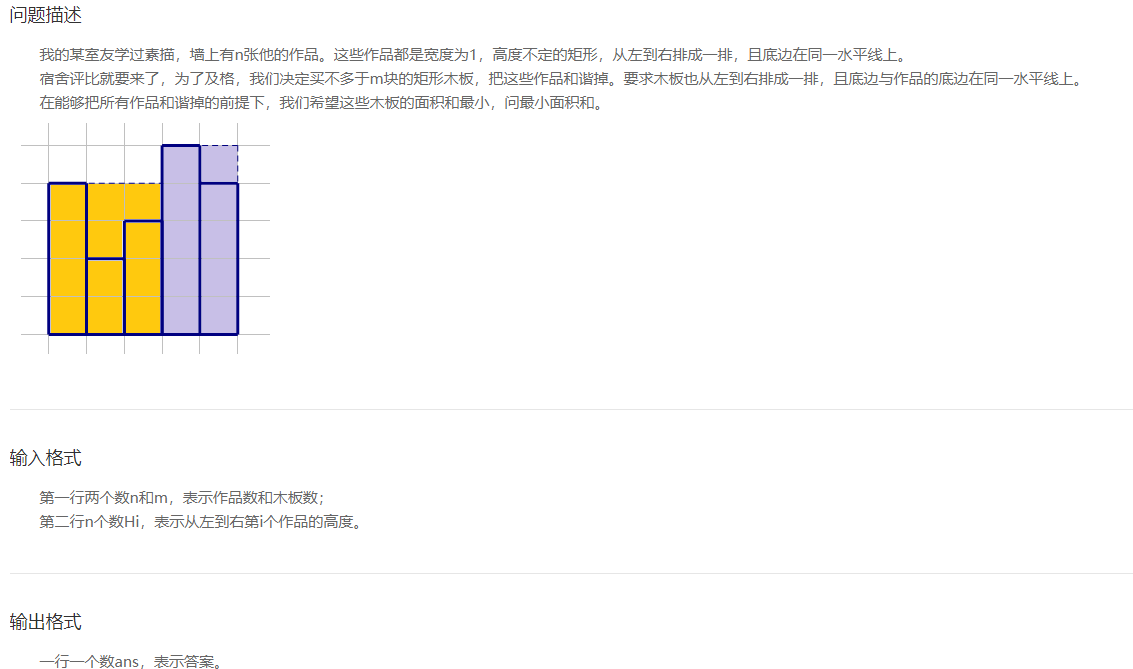

使用动态规划,定义数组
d
p
[
i
]
[
j
]
dp[i][j]
dp[i][j]
d p [ i ] [ j ] dp[i][j] dp[i][j] 存储的数据是前 i i i张素描(包括 i i i本身)在使用 j j j块木板的情况下的最小面积
定义数组
M
a
x
H
e
i
g
h
t
[
i
]
[
j
]
MaxHeight[i][j]
MaxHeight[i][j]
- 存放i到j之间的素描的最大高度
每一个素描均有放一块新的木板、增大原有木板覆盖两种方式,如果增大原有木板,可以选择前面的任意一个组成一个新的木板(for循环遍历最小值),选取的话一定是选择最后结果最小的那一个。
import java.util.Scanner;publicclassMain{publicstaticvoidmain(String[] args){
Scanner cin=newScanner(System.in);int n = cin.nextInt();int m=cin.nextInt();int[][]dp=newint[n+1][m+1];int[][]MaxHeight=newint[n+1][n+1];for(int i=1;i<=n;++i){
MaxHeight[i][i]=cin.nextInt();}for(int i=1;i<=n;++i){for(int j=i+1;j<=n;++j){
MaxHeight[i][j]=Math.max(MaxHeight[i][j-1],MaxHeight[j][j]);}}//背包问题遍历所有素描for(int i=1;i<=n;++i){//初始化
dp[i][1]=MaxHeight[1][i]*i;//遍历所有背包容量,注意j<=ifor(int j=2;j<=m&&j<=i;++j){//为了找最小值,初始化为最大值
dp[i][j]=Integer.MAX_VALUE;//注意遍历时 素描数量应该>=木板数量即:i-k>=j-1 求得k<=i-j+1//这里的k是向前的距离for(int k=1;k<=i-j+1;++k){
dp[i][j]=Math.min(dp[i][j],dp[i-k][j-1]+k*MaxHeight[i-k+1][i]);}}}
System.out.println(dp[n][m]);}}
第二点五个不高兴的小明
题目传送门🚀
问题描述
有一条长为n的走廊,小明站在走廊的一端,每次可以跳过不超过p格,每格都有一个权值wi。
小明要从一端跳到另一端,不能回跳,正好跳t次,请问他跳过的方格的权值和最大是多少?输入格式
输入的第一行包含两个整数n, p, t,表示走廊的长度,小明每次跳跃的最长距离和小明跳的次数。
接下来n个整数,表示走廊每个位置的权值。输出格式
输出一个整数。表示小明跳过的方格的权值和的最大值。
样例输入
8 5 3
3 4 -1 -100 1 8 7 6样例输出
12
数据规模和约定
1<=n, p, t<=1000, -1000<=wi<=1000。
解题步骤可以参考之前的博客:【蓝桥杯冲刺 day23】第二点五个不高兴的小明 — O(n^2)优化思路
🗡 数学
【蓝桥杯省赛真题】螺旋折线
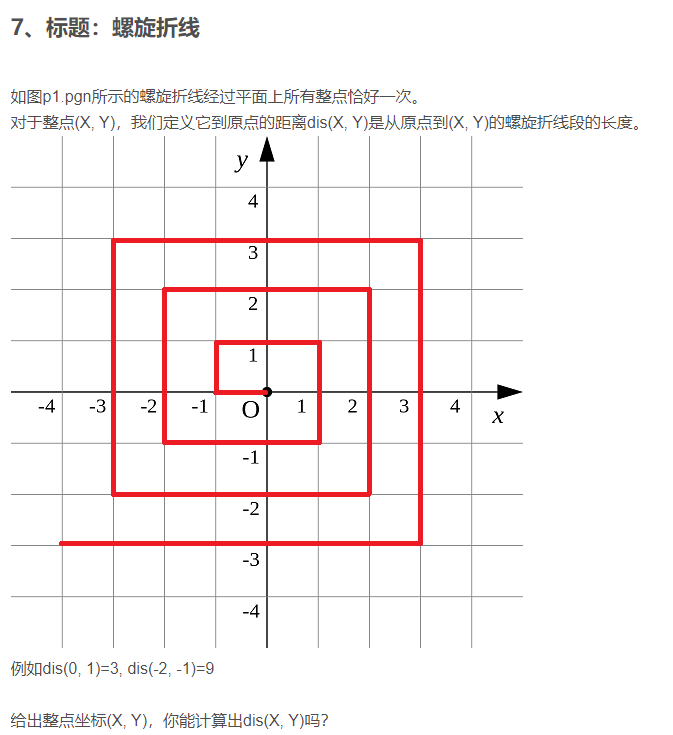

数据量最高位
1
0
9
10^9
109 ,直接搜索或暴力一定会超时,所以这道题使用数学分析的方法求出距离。
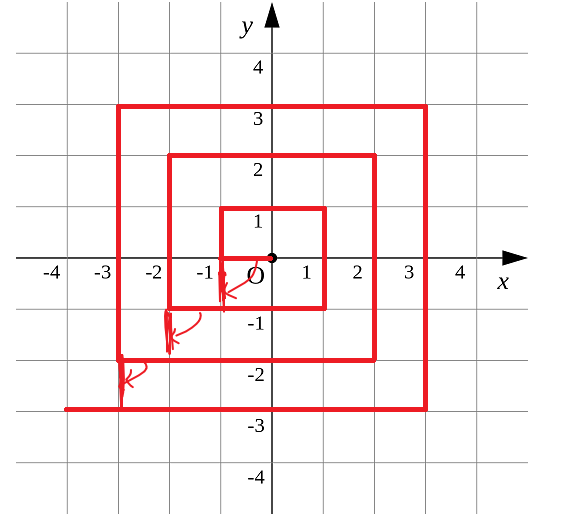
上图中箭头表示将原本位置的线移动到指定位置,于是可以将螺旋线转换为下面这种情况: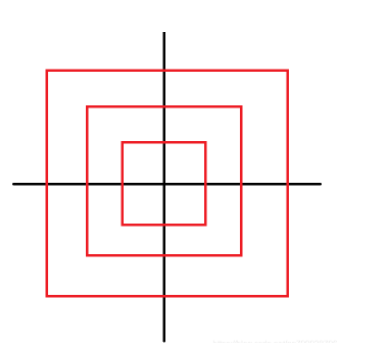
根据分析可以知道,x、y绝对值相比较后得到的最大值就是该坐标所处的正方形层数,最内层为1,那么设该层数为
N
N
N,每一层正方形的开始下标为(-N,-N),那么之前的
N
N
N层正方形的周长就是
4
∗
(
N
−
1
)
∗
N
4*(N-1)*N
4∗(N−1)∗N ,即为
S
u
m
Sum
Sum ,剩下的距离就是该点到该层正方形开始下标的距离,求得后两者相加即可获得答案
import java.util.Scanner;publicclassMain{publicstaticvoidmain(String[] args){
Scanner in =newScanner(System.in);long X = in.nextLong();long Y = in.nextLong();// 判断所在点所在的正方形long n = Math.max(Math.abs(X), Math.abs(Y));// 1. 之前正方形的长度和long Sn =4*(n-1)*n;// 2. 计算点(-n, -n) 到点(X, Y)的距离, 考虑清楚情况long sum =0;long px =-n, py =-n;long d1 = X-px, d2 = Y-py;if(Y > X){
sum +=(d1+d2);}//反绕了一圈else{
sum +=(8*n-d1-d2);}
System.out.println(sum + Sn);}}
【蓝桥杯国赛真题】123
小蓝发现了一个有趣的数列,这个数列的前几项如下:
1, 1, 2, 1, 2, 3, 1, 2, 3, 4, …
小蓝发现,这个数列前 1 项是整数 1,接下来 2 项是整数 1 至 2,接下来3 项是整数 1 至 3,接下来 4 项是整数 1 至 4,依次类推。
小蓝想知道,这个数列中,连续一段的和是多少?输入格式
输入的第一行包含一个整数 T,表示询问的个数。
接下来 T 行,每行包含一组询问,其中第 i 行包含两个整数 li 和 ri,表示询问数列中第 li 个数到第 ri 个数的和。
输出格式
输出 T 行,每行包含一个整数表示对应询问的答案。
样例输入
3
1 1
1 3
5 8
样例输出
1
4
8评测用例规模与约定
对于 10% 的评测用例, 1 ≤ T ≤ 30, 1 ≤ li ≤ ri ≤ 100。
对于 20% 的评测用例, 1 ≤ T ≤ 100, 1 ≤ li ≤ ri ≤ 1000。
对于 40% 的评测用例, 1 ≤ T ≤ 1000, 1 ≤ li ≤ ri ≤ 10 ^ 6。
对于 70% 的评测用例, 1 ≤ T ≤ 10000, 1 ≤ li ≤ ri ≤ 10 ^ 9。
对于 80% 的评测用例, 1 ≤ T ≤ 1000, 1 ≤ li ≤ ri ≤ 10 ^ 12。
对于 90% 的评测用例, 1 ≤ T ≤ 10000, 1 ≤ li ≤ ri ≤ 10 ^ 12。
对于所有评测用例, 1 ≤ T ≤ 100000, 1 ≤ li ≤ ri ≤ 10 ^ 12。
解题思路可参考我之前的博客:【十二届蓝桥杯国赛真题】123 — 时间复杂度O(1)的纯数学解法
🗡 高级数据结构
并查集
标准模板
// 并查集类
class UnionFind {
private:// 保存关系int fa[M];
public:UnionFind(int n){// 初始化,开始是否均指向自己for(int i =1; i <= n;++i){
fa[i]= i;}}intfind(int idx){if(fa[idx]== idx){return idx;}// 改变关系,提高查询速度
fa[idx]=find(fa[idx]);return fa[idx];}voidmerge(int n,int m){int fa1 =find(n);int fa2 =find(m);if(fa1 == fa2){return;}
fa[fa1]= fa2;}};
蓝桥幼儿园
题目传送门🚀
题目描述
蓝桥幼儿园的学生是如此的天真无邪,以至于对他们来说,朋友的朋友就是自己的朋友。小明是蓝桥幼儿园的老师,这天他决定为学生们举办一个交友活动,活动规则如下:
小明会用红绳连接两名学生,被连中的两个学生将成为朋友。
小明想让所有学生都互相成为朋友,但是蓝桥幼儿园的学生实在太多了,他无法用肉眼判断某两个学生是否为朋友。于是他起来了作为编程大师的你,请你帮忙写程序判断某两个学生是否为朋友(默认自己和自己也是朋友)
输入描述
输出描述
对于每个op=2的输入,如果z和y是朋友,则输出一行YES,否则输出一行NO。输入输出样例
输入:5 5
2 1 2
1 1 3
2 1 3
1 2 3
2 1 2
1
2
3
4
5
6
输出:NO
YES
YES
这道题算是并查集的模板题,如果没有学过的同学一定要预先学习一下并查集算法再作答。
本题如果直接使用并查集木板可能会超时,需要将关系图压缩优化一下。如果将关系比喻成一个多叉树,那么多叉树的高度决定了查询关系时的性能。
如果有如下关系:
fa[1]=fa[2]=fa[3]=fa[4]=4
,那么当查询 1 结点的父节点时,需要遍历的次数为3,并且随着层数的增高遍历的次数也会增多,为了优化查找速度,可行的方法是在查询到 1 结点正在的父节点时 4 后,此时直接修改 1 号结点的关系将 1 号结点与 4 号结点绑定:
这样一来,下一次查询 1 号结点的父节点时,需要查询的次数减少为1次,极大地提高了查询性能。希望同学们能记住这种优化方法,只需要简单的一行代码能让性能提升不少!
#include<iostream>#define M 200010
using namespace std;// 定义并查集类
class UnionFind {
private:// 保存关系int fa[M];
public:UnionFind(int n){for(int i =1; i <= n;++i){
fa[i]= i;}}intfind(int idx){if(fa[idx]== idx){return idx;}// 改变关系,提高查询速度
fa[idx]=find(fa[idx]);return fa[idx];}voidmerge(int n,int m){int fa1 =find(n);int fa2 =find(m);if(fa1 == fa2){return;}
fa[fa1]= fa2;}};intmain(){int n, m;
cin >> n >> m;
UnionFind fa(n);for(int i =1; i <= m;++i){int op, s1, s2;
cin >> op >> s1 >> s2;if(op ==1){
fa.merge(s1, s2);}else{int fa1 = fa.find(s1);int fa2 = fa.find(s2);
cout <<(fa1 == fa2 ?"YES":"NO")<< endl;}}return0;}
树状数组
标准模板
publicclassTreeArr{// 树状数组int treeArr[];// 数据范围int n;TreeArr(int n){this.n = n;
treeArr =newint[n +1];}// lowbit 方法intlowbit(int x){return x &-x;}intquery(int x){int ans =0;for(int i = x; i >0; i -=lowbit(i)){
ans += treeArr[i];}return ans;}voidupdate(int x){for(int i = x; i <= n; i +=lowbit(i)){
treeArr[i]+=1;}}}
需要注意:
- 树状数组常用于处理:单点修改、区间查询的问题。
- 树状数组中开始存值的索引位置为1,因此调用
update,query时都需要注意这一点。
第十届蓝桥杯真题 修改数组
题目传送门🚀

该题的解题方法有很多,这里我是用的是树状数组与二分查找,时间复杂度:
O
(
N
∗
l
g
N
∗
l
g
N
)
O(N*lgN*lgN)
O(N∗lgN∗lgN)
最大的数据量为100000,因此可以假象一个数组
arr
存储
1
−
N
1-N
1−N 整数的使用情况,对于数
v
a
l
val
val 加入时,其最终可能确定的值取值范围一定是
[
v
a
l
,
N
]
[val,N]
[val,N] ,既然范围已知,我们可使用二分的方法,定义一个中间值
m
i
d
mid
mid 判断
v
a
l
val
val 的值是否能够为
m
i
d
mid
mid ,如果可以那么缩小范围为:
[
v
a
l
,
m
i
d
]
[val,mid]
[val,mid] ,否则范围为:
[
m
i
d
+
1
,
v
a
l
]
[mid+1,val]
[mid+1,val]。
那么如何判断
m
i
d
mid
mid 值能够作为加入呢?只需要判断区间
[
v
a
l
,
m
i
d
]
[val,mid]
[val,mid]是否全部被使用。如果一个位置
i
i
i被使用那么
a
r
r
[
i
]
arr[i]
arr[i] 的值为1,如果没有被使用那么
a
r
r
[
i
]
arr[i]
arr[i]值为0.
此时判断
[
v
a
l
,
m
i
d
]
[val,mid]
[val,mid]区间全部被使用则可以转换为:
[
v
a
l
,
m
i
d
]
[val,mid]
[val,mid]区间值之和是否为
m
i
d
−
v
a
l
+
1
mid-val+1
mid−val+1。
为了在小于
O
(
N
)
O(N)
O(N)的时间复杂度中获取区间
[
v
a
l
,
m
i
d
]
[val,mid]
[val,mid]之和,使用树状数组获取两侧端点值相减。
#include<iostream>#include<string.h>#include<math.h>#include<vector>#include<set>
using namespace std;#define M 100000int treeArr[M+10];
set<int>s;int n;intlowbit(int x){return x &-x;}intquery(int x){int ans =0;for(int i = x; i >0; i -=lowbit(i)){
ans += treeArr[i];}return ans;}voidupdate(int x){for(int i = x; i <= M; i +=lowbit(i)){
treeArr[i]+=1;}}intcheck(int val){int l, r;
l = val; r = M;// 左端点值固定int query1 =query(val -1);while(l < r){int m =(l + r)/2;// 右端点值int query2 =query(m);int red = query2 - query1;if(red == m - val +1){
l = m +1;}else{
r = m;}}update(l);return l;}intmain(){memset(treeArr,0,sizeof(treeArr));
cin >> n;for(int i =0; i < n;++i){int val;
cin >> val;
cout <<check(val)<<" ";}return0;}
线段树(不常考)
线段树主要处理:区间修改,区间查询问题,在省赛中甚至是国赛中出现的次数极少,因此这里就贴上线段树的模板,感兴趣的朋友可以看看。
标准模板
package artithmetic;publicclassLineSegmentTree{/**
* 原始数据
* */int[]value;/**
* 线段树的数据
* */int[]tree;/**
* 原始数组大小
* */int size;publicLineSegmentTree(int[] val){this.value=val;this.size=val.length;// 初始大小
tree =newint[size <<2];buildTree(0, size -1,1);}protectedvoidputUp(int cur){
tree[cur]= tree[(cur <<1)|1]+ tree[(cur <<1)];}/**
* 描述:生成线段树
*/protectedvoidbuildTree(int l,int r,int cur){if(l == r){
tree[cur]= value[l];return;}int mid =(l + r)>>1;buildTree(l, mid,(cur <<1));buildTree(mid +1, r,(cur <<1)|1);putUp(cur);}/**
* 点修改线段树 pos更新的原数组索引位置,[l,r]表示区间范围,cur表示当前线段树数组中位置,val表示修改值的大小
**/publicvoidupdate(int pos,int l,int r,int cur,int val){if(l == r){
tree[cur]+= val;return;}int mid =(l + r)>>1;if(pos <= mid){update(pos, l, mid,(cur <<1), val);}else{update(pos, mid +1, r,(cur <<1)|1, val);}putUp(cur);}/**
* l,r表示当前处于的区间位置,left,right表示请求的区间,cur表示当前线段树索引
**/publicintquery(int l,int r,int left,int right,int cur){if(l >= left && r <= right){return tree[cur];}int ans =0;int mid =(l + r)>>1;// 左侧数据if(mid >= left){
ans +=query(l, mid, left, right,(cur <<1));}// 右侧数据if(mid < right){
ans +=query(mid +1, r, left, right,(cur <<1)|1);}return ans;}}
如果代码、论述中有任何问题,欢迎大家指出,同时如果有任何疑问,也能够在评论区中留言,大家共同讨论共同进步!
春风得意马蹄疾,一日看尽长安花,秋刀鱼在这里祝愿大家都能够在接下来的比赛中都沉稳发挥、旗开得胜,夺得优异的成绩!

版权归原作者 秋刀鱼与 猫 所有, 如有侵权,请联系我们删除。