
文章目录
搜索
概念及场景
Map 和 Set 是一种专门用来进行搜索的容器或者数据结构,其搜索的效率与其具体的实例化子类有关。以前常见的搜索方式有:
1、直接遍历:时间复杂度O(N),元素如果比较多效率会非常慢
2、二分查找,时间复杂度O(log2 N),但搜索前必须要求序列是有序的
上述搜索比较适合静态类型的查找,即一般不会对区间进行插入和删除操作。
而现实中的查找比如:
1、根据姓名查询考试成绩
2、通讯录,即根据姓名查询联系方式
3、不重复集合,即需要先搜索关键字是否已在集合中
可能在查找时进行一些插入和删除的操作,即动态查找,那上述两种方式就不太适合了。
Map 和 Set 就是一种适合动态查找的集合容器。
模型
一般把搜索的数据称为关键字(Key),和关键字对应的称为值(value),将其称之为 Key - Value的“键值对”,所以模型会有两种:1、纯key 模型 ,2、Key - Value 模型
纯 Key 模型
1、有一个英文字典,快速查找一个单词是否在词典中
2、快速查找某个名字在不在通讯录中
Key - Value模型
1、 统计文件中每个单词的出现次数,统计结果是每个单词都有 与其对应的次数:<单词(Key),单词的出现次数(Value)>
2、梁山好汉的江湖绰号:每个好汉都有自己的江湖绰号(Key 及时雨,Value宋江)
Map 中存储的就是 Key - Value 的“键值对”,Set中只存储了Key。
Map 的使用
Map的官方文档,可以下一个网易有道,翻译一下对着看。
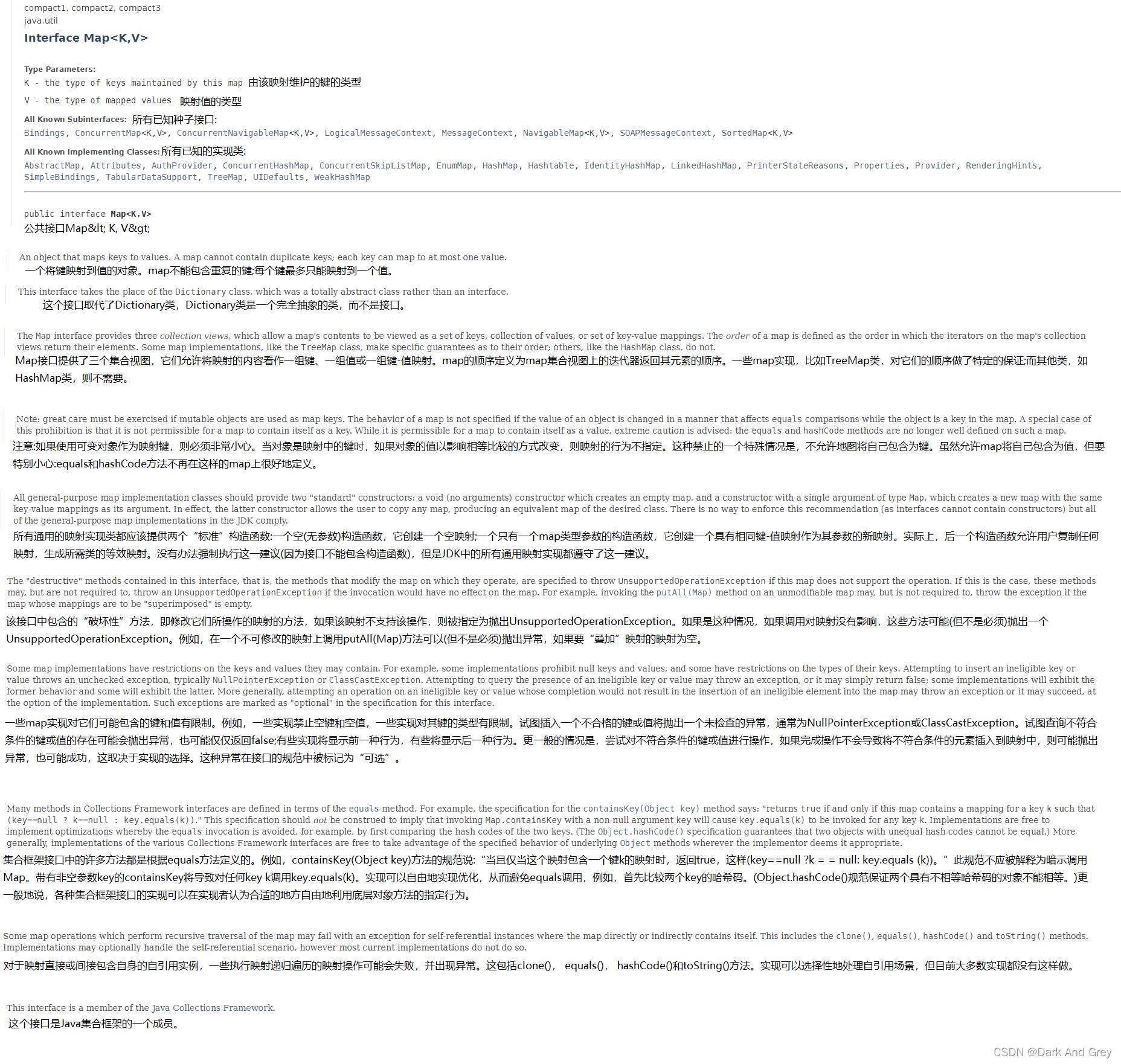
集合框架即背后的数据结构 - 简略概括图
Map 的 说明
Map 是一个接口类,该类没有继承自Collection,该类中存储的是<K,V>结构的“键值对”,并且K一定是唯一的,不能重复。
Map 的常用方法说明
由于 HashM安排 和 TrreMap 没有特别大的区别。几乎是一样的功能。
所以,我们以讲解 HashMap 为主。
方法解释V get(Object key)返回 key 对应的 valueV getOrDefault(Object key, V defaultValue)返回 key 对应的 value,key 不存在,返回默认值V put(K key, V value)设置 key 对应的 valueV remove(Object key)删除 key 对应的映射关系Set keySet()返回所有 key 的不重复集合Collection values()返回所有 value 的可重复集合Set<Map.Entry<K, V>> entrySet()返回所有的 key-value 映射关系boolean containsKey(Object key)判断是否包含 keyboolean containsValue(Object value)判断是否包含 value
实践
put 功能 - 设置 key 对应的 value
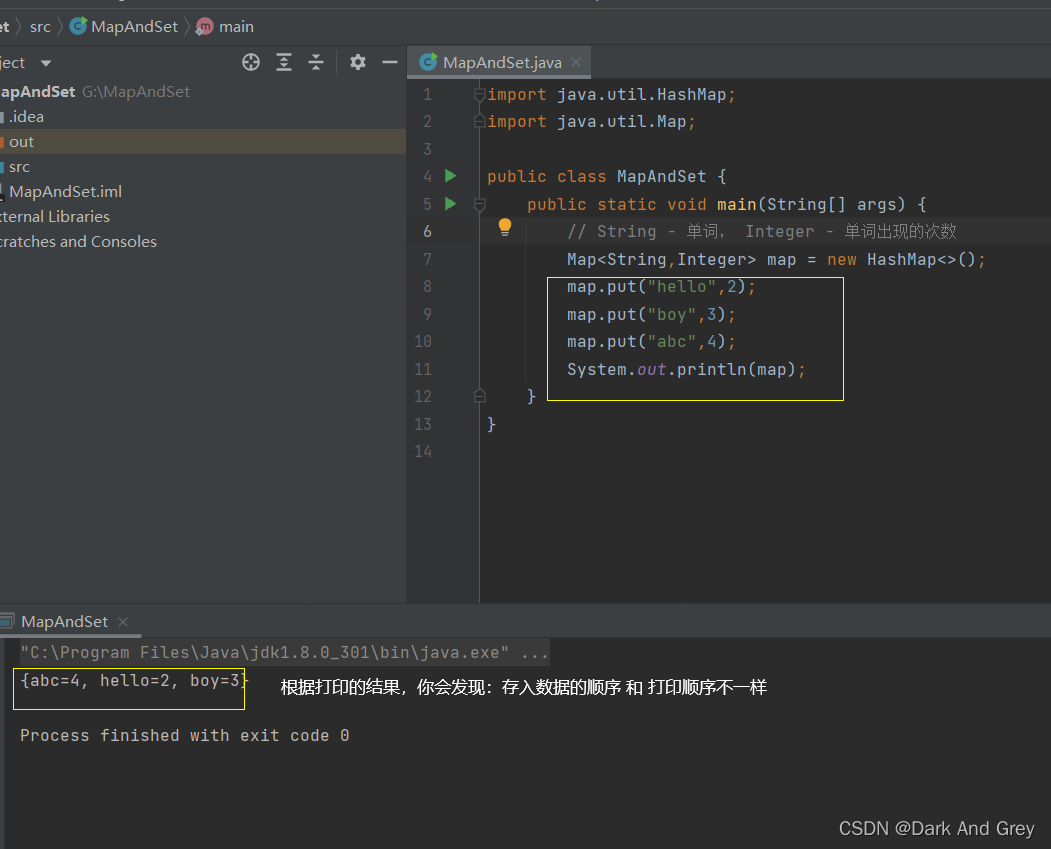
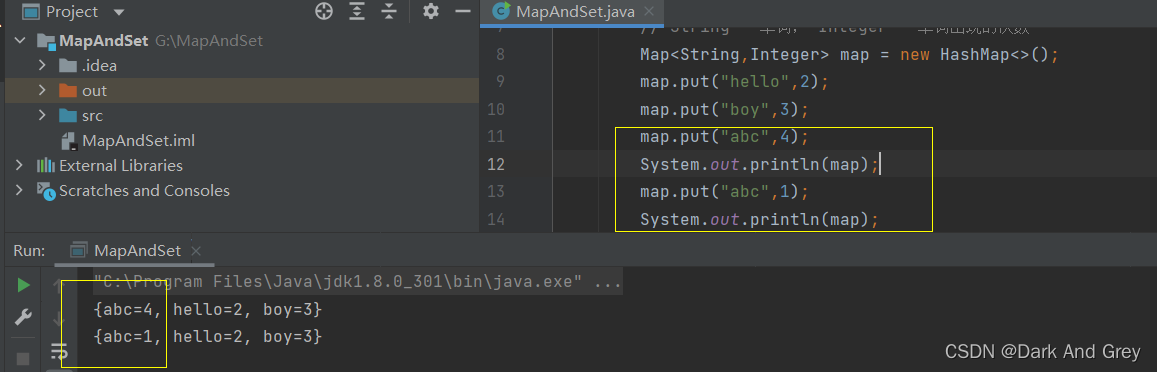
问题就来了!为什么 存入数据的顺序 和 打印数据的顺序 不一样?
这是因为 HashMap 在存储数据的时候,不是按照存储顺序来进行存储。而是根据一个函数来进行存储的。也就是说:具体存储到哪里?是有函数决定的。这个函数就是哈希函数。
所以才会导致 打印的顺序 和 存入的数据的顺序不一样。
细节
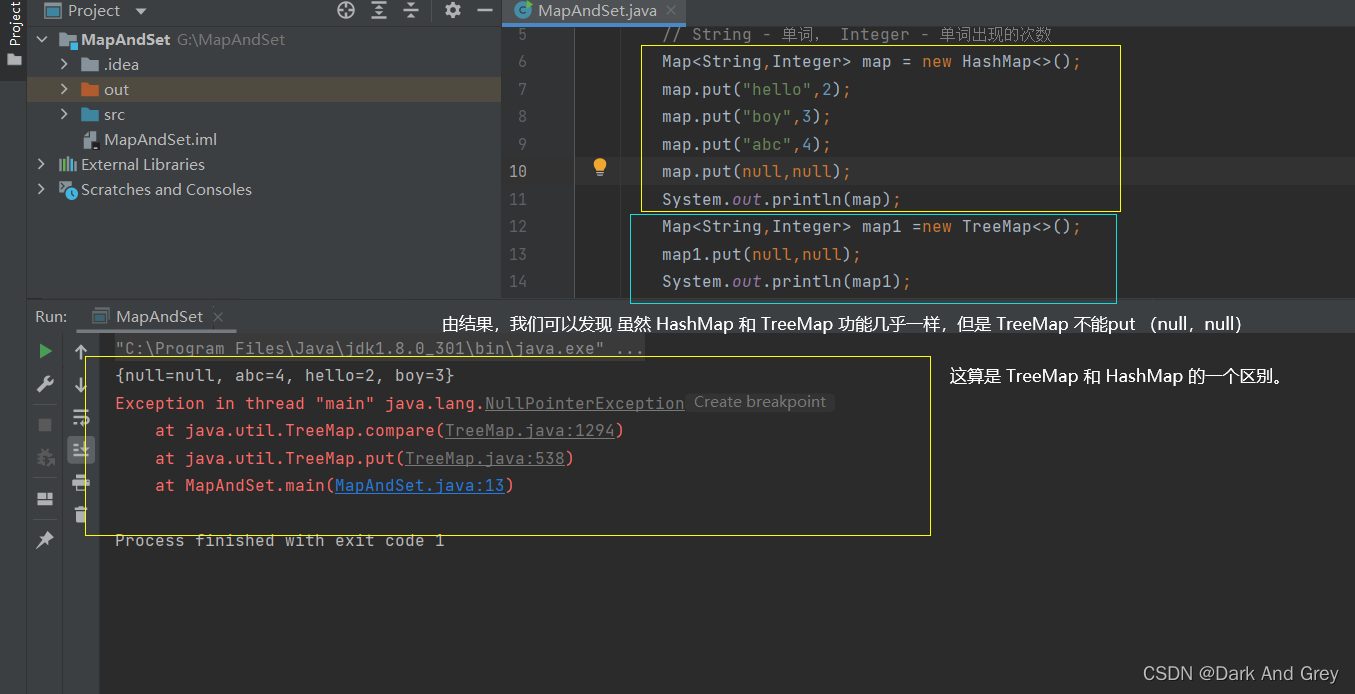
但如果只是 Value 为空的话,就不会出现异常。(也就是说 在TreeMap 存储数据的时候,Key 不能为null)

get 功能 - 返回 key 对应的 value
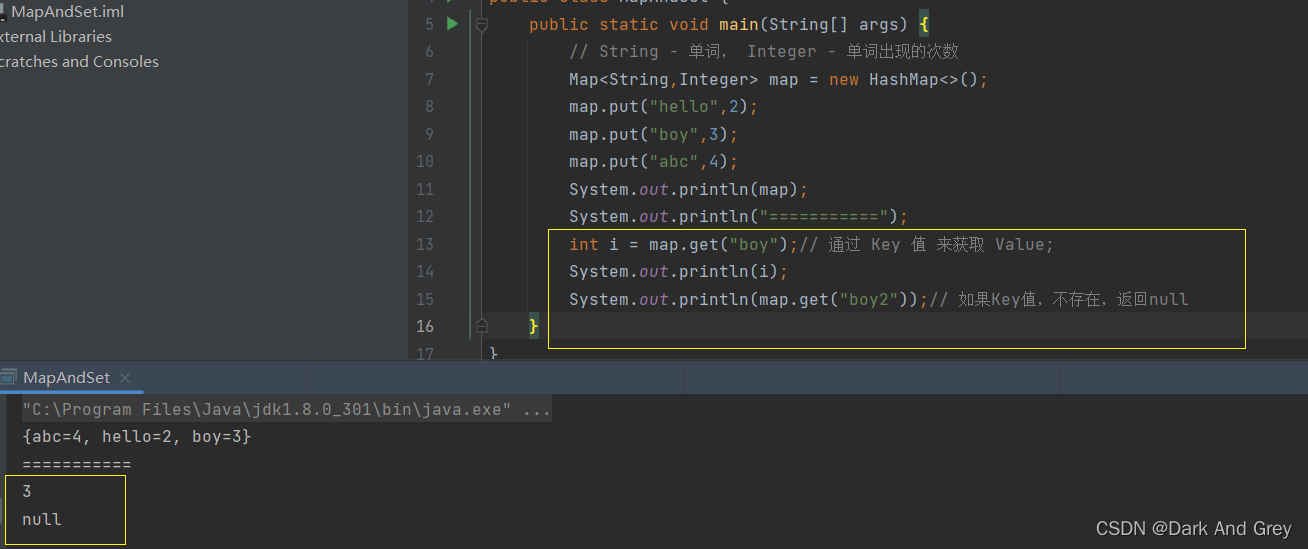
细节
不建议像下面这样去操作。

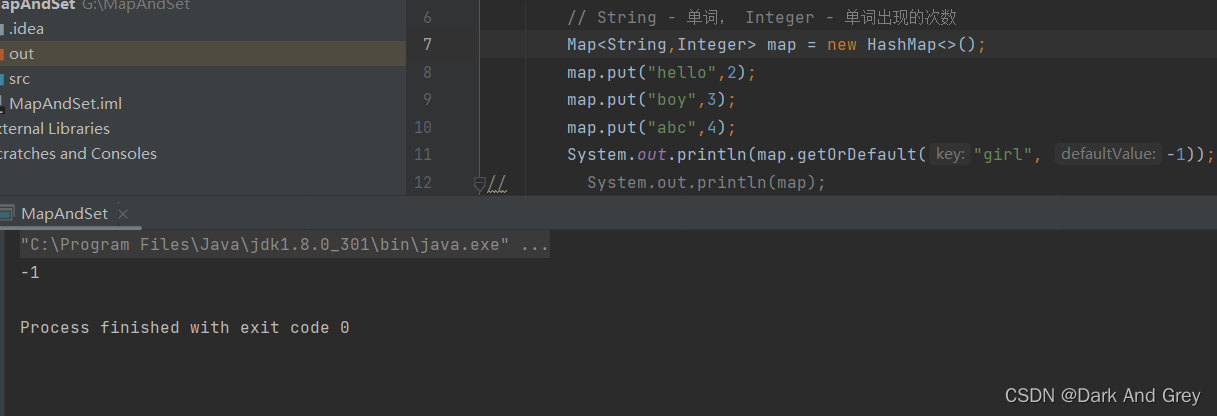
getDefault功能 - 返回 key 对应的 value,key 不存在,返回默认值
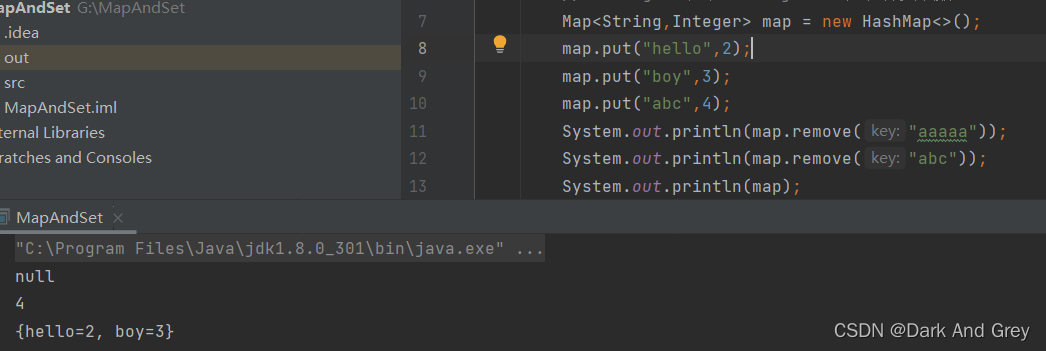
remove功能 - 删除 key 对应的映射关系
Set keySet() - 返回所有 key 的不重复集合
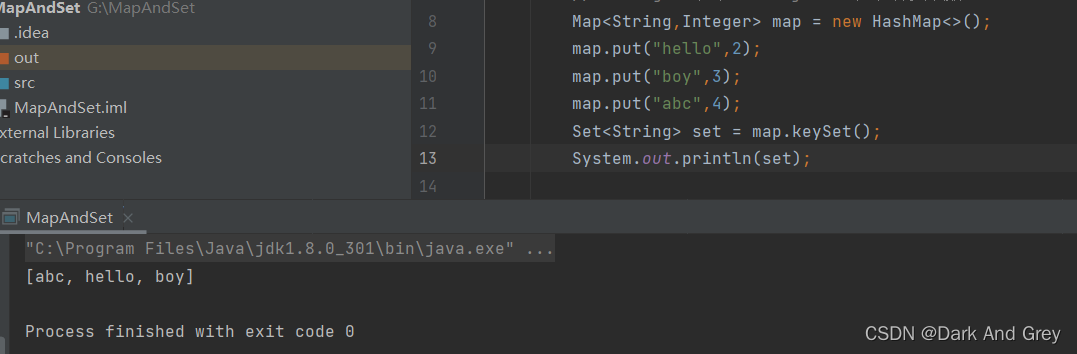
至于为什么说 keySet方法 是返回不重复的集合。
是因为 Set 中 相同的数据只能存储一次。也就说Set里面存储的元素都是不同的。
这个在讲到Set的时候,你们就明白了。
而在 Map 中 存储 相同的元素,也有着自身的特点。
其 value 会根据最后一次的put的value值,进行更新。
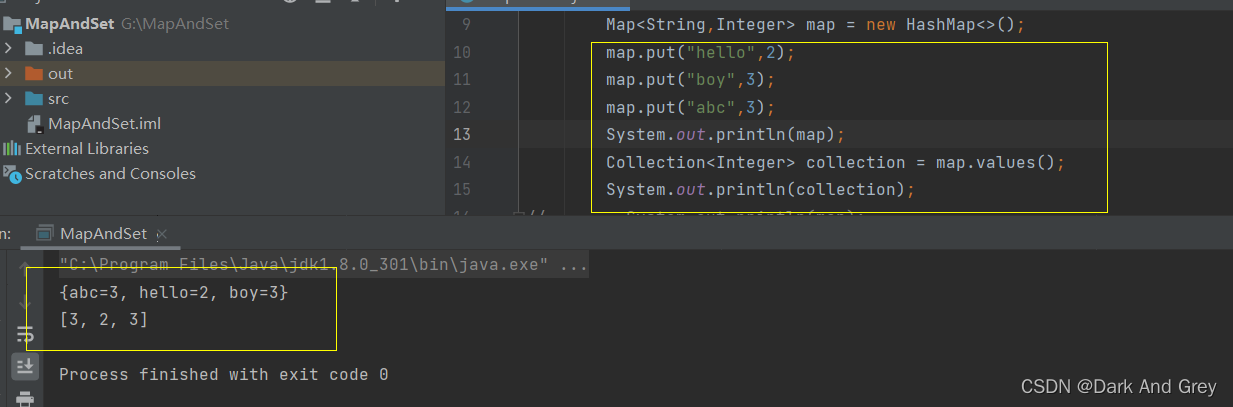
Collection values() - 返回所有 value 的可重复集合
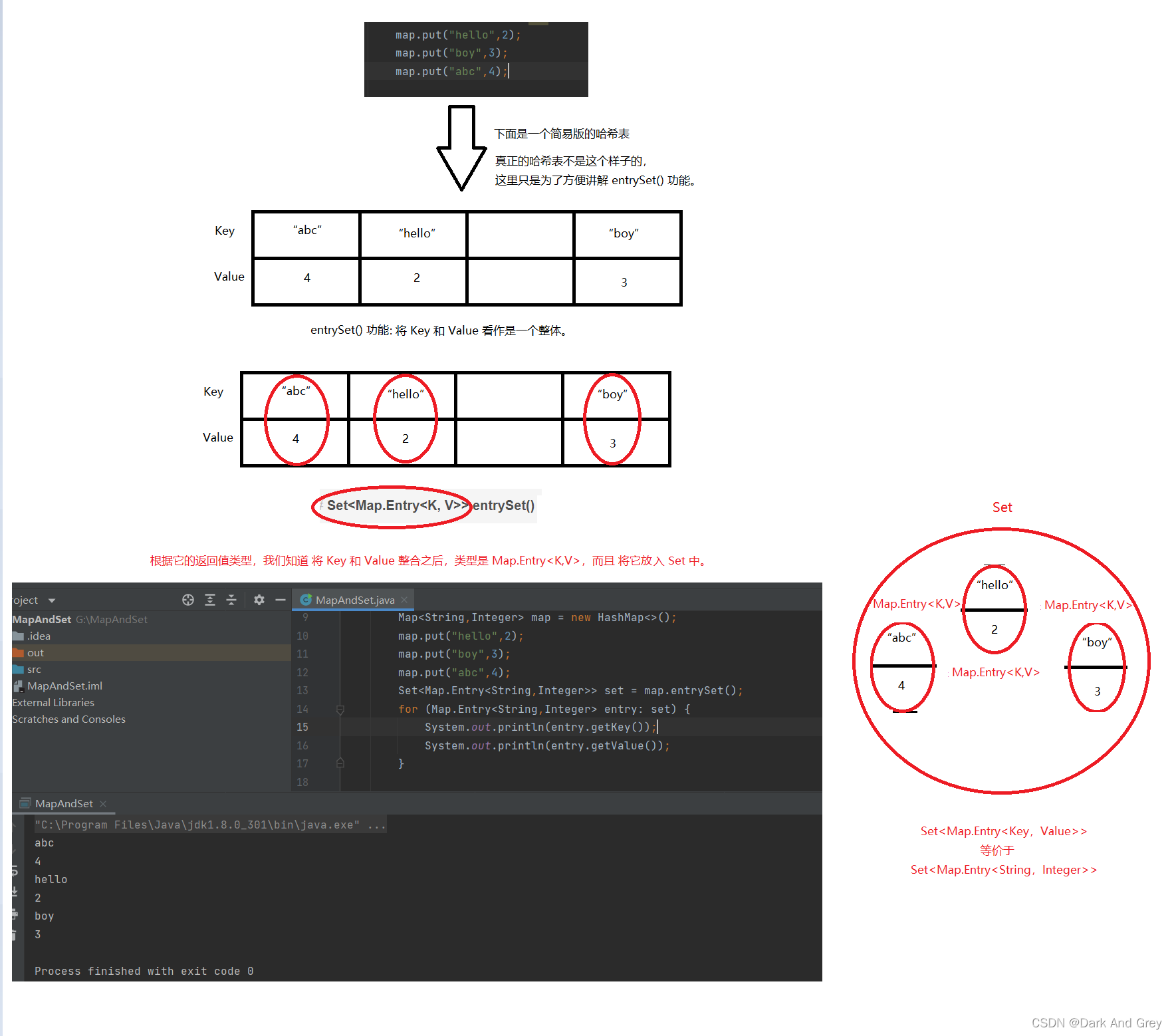
Set < Map.Entry < K , V > > entrySet() - 返回所有的 key-value 映射关系
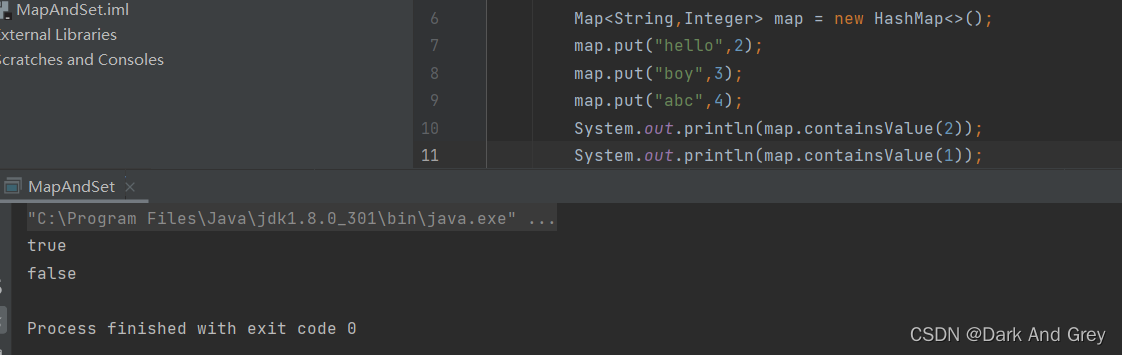
boolean containsKey(Object key) - 判断是否包含 key
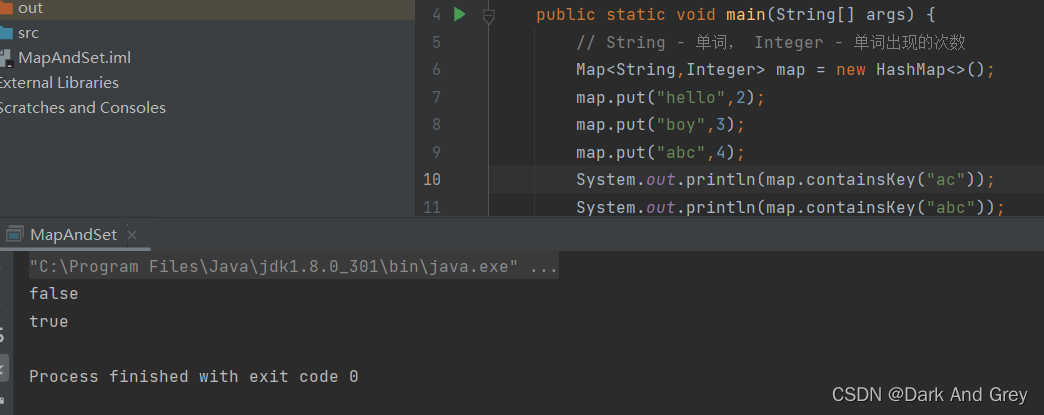
boolean containsValue(Object value) |判断是否包含 value
注意事项
1、Map 是一个接口,不能直接实例化对象,如果实例化对象只能实例化其实现类 TreeMap 和 HashMap。
2、Map中存储“键值对” 的 Key 是唯一的,value 是可重复的。
3、在 TreeMap 中插入“键值对”时,key不能为null,否则就会抛出【NullPointerException异常】,但是Value可以为null。【HashMap 就没有这个问题】
4、Map 中的 Key 可以全部分离出来,存储到 Set中来进行访问(因为 Key 是不能重复)。
5、Map 中的 Value 可以全部分离出来,存储在 Collection 的 任何一个子集合中(value可能有重复)。
6、Map 中 “键值对” 的 Key 不能直接修改,value可以修改,如果要修改 Key,只能先将Key删除掉,然后再来进行重新插入。
7、TreeMap 和 HashMap 的区别
Map 底层结构TreeMapHashMap底层结构红黑树哈希桶插入/删除/查找时间复杂度O(log2 N)O(1)【HashMap的效率非常高】是否有序关于 Key 有序【因为TreeMap 实现了 SortedMap接口,所以放入TreeMap 的数据是一定可以比较,即内部实现了 comparable接口】无序线程安全不安全不安全插入./删除/查找区别Key必须能够比较,否则会抛出ClassCastException 异常自定义类型需要覆写 equals 和 hashCode方法应用场景需要Key 有序场景下Key 是否有序不关心,需要更高的时间性能
Set 的说明
Set 的官方文档
Set 和 Map 主要的不用有两点:Set 继承自 Collection的接口类,Set 中只存储了 Key。
而 Map 是一个单独的接口,Map 中 存储 Key - Value
另外,Set 又称集合【Set 的汉语意思就是 集合】,它具有去重的功能,相同的元素,它只存储一个。

常见方法说明
方法解释boolean add(E e) 添加元素但重复元素不会被添加成功void clear()清空集合boolean contains(Object o)判断 o 是否在集合中Iterator iterator()返回迭代器boolean remove(Object o)删除集合中的 oint size()返回set中元素的个数boolean isEmpty()检测set是否为空,空返回true,否则返回falseObject[] toArray()将set中的元素转换为数组返回boolean containsAll(Collection<?> c)集合c中的元素是否在set中全部存在,是返回true,否则返回falseboolean addAll(Collection<? extendsE> c)将集合c中的元素添加到set中,可以达到去重的效果
实践 - 后面两个不演示,用的少
boolean add(E e) 添加元素 - 但重复元素不会被添加成功
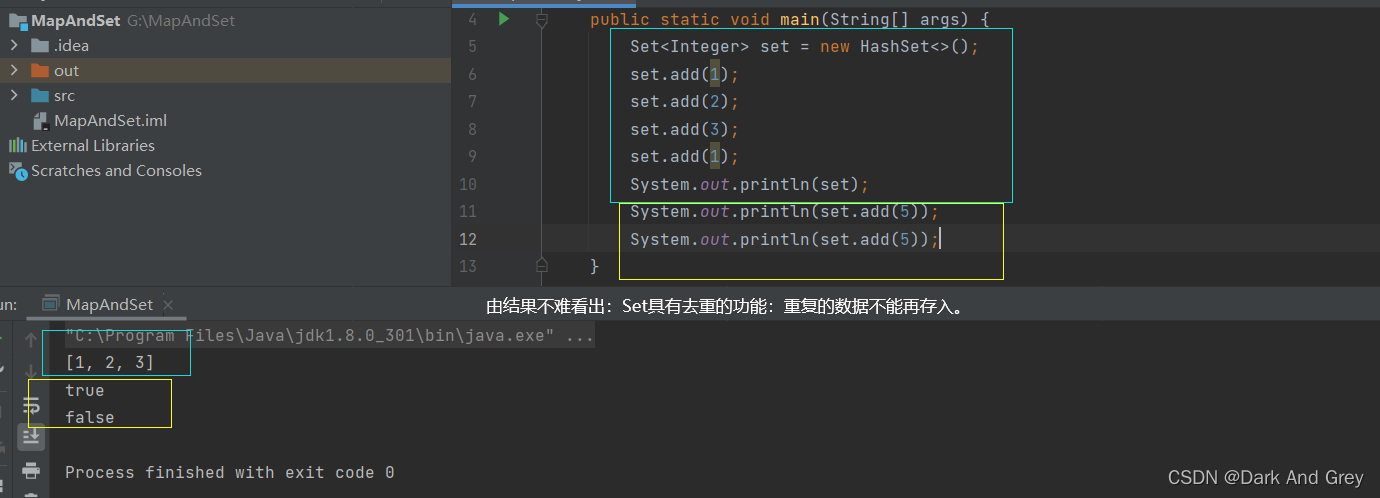
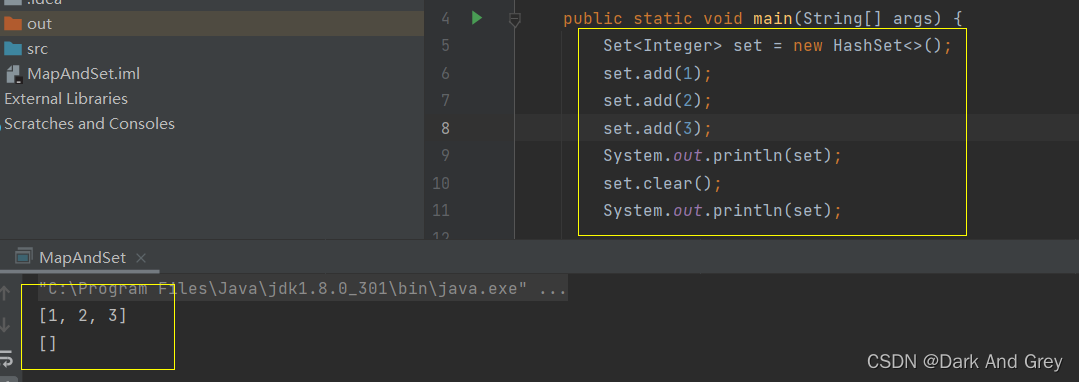
void clear() - 清空集合
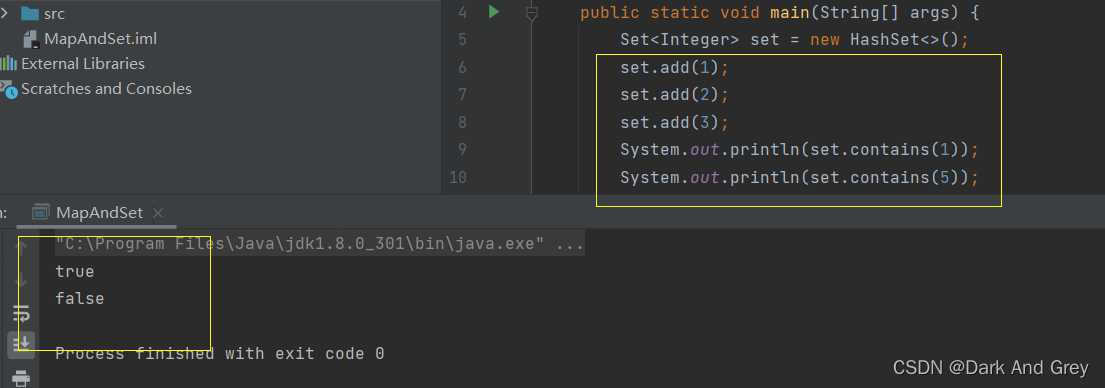
boolean contains(Object o) - 判断 o 是否在集合中
Iterator iterator() - 返回迭代器
可参考 List 接口相关知识 - ArrayList数据结构
此时,我们再来迭代器是如何打印 Set 中的元素。

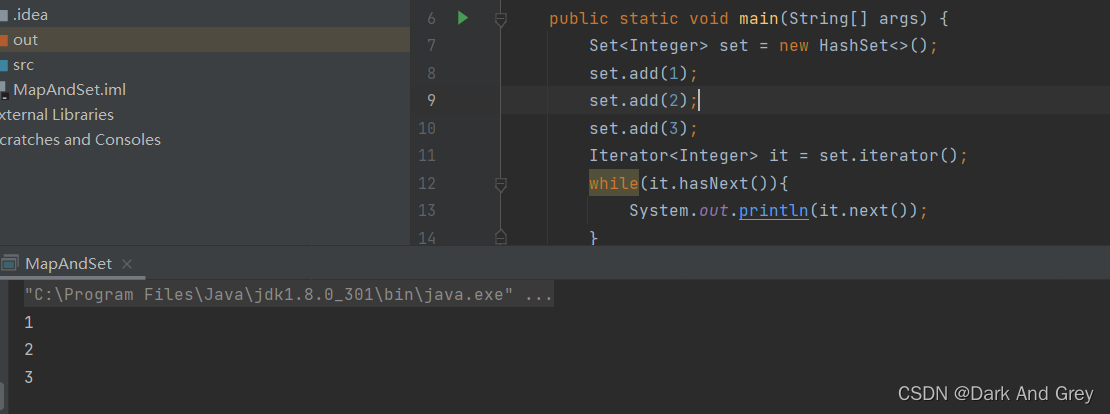
boolean remove(Object o) - 删除集合中的 o
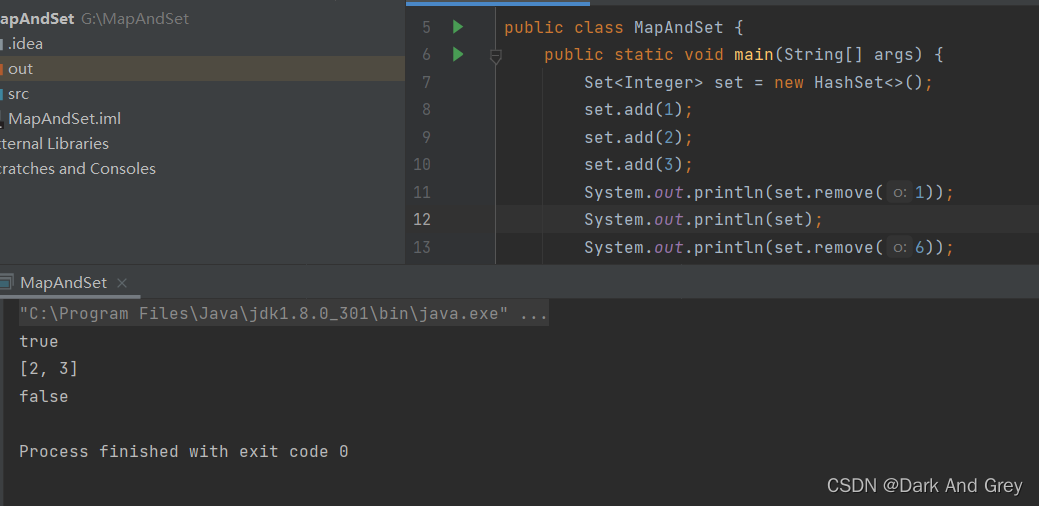
int size() - 返回set中元素的个数

boolean isEmpty() - 检测set是否为空,空返回true,否则返回false

Object[] toArray() - 将set中的元素转换为数组返回
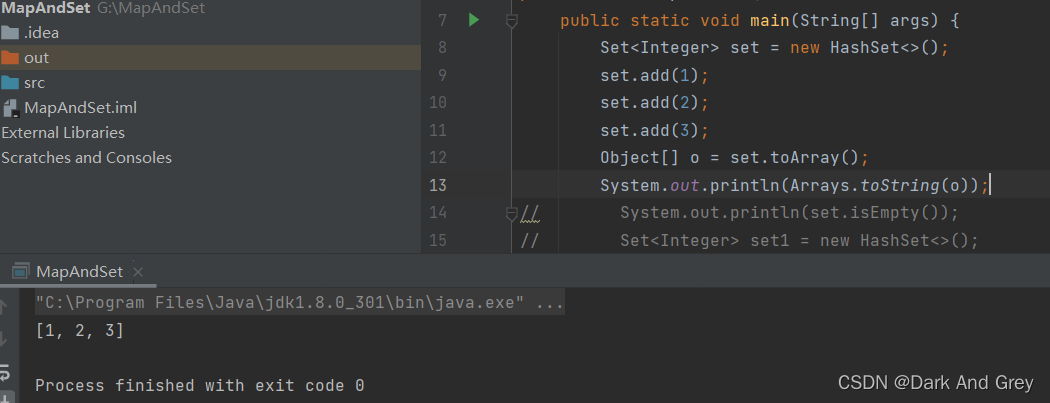
注意事项:
1、Set 是继承自 Collection 的 接口类
2、Set 中 值存储了 Key,并且要求 Key 一定要唯一
3、Set 的底层是 使用 Map 来实现,其使用 Key 与 Object 的 一个默认对象作为 “键值对” 插入到Map中的
4、Set 最大的功能就是集合中的元素进行去重
5、 实现 Set 接口的常用类 有 TreeSet 和 HashSet,还有一个linkedHashSet,LinkedHashSet 是在 HashSet 的基础上 维护了一个双向链表来记录元素的插入次序。
6、Set 中 Key 不能修改,如果要修改,先将原来的删除掉,然后再重新插入。
7、Set 中不能插入 null 的 key
8、TreeSet 和 HashSet 的区别
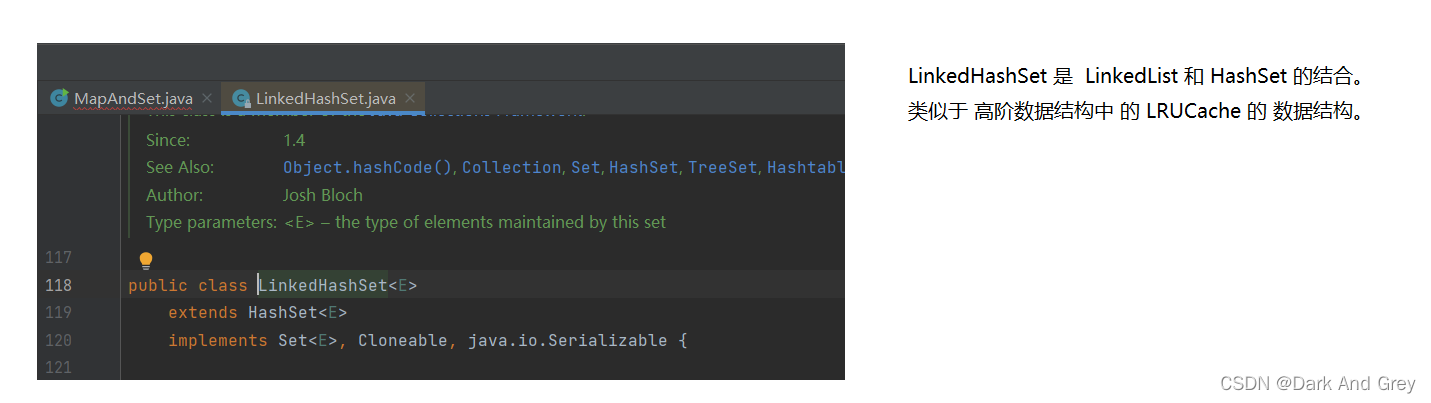
Set底层结构TreeSetHashSet底层结构红黑树哈希桶插入/删除/查找时间O(log2 N)O(1)是否有序关于Key有序不一定有序线程安全不安全不安全插入/删除/查找区别按照红黑树的特性来进行插入和删除1. 先计算key哈希地址 2. 然后进行插入和删除比较与覆写key必须能够比较,否则会抛出ClassCastException异常自定义类型需要覆写equals和hashCode方法应用场景需要Key有序场景下Key是否有序不关心,需要更高的时间性能
面试题练习
LeetCode - 136. 只出现一次的数字
解题思维一:HashSet - 这个思维不适合这题,主要锻炼对 HashSet的掌握。
将所有数据存储 HashSet 中,根据 Set 的 特性,我们明白 Set 具有去重的功能。
所以,我们不能一股脑全部将数据存入,需要作出判断。
思路:在存入数据的时候,去判断存入的数据,在Set 中 是否存在,如果存在,则将该数据删除。
不存在就存入。
【注意题干!最多就两个相同数据】
取出的时候,只需要遍历数组,通过 contains 方法,判断是否包含元素 Key。找到了就返回 Key。
如果没有找到那个只出现一次的 Key,就返回 -1。
代码如下
classSolution{publicintsingleNumber(int[] nums){Set<Integer> set =newHashSet<>();for(int i : nums){if(set.contains(i)){
set.remove(i);}else{
set.add(i);}}int result =0;for(int i : nums){if( set.contains(i)){
result = i;}}return result;}}

解题思维二:HashMap - 【key 为 元素, Value 为 出现次数】
将数据全部存入 HashMap 中,并在存入的过程中判断该元素 在HashMap 中是否存在。
如果存在,说明它已经有一个了【value = 1】,即我们需要在此基础上加上1。反之,如果 HashMap中不存在该元素,返回的Value 为 null,此时就是第一次存入,将 对应 Key - Value 存入。
取出的时候,只需要遍历数组,通过 get 方法,返回其 Value 值,如果等于1,就返回 对应 Key。
如果没有找到那个只出现一次的 Key,就返回 -1。
代码如下
classSolution{publicintsingleNumber(int[] nums){Map<Integer,Integer> map =newHashMap<>();for(int i : nums){Integer count = map.get(i);
count = count ==null?1:++count;
map.put(i, count);}for(int i : nums){Integer count = map.get(i);if(count ==1){return i;}}return-1;}}

解题思维二: 异或
利用异或的特性: 相同为零,相异为1。
而题目说: 数组中只有一个出现一次的元素,其它都是两次。也就是说 一旦进行异或,这些出现2次的元素最终异或的结果为 零,而 只出现一次的元素 与 零进行异或,其结果还是 只出现一次的元素。
所以,我们要做的就是将数组的所有元素进行异或,其结果就是 只出现一次的元素。
代码如下
classSolution{publicintsingleNumber(int[] nums){int result = nums[0];for(int i =1;i < nums.length;i++){
result ^= nums[i];}return result;}}
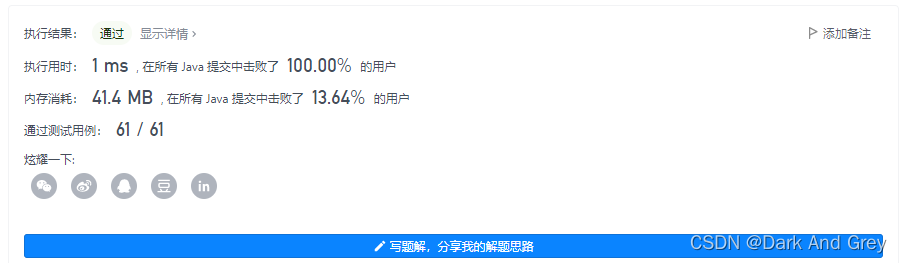
LeetCode - 138. 复制带随机指针的链表
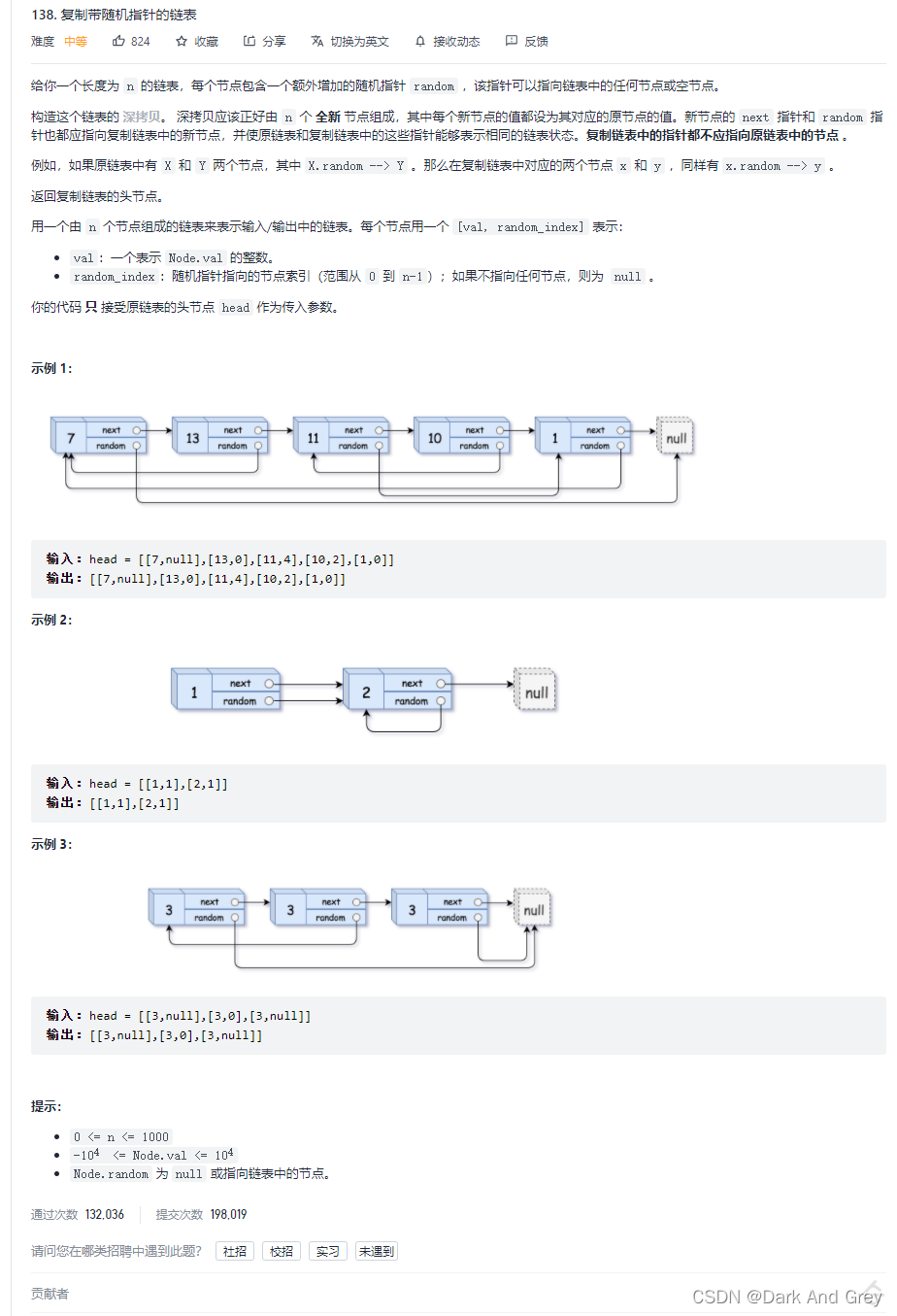
思维一 : 叠代实现
你们可以直接看我这篇博客复制带随机指针的链表 - Java - 迭代实现
思维二 : HashMap
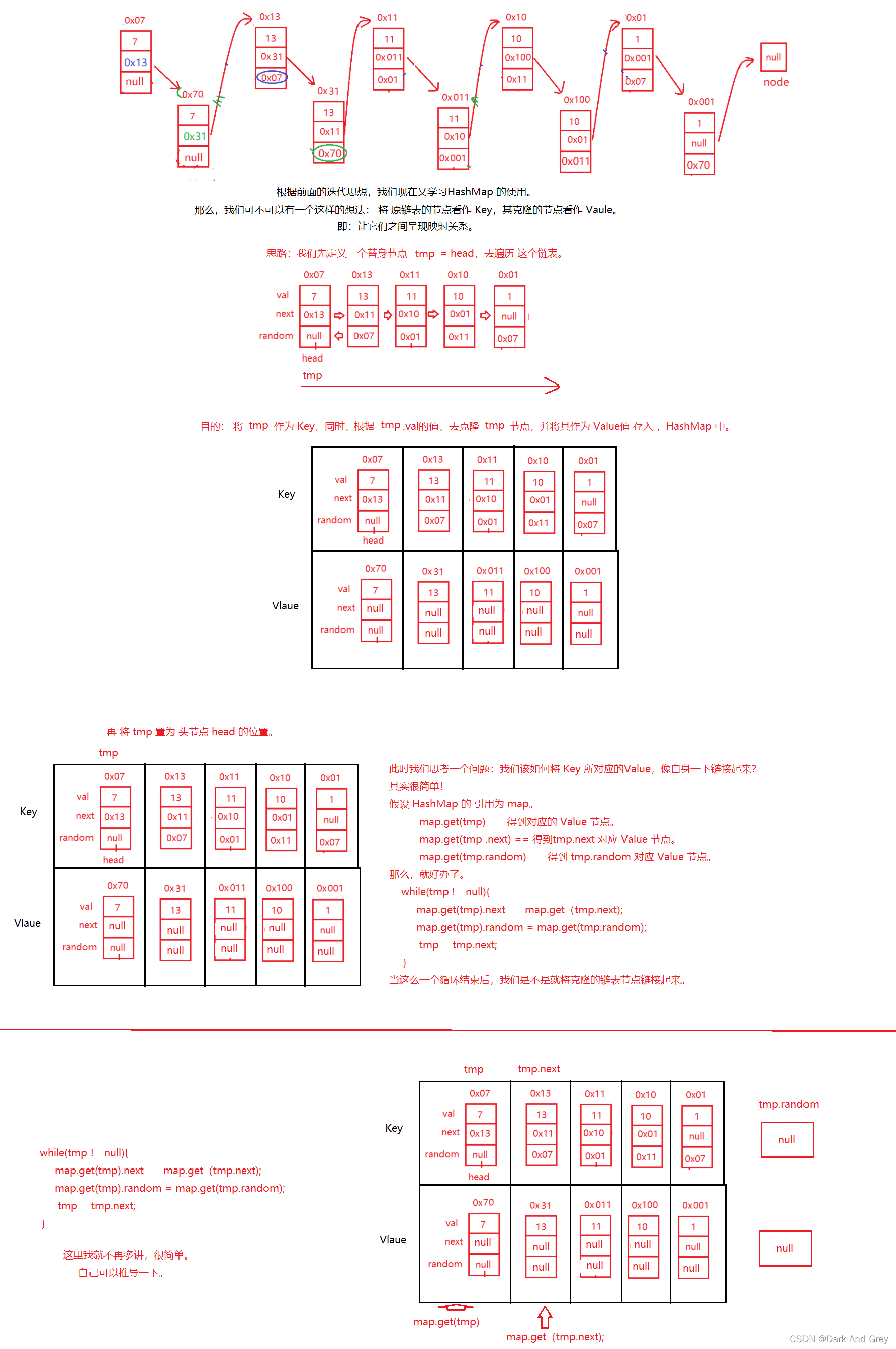
代码如下
classSolution{publicNodecopyRandomList(Node head){Map<Node,Node> map =newHashMap<>();Node tmp = head;while(tmp !=null){Node node =newNode(tmp.val);
map.put(tmp,node);
tmp = tmp.next;}
tmp = head;while(tmp !=null){
map.get(tmp).next = map.get(tmp.next);
map.get(tmp).random = map.get(tmp.random);
tmp = tmp.next;}return map.get(head);}}

LeetCode - 771. 宝石与石头

解题思维一 :HashSet
利用HashSet的去重机制,去记录 jewels 字符串中的 “宝石类型”/ 字符。
至于为什么用HashSet:是因为我们不需要去记录每个类型宝石的对应的个数。
只需要去统计宝石的总个数。
后面,创建一个整形变量result去记录宝石的个数,只需要去 遍历stones字符串,利用 HashSet 的 contains 方法去判断 stones 字符串里的 字符 是在存在HashSet 中,如果存在就加一。最终返回累加结果。
代码如下
// 时间复杂度:O(m+n),其中m是字符串jewels 的长度,n 是字符串stones 的长度。// 空间复杂度:O(m),其中 m 是字符串jewels 的长度。使用哈希集合存储字符串jewels 中的字符个数。classSolution{publicintnumJewelsInStones(String jewels,String stones){Set<Character> set =newHashSet<>();for(int i =0;i < jewels.length();i++){
set.add(jewels.charAt(i));}int result =0;for(int i =0;i < stones.length();i++){if(set.contains(stones.charAt(i))){
result++;}}return result;}}
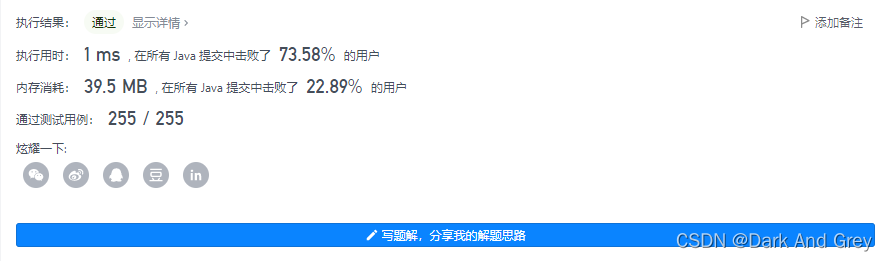
解题思维二 :暴力
双重循环:外层 遍历 jewels,内层遍历 stones。
思路:先定义一个整形变量 result ,每拿到一个 jewels的字符,就到 stones 去里看看有没有“符合条件的宝石”。
有 : result++。
最后返回累加的结果。
代码如下
//时间复杂度:O(mn),其中 m 是字符串 jewels 的长度,n 是字符串stones 的长度。// 空间复杂度:O(1)。只需要维护常量的额外空间classSolution{publicintnumJewelsInStones(String jewels,String stones){int result =0;for(int i =0;i < jewels.length();i++){char ch = jewels.charAt(i);for(int j =0;j < stones.length();j++){if(stones.charAt(j)== ch){
result++;}}}return result;}}
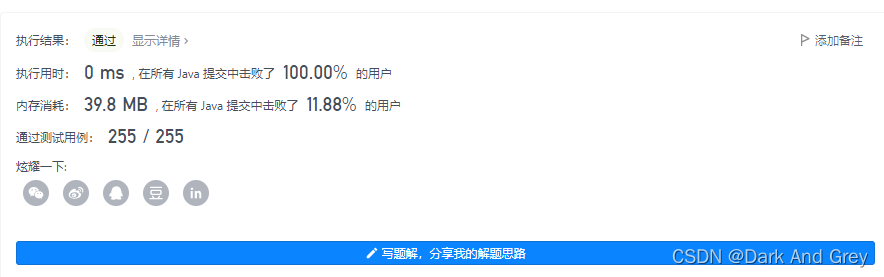
牛客网 - 旧键盘 (20)
解题思维 : HashSet
为了方便大家理解,我将输入的数据整理一下。
我们的思路:还是利用HashSet 去做。


代码如下
importjava.util.*;// 导包publicclassMain{publicstaticvoidfunction(String strExpect,String strActtal){Set<Character> setA =newHashSet<>();// strActtal 先转大写,再转为数组for(char ch : strActtal.toUpperCase().toCharArray()){
setA.add(ch);}Set<Character> setP =newHashSet<>();// strExpect 先转大写,再转为数组for(char ch : strExpect.toUpperCase().toCharArray()){if(!setA.contains(ch)&&!setP.contains(ch)){System.out.print(ch);
setP.add(ch);}}}publicstaticvoidmain(String[] args){// 循环输入Scanner sc =newScanner(System.in);while(sc.hasNextLine()){String strExpect = sc.nextLine();String strActtal = sc.nextLine();function(strExpect,strActtal);}
sc.close();// 资源回收}}

LeetCode - 692. 前K个高频单词

题目分析
看到上面框选的文字,我们脑中的第一个想法:这涉及到 TopK - 问题。
既然是TopK 问题,再加上题目要求返回的是 前k个出现次数最多额单词。
那么,我们就需要建立一个 小根堆。
但这不是难点,难点下面图所框选的。
下面我们就分析一下这两个条件。
下面,我们一个个来解决问题。 先来解决第一个问题:返回的答案应该按单词出现频率由高到低排序


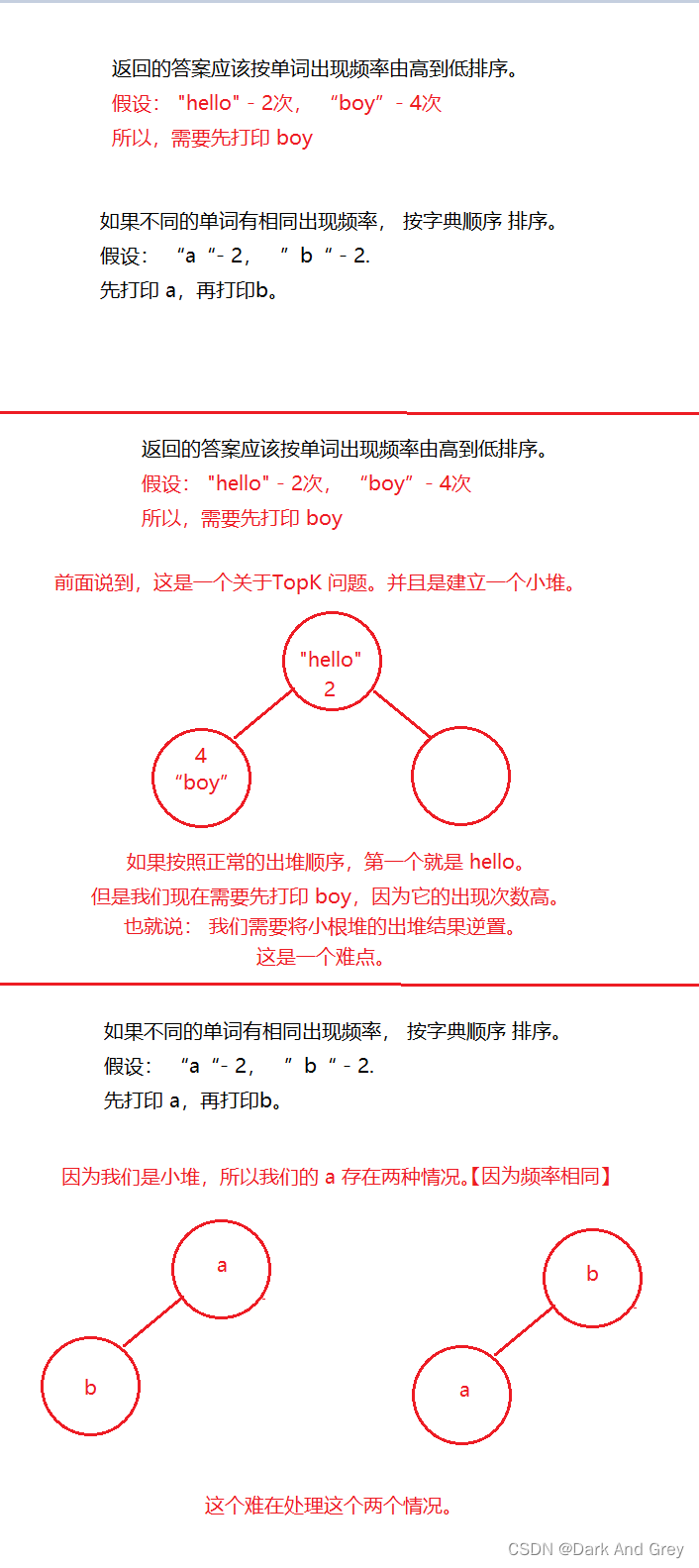
importjava.util.*;publicclassManuscript{publicstaticList<String>topKFrequent(String[] words,int k){// 1、 统计 每个单词的出现的次数 》》 mapHashMap<String,Integer> map =newHashMap<>();for(String s : words){if(map.get(s)==null){
map.put(s,1);}else{int val = map.get(s);
map.put(s,val+1);}}// 第二步 建立一个 大小为 K 的小根堆。【Key - word,Value - 出现次数】// 利用 entrySet 方法,将 Key - Value 结合。看作一个整体PriorityQueue<Map.Entry<String,Integer>> minHeap =newPriorityQueue<>(k,newComparator<Map.Entry<String,Integer>>(){@Overridepublicintcompare(Map.Entry<String,Integer> o1,Map.Entry<String,Integer> o2){return o1.getValue()- o2.getValue();// 以 出现次数 大小 为比较规则。}});// 遍历map,建堆。for(Map.Entry<String,Integer> entry:map.entrySet()){// 先放入 K 个 元素。if(minHeap.size()< k){
minHeap.offer(entry);}else{// 说明堆中 已经放满了 K 个元素,接下里需要看堆顶元素的数据 和 当前的数据的大小关系Map.Entry<String,Integer> top = minHeap.peek();//判断频率是否相同,如果相同,比较单词的大小,单词ASCII小 的 入队。// 因为题目要求:如果不同的单词有相同出现频率, 按字典顺序 排序// a ~ z ASCII码:97 ~ 122if(entry.getValue().compareTo(top.getValue())==0){if(top.getKey().compareTo(entry.getKey())>0){
minHeap.poll();
minHeap.offer(entry);}}else{// 出现频率高:入堆。if(entry.getValue().compareTo(top.getValue())>0){
minHeap.poll();
minHeap.offer(entry);}}}}System.out.println(minHeap);// 返回值类型 创建List<String> ret =newArrayList<>();for(int i =0;i < k;i++){Map.Entry<String,Integer> top = minHeap.poll();
ret.add(top.getKey());}// 反转/ 逆置Collections.reverse(ret);return ret;}publicstaticvoidmain(String[] args){String[] worlds ={"the","day","is","sunny","the","the","the","sunny","is","is"};List<String> list =topKFrequent(worlds,4);System.out.println(list);}}

但是,还没完。还有一个点没有解决 : 就是在前 K个出现次数最多的单词里,存在两个出现次数一样的不同单词。需要按照字母表顺序排序排列。
就比如,我们代入示例1的结果。
这个问题出在哪里呢?就在下图的代码位置
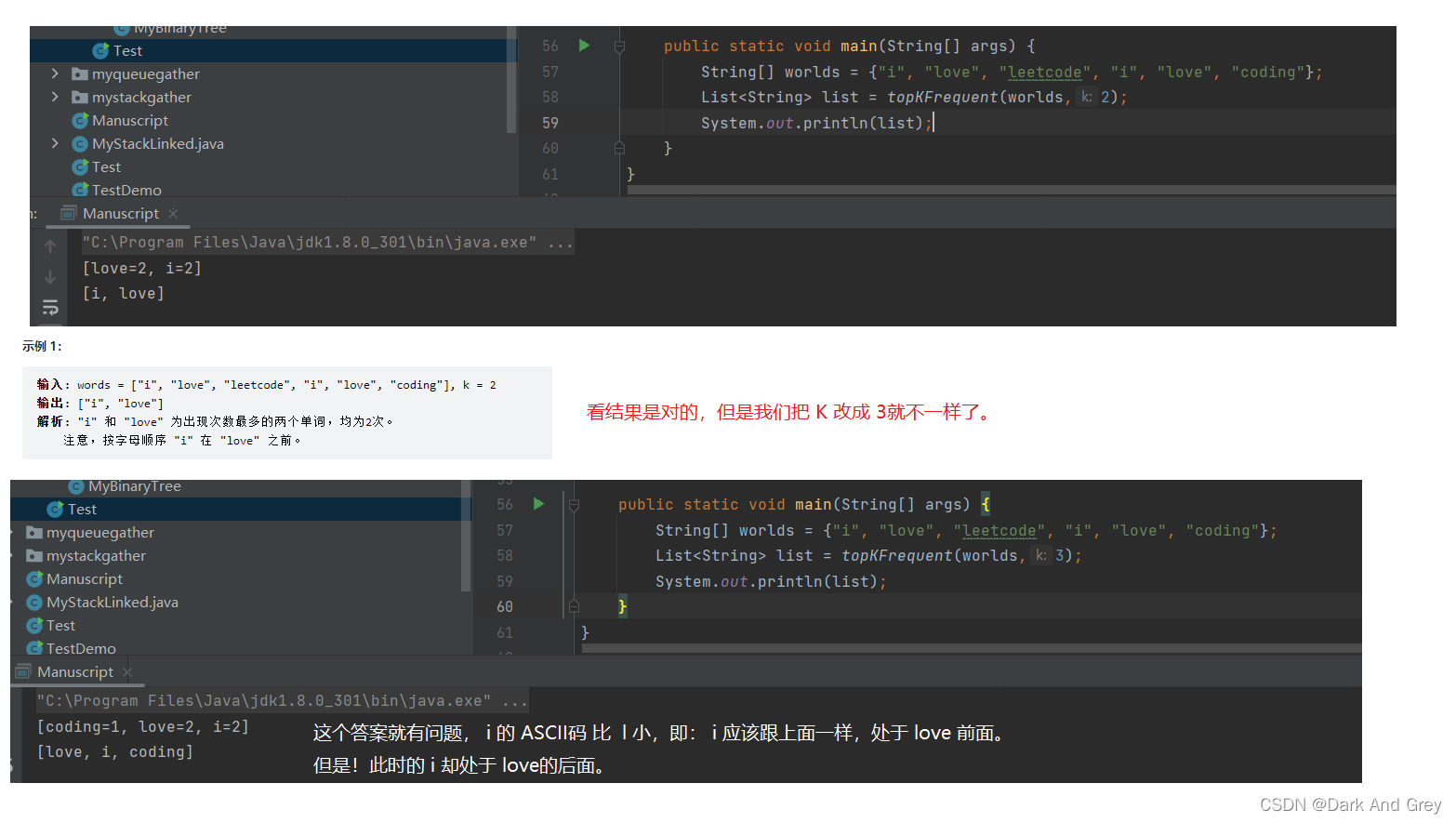
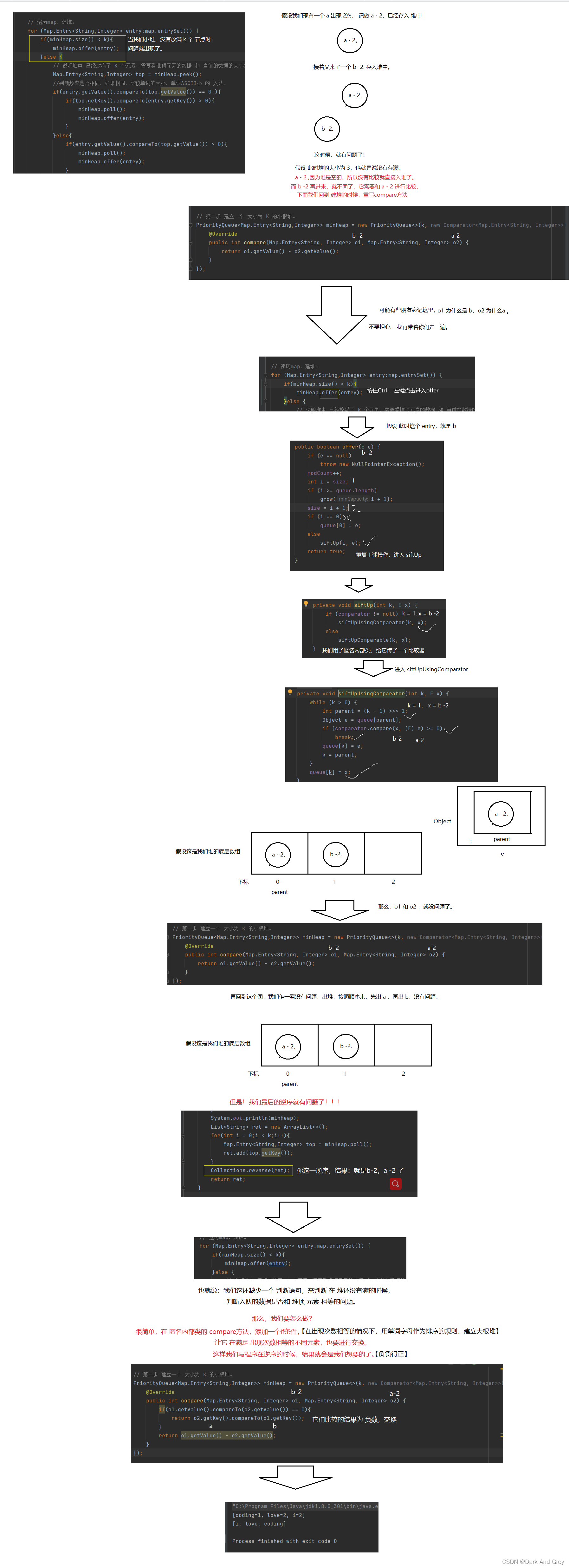
代码如下
publicclassManuscript{publicList<String>topKFrequent(String[] words,int k){// 1、 统计 每个单词的出现的次数 》》 mapHashMap<String,Integer> map =newHashMap<>();for(String s : words){if(map.get(s)==null){
map.put(s,1);}else{int val = map.get(s);
map.put(s,val+1);}}// 第二步 建立一个 大小为 K 的小根堆。PriorityQueue<Map.Entry<String,Integer>> minHeap =newPriorityQueue<>(k,newComparator<Map.Entry<String,Integer>>(){@Overridepublicintcompare(Map.Entry<String,Integer> o1,Map.Entry<String,Integer> o2){if(o1.getValue().compareTo(o2.getValue())==0){return o2.getKey().compareTo(o1.getKey());}return o1.getValue()- o2.getValue();}});// 遍历map,建堆。for(Map.Entry<String,Integer> entry:map.entrySet()){if(minHeap.size()< k){
minHeap.offer(entry);}else{// 说明堆中 已经放满了 K 个元素,需要看堆顶元素的数据 和 当前的数据的大小关系Map.Entry<String,Integer> top = minHeap.peek();//判断频率是否相同,如果相同,比较单词的大小,单词ASCII小 的 入队。if(entry.getValue().compareTo(top.getValue())==0){if(top.getKey().compareTo(entry.getKey())>0){
minHeap.poll();
minHeap.offer(entry);}}else{if(entry.getValue().compareTo(top.getValue())>0){
minHeap.poll();
minHeap.offer(entry);}}}}List<String> ret =newArrayList<>();for(int i =0;i < k;i++){Map.Entry<String,Integer> top = minHeap.poll();
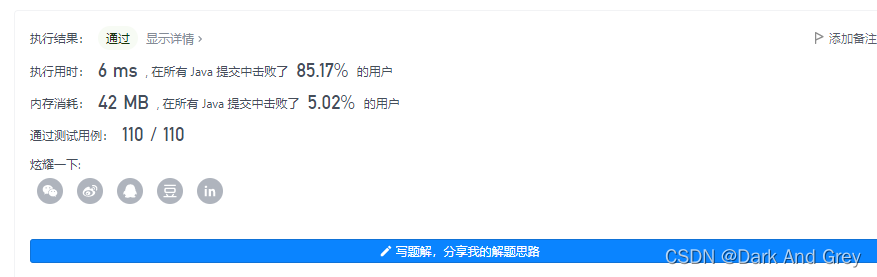
ret.add(top.getKey());}Collections.reverse(ret);return ret;}}
版权归原作者 Dark And Grey 所有, 如有侵权,请联系我们删除。