
文章目录
kafka概述
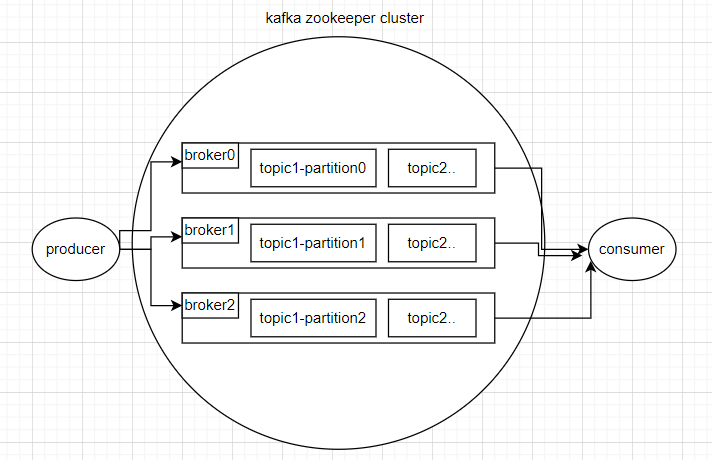
Kafka是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于大数据实时处理领域。
kafka的三个基本组成是生产者、消费者、broker(生产者和消费者之间的消息队列服务器)。
发布/订阅:消息的发布者不会将消息直接发送给特定的订阅者,而是将发布的消息分为不同的类别,订阅者只接受感兴趣的消息。
缓冲/消峰:缓解大流量情况,解决生产消息和消费消息的处理速度不一样的情况。
异步处理机制:允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
消息队列的两种模式
- 点对点 一个生产者一个消费者 ,消费者主动拉取数据,消息收到后清除
- 发布/订阅 多个生产者 ,消费者多个,而且相互独立,多个topic消费者消费数据后不删除数据
几个基本的概念
- Producer:消息生产者,就是向 Kafka broker 发消息的客户端。
- Consumer:消息消费者,向 Kafka broker 接收消息的客户端。
- Consumer Group(CG):消费者组,由多个 consumer 组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
- Broker:一台 Kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个broker 可以容纳多个 topic。
- Topic:可以理解为一个队列,生产者和消费者面向的都是一个 topic。
- Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列。
- Replica:副本。一个 topic 的每个分区都有若干个副本,一个 Leader 和若干个Follower。
- Leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是 Leader。
- Follower:每个分区多个副本中的“从”,实时从 Leader 中同步数据,保持和Leader 数据的同步。Leader 发生故障时,某个 Follower 会成为新的 Leader。
kafka快速入门
官网链接
https://kafka.apache.org/downloads.html
本地搭建伪分布式kafka集群
解压
tar -xzvf kafka_2.12-3.2.3.tgz
在kafka目录下创建etc目录,
mkdir etc
将zookeeper配置文件拷贝进去
cp config/zookeeper.properties etc
,在文件最后添加
audit.enable=true
搭建一个有三个broker的伪分布式节点
cp config/server.properties etc/server-0.properties
cp config/server.properties etc/server-1.properties
cp config/server.properties etc/server-2.properties
分别进入配置文件,修改
broker.id=0
listeners=PLAINTEXT://localhost:9092 注释去掉
log.dirs=/tmp/kafka-logs-0 区分log.dir
broker.id=1
listeners=PLAINTEXT://localhost:9093 注释去掉
log.dirs=/tmp/kafka-logs-1 区分log.dir
broker.id=2
listeners=PLAINTEXT://localhost:9094 注释去掉
log.dirs=/tmp/kafka-logs-2 区分log.dir
进入bin目录下使用启动脚本,开启zookeeper
./zookeeper-server-start.sh ../etc/zookeeper.properties
提示没有java环境就先安装java
sudo apt install openjdk-8-jre-headless
然后启动三个kafka的实例,进入bin目录
./kafka-server-start.sh ../etc/server-0.properties
./kafka-server-start.sh ../etc/server-1.properties
./kafka-server-start.sh ../etc/server-2.properties
创建主题
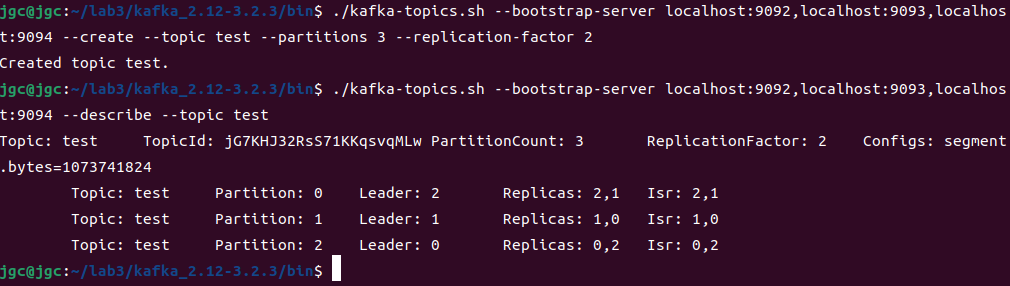
./kafka-topics.sh --bootstrap-server localhost:9092,localhost:9093,localhost:9094--create --topic test --partitions 3--replication-factor 2
查看分区状态
./kafka-topics.sh --bootstrap-server localhost:9092,localhost:9093,localhost:9094--describe --topic test
创建消费者和生产者
./kafka-console-consumer.sh --bootstrap-server localhost:9092,localhost:9093,localhost:9094--topic test --from-beginning
./kafka-console-producer.sh --bootstrap-server localhost:9092,localhost:9093,localhost:9094--topic test
然后在生产者终端发送信息,在消费者终端就可以接收到消息。
梳理一下整个过程,就是先创建好管理节点的zookeeper,然后创建三个broker节点,然后分别创建了生产者和消费者进行通信。
kafka新版本中取消了对zookeeper的依赖,在创建topic时,不用
--zookeeper选项而改用
--bootstrap-server。
--bootstrap-servers参数,只在启动客户端连接Kafka服务时使用。并且,即使列表里面填了多个节点,只要有一个可用就行了。
listeners:指定broker启动时本机的监听名称、端口,给服务器端使用
advertised.listeners:对外发布的访问ip和端口,给客户端使用。如果advertised.listeners没有配置,就采用listeners的配置。
使用docker部署kafka
这里没有实验成功,三个broker链接不起来,先放个官方文档在这,以后需要用到再回来看
https://github.com/bitnami/containers/tree/main/bitnami/kafka
更深入的学习(待更)
另外需要说明,上面的实验只是实验帮助理解,kafka并不是只有这么简单,通常是用java来调用kafka提供的api来对消息进行发送和接收。
学习链接
https://www.bilibili.com/video/BV1h94y1Q7Xg/
版权归原作者 H4ppyD0g 所有, 如有侵权,请联系我们删除。