
🔥《Kafka运维管控平台LogiKM》🔥
✏️更强大的管控能力✏️ 🎾更高效的问题定位能力🎾 🌅更便捷的集群运维能力🌅 🎼更专业的资源治理🎼 🌞更友好的运维生态🌞
文章目录
阅读完本文你大概会获得以下知识
- 什么时候执行消息的压缩操作
- RecordBatch结构图
RecordBatch
我们之前有讲过生产者的ProducerBatch, 这个RecordBatch跟ProducerBatch的区别是什么呢?
RecordBatch是在ProducerBatch里面的一个专门存放消息的对象, 除此之外ProducerBatch还有其他相关属性,例如还有重试、回调等等相关属性。
RecordBatch初始化
在创建一个需要创建一个新的ProducerBatch的时候,同时需要构建一个MemoryRecordsBuilder, 这个对象我们可以理解为消息构造器,所有的消息相关都存放到这个里面。
publicMemoryRecordsBuilder(ByteBufferOutputStream bufferStream,byte magic,CompressionType compressionType,TimestampType timestampType,long baseOffset,long logAppendTime,long producerId,short producerEpoch,int baseSequence,boolean isTransactional,boolean isControlBatch,int partitionLeaderEpoch,int writeLimit){// 省略部分....this.magic = magic;this.timestampType = timestampType;this.compressionType = compressionType;this.baseOffset = baseOffset;this.logAppendTime = logAppendTime;this.numRecords =0;this.uncompressedRecordsSizeInBytes =0;this.actualCompressionRatio =1;this.maxTimestamp =RecordBatch.NO_TIMESTAMP;this.producerId = producerId;this.producerEpoch = producerEpoch;this.baseSequence = baseSequence;this.isTransactional = isTransactional;this.isControlBatch = isControlBatch;this.partitionLeaderEpoch = partitionLeaderEpoch;this.writeLimit = writeLimit;this.initialPosition = bufferStream.position();this.batchHeaderSizeInBytes =AbstractRecords.recordBatchHeaderSizeInBytes(magic, compressionType);// Buffer一开始就需要预留61B的位置用于 存放消息投 RecordHeader
bufferStream.position(initialPosition + batchHeaderSizeInBytes);this.bufferStream = bufferStream;//选择合适的压缩器实现类this.appendStream =newDataOutputStream(compressionType.wrapForOutput(this.bufferStream, magic));}
上面的源码可知重点:
- bufferStream 一开始的时候就需要预留 61B 的位置给 消息头使用,也就是RecordHeader。batchHeaderSizeInBytes = 61
- 根据配置的压缩类型
compression.type,选择对应的压缩输出流。例如假设使用lz4压缩类型,返回的输出流实体对象为KafkaLZ4BlockOutputStream, 这里面有写入消息的方法和压缩方法。
写入消息
创建了Batch之后,自然需要写入消息
源码位置:
privatevoidappendDefaultRecord(long offset,long timestamp,ByteBuffer key,ByteBuffer value,Header[] headers)throwsIOException{ensureOpenForRecordAppend();// 位移偏移量 ;offset 是当前lastOffset+1, 如果是最开始的时候,它是0; baseOffset 默认是0int offsetDelta =(int)(offset - baseOffset);long timestampDelta = timestamp - firstTimestamp;//将数据 写到appendStream中。int sizeInBytes =DefaultRecord.writeTo(appendStream, offsetDelta, timestampDelta, key, value, headers);// 记录一下 写入了多少数据recordWritten(offset, timestamp, sizeInBytes);}
- offsetDelta:表示该条消息的相对整个RecordBatch的位移偏移量, 计算逻辑是(
offset - baseOffset); 使用偏移量可以节省字节数offset 值等于当前RecordBatch的最后一个offset+1,计算逻辑是(offset = lastOffset == null ? baseOffset : lastOffset + 1;) baseOffset 值是RecordBatch的起始偏移量,一般值为0 ; - timestampDelta : 表示该条消息的相对整个RecordBatch的时间戳的偏移量,计算逻辑(
timestamp - firstTimestamp) ,使用偏移量可以节省字节数timestamp 值逻辑timestamp = record.timestamp() == null ? nowMs : record.timestamp(),意思是这个值也是可以通过设置record属性来设置的。 firstTimestamp 值就是timestamp第一次的值。 - 得到了上面的基础值之后, 就将消息写入到Buffer中, 这里的写入涉及到变长字段Varints,一定程度节省空间。这里写入
write()的时候,底层执行的是根据你选择的压缩类型决定使用哪个实现类,例如KafkaLZ4BlockOutputStream。 具体的Record的格式请看下面的 Record格式
注意: 这里写入消息的时候,第一条消息,是从第62位写入的,因为前面的61B已经被BatchHeader先预定了(初始化的时候)。
Record结构图
要了解消息的格式,我们先看看消息是怎么写入的
DefaultRecord#writeTo
publicstaticintwriteTo(DataOutputStream out,int offsetDelta,long timestampDelta,ByteBuffer key,ByteBuffer value,Header[] headers)throwsIOException{int sizeInBytes =sizeOfBodyInBytes(offsetDelta, timestampDelta, key, value, headers);ByteUtils.writeVarint(sizeInBytes, out);byte attributes =0;// there are no used record attributes at the moment
out.write(attributes);ByteUtils.writeVarlong(timestampDelta, out);ByteUtils.writeVarint(offsetDelta, out);if(key ==null){ByteUtils.writeVarint(-1, out);}else{int keySize = key.remaining();ByteUtils.writeVarint(keySize, out);Utils.writeTo(out, key, keySize);}if(value ==null){ByteUtils.writeVarint(-1, out);}else{int valueSize = value.remaining();ByteUtils.writeVarint(valueSize, out);Utils.writeTo(out, value, valueSize);}if(headers ==null)thrownewIllegalArgumentException("Headers cannot be null");ByteUtils.writeVarint(headers.length, out);for(Header header : headers){String headerKey = header.key();if(headerKey ==null)thrownewIllegalArgumentException("Invalid null header key found in headers");byte[] utf8Bytes =Utils.utf8(headerKey);ByteUtils.writeVarint(utf8Bytes.length, out);
out.write(utf8Bytes);byte[] headerValue = header.value();if(headerValue ==null){ByteUtils.writeVarint(-1, out);}else{ByteUtils.writeVarint(headerValue.length, out);
out.write(headerValue);}}returnByteUtils.sizeOfVarint(sizeInBytes)+ sizeInBytes;}
从源码可以得知消息格式为:
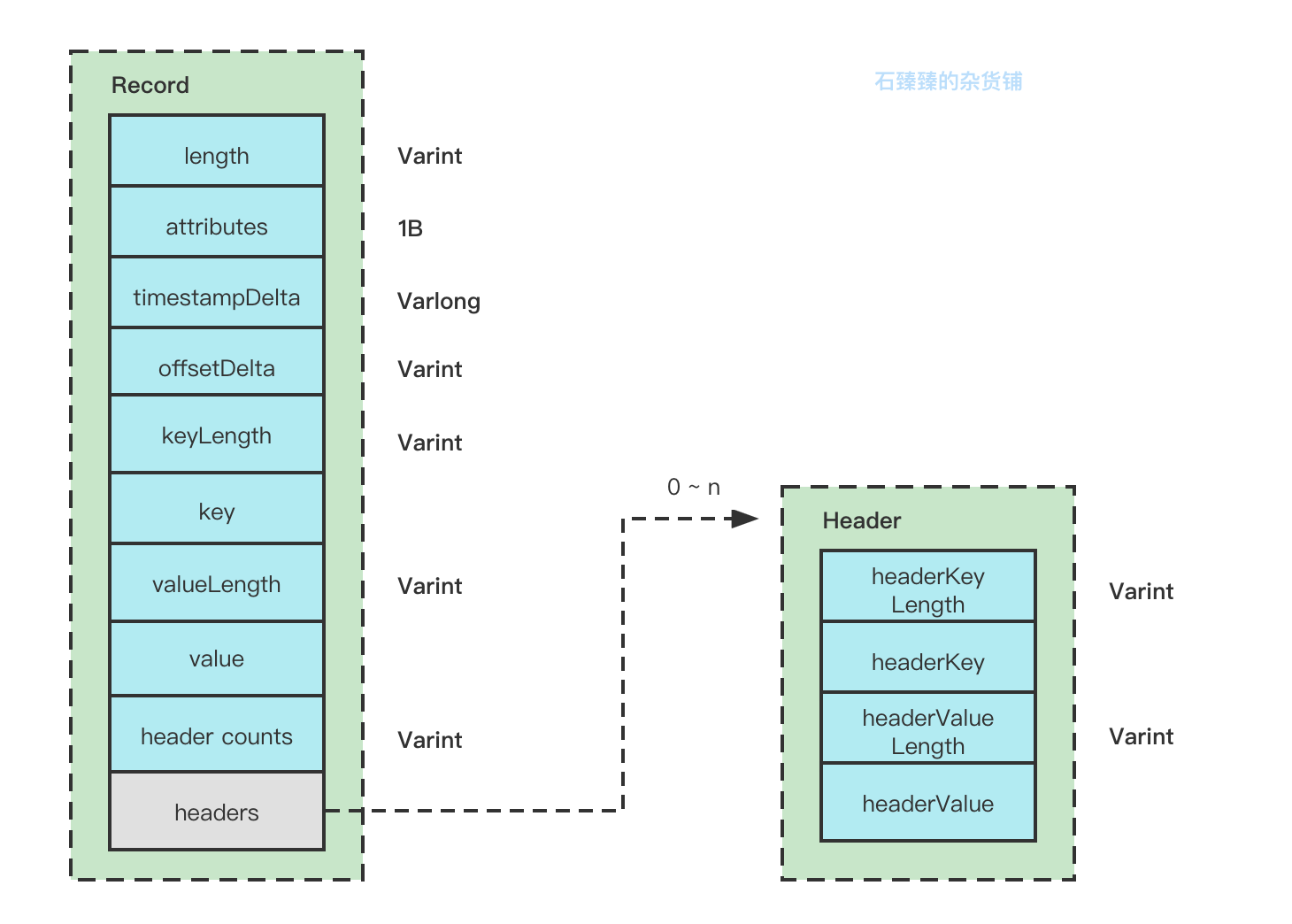
Record属性解释:
- length:整个Record的消息总大小, 使用可变字段。
- attributes:已经弃用,默认为0,固定占用了1B
- timestampDelta: 时间戳的增量,使用可变字段。使用增量可以有效节约内存
- offsetDelta: 位移的增量,使用可变字段, 使用增量可以有效节约内存
- keyLength: key的长度,使用可变字段, 如果没有key,该值为-1。
- key: key的信息,正常存储。如果key==null,则该值不存在。
- valueLength:value的长度,使用可变字段, 如果没有key,改值为-1.
- value: value的信息,正常存储,如果value==null,则该值也不存在。
- headers:消息头,这个字段用于支持应用级别的扩展,可以携带很多信息,例如你带一个TraceId也不过分。
- header counts : 消息头的数量,使用可变字段
Varints 是可变长自动,可以有效的节省空间
Header属性解释:
类似,就不再赘述了。
关闭ProducerBatch
当一个ProducerBatch即将发送出去的时候(ReadyBatch), 会先将Batch关闭掉
batch.close()
。
关闭输出流appendStream并压缩数据
在这个过程中,也会将
appendStream
关闭掉, 也就是用于存储消息体的输出流,那么在它调用
out.flush()
的时候就会调用对应的实现类流,比如我们的压缩类型是lz4, 那么这里实现类就是 KafkaLZ4BlockOutputStream
MemoryRecordsBuilder#closeForRecordAppends
KafkaLZ4BlockOutputStream#flush
publicvoidflush()throwsIOException{if(!finished){writeBlock();}if(out !=null){
out.flush();}}
什么时候执行压缩操作
其中的 writeBlock()就是在执行压缩操作, 所以你应该知道, 这个时候压缩了Records。并且只是Records。
填充RecordBatchHeader数据
上面我们已经给Records消息集压缩过了, 还记得我们在写入消息的时候是从 position****61 后面开始写的吗?
这个61B的空间是用来干嘛的呢?
MemoryRecordsBuilder#writeDefaultBatchHeader
privateintwriteDefaultBatchHeader(){ensureOpenForRecordBatchWrite();ByteBuffer buffer = bufferStream.buffer();//当前buffer的位置int pos = buffer.position();//将位置移动到初始位置0
buffer.position(initialPosition);// 大小int size = pos - initialPosition;//已压缩的大小int writtenCompressed = size -DefaultRecordBatch.RECORD_BATCH_OVERHEAD;// 偏移量增量 int offsetDelta =(int)(lastOffset - baseOffset);finallong maxTimestamp;if(timestampType ==TimestampType.LOG_APPEND_TIME)
maxTimestamp = logAppendTime;else
maxTimestamp =this.maxTimestamp;//讲RecordBatch 消息头写入bufferDefaultRecordBatch.writeHeader(buffer, baseOffset, offsetDelta, size, magic, compressionType, timestampType,
firstTimestamp, maxTimestamp, producerId, producerEpoch, baseSequence, isTransactional, isControlBatch,
partitionLeaderEpoch, numRecords);//重新定位
buffer.position(pos);return writtenCompressed;}
真正写入数据的地方的
DefaultRecordBatch#writeHeader
staticvoidwriteHeader(ByteBuffer buffer,long baseOffset,int lastOffsetDelta,int sizeInBytes,byte magic,CompressionType compressionType,TimestampType timestampType,long firstTimestamp,long maxTimestamp,long producerId,short epoch,int sequence,boolean isTransactional,boolean isControlBatch,int partitionLeaderEpoch,int numRecords){if(magic <RecordBatch.CURRENT_MAGIC_VALUE)thrownewIllegalArgumentException("Invalid magic value "+ magic);if(firstTimestamp <0&& firstTimestamp != NO_TIMESTAMP)thrownewIllegalArgumentException("Invalid message timestamp "+ firstTimestamp);short attributes =computeAttributes(compressionType, timestampType, isTransactional, isControlBatch);int position = buffer.position();
buffer.putLong(position + BASE_OFFSET_OFFSET, baseOffset);
buffer.putInt(position + LENGTH_OFFSET, sizeInBytes - LOG_OVERHEAD);
buffer.putInt(position + PARTITION_LEADER_EPOCH_OFFSET, partitionLeaderEpoch);
buffer.put(position + MAGIC_OFFSET, magic);
buffer.putShort(position + ATTRIBUTES_OFFSET, attributes);
buffer.putLong(position + FIRST_TIMESTAMP_OFFSET, firstTimestamp);
buffer.putLong(position + MAX_TIMESTAMP_OFFSET, maxTimestamp);
buffer.putInt(position + LAST_OFFSET_DELTA_OFFSET, lastOffsetDelta);
buffer.putLong(position + PRODUCER_ID_OFFSET, producerId);
buffer.putShort(position + PRODUCER_EPOCH_OFFSET, epoch);
buffer.putInt(position + BASE_SEQUENCE_OFFSET, sequence);
buffer.putInt(position + RECORDS_COUNT_OFFSET, numRecords);long crc =Crc32C.compute(buffer, ATTRIBUTES_OFFSET, sizeInBytes - ATTRIBUTES_OFFSET);
buffer.putInt(position + CRC_OFFSET,(int) crc);
buffer.position(position + RECORD_BATCH_OVERHEAD);}
可以看到CRC的计算,是在最后面的时候计算,然后填充到buffer里面的,但是这个并不意味着crc32是放在最后一个, CRC_OFFSET的位置是17的位置。
RecordBatchHeader结构图
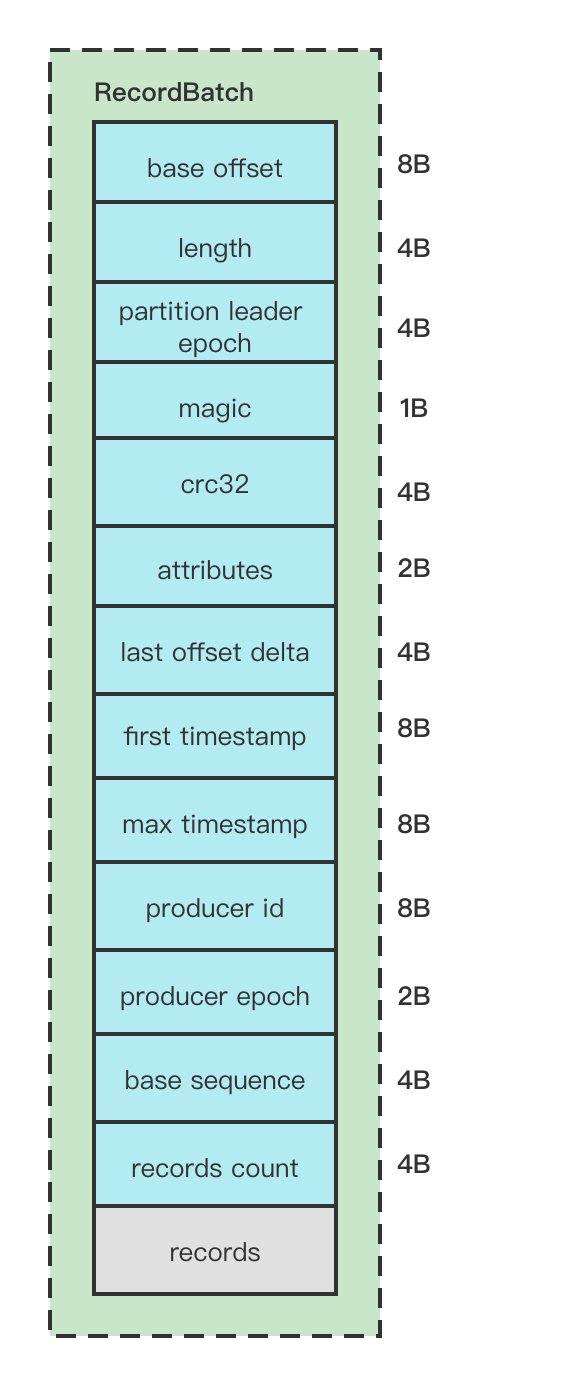
RecordBatchHeader属性解释:
- baseOffset: 当然RecordBatch的起始位移,一般默认为0
- length:计算从
partition leader epoch字段开始到整体末尾的长度,计算的逻辑是(sizeInBytes - LOG_OVERHEAD), 这个sizeInBytes就是整个RecordBatch的长度。LOG_OVERHEAD = 12 - partition leader epoch: 分区的Leader纪元,也就是版本号
- magic: 消息格式版本号, V2版本 该值为2
- crc32: 该RecordBatch的校验值, 计算该值是从attributes的位置开始计算的。
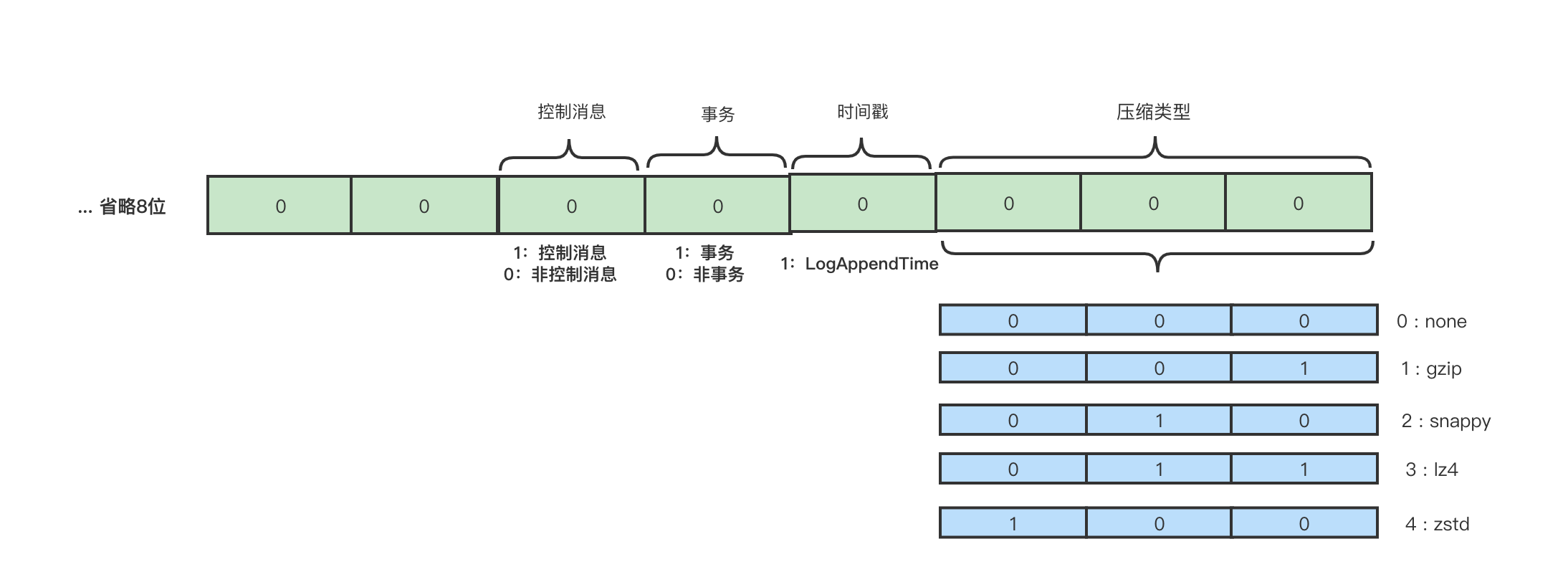
- attributes:消息的属性,这里用了2个字节, 低3位表示压缩格式,第4位表示时间戳,第5位表示事务标识,第6位表示是否控制消息。如下图
- last offset delta : RecordBatch中最后一个Record的offset与first offset的差值。
- first timestamp: 第一条Record的时间戳。对于Record的时间戳的值 ,如果在构造待发送的ProducerRecord的时候设置了timestamp,那么就是这个设置的值,如果没有设置那就是当前时间戳的值。
- max timestamp: RecordBatch中最大时间戳。
- producer id : 用于支持幂等和事务的属性。
- producer epoch :用于支持幂等和事务的属性。
- base sequence :用于支持幂等和事务的属性。
- record count : 消息数量
RecordBatch整体结构图
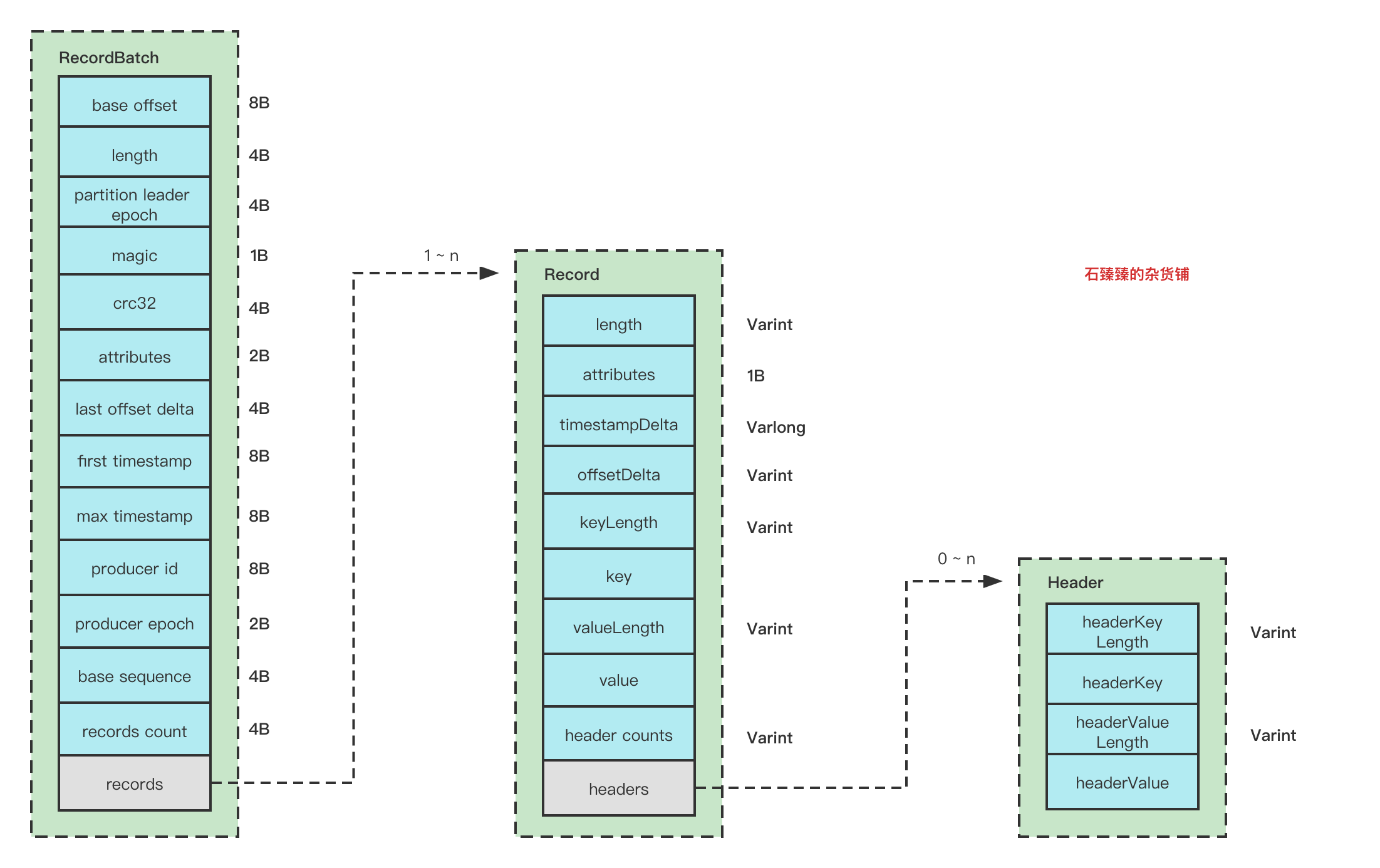
- 在创建RecordBatch的时候,会先预留61B的位置给BatchHeader, 实现方式就是让buffer的位置移动到61位
buffer.possition(61) - 消息写入的时候并不会压缩,只有等到即将发送这个Batch的时候,会关闭Batch,从而进行压缩(如果配置了压缩策略的话), 压缩的知识Records, 不包含 RecordBatchHeader
- 填充RecordBatchHeader
版权归原作者 石臻臻的杂货铺 所有, 如有侵权,请联系我们删除。