
前言
1.知识补充
【机器学习】显卡、GPU、NVIDIA、CUDA、cuDNN(搬运:要点如下,详细可看链接)
加 * 非重要内容,视情况执行。
显卡:即显示卡,全称显示接口卡,是计算机最基本配置、最重要的配件之一(就像联网需网卡,数据显示在屏幕需显卡)。显卡是由GPU、显存等等组成的。
GPU:图形处理器,一般焊接在显卡上的。GPU是显卡上的一块芯片,就像CPU是主板上的一块芯片。GPU功能强大,只用于图形处理太浪费,NVIDIA公司提出CUDA的概念,通用并行计算架构,是一种运算平台,更加方便利用GPU强大的计算能力(并非所有GPU支持CUDA)。
CUDA:通用并行计算架构,该架构使GPU能够解决复杂的计算问题。(加加速-我的理解)
cuDNN:(只是cuda的扩展工具而已)是CUDA在深度学习方面的应用。使得CUDA能够针对性的应用于加速深度神经网络。
2.安装说明

1.如果没有显卡,直接 1 与 3 即可,途中标颜色即建议步骤,只有 2.2.2 较为复杂;
2.所有安装包,都可以备份 U 盘,下次可以直接使用;
3.笔者认为cuDNN 只是 cuda 扩展工具,下载了对应 cuda的 cuDNN,复制 cuDNN 文件到 cuda 即可。所以安装步骤放 cuda 中的一个小点,没必要作为一个大标题。
1、Anaconda的下载安装
搬运:Ubuntu18.04下安装Pytorch-GPU(超详细自己安装全过程)
1.1 下载
最新版本:Anaconda官网下载
历史版本:Anaconda历史版本
下载过慢:Anaconda清华源下载
(其实可以将安装文件保存 U盘 ,下次安装可以直接使用_cuda/cuDNN 也是如此)
1.2 安装
- 终端运行下载 .sh 文件:
bash Anaconda3-(下载文件 Tab 补全即可)-Linux-x86_64.sh
2.过程
Welcome to Anaconda3 5.0.1
In order to continue the installation process, please review the license
agreement.
Please, press ENTER to continue
>>> 按回车
#然后一直按回车到协议完毕
#出现:
Do you accept the license terms? [yes|no]
>>>输入yes
#下面就是问你安装目录,建议就是默认的安装路径,直接按回车
Anaconda3 will now be installed into this location:
/home/mayunteng/anaconda3
- Press ENTER to confirm the location
- Press CTRL-C to abort the installation
- Or specify a different location below
[/home/mayunteng/anaconda3] >>> 按回车
#接下来就是等待安装完成
#注意安装完成以后会询问你是否把anaconda3的路径加到环境变量里去,一定要选yes,一定要选yes,一定要选yes。
*1.3 添加环境变量(1.2默认则不需要执行)
若 1.2 默认路径添加环境变量,新开终端出现会出现 (base),表明已经成功添加环境路径,则无需执行以下代码。
sudo gedit ~/.bashrc
# 在文件末尾处添加以下语句
export PATH=/home/XXX/anaconda3/bin:$PATH XXX为自己的用户名
source ~/.bashrc
终端输入python,可以看到有Anaconda出现,安装成功。
2、安装cuda(cuDNN是配套的)
在安装之前你要先查看你的电脑是否支持GPU运算,否则你也不用安装了。
2.1 NVIDIA驱动安装
平常使用 2.1.1 两行命令安装就可以了,实在安装有问题可以尝试 2.1.2。
2.1.1 命令自动安装
Ubuntu18.04中自带了NVIDIA驱动,但没有完整安装,使用命令
ubuntu-drivers devices(若不显示,sudo apt update更新源)
可查看当前的设备和驱动。
ubuntu-drivers devices
sudo ubuntu-drivers autoinstall #安装所有驱动
sudo apt install nvidia-440 #只安装其中一个驱动
sudo nvidia-smi #验证是否成功
*2.1.2使用官方的NVIDIA驱动进行手动安装(稳定、靠谱)
*下载 cuDNN 没注意,显卡驱动自动降版后,自动安装装不上,使用手动安装成功解决。
(纯纯的搬运工,主要真的有用,怕作者哪天删除了)
参考链接:Ubuntu18-22.04安装和干净卸载nvidia显卡驱动——超详细、最简单
**1.**安装驱动前一定要更新软件列表和安装必要软件、依赖(必须)
sudo apt-get update
sudo apt-get install g++
sudo apt-get install gcc
sudo apt-get install make
**2.**查看GPU型号(通用查看命令:lspci | grep -i vga)
lspci | grep -i nvidia
**3.**官网下载对应驱动(必须)
下载好之后,注意把nvidia驱动放在英文名文件夹下,比如mkdir driver 新建文件夹“driver”
NVIDIA 驱动程序下载
***4.**卸载原有驱动
sudo apt-get remove --purge nvidia* # 或者nvidia-*
5.禁用nouveau(nouveau是通用的驱动程序)(必须)
sudo gedit /etc/modprobe.d/blacklist.conf 或者(blacklist-nouveau.conf)
(1)在打开的blacklist.conf末尾添加如下,保存文本关闭
blacklist nouveau
options nouveau modeset=0
(2) 在终端输入如下更新,更新结束后重启电脑(必须)
sudo update-initramfs –u
(3) 重启后在终端输入如下,没有任何输出表示屏蔽成功
lsmod | grep nouveau
**6.**安装lightdm
lightdm是显示管理器,主要管理登录界面,ubuntu20.04、21.04、22.04需要自行安装,然后上下键选择lightdm即可。
(这一步也可以不安装lightdm,使用ubuntu20.04、21.04、22.04自带的gdm3显示管理器,直观的区别就是gdm3的登陆窗口在显示器正中间,而lightdm登录窗口在偏左边,正常使用没有区别。其他的区别这里不做探究;原文作者亲测需要注意的是,如果你有控制多屏显示的需要,gdm3可能更适合你,亲测使用lightdm设置多屏,可能会出现卡屏,死机,无法动弹情况,仅供参考)
sudo apt-get install lightdm

**7.**停止当前的显示服务器
为了安装新的Nvidia驱动程序,我们需要停止当前的显示服务器。最简单的方法是使用telinit命令更改为运行级别3。在终端输入以下linux命令后,显示服务器将停止。(必须)
sudo telinit 3
退出文本界面到图形界面,输入sudo telinit 5或者Ctrl + Alt + F1/F7/F8 (联想部分电脑:Ctrl + Alt + Fn + F1)
8. 在文本界面中,禁用X-window服务,在终端输入(必须)
(如果是默认的gdm3显示管理器,命令为sudo /etc/init.d/gdm3 stop)
sudo /etc/init.d/lightdm stop或者(sudo service lightdm stop)
**9. **cd命令进入到你存放驱动的目录,输入命令:
sudo chmod 777 NVIDIA-Linux-x86_64-430.26.run #给你下载的驱动赋予可执行权限,才可以安装
sudo ./NVIDIA-Linux-x86_64-430.26.run –no-opengl-files #安装
第二句命令的参数介绍:
–no-opengl-files 只安装驱动文件,不安装OpenGL文件。这个参数原作者亲测台式机不加没问题,笔记本不加有可能出现循环登录,也就是loop login。 看你自己需要把。
显卡驱动安装过程中一些选项(有一些问题记不清楚了,只给出需要选择的选项:):
1.The distribution-provided pre-install script failed! Are you sure you want to continue?
选择continue installation
2.Would you like to register the kernel module souces with DKMS? This will allow DKMS to automatically build a new module, if you install a different kernel later?
选择 No 继续。
3.问题没记住,选项是:install without signing
4.问题大概是:Nvidia's 32-bit compatibility libraries? 选择 No 继续。
5.Would you like to run the nvidia-xconfigutility to automatically update your x configuration so that the NVIDIA x driver will be used when you restart x? Any pre-existing x confile will be backed up.
选择 Yes 继续
————————————————
版权声明:本文为CSDN博主「道阻且长行则将至!」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Perfect886/article/details/119109380
**10.**安装结束后输入sudo service lightdm start 重启x-window服务,即可自动进入登陆界面,不行的话,输入sudo reboot重启,再看看。
(重启后不行,尝试在bios中去掉安全启动设置,改成 secure boot:disable)
**11.**终端输入nvidia-smi 检查是否装好
12.注意
1.如果是替换显卡驱动的话(也就是说你这台机子不是第一次在ubuntu下安装英伟达显卡驱动,这一次是升级或者替换),先进入TTY文本模式,然后在sudo /etc/init.d/lightdm stop
2.安装完驱动,记得sudo service lightdm start
2.2 安装CUDA
** 建议先查看程序 pytorch 对应的 cuda 版本,否则版本错误得重新安装(比如我自己)。**笔者认为cuDNN 只是 cuda 扩展工具,下载了对应 cuda的 cuDNN,复制 cuDNN 文件到 cuda 即可。所以安装步骤放 cuda 中的一个小点,没必要作为一个大标题。
2.2.1 注意
** **cuda安装方式两种,如果方式 1 用deb装低版本 cuda(
比较 sudo nvidia-smi 中推荐版本低
),显卡会自动降版本,导致我使用** 2.1.2 **方式才重新安装显卡驱动。相较而言run方式较为简单。
但是同台设备配置多cuda环境,使用方式 1 用deb,先装
sudo nvidia-smi 中推荐cuda版本,将显卡限制限制在限制的版本,同样方式装多个低版本 cuda 就没问题了,详细见**2.2.2**小标题
。
- 用deb方式安装CUDA,会附带安装显卡驱动,默认安装;
- 用run方式安装CUDA,会附带安装显卡驱动,可以选择不安装;(安装命令简单)
- (不确定是不是真的)devel说涵盖了开发所需的所有工具,包含编译、debug等,以及编译需要的头文件、静态库。runtime是说只涵盖了运行环境的最小集合,例如动态库等,所以runtime的镜像大小会比devel小一些。nvidia/cuda 公开源中的devel和runtime有什么区别
2.2.2 同台设备配置多cuda环境
要安装多个版本的cuda的话,因为使用的是2.2.1中**方式 1 用deb安装方式**,首先得安装**最新版本的cuda**。
**参考链接:**
同台设备配置多cuda环境 (参考一:如 2.2.2 描述 方式 1 deb安装)
在ubuntu上安装多个版本的CUDA,并且可以随时切换(参考二:提供 run 方式多版本安装)
1.先使用nvidia-smi查看当前设备的驱动版本:
nvidia-smi

详细可以官网查看(cuda和driver之间的对应关系 如下图),以笔者的 525.60.13 版本驱动为例,就应该安装 CUDA 12.1.x/CUDA 12.0.x 版本的cuda (注意一定一定,要先安装和当前驱动适配的,最新版本的cuda,否则后面安装一些老版本cuda的时候会自动降低驱动版本):

2.官网下载对应cuda版本
(1)下载链接:历史版本cuda下载,笔者适配12.0/12.1,**注意一定要选择
deb(local)
安装**。 
(2)sudo -s
开启权限(好像可以不用开,原作者开的),然后copy它的命令运行,并记得把下面命令的最后一行**
sudo apt-get -y install cuda
改为
sudo apt install cuda-12-0
**(改为自己已经安装的最高版本):

(3) 查看是否安装成功(之前已经安装过,所以能看到 12.0/11.3):
ls /usr/local

(4)安装对应版本cuDNN
A.然后去官网下载安装对应版本的cuDNN (选择tar包安装,注意不要
deb
或
runfile
安装,不然之后安装其他版本cudnn的时候,会覆盖掉已经存在的其他cuda的cudnn),锁定linux与x86架构。

B.之后解压并写入lib (把下面的文件名和cuda版本号改为自己的):
tar -xzvf cudnn-x.x-linux-x64-v8.x.x.x.tgz
## 当前文件夹下会多出一个cuda/
sudo cp cuda/include/cudnn*.h /usr/local/cuda-M.m/include
sudo cp cuda/lib64/libcudnn* /usr/local/cuda-M.m/lib64
sudo chmod a+r /usr/local/cuda-M.m/include/cudnn*.h /usr/local/cuda-M.m/lib64/libcudnn*
C.修改环境变量(对应当前安装的cuda版本)
sudo gedit ~/.bashrc
export PATH=/usr/local/cuda/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH="/usr/local/cuda/lib64:/usr/local/cuda-12.0/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}"
# 原作者示例
# export LD_LIBRARY_PATH="/usr/local/cuda/lib64:/usr/local/cuda-10.1/lib64:/usr/local/cuda-11/lib64:/usr/local/cuda-11.1/lib64:/usr/local/cuda-11.4/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}"
D.检查是否安装成功
原作者:reboot重启之后,可以
nvcc -V
检查一下。
不过好像:source ~/.bashrc,直接可以 **
nvcc -V
**
nvcc -V
(5)安装多版本cuda
重复上述就可以安装其他版本(更低版本)的cuda了,比方说我现在安装了cuda12.0,完全可以按照2.2.2 的方法安装cuda11.1,cuda10.1以及对应的cudnn。
装完所有你需要的cuda之后,**
reboot
一下可以看一下
nvidia-smi
,确保显卡驱动没有被降低(这也是为什么之前一定要用
deb
安装 显卡适配的 最高版本 的cuda 的原因),然后可用下面代码最终验证一下(笔者不信,先装低版本导致显卡驱动降级,装不上了显卡驱动,据2.2.1中1可知deb安装会附带显卡安装,所以最想安装的一定是 显卡适配的 最高版本** 的cuda):
## 改为自己的cuda版本路径
cd /usr/local/cuda-11.3/samples/1_Utilities/deviceQuery
sudo make
./deviceQuery
## 改为自己的cuda版本路径
cd /usr/local/cuda-12.0/samples/1_Utilities/deviceQuery
sudo make
./deviceQuery
安装了几个cuda,就用几个上述代码(比方说,这里我安装了两个cuda分别为12.0和11.3),最后都能得到这样的输出:
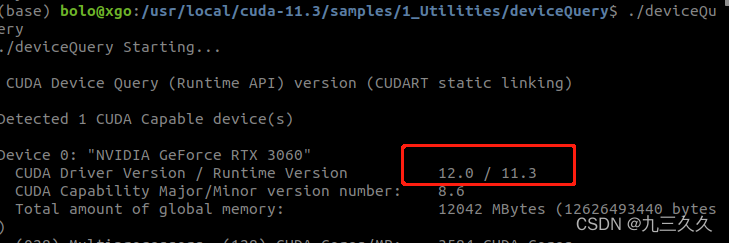
(6)多版本cuda 切换
参考链接:Linux之cuda、cudnn安装及版本切换,
原作者:就说明这些cuda都全部安装成功,都可以同时使用(因为所谓安装多cuda,其实就是有多个cudatoolkit lib,具体程序用到哪个版本的时候,就会去去环境变量里面找引用)。
但是 nvcc -V 只出现了其中一个版本,所以我还看了网络cuda如何切换 --> 修改环境变量 / 软连接

方法一:修改环境变量 (推荐)
如(4)只留下自己需要的 cuda版本 环境变量即可,需要切换时候再修改,然后source一下使生效。
sudo gedit ~/.bashrc
# 不使用如软连接环境变量设置
export PATH="$PATH:/usr/local/cuda-10.0/bin"
export LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/usr/local/cuda-10.0/lib64/"
source ~/.bashrc
这样的好处是只改了当前用户的cuda版本,其它用户还可以用他们需要的cuda版本,互不影响。
方法二:软连接
如果想要把服务器上多用户的CUDA版本都切换了,则删除原有链接,建立新的软链接即可,这样服务器上每个用户的版本都切换了
#使用软连接环境变量设置
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64
export PATH=$PATH:/usr/local/cuda/bin
export CUDA_HOME=$CUDA_HOME:/usr/local/cuda
source ~/.bashrc
sudo rm -rf /usr/local/cuda #删除之前创建的软链接
sudo ln -s /usr/local/cuda-10.0 /usr/local/cuda #创建新 cuda 的软链接,注意修改自己对应的版本
ls -l /usr/local/ #查看软链接情况,带 -> 符号的表明是软链接
nvcc -V # 查看 cuda 版本
2.2.3 单cuda环境
run方式安装比较简单,而且可以选择**不修改显卡驱动**,可以一开始就安装低于自己推荐版本的 cuda,不过按照参考二 在ubuntu上安装多个版本的CUDA,并且可以随时切换 ,run方式也可以多版本安装。
1.1.先使用nvidia-smi查看当前设备的驱动版本 2.2.2 - 1
sudo nvidia-smi
满足适配关系可以官网查看(cuda和driver之间的对应关系 如下图)

满足红框大于图显卡驱动版本即可。
2.官网下载对应版本
(1)下载安装 cuda - run 方式

(2)copy它的命令运行

sudo sh cuda_10.1.243_418.87.00_linux.run
A.稍等几分钟之后,会出现下面这个截图,其中【x】是需要安装的,之前安装了驱动,现在只安装其余的内容。

B.选中install回车,之后会出现是否接受安装,输入accept
C.安装前会提示安装的内容,不需要执行操作,等待安装结束。
(3) 测试是否安装成功
cd /usr/local/cuda-10.1/samples/1_Utilities/deviceQuery
sudo make
sudo ./deviceQuery
出现PASS,说明安装成功了。
(4) 安装对应版本 cuDNN — 同 2.2.2-2(4)
A.然后去官网下载安装对应版本的cuDNN (选择tar包安装,注意不要
deb
或
runfile
安装,不然之后安装其他版本cudnn的时候,会覆盖掉已经存在的其他cuda的cudnn),锁定linux与x86架构。
B.之后解压并写入lib (把下面的文件名和cuda版本号改为自己的):
tar -xzvf cudnn-x.x-linux-x64-v8.x.x.x.tgz
## 当前文件夹下会多出一个cuda/
sudo cp cuda/include/cudnn*.h /usr/local/cuda-M.m/include
sudo cp cuda/lib64/libcudnn* /usr/local/cuda-M.m/lib64
sudo chmod a+r /usr/local/cuda-M.m/include/cudnn*.h /usr/local/cuda-M.m/lib64/libcudnn*
C.修改环境变量(对应当前安装的cuda版本)
sudo gedit ~/.bashrc
export PATH=/usr/local/cuda/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH="/usr/local/cuda/lib64:/usr/local/cuda-10.0/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}"
# 原作者示例
# export LD_LIBRARY_PATH="/usr/local/cuda/lib64:/usr/local/cuda-10.1/lib64:/usr/local/cuda-11/lib64:/usr/local/cuda-11.1/lib64:/usr/local/cuda-11.4/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}"
D.检查是否安装成功
不过好像:source ~/.bashrc,直接可以 **
nvcc -V
**
**
2.3 卸载 cuda
**
**
参考链接:Ubuntu 卸载cuda
**
3、安装pytorch
3.1 Anaconda基本命令
尝试开源算法往往不能一次就将环境创建好,笔者尝试开源代码中,用到 pytorch1.0.1/1.10.0/1.8.1等。用 Anaconda 进行虚拟环境的创建很好解决多种环境搭建,而且如果你 pip install 失败了的话,使用 conda install 基本都能解决!!! 所以先说说基本命令,更多可查看以下链接。
参考链接:【一文汇总全了解】anaconda与conda常用命令 , Anaconda常用命令笔记
#1.新建环境
conda create -n env_name python=3.x # env_name 环境名字
#2.激活和退出环境
conda activate env_name # 激活
conda deactivate #退出
#3.克隆
conda create -n env_name --clone old_env_name
#4.删除虚拟环境
conda remove -n env_name --all
#5.查看
conda list # 查看当前虚拟环境(env_name)安装的包
conda env list # 查看当前所有环境
3.2 官网安装pytorch(推荐)
1.先利用 3.1 创建一个自己需要的虚拟环境,再虚拟环境中运行以下代码进行安装,例如:
conda create -n test python=3.6
conda activate test

2.下载:pytorch官网

3.运行安装程序
在步骤 2 中选定好,匹配的pytorch版本和 cuda,激活的环境中运行代码

等待命令结束就安装好了,而且是将 pytorch 安装激活的虚拟环境中,可以再激活新的安装其他版本。
3.3 其他安装方法
比较喜欢稳定安全的官方下载,慢也慢不了多少,这里就不做详细介绍,有想法可以留言,会补充进来。
离线安装:Ubuntu16.04环境下PyTorch简易安装教程
添加其他安装源加速安装:conda安装Pytorch下载过慢解决办法(11月26日更新ubuntu下pytorch1.3安装方法)
4、测试安装
4.1 使用命令查看torch版本
python
import torch
torch.__version__
**4.**2 使用命令查看是否可加速
print(torch.cuda.is_available())
4.3 使用一个矩阵运算测试是否能正常运行
>>> import torch as t
>>> x = t.rand(5,3)
>>> y = t.rand(5,3)
>>> if t.cuda.is_available():
x = x.cuda()
y = y.cuda()
print(x+y)
版权归原作者 九三久久 所有, 如有侵权,请联系我们删除。