
前言

查询~
和查询结合在一起的新增操作~
简述~
把从上一个表中的查询结果,做为下一个表要插入的数据~
操作案例~:
创建两个表演示一下
表A,插入了三条记录
表B,没有插入任何记录

现在把表A里面的记录插入到表B中
在这个语句中就会先执行查找,针对查找到的每个结果,都执行插入操作,插入到B中
我们需要保证,从A中查询出来的结果的列数和类型,和B表匹配
此时A里面的记录就顺利的导入到了B表中


现在我们再做一些轻微的改动,把B的列的顺序调换一下,此时能否完成把A的数据给插入到B这个操作呢?
是可以的,只要保证A的查询结果的列的顺序和B对应即可~~
调换B表列的顺序
插入成功
本来A表中,id在前,name在后,和B的列顺序不匹配.但是可以通过针对A进行指定列查询,从而可以保证查询的结果的顺序能和B对上~~
另外,还可以给后面的select指定一些其他的条件/排序/limit/去重.....
插入的实际就是select执行结果的临时表~~
查询的结果是在临时表里的.
insert是把临时表中的数据给插入到数据库服务器的硬盘里了~~
(insert 改的是硬盘中的数据)


**增强版的查询~ **
** 聚合查询~把多个数据进行了关联操作~~**
简述~
把多个数据进行了关联操作~~
前面讲过,查询带表达式的,这个是属于"列和列之间的关联运算"
操作案例~:
MySQL内置了一些聚合函数,可以让我们来使用~
COUNT([DISTINCT] expr) : 返回查询到的数据的数量(查询结果有多少行),expr:写的是列名/表达式
我们看一下如何使用
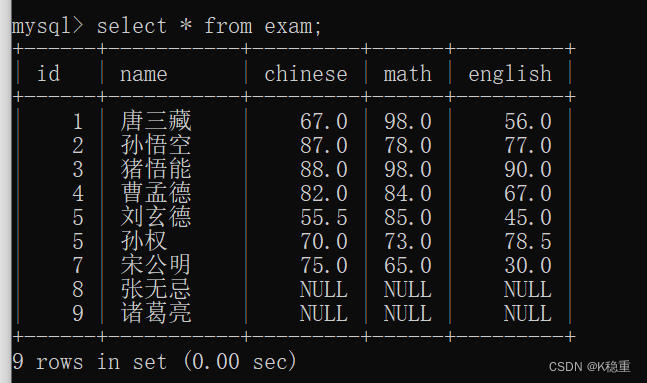
创建一个exam表
创建好并插入好的记录
我们基于上述的这个表为例来操作一下
这是我们执行count()这个聚合函数得到的效果,直接执行count()得到的结果就是整体的行数.
结果为9,就相当于是针对select * from exam的结果集合进行计算行数~
count这里的参数不一定非要写作 *
也可以指定某个列~~
我们来看一下:
为什么上述表求得结果过是7
因为NULL这样的值不会记录到count中



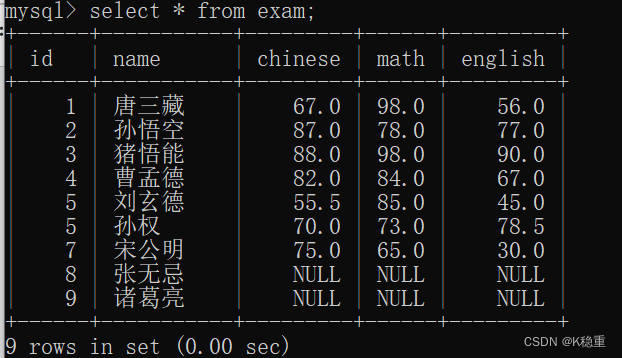
SUM([DISTINCT] expr) 返回查询到的数据的 总和,不是数字没有意义(进行求和)
把这一列的若干行,进行相加~~
还是看这个表:
我们想把chinese这一列进行求和
相当于把chinese这里面这一列整体的内容进行相加了
sum这个操作只能针对数字进行运算,不能针对字符串来进行~~
再来一个总分求和
一个聚合函数里面的参数,也可以通过表达式的方式进行计算
聚合函数,也是表达式中的一部分~~
如果我们尝试字符串求和就会出现问题
字符串是没办法转换成double的,所以说我们的sum操作是针对数字来进行的



**聚合函数,还可以搭配where字句来使用~ **
可以基于条件进行筛选,把筛选结果在进行聚合~~
案例~:
求英语大于70分的成绩总和
形如这样的操作会先执行条件筛选,然后再进行聚合~~

下面的这三个函数和上述介绍的使用方法都一样,分别是求平均值,最大值,最小值.
AVG([DISTINCT] expr) 返回查询到的数据的 平均值,不是数字没有意义
MAX([DISTINCT] expr) 返回查询到的数据的 最大值,不是数字没有意义
MIN([DISTINCT] expr) 返回查询到的数据的 最小值,不是数字没有意义
GROUP BY分组操作
简述~:
分组操作:group by
根据行的值,对数据进行分组,把值相同的行都归为一组~~
操作案列~:
创建好的表:
查询每个角色最高工资,最低工资,平均工资(这种操作就需要按照岗位,来进行分组~~)
group by role 就是根据role这一列进行分组
分成这些组之后,就可以针对每个组都来使用聚合函数
一个SQL的执行过程,具体的执行顺序,和咱们书写的顺序并不完全一致
也可以起一个别名




**HAVING **
简述~:
针对分组之后得到结果,可以通过having来指定条件~~
group by 是可以使用where,只不过where是在分组之前执行.
如果要对分组之后的结果进行条件筛选,就要用having~
操作案列~:
分组之前指定条件:
求每种角色,平均薪资
,但是要去掉马云这里就是先去掉马云,然后在分组~(分组之前指定条件,就要使用where)
可以看到,正好就是马云是服务员,把马云去掉之后,分组结果中,就少了服务员这个记录~

操作案列~:
分组之后指定条件筛选~~
求每种角色,平均薪资,只保留平均薪资1w以下的~~
这里就是得先分组计算,知道了平均工资,才能进一步筛选~~(分组之后,指定条件,就需要使用having了)
很明显的看到,这里董事长平均薪资超过1w的记录已经没有了~~

联合查询~
简述~:
把多个表的记录往一起合并,一起进行查询~~
也可以叫做多表查询~
多表查询是整个sql中最复杂的部分,也是笔试中,比较爱考的部分,但实际开发中一般禁止使用多表查询~~
笛卡尔积~~(多表查询中的核心操作)
迪卡尔积是针对任意两张表之间的运算.
操作案列~:
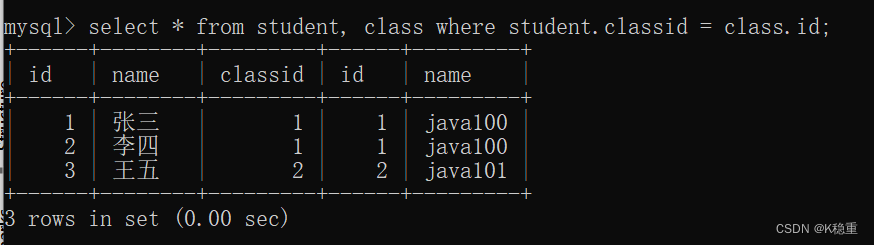
学生表(studentid, name, classid)
1 张三 1
2 李四 1
3 王五 2
4 赵六 2
班级表(classid, name)
1 java100
2 java101
3 java102
笛卡尔积的运算过程:
先拿一张表的第一条记录,
和第二张表的每个记录,分别组合,得到了一组新的记录~
1 张三 1 1 java100
1 张三 1 2 java101
1 张三 1 3 java102
2 李四 1 1 java100
2 李四 1 2 java101
2 李四 1 3 java102
3 王五 2 1 java100
3 王五 2 2 java101
3 王五 2 3 java102
4 赵六 2 1 java100
4 赵六 2 2 java101
4 赵六 2 3 java102
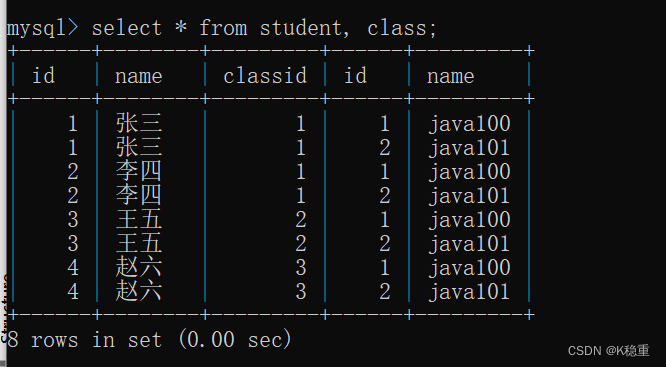
上述就是迪卡尔积
针对A B两张表,计算笛卡尔积.
此时笛卡尔积的列数,就是A的列数+B的列数
笛卡尔积的行数就是,就是A的行数*B的行数~
如何在SQL中进行笛卡尔积?
操作案列~
最简单的做法,就是直接select,from 后面跟上多个表名,表名之间使用逗号分割~~
我们通过上述两张表来进行我们的笛卡尔积操作
这就是我们笛卡尔积执行后的结果


迪卡尔积这个操作,虽然执行效率不高,但是本身确实是一个功能挺好用的操作~~
可以借助笛卡尔积,来完成一些更复杂的操作~~
操作案例~:
查询同学姓名和对应的班级名字
笛卡尔积,是两张表中数据尽可能的排列组合得到的.
在这些排列组合中,仔细看,有没有一些数据是我们需要的,另外一些数据是没有意义的呢
笛卡尔积是一个单纯无脑的排列组合~~
这里的组合结果不一定都是有意义的数据~~
上述标红的才是我们需要的数据
两张表中都有id这一列,
id的值对应相等的记录,其实就是应该要保留的记录~~
像这个里的id相等这样的条件,就称为"连接条件"
带有连接条件的笛卡尔积,其实就是"多表查询了"
我们看看如何筛选出我们需要的条件:
当在代码中加上筛选条件之后,很明显的看到,记录就剩下三条我们需要的数据
如果笛卡尔积中的两个列名相同,在写条件的时候就可以通过表名.列名的方式来访问
如果列名不会混淆(不是同名),可以用表名.列名,也可以省略表名~
这样就完成了我们最终的结果
在最终的查询结果中,一般就只是需要一部分列来显示.需要哪个列就显示指定哪个列就行了~~



实际开发中往往数据来自不同的表,所以需要多表联合查询。
操作案列~:
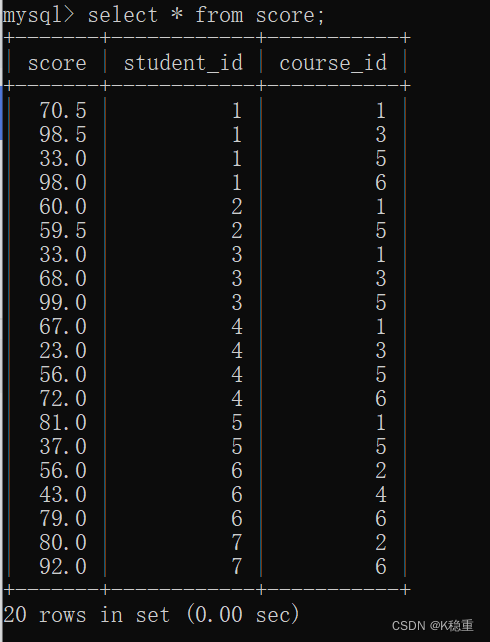
我们先构造几张表格



上述构造了四张表:学生表,班级表,分数表,课程表
在这个场景中涉及的实体主要有三个学生,班级,课程
学生和班级是一对多的关系~
学生和课程是多对多的关系~
分数表是学生和课程之间的关联表~
每张表插入的记录我们也看一下
有了这些内容之后我们就可以做一些具体的多表查询的操作了
关于多表查询的具体操作~
操作案列1~:
查询许仙同学的成绩
首先我们要分析一下:
许仙同学选了很多课,我们需要在学生表中获取到他的姓名,在分数表中获取他的分数信息~~
所以就需要对学生表和分数表进行笛卡尔积操作
笛卡尔积操作之后因为学生表里是8条记录,分数表里是20条记录,两者相乘得到了现在的160条记录
这么多记录哪些是我们需要的,哪些是属于非法的呢
我们仔细想一下,在我们这个迪卡尔积里面仔细观察就能发现:
其中有一个关联的id,在学生表里有一个id,分数表里也有一个student_id
在当前的这两张表里,都存在学生id这个列~~
按照前面总结的规律,应该指定这两个id匹配,才保留记录~不匹配的就属于排列自己直接生成的无效数据
所以在当前的这个代码的基础之上我们加上一个连接条件
加上连接条件之后数据明显就少了很多
我们在看一下每条记录的意思
比如第一条记录,就是李逵同学课程id为1的这门课分数为70.5
加上连接条件之后就相当于是说每个同学每门课程,分数分别是多少~~
接下来我们要找到"许仙"的分数信息
就可以把其他同学给过滤掉~~
再加一个条件即可~
此时我们的结果里面就只包含许仙每门课的成绩了~
我们问题是只需要许仙的成绩~其他列就都不要了
只保留名字和分数~
这样就求得我们的最终结果了









题外话:
大家刚开始学习多表查询的时候,千万不要试图,一步到位~~(一步就把SQL写出来....)
刚开始的时候,一定是,一点一点写~~
先分析数据来自于那些表,然后笛卡尔积,观察笛卡尔积的结果,筛选出合法的数据,在逐步的根据需求,添加新的条件,让结果一点一点的接近预期~~
实现刚才这个多表查询,直接from多张表,是一种写法,除此之外,还有另外一种写法.基于join这样的关键字,也能实现多表查询~~
演示一下:
格式:from 表1 join 表2 on 条件
和前面写的from表1,表2 where 条件~ (更简单一些),这两种写法是等价的~~
那么为什么还有join这种写法呢
因为相比之下,还有from多个表实现不了的功能~~(后续再说)

再看案列:
查询所有同学的总成绩
这个案列要在多表查询的基础上,再加上一个聚合函数~~
还是一样的,我们先通过连接条件把有效记录筛选出来
这个效果就是显示出每个同学每个科目的的分数~~
此处可以看出,同学的分数,是按照行的方式来排列的~~现在我们要做的是针对每个同学分别来求总分,那么就先得按照同学或者学号来进行分组,然后在针对每一组分别求这里面的总分
加上group by id之后,可以看到,记录的函数明显变少了.每个学生只有一行数据了
但是分组之后,可以看到,当前这里score列并不是总成绩,而是每个分组中的第一条记录~
此处我们要想得到总成绩,就需要进行sum操作~~
这样就得到我们想要的结果了
像这种多表查询的sql,就只是刚开始的时候觉得难,多写几个案例,很容易能够找到规律~~



案例:
查询所有同学的成绩,及同学的个人信息
这里不光要查询出同学的名字,还有课程的名字,以及分数~
这个时候,就涉及到三张表的联合查询了~
同学名字出自学生表
课程名字出自课程表
分数出自分数表
三张表算笛卡尔积和两张表,规则都一样~
一共有960条记录,这960条记录怎么来的
这边只截了头和末尾的部分记录~
学生表,有8个记录
分数表,20个记录
课程表6个记录
相乘得到的
按照前面的规律,加上连接条件~~
student.id = score.student_id相当于是把学生表和分数表进行了一个筛选,但是同时还有一个课程表,课程表如何和分数表进行进一步筛选呢
课程表里面也有一个id,分数表里也有一个course_id
所以这里面的连接条件我们就得写两个
score.course_id = course.id
所以就得到了上述结果
当前这个表就列出了每个同学的每个课程拿到的分数,同时带有课程的名字~~
接下来我们只要去掉不必要的列,只保留关注的关键列~
这样就得到了我们想要的结果




如果是join on的写法,能针对三张表进行吗?
我们尝试一下
from 表1 join 表2 条件 join 表3 on 条件
建议大家实际写的时候优先用from多个表的写法,from多个表的写法确实更简单更直观一些
既然推荐使用这个from多个表where~那么join on还有啥用
join on 能够做到上个写法中做不到的事情~~
上面说的这个from多个表where写法叫做"内连接"
使用join on的写法,既可以表示内连接,还可以表示外连接~~
select 列 from 表1 join 表2 on 条件;这种写法其实还可以加一个 inner
select 列 from 表1 inner join 表2 on 条件;
inner join表示是"内连接"
其中 inner 可以省略~~
select 列 from 表1 left join 表2 on 条件; 左外连接
select 列 from 表1 left join 表2 on 条件; 右外连接
虽然说,使用多表查询的时候内连接是用的最多的
但是外连接也会偶尔用到~~

给大家演示一下:
先创建两个表
我们往里面插入一些记录
大家可以仔细看一下,这两张表并不是完全对应的,学生表里classid = 3这个记录在我们的班级表里并没有存在
针对我们当前这个情况,不一定说学生表里classid所有的记录都在class表里,从原则上来说这两列数据是要相互关联好的,但是也不能保证百分之百的就是这个样子,像这样的情况就可能产生一些查找上的差异
针对这样的数据,如果我们进行联合查询,可能会出现一点小问题~~
比如:
这是我们内连接的结果
按照之前介绍过得笛卡尔积操作~~
很明显,这里的记录是少了一个4的同学的记录的~~
我们先看一下不加条件的笛卡尔积:
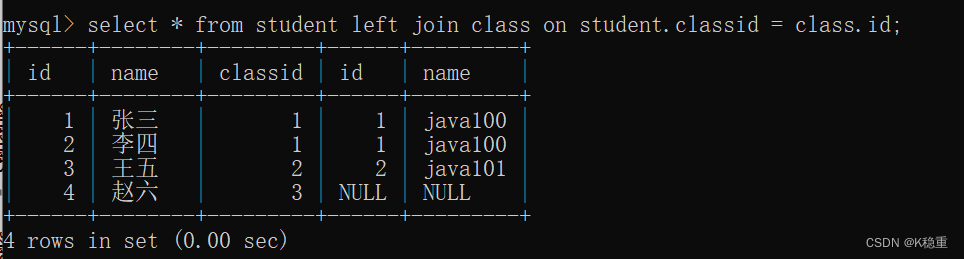
如果我们加上一个 left join
这会的结果和刚才相比就有一个明显的差别,上面的写法就相当于是一个inner join~
上面的结果就是两张表里面都同时包含的记录才会出现在结果里面
而下面的结果赵六其实在班级表里面并没有对应的一个班级信息,classid=3在班级表里不存在,但是我们在对他left join左连接的时候也会把赵六给列到结果里面,然后没有的就填NULL值
通过刚才的例子,可以看到left join和 inner join之间的区别~~
inner join 这里就要求的是两个表里都同时有的数据~~
left join 是以左侧表为主,会尽可能的把左侧表的记录都列出来,大不了后侧的表的对应列填成NULL
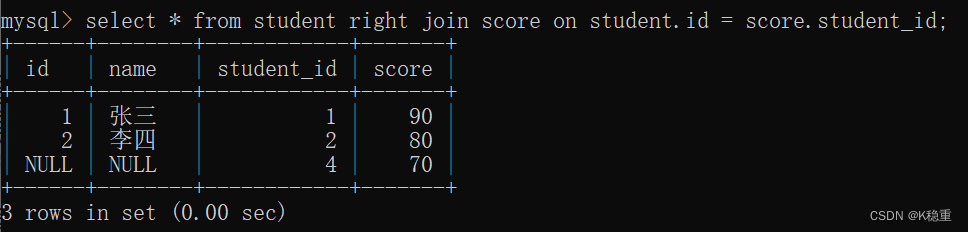
right join 也是类似~~ 就是以右侧的表为主,尽可能把右侧的记录都列出来,大不了左侧的表对应的列填成NULL~~
我们重新构造两个表
第一张表里面的3这个记录在第二张表里不存在
第二张表里面的4这个记录在第一张表里面不存在
这样的数据感觉不是都错了嘛
两个表不是应该完美对应嘛?
正常情况下,两个表是要完美对应的,
如果是完全对应,这个时候内连接和外连接就没有区别了.....
所以构造了这样一个场景让大家理解
这是内连接的情况
内连接里的记录就只是包含两个表中同时拥有的记录~~
这是左外连接情况
左外连接就是以左侧表为主,左侧表中的每个记录都在左外连接中有体现
右外连接情况
右外连接就是以右侧表为主
右侧表中的每个记录都在结果中有体现~~







总结
本章主要讲解了联合查询,也就是笛卡尔积的使用方法,区分了什么是内连接,外连接,外连接又包含左外连接,右外连接.通过案例引导大家如何使用多表查询,多表查询并不难,只要多练习一些题就会发现,其实套路都是一样的.文中有讲解不清楚的地方,或者没看懂的地方,都可以问我,哪里有错误也希望大家能给我指出来.

版权归原作者 K稳重 所有, 如有侵权,请联系我们删除。